实验背景
利用文本挖掘技术对哈利波特系列书籍进行情感分析,旨在探索这些书籍中情感的分布和变化。通过使用tidyverse、tidytext和harrypotter等R语言包,可以提取并分析书籍中的情感词汇。
数据准备
首先从harrypotter包中加载哈利波特系列的七本书,并将其分别存储在一个列表中。然后,将每本书的文本按章节拆分,并进一步拆分为单词。最后,将所有书籍的数据合并到一个名为series的表格中。
R
library(tidyverse)
library(stringr)
library(tidytext)
library(harrypotter)
library(textdata)
titles <- c("Philosopher's Stone", "Chamber of Secrets", "Prisoner of Azkaban",
"Goblet of Fire", "Order of the Phoenix", "Half-Blood Prince",
"Deathly Hallows")
books <- list(philosophers_stone, chamber_of_secrets, prisoner_of_azkaban,
goblet_of_fire, order_of_the_phoenix, half_blood_prince,
deathly_hallows)
series <- tibble()
for(i in seq_along(titles)) {
clean <- tibble(chapter = seq_along(books[[i]]),
text = books[[i]]) %>%
unnest_tokens(word, text) %>%
mutate(book = titles[i]) %>%
select(book, everything())
series <- rbind(series, clean)
}
series$book <- factor(series$book, levels = rev(titles))> series# A tibble: 1,089,427 × 3
book chapter word
<fct> <int> <chr>
1 Philosopher's Stone 1 the
2 Philosopher's Stone 1 boy
3 Philosopher's Stone 1 who
4 Philosopher's Stone 1 lived
5 Philosopher's Stone 1 mr
6 Philosopher's Stone 1 and
7 Philosopher's Stone 1 mrs
8 Philosopher's Stone 1 dursley
9 Philosopher's Stone 1 of
10 Philosopher's Stone 1 number
# ℹ 1,089,417 more rows
# ℹ Use `print(n = ...)` to see more rows情感词汇表
使用tidytext包提供的情感词汇表,包括bing、nrc和afinn。这些词汇表将单词与相应的情感分数或情感类别(如积极、消极等)关联起来。
R
get_sentiments("bing")
get_sentiments("nrc")
get_sentiments("afinn")数据分析
首先统计了每种情感在书中的出现次数。
R
series %>%
right_join(get_sentiments("nrc")) %>%
filter(!is.na(sentiment)) %>%
count(sentiment, sort = TRUE)结果显示,消极情感出现次数最多,其次是积极、悲伤和愤怒等情感。
# A tibble: 10 × 2
sentiment n
<chr> <int>
1 negative 55096
2 positive 37767
3 sadness 34883
4 anger 32747
5 trust 23160
6 fear 21536
7 anticipation 20629
8 joy 13804
9 disgust 12861
10 surprise 12818情感随书籍的变化
我们还分析了每本书中每500个单词的情感变化,使用bing和nrc词汇表。
R
series %>%
group_by(book) %>%
mutate(word_count = 1:n(),
index = word_count %/% 500 + 1) %>%
inner_join(get_sentiments("bing")) %>%
count(book, index = index , sentiment) %>%
ungroup() %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative,
book = factor(book, levels = titles)) %>%
ggplot(aes(index, sentiment, fill = book)) +
geom_bar(alpha = 0.5, stat = "identity", show.legend = FALSE) +
facet_wrap(~ book, ncol = 2, scales = "free_x")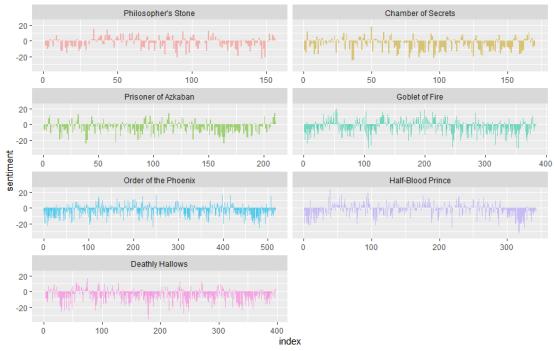
图表显示了每本书中情感分数的变化趋势。我们可以看到,每本书中都有情感波动,显示出故事情节的起伏。
AFINN词汇表为每个单词分配一个情感值,我对这些情感值进行了汇总。
R
afinn <- series %>%
group_by(book) %>%
mutate(word_count = 1:n(),
index = word_count %/% 500 + 1) %>%
inner_join(get_sentiments("afinn")) %>%
group_by(book, index) %>%
summarise(sentiment = sum(value)) %>%
mutate(method = "AFINN")综合使用bing和nrc词汇表进行情感分析,并将结果可视化。
R
bing_and_nrc <- bind_rows(series %>%
group_by(book) %>%
mutate(word_count = 1:n(),
index = word_count %/% 500 + 1) %>%
inner_join(get_sentiments("bing")) %>%
mutate(method = "Bing"),
series %>%
group_by(book) %>%
mutate(word_count = 1:n(),
index = word_count %/% 500 + 1) %>%
inner_join(get_sentiments("nrc") %>%
filter(sentiment %in% c("positive", "negative"))) %>%
mutate(method = "NRC")) %>%
count(book, method, index = index , sentiment) %>%
ungroup() %>%
spread(sentiment, n, fill = 0) %>%
mutate(sentiment = positive - negative) %>%
select(book, index, method, sentiment)
bind_rows(afinn,
bing_and_nrc) %>%
ungroup() %>%
mutate(book = factor(book, levels = titles)) %>%
ggplot(aes(index, sentiment, fill = method)) +
geom_bar(alpha = 0.8, stat = "identity", show.legend = FALSE) +
facet_grid(book ~ method)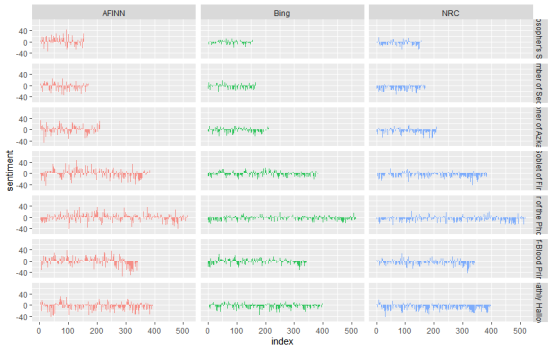
我还分析了哪些词汇对情感贡献最大。
R
bing_word_counts <- series %>%
inner_join(get_sentiments("bing")) %>%
count(word, sentiment, sort = TRUE) %>%
ungroup()
bing_word_counts %>%
group_by(sentiment) %>%
top_n(10) %>%
ggplot(aes(reorder(word, n), n, fill = sentiment)) +
geom_bar(alpha = 0.8, stat = "identity", show.legend = FALSE) +
facet_wrap(~sentiment, scales = "free_y") +
labs(y = "Contribution to sentiment", x = NULL) +
coord_flip()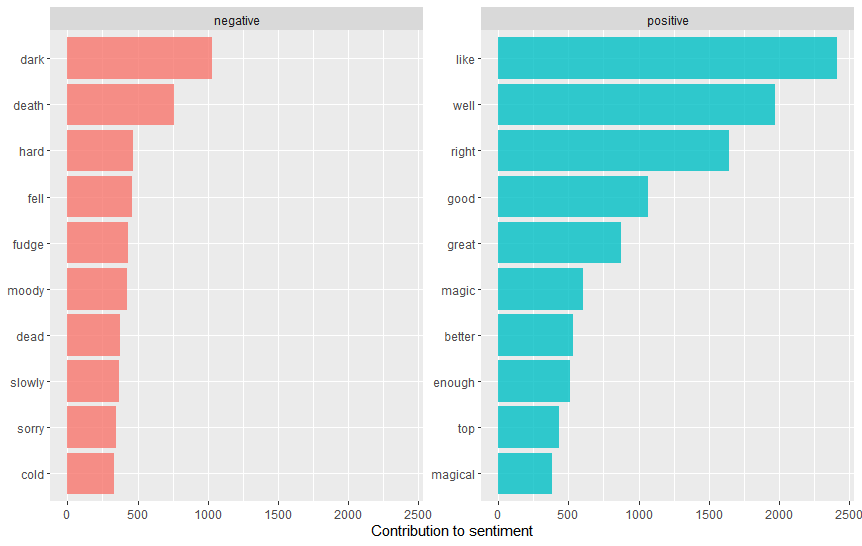
章节分析
对《哈利波特与魔法石》进行了更细致的分析,将文本按句子拆分并计算每个章节的情感分数。
R
ps_sentences <- tibble(chapter = 1:length(philosophers_stone),
text = philosophers_stone) %>%
unnest_tokens(sentence, text, token = "sentences")
book_sent <- ps_sentences %>%
group_by(chapter) %>%
mutate(sentence_num = 1:n()) %>%
ungroup() %>%
mutate(index = round(sentence_num / n(), 2)) %>%
unnest_tokens(word, sentence) %>%
inner_join(get_sentiments("afinn")) %>%
group_by(chapter, index) %>%
summarise(sentiment = sum(value, na.rm = TRUE)) %>%
arrange(desc(sentiment))
ggplot(book_sent, aes(index, factor(chapter, levels = sort(unique(chapter), decreasing = TRUE)), fill = sentiment)) +
geom_tile(color = "white") +
scale_fill_gradient2() +
scale_x_continuous(labels = scales::percent, expand = c(0, 0)) +
scale_y_discrete(expand = c(0, 0)) +
labs(x = "Chapter Progression", y = "Chapter") +
ggtitle("Sentiment of Harry Potter and the Philosopher's Stone",
subtitle = "Summary of the net sentiment score as you progress through each chapter") +
theme_minimal() +
theme(panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
legend.position = "top")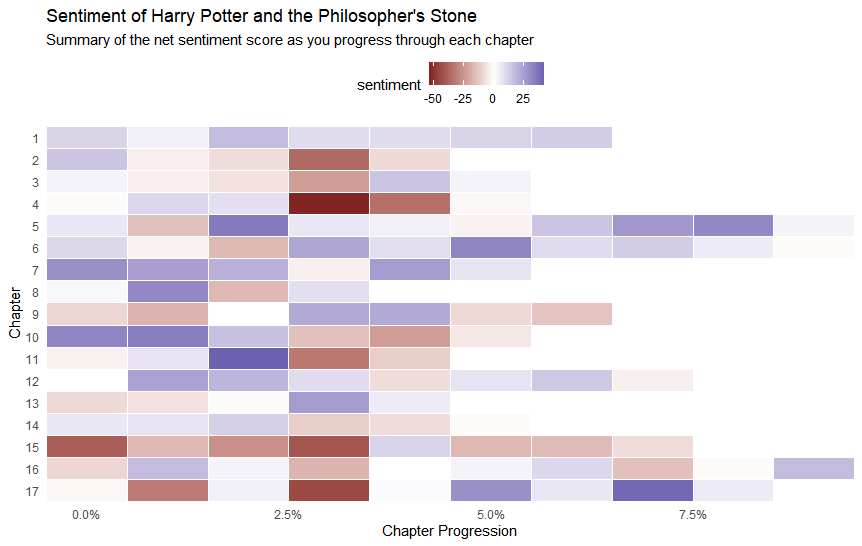
实验结论
通过以上分析,可以得出以下结论:
- 哈利波特系列书籍中消极情感词汇出现次数较多,显示了故事中的冲突和挑战。
- 每本书中的情感分布存在明显的波动,这与故事情节的发展紧密相关。
- 不同情感词汇表(如
bing、nrc和afinn)的分析结果存在差异,这反映了不同词汇表在情感分析中的适用性。