目录
- [1327. 列出指定时间段内所有的下单产品](#1327. 列出指定时间段内所有的下单产品)
- [383. 赎金信](#383. 赎金信)
- [236. 二叉树的最近公共祖先](#236. 二叉树的最近公共祖先)
1327. 列出指定时间段内所有的下单产品
题目链接
表
- 表
Products的字段为product_id、product_name和product_category。 - 表
Orders的字段为product_id、order_date和unit。
要求
写一个解决方案,要求获取在 2020 年 2 月份下单的数量不少于 100 的产品的名字和数目。
返回结果表单的 顺序无要求 。
知识点
sum():求和的函数。group by:根据某些字段分组。having:对分组后的数据进行限制。
思路
要获取在 2020 年 2 月份下单的数量不少于 100 的产品的id,首先得统计出各产品在 2020 年 2 月份下单的数量num,将时间限制到2020-02-01和2020-02-29之间,根据产品id进行分组,对unit进行求和,获取要求中的下单数量num。然后将下单数量num与100进行比较,如果num比100大,则将其id和下单数量num返回。
查到满足要求的产品id后,与Products表进行多表查询,获取这些产品对应的名字。
代码
sql
select
product_name,
num unit
from
Products p,
(
select
product_id,
sum(unit) num
from
Orders
where
order_date between '2020-02-01' and '2020-02-29'
group by
product_id
having
num >= 100
) o
where
p.product_id = o.product_id383. 赎金信
题目链接
标签
哈希表 字符串 计数
思路
判断 ransomNote 能不能由 magazine 里面的字符构成,并且 magazine 中的每个字符只能在 ransomNote 中使用一次。
在 magazine 中找构成 ransomNote 的字符,所以 magazine 就是源字符串 src,ransomNote 就是目标字符串tar。以下使用 src 来代替 magazine、tar代替 ransomNote。
这种判断不需要关心字符的顺序,只需要关心 tar 里面的字符是否都能在 src 中找到,并且由于src 中的每个字符只能在 tar 中使用一次,所以 src 中每个字符的数量还不能少于 tar。
使用两个int[]数组分别统计 tar 和 src 中的字符出现次数 的想法油然而生,由于题目中说明这两个字符串仅由小写字符构成 ,所以使用长度为26的int[]数组即可,并将小写字符通过ch - 'a'的计算映射出它在统计数组中的索引。
统计完两个字符串的字符出现次数后,进行比较,如果发现tar中某个字符的出现次数比src中该字符的出现次数多,则说明tar不能由src中的字符构成,返回false。如果比较完26个字符,则说明tar能由src中的字符构成,返回true。
代码
java
class Solution {
public boolean canConstruct(String ransomNote, String magazine) {
int[] tarCnt = new int[26]; // 用于统计目标字符串中各个字符的出现次数
int[] srcCnt = new int[26]; // 用于统计源字符串中各个字符的出现次数
// 统计目标字符串中各个字符的出现次数
for (char ch : ransomNote.toCharArray()) {
tarCnt[ch - 'a']++;
}
// 统计源字符串中各个字符的出现次数
for (char ch : magazine.toCharArray()) {
srcCnt[ch - 'a']++;
}
// 对比 目标字符串 和 源字符串 的各个字符的出现情况
for (int i = 0; i < 26; i++) { // 对于某一个字符
if (srcCnt[i] < tarCnt[i]) { // 如果它 在源字符串中的出现次数 < 在目标字符串中的出现次数
return false; // 则目标字符串不能由源字符串中的字符构成,返回false
}
}
// 对比完26个字符后,发现 目标字符串 的字符够构成 源字符串,返回true
return true;
}
}236. 二叉树的最近公共祖先
题目链接
标签
树 深度优先搜索 二叉树
思路
由于题目中提到"一个节点也可以是它自己的祖先 ",所以二叉树的公共祖先有两种情况,例如对于以下这个二叉树:
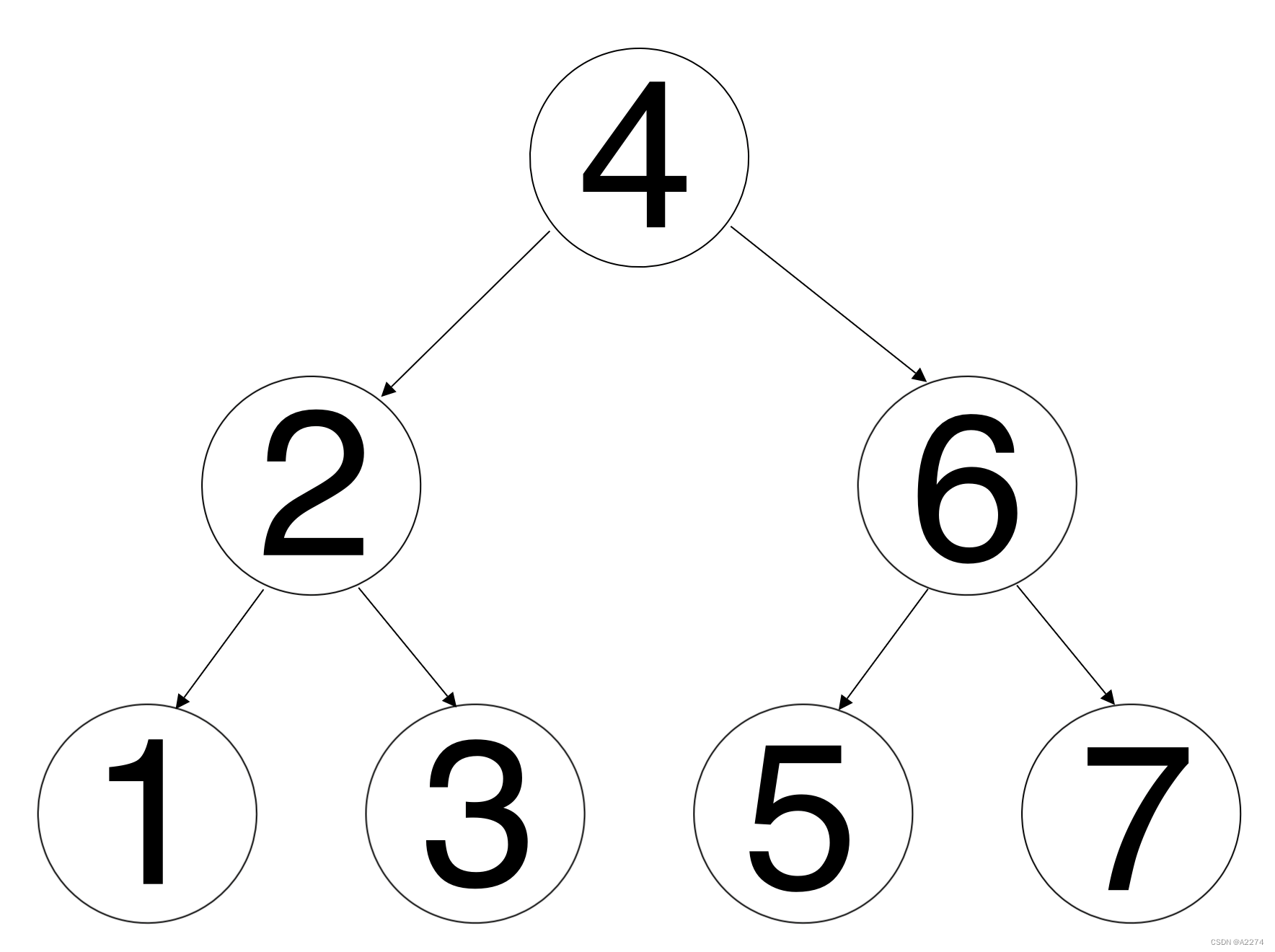
节点1和节点3的公共祖先为节点2
节点1和节点2的公共祖先为节点2
从而得出判断公共祖先的两类条件:当指定的两个节点p, q分别位于节点curr的两侧 (即p, q分别位于curr的左、右子树中)时,那么此时这个curr就是p, q的公共祖先;当指定的两个节点p, q中有一个 节点位于节点curr的子树中,并且另一个节点就是curr时 ,此时的curr也是p, q的公共祖先。
注意:这两种情况提到的公共祖先不一定是最近的公共祖先,要想获得最近的公共祖先,需要遍历整颗二叉树 。虽然不一定是最近的公共祖先,但是每次找到公共祖先时都会向最近的公共祖先逼近。
代码
java
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
dfs(root, p, q);
return res;
}
private TreeNode res; // 公共祖先节点
// 判断 在curr及其子树中 能否找到 p 或 q,顺便更新公共祖先节点
private boolean dfs(TreeNode curr, TreeNode p, TreeNode q) {
if (curr == null) { // 如果curr为null
return false; // 则找不到p或q,返回false
}
boolean left = dfs(curr.left, p, q); // 在左子树中寻找p或q
boolean right = dfs(curr.right, p, q); // 在右子树中寻找p或q
if (left && right) { // 如果p, q位于curr的两侧
res = curr; // 说明当前节点curr为p和q的公共祖先
} else if ((left || right) // 如果在左子树或右子树中能找到p或q
&& (curr.val == p.val || curr.val == q.val)) { // 并且当前节点的值为p或q中的一个
res = curr; // 说明当前节点curr为p和q的公共祖先
}
return left // 如果在左子树中能够找到p或q,则返回true
|| right // 如果在右子树中能够找到p或q,则返回true
|| (curr.val == p.val || curr.val == q.val); // 如果本节点就是要找的p或q,则返回true
}
}