李宏毅深度学习笔记
https://blog.csdn.net/Tink1995/article/details/105080033
Transformer 是一个基于自注意力的序列到序列模型,与基于循环神经网络的序列到序列模型不同,其可以能够并行计算
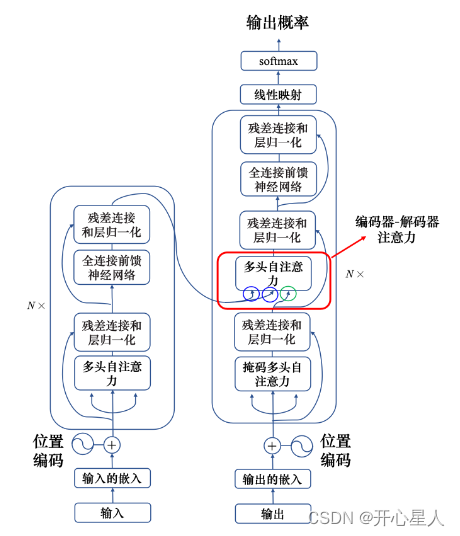
Transformer架构
Transformer主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。
(1)输入部分
- 源文本嵌入层:将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
- 位置编码层:为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
- 目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
(2)编码器部分
- 由N个编码器层堆叠而成。
- 每个编码器层由两个子层连接结构组成:第一个子层是多头自注意力子层,第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
(3)解码器部分
- 由N个解码器层堆叠而成。
- 每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接层。每个子层后都接有一个规范化层和一个残差连接。
(4)输出部分
- 线性层:将解码器输出的向量转换为最终的输出维度。
- Softmax层:将线性层的输出转换为概率分布,以便进行最终的预测。
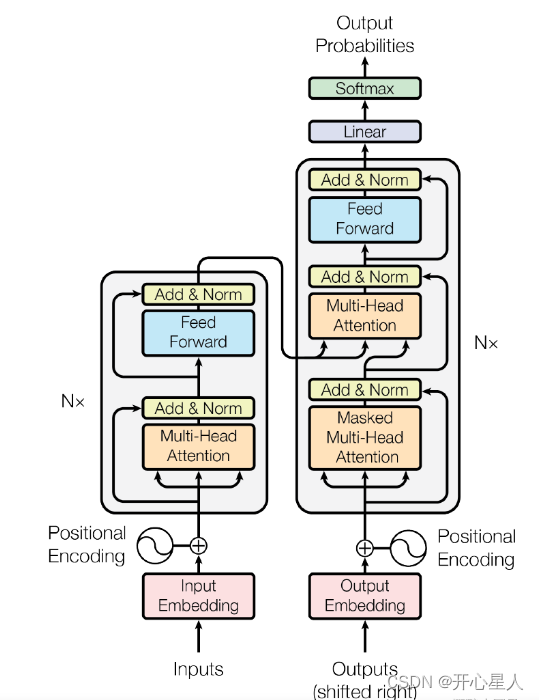
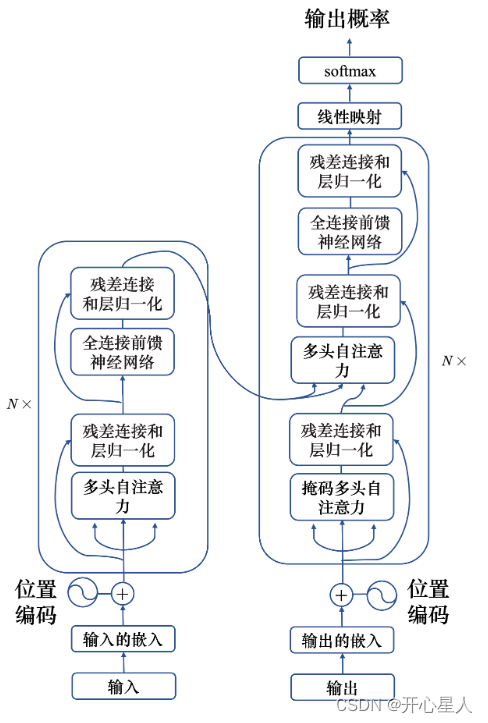
编码器-解码器
左边是N个编码器,右边是N个解码器,Transformer中的N为6。
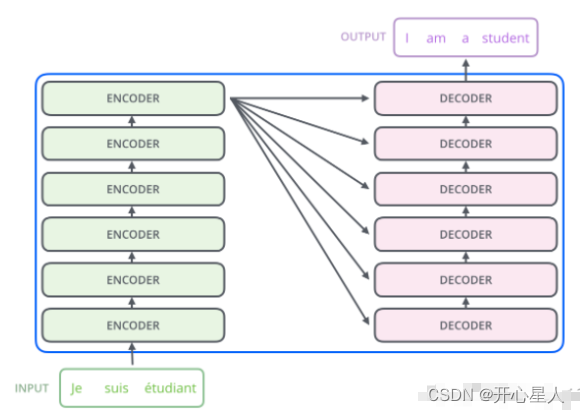
编码器
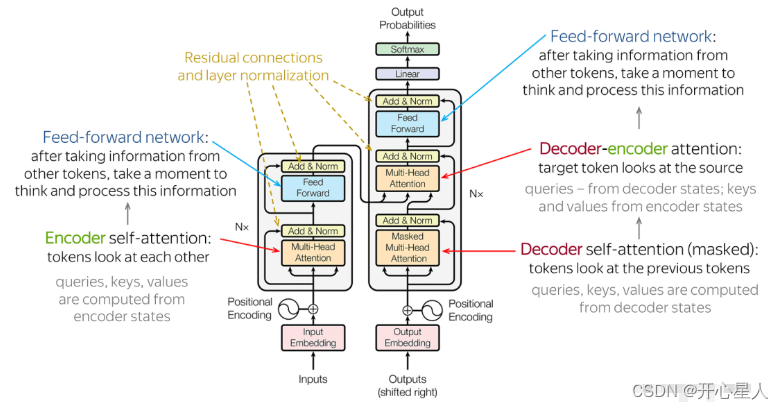
每个编码器层都有两个子层,即多头自注意力层(考虑整个序列的信息)和逐位置的前馈神经网络(Position-wise Feed-Forward Network)。在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为 Add&Norm 操作
残差连接:最左边的向量 b 输入到自注意力层后得到向量 a,输出向量 a 加上其输入向量 b 得到新的输出。
层归一化:层归一化比信念网络更简单,不需要考虑批量的信息,而批量归一化需要考虑批量的信息。层归一化输入一个向量,输出另外一个向量。层归一化会计算输入向量的平均值和标准差。(批量归一化是对不同样本不同特征的同一个维度去计算均值跟标准差,但层归一化是对同一个特征、同一个样本里面不同的维度去计算均值跟标准差,接着做个归一化。)
解码器
每个解码器层都有三个子层,掩码自注意力层 (Masked Self-Attention)、Encoder-Decoder自注意力层、逐位置的前馈神经网络。同样,在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作。
掩蔽自注意力可以通过一个掩码来阻止每个位置选择其后面的输入信息。
原来的自注意力输入一排向量,输出另外一排向量,这一排中每个向量都要看过完整的输入以后才做决定。根据 a1 到 a4 所有的信息去输出 b1。掩蔽自注意力的不同点是不能再看右边的部分。产生 b1 的时候,只能考虑 a1 的信息,不能再
考虑 a2、a3、a4。产生 b2 的时候,只能考虑 a1、a2 的信息,不能再考虑 a3、a4 的信息。
一开始解码器的输出是一个一个产生的,所以是先有 a1 再有 a2,再有 a3,再有a4。这跟原来的自注意力不一样,原来的自注意力 a1 跟 a4 是一次整个输进去模型里面的。编码器是一次把 a1 跟 a4 都整个都读进去。但是对解码器而言,先有 a1 才有a2,才有 a3 才有 a4。所以只能考虑其左边的东西,没有办法考虑其右边的东西。
编码器-解码器注意力
编码器和解码器通过编码器-解码器注意力(encoder-decoder attention)传递信息,编码器-解码器注意力是连接编码器跟解码器之间的桥梁。解码器中编码器-解码器注意力的键和值来自编码器的输出,查询来自解码器中前一个层的输出。