
-
作者:Josh Qixuan Sun, Xiaoying Xing, Huaiyuan Weng, ChulMin Yeum, Mark Crowley
-
单位:滑铁卢大学电气与计算机工程系,西北大学电气与计算机工程系,滑铁卢大学土木与环境工程系
-
论文标题:View Invariant Learning for Vision-Language Navigation in Continuous Environments
主要贡献
-
引入新的评估场景V2-VLNCE,在该场景中,通过改变相机高度和视角角度来模拟真实世界中不同的相机视角,从而能够更真实、系统地分析视角鲁棒性。
-
提出视角不变学习策略VIL,该策略通过对比学习框架来学习稀疏且视角不变的特征,并引入教师-学生框架用于航点预测模块,以增强现有导航策略对相机视角变化的鲁棒性。
-
通过大量实验表明,VIL方法在V2-VLNCE设置下优于现有的基线方法,且在标准VLNCE设置下,尽管是针对不同视角进行训练的,VIL通常仍能提高性能,可作为一种即插即用的后训练方法来改进现有策略。
研究背景
-
VLNCE任务的重要性:VLNCE(Vision-Language Navigation in Continuous Environments)是一个关键的具身AI研究问题,要求智能体能够根据人类指令自由移动以到达目的地。然而,大多数导航策略对视角变化较为敏感,即使较小的相机高度和视角角度的变化也可能导致性能大幅下降,这限制了这些策略在真实世界中的应用。
-
现有工作的局限性:虽然此前有一些工作关注视角变化问题,但它们大多针对机器人操作任务而非导航任务,且通常采用两阶段训练流程,或者只考虑单一固定视角,无法有效解决VLNCE任务中视角多样性带来的挑战。
方法
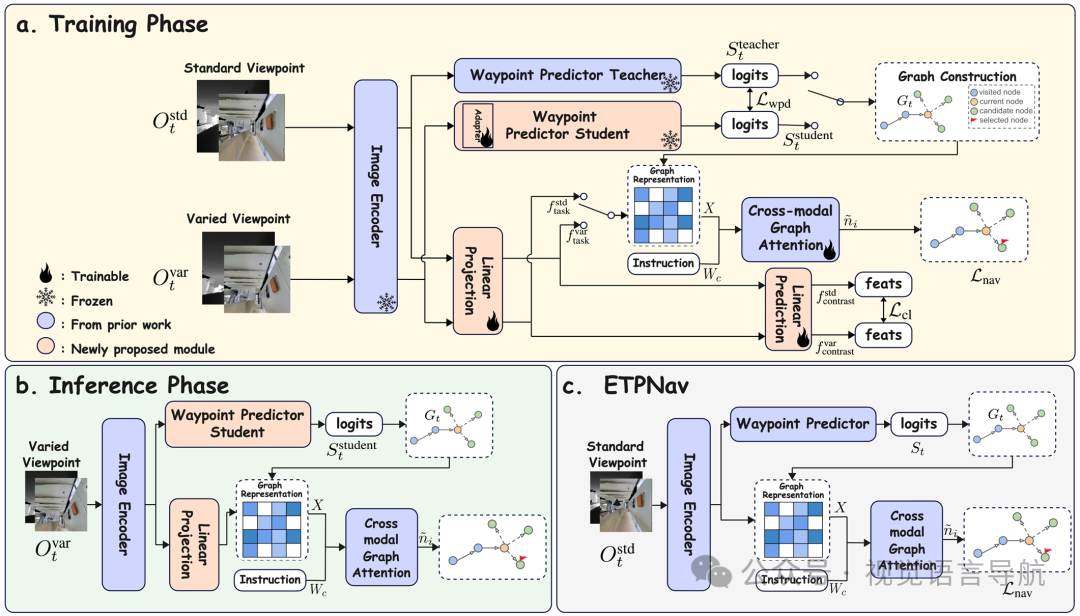
ETPNav基础架构
论文使用ETPNav作为VIL策略的基础架构TPAMI-2024 | 中科院模式识别国重连续环境具身导航!ETPNav:基于进化拓扑规划的连续环境视觉语言导航,其主要结构和处理流程如下:
-
全景观测和指令输入:在每个时间步,智能体接收全景RGB-D观测,包含12个RGB图像和12个深度图像,分别从12个等间距的朝向角度(0°, 30°, ..., 330°)捕获。此外,智能体还接收自然语言指令。
-
航点预测和拓扑映射:基于当前全景观测,航点预测器生成一个密集的热图,表示附近可导航的航点。通过非极大值抑制(NMS)从热图中采样航点,并将这些航点作为新节点添加到动态更新的局部拓扑图中。
-
跨模态图编码:使用LXMERT文本编码器将指令编码为文本嵌入。然后,将节点特征集合和指令嵌入通过跨模态图注意力(CMGA)模块进行联合处理,该模块实现为一个多头自注意力层(MHSA)。输出表示经过图感知交互后的跨模态节点嵌入。
-
目标预测:最后,通过一个前馈网络(FFN)基于每个节点的跨模态嵌入预测目标分数,智能体选择分数最高的节点作为下一个导航目标。导航损失是智能体预测和真实动作之间的交叉熵损失。
视角不变表示学习
为了解决现有VLNCE策略对视角变化敏感的问题,论文提出了对比学习目标,以鼓励视角不变的特征表示,促进标准和变化观测之间的一致性。具体方法如下:
-
生成不同视角的观测:对于每个时间步的全景RGB-D观测,生成两种视图:标准视角和变化视角,通过随机改变相机高度和角度来创建变化视角。
-
特征提取和投影:使用共享的视觉编码器对两种视图进行编码,然后应用一个三层投影头,按照SimCLRv2的标准设计。第一层输出记为,第二层为,第三层为。用于下游导航任务和对比学习的特征分别为:
-
构建图表示和对比学习样本:为了与预训练的ETPNav模型兼容,初始化第一层线性层为单位矩阵,保留原始特征分布。在对比学习中,将标准视图和变化视图的特征分别记为和,并构建正样本和负样本对。对于训练批次中的每个实例,定义正样本对为同一朝向下标准视图和变化视图的特征,负样本对则通过选择相反朝向的特征或不同场景中相同朝向的特征来构建。
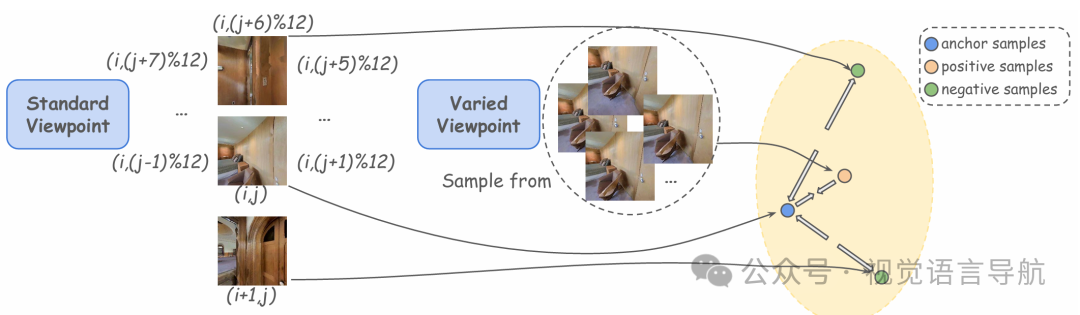
- 对比学习损失:采用InfoNCE损失函数来优化对比学习目标,促使模型学习到对视角变化更鲁棒的特征表示。损失函数公式为:其中,是标准视图的特征,是同一场景下变化视图的特征,是负样本的特征,表示余弦相似度。
教师-学生航点预测蒸馏
针对VLNCE任务中航点预测模块对视角变化敏感的问题,论文提出了一个教师-学生框架,以实现鲁棒的航点预测。具体实现如下:
-
教师和学生模型的初始化:教师模型和学生模型共享相同的航点预测器架构,均初始化为ETPNav中使用的模型。教师模型固定,处理标准视角观测,而学生模型处理变化视角观测。
-
学生模型的训练:为了让学生模型能够适应视角变化,仅训练学生模型中的早期线性变换层(称为适配器模块),而其余模型权重保持冻结。这种选择性训练确保了学生模型能够平滑地调整到视角变化。
-
航点预测的蒸馏损失:给定时间步的观测,教师模型输出航点logits,学生模型输出。通过KL散度作为蒸馏损失来对齐学生模型和教师模型的输出:在图构建过程中,以一定概率从教师和学生模型的预测中采样,以构建局部拓扑图。
训练目标
VIL模型通过联合优化三个目标进行端到端训练:标准导航损失、对比学习损失和航点预测器蒸馏损失。总体训练损失公式为:
其中,和是平衡不同损失贡献的超参数。
实验
不同视角下的性能
-
实验设置:使用R2R-CE和RxR-CE两个基准数据集进行评估。R2R-CE包含5611条轨迹,平均路径长度为9.89米,每条指令平均包含32个单词;RxR-CE则更大且更具挑战性,指令平均长度为120个单词,路径平均长度为15.32米。评估指标包括导航误差(NE)、成功率(SR)、Oracle成功率(OSR)、路径长度惩罚的成功率(SPL)、归一化动态时间规整(nDTW)和成功加权的归一化动态时间规整(SDTW)。
-
基线方法:将VIL应用于两个强大的VLNCE基线方法BEVBert和ETPNav,并与现有的其他方法进行比较。
-
实验结果:
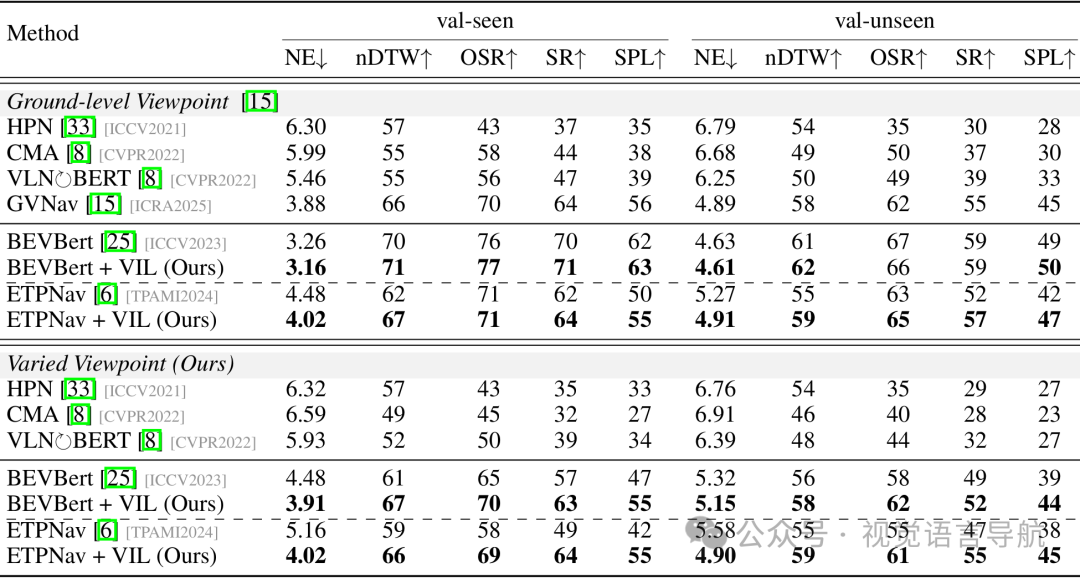

-
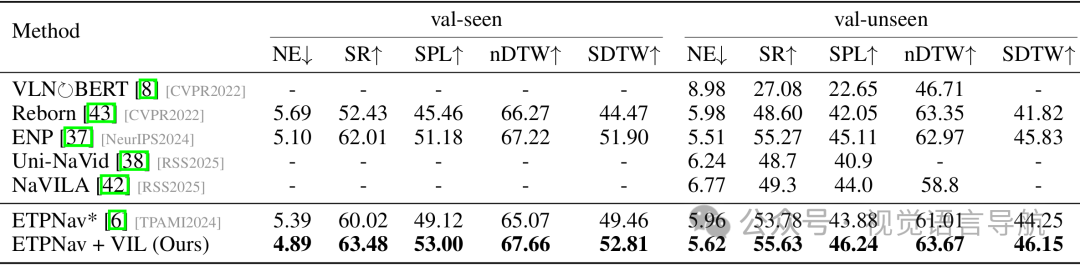
R2R-CE数据集:VIL显著提高了性能。例如,ETPNav + VIL相比于ETPNav在val-seen和val-unseen上分别将NE降低了0.68-1.14,nDTW提高了3%-7%,OSR提高了6%-9%,SR提高了8%-15%,SPL提高了7%-13%。BEVBert + VIL相比于BEVBert在val-unseen上的SPL从49.2提高到49.6。
-
RxR-CE数据集:VIL同样表现出色。ETPNav + VIL相比于ETPNav在val-seen和val-unseen上分别将nDTW提高了10%-13%,OSR提高了9%-13%,SR提高了11%-15%,SPL提高了10%-13%。
-
标准视角下的性能
-
实验设置:使用R2R-CE和RxR-CE数据集,在标准视角设置下进行评估。
-
基线方法:同样将VIL应用于BEVBert和ETPNav。
-
实验结果:
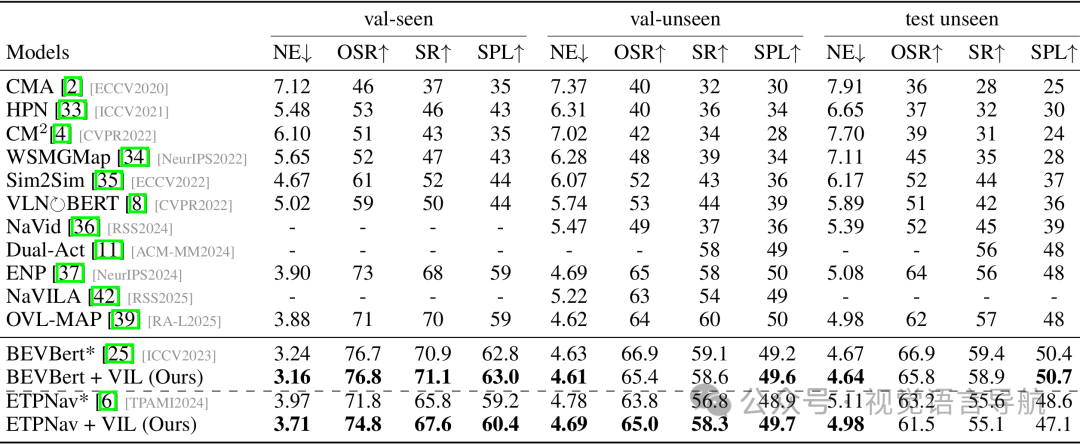
-
R2R-CE数据集:VIL不仅没有降低性能,还略有提升。例如,BEVBert + VIL相比于BEVBert在val-unseen上的SPL从49.2提高到49.6。ETPNav + VIL相比于ETPNav在val-unseen上的SR从56.8提高到58.3,SPL从48.9提高到49.7。
-
RxR-CE数据集:ETPNav + VIL相比于ETPNav在val-seen和val-unseen上分别将nDTW提高了2.61和2.36,OSR提高了2.38和1.85,SR提高了3.46和1.85,SPL提高了3.88和2.36。
-
消融研究
-
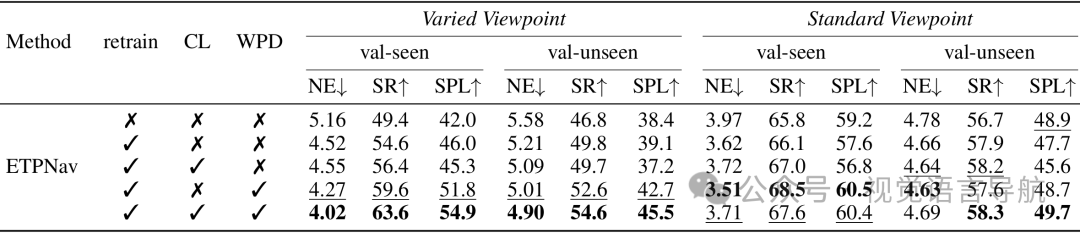
实验设置:在R2R-CE数据集上进行消融研究,评估以下三种情况:
-
仅在变化视角数据上重新训练模型(retrain)。
-
仅使用对比学习(CL)。
-
仅使用航点预测器蒸馏(WPD)。
-
同时使用对比学习和航点预测器蒸馏(CL + WPD)。
-
-
实验结果:
-
仅重新训练(retrain):在变化视角设置下,性能略有提升,但在标准视角设置下性能略有下降。例如,在val-unseen上,SPL从38.4%提升到39.1%,但在标准视角下SR从56.7%下降到55.9%。
-
仅使用对比学习(CL):在变化视角设置下,性能有所提升。例如,在val-unseen上,SPL从42.7%提升到45.5%。在标准视角设置下,虽然val-seen的SR略有下降,但val-unseen的SR和SPL有所提升。
-
仅使用航点预测器蒸馏(WPD):在变化视角设置下,性能显著提升。例如,在val-unseen上,SPL从37.2%提升到45.5%。在标准视角设置下,性能也有所提升。
-
同时使用对比学习和航点预测器蒸馏(CL + WPD):在变化视角和标准视角设置下,性能均显著提升。例如,在val-unseen上,SPL从38.4%提升到45.5%,在标准视角下SR从56.7%提升到58.3%,SPL从48.9%提升到49.7%。
-
视角鲁棒性分析
-
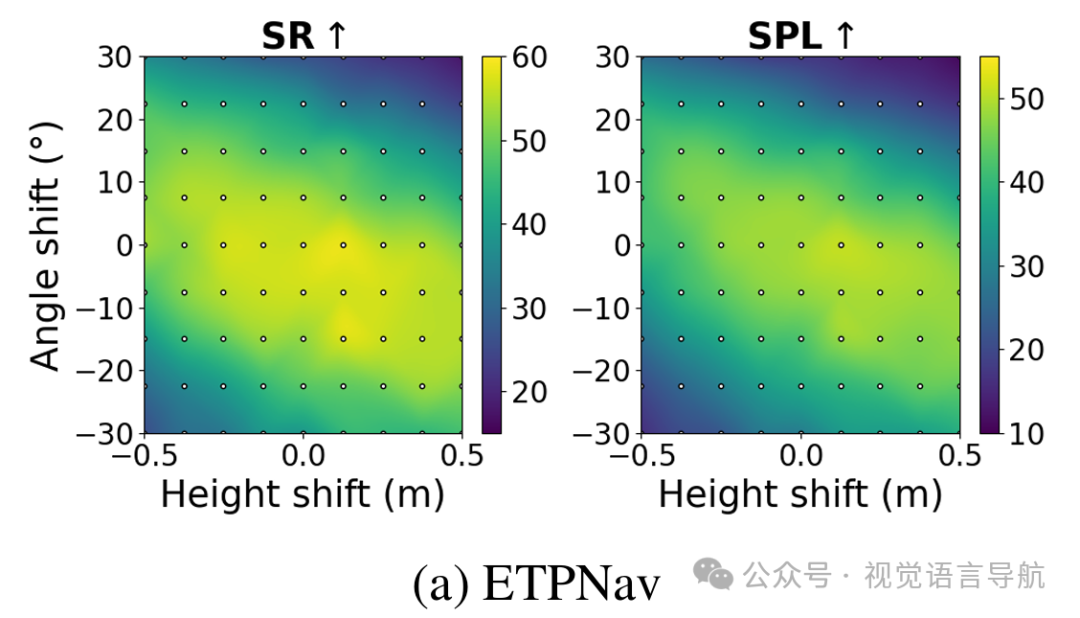
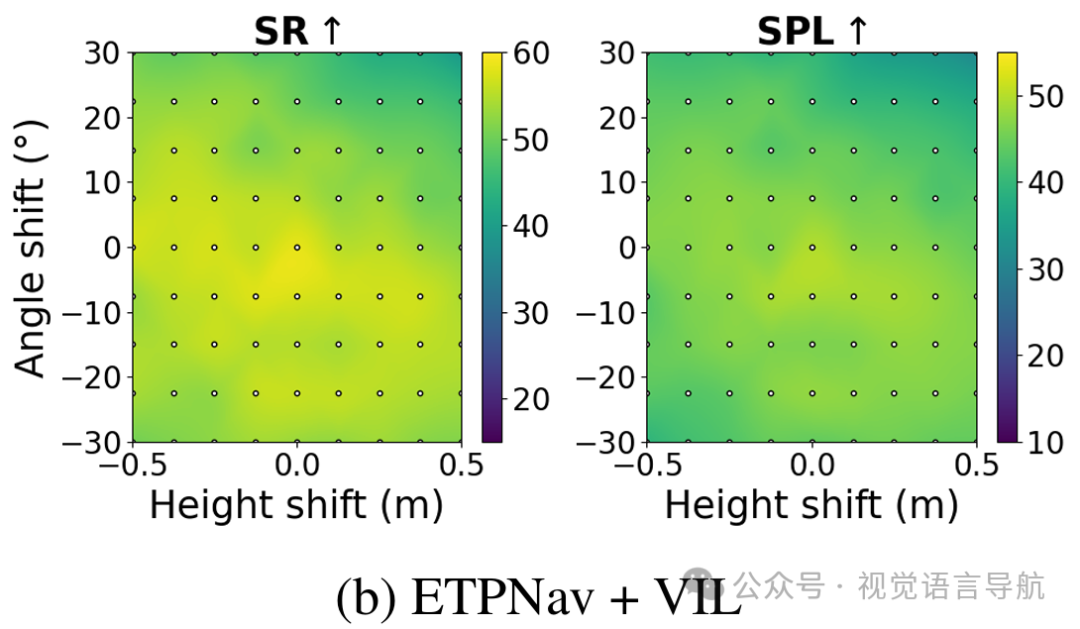
实验设置:在R2R-CE数据集的val-unseen集上,评估每个模型在81种不同的视角配置下的性能。每种配置由一个高度-角度对定义,从和的均匀网格中采样。
-
实验结果:
-
ETPNav:性能热图显示出强烈的视角依赖性,特别是在角落区域性能显著下降,标准差较大。例如,SPL的标准差为10.79,SR的标准差为10.54。
-
ETPNav + VIL:性能热图更加平滑,性能在不同视角配置下更加均匀,标准差显著降低。例如,SPL的标准差降低到3.59,SR的标准差降低到3.66。
-
结论与未来工作
-
结论:
- VIL策略有效地提高了VLNCE策略在不同相机高度和视角角度下的鲁棒性,并且在标准VLNCE设置下也能够保持或提高性能,是一种有效的后训练方法,可以增强现有VLNCE策略的泛化能力。
-
未来工作:
- 当前的研究仅考虑了相机的外参变化,未来可以探索将VIL扩展到处理相机内参变化(如图像分辨率或视场角)的情况,以进一步提高VLNCE策略在真实世界中的泛化能力。
