
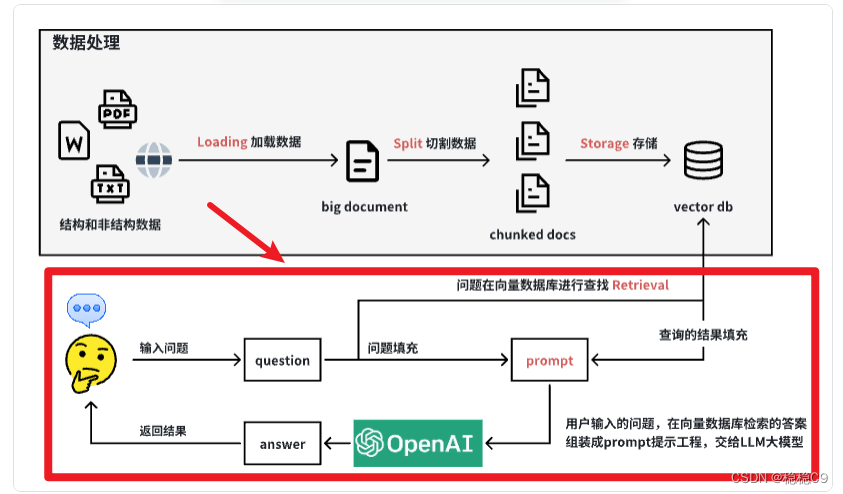
项目背景
在这个快节奏的职场世界里,我们每个人都可能在某个时刻,化身为一头辛勤的牛或一匹奔腾的马,面对入职签合同时的迷茫,或是离职时的纠纷,心中难免会涌现出各种疑问。比如:
- "这份合同里的条款,是保护我还是给我挖坑?"
- "加班费怎么算,难道是按草料的重量来计价的吗?"
- "离职时的赔偿金,是不是该按马的奔跑速度来计算?"
别担心,就算我们不是法律专家,也能在**《中华人民共和国劳动法》**的庇护下,找到解决问题的钥匙。现在,让我们用一点幽默来轻松一下,同时开发一款劳动法问答机器人,让它成为我们职场路上的得力助手。
实施方案
简单来讲,我们的计划是将**《中华人民共和国劳动法》**的内容向量化,并存储到向量化数据库中。在用户提出与劳动法相关的问题时,将问题检索向量数据库,通过提示工程组装交给大模型进行回复,最终得到最终答案。
模型选择:GPT-3.5 Turbo
下面为开发这个项目的流程说明以及详解:
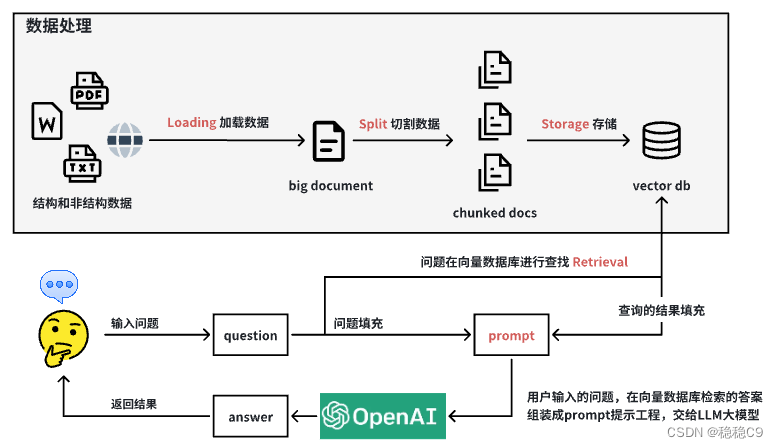
1. 数据加载 (Loading)
- 描述 : 将**《中华人民共和国劳动法》**的法律文档加载到本地系统中。
- 目的: 使文档变成LangChain能够识别和处理的格式。
2. 文本切割 (Split)
- 描述: 将大型法律文档切割成指定大小的文档块。
- 目的: 便于后续的存储和高效检索。
3. 向量化存储 (Storage)
- 描述: 对切割后的文档块进行向量化处理。
- 目的: 将文档块转换为LangChain可以索引的向量形式,并存储到向量数据库中。
4. 数据检索 (Retrieval)
- 描述: 用户提出问题后,在向量数据库中检索相关的文档块。
- 目的: 快速找到与用户问题最相关的法律条文。
5. 提示工程(Prompt)
- 描述: 组装用户输入的问题,以及检索后的文档快。
- 目的: 为LLM提供数据。
在整个项目开发过程中,LangChain平台提供了一系列工具和组件,极大地简化了开发流程,使我们能够轻松实现各项功能。
环境配置
安装python 3.11版本
网上已经有很多教程了,这里就不累赘了
安装langchain以及其它会用到的包
python
pip install langchain==0.2.6
pip install bs4
pip install langchain_community
pip install langchain_openaistep1 数据处理
1、数据加载 Loading
准备数据,《中华人民共和国劳动法》内容链接:中华人民共和国劳动法
Langchain提供了很多文档加载器,以面对各种类型的文档。本次我们使用的WebBaseLoader,
详细使用方法请看我文章中第二小节
03|LangChain | 从入门到实战 -六大组件之Retrival_longcontext-CSDN博客
当然你也可以看官方文档:WebBaseLoader | 🦜️🔗 LangChain
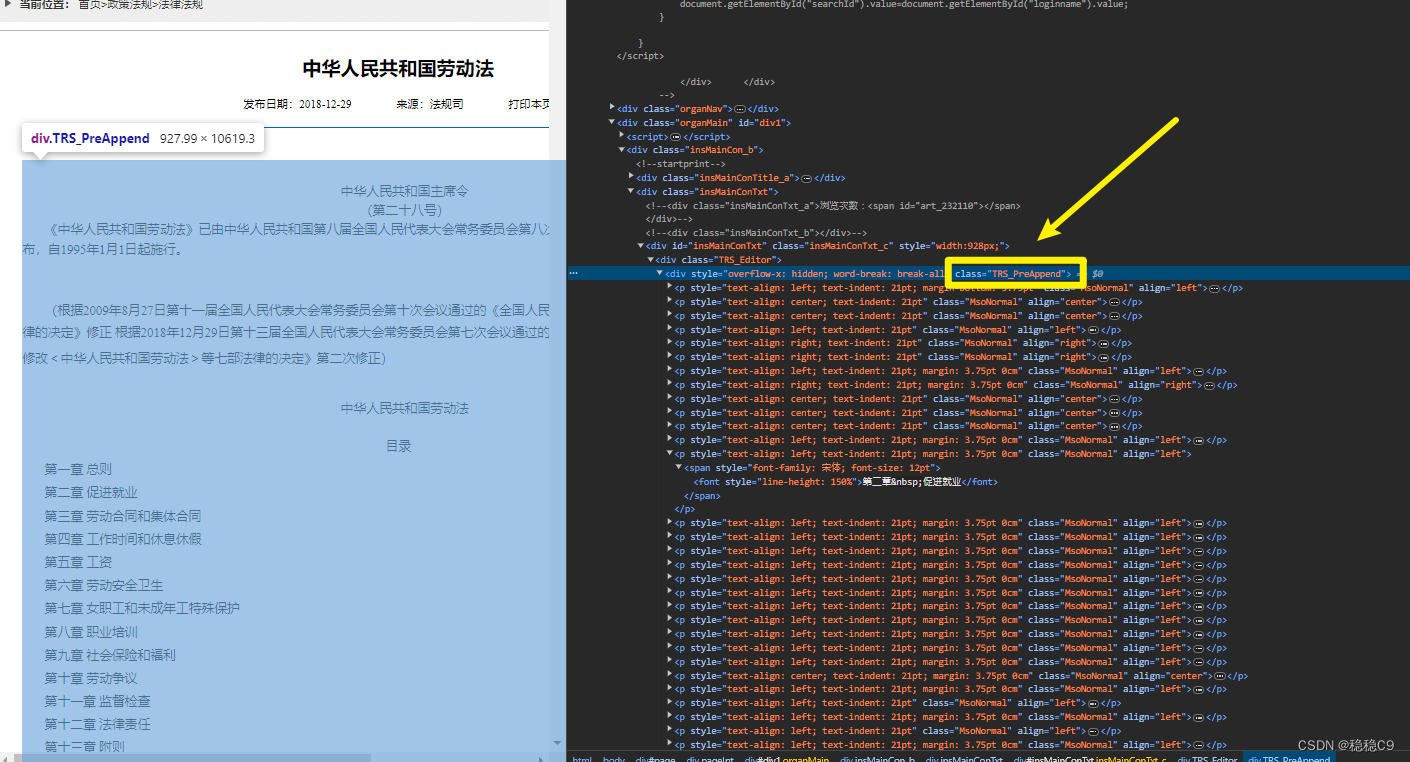
我们来观察一下数据,可以看到所有条目都是位于div class="TRS_PreAppend"
加载代码
python
import bs4
from langchain_community.document_loaders import WebBaseLoader
import os
os.environ["OPENAI_API_KEY"] = 'openAi key'
os.environ["OPENAI_API_BASE"] = "代理"
loader = WebBaseLoader(
web_path="https://www.mohrss.gov.cn/SYrlzyhshbzb/zcfg/flfg/201601/t20160119_232110.html",
bs_kwargs=dict(parse_only=bs4.SoupStrainer(
class_=("TRS_PreAppend")
))
)
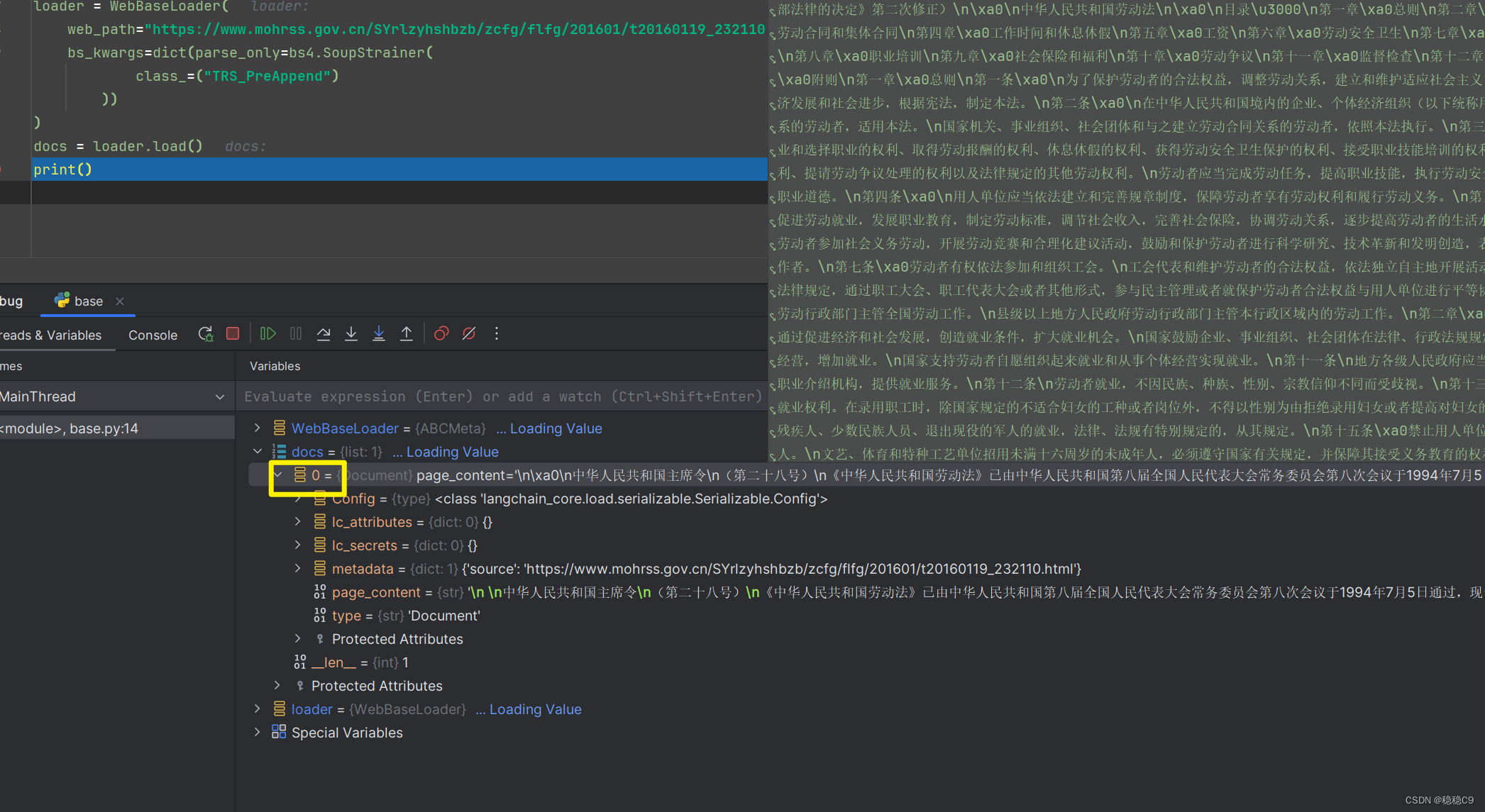
docs = loader.load()
print()打上断点可以发现,此时得到了一个 big documents
Langchain工具中的,WebBaseLoader 将 url网页的代码配合bs4 提取 html数据中 div 标签属性为TRS_PreAppend的数据。
2、切割数据 Split
现在我们有了数据,但是是一个非常大的文本内容。
或许你有疑问,为啥要切割呢?
在我以往的文章中也讲过,LLM对于一次对话的token是有限制的。当然现在也有许多非常优秀的大模型甚至可以做到一次对话128k,但是本次我们使用的模型为 GPT-3.5 Turbo ,所以还是需要切割的。
所以需要需要切割成小块的 chunk documents,以提交给LLM,才能进行问答。
同样的Langchain也提供了非常多的切割方法。
03|LangChain | 从入门到实战 -六大组件之Retrival_longcontext-CSDN博客我在这个小节有介绍常用的

Langchain官方介绍地址:How-to guides | 🦜️🔗 LangChain

在这里我们使用一个最基本的切割器:RecursiveCharacterTextSplitter
此文本分割器是推荐用于一般文本的分割器。它由字符列表参数化。它会尝试按顺序分割这些字符,直到块足够小。默认列表是"\\n\\n", "\\n", " ", ""。这样做的目的是尽量将所有段落(然后是句子,然后是单词)放在一起,因为这些段落在一般情况下似乎是语义上最相关的文本片段。
编写切割代码
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(docs)- chunk_size:指定切割的每个块的大小(以字符为单位)
- chunk_overlap:指定块之间的重叠部分的大小(以字符为单位)
这个是指切割后的每个 document 里包含几个上一个 document 结尾的内容, 主要作用是为了增加每个 document 的上下文关联。
比如,chunk_overlap=0时, 第一个 document 为 aaaaaa,第二个为 bbbbbb;
当 chunk_overlap=2 时, 第一个 document 为 aaaaaa,第二个为 aabbbbbb。
不过,这个也不是绝对的,要看所使用的那个文本分割模型内部的具体算法。
我们来看看切割后的内容,得到11个块

3、向量化存储 Vector
在当前项目中,我们已经成功解析并拆分获得了11个数据块。为了提高检索效率,避免在每次检索时重新进行解析操作,我们将这些数据块存储到数据库中,以便在需要时能够直接从数据库中快速查询。
我们选择使用向量数据库来存储和查询这些数据块。向量数据库的工作原理是将数据项转换成向量形式,这使得它在处理相似性搜索和聚类等任务时表现出色,具有高效率。
设想一下,如果我们有一系列复杂的机械零件,每个零件都有其独特的属性,如耐用性、重量、尺寸和材料类型。向量数据库将这些属性转化为数值向量,例如(7, 2, 5, 3), (6, 3, 4, 2),每个元素代表该零件在某个特定属性上的评分或量度。当我们需要找到与给定零件相似的其他零件时,向量数据库会先将该零件的属性转换为向量,然后在数据库中搜索并返回与之最相似的其它零件的向量。
为了将数据块存入向量数据库,我们首先需要对这些数据进行向量化处理,也就是常说的"数据嵌入"。在这个过程中,LangChain 提供了多种嵌入技术,我们选择了 OpenAIEmbeddings 。这种嵌入方式利用 OpenAI 的 text-embedding-ada-002 模型来实现数据的向量化。在使用此嵌入方式之前,我们需要设置OPENAI_API_KEY,这是调用 OpenAI 服务所需的密钥。
通过这种方式,我们不仅优化了数据的存储和检索过程,还为系统增添了强大的语义理解能力,确保了在处理复杂查询时的准确性和效率。
向量数据库有很多,需要了解可以跳转到这个地方查看:Vector stores | 🦜️🔗 LangChain
这里我们选择使用Chroma,更多用法:Chroma | 🦜️🔗 LangChain
安装
python
pip install langchain-chroma现在,我们编写一个代码,将前面切割好的文档,存储到向量数据库中
python
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
db = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
persist_directory="./chroma_db")- documents:上一步切割后的文档块列表。
- embedding:嵌入函数,这里我们使用 OpenAI 的OpenAIEmbeddings。
- persist_directory:数据存储的目录。
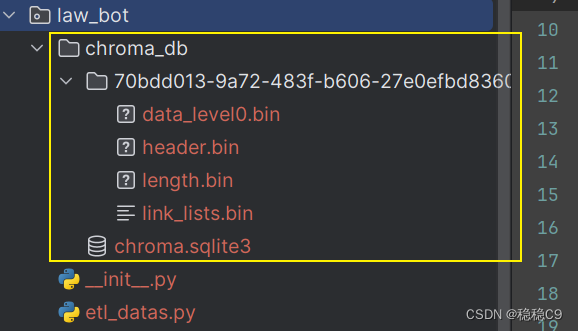
执行代码后,会在项目目录下自动生成了chroma_db目录,存放着向量化后的数据
4、数据处理完整代码
到现在,我们完成了从数据获取,到切割,存储到向量数据库的步骤,此刻贴上 etl_datas.py完整代码
python
import bs4
from langchain_community.document_loaders import WebBaseLoader
# 配置OpenAi密匙
import os
os.environ["OPENAI_API_KEY"] = 'openai key'
os.environ["OPENAI_API_BASE"] = "代理地址"
# 构建加载器,加载URL数据
loader = WebBaseLoader(
web_path="https://www.mohrss.gov.cn/SYrlzyhshbzb/zcfg/flfg/201601/t20160119_232110.html",
bs_kwargs=dict(parse_only=bs4.SoupStrainer(
class_=("TRS_PreAppend")
))
)
docs = loader.load()
# 切割文档
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 向量化数据
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
db = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
persist_directory="./chroma_db")step2 创建问答机器人
现在我们要开始构建第二步,创建问答机器人。
这里运用Langchain当中的模块清单:
-
Retrieval检索器,Langchain集成了与向量数据库 增删改查的封装
-
Chain 我在文章当中有详细介绍 04|LangChain | 从入门到实战 -六大组件之chain-CSDN博客

-
Prompt提示模版工程,让LLM获悉外部的数据,以解决某些任务,得到具体结果行为
-
LangServe LangServe帮助开发人员将可运行LangChain 对象和链部署 为 REST API。更多内容参考:GitHub - langchain-ai/langserve: LangServe 🦜️🏓
总的来说,Chain 帮助我们串联整个流程,并且利用 **LangServe,**快速构建交互API,配合web网页进行操作。
1、创建提示 Prompt
你可以理解 Prompt是与LLM沟通的方式,Prompt编写的好坏决定了最后的效果,关于Prompt也有
提示词是一门大学问,可以阅读一下这个地址:🟢 AI 简介
这里我们运用RAG工程
++RAG(Retrieval Augmented Generation)++检索增强生成,通过检索增强大模型的生成能力。
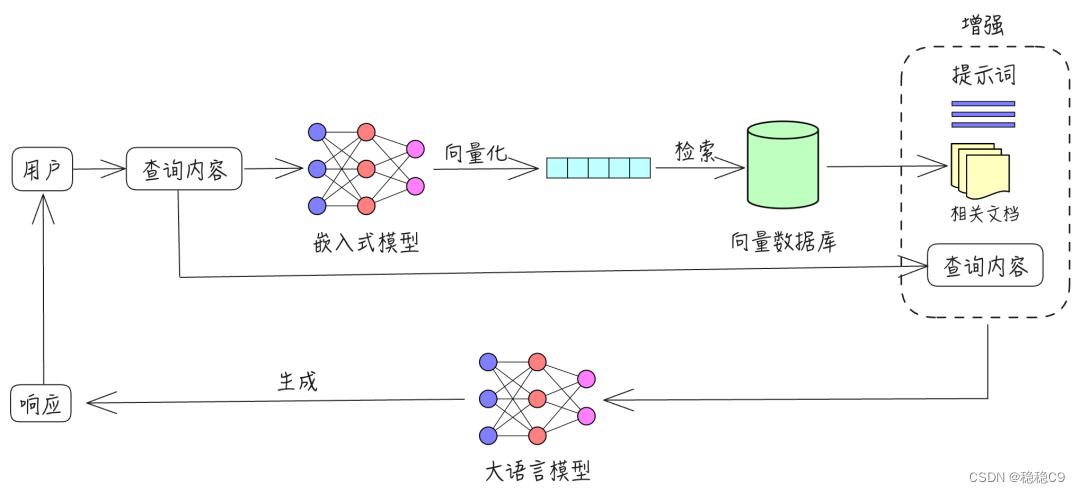
参考论文:https://arxiv.org/abs/2005.11401
假设一位你需要从繁杂的**《中华人民共和国劳动法》**中找到相关的法律条文来协助处理劳动争议或合同问题,那么他有三种方式可以使用:
-
最原始的方法 :他可以直接翻阅纸质版的**《中华人民共和国劳动法》**,或者查询其电子版,然后仔细阅读以掌握具体的法律条文和操作方法。如果他遇到的劳动问题较为复杂,就需要综合多个章节的内容,自行分析和理解法律条文的适用。
-
借助问答机器人:他也可以向问答机器人(chatbot)咨询,机器人能够提供相关的法律知识。但这种方法可能存在两个问题:一是机器人可能只能提供类似常见问题解答(FAQ)式的服务,需要用户自己整合答案;二是机器人需要大量的预训练和知识库的构建,这通常需要专业法律人员的大量工作,逐条输入法律条目及其相似问法,这在大规模推广时可能不太实用。
-
使用RAG技术 :第三种方式是将**《中华人民共和国劳动法》**的电子版上传到RAG(Retrieval-Augmented Generation)系统中,系统能在几分钟内创建索引,供专员进行咨询。RAG系统不仅能提供综合了整个法律文本的多个知识点的答案,还能以专家的口吻给出建议:"要解决这个问题,你需要先确认两个前提条件,并有三种可能的解决途径。下面我们逐步分析具体的操作步骤..."。
通过RAG技术,你可以能够快速获得全面、综合的法律建议,极大地提高了工作效率和解决问题的准确性。这种方法不仅减少了查找和分析法律条文的时间,还为用户提供了一种更为智能和高效的法律咨询服务。
下面我们使用Langchain提供的一个最基本的RAG 提示
"""
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
翻译成中文
你是问答任务的助手。使用以下检索到的上下文来回答问题。如果你不知道答案,就说你不知道。最多使用三个句子并保持答案简洁。
问题:{question}
上下文: {context}
答案:
这里我们使用Langhcain最基础的模版 PromptTemplate ,可以看到下面有2个参数
- {question} 将用户传入的问题进行填充
- {context} 向量数据库检索出来的数据
python
from langchain.prompts.prompt import PromptTemplate
prompt_template_str = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt_template = PromptTemplate.from_template(prompt_template_str)我在我的文章中有详细介绍:02|LangChain | 从入门到实战 -六大组件之Models IO_langchain编程:从入门到实践-CSDN博客
2、检索向量数据库
Langchain集成了与向量数据库 增删改查的封装,开箱即用。
前面我们将数据存储在本地db中,现在,我们利用Langchain查询一下DB,看看效果。
python
# 配置OpenAi密匙
import os
os.environ["OPENAI_API_KEY"] = ''
os.environ["OPENAI_API_BASE"] = ""
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 链接本地向量数据库
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=OpenAIEmbeddings()
)
# 构建检索器
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
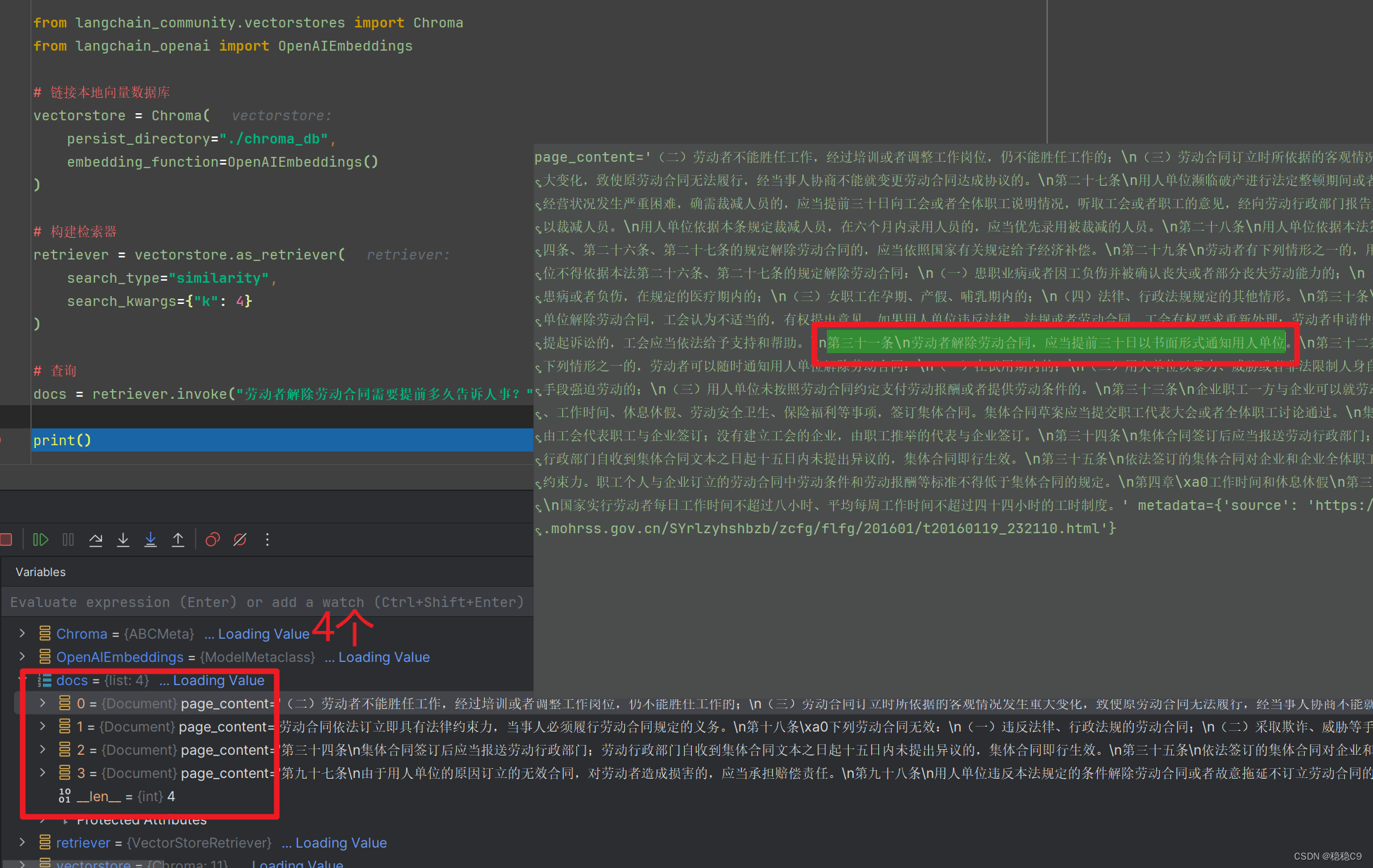
# 查询
docs = retriever.invoke("劳动者解除劳动合同需要提前多久告诉人事?")
print()在上面代码中使用的是 OpenAIEmbeddings() 向量模型
并且利用检索器的相似度算法,去查询检索出4条可能相关的知识,并且我们看第一个检索出来的数据,可以看到答案就在这里
3、创建Chain
现在我们已经得到了 检索出来的知识,现在我们要将前面流程通过Langchain提供的Chain串联起来。
在此之前,我们先安装一个包,用于后面生成Chain的图
python
pip install grandalf其中这个包会比较麻烦
python
pip install pygraphviz如果在你安装 pygraphviz 这个包报错了,请参考我另外一个方法
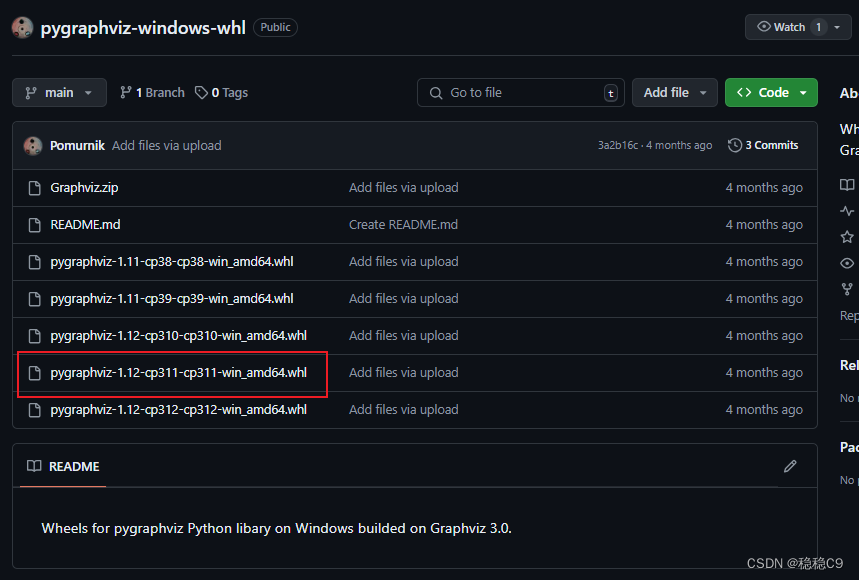
因为我们是python3.11 环境,所以选择这个,点击下载
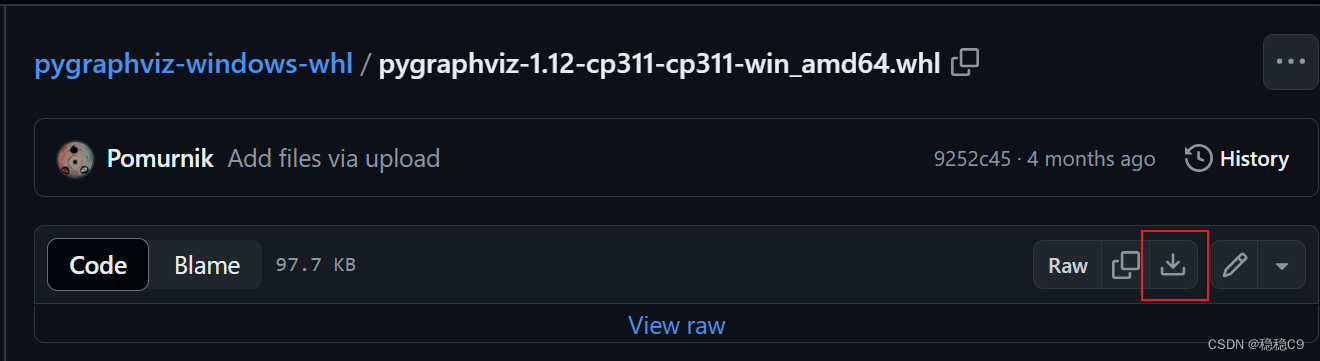
下载好的文件复制到工程下,进入到这个目录执行安装即可
python
pip install .\pygraphviz-1.12-cp311-cp311-win_amd64.whl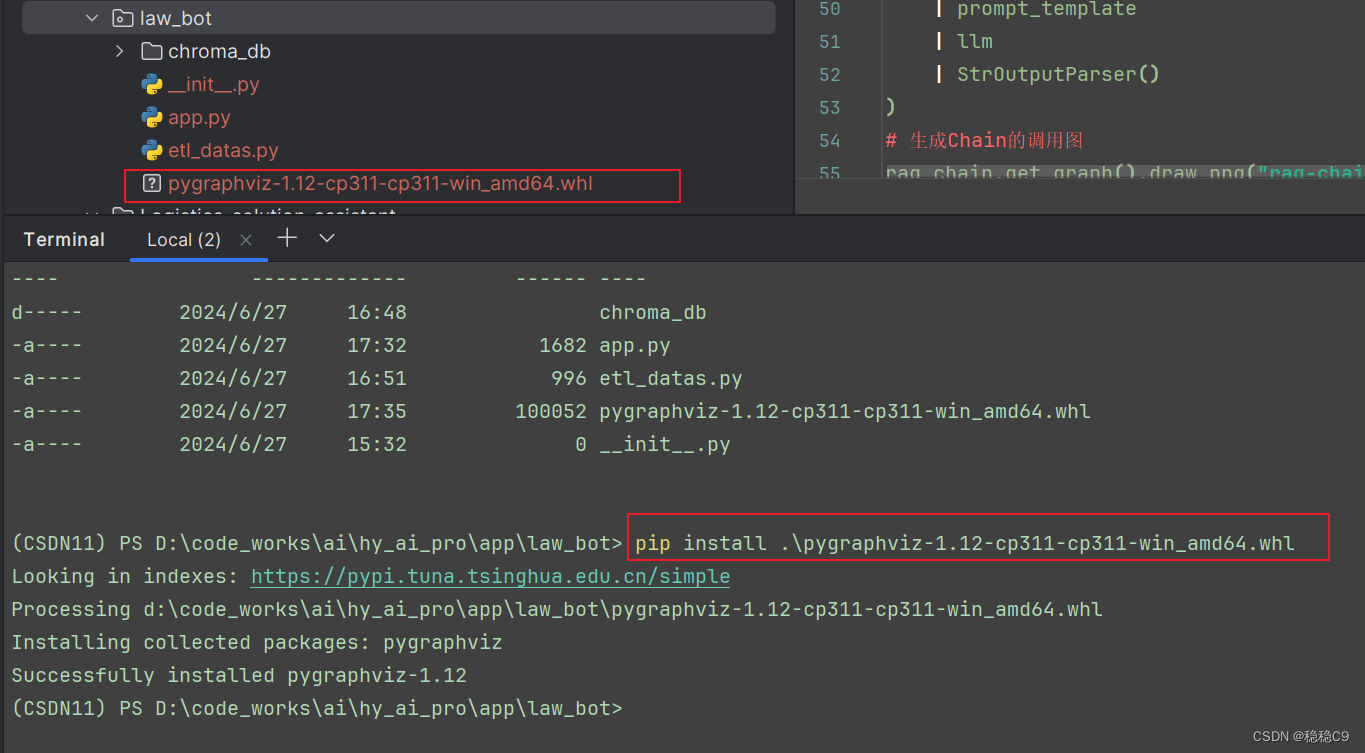
现在运行我这个代码
python
# 配置OpenAi密匙
import os
os.environ["OPENAI_API_KEY"] = ''
os.environ["OPENAI_API_BASE"] = ""
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 链接本地向量数据库
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=OpenAIEmbeddings()
)
# 构建检索器
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
# 查询
# docs = retriever.invoke("劳动者解除劳动合同需要提前多久告诉人事?")
# 将前面查询出来的结果,提取成一个大的文本
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 构建RAG链
from langchain.prompts.prompt import PromptTemplate
prompt_template_str = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt_template = PromptTemplate.from_template(prompt_template_str)
from langchain_core.runnables import RunnablePassthrough
from langchain_community.chat_models import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI()
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()} # 组装用户问题跟检索后的知识
| prompt_template # 提示模版
| llm # 大模型
| StrOutputParser() # 结构化输出
)
# 生成Chain的调用图
rag_chain.get_graph().draw_png("rag-chain.png")我们在目录下会得到一幅图,这个过程为链的调用过程,可能看起来有点抽象。
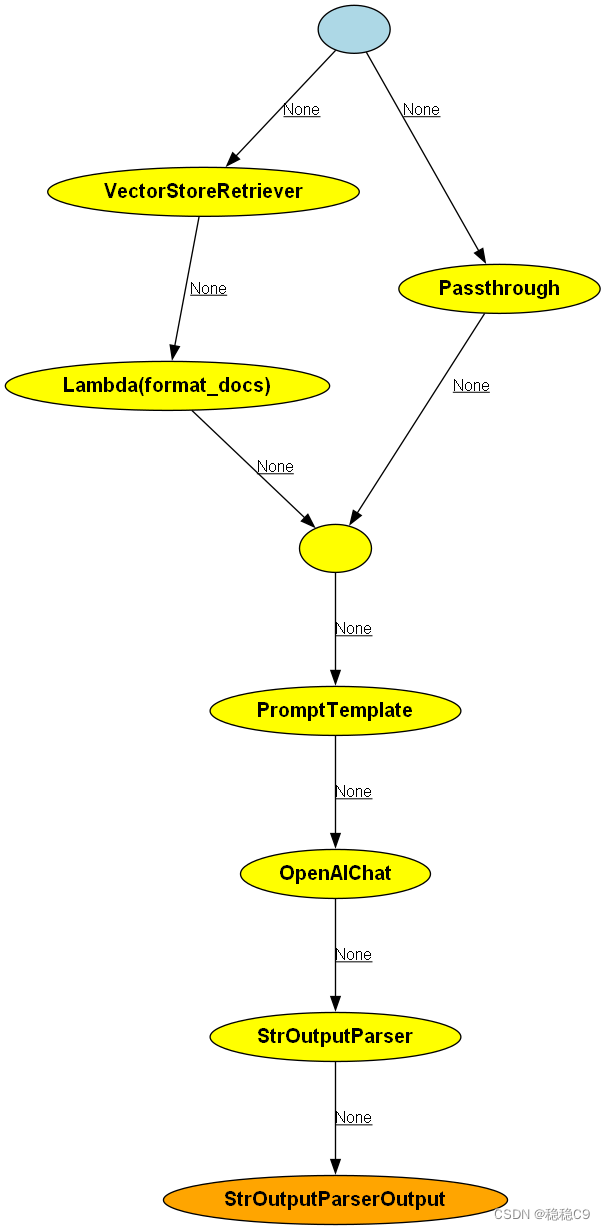
现在我将图简化一下说明
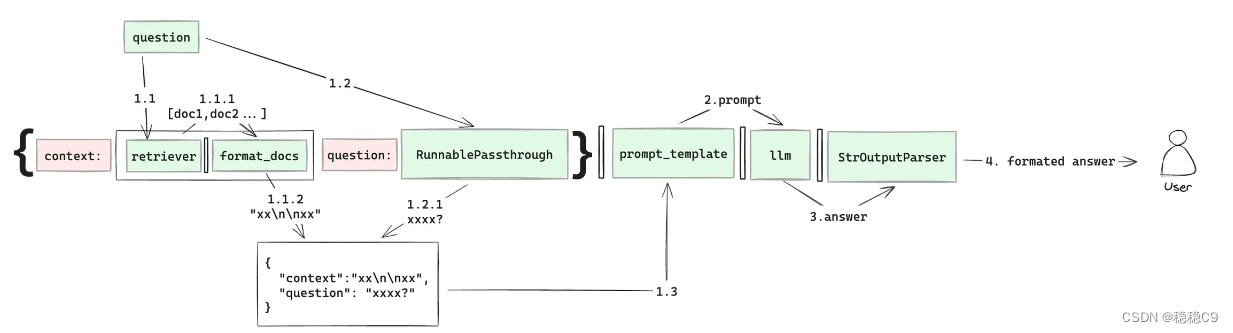
我们配合代码片段看
首先我们来说代码,这种写法为langchain的 LCEL 编码格式,LangChain Expression Language (LCEL) 翻译过来叫做langchain expression语言,详细内容参考
Conceptual guide | 🦜️🔗 LangChain
在构建劳动法问答机器人的过程中,Retriever组件扮演着至关重要的角色,它是整个信息检索流程的起点。用户输入的问题将首先被传递给Retriever,它负责在向量数据库中查询并筛选出相关的法律文档列表。以下是对您提供的段落进行优化后的描述:
在劳动法问答机器人的工作流程中,Retriever 是接收用户查询的第一站。用户提出的每一个问题,无论是关于劳动合同的细节还是劳动争议的解决,都会被自动送入Retriever进行处理。
Retriever 的核心任务是从向量数据库中检索与用户问题最相关的法律文档。这一步骤完成后,检索到的文档列表将被传递给Format_docs 组件。Format_docs 的作用是将文档列表转换成适合LLM(大型语言模型)处理的字符串格式,确保信息的流畅性和可读性,并将转换后的字符串赋值给context变量,为下一步的LLM处理提供上下文。
在这一过程中,RunnablePassthrough 作为一个直通组件,确保了从Retriever 到Format_docs 的数据流转。由于我们处于整个链的第一环节,RunnablePassthrough() 将捕获用户原始的问题,并将其作为问题变量question进行传递。
随着**context 和question 两个关键变量的准备就绪,我们便可以利用它们与预先定义的提示词模板结合,构建最终的prompt 。这个prompt将引导LLM生成精准的答案。
LLM 在接收到prompt 后,将运用其语言理解与生成能力,提供一个经过深思熟虑的答案。生成的答案随后被送入**StrOutputParser**------一个专门的输出解析器,它负责对答案进行格式化处理,确保输出结果的准确性和可读性。
最终,经过StrOutputParser处理的答案将以一种易于理解且专业的形式呈现给用户,完成整个问答过程。
4、部署应用
我们现在都是代码级别,需要一个web页面及其后端接口才能更好的进行交互。
LangServe 帮我们解决了这个问题
LangServe GitHub - langchain-ai/langserve: LangServe 🦜️🏓

详细内容见:langchain/templates/README.md at master · langchain-ai/langchain · GitHub
安装包
python
pip install langserve
pip install sse_starlette编写服务代码 app.py
python
# 配置OpenAi密匙
import os
os.environ["OPENAI_API_KEY"] = ''
os.environ["OPENAI_API_BASE"] = ""
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 链接本地向量数据库
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=OpenAIEmbeddings()
)
# 构建检索器
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
# 查询
# docs = retriever.invoke("劳动者解除劳动合同需要提前多久告诉人事?")
# 将前面查询出来的结果,提取成一个大的文本
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 构建RAG链
from langchain.prompts.prompt import PromptTemplate
prompt_template_str = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt_template = PromptTemplate.from_template(prompt_template_str)
from langchain_core.runnables import RunnablePassthrough
from langchain_community.chat_models import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI()
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()} # 组装用户问题跟检索后的知识
| prompt_template # 提示模版
| llm # 大模型
| StrOutputParser() # 结构化输出
)
# 生成Chain的调用图
# rag_chain.get_graph().draw_png("rag-chain.png")
from fastapi import FastAPI
from langserve import add_routes
app = FastAPI(
title="劳动法智能助手",
version="1.0",
)
# 3. Adding chain route
add_routes(
app,
rag_chain,
path="/low_ai",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=7777)现在咱们运行脚本
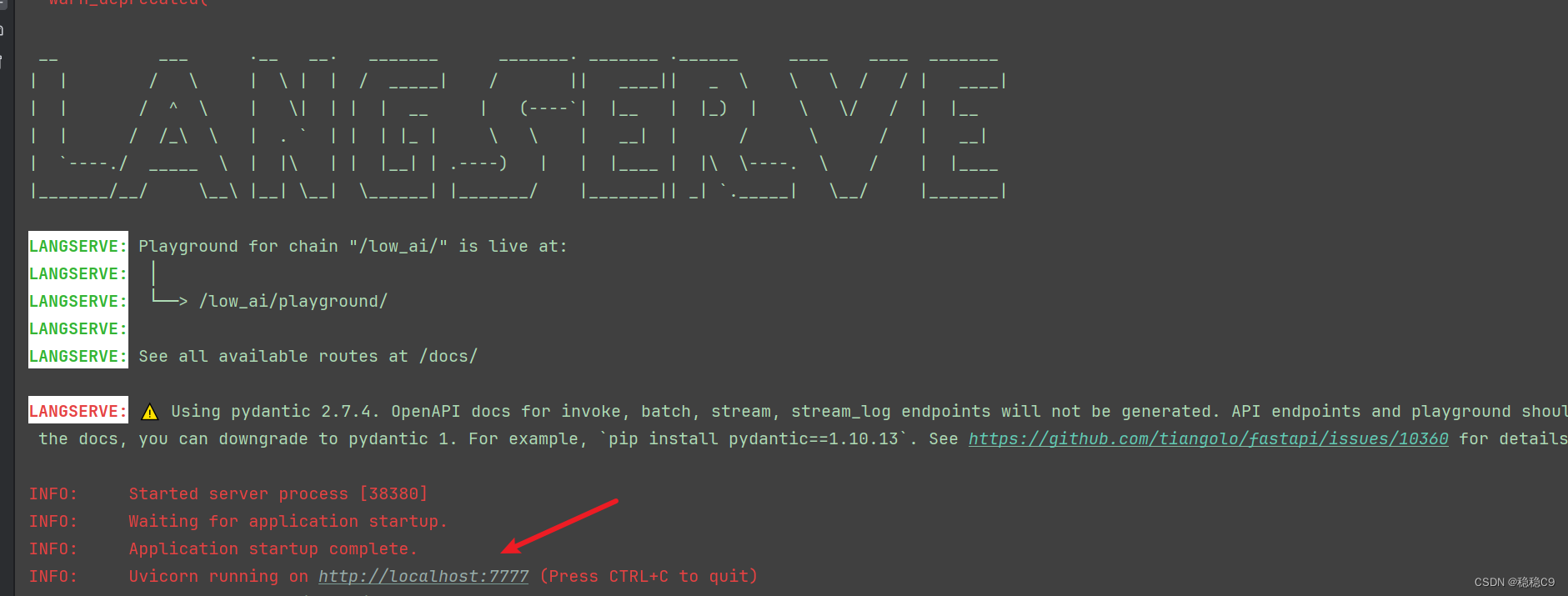
访问 http://localhost:7777/low_ai/playground/
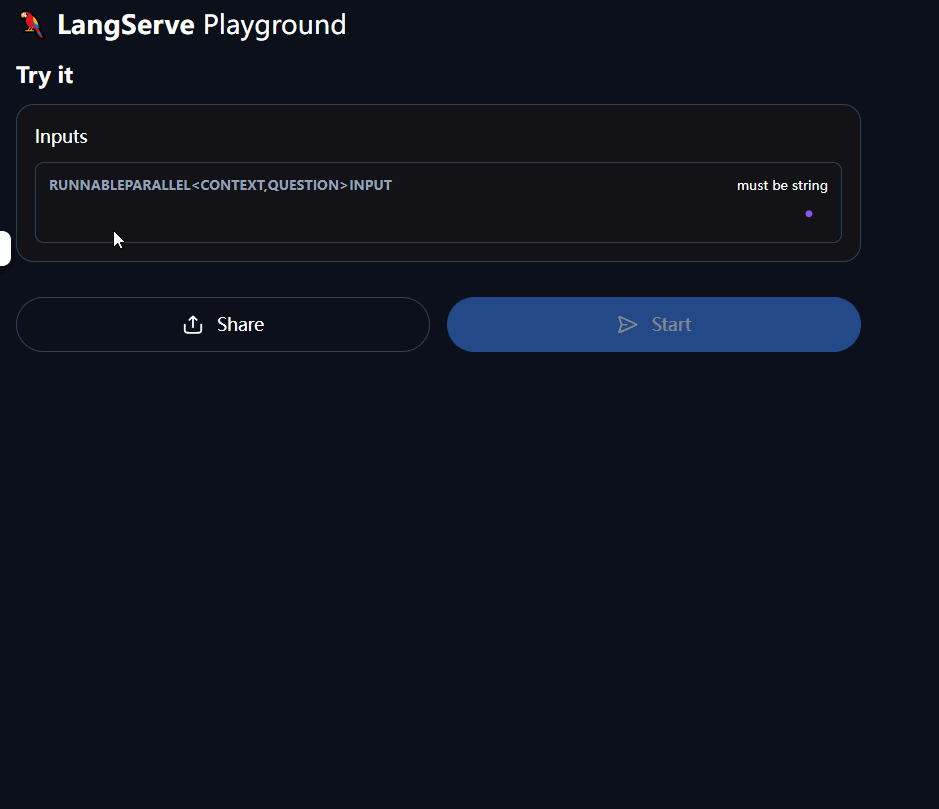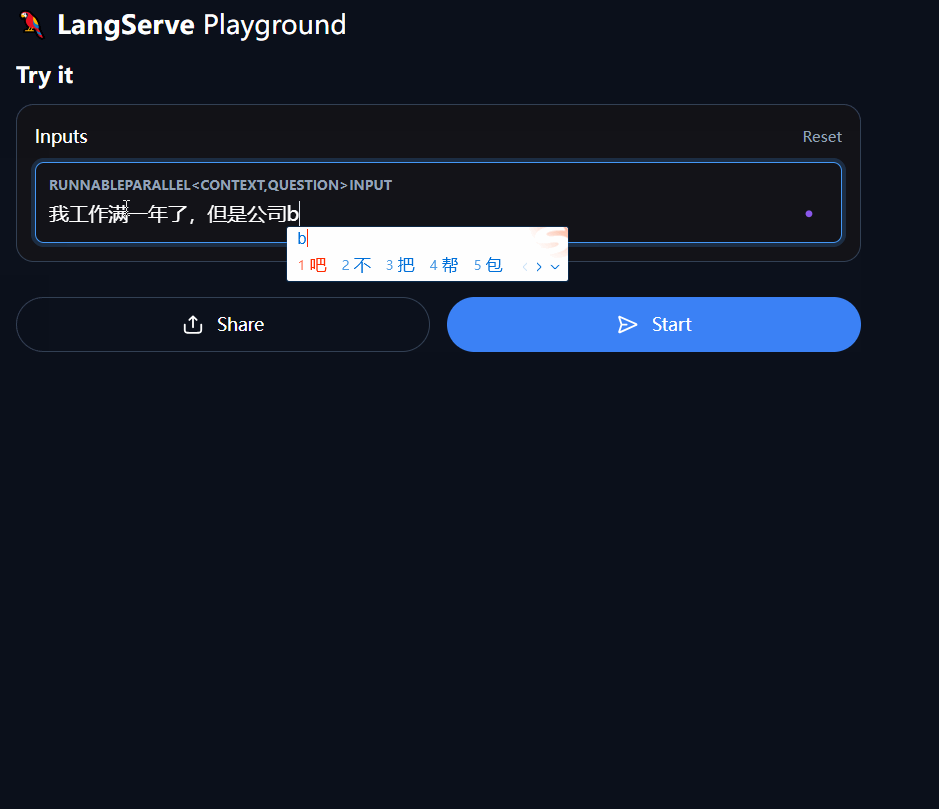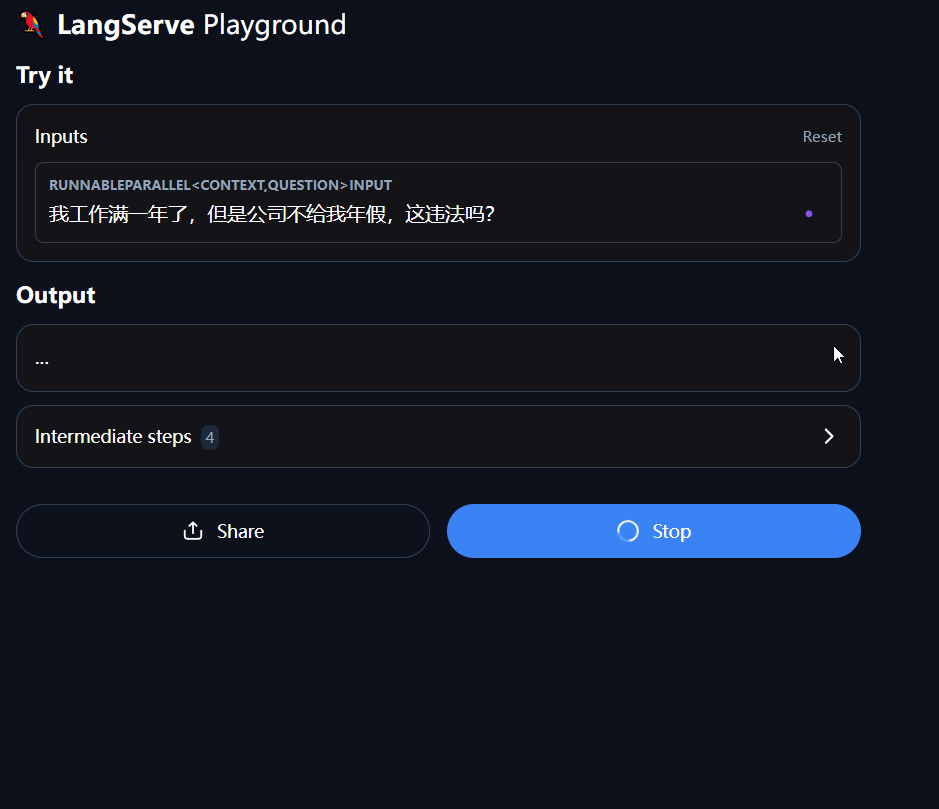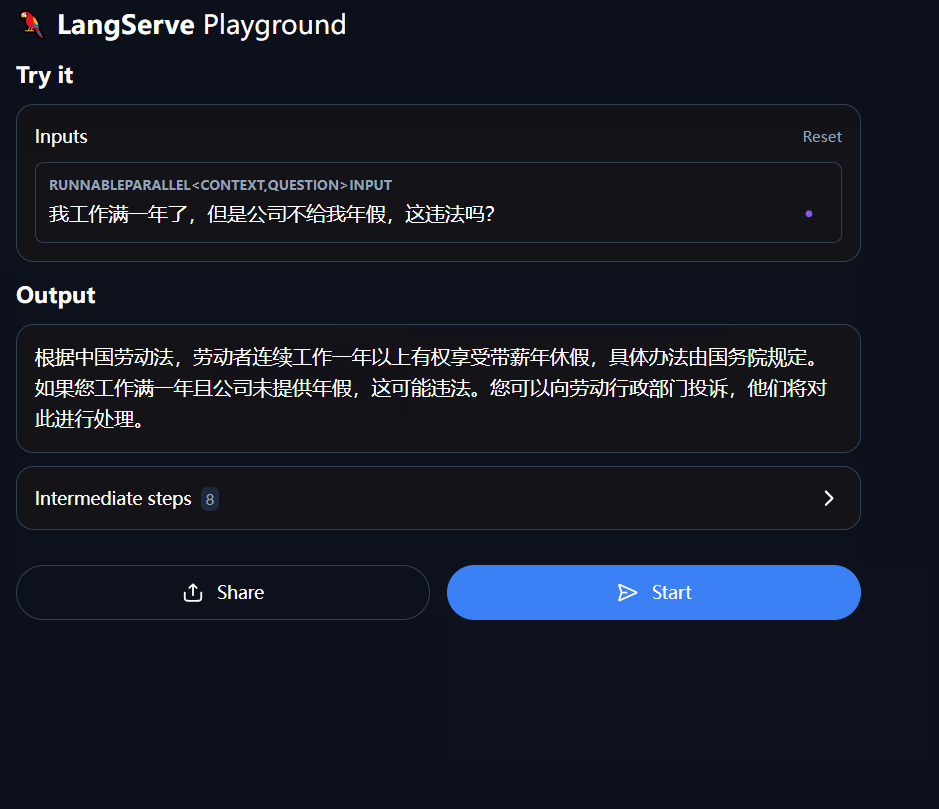
现在,输入你的问题!进行测试吧!
完整代码
数据处理:数据加载+数据切割+存储向量数据库
etl_datas.py
python
import bs4
from langchain_community.document_loaders import WebBaseLoader
# 配置OpenAi密匙
import os
os.environ["OPENAI_API_KEY"] = 'openai key'
os.environ["OPENAI_API_BASE"] = "代理地址"
# 构建加载器,加载URL数据
loader = WebBaseLoader(
web_path="https://www.mohrss.gov.cn/SYrlzyhshbzb/zcfg/flfg/201601/t20160119_232110.html",
bs_kwargs=dict(parse_only=bs4.SoupStrainer(
class_=("TRS_PreAppend")
))
)
docs = loader.load()
# 切割文档
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
# 向量化数据
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
db = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
persist_directory="./chroma_db")应用构建:创建 llm ,创建prompt,检索数据库,构建 web 服务
python
# 配置OpenAi密匙
import os
os.environ["OPENAI_API_KEY"] = 'openai key'
os.environ["OPENAI_API_BASE"] = "代理地址"
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
# 链接本地向量数据库
vectorstore = Chroma(
persist_directory="./chroma_db",
embedding_function=OpenAIEmbeddings()
)
# 构建检索器
retriever = vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 4}
)
# 查询
# docs = retriever.invoke("劳动者解除劳动合同需要提前多久告诉人事?")
# 将前面查询出来的结果,提取成一个大的文本
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
# 构建RAG链
from langchain.prompts.prompt import PromptTemplate
prompt_template_str = """
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt_template = PromptTemplate.from_template(prompt_template_str)
from langchain_core.runnables import RunnablePassthrough
from langchain_community.chat_models import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
llm = ChatOpenAI()
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()} # 组装用户问题跟检索后的知识
| prompt_template # 提示模版
| llm # 大模型
| StrOutputParser() # 结构化输出
)
# 生成Chain的调用图
# rag_chain.get_graph().draw_png("rag-chain.png")
from fastapi import FastAPI
from langserve import add_routes
app = FastAPI(
title="劳动法智能助手",
version="1.0",
)
# 3. Adding chain route
add_routes(
app,
rag_chain,
path="/low_ai",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=7777)