目录
序列化(Serialization)
序列化是将Java对象转换成字节流的过程,使得对象可以被存储到磁盘上或通过网络进行传输。在Hadoop中,这个过程特别关键,因为数据经常需要在网络间传递(例如,从Map任务到Reduce任务),或者存储到HDFS上。Hadoop自定义了一套序列化机制------Writable接口,任何需要进行序列化的类都必须实现这个接口。实现Writable接口的类需要重写两个方法:write(DataOutput out)和readFields(DataInput in)。前者负责将对象的状态(即成员变量的值)写入到DataOutput流中;后者则从DataInput流中读取字节并恢复对象状态。
反序列化(Deserialization)
反序列化则是序列化的逆过程,即将字节流转换回Java对象。在Hadoop中,当数据从网络接收或从HDFS读取后,需要通过反序列化恢复成原始的Java对象,以便程序能够进一步处理这些数据。利用前面提到的readFields(DataInput in)方法,Hadoop可以从输入流中重建对象实例。
Hadoop选择了自定义Writable接口,主要出于以下考虑:
- 性能:Hadoop的Writable接口设计得更加轻量级和高效,特别适合大规模数据处理,减少序列化和反序列化过程中的开销。
- 紧凑性:Writable接口能够生成更紧凑的二进制格式,节省存储空间和网络带宽。
- 可移植性:Hadoop集群可能包含不同版本的Java或运行在不同的操作系统上,自定义序列化机制保证了跨平台的一致性。
事例操作
使用自定义对象,实现对用户购买商品总额的计算
入口文件示例
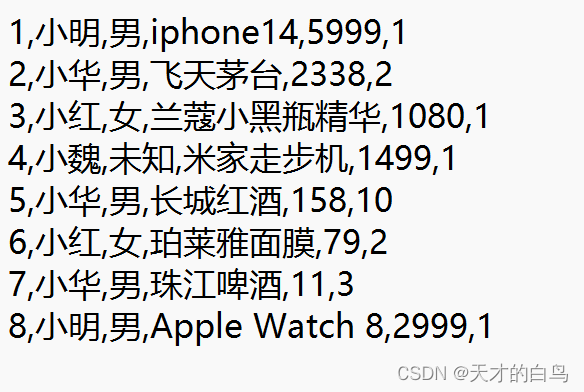
UserSale
实现Hadoop的**Writable**接口
java
public class UserSale implements Writable {
java
//销售id
private int saleId;
//用户名称
private String username;
//用户性别
private String sex;
//商品名称
private String goodsName;
//商品单价
private int price;
//购买数量
private int saleCount;
//购买总价
private int totalPrice;记得得有空参构造
java
public UserSale() {
}重写序列化方法
java
//重写序列化方法
@Override
public void write(DataOutput out) throws IOException {
out.writeInt(saleId);
out.writeUTF(username);
out.writeUTF(sex);
out.writeUTF(goodsName);
out.writeInt(price);
out.writeInt(saleCount);
out.writeInt(totalPrice);
}重写反序列化
顺序和序列化的顺序一样
java
@Override
public void readFields(DataInput in) throws IOException {
this.saleId = in.readInt();
this.username = in.readUTF();
this.sex = in.readUTF();
this.goodsName = in.readUTF();
this.price = in.readInt();
this.saleCount = in.readInt();
this.totalPrice = in.readInt();
}重写toString方法
reduce阶段的输出的格式
java
//重写toString方法
//最终输出到文件的value
@Override
public String toString() {
return " " + totalPrice;
}get,set方法,以及定义totalPrice的构造方法
java
public void setTotalPrice(int totalPrice) {
this.totalPrice = totalPrice;
}
public void setTotalPrice(){
this.totalPrice = this.price*this.saleCount;
}SaleMapper
java
package com.igeekhome.mapreduce.sale;
import com.igeekhome.mapreduce.model.UserSale;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class SaleMapper extends Mapper<LongWritable, Text, Text, UserSale>{
//创建输出key对象
private Text keyOut = new Text();
//创建输出value
UserSale valueOut = new UserSale();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, UserSale>.Context context) throws IOException, InterruptedException {
//获取一行数据
String line = value.toString();
//根据分隔符拆解数据
String[] saleDetails = line.split(",");
//封装对象
valueOut.setSaleId(Integer.parseInt(saleDetails[0]));
valueOut.setUsername(saleDetails[1]);
valueOut.setSex(saleDetails[2]);
valueOut.setGoodsName(saleDetails[3]);
valueOut.setPrice(Integer.parseInt(saleDetails[4]));
valueOut.setSaleCount(Integer.parseInt(saleDetails[5]));
//赋值
keyOut.set(valueOut.getUsername());
//计算总价
valueOut.setTotalPrice();
System.out.println(keyOut+"+"+valueOut);
//map阶段的输出
context.write(keyOut,valueOut);
}
}其中
Mapper<LongWritable, Text, Text, UserSale>
分别表示
LongWritable:map阶段输入的key类型,一行文本的偏移量
Text:map阶段输入的value类型,表示一行文本中的内容
Text: map阶段输出的key类型 ,表示一个单词
UserSale :map阶段输出的value类型,这里是UserSale对象
SaleReducer
新建reduce阶段输出的alue
reduce()方法的调用次数 是由kv键值对中有多少不同的key决定的
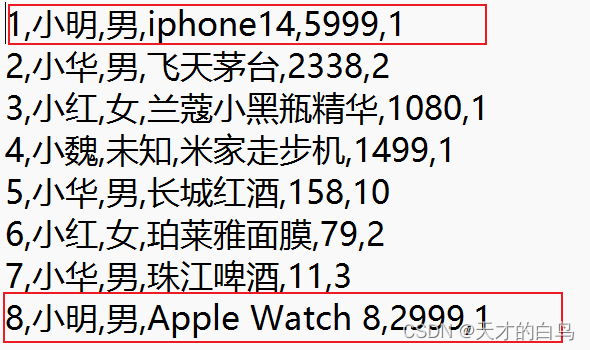
比如此时小明的两条数据进入Reducer,for循环执行的是这两条数据里的总价相加
java
package com.igeekhome.mapreduce.sale;
import com.igeekhome.mapreduce.model.UserSale;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class SaleReducer extends Reducer<Text, UserSale,Text, UserSale> {
//新建reduce阶段输出的alue
//reduce()方法的调用次数 是由kv键值对中有多少不同的key决定的
private UserSale valueOut = new UserSale();
@Override
protected void reduce(Text key, Iterable<UserSale> values, Reducer<Text, UserSale, Text, UserSale>.Context context) throws IOException, InterruptedException {
//定义一个用户的订单
int sumTotalPrice = 0;
for (UserSale userSale : values) {
//获取一个订单中的总价
int totalPrice = userSale.getTotalPrice();
valueOut.setSex(userSale.getSex());
//进行累加
sumTotalPrice +=totalPrice;
}
//设置在结果文件终端输出
valueOut.setTotalPrice(sumTotalPrice);
System.out.println("reduce" +valueOut);
//reduce阶段的输出
context.write(key,valueOut);
}
}Reducer<Text, UserSale,Text, UserSale>Text:reduce阶段的输入key类型, 即map阶段输出key类型,表示用户名
UserSale:reduce阶段的输入value类型,即map阶段输出value类型,表示用户对象
Text:reduce阶段的输出key类型,表示用户名
UserSale:reduce阶段的输出value类型,表示用户对象,实际上输出的是totalPrice(因为toString方法的重写)
SaleDriver
java
package com.igeekhome.mapreduce.sale;
import com.igeekhome.mapreduce.model.UserSale;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class SaleDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1.获取配置对象和job对象
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2.设置Driver类对象
job.setJarByClass(SaleDriver.class);
//3.设置mapper和reducer类对象
job.setMapperClass(SaleMapper.class);
job.setReducerClass(SaleReducer.class);
//4.设置map阶段输出的kv对象
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(UserSale.class);
//5.设置最终输出的kv类对象
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(UserSale.class);
//6.设置读取文件的路径 和 输出文件的路径
FileInputFormat.setInputPaths(job,new Path("D:\\code\\sale_details (1).txt"));
FileOutputFormat.setOutputPath(job,new Path("D:\\code\\output"));
//7.提交job
boolean result = job.waitForCompletion(true);
System.out.println(result?"计算成功":"计算失败");
}
}