参考资料来自生信技能树
先输入echo 'export PS1="\\0332;\h:\u \w\007\03333;1m\u \03335;1m\\t\\033\[0m \[\\033\[36;1m\w\\033\[0m\n\\e\[32;1m$ \\e\[0m"' >> ~/.bashrc
再输入source ~/.bashrc就能够让命令字体带上颜色,同时命令将会在下一行开始输入,如图
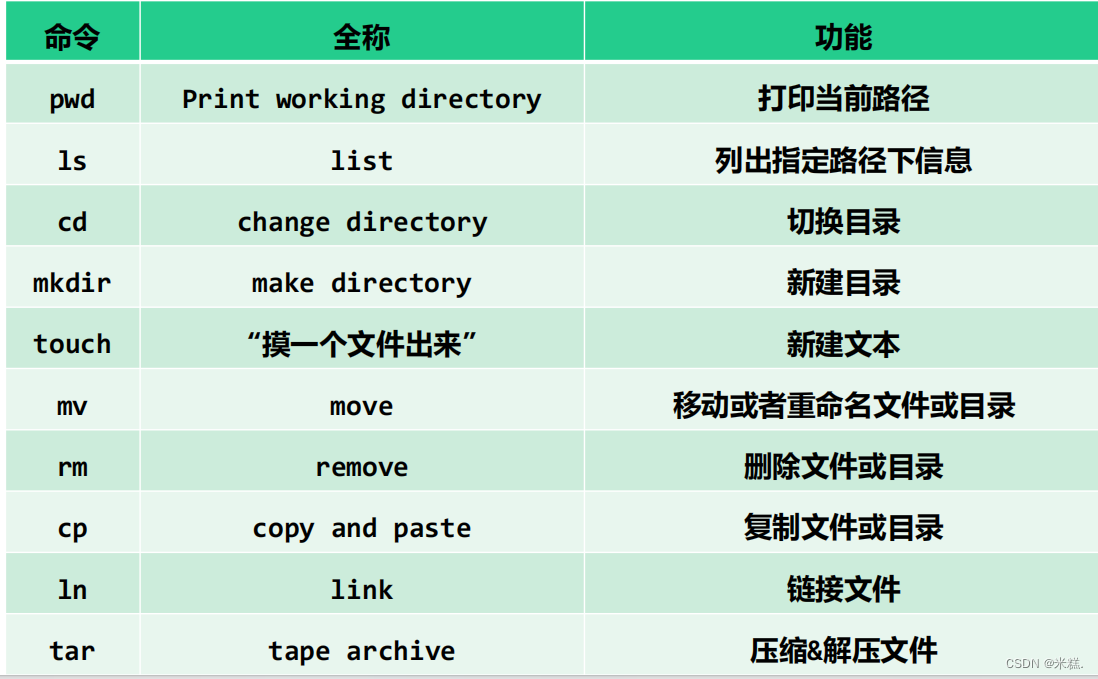
十个重要命令

挑出几个做详细介绍
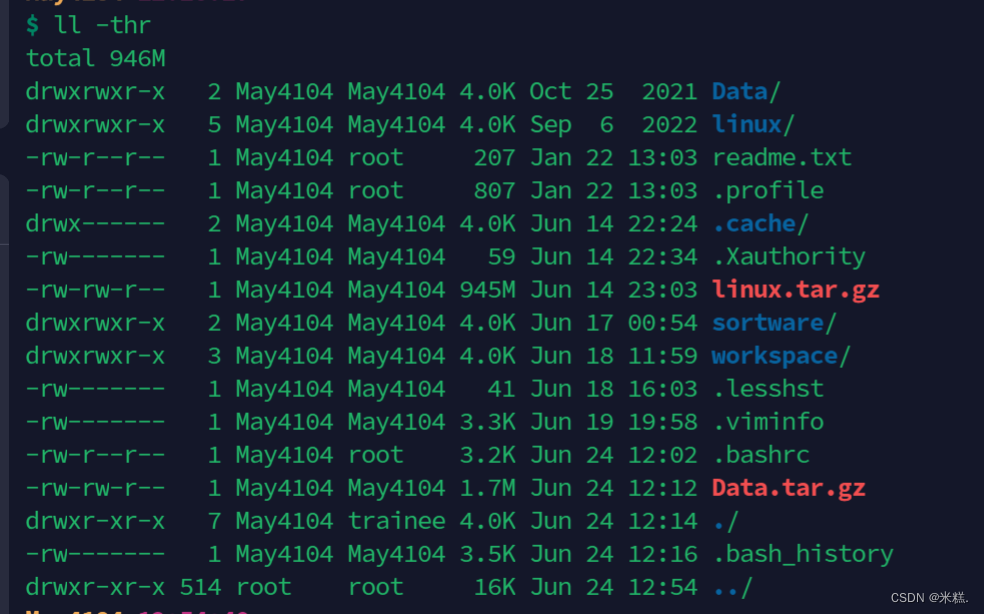
使用ll -thr来进行展示是一种比较好的展示形式,其中ll是ls -alF的简写,t和h表示按照时间倒序排列,这样的好处是让最新创建的文件都显示在下面,然后h表示将容量以KB,MB等我们能看懂的方式展示,而非字节。效果如图所示,
cd-可以返回上一级目录
cd或者cd~都是回到家目录
创建文件夹使用mkdir,如果要先创建一个test1,然后再test1里面创建test2,不能直接写mkdir test1/test2,应该写
mkdir -p test1/test2
创建文件使用touch 文件名
同时创建多个文件可以使用touch {文件1,文件2...}
如果要创建的文件名都差不多,比如file1,file2..可以写
touch file{1,2,3....}
tree可以以树状图的形式展示当前目录下的所有文件,如果在根目录下直接运行这个tree会导致刷屏,因为文件太多了,此时我们可以写tree -L 3来只显示三级,还可以直接tree 文件夹名,来查看指定文件夹的层级结构。
移动文件的命令是mv 语法为mv 要移动的文件名 移动到哪里去
重命名的命令也是mv 语法为 mv 要改的文件名 新名字
也就是说如果mv处理的是文件和文件之间的关系,则表示重命名,如果处理的是文件和文件夹之间的关系,则表示移动
如果mv处理的是文件夹和文件夹之间的关系,就比较复杂了,需要看后面的文件夹是否存在,如果存在,就表示把一个文件夹移动到另一个文件夹里面去,如果不存在,就表示把一个文件夹重命名
可以使用命令mv 文件名1,文件名2....同时移动多个文件,如果这些文件名类似,比如都叫file1,file2...则可以使用
mv file* 文件夹名,来把以file开头的文件都移动到指定文件夹去。
删除文件使用命令rm 要删的文件的名字
删除文件夹使用的命令是rm -r 文件夹名字
有时候文件夹会比较复杂,每删除一个文件系统就会询问是否要删除,就挺烦的,这时候我们可以使用rm -rf 文件夹名字,就可以直接删掉文件夹了
复制文件用的指令是cp,这个cp不是copy的简写,而是copy and paste的缩写,顾名思义我们在使用的时候就要告诉系统拷贝谁,拷贝到哪里去,基本语法就是cp 文件名 文件夹名
拷贝的时候可以给要拷贝的文件重命名,比如写成
cp file1 mydir/file2 就可以把file1重命名成file2然后拷贝到mydir去,其中这里的mydir是一个文件夹,file2是不存在于mydir里面的一个文件。
如果要拷贝文件夹,就需要加上参数-r,语法为
cp -r mydir1 mydir2
链接文件使用的命令是ln,也就是link:链接的缩写。
通常我们使用的是软链接,但是直接ln默认是硬链接,软硬链接这两个概念非常计算机,我们不用管,只需要知道所谓链接就好像是创建一个快捷方式,就好像我们在windows系统中点击桌面上的快捷方式和去C盘里面找到这个应用的安装位置点击他,效果一样。
ln默认是硬链接,我们需要软链接,就要加上参数-s,还需要提供两个参数,即链接的是谁,连接到哪里去,语法为:
ln -s 要链接的文件 链接到的目录
比如在我的根目录里面的home下有一个t_linux文件,我要把这个文件链接到家目录下
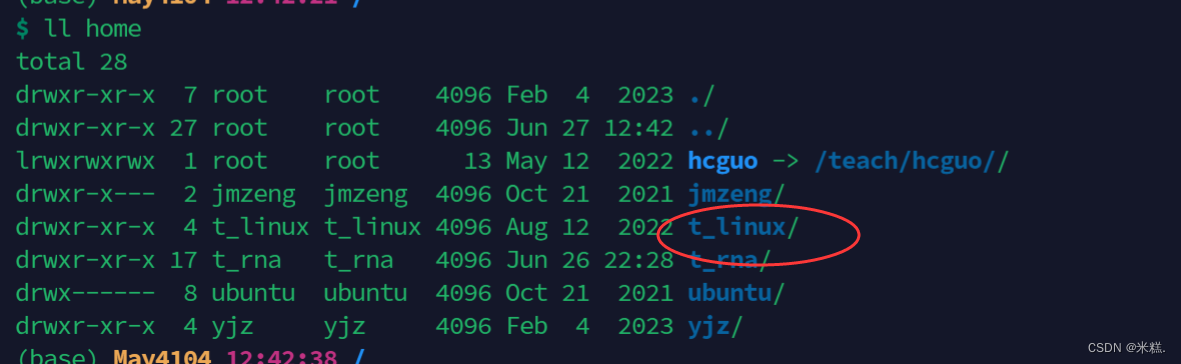
就可以写:ln -s /home/t_linux ~,此时在我们的家目录下已经出现了这个链接的文件
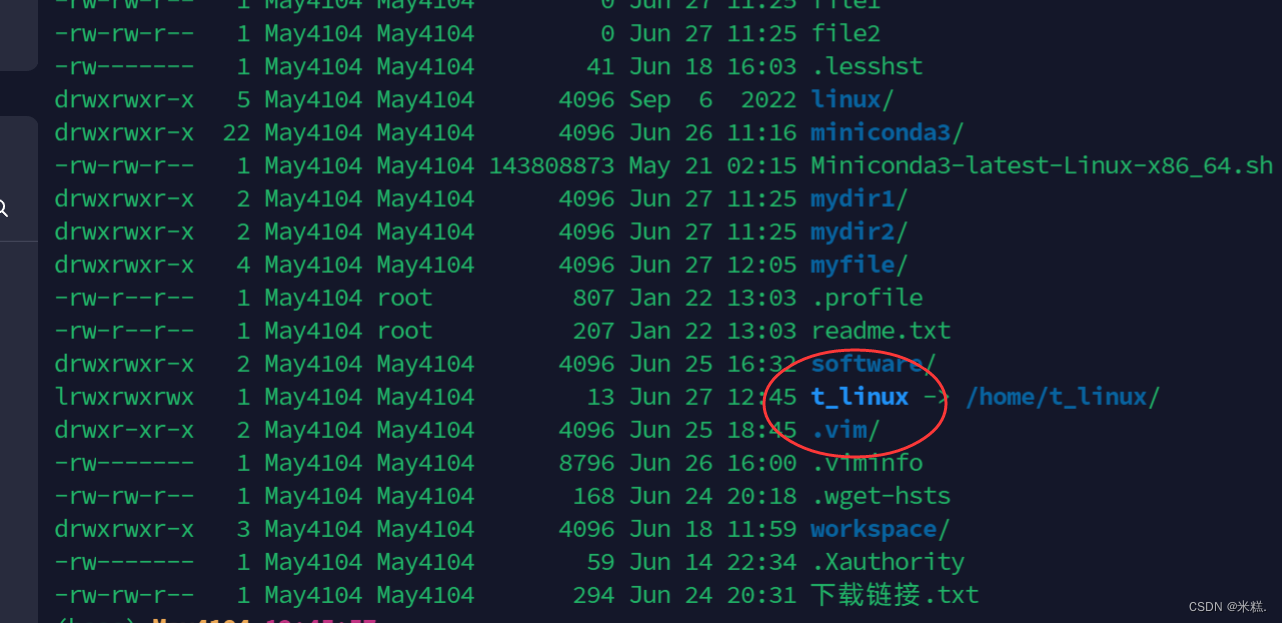
注:链接的时候最好使用绝对路径。
解压与压缩的命令是tar,以下是常用的参数
解压:
-c 创建一个新的tar归档文件(创建压缩文件)
-x 从已有tar归档文件中提取文件(解压缩)
-f 输出结果到文件或设备
-v 在处理文件时显示文件(显示处理进度)
-j 将输出重定向给bzip2命令
-z 将输出重定向给gzip命令
压缩:
-c 创建一个新的tar归档文件(创建压缩文件)
-f 输出结果到文件或设备
-v 在处理文件时显示文件(显示处理进度)
-z 将输出重定向给gzip命令
tar这个指令一般就是两种方式,如果是解压,就写
tar -zxvf 待解压文件
如果是压缩,就写
tar -zcvf 压缩后的文件名 要压缩的文件
其中要压缩的文件可以有多个
注:tar常用的5个参数(z x c v f),其中f后面一定是文件名,其他的几个参数顺序可以随便换。
还有一些其他的压缩和解压命令

小结:
一些技巧

ctrl+u:剪切光标位置到行首的字符
cat这个指令原本用于把某个文件的内容全部展示在屏幕上,语法为cat 文件名,但是如果文件过长会导致刷屏,所以这个指令一般不这么用,而是搭配重定向符> 或者追加符>>来使用,原理在于cat指令是可以输出结果的,如果我们只写一个cat,接着按回车,我们就可以在下一行随便输入一些字符,比如我们输入123,cat就会紧接着输出一个123在屏幕上,我们继续输入456,cat也输出了一个456,只有当我们使用ctrl+c终止命令才会结束这个流程。如果搭配>,比如我写cat>file ,(这里如果没有file这个文件,则会自动创建一个名为file的文件)按回车,再输入123,我们发现屏幕上什么也没有,然而根据前面的经验我们知道cat已经输出了123,原因在于>把cat的结果重定向了,重定向顾名思义就是重新定义输出方向,此时cat的输出结果也就是123已经输出到了file文件里面,使用>的效果是覆盖原本文件的内容,或者说是先把原文件内容清空然后再把内容输出进去,要想不覆盖掉文件原本内容应该使用>>,使用方法和>一样,写作cat>>file。
总结:cat与重定向符号和追加符号的组合给我们提供了一种非常简陋的往文件里面写内容的方法。
查看文件前/后几行用的命令是head/tail,默认是查看前/后10行,查看前5行可以写head -5 文件名。
| 在linux中不是或的意思,而是管道符的意思,就是R语言里面那个管道符,表示把|前面的输出作为|后面的输入。管道符经常搭配cat进行使用,表示把某个文件的全部内容作为输出传给下一个指令。例如cat file | head -5,表示把file这个文件的内容前五行显示出来。
more表示按页来显示文件内容,按回车会翻一行,按空格翻一页,这个命令在我们安装软件的时候非常常见,可以直接用空格快读翻页。按q可以退出more的模式。
查看文件最常用的命令其实是less,常用参数有-N,表示显示行号,-S,表示单行显示。执行指令less的时候再按/,可以输入一个我们要查询的关键字来进行关键字查询,此时有该关键词的就会高亮,然后使用n可以查看下一个关键词匹配到的内容,按shift+n可以查看上一个。同时less保留了more的一些功能,比如可以使用空格进行翻页。
注:less可以直接查看压缩文件
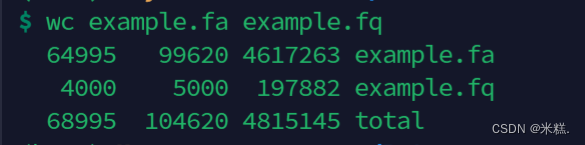
统计一个文件文本内容用命令wc,语法为wc 文件名,默认会返回这个文件的行数,字符串数,字节数,但是在做生信的时候通常只需要使用行数,因此我们可以加一个参数-l,表示只显示行数。
允许一次性统计多个文件,只需要用空格隔开就行。
cut命令用于切割文本,语法为cut 文件名,默认以制表符切割,如果要指定分隔符,要加上参数-d,比如我想要指定逗号作为分隔符,就要写cut -d ',' 文件名,这样就是按照逗号来分割文件了。指定输出哪几列需要加参数-f,比如我有这样一个命令行:
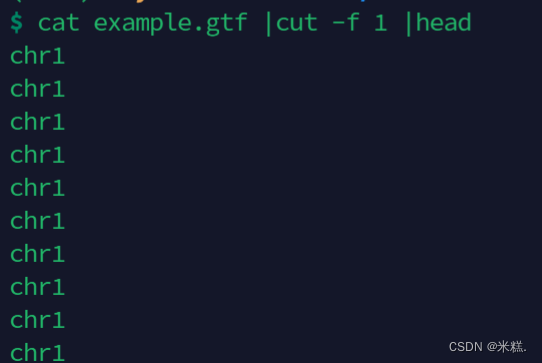
这个命令行意思是先用cat命令查看这个文件内容,本来应该打印在屏幕上,因为这是cat的输出结果,但后面有管道符,那么这个输出结果就给了cut,cut -f 1表示按制表符分隔,并显示第一列,之后这个结果又给了head,表示查看前10行。如果要拿出第1列和第3列,就要写cut -f 1,3
如果要拿出前10列,就写cut -f 1-10,而且即使我们给的顺序是乱的,比如我写cut -f 3,1,5,结果仍然是按照列的编号从小到大的顺序显示的,而不是先显示第三列再显示第一列。
对文件进行排序的指令是sort,常见参数如下

通常-k这个参数肯定会有的,除非传给sort的输入只有一列,sort默认所有的排序内容是字符串,如果要按照数值排序,需要使用-n参数,否则会出现错误,导致12回避110大,因为是挨个字符来比较的,12的第二个字符是2,110的第二个字符是1,所以12会排在110后面,表示12比110大,这显然错误。比如我们要按第四列进行排序,第四列恰好是数字,就要写sort -k 4 -n 文件名,k和4是要放在一起的。
uniq:用于删除重复的行。但是这个指令只能删除相邻的重复行,如果前面有好几行重复,后面又有好几行重复,那么会导致删不干净,如图
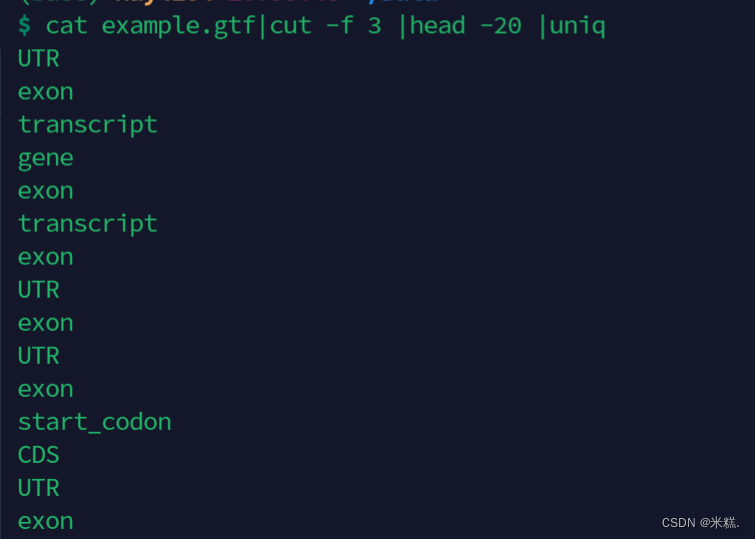
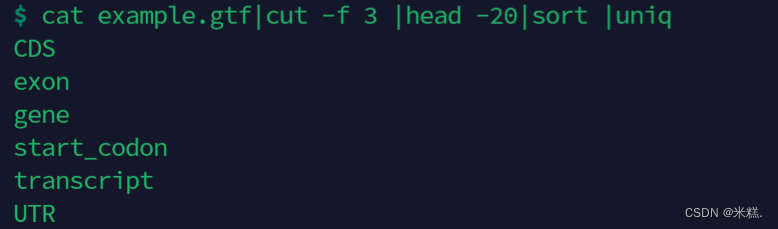
因此通常这个指令要搭配sort来使用,先把重复的行放一起,在使用uniq,如图,先打开一个文件,按制表符进行分割并且显示第三列,之后查看第三列前20行,然后排序,这样就让重复的行相邻了,之后可以使用uniq指令去重。
合并文件内容的命令是paste,实际上如果仅仅是上下合并的话直接用cat就行,比如cat file1 file2就能上下合并两个文件的内容,举个例子
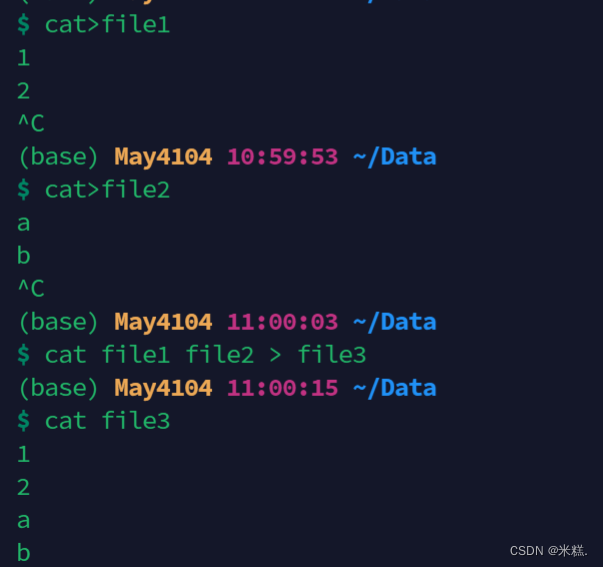
首先利用cat有输出结果的特点搭配重定向符创建一个文件file1,同理创建一个file2,之后cat file1,file2并重定向到file3去,这时候file3的内容就是file1和file2上下合并的。
如果是左右合并需要用paste,如图
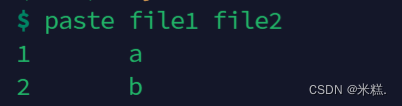
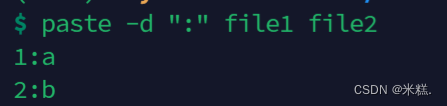
可以看到paste左右合并的时候默认是用制表符进行分隔的,我们可以使用参数-d指定分隔符,比如我想要用冒号进行分隔,就写
paste -d ":" file1 file2,效果如图
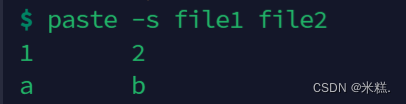
左右合并其实就是按列合并,如果想按行合并,可以加上参数-s
如图,有点类似于转置。
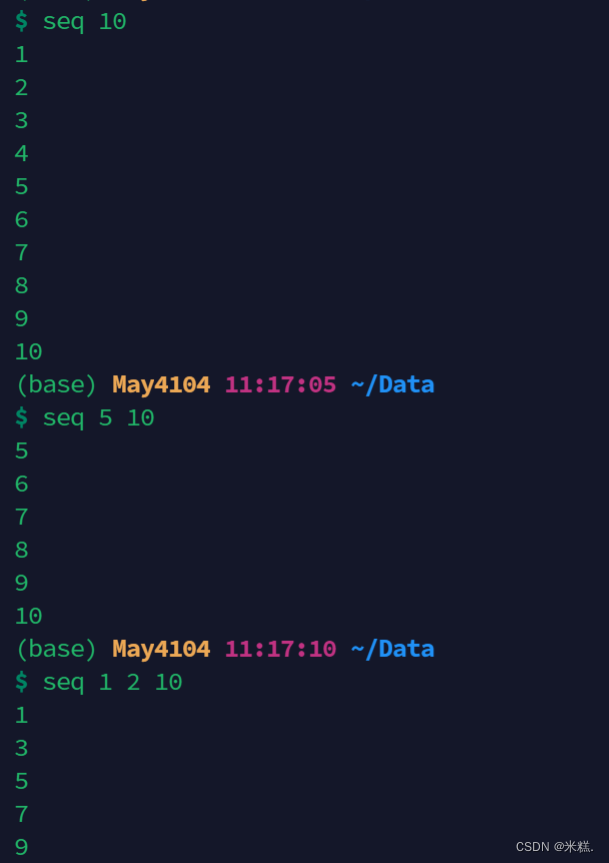
paste可以与与seq搭配使用,seq是一个生成数列的指令,有三种用法,如果只给一个数字,就把这个数字当做结尾,如果给两个数字,就把这两个数字当做开头和结尾,如果给三个数字,第一个是开头,第二个是步幅,第三个是结尾,如图
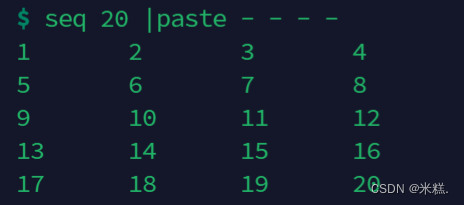
seq与paste搭配可以生成一个矩阵
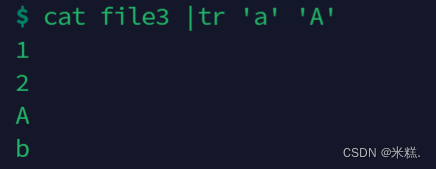
替换字符的命令是tr,如果我想要把file3里面的小写a全替换成大写A,就可以写cat file3 | tr 'a' 'A'或者是tr 'a' 'A'
两个命令行的效果一致,如图
如果要把整个文档所有的小写字母都替换成大写字母,可以写
tr ':lower:' ':upper:' < file3或者tr 'a-z' 'A-Z' < file3
其中两个字符都不能是空字符,所以不能使用 tr 字符1 ''这样的方式删除指定字符,要删除指定字符应该使用参数-d,比如
tr -d '\n'
总结
vi可以使用vim编辑器打开某个文件,按G直接到文件末尾,按gg到文件最开头,按^到所在行的最开始,按$到所在行的末尾。按ctrl+f/b是向上/下翻页。刚开始是一般模式,可以进行复制粘贴和删除的操作,x表示剪切光标处的字符,100x就从光标开始剪切100个字符,dd是剪切所在行,10dd就是剪切包括当前行在内的10行,yy是复制当前行,10yy就是复制包括当前行在内的往下10行,p是粘贴。
按i进入编辑模式,此时所有快捷键失效,可以对文件内容进行编辑,其实按o也可以进入编辑模式,而且是直接进入到文件末尾下一行,当我们需要在文件末尾追加内容的时候可以直接使用o进入编辑模式。
按/,再输入要查询的关键字可以进行查询操作。
还有几个替换的操作

以全局替换为例,三条斜线之间有两个空间,分别写要替换的字符和替换成什么,比如输入:%s/+/-/g就可以把全文的+替换成-,连引号都不用加。实际上不一定要写三个斜线,只要是三个一样的字符就行了,因为如果固定非要写斜线,那么如果我想要把斜线替换成加号,就要写%s ///+/g,这样就会造成歧义,此时我可以用别的符号比如*来代替原来的/,写成%s*/*+*g,这样就可以把所有的/替换成+。
vim编辑器查看文件内容的时候还有一组set命令

使用vim编辑器查看文件的时候可能会报这样的警告
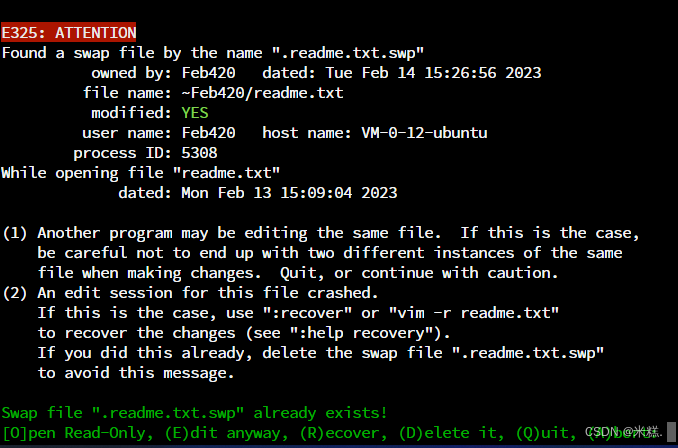
这是因为当多处编辑或者异常断开时会有待处理的.swp文件,解决方法就是手动删除这个.swp文件。
文本处理三驾马车:grep sed awk
grep用于搜索文本,也就是文件的内容,如果要搜索文件,应该使用命令find,grep的语法为:grep 参数 要查的内容 文件名
常见参数有这些

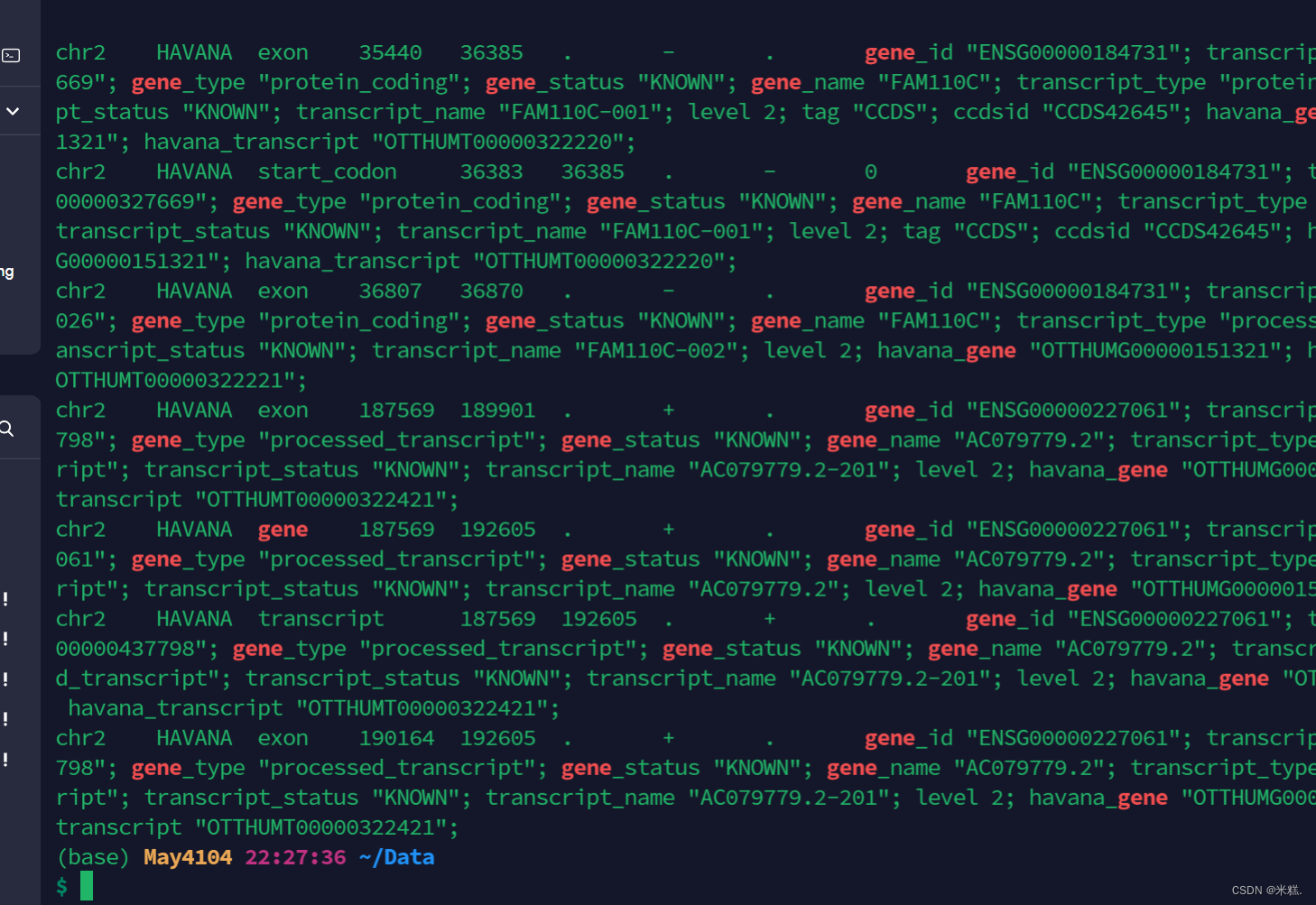
比如我写cat example.gtf |grep 'gene',结果如图,所有gene都变成了红色
如果我想要精确搜索,则需要加上参数-w,通常情况只要使用命令grep,都要写上-w这个参数。
比如less example.gtf |grep -w 'gene'的结果如图
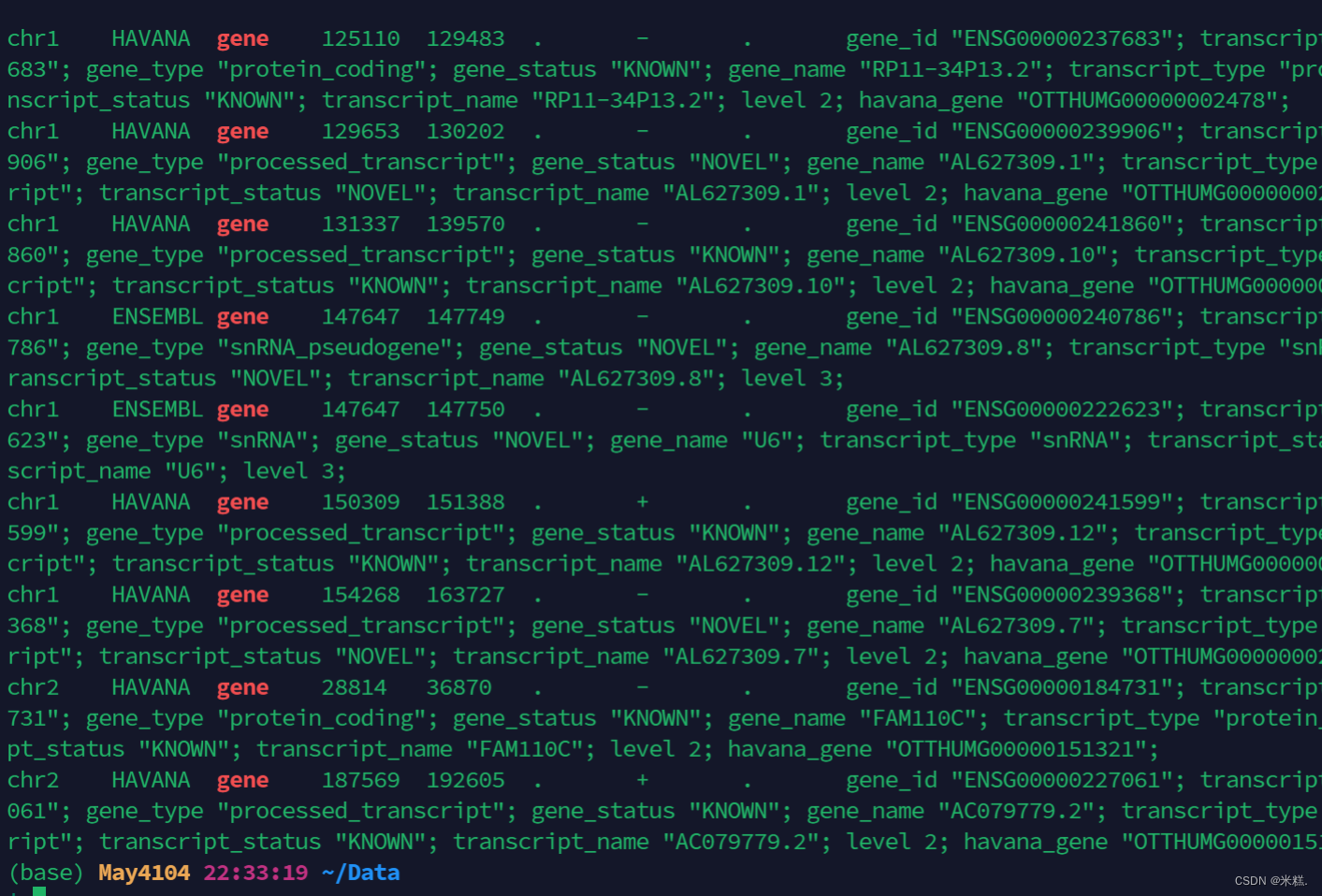
只有他本是就是gene的才高亮了,如果gene只是某个字符串的一部分,则不会高亮。但是精确搜索也不是万能的,比如运行下面这个命令行:
less Homo_sapiens.gz |grep -w 'gene',结果如图
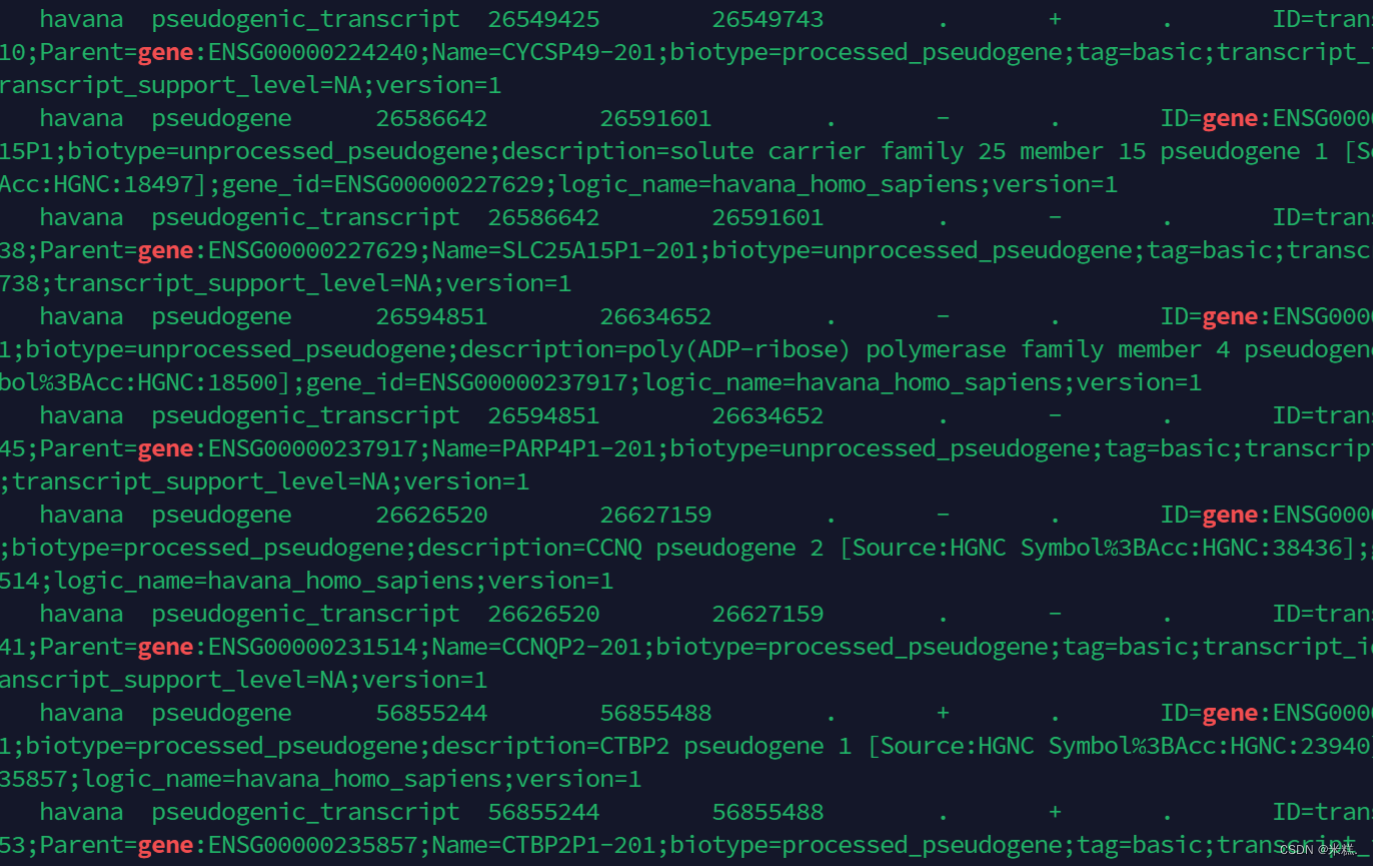
我们发现后面有个ID=gene的也被标成高亮了,这个问题怎么解决后面再说,反正目前知道grep -w 'gene'这种方法失败了。
grep还有一个比较常用的参数就是-v,这个参数用于输出没有匹配到关键字的行。比如grep -v '#' 文件名 这个命令就表示把没有#的行输出,等价于把带有#的行删掉。
如果要同时搜索多个关键词可以使用-e参数,语法为
grep -w -e 'a' -e 'b' 文件名
表示搜索带a的关键词和带b的行,grep会把含有这些关键字的行都打印出来。但是这种方法比较麻烦,要写的代码比较多,还有一种更优雅的方式,当我们要搜索多个关键词的时候,可以把这些关键词写到一个文件里面,比如我有一个文件夹名为myfile(不要管为什么没有后缀,linux中后缀没用),里面内容是这样子

这四个就是我们要搜索的关键词,然后我们使用-f参数通过读取这个文件的内容来搜索这些关键词,命令行如下:
less example.gtf |grep -w -f myfile
结果如图
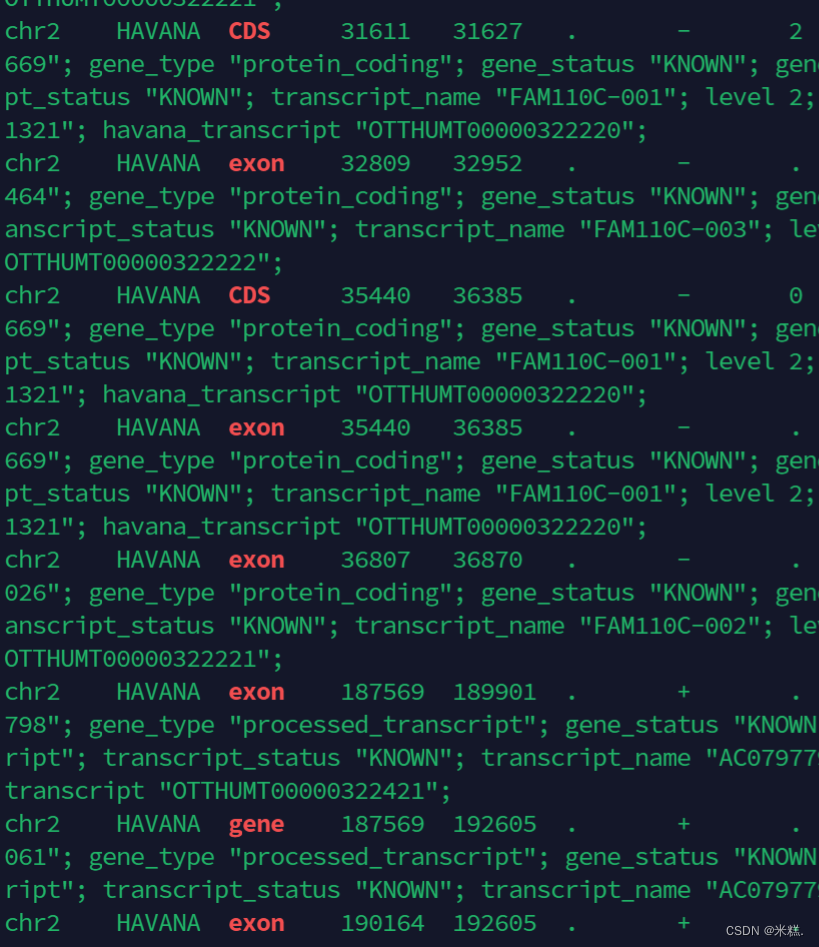
使用-f这种方式来搜索多个关键词要注意-f后面跟的是文件名,不要把别的参数写在-f后面,比如我写了-f -c,那么grep就认为-c是我的文件,当然会有问题。
参数-c会返回匹配成功的行数,比如
cat example.gtf |grep -w -c 'gene'的返回结果是20,说明有20行里面有gene这个单词。且一旦grep戴上了-c这个参数,显示的就只有匹配成功的行数了,而不会把整个匹配结果打印在屏幕上

如果我们只知道要查什么东西和这个东西在哪个文件夹里面,但是不知道这个文件在这个文件夹里的那个文件里面,可以使用-r参数来直接在文件夹里面搜索,比如
grep 'AAGCT' -r Data,结果如图

发现搜索的AAGCT这个关键词在多个文件里面都有。
注:1.使用-r参数只会搜索指定文件夹下的非压缩文件
2.还可以使用-n参数来查看文件夹下哪个文件的哪一行有关键词。
练习:cat example.fq |grep '^@'|grep -v '^@E'|less -SN什么意思?
这个命令的意思是找出example.fq文件中以@开头但是不以
'@ERR329499'开头的行。
正则表达式
^abc 表示以abc开头的行
比如grep '^TGCGA' -r Data -n表示找出Data文件夹中以TGCGA开头的行,-n表示显示这些行在文件中的行号。
abc$ 表示以abc结尾的行
比如grep 'TGCGA$' -r Data -n 表示找出Data文件夹中以TGCGA结尾的行。
abc. 点可以代表任何字符,意思是前三个是abc,第四个字符是啥都行,比如grep 'TGCGA.$' -r Data -n就表示以TGCGA+任意一个字符结尾的行。
?表示前面的一个字符可以出现0次或者1次,比如ab?代表的真实含义是ab或者a,也就是b有没有都行。
当我们写grep 'a?b' 文件名 的时候会出现没有结果的情况,这是因为grep会把引号里面的?当做一个普通字符,而不是正则表达式,解决这个问题的方法是在?前面加一个\,或者在参数里面加一个-E,二者的效果相同,但不能既加\又加-E,不然会负负得正,相当于什么也没做。
什么叫出现零次或者一次?其实就是?前面那个字符可有可无。举个例子:假设我们有一个单词"color",如果我们想要匹配"color"或者"colour",我们可以使用正则表达式colou?r。这里的"?"放在"u"后面,意味着"u"这个字符可以有,也可以没有。
又比如grep -E '^TGCGG?' -r Data -n,表示我要找以TGCGG或者TGCG开头的行,-r Data表示从Data这个文件夹里面找,-n表示显示行号。效果如图

+是匹配一次或者多次,比如ab+的真实含义是ab,abb,abbb...等等,只要一直是b就行。
举个例子grep -E '^TGCG+' -r Data -n
表示找出以TGCG加任意个G开头的行,这个开头可以是TGCG,也可以是TGCGG,甚至可以是TGCG跟上一百个G。

*:表示前面的元素可以出现零次或多次。比如ab*,可以是a,ab,abb,....相当于是?和+的合体版。
举个例子grep -E '^TGCG*' -r Data -n的结果如下

总结:
.(点):可以匹配任何单个字符,除了换行符。
*:表示前面的元素可以出现零次或多次。
+:表示前面的元素至少出现一次或多次。
?:表示前面的元素可以出现零次或一次。
\[\]:表示匹配括号内的任意一个字符。比如ab,表示匹配有a或者b的行,注意直接在\[\]内写字符就行,字符之间不需要用什么空格逗号什么的隔开,因为那些也会被认为是字符。
\^:表示匹配不在括号内的任意一个字符。比如\^abc就会匹配所有没有abc这三个字符的行。
{}:用来指定前面的元素出现的次数范围。
|:表示逻辑"或",用来匹配两个或多个选项中的一个。
sed:流编辑器
用法:sed 参数 'script' 文件名
其中参数可以省略,常用参数如下

sed里面有个script参数,这个参数由address! command这几部分组成,且所有script都要写在引号里面,然后script组成部分里面有个address,这个东西就是告诉sed命令要对哪些行进行操作,address常用写法有下面这些

然后command有下面这些

举个例子,我要在myfile这个文件的第一行后面增加一行,内容为123,就可以写sed '1a 123' myfile,这条指令没有给sed参数,只给了文件名和'script','script'的内容为'1a 123',1表示对第一行进行操作,a表示在指定的行后面添加内容,123是添加的内容,合起来就是在myfile这个文件的第一行后面添加一行。'script'的address和commend之间有没有空格都可以,直接写在address后面即可。比如1a,比如1,3a,1 a
如果我又想在第二行和第三行前面添加一行,就可以写
sed '2,3i hello' myfile
如果想在第一行后面添加hello,第二行前面添加hi,就可以写
sed -e '1a hello' -e '2i hi' myfile
linux中不允许输入文件和输出文件是同一个文件,否则就会报错,比如我想要把修改过的文件直接使用重定向符号>输出到同名文件,sed -e '1a hello' -e '2i hi' myfile > myfile这么写是不行的,这样会导致myfile文件被清空。规则就是这样的。正确方法是先sed -e '1a hello' -e '2i hi' myfile >tmp 把修改的文件重定向到tmp文件里面去,然后再cp tmp myfile 把tmp的内容拷贝到myfile取并覆盖掉myfile,如果我们想要把修改后的文件直接用起来,可以写$(sed -e '1a hello' -e '2i hi' myfile)这个表达式就是前面要保存的tmp的内容。
删除myfile的第一行可以写sed '1d' myfile,删除前三行可以写
sed '1,3d' myfile
改变myfile第一行的内容可以写sed '1c abc' myfile 这样就把myfile第一行的内容改成了abc
注:在使用-e 参数的时候应该遵循先增后删的原则。
再来看几个命令行:
''里面带s表示对文本内容中的字符串进行替换
sed 's/a/A/2'这个命令没有指定adress,那就表示遍历整个文件,最后那个2并不是说每行换两个,而是把每行第二次出现的a换成A。
sed '1~3s/a/A/' myfile 的意思是把myfile1 4 7 10这些行中的a都改成A
sed '/www/s/a/A/' myfile 意思是把myfile的以www开头的行中的所有a都改成A,一定要注意www前面有个/
sed中的替换功能要在''里面写y,这个不建议使用,这个东西一般只适用于想要替换一些比较少的字符的情况,因为y不支持正则表达式,比如我想要把myfile里面的所有abc替换成ABC,可以写:
cat myfile | sed '/y/abc/ABC/',但是如果我们想要把所有的小写字母替换成大写字母,不能写sed 'y/a-z/A-Z/' myfile,因为y不支持正则表达式,如果硬要用y来做全局替换这件事,就只能把26个小写字母和大写字母都写一遍,所以在进行文本的全局替换的时候一般就用前面学过的tr就行,写作tr a-z A-Z myfile
这个''里面放y要求一对一替换,比如把abc替换成def,因为他们都是三个字符,不能把abc替换成abcd,因为这样就不是一对一了。一般替换字符串我们用's'就行,替换全局文本用tr就行。
练习
使用head查看 example.fa 文件,结果传递给 sed,取第2行及
之后行(即序列行)的互补序列,并保存到新文件中
head example.fa|sed '2,$y/AGCT/TCGA/'>hubu
三驾马车之awk

使用awk跟less,cat,vi等命令一样都可以打开某个文本,但是不同的是使用awk打开文本的时候就自动对文本进行分割,默认分隔符用的是空格或者tab键,使用awk的时候可以不写参数(实际上awk的常用参数就只有一个-F)但是必须要写'{...}'大括号里面可以写一些表达式,通常就是print加上一些数据字段(可以理解为awk自动分隔的列)。

0和NF分别代表整个文本行和最后一个数据字段,其余的比如1,2就是第一个数据字段,第二个数据字段,所谓数据字段就是awk读取的时候碰到空白字符了,就认为这是一个数据字段,然后从这里开始直到遇到下一个空白字符,两个空白字符之间又是一个数据字段。
awk '{print $9}' example.gtf表示使用awk打开文件example.gtf并打印他的第九个数据字段。
awk '{print 9,10}' example.gtf |less -S使用awk打开文件example.gtf并打印他的第九个和第十个数据字段数据字段。使用awk打开文本的第9个数据字段和使用vi打开文本的第9列是不同的,因为vi只认tab,awk分割的时候只要是空白字符就行。上面的命令行运行结果如图
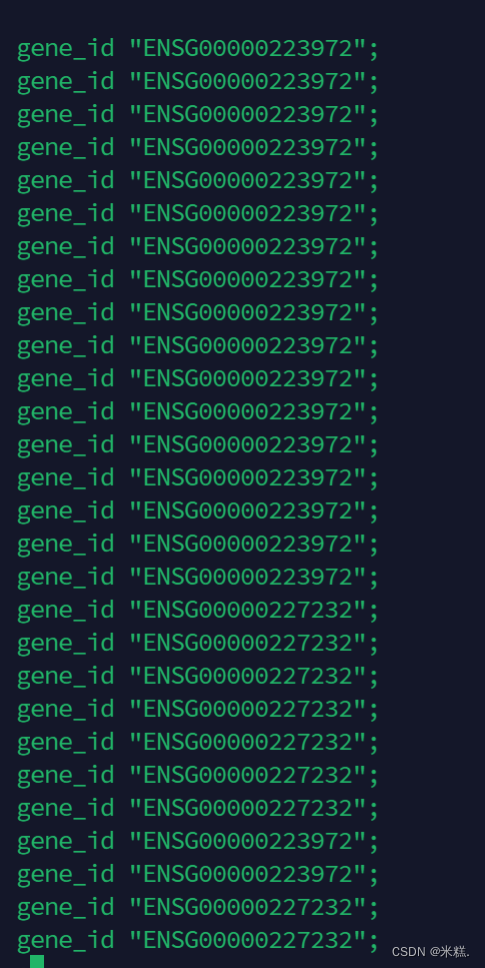
使用awk打开文本的时候,如果要打印多个数据字段在屏幕上,还可以指定两个数据字段的连接符号,如果不指定我们就写逗号就行,如果要指定,就在两个数据字段之间写上指定的符号,并用引号引起来。比如我写awk '{print 9"x"10}' example.gtf |less -S
结果如下,表示第九个数据字段和第十个数据字段之间用一个x连接。注意里面指定分割符号的引号和外边的引号不能一样,如果大括号外边用的是单引号,那里面引指定字符的就要是双引号。
再来讲讲awk的匹配模式,比如命令行
less -S example.gtf |awk '/UTR/{print $0}'|less -S
结果如图,与一般模式不同的是在大括号前面加了一个/UTR/,意思是先筛选出含有UTR的行,在打印全部内容,/UTR/的效果就等价于grep UTR
这个匹配模式不是很重要,因为我们一般会使用一般模式搭配if语句来挑选出含有某个关键词的行,比如
awk '{if(3=="gene")print 0}' myfile
这个命令行的意思是如果第三个数据字段是gene就打印全部这一行的所有内容。
总结
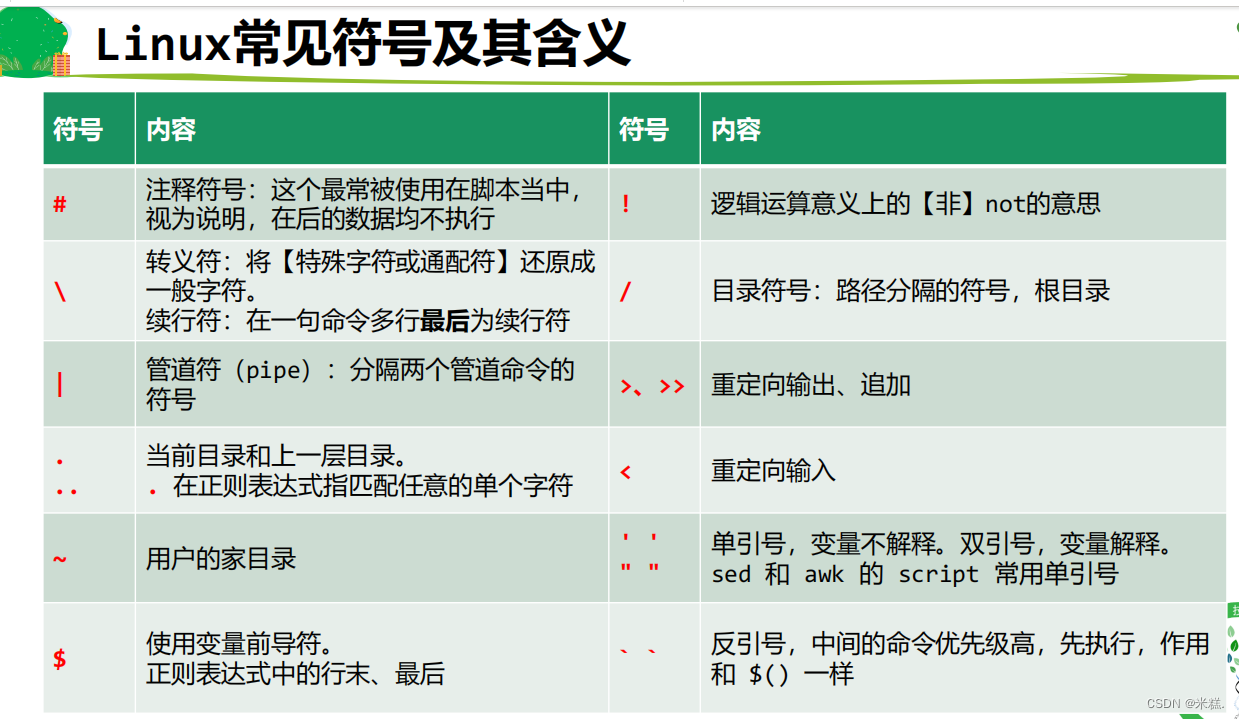
如何自己创建一个命令?
要创建命令首先要明白命令应该具备什么条件,通常情况下爱具备以下三个条件的就可以叫做命令:
1.这个命令的本体文件真实存在在服务器里
2.这个命令的本体文件有可执行的权限
3.这个命令能被系统查找到(命令所在的路径在$PATH里有记录),否则我们就要用绝对路径来执行这个命令。
发现没,其实命令也是一个文件,在linux中一切皆文件。后缀也不重要,只是为了方便区分是什么文件,文件夹也是文件,我们通常说的那个文件叫做文本文件,在linux中也叫文件。
所以创建一个命令就是创建一个文件,创建文件非常简单啊,直接mkdir不就行了?是的,但是这样创建文件里面没有内容,我们要自己加上,我们不如直接vi 文件名,然后在新打开的界面中输入文件的内容,然后sh 文件名 就可以运行刚才我们写的命令了。比如我创建一个命令叫做sayhi,就写vi sayhi ,之后出现一个空界面,按i进入编辑模式,输入echo 'Hi' 然后保存并退出,之后sh sayhi就可以正常运行我们这个命令了。
查看sayhi这个命令

发现最左边是一些看不懂的东西,有r和w,有三部分,中间用-隔开了,这些东西其实是告诉我们有什么权限,其中第一部分是用户的权限,也就是我本人的权限,第二部分是同组的权限,第三部分是其他人的权限。然后r表示可以读,w表示可以写,x表示可以执行。第一位那个-表示这是一个一般文件,如果是d就表示这是目录,如果是l就表示链接文件。发现没,我们这个sayhi文件并没有可执行文件,因为我只有r和w的权限,没x的权限,所以我才用
sh sayhi来执行这个指令,而不是直接sayhi,因为只要是个文件,我们就可以用sh来执行他,现在我想要給sayhi加一个可执行权限x,应该使用命令chmod,就是改变模式的意思,使用命令行:
chmod u+x sayhi,表示給user加上x权限,给哪个文件加呢?给sayhi文件加,这样我们就能直接用sayhi来执行我们的命令了。如图,因为我们没有把这个路径添加到环境变量PATH中去,所以我们只能使用绝对路径来调用这个命令

现在export PATH="/trainee/May4104:$PATH"
把say所在路径添加到环境变量中去,就可以直接使用sayhi来调用这个命令了,如图

不过这样的添加方式只针对本次会话,若想永久生效,应该把
export PATH="/trainee/May4104:$PATH"这句命令添加到家目录下的.bashrc中最下面去,或者说直接把这个命令放到已经存在于环境变量中的某个路径中。
如果想要移除用户的某个权限比如移除掉sayhi这个命令的可执行权限,就把刚才的+改成-就行了,写作:
chmod u-x sayhi,如果要移除所有人对这个文件的可执行权限,就可以写chmod -x sayhi。
还可以用1 2 4 7来分别代表读,写,可执行,可读可写可执行
所以chmod 777 sayhi 就表示所有人都对sayhi这个文件有读写执行的权限。