AGI 之 【Hugging Face】 的【文本分类】的数据集文本转换成词元的简单整理
目录
[AGI 之 【Hugging Face】 的【文本分类】的数据集文本转换成词元的简单整理](#AGI 之 【Hugging Face】 的【文本分类】的[数据集][文本转换成词元]的简单整理)
[1、Hugging Face Datasets 库](#1、Hugging Face Datasets 库)
一、简单介绍
AGI,即通用人工智能(Artificial General Intelligence),是一种具备人类智能水平的人工智能系统。它不仅能够执行特定的任务,而且能够理解、学习和应用知识于广泛的问题解决中,具有较高的自主性和适应性。AGI的能力包括但不限于自我学习、自我改进、自我调整,并能在没有人为干预的情况下解决各种复杂问题。
AGI能做的事情非常广泛:
跨领域任务执行:AGI能够处理多领域的任务,不受限于特定应用场景。
自主学习与适应:AGI能够从经验中学习,并适应新环境和新情境。
创造性思考:AGI能够进行创新思维,提出新的解决方案。
社会交互:AGI能够与人类进行复杂的社会交互,理解情感和社会信号。
关于AGI的未来发展前景,它被认为是人工智能研究的最终目标之一,具有巨大的变革潜力:
技术创新:随着机器学习、神经网络等技术的进步,AGI的实现可能会越来越接近。
跨学科整合:实现AGI需要整合计算机科学、神经科学、心理学等多个学科的知识。
伦理和社会考量:AGI的发展需要考虑隐私、安全和就业等伦理和社会问题。
增强学习和自适应能力:未来的AGI系统可能利用先进的算法,从环境中学习并优化行为。
多模态交互:AGI将具备多种感知和交互方式,与人类和其他系统交互。
Hugging Face作为当前全球最受欢迎的开源机器学习社区和平台之一,在AGI时代扮演着重要角色。它提供了丰富的预训练模型和数据集资源,推动了机器学习领域的发展。Hugging Face的特点在于易用性和开放性,通过其Transformers库,为用户提供了方便的模型处理文本的方式。随着AI技术的发展,Hugging Face社区将继续发挥重要作用,推动AI技术的发展和应用,尤其是在多模态AI技术发展方面,Hugging Face社区将扩展其模型和数据集的多样性,包括图像、音频和视频等多模态数据。
在AGI时代,Hugging Face可能会通过以下方式发挥作用:
模型共享:作为模型共享的平台,Hugging Face将继续促进先进的AGI模型的共享和协作。
开源生态:Hugging Face的开源生态将有助于加速AGI技术的发展和创新。
工具和服务:提供丰富的工具和服务,支持开发者和研究者在AGI领域的研究和应用。
伦理和社会责任:Hugging Face注重AI伦理,将推动负责任的AGI模型开发和应用,确保技术进步同时符合伦理标准。
AGI作为未来人工智能的高级形态,具有广泛的应用前景,而Hugging Face作为开源社区,将在推动AGI的发展和应用中扮演关键角色。
(注意:以下代码运行,可能需要科学上网)
二、文本分类
文本分类(Text Classification)是自然语言处理(NLP)中的一项基本任务,其目的是将文本数据自动归类到预定义的类别中。文本分类的具体任务可以有多种形式,包括情感分析、主题分类、垃圾邮件检测、语言检测、意图识别等。
Hugging Face 提供了一个强大且易于使用的库(Transformers),能够处理各种文本分类任务。该库包含了众多预训练的变换器模型,如 BERT、RoBERTa、GPT-3 等,这些模型已经在大规模数据集上进行了预训练,能有效提升分类任务的准确性和效率。
Hugging Face生态系统中的三个核心库:Datasets、Tokenizers和Transformers。如下图所示,这些库令我们能够快速地将原始文本输入微调后的模型,以用于推理新的推文。

三、数据集
1、H u g g i n g F a c e D a t a s e t s 库
我们将使用 Hugging Face 的 Datasets 来从 Hugging Face Hub 下载数据。可以使用 list_datasets() 函数查看 Hub 上可用的数据集:
我们将使用 Hugging Face 的Datasets模块,从Hugging Face Hub下载数据。可以通过调用list_datasets()函数来查看Hub上所有可用的数据集。
python
# 从 datasets 模块导入 list_datasets 函数
from datasets import list_datasets
# 调用 list_datasets 函数获取所有可用的数据集列表
all_datasets = list_datasets()
# 打印当前 Hub 上可用数据集的总数量
print(f"There are {len(all_datasets)} datasets currently available on the Hub")
# 打印前 10 个数据集的名称
print(f"The first 10 are: {all_datasets[:10]}")运行结果:
There are 171532 datasets currently available on the Hub
The first 10 are: ['amirveyseh/acronym_identification', 'ade-benchmark-corpus/ade_corpus_v2', 'UCLNLP/adversarial_qa', 'Yale-LILY/aeslc', 'nwu-ctext/afrikaans_ner_corpus', 'fancyzhx/ag_news', 'allenai/ai2_arc', 'google/air_dialogue', 'komari6/ajgt_twitter_ar', 'legacy-datasets/allegro_reviews']我们可以看到每个数据集都有一个名称,因此让我们使用load_dataset()函数加载情感数据集:
python
# 导入 os 模块,用于设置环境变量
import os
# 设置环境变量以忽略 SSL 证书验证
os.environ['CURL_CA_BUNDLE'] = ''
os.environ['PYTHONHTTPSVERIFY'] = '0'
# 从 datasets 模块导入 load_dataset 函数
from datasets import load_dataset
# 使用 load_dataset 函数加载名为 "emotion" 的数据集,并允许执行自定义代码
emotions = load_dataset("emotion", trust_remote_code=True)
# 打印加载的数据集的基本信息
print(emotions)运行结果:
emotions对象详情如下:
python
emotions运行结果:
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})我们可以看到它类似于Python字典,每个键对应不同的数据集分割。我们可以使用常用的字典语法来访问某个数据集分割:
python
train_ds = emotions["train"]
train_ds运行结果:
Dataset({
features: ['text', 'label'],
num_rows: 16000
})以上代码返回一个Dataset类的实例。Dataset对象是Hugging Face Datasets库的核心数据结构之一,在本书中我们将探索它的许多特性。首先,它的行为类似于普通的Python数组或列表,因此我们可以查询它的长度:
python
len(train_ds)运行结果:
16000或者通过索引访问某个样本
python
train_ds[0]运行结果:
{'text': 'i didnt feel humiliated', 'label': 0}在这里我们可以看到,这行数据将表示成这样一个字典,其中键对应着列名:
python
train_ds.column_names运行结果:
['text', 'label']值分别是推文和情感。这反映了Hugging Face Datasets库是基于A p a c h e A r r o w (h t t p s : / / a r r o w . a p a c h e . o r g)构建的。Apache Arrow定义了一种类型化的列格式,比原生的Python更有效地利用内存。我们可以通过访问Dataset对象的features属性来查看其背后使用了哪些数据类型。
python
print(train_ds.features)运行结果:
{'text': Value(dtype='string', id=None), 'label': ClassLabel(names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], id=None)}text列的数据类型为字符串,而label列是一个特殊的ClassLabel对象,它包含有关类名称及其映射到整数的信息。我们还可以使用切片查看几行数据:
python
print(train_ds[:5])运行结果:
{'text': ['i didnt feel humiliated', 'i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake', 'im grabbing a minute to post i feel greedy wrong', 'i am ever feeling nostalgic about the fireplace i will know that it is still on the property', 'i am feeling grouchy'], 'label': [0, 0, 3, 2, 3]}请注意,这种情况下,字典的值是列表而不是某个元素。我们也可以通过名称获取整个列:
python
print(train_ds["text"][:5])运行结果:
['i didnt feel humiliated', 'i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake', 'im grabbing a minute to post i feel greedy wrong', 'i am ever feeling nostalgic about the fireplace i will know that it is still on the property', 'i am feeling grouchy']2、如 果 我 的 数 据 集 不 在 H u b 上 那 该 怎 么 办 ?
大部分示例中,我们将使用Hugging Face Hub库下载数据集。但在许多情况下,你会发现自己处理的数据要么存储在你的笔记本电脑上,要么存储在你的组织的远程服务器上。Datasets提供了多个加载脚本来处理本地和远程数据集。

可以看到,对于每种数据格式,我们只需要将相关的加载脚本参数和数据文件data_files参数传给load_dataset()函数即可,其中data_files参数指定一个或多个文件的路径或URL。假如情感数据集的源文件实际上托管在某个网站上,那么可以使用以下代码加载数据集:
python
import requests
dataset_url = "https://huggingface.co/datasets/transformersbook/emotion-train-split/raw/main/train.txt"
output_file = "train.txt"
# 发起GET请求下载文件
response = requests.get(dataset_url)
# 检查响应状态
if response.status_code == 200:
# 打开本地文件,并写入下载的内容
with open(output_file, 'wb') as f:
f.write(response.content)
print(f"File downloaded successfully as {output_file}")
else:
print(f"Failed to download file. Status code: {response.status_code}")运行结果:
File downloaded successfully as train.txt本地会保存一份 train.txt。
现在,我们查看train.txt文件的第一行:
python
# 定义要读取的文件名
file_name = "train.txt"
# 打开文件并读取前几行
with open(file_name, 'r', encoding='utf-8') as file:
# 读取文件的前1行
first_line = file.readline().strip()
# 打印读取的行
print(f"First line of {file_name}: {first_line}")运行结果:
First line of train.txt: i didnt feel humiliated;sadness我们可以看到这里没有列标题,每个推文和情感之间用分号分隔。看起来与CSV文件非常相似,因此我们可以使用csv脚本并将data_files参数指向train.txt文件来将数据集加载到本地:
python
emotions_local = load_dataset("csv", data_files="train.txt", sep=";",
names=["text", "label"])运行结果:
3、从 D a t a s e t s 到 D a t a F r a m e
尽管Hugging Face Datasets库提供了许多底层的功能供我们切分和处理数据,但我们通常将Dataset对象转换为Pandas DataFrame,这样我们就可以使用高级API来进行可视化,这样做将非常方便。Hugging Face Datasets库提供了set_format()方法,该方法允许我们更改数据集的输出格式以进行转换。请注意,它不会改变底层的数据格式(Arrow表),并且你可以随时切换到另一种格式。
python
# 导入 pandas 库,通常用于数据分析和操作
import pandas as pd
# 将数据集的格式设置为 pandas DataFrame 格式
emotions.set_format(type='pandas')
# 获取 "train" 子集的数据,并将其转换为 pandas DataFrame 格式
df = emotions["train"][:]
# 显示数据集的前几行(默认前5行),以便快速查看数据的结构和内容
df.head()运行结果:
|-------|---------------------------------------------------|-----------|
| | text | label |
| 0 | i didnt feel humiliated | 0 |
| 1 | i can go from feeling so hopeless to so damned... | 0 |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 |
| 3 | i am ever feeling nostalgic about the fireplac... | 2 |
| 4 | i am feeling grouchy | 3 |
可以看到,列标题被保留,前几行与我们以前查看的数据相匹配。然而,标注(label列)表示为整数,因此我们需要使用int2str()方法在我们的DataFrame中创建一个包含相应标注名称的新列(label name列):
python
# 定义一个函数,用于将标签的整数值转换为字符串标签
def label_int2str(row):
# 从情感数据集的训练子集中获取标签的特征,并使用 int2str 方法将整数标签转换为字符串
return emotions["train"].features["label"].int2str(row)
# 创建一个新的列 "label_name",将 "label" 列的整数值标签转换为字符串标签
# 通过 apply 方法将 label_int2str 函数应用于 "label" 列的每一行
df["label_name"] = df["label"].apply(label_int2str)
# 显示数据集的前几行(默认前5行),以便快速查看新添加的 "label_name" 列
df.head()运行结果:
|-------|---------------------------------------------------|-----------|----------------|
| | text | label | label_name |
| 0 | i didnt feel humiliated | 0 | sadness |
| 1 | i can go from feeling so hopeless to so damned... | 0 | sadness |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 | anger |
| 3 | i am ever feeling nostalgic about the fireplac... | 2 | love |
| 4 | i am feeling grouchy | 3 | anger |
在构建分类器之前,我们仔细研究一下数据集。正如Andrej Karpathy在他著名的博客文章"A Recipe for Training Neural Networks"(h t t p s : / / o r e i l . l y / b N a y o)中所指出的那样,与数据"融为一体"是训练出优秀模型的关键步骤!
4、查 看 类 分 布
对于处理文本分类问题,检查类的样本分布无论何时都是一个好主意。相对于类平衡的数据集来说,一个类分布不平衡的数据集可能需要在训练损失和度量指标方面采取不同的处理方法。
我们可以使用 Pandas 和 Matplotlib 快速地可视化类分布:
python
# 导入 Matplotlib 库中的 pyplot 模块,并简称为 plt
import matplotlib.pyplot as plt
# 绘制水平条形图,显示每个类别的频率(使用 value_counts() 函数)
df["label_name"].value_counts(ascending=True).plot.barh()
# 设置图表标题
plt.title("Frequency of Classes")
# 保存图表为文件(可选操作)
plt.savefig('images/class_frequency_plot.png')
# 显示图表
plt.show()运行结果:
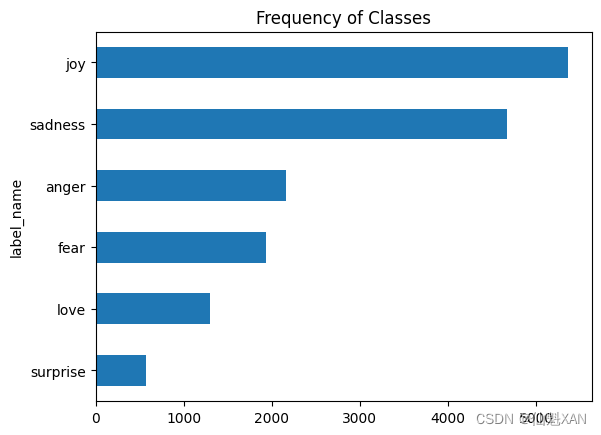
我们可以看到数据集严重不平衡;joy和sadness类频繁出现,大约是love和surprise类的5~10倍。处理不平衡数据的方法包括:
●随机对少数类进行过采样(oversample)。
●随机对多数类进行欠采样(undersample)。
●收集更多来自未被充分表示的类的标注数据。
为了保持本章简单,我们不使用以上的任何方法,而将使用原始的、不平衡的类。如果你想了解更多关于这些采样技术的内容。需要注意的是,在将数据集分割成训练/测试集之前不要应用采样方法,否则会在两者之间造成大量泄漏!
4、这 些 推 文 有 多 长
Transformer模型的输入序列长度有一个最大限制,称为最大上下文大小(maximum context size)。对于使用DistilBERT的应用程序,最大上下文大小为512个词元,只有几段文本长。正如前面看到的,词元是指一段文本的原子单元,这里为简单起见我们将词元视为一个单词。我们可以通过查看每个推文中单词的分布来对每种情感的推文长度进行大致估计:
python
# 导入 Matplotlib 库中的 pyplot 模块,并简称为 plt
import matplotlib.pyplot as plt
# 计算每条推文的单词数,并将结果存储在新列 "Words Per Tweet" 中
df["Words Per Tweet"] = df["text"].str.split().apply(len)
# 绘制箱线图,展示每个类别下推文单词数的分布情况
df.boxplot("Words Per Tweet", by="label_name", grid=False, showfliers=False, color="black")
# 设置总标题为空字符串,以便更好地布局图表
plt.suptitle("")
# 设置 x 轴标签为空字符串,以便更好地布局图表
plt.xlabel("")
# 自适应保存图像为文件(在显示图表之前调用 plt.savefig())
plt.savefig('images/words_per_tweet_boxplot.png', bbox_inches='tight')
# 显示图表
plt.show()运行结果:

从图中可以看出,对于每种情感,大多数推文长度为15个单词,最长的推文远远低于DistilBERT的最大上下文大小。超过模型上下文大小的文本需要被截断,如果被截断的文本包含关键信息,则可能会导致性能下降。就我们的示例而言,应该不会有这方面的问题。
接下来我们将原始文本转换为Hugging Face Transformers库支持的格式,首先我们需要重置数据集的输出格式,因为我们不再需要DataFrame格式了:
python
# 重置数据集的格式,恢复默认格式
emotions.reset_format()四、将 文 本 转 换 成 词 元
像DistilBERT这样的Transformer模型不能接收原始字符串作为输入。它假定文本已经被词元化并编码为数字向量。词元化(tokenization)是指将字符串分解为给模型使用的原子单元的步骤。词元化的策略有好几种,具体哪种最佳通常需要从语料库中学习。在讨论DistilBERT使用的Tokenizer之前,我们先讨论两种极端情况:字符词元化和单词词元化。
将文本转换成词元(tokenization)是指将文本分割成单独的词或子字符串的过程。在自然语言处理中,词元可以是单词、词根、标点符号或其他单位,这取决于具体的任务和处理需求。
过程解释:
分割文本: 首先,文本会根据空格、标点符号等分隔符进行切分,生成词元序列。
标准化: 可能会对词元进行标准化处理,例如将大写字母转换为小写,以便统一词元的形式。
构建词汇表: 可能会根据语料库中的词元构建一个词汇表或者使用预先定义的词汇表。
编码: 每个词元可能会被编码成一个唯一的索引或者向量,以便机器学习模型能够处理。
应用领域:
文本分类: 在进行文本分类任务时,文本通常需要被转换成词元序列,以便输入到分类器中。
机器翻译: 在机器翻译任务中,源语言和目标语言的文本都需要被词元化,以便进行对应的转换和匹配。
信息检索: 在搜索引擎中,将用户查询转换成词元,以便与文档库中的词元进行匹配。
例子:
考虑以下句子:"The cat sat on the mat.",经过词元化处理后可能会得到词元序列:"The", "cat", "sat", "on", "the", "mat", "."。每个词元都代表了句子中的一个单词或标点符号,这样的处理使得文本能够被计算机更好地理解和处理。
1、字 符 词 元 化
最简单的词元化方案是按每个字符单独馈送到模型中。在Python中,str对象实际上是一组数据,这使我们可以用一行代码快速实现字符词元化:
python
# 定义一个包含文本的字符串变量
text = "Tokenizing text is a core task of NLP."
# 将文本分割成单个字符,并存储在列表中(即将文本转换为字符级别的词元)
tokenized_text = list(text)
# 打印输出分割后的文本列表
print(tokenized_text)运行结果:
['T', 'o', 'k', 'e', 'n', 'i', 'z', 'i', 'n', 'g', ' ', 't', 'e', 'x', 't', ' ', 'i', 's', ' ', 'a', ' ', 'c', 'o', 'r', 'e', ' ', 't', 'a', 's', 'k', ' ', 'o', 'f', ' ', 'N', 'L', 'P', '.']这是一个很好的开始,但我们还没有完成任务。我们的模型希望把每个字符转换为一个整数,有时这个过程被称为数值化(numericalization)。一个简单的方法是用一个唯一的整数来编码每个唯一的词元(在这里为字符):
python
# 使用列表推导式创建一个字典,将词元列表中的每个唯一字符映射到其索引位置
token2idx = {ch: idx for idx, ch in enumerate(sorted(set(tokenized_text)))}
# 打印生成的 token 到索引的映射字典
print(token2idx)运行结果:
{' ': 0, '.': 1, 'L': 2, 'N': 3, 'P': 4, 'T': 5, 'a': 6, 'c': 7, 'e': 8, 'f': 9, 'g': 10, 'i': 11, 'k': 12, 'n': 13, 'o': 14, 'r': 15, 's': 16, 't': 17, 'x': 18, 'z': 19}我们可以看到,我们得到了一个包括了每个字符到一个唯一性整数的映射,即词元分析器的词表。我们现在可以使用token2idx将词元化的文本转换成一个整数列表:
python
# 使用 token2idx 字典将 tokenized_text 中的每个词元映射到其对应的索引,并存储在 input_ids 列表中
input_ids = [token2idx[token] for token in tokenized_text]
# 打印生成的 input_ids 列表,显示每个词元的索引编号
print(input_ids)运行结果:
[5, 14, 12, 8, 13, 11, 19, 11, 13, 10, 0, 17, 8, 18, 17, 0, 11, 16, 0, 6, 0, 7, 14, 15, 8, 0, 17, 6, 16, 12, 0, 14, 9, 0, 3, 2, 4, 1]现在,每个词元都已映射到唯一的数字标识符(因此称为input_ids)。最后一步是将input_ids转换为独热向量(one-hot vector)的二维张量。在机器学习中,独热向量常常用于编码分类数据(包括有序和无序数据)。例如,假设我们想对《变形金刚》中的角色名称进行编码。一种方法是将每个Name映射到唯一的ID,如下所示:
python
# 使用 pandas 库创建一个包含分类数据的 DataFrame
categorical_df = pd.DataFrame(
{"Name": ["Bumblebee", "Optimus Prime", "Megatron"], "Label ID": [0, 1, 2]})
# 显示创建的 categorical_df DataFrame
categorical_df解释每行代码的作用:
-
categorical_df = pd.DataFrame(...)- 使用
pd.DataFrame()函数创建一个新的 DataFramecategorical_df,该 DataFrame 包含了一个名为 "Name" 的列和一个名为 "Label ID" 的列。每列的数据由一个字典提供,字典的键是列名,值是该列的数据列表。
- 使用
-
{"Name": ["Bumblebee", "Optimus Prime", "Megatron"], "Label ID": [0, 1, 2]}- 这个字典定义了 DataFrame 中的数据。"Name" 列包含了三个名字 "Bumblebee", "Optimus Prime", "Megatron",而 "Label ID" 列包含了对应的标签 ID:0, 1, 2。
-
categorical_df- 打印显示创建的
categorical_dfDataFrame,展示了其中包含的所有行和列数据。
- 打印显示创建的
运行结果:
|-------|---------------|--------------|
| | Name | Label ID |
| 0 | Bumblebee | 0 |
| 1 | Optimus Prime | 1 |
| 2 | Megatron | 2 |
这种方法的问题在于它会给Name这一列的值引入虚假的顺序关系,这个缺陷在某些情况下可能会导致神经网络学习到错误的模式和关系,从而降低模型的性能。因此,我们可以为每个类别创建一个新列,在该类别为true时分配1,否则分配0。在Pandas中,可以使用get_dummies()函数实现这点:
python
# 使用 pandas 的 get_dummies 函数对 categorical_df 中的 "Name" 列进行独热编码处理
pd.get_dummies(categorical_df["Name"])运行结果:
|-------|---------------|--------------|-------------------|
| | Bumblebee | Megatron | Optimus Prime |
| 0 | TRUE | FALSE | FALSE |
| 1 | FALSE | FALSE | TRUE |
| 2 | FALSE | TRUE | FALSE |
以上DataFrame中的每行是一个独热向量,一整行只有一个TRUE,其他都是FALSE。现在,看看我们的input_ids,我们有类似的问题:这些元素的取值之间引入了虚假的顺序关系。因为这个关系是虚假的,所以对两个ID进行加减是一个没意义的操作。
如果我们将input_ids改成独热编码,结果就很容易解释:"热"的两个条目表明是相同的两个词元。在PyTorch中,我们可以使用one_hot()函数对input_ids进行独热编码:
python
# 导入 PyTorch 库和相关模块
import torch # 导入 PyTorch 库,用于张量操作和深度学习计算
import torch.nn.functional as F # 导入 PyTorch 的函数模块,包含各种神经网络操作函数
# 将列表 input_ids 转换为 PyTorch 的 Tensor 格式
input_ids = torch.tensor(input_ids)
# 使用 F.one_hot 函数将 input_ids 转换为独热编码表示,num_classes 参数指定了独热编码的长度
one_hot_encodings = F.one_hot(input_ids, num_classes=len(token2idx))
# 打印生成的独热编码张量的形状
one_hot_encodings.shape运行结果:
torch.Size([38, 20])本例共有38个输入词元,我们得到了一个20维的独热向量,因为我们的词表包含了20个唯一字符。
在one_hot()函数中,始终要设置num_classes参数,否则独热向量可能会比词表长度短(需要手动用零来填充)。在TensorFlow中,对应的函数是tf.one_hot(),对应num_classes的参数是depth。
通过输出input_ids0的如下信息来检查第一个向量,我们可以看到有个位置出现了1:
python
# 打印第一个词元的文本表示
print(f"Token: {tokenized_text[0]}")
# 打印第一个词元在独热编码中的索引表示
print(f"Tensor index: {input_ids[0]}")
# 打印第一个词元的独热编码表示
print(f"One-hot: {one_hot_encodings[0]}")运行结果:
Token: T
Tensor index: 5
One-hot: tensor([0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])从我们这个简单的示例可以看出,字符级别的词元化忽略了文本中的任何结构,将整个字符串视为一串字符流。虽然这有助于处理拼写错误和生僻词,但主要缺点是语言结构(如单词)需要从数据中学习。这需要大量的计算、内存和数据。因此,字符词元化在实践中很少使用。如果想保留文本的某些结构,那么单词词元化是实现这一目标的一种简单直接的方法,让我们来看看它是如何工作的。
2、单 词 词 元 化
与字符词元化相比,单词词元化将文本细分为单词,并将每个单词映射到一个整数。单词词元化使模型跳过从字符学习单词的步骤,从而降低训练过程的复杂性。
有一种简单的单词词元化方法是使用空格来分割文本。我们可以直接在原始文本上应用Python的split()函数(就像我们统计推文字数那样)来实现这一点:
python
# 使用空格将文本分割为词元,并存储在列表 tokenized_text 中
tokenized_text = text.split()
# 打印生成的词元列表
print(tokenized_text)运行结果:
['Tokenizing', 'text', 'is', 'a', 'core', 'task', 'of', 'NLP.']这里我们可以采取相同的步骤,将每个字符映射到ID。但是,我们已经可以看到这种词元化方案中的一个潜在问题:未考虑标点,因此将NLP.视为一个单独词元。单词词元化有一个缺点:鉴于单词可以包括变形、派生或拼写错误,词表的大小很容易增长到数百万!
有些单词词元分析器支持标点以及词干提取或词形还原,因此它们可以将单词规范化成其词干(例如将great、greater和greatest都变成great),但这样会丢失文本中一些信息。
GPT-2是GPT的后继者,凭借其令人印象深刻的生成逼真文本的能力吸引了公众的关注。我们将在后面详细探讨GPT-2。
词表太大是一个问题,因为它导致了神经网络需要大量的参数。举例来说,假设词表中有100万个唯一词项,并按照大多数NLP架构中的标准步骤将100万维输入向量压缩到第一层神经网络中的1000维向量。这样就导致了第一层的权重矩阵将包含100万×1千=10亿个权重。这已经可以与最大的GPT-2模型 看齐了,该模型总计拥有大约15亿个参数!
自然,我们希望避免在模型参数上浪费过多,因为模型训练成本高昂,而且规模较大的模型更难维护。一种常见的方法是只取语料库中最常见的100 000个单词并丢弃罕见的单词来避免词表过大。词表之外的单词统一归类为"unknown"(未知,UNK),映射到一个共用的UNK词元。这意味着我们在单词词元化过程中丢失了一些可能很重要的信息,因为模型无法获得与UNK关联的单词的信息。
那么有没有这么一种方法:介于字符词元化和单词词元化之间,既可以保留输入信息又能保留文本结构?确实有,这种方法叫子词词元化。
3、子 词 词 元 化
子词词元化背后的基本思想是将字符和单词词元化的优点结合起来。一方面,我们希望将生僻单词拆分成更小的单元,以使模型能够处理复杂单词和拼写错误。另一方面,我们希望将常见单词作为唯一实体保留下来,以便我们将输入长度保持在可管理的范围内。子词词元化(以及单词词元化)是使用统计规则和算法从预训练语料库中学习的。
M. Schuster and K. Nakajima,"Japanese and Korean Voice Search,"2012 IEEE InternationalConference on Acoustics,Speech and Signal Processing(2012): 5149-5152,https://doi.org/10.1109/ICASSP.2012.6289079.
在NLP中常用的子词词元化算法有几种,我们先从 WordPiece 算法开始,这是BERT和DistilBERT词元分析器使用的算法。了解WordPiece如何工作最简单的方法是看它的运行过程。Hugging Face Transformers库提供了一个很方便的AutoTokenizer类,它能令你快速加载与预训练模型相关联的词元分析器------只需要提供模型在Hub上的ID或本地文件路径,然后调用它的from_pretrained()方法即可。我们先加载DistilBERT的词元分析器:
python
# 导入 AutoTokenizer 类从 transformers 模块中
from transformers import AutoTokenizer
# 指定要使用的预训练模型的检查点名称或路径
model_ckpt = "distilbert-base-uncased"
# 使用 AutoTokenizer 类的 from_pretrained 方法加载指定的预训练 tokenizer 模型
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)AutoTokenizer类是"auto"类的一种,其任务是根据checkpoint的名称自动检索模型的配置、预训练权重或词表。使用以上代码的优点是可以快速切换模型,但是你也可以手动加载特定类。例如,我们可以按照下面的方式加载DistilBERTTokenizer:
python
# 导入 DistilBertTokenizer 类,用于加载 DistilBERT 模型的 tokenizer
from transformers import DistilBertTokenizer
# 指定要加载的 DistilBERT 预训练模型的检查点名称或路径
model_ckpt = "distilbert-base-uncased"
# 使用 from_pretrained 方法加载指定的预训练 tokenizer 模型
distilbert_tokenizer = DistilBertTokenizer.from_pretrained(model_ckpt)当你第一次运行AutoTokenizer.from_pretrained()方法时,你将看到一个进度条,显示从Hugging Face Hub加载的预训练词元分析器的参数。当你第二次运行代码时,它会从缓存(通常是*~* / . c a c h e / h u g g i n g f a c e)中加载词元分析器。
我们输入"Tokenizing text is a core task of NLP."这一简单样本来检验这个词元分析器是如何工作的:
python
# 使用之前加载的 tokenizer 对文本进行编码
encoded_text = tokenizer(text)
# 打印编码后的文本表示
print(encoded_text)运行结果:
{'input_ids': [101, 19204, 6026, 3793, 2003, 1037, 4563, 4708, 1997, 17953, 2361, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}和字符词元化一样,我们可以看到,单词映射成input_ids字段中的唯一整数。我们将在2.2.4节中讨论attention mask字段的作用。现在我们有了input_ids,我们可以通过使用词元分析器的convert_ids_to_tokens()方法将它们转换回词元:
python
# 使用 tokenizer.convert_ids_to_tokens 方法将编码后的输入 IDs 转换为词元
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
# 打印转换后的词元列表
print(tokens)运行结果:
['[CLS]', 'token', '##izing', 'text', 'is', 'a', 'core', 'task', 'of', 'nl', '##p', '.', '[SEP]']可以观察到三件事情。首先,序列的开头和末尾多了一些特殊的词元:CLS和SEP。这些词元具体因模型而异,它们的主要作用是指示序列的开始和结束。其次,词元都小写了,这是该checkpoint的特性。最后,我们可以看到tokenizing和NLP都被拆分为两个词元,这是有道理的,因为它们不是常用的单词。##前缀中的##izing和##p意味着前面的字符串不是空白符,将带有这个前缀的词元转换回字符串时,应当将其与前一个词元合并。AutoTokenizer类有一个convert_tokens_to_string()方法可以做到这一点,所以让我们将它应用到我们的词元:
python
# 使用 tokenizer.convert_tokens_to_string 方法将词元列表转换回原始文本
print(tokenizer.convert_tokens_to_string(tokens))运行结果:
[CLS] tokenizing text is a core task of nlp. [SEP]AutoTokenizer类还有几个属性可以提供该词元分析器的其他信息。例如,我们可以检查词表的大小:
python
# 获取 tokenizer 的词汇表大小,即词汇表中唯一词元的数量
tokenizer.vocab_size运行结果:
30522还有模型的最大上下文大小:
python
# 获取 tokenizer 的模型最大长度限制
tokenizer.model_max_length运行结果:
512还有另一个有趣的属性,模型在前向传递中期望的字段名称:
python
# 获取 tokenizer 模型的输入名称
tokenizer.model_input_names运行结果:
['input_ids', 'attention_mask']现在我们了解了处理单个字符串的词元化过程,接下来我们看看如何对整个数据集进行词元化!
在使用预训练模型时,确保使用与模型训练时相同的词元分析器非常重要。从模型的角度来看,更换词元分析器就像打乱词表一样。如果身边的每个人都开始随机使用单词,比如将"house"换成"cat",那么你会很难理解发生了什么!
4、对 整 个 数 据 集 进 行 词 元 化
我们将使用DatasetDict对象的map()方法来对整个语料库进行词元化。在这里,我们将多次遇到这种方法,因为它提供了一种方便的方法,可以将处理函数应用于数据集中的每个元素。我们很快就会看到,map()方法还可以用于创建新的行和列。
我们要做的第一件事就是编写一个将我们的样本进行词元化的处理函数:
python
# 定义一个函数,用于对批量数据进行分词处理
def tokenize(batch):
# 使用 tokenizer 对批量数据中的 "text" 字段进行分词处理,添加填充和截断
return tokenizer(batch["text"], padding=True, truncation=True)这个函数将词元分析器应用于一个批量样本。padding=True表示以零填充样本,以达到批量中最长样本的长度,truncation=True表示将样本截断为模型的最大上下文大小。为了观察tokenize()具体做了什么,现在我们从训练集中取两个批量样本传给tokenizer()函数:
python
# 打印分词函数对 emotions 数据集的训练集前两个样本进行分词处理的结果
print(tokenize(emotions["train"][:2]))运行结果:
{'input_ids': [[101, 1045, 2134, 2102, 2514, 26608, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1045, 2064, 2175, 2013, 3110, 2061, 20625, 2000, 2061, 9636, 17772, 2074, 2013, 2108, 2105, 2619, 2040, 14977, 1998, 2003, 8300, 102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]}这里我们可以看到填充的结果:input_ids的第一个元素比第二个短,因此向该元素填充零以使两个元素具有相同的长度。这些零在词表中具有对应的PAD词元,而特殊词元集还包括我们之前遇到的CLS和SEP词元:
python
# 将 tokenizer 的所有特殊词元及其对应的 ID 组合成一个列表
tokens2ids = list(zip(tokenizer.all_special_tokens, tokenizer.all_special_ids))
# 将该列表按照特殊词元的 ID 进行排序
data = sorted(tokens2ids, key=lambda x: x[-1])
# 将排序后的数据转换为 DataFrame,并指定列名为 "Special Token" 和 "Special Token ID"
df = pd.DataFrame(data, columns=["Special Token", "Special Token ID"])
# 转置 DataFrame,以便更好地显示数据
df.T运行结果:
|----------------------|---------|---------|---------|---------|----------|
| | 0 | 1 | 2 | 3 | 4 |
| Special Token | PAD | UNK | CLS | SEP | MASK |
| Special Token ID | 0 | 100 | 101 | 102 | 103 |

此外,除了将编码后的推文返回为input_ids外,词元分析器还返回一系列attention_mask数组。这是因为我们不希望模型被额外的填充词元所困惑:注意力掩码(attention mask)允许模型忽略输入的填充部分。如图提供了输入ID和注意力掩码如何填充的视觉解释。
 在每个批量中,输入序列将填充到批量中最大序列的长度。模型使用注意力掩码来忽略输入张量中的填充区域
在每个批量中,输入序列将填充到批量中最大序列的长度。模型使用注意力掩码来忽略输入张量中的填充区域
在定义完处理函数之后,我们可以通过一行代码将该函数应用到语料库整个数据集:
map()方法默认按单个样本操作,因此将batched设置为True以按批量对推文进行编码。由于我们设置了batch_size=None,所以将把整个数据集作为一个批量应用tokenize()函数。这可以确保全局输入张量和注意力掩码具有相同的形状,我们可以看到此操作已将新的input ids和attention mask列添加到数据集中:
python
# 使用 map 方法对 emotions 数据集进行分词处理
# tokenize 函数会应用到每个样本的 "text" 字段,进行填充和截断
# batched=True 表示批量处理样本,batch_size=None 表示一次处理整个数据集
emotions_encoded = emotions.map(tokenize, batched=True, batch_size=None)运行结果:

map()方法默认按单个样本操作,因此将batched设置为True以按批量对推文进行编码。由于我们设置了batch_size=None,所以将把整个数据集作为一个批量应用tokenize()函数。这可以确保全局输入张量和注意力掩码具有相同的形状,我们可以看到此操作已将新的input ids和attention mask列添加到数据集中:
python
# 打印 emotions_encoded 数据集中训练集的列名
print(emotions_encoded["train"].column_names)运行结果:
['text', 'label', 'input_ids', 'attention_mask']