本文重点介绍使用无 OCR 大型多模态模型解析 PDF 的方法。它主要讨论了三种典型的无 OCR 大型多模态模型用于文档理解:
- TextMonkey:一种用于理解文档的无 OCR 大型多模式模型
- Vary:扩大大型视觉语言模型的视觉词汇量
- StrucTexTv3:一种高效的富文本图像视觉语言模型
本文还将提供从这些模型中得出的见解和想法。
文本猴子
TextMonkey是一个大型多模式模型,专为以文本为中心的任务(例如文档问答和场景文本分析)而设计。
概述
TextMonkey 能够在有限的训练资源下实现分辨率增强,同时保留跨窗口信息,减少分辨率增强引入的冗余 token。此外,通过各种数据和借口提示,TextMonkey 已经具备了处理多任务的能力。
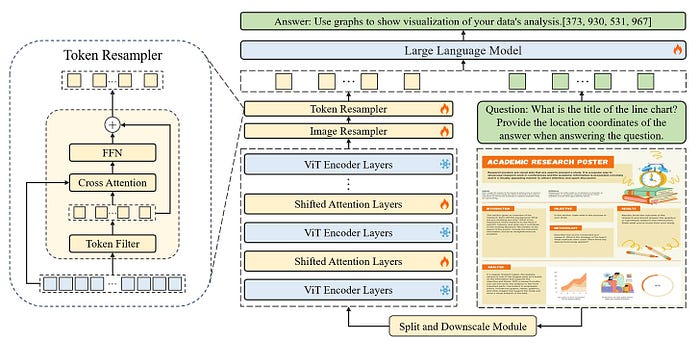
图 1:TextMonkey 概览。来源:TextMonkey。
如图 1 所示,TextMonkey 架构特点如下:
- 首先,输入图像通过分割模块分割成互不重叠的块,每个块的尺寸为 448x448 像素。这些块进一步划分为更小的 14x14 像素块,其中每个块被视为一个标记。
- 增强跨窗口关系。TextMonkey 采用移位窗口注意力机制,在扩展输入分辨率的同时成功整合了跨窗口连接。此外,TextMonkey 在移位窗口注意力机制中引入了零初始化,使模型能够避免对早期训练进行大幅度修改。
- Token Resampler 用于压缩 token 的长度,从而减少语言空间中的冗余。然后,这些处理过的特征与输入问题一起由 LLM 进行分析,以生成所需的答案。
表现
由于TextMonkey 尚未发布其推理方法,我们将通过其论文中描述的实验来检查其能力。
我们主要关注的是它的PDF 解析能力。也就是说,将 PDF 和图像转换为结构化或半结构化格式的能力。
如图 2 左侧所示,TextMonkey 可以准确定位和识别场景和文档图像中的文本。
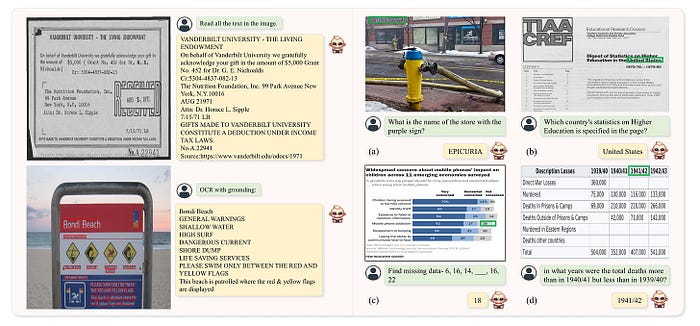
图 2:TextMonkey 的可视化结果。模型生成的边界框以红色显示。基本事实的位置以绿色框突出显示。来源:TextMonkey。
此外,表格和图表的解析能力也至关重要,TextMonkey也进行了相关测试,如图3所示。
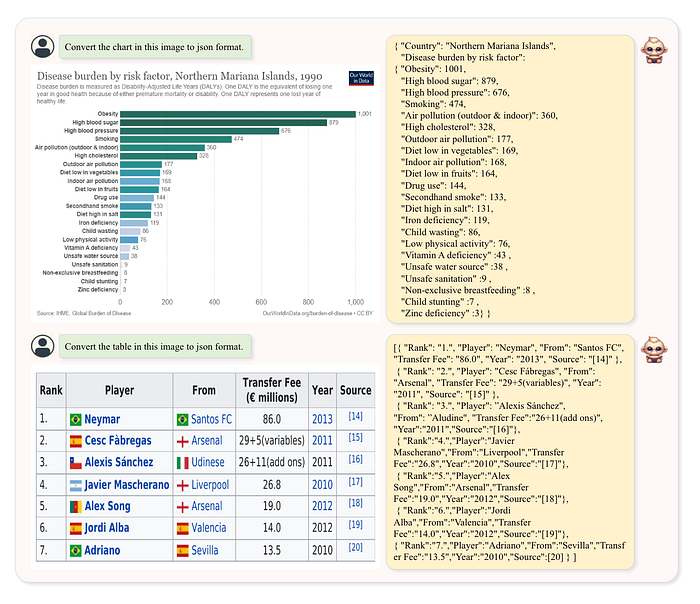
图 3:图表和表格结构化示例。来源:TextMonkey。
如图 3 所示,TextMonkey 可以将图表和表格转换为 JSON 格式,展示了其在下游应用程序中使用的潜力。
Vary
现代大型视觉语言模型拥有庞大的通用视觉词汇表 --- CLIP,其中包含超过 4 亿个图像文本对。它涵盖了最常见的图像和视觉任务。
然而,在某些场景中,例如高分辨率感知、非英语 OCR 和文档/图表理解,CLIP-VIT 可能会因标记效率低下而遇到困难。这是因为它很难将所有视觉信息编码为固定数量的标记,通常为 256 个。
虽然mPlug-Owl和Qwen-VL尝试通过解冻其视觉词汇网络(CLIP-L 或 CLIP-G)来解决此问题,但Vary认为这不是一种合理的方法。原因如下:
- 它可能会覆盖原有的词汇知识。
- 在相对较大的 LLM(7B)上更新视觉词汇的训练效率较低。
- LLM 强大的记忆容量可防止视觉词汇网络多次查看图像,即在多个时期内训练数据集。
这就给我们带来了一个问题:我们能否找到一种简化并有效增强视觉词汇的策略?
概述
提出了一种高效、用户友好的方法Vary来解决上述问题。
该方法的灵感来自于扩展 vanilla LLM 的文本词汇量。当将英语 LLM 转换为另一种语言(例如中文)时,需要扩充文本词汇量以增强新语言下的编码效率和模型性能。直观地讲,对于视觉分支,当将"外语"图像输入模型时,视觉词汇量也需要扩展。
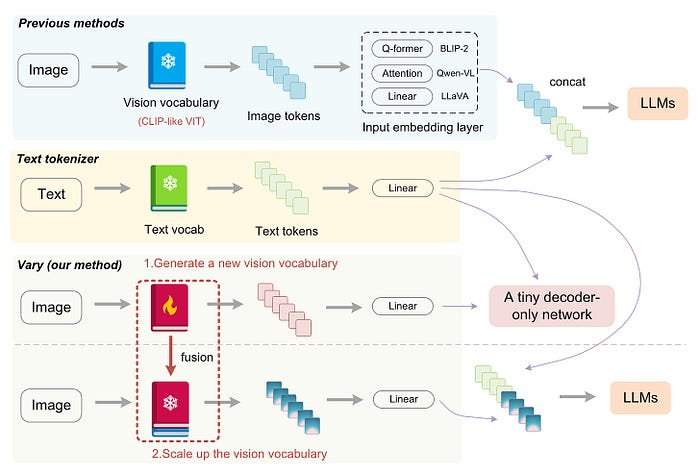
图 4:之前的方法与 Vary 的比较。与其他使用现成视觉词汇的模型不同,Vary 的过程可以分为两个阶段:视觉词汇的生成和融合。在第一阶段,Vary 使用"词汇网络"以及一个小型的解码器专用网络通过自回归生成强大的新视觉词汇。在第二阶段,Vary 将视觉词汇与原始词汇相结合,有效地为 LVLM 提供新特征。来源:Vary。
如图4所示,Vary中的词汇扩展过程包括两个步骤:
- 创建新的视觉词汇表来补充现有词汇表 (CLIP)。此管道包括一个词汇表网络和一个小型解码器专用转换器,它通过预测下一个标记来训练词汇表模型。
- 合并新旧词汇。在此过程中,新旧词汇网络均被冻结,以防止视觉知识被覆盖。
架构
如图5所示,Vary有两种形式:Vary-tiny和Vary-base。
- Vary-tiny 主要致力于生成新的视觉词汇。
- 另一方面,Vary-base 是一种新颖的大型多模式模型,旨在使用这种新的视觉词汇来处理各种视觉任务。
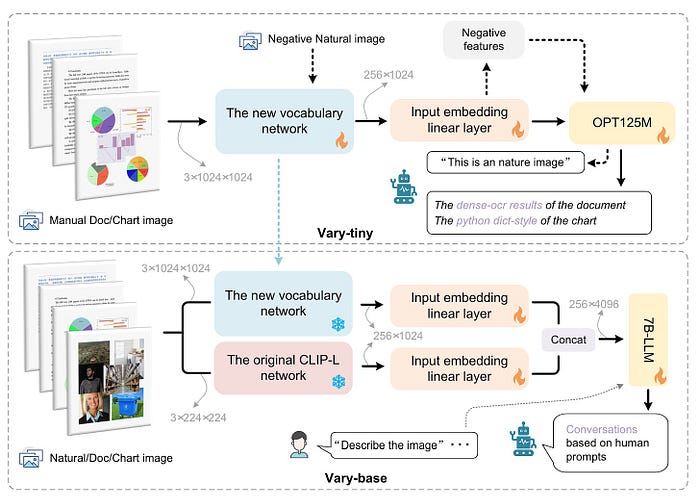
图 5:Vary 概览。来源:Vary。
关于数据
Vary的训练数据有很多种,如图6所示。
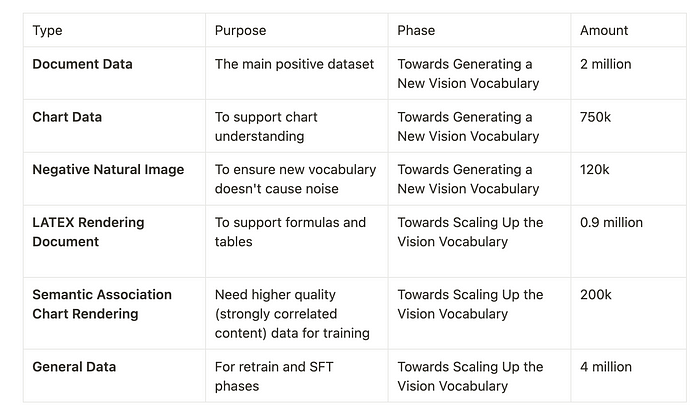
图 6:Vary 的训练数据。图片由作者提供。获取具体资资料: 2img.ai
下面将详细说明每类数据的具体构造过程。
文档数据
使用文档中的高分辨率图像-文本对作为预训练新视觉词汇的主要数据集。
该流程首先从 arXiv 和 CC-MAIN-2021--31-PDFUNTRUNCATED 中可公开访问的文章中收集 PDF 格式的文档,这些文档构成英文部分。中文部分包括从互联网上收集的电子书。
使用 PyMuPDF 的 fitz 提取每个 PDF 页面的文本信息,并使用 pdf2image 将每页转换为 PNG 图像。通过此过程创建一百万个中文文档和一百万个英文文档图文对用于训练。
图表数据
这是为了支持图表理解。
绘制工具选择Matplotlib和pyecharts,其中matplotlib风格图表建立了中英文各250k空间,pyecharts建立了中英文各500k空间。
另外,每个图表的文本 ground truth 都被转化成了 python-dict 形式,图表中使用的文本,例如标题、x 轴、y 轴等都是从网上下载的 NLP 语料库中随机选取的。
负面自然形象
为了确保新引入的词汇不会造成噪音,Vary 在COCO 数据集中提取了 120k 张图片,每张图片对应一个文本。文本部分是从以下句子中随机选择的:"这是一张大自然的图像";"这是一张大自然的照片";"这是一张大自然的照片";"这是一张自然的图像";"那是一张来自大自然的照片"。
LATEX 渲染文档
这是为了支持公式和表格。
首先在arxiv上收集一些.tex源文件,然后使用正则表达式提取表格、数学公式和纯文本,最后使用pdflatex准备的新模板将这些内容重新渲染。
收集了10多个模板进行批量渲染,另外将每个文档页面的文本ground truth都转换成mathpix markdown风格,以统一格式。
经过本次建设,共获取英文页面50万个、中文页面40万个,部分样本如图7所示。
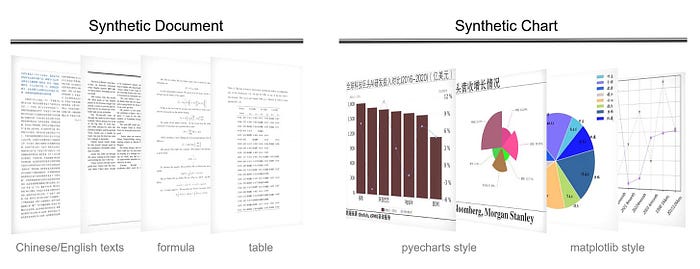
图 7:合成数据可视化。来源:Vary。
如图7所示,Vary使用pdflatex来渲染文档,使用pyecharts/matplotlib来渲染图表。文档数据包括中英文文本、公式、表格等。图表数据包括中英文条形图、折线图、饼图、组合图等。
语义关联图渲染
使用 GPT-4 使用相关语料生成一些图表,然后使用高质量语料库渲染另外 200k 图表数据进行 Vary-base 训练。
一般数据
图文对从LAION-COCO中随机抽取,数量为400万。在SFT阶段,使用LLaVA-80k或LLaVA-CC665k以及DocVQA和ChartQA的训练集进行微调。
尽管 Vary 进行了许多实验,但我们的重点主要放在与PDF 解析相关的性能上。

图 8:细粒度文本感知对比 Nougat。Vary-tiny 是基于 OPT-125M 生成视觉词汇的模型,拥有纯 OCR 能力,包括中文和英文。Vary-base 是基于 Qwen-Chat 7B 扩展视觉词汇后的模型,既拥有纯文档 OCR 能力,又通过提示控制拥有 markdown 格式对话能力。来源:Vary。
如图8所示,Vary-base在英文纯文本文件上的表现与Nougat相当,并且在处理公式和表格方面,Vary-base的表现优于Nougat,编辑距离为0.181,F1得分为81.10%。
图 9 展示了 Vary 将图像转换为 Markdown 的能力以及纯 OCR 的能力。

图 9:Vary-base 的 Excel Markdown 转换或纯 OCR 功能遵循指令。Vary-base 可以根据用户的提示控制文档图像输入的输出格式。来源:Vary。
图10展示了Vary的表格识别能力。
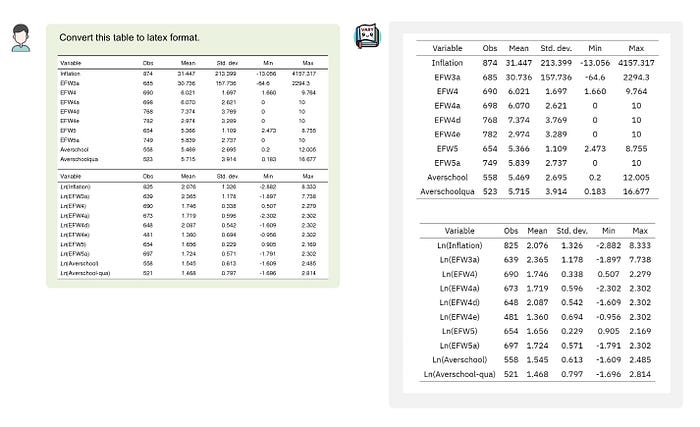
图十:Vary-base 的 Markdown/Latex 格式转换能力(表格中)。图片来自网络。来源:Vary。
StrucTexTv3:一种高效的富文本图像视觉语言模型
富含文本的图像由于其多样性、复杂性和独特的理解需求,对大型多模态模型提出了各种挑战。
一个重要的挑战是这些图像中充斥着小而密集的文本,这需要高分辨率的输入才能精确地提取文本。有三种方法可以解决这个问题。
- LLaVA和Qwen-VL等方法通常使用 224x224 或 336x336 的图像大小,很难捕捉到这些精细的细节。
- PALI-X和PALI-3旨在直接利用高分辨率图像。然而,这种方法受到内存和计算资源的限制,大大限制了基于 ViT 的视觉编码器可以处理的分辨率。
- Monkey和UReader使用滑动窗口技术将输入图像划分为较小的块。虽然这种方法在一定程度上缓解了规模问题,但它可能会引入语义不一致,从而可能影响模型的感知和理解能力。
StrucTexTv3是一种高效的视觉语言模型,它通过三项关键创新解决上述挑战。
- 开发了一种先进的视觉语言模型,专门用于感知和理解富含文本的图像。该模型有效地解决了与高分辨率输入和复杂表征学习相关的挑战。
- StrucTexTv3 收集了近 3000 万个基于文本丰富图像的多模态数据点,简称 TIM-30M。该数据集包含大量感知和理解指导学习数据。
- 利用指令学习,StrucTexTv3 展现出广泛的感知和理解能力。尽管其 LLM 只有 1.8B,但它在各种任务和数据集上都表现出色,超越了 LLM 为 7B 的模型。
概述
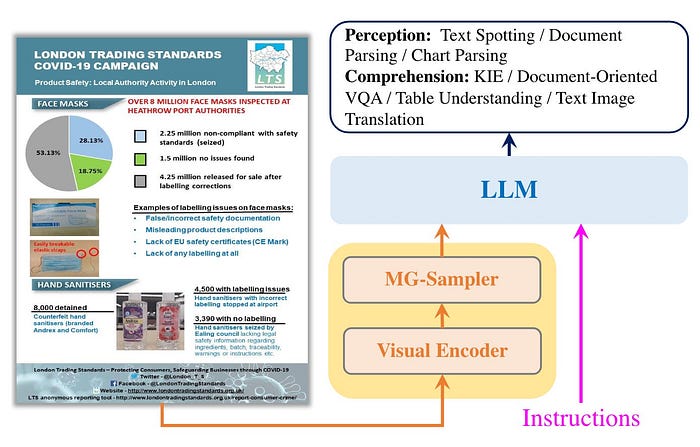
图 11:StrucTexTv3 概览。来源:StrucTexTv3。 获取具体资资料: 2img.ai
如图 11 所示,StrucTexTv3 由三个组件组成:
- 一种有效的视觉编码器,可以有效提取视觉特征。
- 多粒度标记采样器,从多尺度视觉特征中获取丰富、细粒度的视觉表示。
- 理解和推断富含文本的图像中的视觉线索和语言符号的LLM。
训练数据
如图12所示,StrucTexTv3构建了大规模基于文本图像的多模态训练数据,即TIM-30M,主要包括感知任务和理解任务。
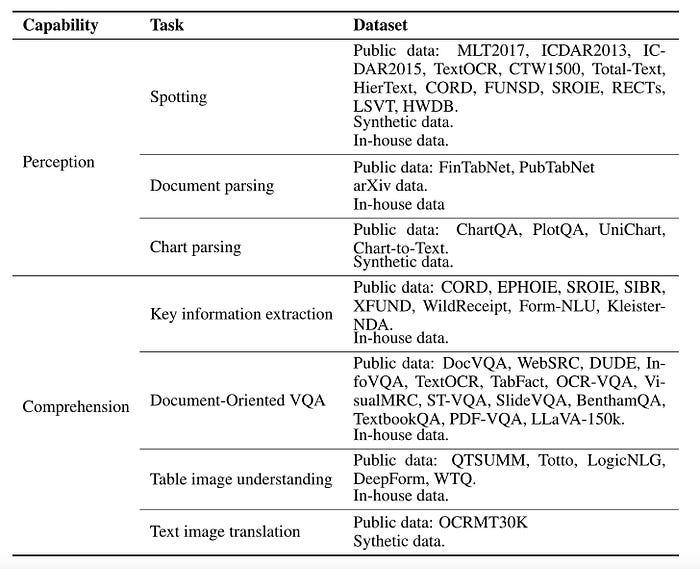
图 12:TIM-30M 数据摘要。来源:StrucTexTv3。
在这里,我们将重点关注文档解析数据集的构建,这也是PDF解析中最相关的任务。
StrucTexTv3 的文档解析数据源主要由三部分组成:公开的基准数据、arXiv 数据和弱标记的内部数据集。此外,表格结构识别得到了FinTabNet和PubTabNet数据的支持,使我们的模型能够解析表格结构。每个表格图像都表示为一个 HTML 序列。
StrucTexTv3 沿用了Nougat的数据生产流程 **,**从 arXiv 下载 LaTeX 源码,转为 PDF 格式,再转换成对应的 Markdown 序列,同时收集了大量书籍和学术论文图片,并通过商业 API 获取伪标签,提升模型的泛化能力。
StrucTexTv3 使用提示"将图像的文本内容转换为 markdown。"来指导模型将输入解析为 Markdown 格式。
训练
训练过程包括三个阶段:
- 在预训练阶段,目标是赋予模型感知文本的能力。
- 在多任务预训练过程中,利用各种感知和认知任务的训练数据,使模型具备感知和认知能力。输入图像大小保持在1600x1600,最大序列长度设置为4096。
- 在监督微调阶段,应使用图 12 中详述的高质量基准数据对模型进行进一步微调。StrucTexTv3 保持与第二阶段相同的图像大小、序列长度和可训练参数,并在更高质量的基准上进行了额外 2000 步的训练。
关于性能
图13是StrucTexTv3感知和理解富含文本的一般图像的能力的演示。
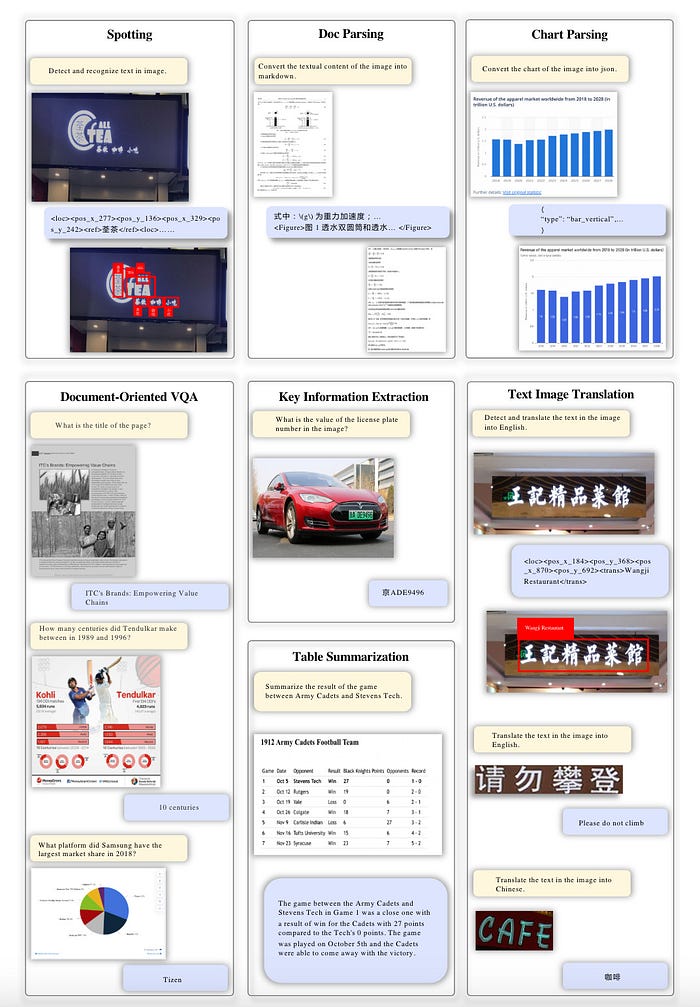
图 13:StrucTexTv3 的通用富文本图像感知和理解能力。第一行显示感知级能力,例如文本识别、文档解析和图表解析。第二行展示认知级能力,包括面向文档的 VQA、关键信息提取、表格摘要和文本图像翻译。来源:StrucTexTv3。
这里我们重点关注PDF解析任务的性能。
对于该任务,当提供文档图片时,模型需要输出Markdown转换的结果,包括正文、表格HTML信息、公式识别结果等。
应使用三个测试集来评估模型在此任务上的表现。这三个测试集包括 200 个用于正文解析的文档图像、100 个包含数学公式的文档图像和 100 个带有跨单元格表格的文档图像。在每个数据集中,一半图像应为中文,另一半应为英文。
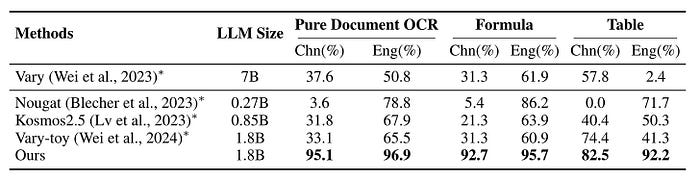
图 14:Doc Parsing 基准测试的实验结果。来源:StrucTexTv3。
图14表明,StrucTexTv3在处理中文和英文文档时都优于其他方法。无论文档包含纯文本还是带有公式和表格识别结果的图像,这种优越性都是显而易见的。
见解和思考
对于具有代表性的大型文档理解多模态模型的介绍就到此结束了,现在我们来谈谈一些感悟和思考。
关于训练数据
从上一节可以看出,用于文档理解的无 OCR 大型多模态模型需要大量数据。这是因为这些模型需要解决文档感知和理解等各种任务,并且其结构相当复杂。
如果专注于PDF 解析任务,则需要的数据较少。例如,使用 TIM-30M 数据集,我们可以删除理解数据。但是,此操作是否会影响 PDF 解析任务的有效性仍有待验证。
另外,如果希望获得像StrucTexTv3这样的image-markdown对,建议使用Nougat的方法,如图15所示。
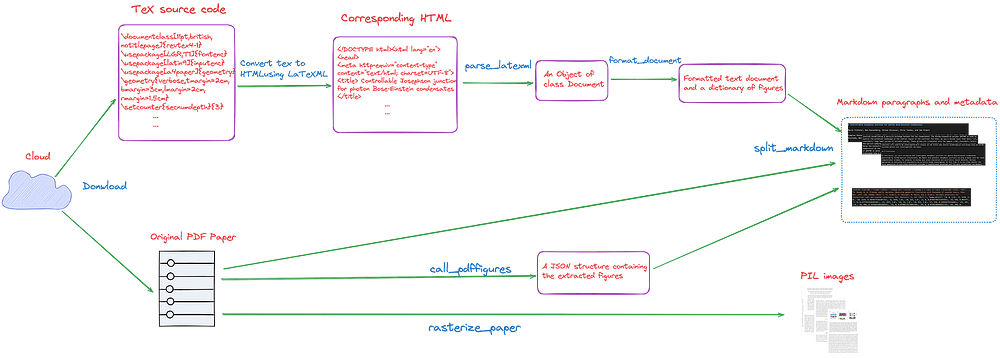
图 15:Nougat 的数据处理流程,TeX 源码和原始 PDF 论文最终被转换成图片-Markdown 对。图片来自作者。参见上一篇文章。
关于模型
TextMonkey 和 Vary 都集成了具有 7B 参数的 LLM,而 StrucTexTv3 的参数最少,只有 1.8B。
如图14所示,StrucTexTv3在PDF解析任务中的表现甚至超越了7B模型。因此,StrucTexTv3模型架构是优先考虑的。
但截至2024年7月1日,StrucTexTv3尚未开源,因此目前尚无官方代码可供参考。
关于 PDF 解析的评估
Vary 与 StrucTexTv3 都进行了对比实验,如图 8 和图 14 所示。Vary 采用了 Normalized Edit Distance 和 F1-score,以及 precision 和 recall 作为评价指标。而 StrucTexTv3 则采用了 1-Normalized Edit Distance 作为评价指标。
我的印象是,对 PDF 解析的评估相对不成熟,可供比较实验的模型很少。
关于输入分辨率
TextMonkey 认为提高分辨率也会增加 token 的数量。TextMonkey 做过相关实验,结果表明分辨率并不一定越大越好,不合理的提高模型分辨率策略有时候还会对模型产生负面影响。
如何合理地放大分辨率是一个更值得考虑的问题。
限制和 GPT-4V
使用无OCR的大型多模态模型进行PDF解析尚处于早期阶段,技术尚未完全开发。
这种方法需要大量的训练数据和高端机器配置。它最适合规模较大的团队或资源丰富的团队。对于规模较小的团队或资源有限的团队,这种方法可能不是最佳选择。
此外,作为闭源领域的代表模型, GPT-4V在文档OCR方面并不具备明显的优势。
本文对 GPT4V 在广泛任务中的表现进行了定性演示和定量分析。这些任务包括场景文本识别、手写文本识别、手写数学表达式识别、表格结构识别以及从视觉丰富的文档中提取信息。
虽然 GPT-4V 在准确识别拉丁内容和处理可变分辨率输入图像方面表现出令人印象深刻的能力,但它在多语言和复杂场景中尤其困难。
结论
本文介绍了使用无OCR大型多模态模型解析PDF的典型方法,并提供了个人的见解和想法. 获取具体资资料: 2img.ai