一、上周工作
机器学习,同时思考实验如何修改
二、本周计划
整理代码、设计损失函数并实验、安装LaTeX、
三、完成情况
3.1 整理代码
之前在工作站上跑的 在aba基础上改的
本周重新整理并编写了代码
3.2 机器学习
3.2.1 梯度下降的实现
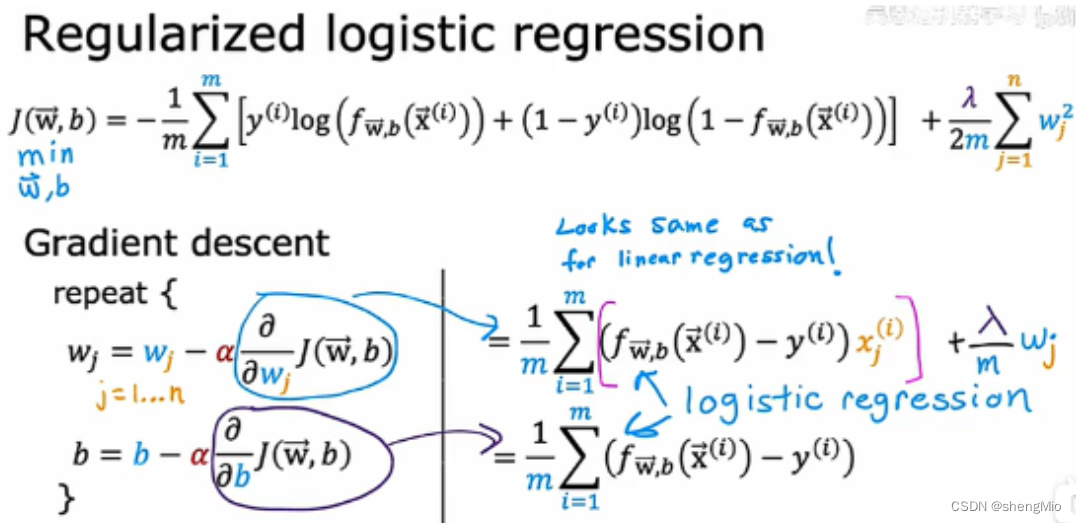
需要找到合适的w,b对logistics回归模型参数的拟合,仍使用梯度下降来实现
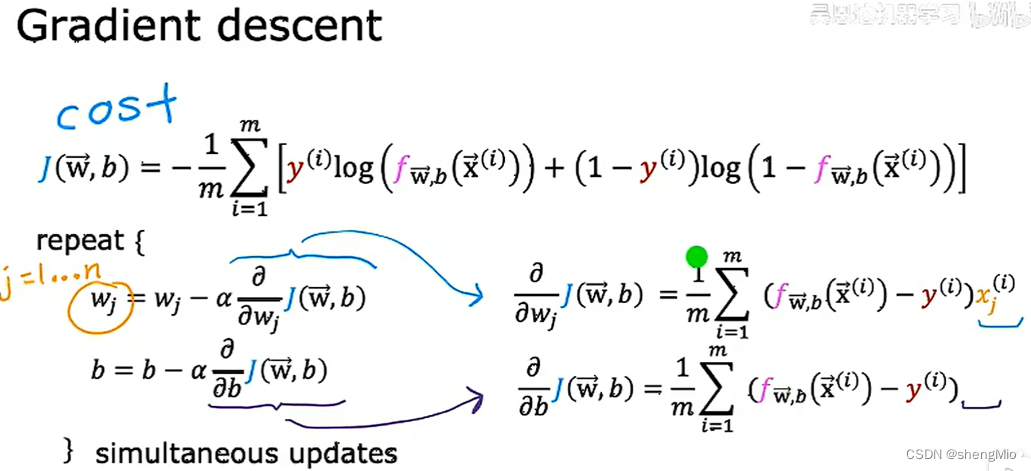
和线性回归一样,可以对logistics的梯度下降进行学习率的检测、向量化的实现以及进行特征缩放等等。
3.2.2 过拟合
过拟合 (overfitting)简单来说是训练集上表现的很好,测试集上较差。
解决过拟合的方法:
- 第一个方法是去收集更多的数据
- 第二个方法是选择合适的特征,而不是选择过多的特征。特别是当数据量不够时,该方法可能会丢失一些有用信息
- 最后一种方法是正则化,可以减小一些参数的大小,这些参数对应的特征一般对整体影响较大。例如下面的右图,x的幂越高,就让其对应的参数变小。
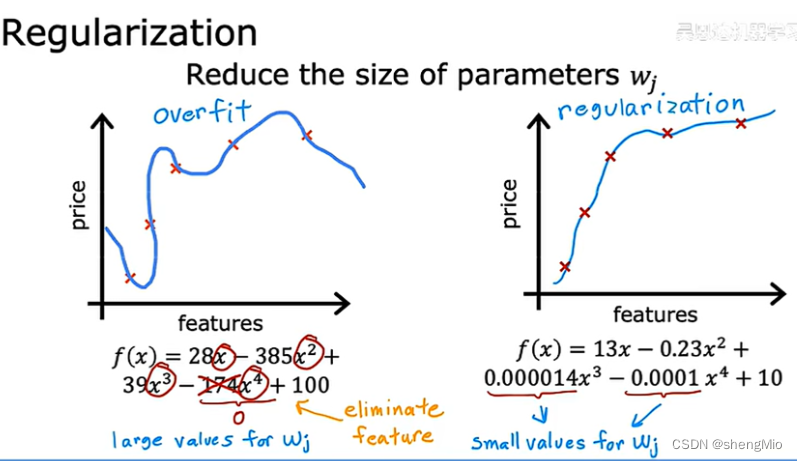
3.2.3 正则化
正则化:让参数有更小的值,使其不容易发生过拟合。
但大多数我们不知道应该减小哪些特征对应的参数,这时候就可以对所有的参数进行处理。
一般只需要正则化参数进行处理,而无需对b。
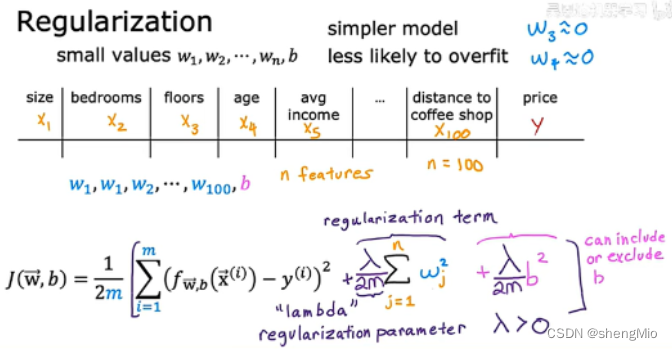
对于正则化参数的选择,一个极端是设置其值为0,但失去了意义,另一个极端是选择其极大值,此时,由于需要保证成本函数取最低值,就需要保证
的所有值都非常接近0。
如下图,如果取0,就会过拟合,但若
取很大,会使最后的曲线接近f(x)=b。
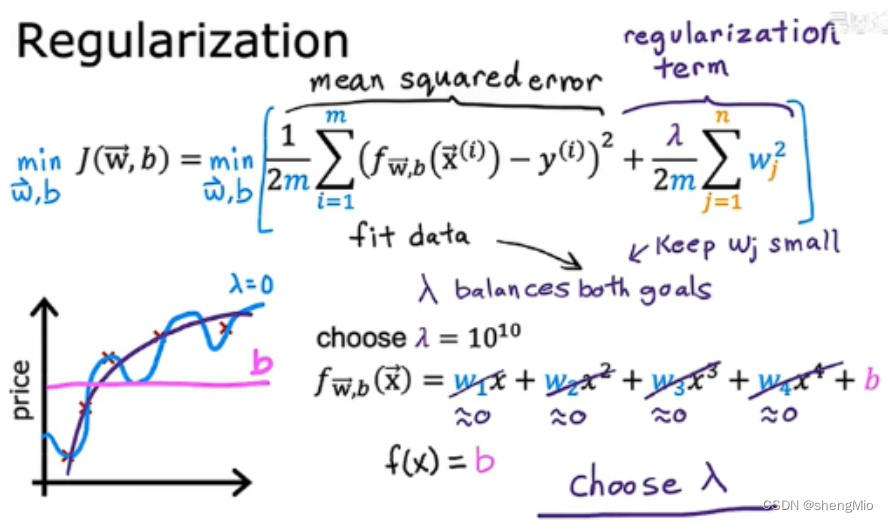
正则化线性回归:

正则化logistics回归:
3.3 安装LaTex
texlive、texstudio的下载与安装
3.4 设计损失函数
等工作站空了跑实验 验证所设计的联合损失函数
调整权重
两个损失函数的结合
四、存在的主要问题
1.整理代码时遇到IndexError: index 10 is out of bounds for axis 0 with size 10
------通常是由于尝试访问一个空数组或矩阵的超出范围索引导致的。debug:检查数组的形状和大小,确保非空。数据加载处的代码有误,已修改。
2.整理代码时总是在dataset文件下面再次生成train_result、test_result两个文件夹
------因为根目录的原因。在PathConfig出修改成绝对路径。
五、下一步计划
跑实验
准备开始论文编写,再次学习师兄师姐的论文框架