对于许多机器学习算法,提供的特定数据表示非常重要。比如,首先对数据进行缩放,然后手动合并特征,再利用无监督机器学习来学习特征。因此,大多数机器学习应用不仅需要应用多个算法,而且还需要将许多不同的处理步骤和机器学习模型链接在一起。
使用Pipeline类可以简化构建变换和模型链的过程。
我们知道可以通过MinMaxScaler进行预处理来打打提高核SVM在cancer数据集上的性能,下面代码实现了数据划分、计算最小值最大值、缩放数据和训练SVM:
python
import mglearn.plots
from sklearn.svm import SVC
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
cancer=load_breast_cancer()
#加载并划分数据
X_train,X_test,y_train,y_test=train_test_split(cancer.data,cancer.target,random_state=0)
#计算训练数据的最大最小值
scaler=MinMaxScaler().fit(X_train)
#对训练数据进行缩放
X_train_scaler=scaler.transform(X_train)
svm=SVC()
#在缩放后的训练数据上学习SVM
svm.fit(X_train_scaler,y_train)
X_test_scaler=scaler.transform(X_test)
print('测试集精度:{}'.format(svm.score(X_test_scaler,y_test)))现在,如果我们希望利用GridSearchCV知道更好的SVC参数,有一种简单的方法可能如下所示:
python
from sklearn.model_selection import GridSearchCV
param_grid={'C':[0.001,0.01,0.1,1,10,100],
'gamma':[0.001,0.01,0.1,1,10,100]}
grid=GridSearchCV(SVC(),param_grid=param_grid,cv=5)
grid.fit(X_train_scaler,y_train)
print('最高精度:{}'.format(grid.best_score_))
print('最高测试集精度:{}'.format(grid.score(X_test_scaler,y_test)))
print('最佳参数:{}'.format(grid.best_params_))
其实实践中是不能这样使用的
这里我们利用缩放后的数据对SVC参数进行网格搜索。但是,上面的代码有个不易察觉的陷阱:
在缩放数据时,我们使用了训练集中的所有数据 来找到训练的方法,然后我们使用缩放后的训练数据来运行带交叉验证的网格搜索;对于交叉验证的每次划分,原始数据集的一部分被划分为训练部分,另一部分被划分为测试部分,测试部分用于度量在训练部分上所训练的模型在新数据上的表现。但是,我们在缩放数据时就已经试用过测试部分中所包含的信息。要知道,交叉验证每次划分的测试部分都是训练集的一部分,我们使用整个训练集的信息来找到数据的正确缩放。
对于模型来说,这些数据与新数据看起来截然不同。如果我们观察新数据集,那么这些数据并没有用于对训练数据进行缩放,其最大最小值也可能与训练数据不同。
下面这个例子显示了交叉验证与最终评估这两个过程中数据处理的不同之处:
python
import matplotlib.pyplot as plt
mglearn.plots.plot_improper_processing()
plt.show()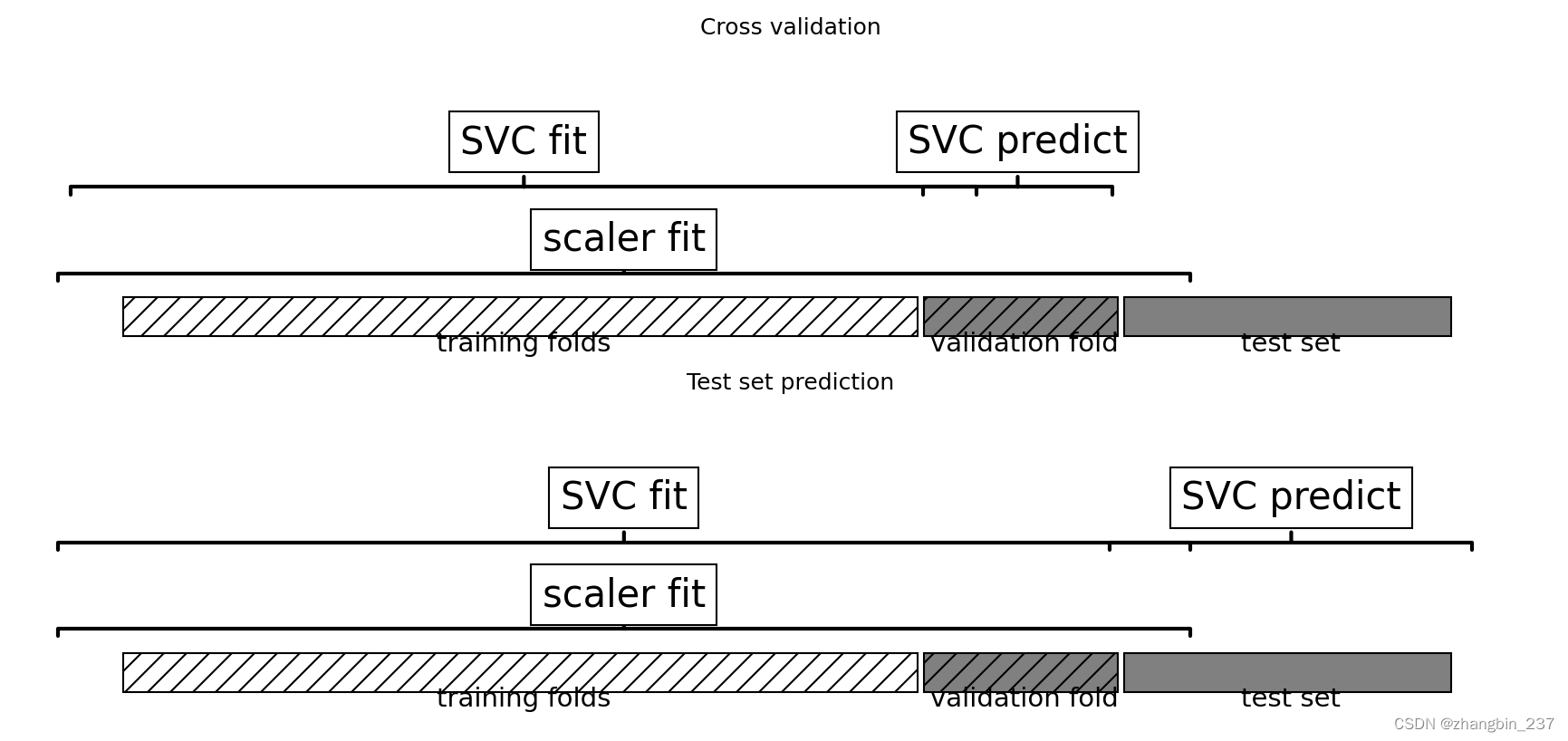
因此,对于建模过程,交叉验证中的划分无法正确地反映新数据的特征。我们已经将这部分数据的信息"泄露"给建模过程。这将导致在交叉验证过程中得到过于乐观的结果。
为了解决这个问题,在交叉验证的过程中,应该在进行任何预处理之前就完成数据集的划分。任何从数据集中提取信息的过程都应该仅应用于数据集的训练部分,因此,任何交叉验证都应该位于处理过程的"最外层循环"。
在scikit-learn中,要想使用cross_val_score函数和GridSearchCV函数实现这一点,可以使用Pipeline类。Pipeline类可以将多个处理步骤合并为单个scikit-learn估计器。Pipeline类本身具有fit、predict、score方法,其行为与scikit-learn中的其他模型相同。
Pipeline类最常见的用例是将预处理步骤(比如数据缩放)与一个监督模型(比如分类器)链接在一起。