
------->更多内容,请移步"鲁班秘笈"!!<-------
扩散模型在生成高质量图像、视频、声音等方面表现突出。它们与物理学中的自然扩散过程相似而得名,自然扩散过程描述了分子如何从高浓度区域移动到低浓度区域。在机器学习的背景下,扩散模型通过逆转扩散过程来生成新数据。主要的思想是向数据添加随机噪声,然后反过来从噪声数据中推理和获取原始数据。

"是先有雕像,还是先有石头,其实雕像已经早在石头里面!"

Diffusion Model
Diffusion Model(扩散模型)其实理解起来不难,它分为两个过程,正向扩散和逆向扩散。正向扩散过程从基本分布(通常是高斯分布)采样开始生成噪声。选择一幅图片,然后对图片不断地增加噪声,随着噪声不断地增加,最后会变为一个纯噪声图片。可以想象一下较早期收不到信号的电视画面!

每一个噪声都是在前一时刻增加噪声而来。从最开始的x0开始,反复迭代直到最终得到xt的纯噪声图像(中间经历N轮)。因为Diffusion的本质是去噪,为了推导出逆向的去噪方法,采用了很取巧的加噪声的原理。<大白话的意思是,让你在画上乱涂是很容易的,但是让你画出还是有难度的吧!>。
添加噪声的过程的目的其实就是不断构建新的训练样本,因为前一时刻可以预测出来后一时刻的噪声。按照刚才的说法,在第一个过程的扩散中将数据收集起来,用于下面的这个Noise Predicter的模型训练。最终训练出来的模型可以从噪声中恢复(创造)出清晰的图片。
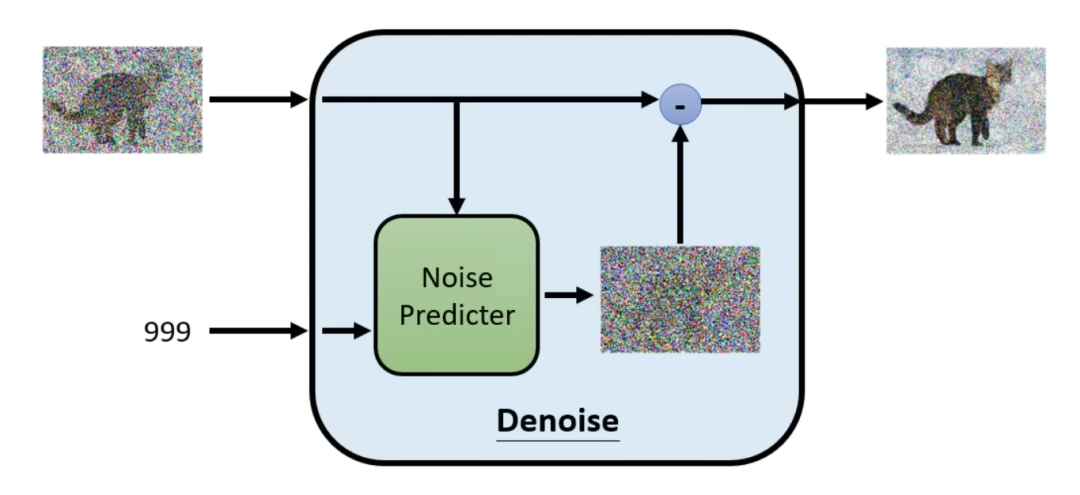
这个模型是一个逆噪声的模型,它用于预测输入图片中在本轮需要去掉的噪声,然后将原图与预测生成的噪声相减,突出下一轮更清晰的图。这个训练过程将刚才正向迭代的数据集作为样本反向训练这个模块(上图蓝色的为输入值,红色的为预测值),读者好好思考下为什么?<说白了就是训练它的去噪声能力!> 是不是很巧妙,也是不是很简单~

当训练完毕再生成图片的时候,就开始要表演魔术了。可以随机生成噪声,然后丢进去Noise Predicter,一轮一轮的去掉噪声,一幅清晰的图片不就展示在读者的眼前。具体的算法如上,在原来的论文中,第0步代表最清晰的图,第N步代表噪声图,一般N是个超参数。可视化过程如下:

那么文绉绉的术语如下:"它逐渐增加了复杂性,通常被可视化为结构化噪声的添加。通过连续变换对初始数据的扩散使模型能够捕获和再现目标分布中固有的复杂模式和细节。前向扩散过程的最终目标是将这些简单的开始演变为紧密模拟所需复杂数据分布的样本。前向扩散过程的最终目标是将这些简单的开始演变为紧密模拟所需复杂数据分布的样本。这确实表明了如何从最少的信息开始可以带来丰富、详细的输出。"
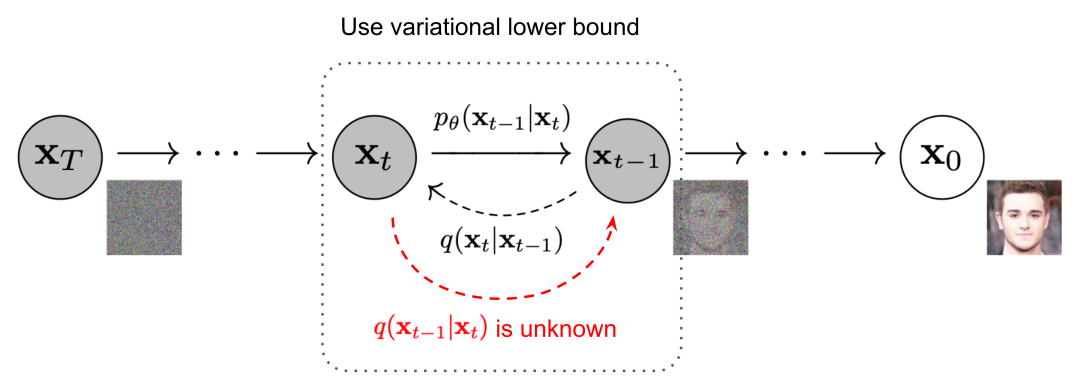
通过缓慢添加(去除)噪声来生成样本的马尔可夫链前向(反向)扩散过程。

文本生成图片
现在的Stable Diffusion、DALL-E、Imagen背后都有比较类似的文本生成图片的架构。抽象出来一般分为三部分:1 文字Embedding(Encoder)、2 文字和图的Diffusion的过程生成具有特定意义的中间向量(Latent Representation)、3 将最终的中间向量丢到解码器(Decoder)进而生成图片。

值得注意的是第2部分的过程也是Diffusion的逆生成过程,将噪声和文本一起输入去噪声模块,不断地重复,值得生成的中间表达向量比较优质,在将中间表达向量丢到解码器生成图片。
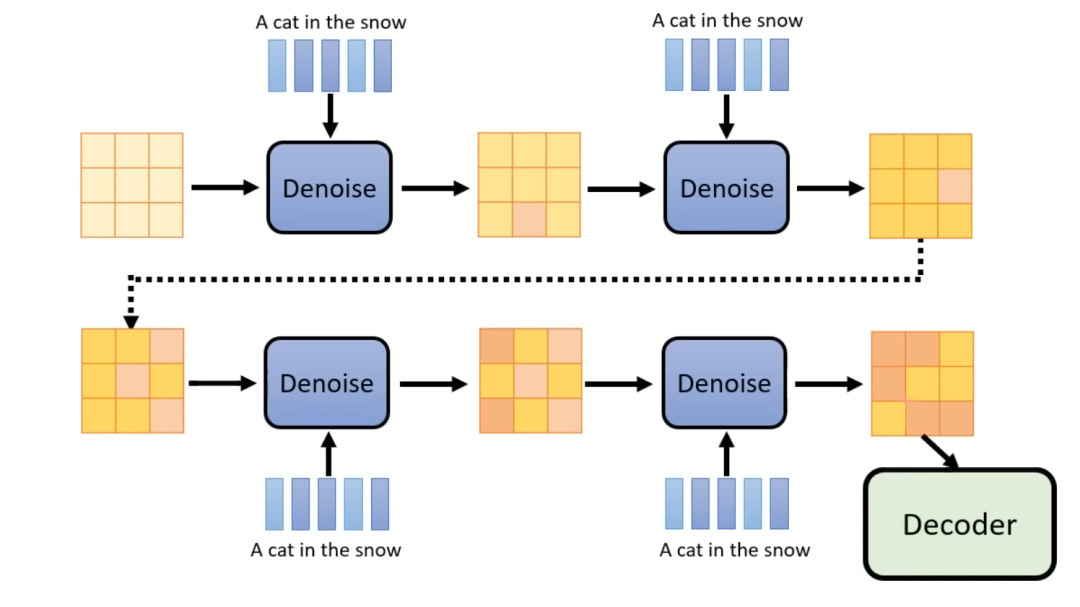
是不是很熟悉的味道和配方,其实类似于自动编解码器。先来看看Stable Diffusion的架构图。

上面的正向扩散,下面是逆向训练过程。Z是原始的图片,Zt是噪声图。读者可以在图中找1,2,3,其实就是从右到左的三个部分。
再来看看DALL-E的模型架构图,这时候的1,2,3则是从左往右。text-encoder就是之前说的1文字编码器,prior就是2中间的Diffusion过程,最后的decoder就是3。

上图虚线上方,描述了CLIP训练过程,通过该过程可以学习文本和图像的联合表示空间。还记得CLIP么,不记得的话点击链接回去温习一下。
虚线下方,描述了文本到图像的生成过程:将CLIP文本嵌入馈送到自回归或扩散prior以生成图像嵌入,然后使用此嵌入来调节扩散解码器,从而生成最终图像。值得一提的是,在prior和解码器的训练期间,CLIP 模型处于冻结状态。
而22年的Google的Imagen也是类似的架构,从上往下1,2,3。读者可以发现这个图中,第二部分输出的Latent Representation是64*64的图(应该称呼为特征表达向量),最终64*64会经过Decoder(这里也使用了Diffusion Model)生成1024*1024的图片。

相信读者还是会有很多疑问,不着急。先建立起基本的概念,形成初步的认知,后续会循序渐进地带着读者进一步遨游这个领域。