高可用性
故障转移和故障恢复
冗余是很好的技术,但实际上只有在遇到故障需要恢复时才会用到。(见鬼,这可以用备份来实现)。冗余一点儿也不会增加可用性或减少宕机。在故障转移的过程中,高可用性是建立在冗余的基础上。当有一个组件失效,但存在冗余时,可以停止使用发生故障的组件,而使用冗余备件。冗余和故障转移结合可以帮助更快地恢复,如你所知,MTTR(平均恢复时间)的减少将降低宕机时间并改善可用性。在继续这个话题之前,我们先来定义一些术语。我们统一使用"故障转移(failover)",有些人使用"回退(fallback)"来表达同一意思。有时候也有人说"切换(switchover)",以表明一次计划中的切换而不是故障后的应对措施。我们也会使用"故障恢复"来表示故障转移的反面。如果系统拥有故障恢复能力,故障转移就是一个双向过程:当服务器A失效,服务器B代替它,在修复服务器A后可以再替换回来.故障转移比仅仅从故障中恢复更好。也可以针对一些情况制定故障转移计划,例如升级、schema变更、应用修改,或者定期维护,当发生故障时可以根据计划进行故障转移来减少宕机时间(改善可用性)。
你需要确定故障转移到底需要多快,也要知道在一次故障转移后替换一个失效组件应该多快。在你恢复系统耗尽的备件容量之前,会出现冗余不足,并面临额外风险。因此,拥有一个备件并不能消除即时替换失效组件的需求。构建一个新的备用服务器,安装操作系统,并赋值数据的最新副本,可以多快呢?有足够的备用机器码?你可能需要不止一台以上。
故障转移的缘由各不相同。因为负载均衡和故障转移在很多方面很相似,它们之间的分界线比较模糊。总的来说,我们认为一个完全的故障转移解决方案至少能够监控并自动替换组件。它对应用应该是透明的。负载均衡不需要系统这些功能。
在UNIX领域,故障转移常常使用High Availability Linux项目提供的工具来完成,该享目可在许多类UNIX系统上运行,而不仅仅是Linux.Linux-HA栈在最近几年明显多了许多新特性。现在大多数认为Pacemaker是栈中的一个主要组件。Pacemaker替代了老的心跳工具。还有其他一些工具实现了IP托管和负载均衡功能。可以将它们跟DRBD和/或者LVS结合起来使用。
故障转移最重要的部分就是故障恢复。如果服务器间不能自如切换,故障转移就是一个死胡同,只能是延缓宕机时间而已。这也是我们倾向于对称复制布局。例如双主配置,而不会选择使用三台或更多的联合主库(co-master)来进行环形复制的原因。如果配置是对等的,故障转移和故障恢复就是在相反方向上的相同操作。(值得一提的是DRBD具有内建的故障恢复功能)。
在一些应用中,故障转移和故障恢复需要尽量快速并且具备原子性。即便这不是决定性的,不依靠那些不受你控制的东西也依然是个好主意,例如DNS变更或者应用程序配置i文件。一些问题知道系统变得更加庞大时才会显现出来,例如当应用程序强制重启以及原子性需求出现时。
由于负载均衡和故障转移两者联系较紧密,有些硬件和软件是同时为这两个目的设计的,因此我们建议所选择的任何负载均衡技术应该都提供故障转移功能。这也是我们建议避免使用DNS和修改代码来做负载均衡的真实原因。如果为负载均衡采用了这些策略,就需要做一些额外的工作;当需要高可用性时,不得不重写受影响的代码。
提升备库或切换角色
提升一台备库为主库,或者在一个主------主复制结构中调换主动和被动角色,这些都是许多MySQL故障转移策略很重要的一部分。我们不能认定自动化工具总能在所有的情况下做正确地事情。你不应该假定在发生故障时能够立刻切换到被动备库,这要看具体的工作负载。备库会重放主库的写入,但如果不用来提供读操作,就无法进行预热来为生产环境负载提供服务。如果希望有一个随时能承担读负载的备库,就要不断地"训练"它,既可以将其用于分担工作负载,也可以将生产环境地读查询镜像到备库上。我们有时候通过监听TCP流量,截取除其中地SELECT查询,然后在备库上重放来实现这个目的。Percona Toolkit中有一些工具可以做到这一点。
虚拟IP地址或IP接管
可以为需要提供特定服务的MySQL实例指定一个逻辑IP地址。当MySQL实例失效时,可以将IP地址转移到另一台MySQL服务器上。这和前面提到的思想本质是相同的,唯一的不同是现在是用于故障转移,而不是负载均衡。
这种方法的好处是对应用透明。它会中断已有的连接,但不要求修改配置。有时候还可以原子地转移IP地址,保证所有的应用在同一时间看到这一变更。当服务器在可用和不可用状态间"摇摆"时,这一点尤其重要。以下是它的一些不足之处:
- 1.需要把所有的IP地址定义在同一网段,或者使用网络桥接
- 2.改变IP地址需要系统root权限
- 3.有时候还需要更新ARP缓存。有些网络设备可能会把ARP信息保存太久,以致无法即时将一个IP地址切换到另一个MAC地址上。我们看到过很多网络设备或其他组件不配合切换的例子,结果系统的许多部分可能无法确定IP地址到底在哪里
- 4.需要确定网络硬件支持快速IP接管。有些硬件需要克隆MAC地址后才能工作
- 5.有些服务器即使完全丧失功能也会保持持有IP地址,所以可能需要从物理上关闭或断开网络连接。这就是为人所熟知的"击中其他节点的头部"(shoot the other node in the head 简称STONITH).他还有一个更加微妙并且比较官方的名字:击剑(fencing)
浮动IP地址和IP接管能够很好地应付彼此临近(也就是同一子网内)的机器之间的故障转移。但是最后需要提醒的是,这种策略并不总是万无一失,还取决于网络硬件等因素
中间件解决方案
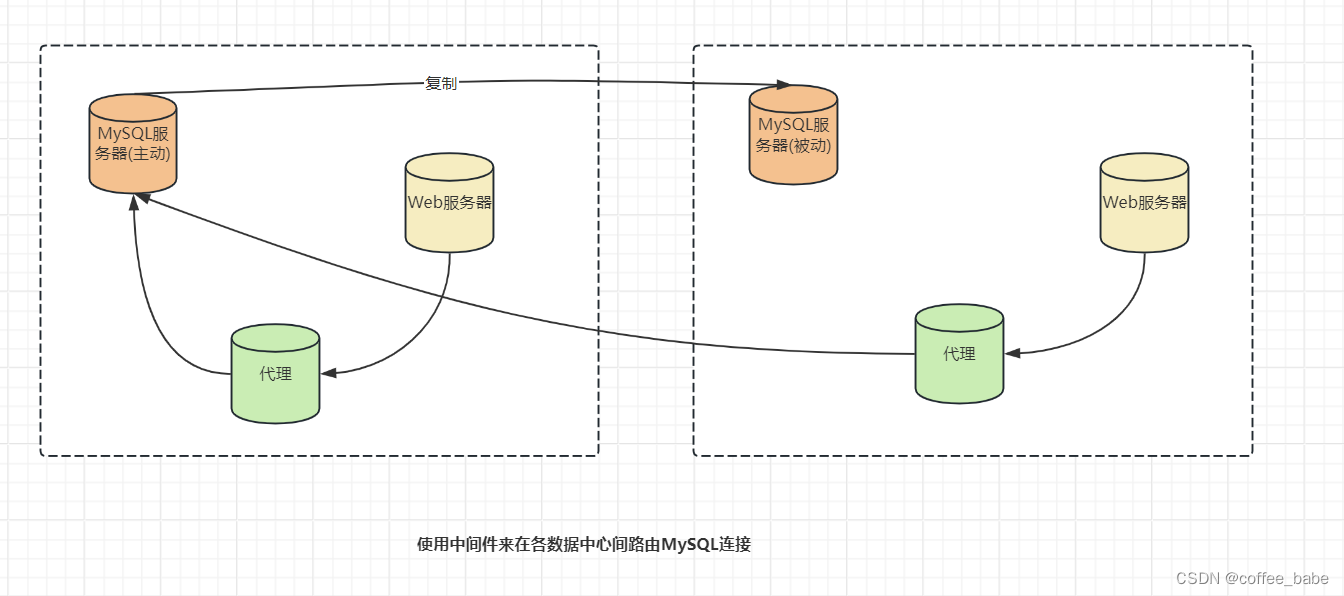
可以使用代理、端口转发、网络地址转换(NAT)或者硬件负载均衡来实现故障转移和故障恢复。这些都是很好的解决方法,不像其他方法可能会引入一些不确定性(所有系统组件认同哪一个是主库码?它能够即使并原子地更改吗?)它们是控制应用和服务器连接的中枢。但是,它们自身也引入了单点失效,需要准备冗余来避免这个问题。
使用这样的解决方案,你可以将一个远程数据中心设置成看起来好像和应用在同一个网络里。这样就可以使用诸如浮动IP地址这样的技术让应用和一个完全不同的数据中心开始通信。你可以配置每个数据中心的每台应用服务器,通过它自己的中间件连接,将流量路由到活跃数据中心的机器上,如图所示。
如果活跃数据中心安装的MySQL彻底崩溃了,中间件可以路由流量到另外一个数据中心的服务器池中,应用无须知道这个变化。
这种配置方法的主要缺点是在一个数据中心的Apache服务器和另外一个数据中心的MySQL服务器之间的延迟比较大。为了缓和这个问题,可以把Web服务器设置重定向模式。这样通信都会被重定向到放置活跃MySQL服务器的数据中心。还可以使用HTTP代理来实现这一目标。如图显示了如何使用代理来连接MySQL服务器,也可以将这个方法和许多别的中间件架构结合在一起,例如LVS和硬件负载均衡器