为什么需要集群
- 为了高的处理速度
- 单机redis,官网宣传处理速度为10万命令/秒
- 如果业务需要更高的处理速度,则需要使用集群
- 为了存储大量数据
- 一般机器的内存为16-256G
- 如果想要存储更大量的数据,则需要使用集群
分布式之数据分区
-
因为数据需要分布存储在不同的节点上,所以数据在进行存储之前需要先分区
-
数据分区示意图
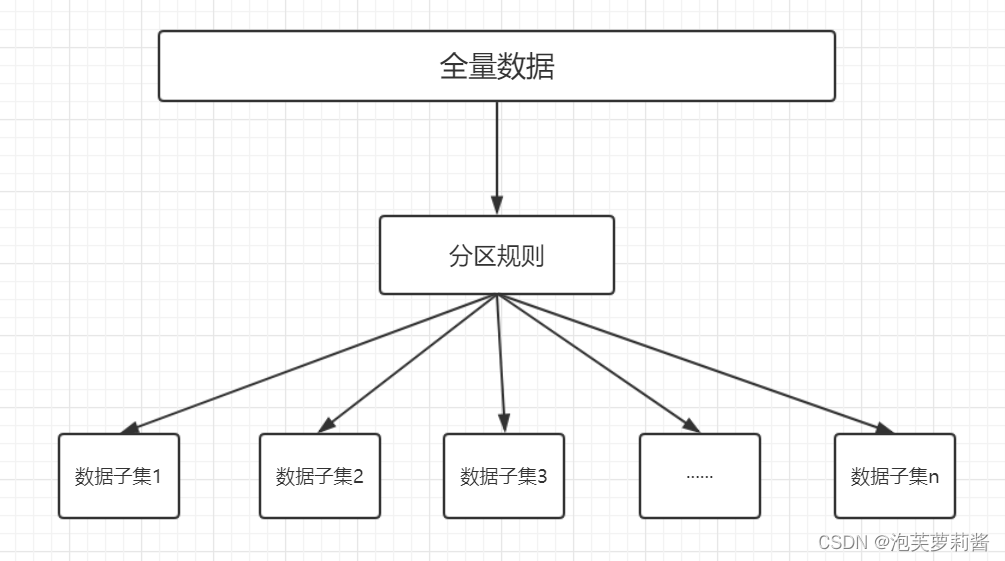
-
数据分区方法
分区方式 特点 典型产品 顺序分区 数据分散有倾斜(某些节点有过多热门数据) 可以顺序访问 键与业务有关 BigTabl HBase 哈希分区 数据分布无倾斜 不能顺序访问 键与业务无关(由哈希函数生成) Redis Cluster Memcache -
哈希分区的三种方法
-
节点取分区余法
- 原理:数据所属节点 = Hash(key) % 节点数
- 优点:原理简单,实现简单
- 缺点:在进行节点伸缩过程中,可能会发生大量的数据迁移,且缓存会失效
- 经验:进行节点伸缩时,最好是以倍数进行扩容或缩减
-
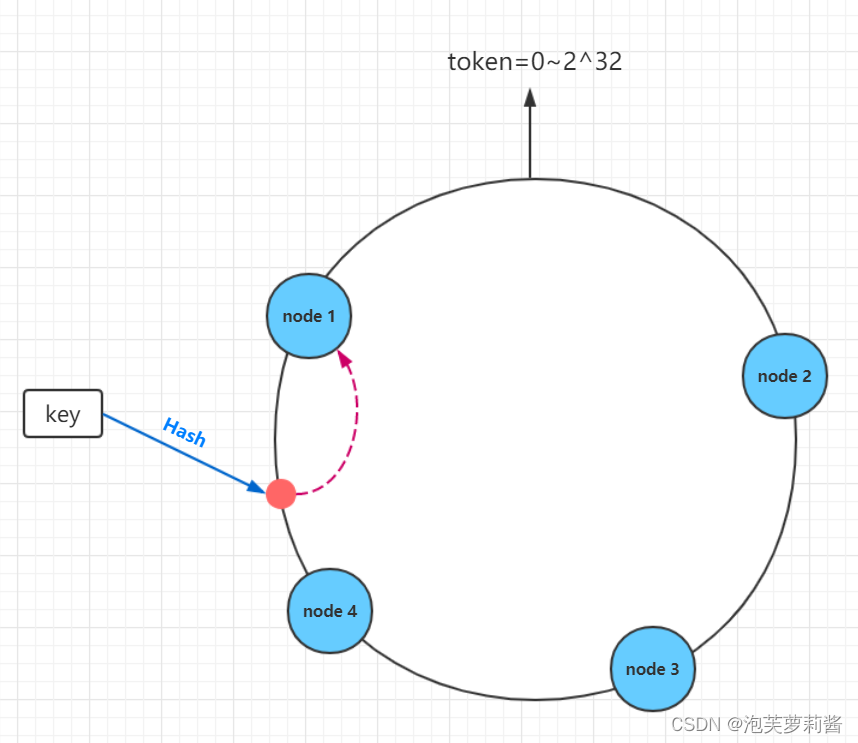
一致性哈希分区法
-
原理:先定义Hash的取值范围,令它组成一个环,集群中每个节点负责一区间的Hash值,当一个数据加入集群时,让它加入哈希值按顺时针最近的节点
-
-
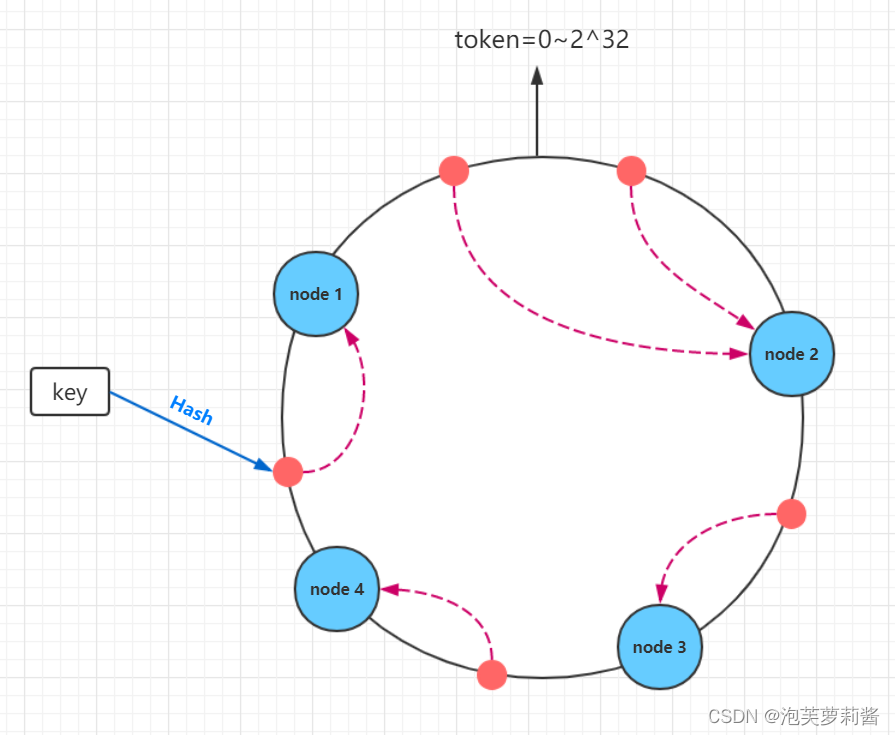
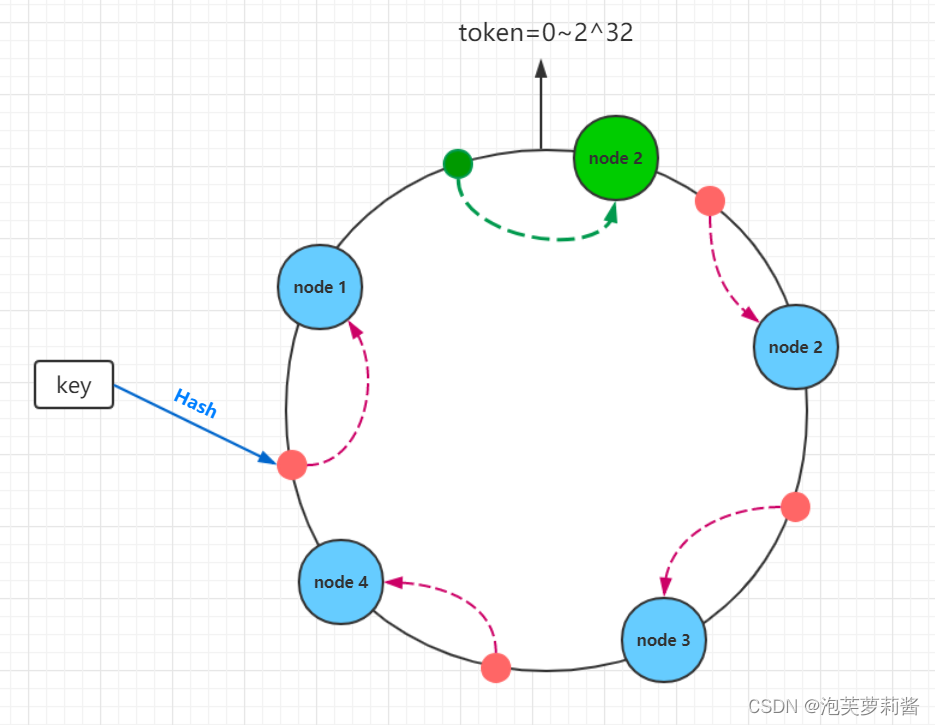
* 优点:节点伸缩只会影响最近邻近节点
* 缺点:还是具有数据迁移-
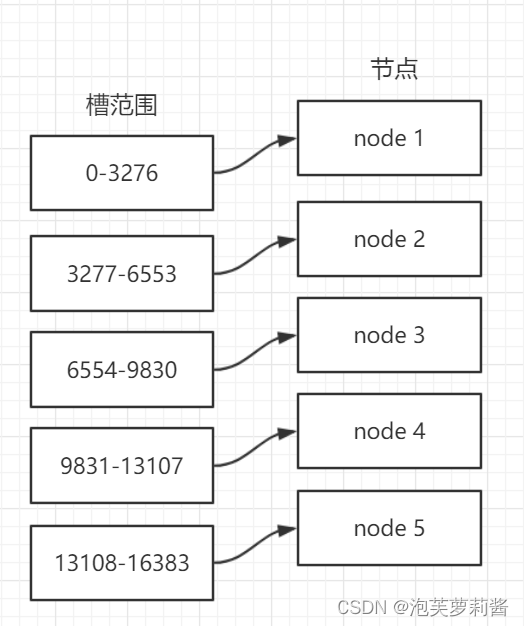
虚拟槽分区法
-
原理:预设虚拟槽,每个槽映射一个数据子集,一般比节点数大
-
优点:不会发生数迁移
-
经验:redis-cluster使用的数据分区算法是虚拟槽分区法
-
redis-cluster架构
架构图
- 节点之间相互通信,客户端随机连接一个节点
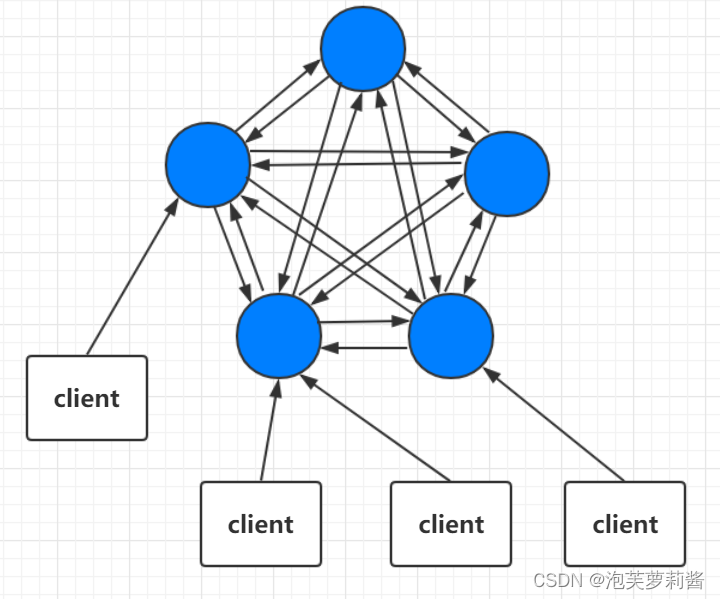
- 集群中节点共享信息
- 当客户端访问一个节点拿数据时
- 数据就在访问节点:直接返回数据给客户端
- 数据在其他节点:返回信息告诉客户端去哪个节点拿数据(不帮忙拿,只是告诉去哪里拿)
- 集群中节点是高可用的,但不是依靠sentinel实现的,而是依靠节点之间通信实现的
节点配置
| 配置项 | 配置说明 |
|---|---|
| daemonize yes|no | 是否以守护线程方式启动 |
| port | 端口 |
| dir | 工作目录 |
| logfile | 日志文件名 |
| dbfilename | RDB文件名 |
| cluster-enabled yes|no | 是否构建集群 |
| cluster-config-file | 集群日志文件名 |
| cluster-require-full-coverage yes|no | 是否只有当所有节点都可用时,集群才可用 |
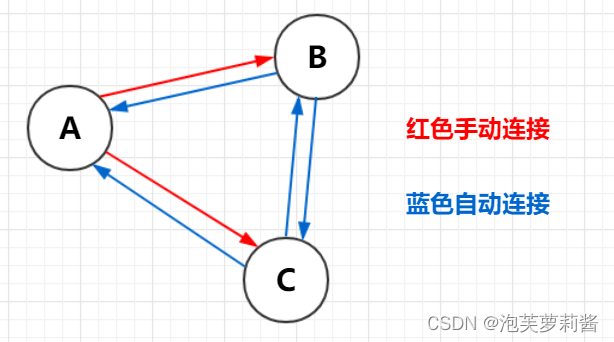
meet操作
-
概念:当一个节点A与节点B连接时,由于节点数据共享,所以节点B可以自动连接上与节点A进行连接的节点
-
命令
- redis-cli -h 127.0.0.1 -p 7000 cluster meet 127.0.0.1 7001
指派槽
-
概念:让某个节点负责某个区间哈希值的槽
节点 槽 A 0 ~ 5460 B 5461 ~ 10922 C 10923 ~ 16383 -
经验:当集群中未分配完所有的槽(16383)时,节点是不可用的
主从复制
客户端命令
- 查看当前节点的信息
- redis-cli -h 127.0.0.1 -p 7000 cluster info
- 查看当前节点连接了多个其他节点
- redis-cli -h 127.0.0.1 -p 7000 cluster nodes