盛夏已至,炎热的七月伊始,DolphinDB 也迎来了版本的更新。此次更新的 3.00.1 与 2.00.13 版本从多个维度进行了优化扩展,进一步深化了 DolphinDB 在机器学习、数据分析等领域的尝试与探索。
为了响应用户日益增长的 AI 运算需求,DolphinDB 引入了向量数据引擎 VectorDB ,以实现海量数据的向量检索,增加了对张量(Tensor) 这一数据结构 和模型推理插件 LibTorch 的支持,集成了高速网络 RDMA 通讯框架 ,满足 AI 训练对大数据的需求。新增了主键存储引擎 ,为 CDC 场景下的实时高负载写入和高频更新提供了保障。自定义分区函数 能够更灵活地适配多样的业务逻辑。新增了多个金融相关函数,进一步助力 FICC 业务拓展。
除此之外,新版本还提升了对标准 SQL 的兼容性、增强了流计算引擎的功能和易用性、同时从内存管理、作业管理和用户管理等方面对数据库进行了升级......
接下来,让我们一起看看本次更新具体包含的功能和特性吧!
3.00.1 版本功能新增
一直以来,极其丰富的函数库都是 DolphinDB 的一大产品亮点。随着版本持续更迭和对业务理解的不断沉淀,DolphinDB 的内置函数已接近 2000 个,成为了用户效能提升的重要工具。我们先来看看,本次版本更新为这一宝库又带来了哪些补强
助力 FICC 业务:新增多个 FICC 相关函数
对冲基金在股票交易中应用金融信号处理技术,但金融时间序列数据具有高度非平稳性。处理这类数据时,常将其表示为线段,以减少不确定性和噪声。线段断点数量 K 是衡量市场趋势变化及交易次数的指标,对制定交易策略、获取超额收益至关重要。因此,最小化给定 K 的全局平方误差,并确定每个线段的最优表示,成为量化交易中判断交易时机的重要方法。
为方便用户实现上述复杂的业务逻辑,DolphinDB 在 3.00.1 与 2.00.13 版本中新增了 piecewiseLinFit 和 pwlfPredict 函数 ,用于拟合分段线性回归函数、根据回归模型对数据进行预测,用户可直接调用函数辅助制定交易策略。
除此之外,新版本中还增加了对下列约束优化函数的支持,可用于 FICC 业务中的曲线拟合。
-
新增 brute 函数,用于通过穷举法在给定范围内最小化一个函数。
-
新增 fminSLSQP 函数,支持使用顺序最小二乘编程方法找到目标函数的最小值。
-
新增 fminNCG 函数,支持使用牛顿共轭梯度法对目标函数进行无约束最小化。
-
新增 fminLBFGSB 函数,支持使用 L-BFGS-B 算法找到目标函数的最小值。
-
新增 fminBFGS 函数,支持使用 BFGS 算法找到目标函数的最小值。
海量数据的向量检索:VectorDB
在搜索引擎和 AI 生成模型等应用场景下,系统需要在庞大的数据集中,以低延迟和高精度完成相似度搜索和推荐任务,这类任务通常涉及到向量数据的存储和查询。
DolphinDB 已经对向量数据的存储提供了支持,但为了满足对海量数据进行近似检索(即向量检索) 的需求, DolphinDB 在 3.00.1 版本中推出了以 TSDB 作为底层存储引擎的向量数据库 VectorDB。
VectorDB 支持功能如下:
-
高效的向量检索:通过对向量数据添加索引,以支持高效的向量相似度查询,显著提高向量检索速度和响应时间。
-
索引持久化:通过将构建好的向量索引与其他二级索引(如 ZoneMap)一起持久化至磁盘,系统重启后只需要从磁盘读取向量索引,即可通过索引进行相似度检索,而无需重新构建索引。
-
混合搜索:混合搜索结合了基于关键字的检索(如 SQL 查询语句中的 where 条件)和向量检索,通过这种结合,混合搜索可以在搜索过程中同时利用向量数据的其他属性来提供更加准确和相关的搜索结果。例如在电商搜索中,用户可以根据品牌、颜色等特定条件和上传图片结合的方式搜索产品。
向量检索技术在检索增强生成(RAG)系统中同样扮演着至关重要的角色,其能够有效地从知识库中找到与查询相关的信息,为生成模型提供丰富的上下文支持。
目前 DolphinDB 正在开发基于大模型的文档检索系统 DolphinDB AI,后续 DolphinDB 计划将向量数据库与该系统结合,以进一步扩展系统知识库,并利用向量检索提供的上下文信息提高生成结果的质量和准确性。
强化深度学习集成:支持 Tensor 数据类型
在机器学习库如 TensorFlow 和 PyTorch 中,Tensor 是一种核心的数据结构,类似于多维数组,是处理数据的基本单位。Tensor 能够表达从一维的向量到多维的矩阵,直至更高维度的数组,这使得它非常适合于各种数据类型的科学计算,包括图像、声音、文本等。
DolphinDB V3.00.1 中新增了对 Tensor 数据类型的支持 。通过函数 tensor ,用户可以在 DolphinDB 中完成向量、矩阵、表等数据形式到 Tensor 数据形式的转换。
此外,DolphinDB 还推出了深度学习模型推理插件 LibTorch 。该插件支持使用 Tensor 数据类型以及 PyTorch 模型进行推理。这意味着用户可以直接在 DolphinDB 的数据库环境内完成数据查询、数据处理和模型预测等操作,无需切换至 Python 环境,从而使深度学习的数据处理与模型训练变得更加便捷灵活。
注:LibTorch 插件目前可以在 3.00.1 版本及以上的 Shark Server(DolphinDB 的 GPU 版本)中通过插件市场进行安装。从 3.00.2 开始,将可以在普通的 DolphinDB Server 中使用。
保障主键唯一性,支持高负载写入:主键存储引擎
企业级的数据分析和指标计算,经常需要将 OLTP 业务数据库中的数据通过 CDC (Change Data Capture) 等方法同步到 DolphinDB 。由于上游的 OLTP 数据库通常设置主键,因此 DolphinDB 接收数据时需要能够保证主键的唯一性 。同时,DolphinDB 需要承受类似 OLTP 的写入负载 ,包括频繁地对数据进行按行更新、插入和删除等操作。为此,DolphinDB 在新版本中推出了主键存储引擎 PKEY (Primary Key Storage Engine),以适应 CDC 场景下实时高负载写入和高频更新的需求。
创建数据库时,在 engine参数上新增引擎名"PKEY",即可创建主键存储引擎,例如:
database("dfs://test", VALUE, 0..10, engine='PKEY')主键引擎支持通过参数 primaryKeys 配置主键,以保证数据的唯一性和完整性,减少查询的去重开销。通过参数 indexes,主键引擎支持在非主键列上配置自定义索引键,从而加速数据查询性能。
灵活应对多样业务逻辑:支持自定义分区函数
在 DolphinDB 当前支持的分区方式中,诸如 RANGE、VALUE、LIST 等固定分区方式可能会遇到分区粒度过大或过小的问题,而 HASH 分区虽然能固定分区粒度,但同类数据在经过哈希处理后可能会分散到不同的分区,不利于查询性能的优化。
为了更灵活地适应多样的业务逻辑,DolphinDB 希望为用户提供一个根据自定义规则进行数据分区的方案。譬如利用前缀函数对交易所的期货和期权合约数据进行分区,或者利用前缀函数对物联网指标 id 进行分区。又譬如经常可以从一些编码中抽取日期和时间信息用于数据分区。
因此,在DolphinDB 的新版本中,createPartitionedTable 函数和 create 语句的 partitionColumns参数支持为分区列指定函数,以对分区列的数据进行转换。
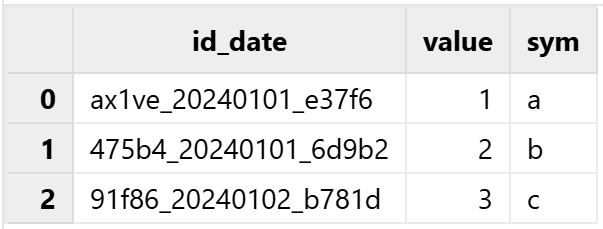
例如,对于格式为 id_date_id 的分区列数据(如 ax1ve_20240101_e37f6, 91f86_20240102_b781d),如果用户期望根据其中的日期进行分区,那么在数据写入时,就可以通过调用分区函数,从原始数据中提取出日期作为分区依据:
// 首先定义处理分区列数据(形如如"id_date_id")的函数
def myPartitionFunc(str,a,b) {
return temporalParse(substr(str, a, b),"yyyyMMdd")
}
// 生成分区列数据,并建库
data = ["ax1ve_20240101_e37f6", "475b4_20240101_6d9b2", "91f86_20240102_b781d"]
tb = table(data as id_date, 1..3 as value, `a`b`c as sym)
db = database("dfs://partitonFunc", VALUE, 2024.02.01..2024.02.02)
// 使用 myPartitionFunc 函数对分区列的数据进行处理
pt = db.createPartitionedTable(table=tb, tableName=`pt,
partitionColumns=["myPartitionFunc(id_date, 6, 8)"])
pt.append!(tb)
// 查询数据
select * from pt最后得到按日期分区的查询结果:
网卡利用率提升:支持高速网络 RDMA 框架
RDMA(远程直接内存访问)意味着一台设备可以直接操控另外一台设备的内存,而无需后者操作系统的介入。这种通信方式具备零拷贝、内核旁路、协议栈卸载 等优势,不再需要在应用程序内存与操作系统缓冲区之间复制数据,从而降低了延迟并实现了快速的消息传输。
DolphinDB 的 3.00.1 版本中对网络模块进行了优化,如果你的网络设备支持 RDMA,只需通过配置项 enableRDMA,即可启用 RDMA 全新通讯架构 。同时,与 Linux 提供的 IPoIB 相比,DolphinDB 的网卡利用率实现了约两倍的性能提升。
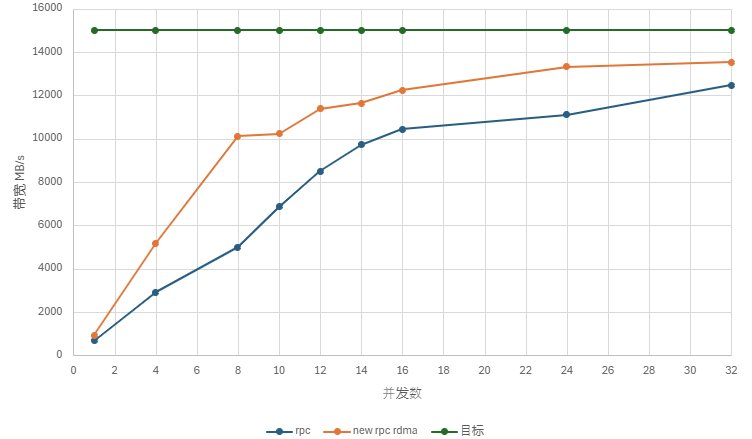
目前,DolphinDB的优化主要集中在网络模块,但仍有相当一部分开销来源于序列化和反序列化过程,以及无法完全避免的内存拷贝。未来,DolphinDB将致力于深度优化序列化部分,以期真正实现零拷贝。
3.00.1 & 2.00.13 升级功能一览
除以上重点新功能外,本次版本更新同样为 SQL 语法、流数据功能、数据库使用体验、数据分析能力、运维管理功能等方面带来了优化提升。
SQL 兼容性增强
语法方面,本次版本更新进一步提升了对标准 SQL 的兼容性,并增强了易用性,具体表现为:
-
SQL DELETE 语句和 sqlDelete 函数支持通过 join 来指定删除行。
-
分布式表增加对 insert into 语句的支持,同时支持使用 insert into 语句单行/批量写入数据。
-
新增函数 setTableComment,用于为分布式表添加表注释。
性能方面的具体改进为:
-
优化了基于规则的优化器的实现,增强了对谓词下推的支持。
-
提升了多表 join 的性能。
流数据功能拓展
新版本对流计算引擎的功能和易用性进行了增强,包括 metrics 所支持的函数/表达式、窗口计算触发方式、乱序处理方式等,尤其对响应式状态引擎进行了多项优化。
响应式状态引擎 reactiveStateEngine:
-
支持对 array vector 列使用 prev 函数。
-
新增对例如 cumTopN、tmTopN 等 35 个 topN 状态函数的支持。
流计算引擎的 metrics 支持常数列 :createReactiveStateEngine, createAsofJoinEngine 等流计算引擎的 metrics支持指定为常数标量或向量。
窗口触发 :createOrderBookSnapshotEngine 新增参数 useSystemTime,支持使用系统时间来触发快照输出。
乱序处理:时序聚合引擎 TimeSeriesEngine 支持基于数据窗口关闭时间支持设置延时,以处理乱序数据。
数据库使用体验优化
chimp 是一种高效的压缩/解压 double 类型的压缩算法,若浮点数的小数部分仅为三位以内,则 chimp 的压缩率会非常高。DolphinDB 新版本中增加了对 chimp 压缩算法的支持,例如在 createPartitionedTable 和 createTable 时,为 double 类型的列指定 chimp 压缩算法:
login("admin", "123456")db = database("dfs://test", HASH, [INT, 20], engine="TSDB")t = table(1..10 as id, rand(1.0, 10) as val)pt = db.createPartitionedTable(table=t, tableName=`pt, partitionColumns=`id, compressMethods={"val" : "chimp"}, sortColumns=`id)pt.append!(t)在之前版本中,TSDB 存储引擎第 3 层的 Level File 不会再进行 Compaction。如果数据量较大的情况下, Compaction 比较频繁,可能会导致 Level 3 的 Level File 过多,存在冗余数据,导致查询性能下降。新版本中,我们引入了 Level 3 Compaction 的功能 ,以及 Level 4 的概念 ,允许 Level 3 和 Level 4 的 Level File 同时参与 Compaction,从而改善了查询性能。
数据分析能力更强大
新版本从编程语言、函数和远程计算三方面,对产品的数据分析能力进行了扩展与加持。
编程语言方面:
-
新增支持三元运算符
?,可以保证便捷而又高效的条件分支执行。 -
拓展了函数对 BLOB 数据类型的支持性,如 isDuplicated 函数支持 BLOB 类型的去重,parseJsonTable 函数支持 BLOB 字段的解析。
-
JIT 支持处理矩阵索引,可通过 column、columns、row、rows 函数获取矩阵切片。
函数方面:
-
新增支持时间序列模型函数 vectorAR。
-
提高函数 std、stdp、var、varp、skew、kurtosis 的计算精度。
-
拓展 interval 函数对交易日历的支持。
远程计算方面:
新增函数 remoteRunCompatible。remoteRunCompatible 函数与 remoteRun 函数的功能相同,但 remoteRunCompatible 函数对本地和远程数据库的版本不做限制。
运维管理功能强化
新版本从内存管理、作业管理、用户管理等方面对数据库进行了升级,为用户的使用体验保驾护航。
内存管理层面:clearAllCache 函数新增支持清理 TSDB 引擎相关的缓存。
作业管理层面:
-
新增配置项 jobLogRetentionTime,用于定时删除作业的输出和返回值。
-
scheduleJob 新增参数 priority 和 parallelism,用于设置定时任务的优先级和并行度。
**用户管理层面:**拓展支持对计算节点上用户级别的资源使用情况进行采样,以及查询分布式表操作的功能。
除此之外,新版本还进行了如下优化:
-
拓展了 version 函数返回的版本信息,以便用户进行版本定位。
-
增强了集群间异步复制的安全性,通过内部身份认证的用户无需明文指定用户密码。
同时,新版本还从插件层面新增了配置项 pluginServerAddr,用于配置插件仓库地址,以便下载提速和团队共享。
未完待续......
接下来的版本中,DolphinDB 将会推出的重点功能如下:
-
支持存算分离 ,可以弹性地伸缩计算节点组,为计算节点增加数据缓存能力。支持外部分区表,用户可直接加载外部数据文件如 Parquet,进行 SQL 查询和数据分析。
-
支持 TextDB,增加倒排索引,可以直接在数据库内对文本字段进行高效检索。
-
引入物联网点位管理引擎,窄表模式下支持 ANY 数据类型。
-
支持多集群监控和运维。
-
为嵌入式版本 Swordfish 增加 Python 和 Java 接口。
-
提升 AI DataLoader 性能,与 AI 的结合更加丝滑。
-
进一步提升 SQL 引擎多表关联的性能。
-
回测引擎引入 Class 机制,并通过 Class JIT 的优化,来提升高频回测性能。