引言
今天带来一篇多智能体的论文笔记,Mixture-of-Agents Enhances Large Language Model Capabilities。
随着LLMs数量的增加,如何利用多个LLMs的集体专业知识是一个令人兴奋的开放方向。为了实现这个目标,作者提出了一种新的方法,通过混合代理(Mixture-of-Agents, MoA)方法学利用多个LLMs的集体优势。构建了一个分层的MoA架构,其中每一层都包含多个LLM代理。每个代理使用前一层代理的所有输出作为辅助信息来生成其响应。
代码发布在:https://github.com/togethercomputer/moa 。
1. 总体介绍
不同的LLMs具有独特的优势,并专注于各种任务方面。例如,一些模型擅长复杂指令的跟随,而其他模型可能更适合代码生成。不同LLMs之间的技能多样性提出了一个有趣的问题:我们能否利用多个LLMs的集体专业知识来创建一个更强大、更稳健的模型?
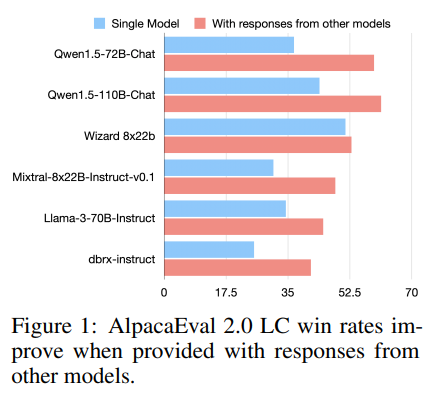
答案是肯定的,作者发现了一种内在现象,称之为LLMs的合作性(collaborativeness)现象,即当LLM接收来自其他模型的输出时,它往往会生成更好的响应,即使这些其他模型本身的能力较弱。图1展示了6个热门LLMs在AlpacaEval 2.0基准测试上的LC胜率。当这些模型独立生成的回复提供给它们时,它们的LC胜率显著提高。这表明合作性现象在LLMs之间是普遍存在的。哪怕其他模型提供的辅助响应质量低于单个LLM独立生成的质量。
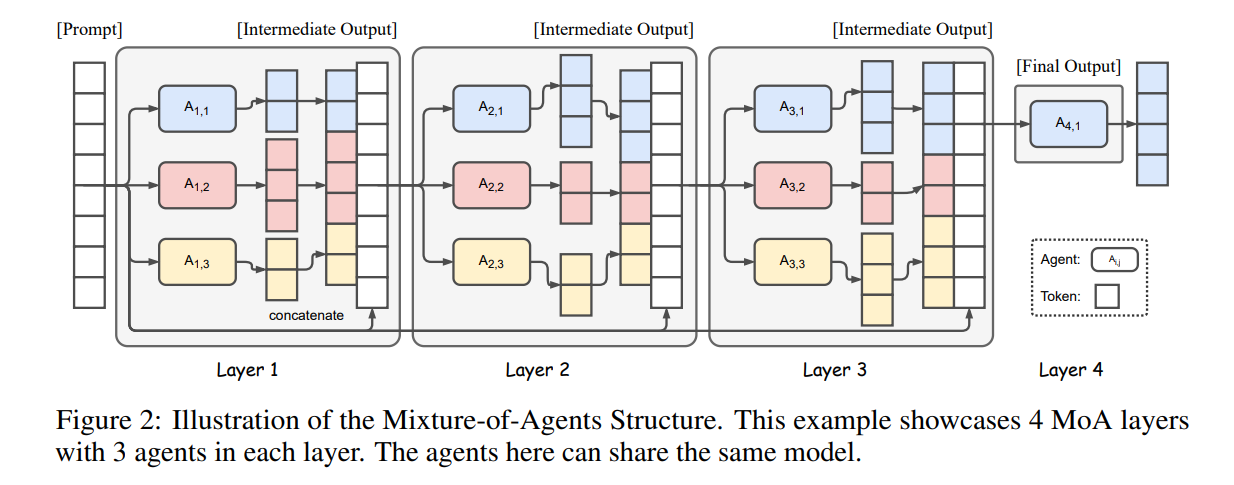
基于这一发现,作者引入了一种名为混合代理的方法,通过利用多个LLMs来迭代地提高生成质量。MoA的结构如图2所示。最初,第一层中的LLMs,表示为 A 1 , 1 , . . . , A 1 , n A_{1,1},...,A_{1,n} A1,1,...,A1,n,独立地对给定提示生成响应。然后,将这些响应呈现给下一层的代理 A 2 , 1 , . . . , A 2 , n A_{2,1},...,A_{2,n} A2,1,...,A2,n(也可能是第一层的模型重用)进行进一步的改进。这个迭代的改进过程持续进行多个周期,直到获得一个更强大、更全面的响应。
为了确保模型之间的有效协作并提高整体响应质量,对于每个MoA层的LLMs的精心选择至关重要。这个选择过程由两个主要标准指导:(a) 性能指标:第i层模型的平均胜率在确定它们是否适合纳入第i + 1层时起着重要作用。因此,根据他们的性能指标选择模型可以确保更高质量的输出。 (b)多样性考虑:模型输出的多样性也非常重要。由异构模型生成的响应比由同一模型生成的响应贡献更大。通过利用这些性能和多样性的标准,MoA旨在通过协同合成来减轻单个模型的缺陷并提高整体响应质量。
本工作的贡献总结如下:
- 新颖的框架:提出了一种Mixture-of-Agents框架,旨在充分利用多个LLMs的优势,从而提高它们的推理和语言生成能力。
- 发现语言模型的合作性:强调了LLMs之间的合作性,即当模型可以访问其他模型的输出时,它们往往会生成更高质量的响应,即使这些输出质量较低。
- 最先进的LLM性能:使用多个竞争激烈的基准测试,如AlpacaEval 2.0,MT-Bench和FLASK进行了大量实验。MoA框架在这些基准测试中实现了最先进的性能。
2. MOA方法
2.1 LLMs的合作性
从多个LLMs的合作中获得最大利益的一个重要途径是刻画不同模型在合作的各个方面的优势。在合作过程中,我们可以将LLMs分为两个不同的角色:
- **提议者(Proposers)**擅长为其他模型生成有用的参考响应。一个好的提议者可能不一定会自己生成高分的响应,但它应该能提供更多的上下文和多样的观点,最终为聚合模型提供更好的最终响应。
- **聚合者(Aggregators)**是在将其他模型的响应综合为单个高质量输出方面熟练的模型。一个有效的聚合者应该能够在整合低于自身质量的输入时,保持或提高输出质量。
聚合者可以通过基于其他模型的输出生成更高质量的响应,作者提出通过引入额外的聚合者进一步增强这种合作潜力。一个直观的想法是使用多个聚合者进行多次聚合------最初使用几个聚合者来聚合更好的答案,然后重新聚合这些聚合的答案。通过将更多的聚合者纳入过程中,可以迭代地合成和优化响应,利用多个模型的优势产生更好的结果。这启发了作者提出的混合代理方法的设计。
MoA的结构如图2所示。它有l个层,每个层i包含n个LLMs,表示为 A i , 1 , . . . , A i , n A_{i,1},...,A_{i,n} Ai,1,...,Ai,n。注意LLMs可以在同一层内或跨不同层之间重复使用。当一个层中的许多LLMs是相同的时,这种配置会导致一个特殊的结构,对应于一个模型生成多个可能不同的输出(由于温度采样的随机性)。将这种设置称为单提议者(single-proposer),只有一个稀疏的模型子集被激活。
在这里,每个LLM A i , j A_{i,j} Ai,j处理输入文本并生成输出(补全)。该方法不需要任何微调,只使用LLMs的提示和生成接口。形式上,给定输入提示 x 1 x_1 x1,第i层MoA的输出 y i y_i yi可以表示如下:
y i = ⊕ j = 1 n A i , j ( x i ) + x 1 , x i + 1 = y i (1) y_i = \oplus_{j=1}^n A_{i,j}(x_i) +x_1,x_{i+1} = y_i \tag 1 yi=⊕j=1nAi,j(xi)+x1,xi+1=yi(1)
这里的 + + +表示文本的拼接; ⊕ \oplus ⊕表示应表1中展示的聚合-合成(Aggregate-and-Synthesize)提示到这些模型的输出上。
实际上,我们不需要将提示和所有模型的响应拼接在一起,只需要在最后一层(图2中的层)中使用一个LLM。使用第l层的一个LLM的输出( A l , 1 ( x l ) A_{l,1}(x_l) Al,1(xl))作为最终的输出,并基于它来评估指标。

根据提供的来自不同开源模型的一系列响应,你的任务是将这些响应合成为一个单一的、高质量的响应。在评估这些响应中提供的信息时,关键是要批判性地判断,认识到其中一些可能存在偏见或错误。你的回复不应仅仅复制给定的答案,而应提供一个经过精炼、准确和全面的回应。确保你的回答结构良好、连贯,并符合最高的准确性和可靠性标准。
来自一些模型的响应:
1. [来自Ai,1的模型响应]
2. [来自Ai,2的模型响应]
...
n. [来自Ai,n的模型响应]2.3 与MoE比较
Mixture-of-Experts(MoE)是机器学习中一种著名且成熟的技术,其中多个专家网络专注于不同的技能集。由于其能够利用多样的模型能力进行复杂问题的解决,MoE方法在各种应用中取得了显著的成功。作者的MoA方法从这种方法中汲取了灵感。
一个典型的MoE设计由一系列称为MoE layer的层组成。每个MoE layer由一组n个专家网络和一个门控网络组成,并包括用于改善梯度流的残差连接。形式上,对于第i层,这个设计可以表示如下:
y i = ∑ j = 1 n G i , j ( x i ) E i , j ( x i ) + x i (2) y_i = \sum_{j=1}^n G_{i,j}(x_i) E_{i,j}(x_i) + x_i \tag 2 yi=j=1∑nGi,j(xi)Ei,j(xi)+xi(2)
其中 G i , j G_{i,j} Gi,j表示对应于专家j的门控网络的输出(分配给专家j的权重),而 E i , j E_{i,j} Ei,j表示由专家网络j计算得到的函数。利用多个专家的优势使得模型能够学习不同的技能集,并专注于任务的各个方面。
从高层次的角度来看,MoA框架将MoE的概念扩展到模型级别,而不是激活级别。具体而言,MoA方法利用LLMs,在完全通过提示接口进行操作,而无需修改内部激活或权重。这意味着,与MoE中单个模型的专门子网络不同,在不同层之间利用多个全功能LLMs。需要注意的是,这里使用LLM来整合门控网络和专家网络的角色,因为LLMs的内在能力允许它们通过解释提示并生成连贯的输出来有效地对输入进行规范化,而无需外部的协调机制。
此外,由于这种方法仅依赖于现成模型内在的提示能力:(1)它消除了与微调相关的计算开销;(2)它提供了灵活性和可扩展性:可以应用于最新的LLMs,无论其大小或架构如何。
3. 评估
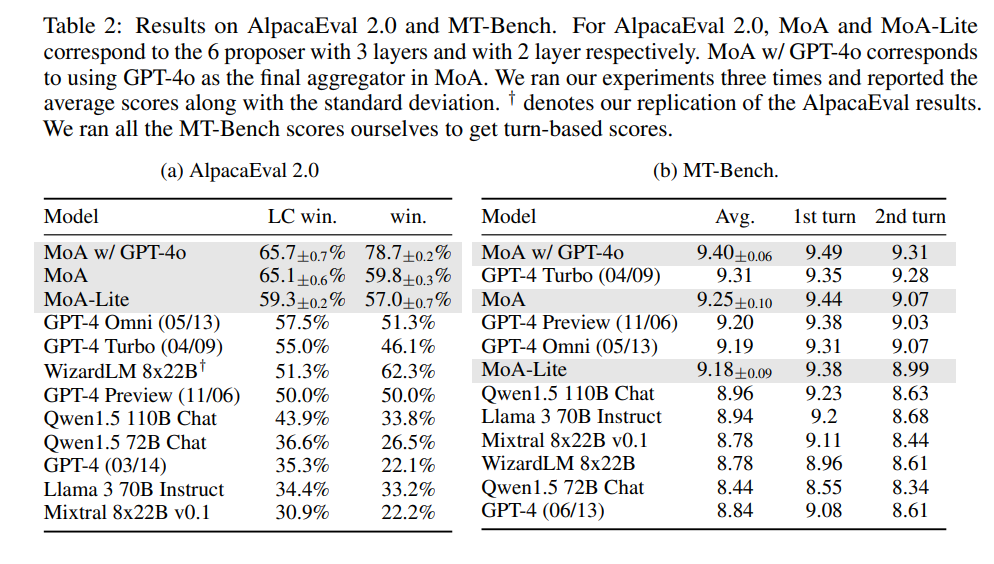
在AlpacaEval 2.0和MT-Bench上的结果。对于AlpacaEval 2.0,MoA和MoA-Lite分别对应具有3层和2层的6个提议者。MoA w/ GPT-4o对应于在MoA中使用GPT-4o作为最终的汇总器。运行了三次实验,并报告了平均分数以及标准偏差。†表示复制了AlpacaEval结果。
与GPT-4和其他最先进的开源模型进行了比较。详细结果见表2a,在AlpacaEval 2.0排行榜上,MoA方法取得了最高乘积。此外,值得特别注意的是,仅使用开源模型就超越了GPT-4o,改进幅度达到了7.6%。MoA-Lite设置使用较少的层次,更加经济高效。即使采用这种轻量级的方法,仍然比最佳模型表现出1.8%的优势,这表明了作者的方法在最大限度地发挥开源模型能力的计算预算不同的情况下的有效性。
虽然在MT-Bench上对个别模型的改进相对较小,但这是可以理解的,因为当前模型在这个基准测试上的表现已经非常出色。尽管改进幅度较小,作者的方法仍然在排行榜上保持着领先地位。
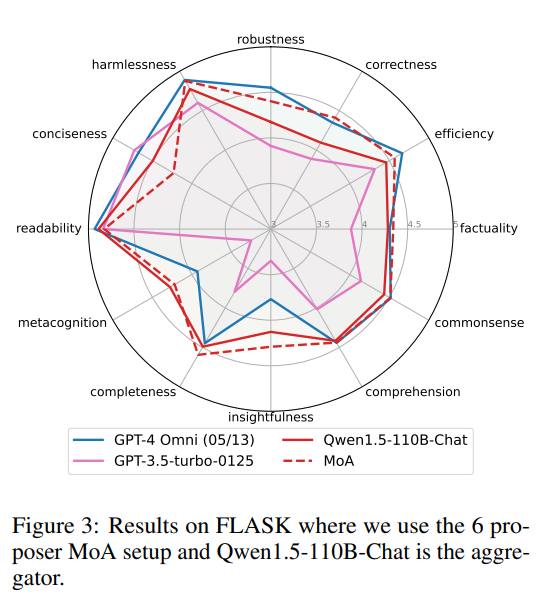
FLASK提供了对模型的细粒度评估。在这些指标中,MoA在几个关键方面表现出色。与聚合器Qwen-110B-Chat的单个模型得分相比,作者的方法在鲁棒性、正确性、效率、真实性、常识、洞察力、完整性等方面显示出显著的改进,也优于GPT-4 Omni。唯一一个MoA表现不佳的指标是简洁性;模型生成的输出稍微冗长一些。
何以使Mixture-of-Agents取得良好效果?
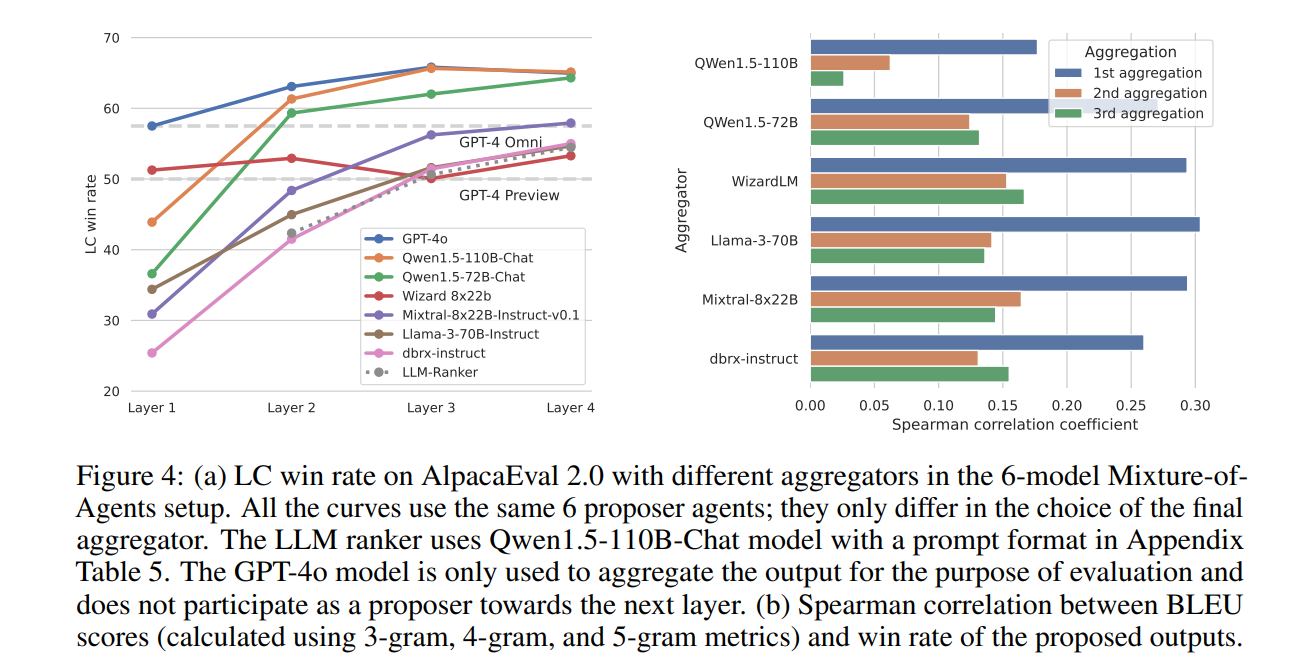
Mixture-of-Agents明显优于其他LLM ranker。结果如图4所示,MoA明显优于LLM ranker基准线。
MoA倾向于纳入最佳的提议答案。图4中的结果确实证实了胜率和BLEU得分之间的正相关关系。
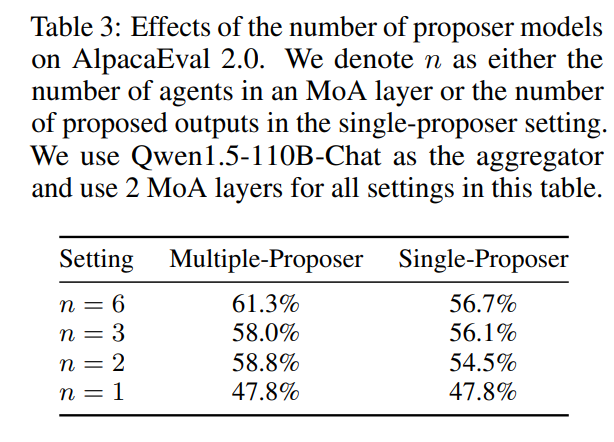
模型多样性和提议者数量的影响。 通过改变每个层中的提议者数量n来分析提议数量如何影响最终输出质量。表3中展示了结果,发现得分随着n的增加而单调增加,反映了拥有更多辅助信息的好处。使用多种不同的LLMs始终产生了更好的结果。这两个结果表明,在每个MoA层中拥有更多多样化的LLM代理可以提高性能。进一步扩展MoA的规模是未来研究的一个有前景的方向。
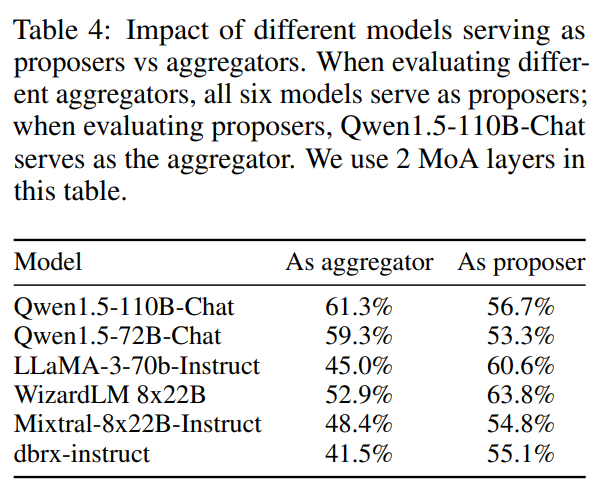
Mixture-of-Agent生态系统中模型的专业化。还进行了实验,确定了哪些模型在特定角色中表现出色。具体而言,表4显示了GPT-4o、Qwen和LLaMA-3作为多功能模型,在辅助和聚合任务中都很有效。相比之下,WizardLM作为提议者模型表现出色,但在聚合其他模型的响应时遇到了困难,难以保持其有效性。
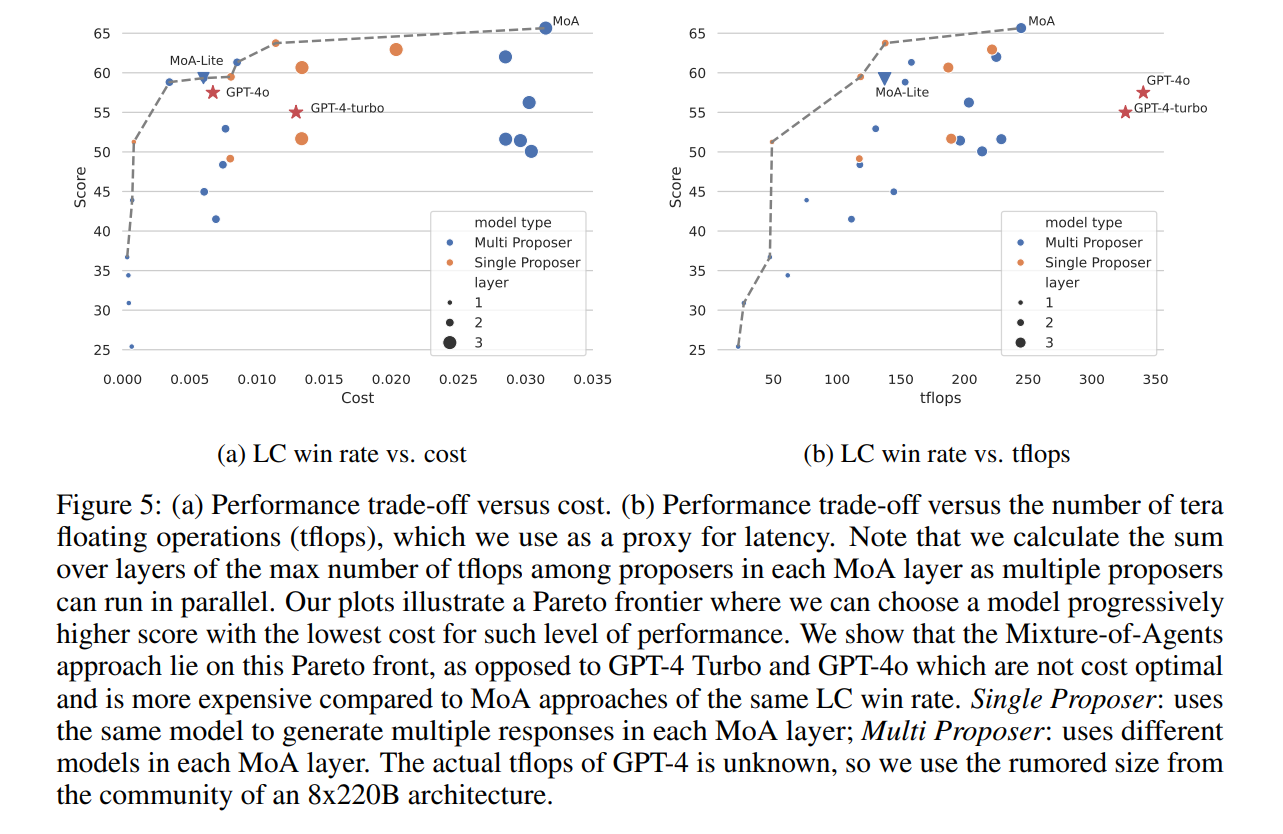
为了理解预算、令牌使用和LC胜率之间的关系,还进行了预算和令牌分析。图5a和图5b说明了这些关系。成本效益在图5a中,图表显示了一个帕累托前沿(Pareto front ),其中某些模型在成本和性能之间达到了最佳平衡。靠近这个帕累托前沿的模型更加理想,因为它们以更低的成本提供更高的LC胜率,提供更好的货币价值。如果我们优先考虑质量,那么MoA是最佳配置。然而,如果我们想在质量和成本之间取得良好的平衡,MoA-Lite可以在与GPT-4o相等的成本的同时实现更高水平的质量。值得注意的是,它在成本效益方面的表现超过了GPT-4 Turbo约4倍。
Tflops消耗 图5b描述了LC胜率与tflops数量之间的关系。与成本效率分析类似,在这里也可以观察到一个帕累托前沿。在这个前沿上的模型有效地利用其计算资源,以最大化其LC胜率。
4. 相关工作
略
5. 结论
本文介绍了一种Mixture-of-Agents方法,旨在通过连续迭代协作,充分利用多个LLM的能力。利用了Mixture-of-Agents家族中各个代理(Agent)的集体优势,可以显著提高每个单独模型的输出质量。
局限性。需要迭代地聚合模型的响应,这意味着模型无法在达到最后一个MoA层之前产生第一个令牌。这可能导致很高的首个令牌响应时间(Time to First Token,TTFT),就是响应时间慢,这可能对用户体验产生负面影响。为了缓解这个问题,我们可以限制MoA层数,因为第一个响应聚合对生成质量有最显著的提升。
广泛影响。这项研究有潜力提高以LLM为驱动的聊天助手的效果,从而使人工智能更易于使用。此外,由于以自然语言表达的中间输出,MoA的提出改善了模型的可解释性。这种增强的可解释性有助于更好地与人类推理进行对齐。
A 使用不同相似函数的Spearman相关性
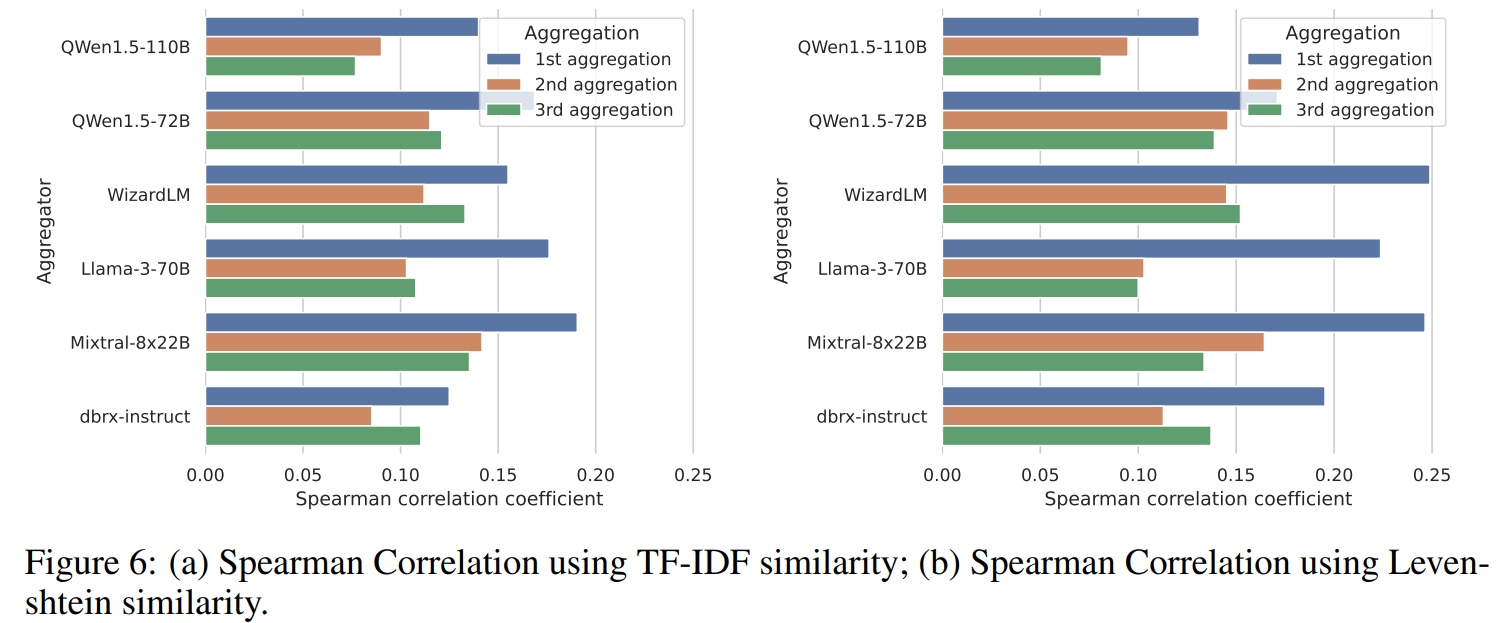
在计算Spearman相关系数时,使用了基于TF-IDF相似度和Levenshtein相似度的结果。具体而言,在每个包含n个候选答案的样本中,计算了n个相似度得分和由基于GPT-4的评估器确定的n个偏好得分之间的Spearman相关系数。如图6所示,确实存在LC胜率与TF-IDF相似度和Levenshtein相似度之间的正相关关系。
You are a highly efficient assistant, who evaluates and selects the best large language model (LLMs) based on
the quality of their responses to a given instruction. This process will be used to create a leaderboard reflecting
the most accurate and human-preferred answers.
I require a leaderboard for various large language models. I'll provide you with prompts given to these models
and their corresponding outputs. Your task is to assess these responses, and select the model that produces the
best output from a human perspective.
## Instruction
{
"instruction": """{instruction}""",
}
## Model Outputs
Here are the unordered outputs from the models. Each output is associated with a specific model, identified by a
unique model identifier.
{
{
"model_identifier": "{identifier_1}",
"output": """{output_1}"""
},
{
"model_identifier": "{identifier_2}",
"output": """{output_2}"""
},
{
"model_identifier": "{identifier_3}",
"output": """{output_3}"""
},
{
"model_identifier": "{identifier_4}",
"output": """{output_4}"""
},
{
"model_identifier": "{identifier_5}",
"output": """{output_5}"""
},
{
"model_identifier": "{identifier_6}",
"output": """{output_6}"""
}
}
## Task
Evaluate the models based on the quality and relevance of their outputs, and select the model that generated the
best output. Answer by providing the model identifier of the best model. We will use your output as the name of
the best model, so make sure your output only contains one of the following model identifiers and nothing else
(no quotes, no spaces, no new lines, ...).
## Best Model Identifier表5: 使用LLM排序的提示词
B LLM Ranker
本节介绍了本文中使用的LLM-Ranker的设置。LLM-Ranker旨在评估和排序由一些LLMs生成的最佳输出。表5展示了在这些评估过程中提示模型的模板。使用这个LLM-Ranker来选择最好的答案,并使用AlpacaEval评估器来评估排名最高的答案。
C 案例研究
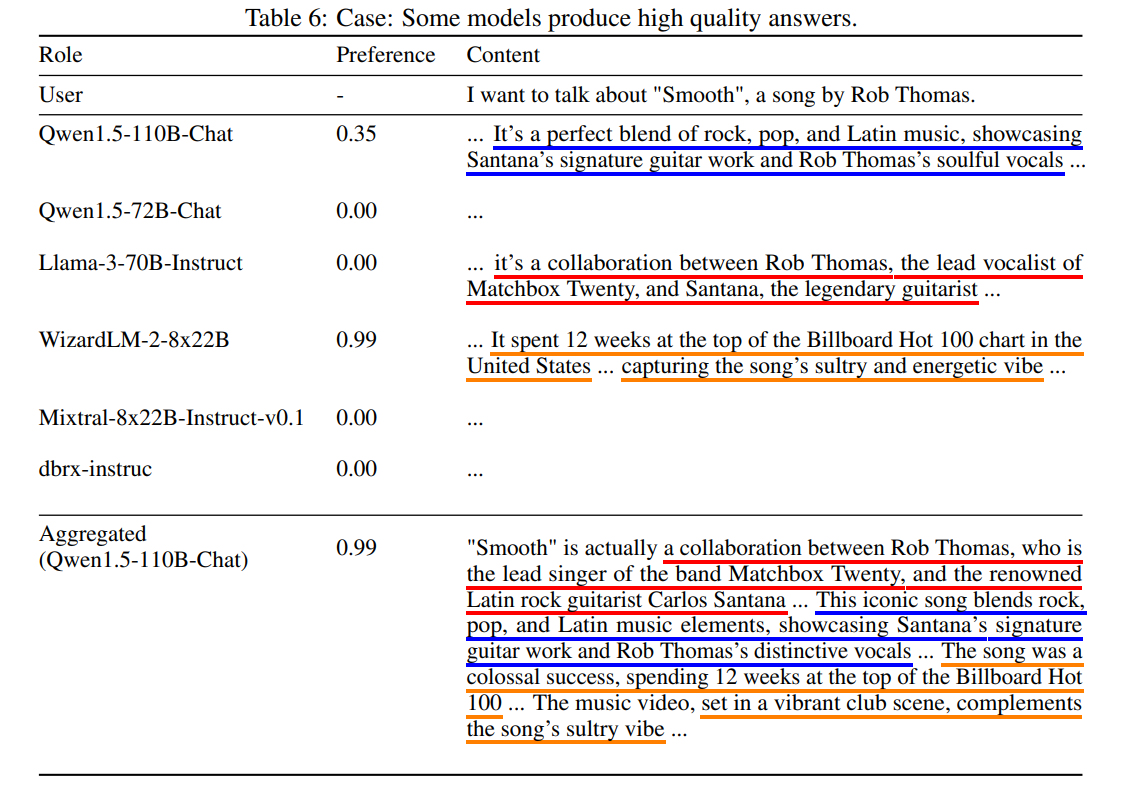
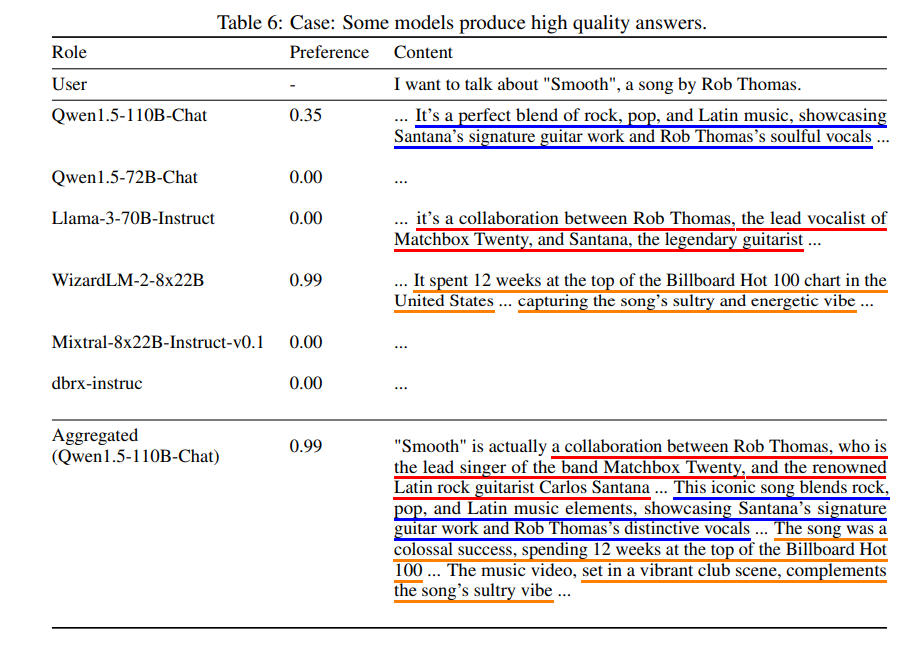
为了说明聚合器如何综合回答,在提议的回答和聚合回答中,用不同颜色的下划线标出相似的表达方式。省略了所有提议回答都提到的内容。表6展示了不同提议者生成的回答。由Qwen1.5-110B-Chat生成的聚合回答体现了对自己内容的高偏好,同时也融入了Llama-3-70B-Instruct和WizardLM 8x22B的关键观点。值得注意的是,GPT-4对WizardLM 8x22B的回答的偏好得分为0.99,最终的聚合回答也达到了0.99的偏好得分。与此同时,表7展示了另一个案例,其中没有任何提议的回答获得了较高的GPT-4偏好得分。尽管如此,聚合器成功地识别并融入了这些回答的优点,实现了0.33的偏好得分。

D 数学任务
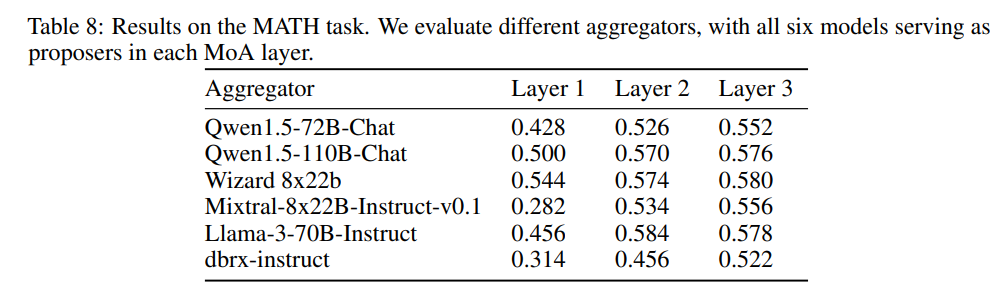
这里证明了该方法适用于推理任务,例如MATH数据集中的任务。结果显示在表8中,该方法始终显著提高了准确性。这表明对于这类任务也是有效的。值得注意的是,该方法与现有的推理技术如Chain of Thought和Self-consistency相辅相成。
总结
⭐ 作者提出了一种混合多个智能体的方法,通过多层的设计,最终层给出输出。取得了较好的效果,但成本和响应时间也增加很多。在仅需要高质量回复的场景下可以使用。