在深度学习驱动的多通道语音增强和声源定位系统的开发中,由于缺乏大规模的真实录制数据集,这些系统的训练在很大程度上依赖于房间脉冲响应(RIR)和多通道扩散噪声的模拟。然而,模拟数据和真实世界数据之间存在的声学失配可能会导致模型在应用于现实场景时性能下降。现有数据集的局限性如下:
- 缺乏真实数据: 目前大多数公开数据集都是通过模拟房间脉冲响应和扩散噪声生成的,缺乏真实录制的麦克风阵列数据。这导致模拟数据与真实世界数据之间存在声学失配,限制了模型的泛化能力。
- 数据量和多样性不足: 现有的真实录制数据集规模较小,场景和噪声类型有限,难以有效训练通用的语音增强和声源定位网络。
- 缺乏特定任务的标注: 现有数据集往往缺乏目标语音、声源位置等标注信息,限制了其在语音增强和声源定位任务中的应用。
- 阵列依赖性: 现有的端到端语音增强和声源定位模型通常依赖于特定阵列,难以应用于未见过的新阵列。
++++为了解决++++ ++++上述++++ ++++问题,本文提出了一个新的大规模的真实录制且经过注释的麦克风阵列语音和噪声数据集,名为RealMAN。++++
++++数据集下载地址:++++ github.com/Audio-WestlakeU/RealMAN
1 RealMAN 数据集概述
RealMAN 数据集是一个用于语音增强和声源定位的真实录制和标注麦克风阵列数据集。该数据集具有以下特点:
1.1 数据规模
- 83 小时语音信号(48 小时静态说话人,35 小时动态说话人)
- 144 小时背景噪声
- 32 个不同的语音录制场景
- 31 个不同的噪声录制场景
1.2场景多样性
- 覆盖室内、室外、半室外和交通等多种场景
- 包括多种常见的室内场景(如客厅、办公室、走廊、餐厅等)
- 包括多种常见的室外场景(如公园、街道、广场等)
- 包括交通场景(如汽车、公交车、地铁等)
1.3 说话人状态
- 包含静态说话人和动态说话人
- 动态说话人模拟人类行走状态,移动速度合理
1.4 数据标注
- 声源方位角:使用全向鱼眼相机自动检测声源位置
- 直达目标语音:通过估计直达路径传播滤波器从源语音信号中获取
- 语音转录:用于评估自动语音识别性能
1.5 阵列配置
1.7 数据格式
2 RealMAN 数据集优势与潜在应用
2.1 RealMAN 数据集的优势
2.2 RealMAN 数据集的潜在应用
3 基准实验
本文进行了基准实验,以评估该数据集在语音增强和声源定位任务上的性能,并与模拟数据集进行比较。以下是基准实验的详细内容:
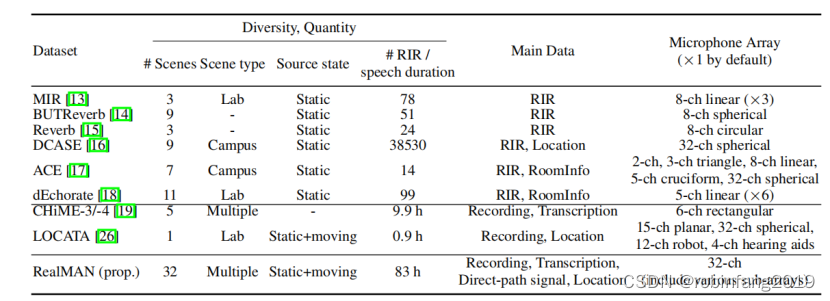

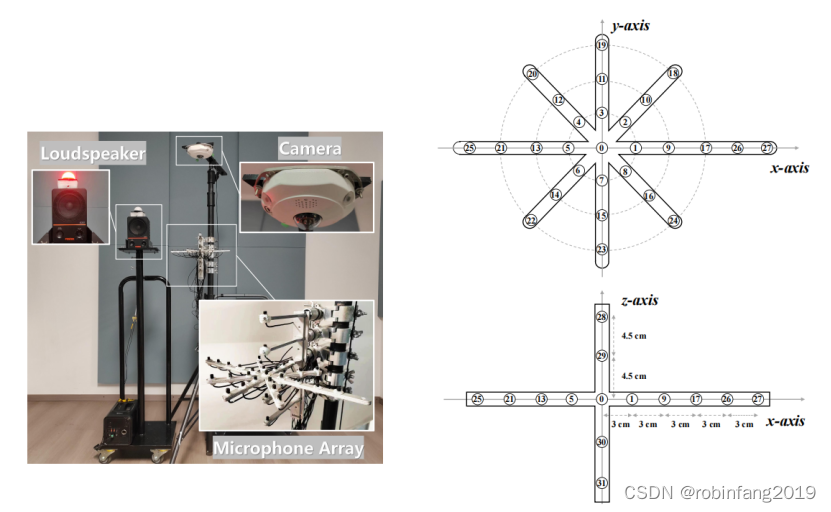
- 使用 32 通道麦克风阵列进行录制
- 阵列包含多种拓扑结构,包括平面线性阵列、圆形阵列和 3D 阵列
1.6 数据分割
- 将数据分割为训练集、验证集和测试集
- 训练集包含 40 个不同的场景,验证集和测试集包含 17 个和 21 个不同的场景
- 将 55 名说话人分配到训练集、验证集和测试集
- 演示集和测试集中的语音和噪声来自匹配的场景,以模拟真实场景
- 语音信号:WAV 格式,采样率 48 kHz
- 噪声信号:WAV 格式,采样率 48 kHz
- 声源方位角:JSON 格式
- 语音转录:JSON 格式
- 真实数据: 避免了模拟数据与真实数据之间的声学失配问题,能够更准确地评估算法性能。
- 大规模和高多样性: 能够有效训练通用的语音增强和声源定位网络。
- 特定任务标注: 方便进行语音增强和声源定位任务的训练和评估。
- 阵列泛化能力: 可以用于训练可泛化到未见阵列的可变阵列网络,解决阵列依赖性问题。
- 语音增强: 改善噪声环境下的语音质量,提高语音识别系统的准确率。
- 声源定位: 确定声源的位置,应用于语音交互、机器人导航等场景。
- 声学场景识别: 识别不同的声学场景,用于智能语音控制、智能家居等场景。
3.1 基准方法
3.1.1 语音增强
FaSNet-TAC:一个流行的时域网络。FaSNet-TAC是一种端到端的滤波求和风格的多通道语音增强系统,它在时间域内操作,并且通过神经网络以端到端的方式估计波束成形系数 SpatialNet:一个新提出的频域网络。
SpatialNet则是一个在短时傅里叶变换(STFT)域内进行端到端语音增强的神经网络,主要用于多通道联合语音分离、降噪和去混响。SpatialNet采用了深度学习方法,结合了Narrow-band Conformer网络结构,能够高效地学习多通道语音信号的空间信息。
3.1.2 声源定位
3.2 评估指标
3.2.1 语音增强
3.2.2 声源定位
3.3 实验设置
3.4 实验结果
3.4.1 语音增强
总体而言,RealMAN 数据集是一个具有挑战性的数据集,能够更准确地反映算法在真实场景中的性能。
3.4.2 声源定位
3.5 可变阵列网络和阵列泛化
这表明 RealMAN 数据集可以成功训练可泛化到未见阵列的可变阵列网络,为解决阵列依赖性问题提供了有效方案。
++++RealMAN 数据集基准实验结果表明,使用真实数据训练的模型在真实场景中取得了更好的性能,有效消除了模拟数据与真实数据之间的差距。++**++**RealMAN 数据集可以用于评估和比较语音增强和声源定位算法的性能,并提供更可靠的基准。此外,使用 RealMAN 数据集训练的可变阵列网络可以应用于未见阵列,为语音增强和声源定位技术在实际场景中的应用提供了新的可能性。
- CRNN:一种结合了卷积神经网络(CNN)和循环神经网络(RNN)的模型,主要用于处理序列化数据并进行识别任务。它通过先使用CNN提取图像特征,然后将这些特征输入到RNN中进行时间序列处理,从而实现对文本、语音等序列数据的识别。
- IPDnet:IPDnet(Inter-Channel Phase Difference Estimation Network)是一种新提出的声源定位方法,旨在从麦克风阵列信号中估计声源的直接路径互通道相位差(DP-IPD)。该方法在不利的声学环境中提取直接路径空间特征,从而实现声源定位。
- ++++SI-SDR:尺度不变信号失真比++++ ++++。++**++**SI-SDR是一种优化生成对抗网络(GAN)语音增强方法的指标,旨在解决模型训练不稳定和生成语音质量不高的问题。它通常被认为是衡量源声音质量的整体指标,适用于时域语音分离中的训练措施。SI-SDR值越高,表示语音质量越好。
- WB-PESQ:宽带感知语音质量评估。WB-PESQ是基于ITU-T P.862标准的语音质量评估方法,用于预测主观意见,适用于宽带语音条件下的语音质量评估。它需要带噪的衰减信号和一个原始的参考信号,能够对客观语音质量评估提供一个主观MOS的预测值。WB-PESQ的评分范围在-0.5到4.5之间,评分越高表示语音质量越好。
- MOS-SIG, MOS-BAK, MOS-OVR:DNSMOS 中的语音质量指标
- CER:字符错误率
- MAE:平均绝对误差。MAE是一种常用的回归模型评估指标,用于衡量预测值与实际值之间的平均绝对偏差。它反映了预测值与真实值之间的差异,能够直观地显示预测结果的准确性。
- ACC:定位精度(N°)。ACC通常用于描述定位系统的精度,特别是在机器视觉和室内定位等应用中。它表示定位系统能够准确确定目标位置的能力。
- 使用 9 通道子阵列进行实验
- 训练集由随机混合的语音和噪声组成,SNR 在 0, 15 dB 范围内均匀分布
- 验证集和测试集由匹配场景的语音和噪声混合而成,信号级别保持不变
- 与模拟数据相比,使用 RealMAN 数据集训练的模型在真实数据集上取得了更好的性能,有效消除了模拟数据与真实数据之间的差距。
- 与模拟数据相比,使用 RealMAN 数据集训练的模型在真实数据集上取得了更好的定位精度。
- 真实录制数据和模拟 RIR 之间的失配会导致声源定位性能下降。
- 真实噪声和模拟噪声之间的失配也会对声源定位性能产生较大影响。
- 使用 28 个麦克风数据训练 FaSNet-TAC 和 IPDnet 网络的可变阵列版本。
- 可变阵列网络在未见阵列上的性能略低于使用测试阵列训练的固定阵列网络,但差距较小。