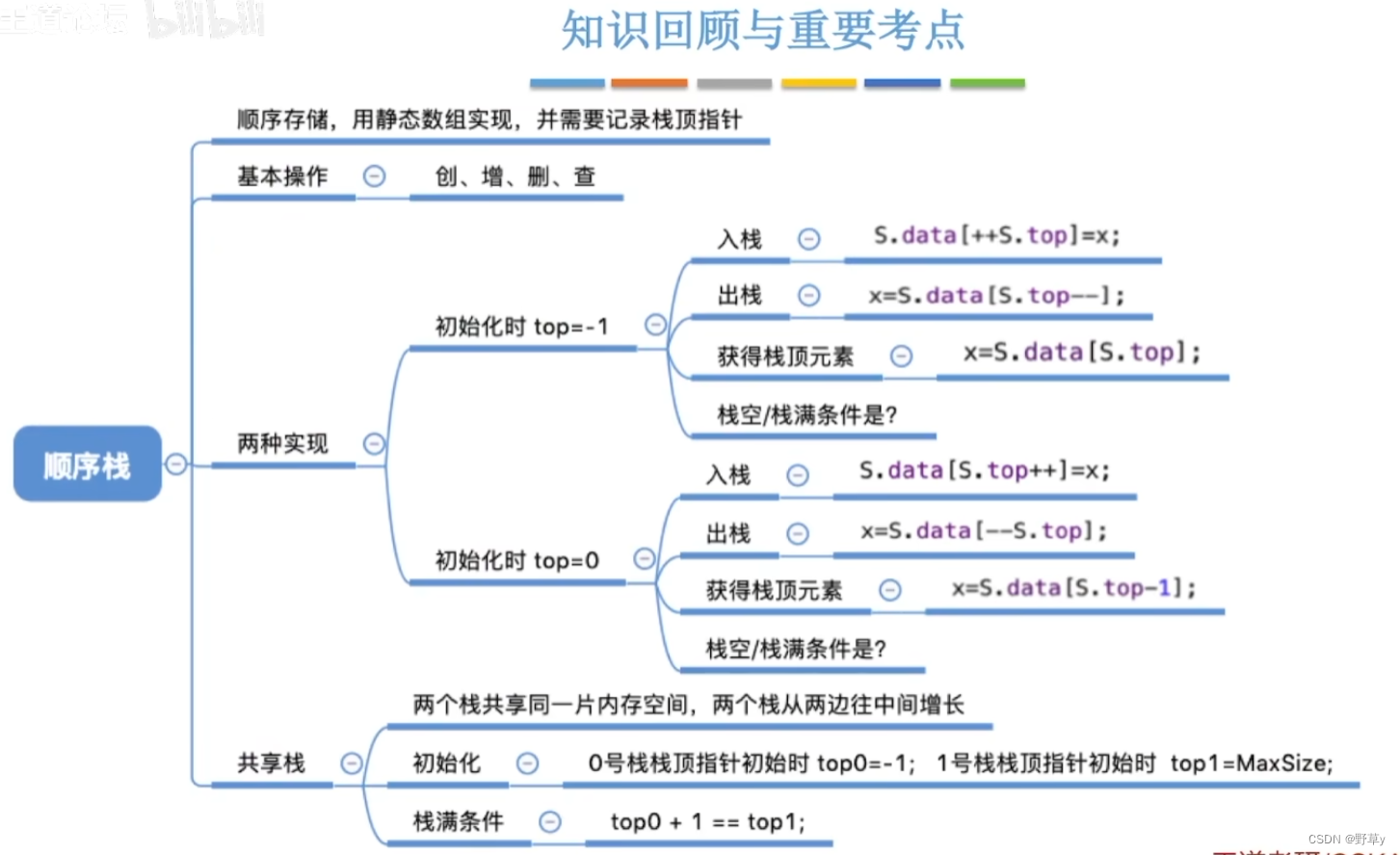
顺序栈的定义
cs
#define MaxSize 10//定义栈中元素的最大个数
typedef struct {
int data[MaxSize];//静态数组存放栈中元素
int top;//栈顶指针
} SqStack;初始化操作
cs
#define MaxSize 10//定义栈中元素的最大个数
typedef struct {
int data[MaxSize];//静态数组存放栈中元素
int top;//栈顶指针
} SqStack;
//初始化栈
void InitStack(SqStack& S) {
s.top = -1;//初始化栈顶指针
}
void testStack() {
SqStack S;//声明一个顺序栈(分配空间)
InitStack(S);
}为什么top指针初始化要指向-1
具体来说,有以下几点原因:
-
空栈的表示: 初始时,栈中没有元素,将栈顶指针设置为-1可以清楚地表示栈是空的。因为数组下标通常是从0开始的,所以-1不可能是任何有效元素的数组下标。
-
简化入栈操作: 当第一个元素入栈时,可以直接将栈顶指针加1,然后将元素放入数组下标为0的位置。如果栈顶指针初始为0,那么在第一个元素入栈时,就需要先减1再赋值,这样的逻辑处理相对复杂。
-
统一性: 初始化为-1可以使得入栈(push)和出栈(pop)操作统一。无论是入栈还是出栈,都可以通过修改栈顶指针的值来实现,即指针的增减。
-
防止数组越界: 当栈满时,如果继续进行入栈操作而没有检查,可能会导致数组越界。如果栈顶指针初始化为-1,那么在入栈操作之前,可以先检查栈顶指针是否等于数组长度减1,以避免越界。
-
编程习惯: 在很多编程语言和教科书中,初始化栈顶指针为-1已经成为一种标准做法,这样做可以使得代码更容易被其他程序员理解和维护。

因此根据栈的初始化指向-1的逻辑可以判断栈的判空代码也是指向-1
cpp
//判断栈空
bool StackEmpty(SqStack S) {
if (S.top == 1){//栈空
return true;
}else { //不空
return false;
}
}进栈操作
栈的入栈操作,也称为压栈或推栈,是指将一个新元素放入栈顶的过程。在栈这种数据结构中,入栈操作同样遵循后进先出(Last In, First Out, LIFO)的原则,即最后进入栈的元素将是最先被移除的。
下面是入栈操作的基本步骤:
-
检查栈是否已满: 在进行入栈操作之前,首先需要检查栈是否有足够的空间来容纳新元素。如果栈已满,那么入栈操作不能进行,通常会返回一个错误或者特殊值。
-
移动栈顶指针: 如果栈有空闲空间,那么首先需要将栈顶指针向上移动一位,以指向新的栈顶位置。在数组实现的栈中,这通常意味着栈顶指针加1。
-
将新元素放入栈顶: 在移动栈顶指针之后,可以将新元素放入栈顶位置。在实际的实现中,通常是通过数组下标来访问和更新栈顶元素。
-
操作完成: 入栈操作完成后,新的元素就成为了栈顶元素,等待后续的出栈操作或其他操作。
入栈操作的时间复杂度通常是O(1),因为无论栈中有多少元素,入栈操作都只涉及到栈顶指针的更新和新元素的插入,这些操作都是常数时间的。
cpp
//新元素入栈
bool Push(SqStack& S, int x) {
if (S.top == MaxSize - 1) {//栈满,报错
return false;
}else {
//等价S.data[++S.top]=x;
S.top = S.top + 1;//指针先加1
S.data[S.top] = x;//新元素入栈;
return true;
}
}-
函数参数: 函数接受两个参数,一个是引用类型的
SqStack对象S,表示栈结构;另一个是int类型的变量x,表示要入栈的新元素。 -
栈满判断: 函数首先检查栈是否已满。这是通过比较栈顶指针
S.top和最大容量MaxSize - 1来实现的。如果栈顶指针等于MaxSize - 1,则表示栈已满,无法再添加新元素,函数返回false。 -
移动栈顶指针: 如果栈不满,先将栈顶指针
S.top向上移动一位,即加1。这样,S.top指向了新的栈顶位置。 -
新元素入栈: 将新元素
x放入数组S.data中下标为S.top的位置,完成入栈操作。 -
函数返回值: 如果入栈操作成功,函数返回
true。
代码中的注释提到了一种等价的表达方式S.data[++S.top]=x;,这种写法是先将栈顶指针S.top加1,然后将新元素x放入加1后的位置。这种写法更加简洁,但效果是一样的。
在实际使用中,MaxSize应该是一个已经定义好的常量,代表栈数组S.data的最大容量。S.top是栈顶指针,它在初始时应该设置为-1,这样当栈为空时,S.top的值就是-1;当栈中有元素时,S.top的值就是最后一个元素的数组下标。
出栈操作
栈的出栈操作,也称为弹出操作,是指从栈中移除最顶层元素的过程。在栈这种数据结构中,出栈操作遵循后进先出(Last In, First Out, LIFO)的原则,即最后进入栈的元素最先被移除。
下面是出栈操作的基本步骤:
-
检查栈是否为空: 在进行出栈操作之前,首先需要检查栈是否为空。如果栈为空,即没有元素可以移除,那么出栈操作不能进行,通常会返回一个错误或者特殊值。
-
获取栈顶元素: 如果栈不为空,那么可以获取栈顶元素的值。在实际的实现中,通常是通过栈顶指针来访问栈顶元素。
-
更新栈顶指针: 在获取了栈顶元素的值之后,需要将栈顶指针向下移动一位,以反映栈顶元素已经被移除。在数组实现的栈中,这通常意味着栈顶指针减1。
-
返回栈顶元素: 最后,将获取到的栈顶元素的值返回给调用者,或者将其存储在指定的变量中。
出栈操作的时间复杂度通常是O(1),因为无论栈中有多少元素,出栈操作都只涉及到栈顶元素的移除和栈顶指针的更新,这些操作都是常数时间的。
cpp
//出栈操作
bool Pop(SqStack& S, int& x) {
if (S.top == -1){//栈空
return false;
}else { //不空
x = S.data[S.top];//栈顶元素先出栈
S.top = S.top - 1;//指针再减1
return true;
}
}-
函数参数: 函数接受两个参数,一个是引用类型的
SqStack对象S,表示栈结构;另一个是引用类型的int变量x,用于存储出栈元素的值。 -
栈空判断: 函数首先检查栈是否为空。由于栈顶指针
S.top在初始化时设置为-1,因此当S.top == -1时,表示栈中没有元素,即栈为空。如果栈为空,函数返回false,表示出栈操作失败。 -
出栈操作: 如果栈不为空,函数将栈顶元素的值赋给变量
x。这是通过访问数组S.data中下标为S.top的元素来实现的。 -
更新栈顶指针: 在弹出栈顶元素后,需要将栈顶指针
S.top向下移动一位,即减1。这样,原来的栈顶元素就被"移出"了栈,新的栈顶元素现在是原来栈顶元素的下一个元素。 -
函数返回值: 如果出栈操作成功,函数返回
true。
这个函数的实现是正确的,它遵循了栈的后进先出(LIFO)原则。当调用这个函数时,它会从栈顶移除一个元素,并且调用者可以通过参数x获取到这个元素的值。如果栈为空,则不会进行任何操作,并返回false。
读取栈顶元素的操作
cpp
//读栈操作
bool GetTop(SqStack& S, int& x) {
if (S.top == -1) {//栈空
return false;
}
else { //不空
x = S.data[S.top];//栈顶元素先出栈
return true;
}
}共享栈 (两个栈共享一片空间)
共享栈是一种特殊的栈实现方式,它允许两个栈共享同一片连续的内存空间。这种设计可以有效地利用内存,尤其是在两个栈的大小变化不均匀时,可以避免一个栈已满而另一个栈还有很多空闲空间的情况。
共享栈通常是这样实现的:假设有一个数组data,用来存储两个栈的所有元素。栈1的元素从数组的开始位置向中间增长,而栈2的元素从数组的末尾位置向中间增长。两个栈的顶部指针(记为top1和top2)分别指向它们下一个元素应该存储的位置。当top1 + 1 = top2时,表示栈空间已满,不能再进行入栈操作。
以下是共享栈的基本特点和操作:
-
内存共享: 两个栈使用同一个数组,分别从数组的两端向中间增长。
-
栈满条件: 当两个栈的顶部指针相遇时,即
top1 + 1 = top2时,栈满。 -
入栈操作: 对于栈1,先检查
top1 + 1 != top2,然后将元素放入data[top1++];对于栈2,先检查top1 != top2 - 1,然后将元素放入data[top2--]。 -
出栈操作: 对于栈1,先检查
top1 != -1,然后top1--;对于栈2,先检查top2 != data.length,然后top2++。 -
栈空条件: 栈1为空当且仅当
top1 = -1;栈2为空当且仅当top2 = data.length。
共享栈的优点在于它能够根据需要动态地调整两个栈的大小,从而提高内存的使用效率。但是,它也有局限性,比如需要额外的逻辑来处理栈满的情况,以及可能出现的内存碎片问题。此外,由于两个栈共享同一片内存,如果一个栈的内容变化非常频繁,可能会影响另一个栈的性能。
cpp
#define MaxSize 10 // 定义栈中元素的最大个数
typedef struct {
int data[MaxSize]; // 静态数组存放栈中元素
int top0; // 0号栈栈顶指针
int top1; // 1号栈栈顶指针
} ShStack;
void InitStack(ShStack& S) {
S.top0 = -1; // 初始化0号栈栈顶指针
S.top1 = MaxSize; // 初始化1号栈栈顶指针
}它定义了一个共享栈的结构体ShStack,其中包含一个静态数组data用于存储栈中的元素,以及两个栈顶指针top0和top1用于分别表示两个栈的栈顶位置。
在初始化函数InitStack中,您正确地初始化了ShStack类型的栈S。top0被初始化为-1,表示0号栈当前为空,top1被初始化为MaxSize,表示1号栈当前也为空。这样,两个栈就可以从数组的两端开始增长,当top0 + 1 == top1时,表示栈满,无法再进行入栈操作。
这是共享栈的一个典型实现,它允许两个栈共享同一片连续的内存空间,从而提高内存的使用效率。在实际应用中,共享栈适用于那些对内存使用有严格要求,且两个栈的大小变化不均匀的场景。
判断共享栈满的条件
cpp
top0+1==top1
总结