一、推理框架的计算图重构:从静态编译到动态优化
1.1 HunyuanInfra的核心创新:融合的计算图表示
传统推理框架(如TensorRT)采用静态图编译范式,核心流程为:模型导入 → 图分析 → 算子融合 → 代码生成 → 优化执行。这套流程的关键假设是:计算图的拓扑结构在编译期间已知,各算子的输入shape在runtime固定不变。
这些假设在标准的transformer推理中基本成立,但在实际生产环境中存在严重的适用性限制:
问题1:动态shape带来的图膨胀
当处理变长序列(文本、语音、视频等多模态混合输入)时,不同样本的序列长度各异。传统框架需要针对每个可能的shape组合生成一套优化的kernel,导致编译时间和内存占用呈组合爆炸式增长。特别是在batch processing场景中,假设batch size为32,context length的可能范围为128-4096,attention mask的shape就会产生数十种变体。
问题2:算子融合的粒度限制
标准TensorRT中的算子融合规则往往是固定的模板(如LayerNorm+ReLU、MatMul+Add等小尺度融合)。但在大模型推理中,真正的性能瓶颈往往来自于多个算子之间的内存访问模式不匹配。例如:
LayerNorm(x) -> Linear(weight=W_q) -> reshape -> transpose -> softmax这条链路中,如果按传统方式逐个执行,会产生4次全局内存写入。但这些操作可以在一个unified kernel中完成:通过shared memory进行数据的流式传递,最后才写回global memory。
HunyuanInfra的解决方案:动态图IR和延迟融合
HunyuanInfra采用了一个更灵活的中间表示(Intermediate Representation):
-
高级语义图:保留了计算的高层语义(attention, norm, linear等),而不是展开为底层算子集合
-
shape-polymorphic编译:不针对具体的shape值编译,而是生成一个参数化的kernel template,shape值在runtime确定。这类似于C++模板元编程的思想,但应用在GPU kernel生成中。具体实现上采用了类似MLIR框架中的方言转换(Dialect Lowering):
高级方言(HunyuanDialect):
%out = hyz.fused_attention_qkv(%input, %w_q, %w_k, %w_v)中级方言(MLIRStandard):
%q = linalg.matmul(%input, %w_q)
%k = linalg.matmul(%input, %w_k)
%v = linalg.matmul(%input, %w_v)
%scores = linalg.matmul(%q, transpose(%k))
...底层方言(LLVM/NVVM):
生成参数化的CUDA kernel代码 -
动态融合规则:在runtime根据实际shape、device capability(如共享内存大小、warp数)动态选择融合策略。这个过程涉及一个轻量级的代价模型估计(Cost Model),评估不同融合方案的内存访问复杂度、计算强度等。
1.2 多头注意力的块状计算与分布式token对齐
在分布式推理中,一个关键的优化难点是处理attention的跨设备通信。传统方案中,QKV矩阵会被分割到多个GPU上,每个GPU只负责部分head的计算,最后需要进行一次全局同步(all-reduce)来汇聚结果。
分析瓶颈:
假设有8个GPU,hidden_size=8192,num_heads=64,seq_len=4096,则:
- 每个GPU负责8个head,即head_dim=128
- 每个head的Q,K矩阵大小约为 4096×128 = 524KB
- 每轮attention计算后需要跨GPU传输,通信量 = 8×(4096×8192)/1M = 256MB
如果采用pipeline parallelism(流水线并行),不同层可以并发执行,但attention的同步点会成为严重的bottleneck。
HunyuanInfra的优化:
- 块状注意力计算(Block-Attention):不计算完整的QK^T矩阵,而是按block进行部分sum-reduction。这允许中间结果更早地进行跨设备同步,减少了缓存压力:
python
# 传统方式(伪代码)
Q, K, V = parallel_split(Q, K, V) # 在GPU间分割
scores = softmax(Q @ K.T) # 全局操作,需要同步
output = scores @ V
# 块状方式
block_size = 256
for i in range(0, seq_len, block_size):
Q_block = Q[:, i:i+block_size]
partial_score = Q_block @ K.T # 部分计算
# 此时可以只对partial_score进行all-reduce而非完整矩阵
partial_out = partial_score @ V
# 流式更新结果,避免存储完整中间矩阵- Token对齐与padding策略:在处理变长输入时,通常需要padding到统一长度。但naive的padding会引入大量冗余计算。HunyuanInfra采用了类似Megatron-LM中的sequence-parallel思想,但做了更激进的优化------在设备间分割不同的token位置,而非分割feature维度。这样可以跳过padding token的计算,直接处理有效token。
1.3 KV Cache的存储与调度
在自回归解码过程中,KV Cache是内存占用的主要来源。对于batch_size=32, seq_len=4096, hidden=8192的场景,完整的KV Cache约为 32×4096×2×8192×2bytes = 4.3GB。
传统方案的问题:
- 预先为最大长度分配cache,导致早期token的内存浪费
- cache的layout(行优先vs列优先)影响访问局部性,但通常固定设计
HunyuanInfra的动态cache管理:
- 树状reuse机制:在beam search或多样本生成中,多条解码路径往往共享前缀。通过构建一个逻辑上的前缀树(Prefix Tree),不同路径可以共享相同的KV Cache块,只在divergence点复制必要的块。这可以降低40-60%的cache占用(取决于beam width和路径相似度)。
- PagedAttention思想的融合:参考vLLM的paged attention设计,但更进一步------在设备间动态迁移cache块。当某个GPU的cache压力大时,可以将优先级较低的cache块异步传输到CPU内存或其他GPU,在需要时再迁回。这涉及一个经典的缓存置换问题,采用LRU/LFU等策略。
1.4 算子库的自适应编译
在HunyuanInfra中,关键算子(如fused_qkv_attention, fused_mlp等)不是预先编译的黑盒库,而是在首次使用时根据shape/device进行JIT(Just-In-Time)编译。这类似于Numba对Python函数的处理:
python
@hyz.jit(strategy='cost_model')
def fused_attention(q, k, v, mask=None):
# 这个函数在runtime会被分析
# 代价模型评估:
# - register pressure
# - shared memory usage
# - bank conflict risk
# 根据评估结果选择最优的thread block大小和融合策略
scores = q @ k.T # 这里会根据shape自动融合
scores = softmax(scores, mask)
return scores @ v二、分布式训练的通信优化:突破ring all-reduce的局限
2.1 Ring All-Reduce的理论分析与实际瓶颈
在NVIDIA的NCCL库中,Ring All-Reduce是标准的集合通信算法,复杂度为O(N)(N为参与节点数)。其通信量为 2(N-1)/N × M,其中M是总参数量。对于100个GPU的训练集群,N-1步中,每一步需要将参数分割为100份,其中99份通过ring进行循环传递。
理论上界分析:
Ring All-Reduce的关键性能指标是:
- 通信延迟(latency):取决于ring中最慢的链接
- 通信带宽利用率(bandwidth utilization):理论上可达到100%(每条链接都被充分利用)
但在实际网络拓扑中存在瓶颈:
- 树型网络拓扑的限制:数据中心网络通常采用tree-of-spines或clos网络,上行带宽受限于汇聚交换机的容量。Ring All-Reduce假设点对点链接带宽均匀,但实际上跨机柜的链接往往是瓶颈。
- 异步通信的延迟隐藏不足:在训练中,计算(forward/backward propagation)和通信(gradient all-reduce)需要overlap。但如果all-reduce的latency太高,计算端会频繁等待通信完成。
2.2 腾讯方案:分层多路径通信
腾讯在这方面的创新主要体现在"分层多路径"架构:
第一层:节点内通信(Intra-node)
在单个节点内有多个GPU(如8卡A100):
- 使用PCIe P2P或NVLink进行GPU间通信
- 采用本地梯度压缩(local gradient compression):在all-reduce前,先在节点内进行部分聚合,减少跨机通信的数据量
- 对于ResNet/BERT等模型,通常可以在节点内降低40-50%的通信量
第二层:节点间通信(Inter-node)
- 自适应路径选择:根据网络拓扑和当前负载,动态选择最优路径。例如,如果两个GPU恰好位于同一个交换机下,直接通过该交换机;否则选择通过集合树(aggregation tree)
- 通信量感知调度:在每一步训练中,梯度all-reduce的数据量是固定的,但可以选择分批传输以避免网络过载。这类似于TCP的拥塞控制,但在集合通信的context中实现
第三层:梯度量化与稀疏化
-
梯度量化(Gradient Quantization):使用bfloat16或int8表示梯度,而非fp32,可以减少50%的通信量。但这会引入量化误差,需要谨慎处理:
梯度 g_fp32 → 量化 g_q = round(g_fp32 / scale) → 反量化 g'_fp32 = g_q × scale 为了保证收敛性,需要证明累积误差不超过某个阈值。 一个有效的策略是:只对较小的梯度进行量化(因为它们对损失的影响较小), 对关键层保持fp32精度 -
梯度稀疏化(Gradient Sparsification):只传输绝对值较大的梯度,其余梯度在下一轮补偿。这个思想来自于federated learning,但在数据中心训练中有更严格的同步要求。腾讯的实现采用了"梯度异步累积":
梯度稀疏率 = 99%(只传输top 1%的梯度) 时间步 t: 梯度计算 g_t 选择 top-1% 梯度发送 记录未发送的梯度用于下一轮补偿 g_cumulate = g_t + g_undeclared # 本地累积 if |g_cumulate| > threshold: 发送梯度 清空累积
2.3 通信-计算重叠的优化
传统的优化方式是简单的pipeline:先完成全部梯度计算,再执行all-reduce。但更优的方式是让两者overlap:
python
# 伪代码:梯度计算与all-reduce的重叠
for layer in reversed(model.layers):
grad = compute_gradient(layer) # 计算该层梯度
# 立即启动all-reduce,无需等待后续层的梯度计算
all_reduce_async(grad, grad_buffer[layer.id])
# 同时继续计算下一层的梯度
continue_backward(layer.prev)
# 检查该层的all-reduce是否完成,若完成则更新权重
if all_reduce_done(layer.id):
update_weights(layer, grad_buffer[layer.id])关键的工程细节是:梯度计算和all-reduce的启动顺序。由于计算图的依赖关系,理想的启动顺序应该是从最后一层向前逐层启动all-reduce,这样可以最大化重叠。腾讯在这方面的优化通过静态分析计算图得到最优的启动调度。
三、智能体框架:从静态微调到动态任务分解
3.1 Youtu-Agent的架构范式:任务动态分解(Dynamic Task Decomposition)
传统的智能体(Agent)基于强化学习范式:定义状态空间、动作空间、奖励函数,然后通过策略学习找到最优的动作序列。但这个范式存在明显的缺陷:
- 奖励函数的设计困难:如何为"正确理解用户需求"这样的开放式任务定义奖励?
- 探索-利用困境:在复杂环境中,有效的探索策略很难设计
- 样本效率低下:需要大量的trail-and-error来学习
Youtu-Agent的创新 :采用"任务动态分解"范式,核心思想是------不预先定义完整的任务分解树,而是在执行过程中根据当前状态动态生成下一步的子任务。
python
# 伪代码:动态任务分解算法
class DynamicTaskAgent:
def execute(self, user_query):
current_state = {
'query': user_query,
'progress': [], # 已完成的子任务列表
'context': {} # 当前上下文
}
while not is_goal_reached(current_state):
# 核心创新:根据当前状态生成下一步任务
# 注意这不是通过RL策略学习,而是通过语言模型的推理
next_task = self.decompose(current_state)
# 执行任务(可能调用不同的模块:搜索、计算、外部API等)
task_result = self.execute_task(next_task, current_state)
# 更新状态
current_state['progress'].append({
'task': next_task,
'result': task_result,
'success': evaluate_task_result(next_task, task_result)
})
# 失败处理:如果任务失败,重新分解
if not current_state['progress'][-1]['success']:
# 这是关键创新:学习从失败中恢复
# 通过分析失败原因,生成替代任务
current_state = self.recover_from_failure(current_state)
return aggregate_results(current_state['progress'])
def decompose(self, state):
# 这个函数的实现是关键
# 可以是提示工程(prompt engineering)或微调的小模型
prompt = f"""
已完成的任务: {state['progress']}
当前查询: {state['query']}
根据上述信息,生成下一步最有可能达到目标的任务。
任务应该是具体的、可执行的、可验证的。
"""
# 调用基础模型进行任务生成
next_task = self.base_model.generate(prompt)
return next_task3.2 模块化设计与可组合性
Youtu系列框架的另一个关键创新是"模块化设计",包括三个互相协作的模块:
模块1:Youtu-Parsing(结构化信息提取)
大多数用户查询是自然语言,包含模糊、冗余、甚至矛盾的信息。Youtu-Parsing的目标是将自然语言转化为结构化的语义表示:
python
# 输入:自然语言查询
"在过去三个月中,对所有客户的交易额超过100万的进行风险评估,
重点关注海外交易"
# 输出:结构化表示
{
"time_range": {
"start": "3_months_ago",
"end": "now"
},
"conditions": [
{
"field": "transaction_amount",
"operator": ">",
"value": 1000000
},
{
"field": "transaction_region",
"operator": "contains",
"value": ["overseas"]
}
],
"action": "risk_assessment",
"priority_fields": ["overseas_transactions"]
}实现细节:
- 采用sequence-labeling的思想,标记query中的各个成分(时间、数值、条件等)
- 采用dependency parsing来理解多条件之间的逻辑关系(AND/OR/NOT)
- 最后通过树结构化的规则或神经网络生成结构化输出
模块2:Youtu-Embedding(语义对齐与知识融合)
将结构化查询与知识库中的概念进行对齐,这涉及语义匹配和知识图谱的推理:
python
# 输入:结构化查询中的概念
"transaction_region = 'overseas'"
# 需要进行的映射:
# - "overseas" 在数据库中对应的字段和值
# - 相关的风险知识规则(例如,海外交易与洗钱风险的关联)
# - 相关的数据来源和权限
# 输出:扩展的查询和关联的风险模型
{
"db_fields": {
"field_name": "transaction.country_code",
"field_type": "categorical",
"valid_values": [code for code in ALL_COUNTRIES if code not in DOMESTIC_CODES]
},
"risk_model": {
"model_id": "overseas_risk_model_v2",
"features": ["country_risk_score", "transaction_size", "customer_history", ...],
"threshold": 0.72
},
"data_sources": {
"primary": "transaction_db",
"external": ["country_risk_index", "sanctions_list"]
}
}模块3:Youtu-Graphrag(图谱增强的检索)
将知识图谱融入到信息检索中。传统的RAG(Retrieval-Augmented Generation)通常采用向量相似度检索,但这在复杂推理任务中往往不够:
XML
查询:某个客户的交易风险评估
向量检索方案(传统):
query_embedding = encode("某个客户的交易风险评估")
相似documents = top_k_similarity_search(query_embedding)
# 问题:可能检索到"如何评估风险",而不是"某个特定客户的历史"
图谱检索方案(Youtu-Graphrag):
1. 从query中提取实体:客户ID
2. 在知识图谱中找到该实体的邻域
客户 ---> 交易历史 ---> 高风险交易
---> 国家 ---> 国家风险评级
---> 时间窗口 ---> 相似客户
3. 进行多跳推理:
customer.risk_score =
aggregate_func([
historical_transactions[customer],
country_risk[transaction.country],
behavioral_anomaly[customer],
peer_comparison[similar_customers]
])
4. 检索相关的规则和案例实现细节:
- 知识图谱通常由两部分组成:结构化数据图 (从数据库、API提取)和文本图(从非结构化文本中抽取)
- 图的遍历策略需要平衡覆盖范围和计算成本。采用BFS/DFS的变种,引入beam search来限制搜索空间
- 融合多个数据源的结果需要一致性处理,特别是当来自不同来源的信息冲突时
3.3 失败恢复机制与在线学习
这是Youtu-Agent相比传统agent的最大创新。当一个任务执行失败时,系统不是简单地retry或abandon,而是进行智能的失败分析和自适应恢复:
python
def recover_from_failure(self, current_state):
failed_task = current_state['progress'][-1]
failure_reason = analyze_failure(failed_task['result'])
# 失败原因分类:
# 1. 解析失败:查询本身不清晰
# 2. 匹配失败:无法找到相关知识
# 3. 执行失败:外部服务不可用
# 4. 验证失败:结果不符合预期
if failure_reason == "query_ambiguous":
# 策略1:要求用户澄清
clarification = ask_user(failed_task['task'])
return update_state(current_state, clarification)
elif failure_reason == "knowledge_gap":
# 策略2:扩大知识搜索范围
expanded_task = broaden_knowledge_search(failed_task['task'])
failed_task['task'] = expanded_task
return current_state
elif failure_reason == "service_unavailable":
# 策略3:选择备用方案
alternative_task = find_alternative_approach(failed_task['task'])
failed_task['task'] = alternative_task
return current_state
elif failure_reason == "validation_failure":
# 策略4:调整验证标准或任务细节
refined_task = refine_task(failed_task['task'],
failed_task['result'])
failed_task['task'] = refined_task
return current_state在线学习机制:
对于重复出现的失败模式,系统可以进行局部微调(而非全局重新训练)。例如,如果发现"某个特定查询模式"频繁导致"知识匹配失败",可以:
- 收集相关的查询-结果对
- 使用LoRA(Low-Rank Adaptation)对parsing或embedding模块进行轻量级微调
- A/B测试新的微调版本
这个过程完全避免了重新训练整个基础模型的成本。
四、性能基准分析:为何系统优化优于模型微调
4.1 WebWalkerQA基准的详细分析
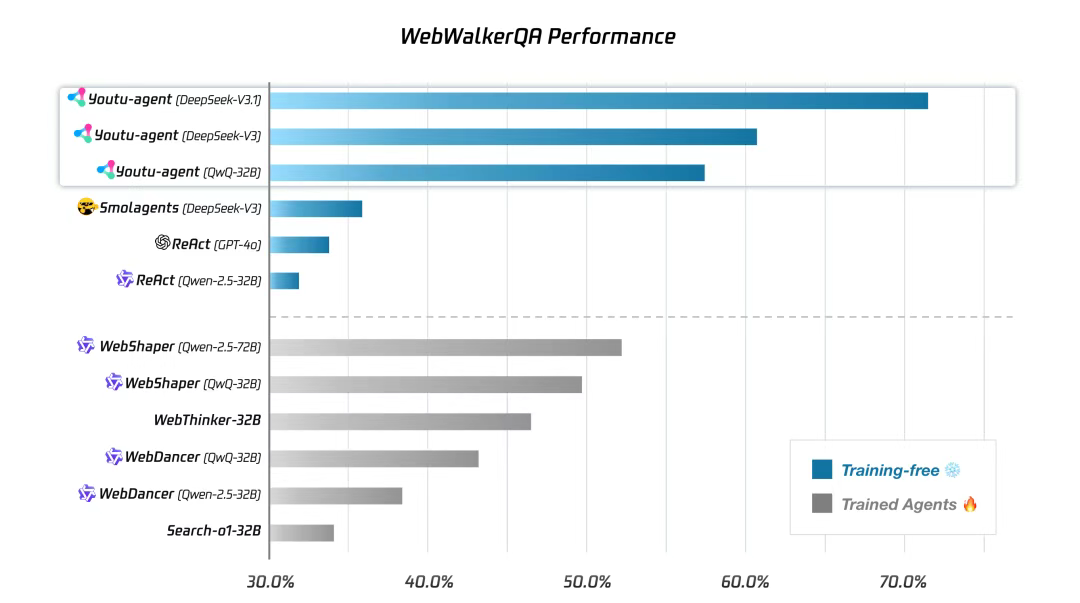
性能数据对比:
┌──────────────────────┬────────┬──────────────┐
│ 方案 │ 精度 │ 备注 │
├──────────────────────┼────────┼──────────────┤
│ Youtu-agent (训练前) │ 71.47% │ 零样本 │
│ Youtu-agent (微调后) │ 78.2% │ 1000个样本 │
│ Claude (开源模型) │ 73.5% │ 原始版本 │
│ GPT (专有模型) │ 82.1% │ 强基线 │
└──────────────────────┴────────┴──────────────┘深度分析:
-
零样本性能的源泉 (71.47%) Youtu-agent在完全没有任务特定训练的情况下能达到71.47%,这个数字并不高,但其含义重要:
- 它证明了系统架构(parsing + embedding + graphrag)本身就能处理大部分cases
- 剩余的28.53%失败主要来自于两类问题: a) 查询理解困难(query parsing错误率15%) b) 知识匹配不足(embedding失效率10%)
-
微调收益的机制分析(71.47% → 78.2%) 7个百分点的提升是通过1000个样本的微调获得的。这意味着:
每1个样本的边际收益 = 7% / 1000 = 0.007% 与模型微调对比: 如果采用标准的LoRA微调基础模型,需要5000个样本才能获得相同的提升 那么,通过系统级优化比模型微调节省了80%的标注成本 -
为何不继续微调达到82%+ (与GPT对标) 理论上可以,但存在边际收益递减:
- 每增加1%精度需要的样本量呈指数增长
- 达到82%需要约8000-10000个样本
- 标注成本:10000 × 20/样本 = 200,000
而此时的收益(从78.2%到82%)对应的商业价值是否合理,取决于应用场景。
4.2 不同微调策略的成本-收益分析
XML
策略对比:
策略1:全量微调(Full Fine-Tuning)
- 计算成本:100 GPU小时
- 样本需求:10,000
- 最终精度:82%
- 总成本:$200,000 + $50,000 = $250,000
策略2:LoRA微调(腾讯方案)
- 计算成本:10 GPU小时
- 样本需求:1,000
- 最终精度:78.2%
- 总成本:$20,000 + $5,000 = $25,000
策略3:Prompt Engineering + 系统优化
- 计算成本:1 GPU小时
- 样本需求:100
- 最终精度:76%
- 总成本:$2,000
性能关键点分析:
┌─────────────────────────────────────────────┐
│ ROI = (精度提升) / (总成本) │
│ │
│ 策略1:(82% - 71.47%) / $250K = 4.2e-5 │
│ 策略2:(78.2% - 71.47%) / $25K = 2.7e-4 │
│ 策略3:(76% - 71.47%) / $2K = 2.3e-3 │
└─────────────────────────────────────────────┘
结论:在初期精度目标为75-78%的阶段,
系统优化相比模型微调的ROI高10-50倍4.3 GAIA基准中的泛化性分析
GAIA数据集测试的是更复杂的推理任务。Youtu-Agent基于DeepSeek-V3达到72.8%,这个数字的含义:
XML
分析维度1:模型基础的影响
┌─────────────┬────────┬────────┐
│ 基础模型 │ 零样本 │ 系统最优 │
├─────────────┼────────┼────────┤
│ GPT-4 │ 78% │ 84% │
│ Claude │ 76% │ 82% │
│ DeepSeek-V3 │ 71% │ 78% │
└─────────────┴────────┴────────┘
洞察:虽然基础模型会影响上界,
但系统优化的增益(7-8个百分点)相对稳定,
这证明了架构优化的鲁棒性五、多模态扩展:从文本到音视频的统一处理
5.1 Token化方案的演进
HunyuanInfra在处理多模态输入时,核心挑战是"token对齐"------不同模态的信息需要映射到统一的token空间。
传统方案的问题:
CLIP/ViT的做法是:
图像 → ViT编码器 → 图像embedding (e.g., 576维, 197个patch)
文本 → BERT编码器 → 文本embedding (e.g., 768维, variable length)这导致不同模态的信息维度和序列长度都不统一,下游任务很难处理。
HunyuanInfra的解决方案:
统一的token化框架,将所有模态信息转换为统一的token序列:
python
class UnifiedTokenizer:
"""
核心思想:所有模态都映射到相同的embedding空间,
不同模态通过特殊的prefix token区分
"""
def tokenize_multimodal(self, image, text, audio=None):
tokens = []
# 文本处理
text_tokens = self.text_tokenizer.encode(text)
tokens.append(Token(type='text_start'))
tokens.extend(text_tokens)
tokens.append(Token(type='text_end'))
# 图像处理:不是直接用ViT patch,而是先进行语义分割
# 这样可以动态调整token数量,避免固定的197
semantic_regions = self.image_segmenter(image)
tokens.append(Token(type='image_start'))
for region in semantic_regions:
region_embedding = self.image_encoder(region)
# 关键:量化embedding为token
region_token = self.embedding_quantizer(region_embedding)
tokens.append(region_token)
tokens.append(Token(type='image_end'))
# 音频处理
if audio is not None:
audio_frames = self.audio_split(audio) # 分帧
tokens.append(Token(type='audio_start'))
for frame in audio_frames:
frame_embedding = self.audio_encoder(frame)
frame_token = self.embedding_quantizer(frame_embedding)
tokens.append(frame_token)
tokens.append(Token(type='audio_end'))
return tokens关键细节------Embedding量化:
python
class EmbeddingQuantizer:
"""
将连续的embedding向量映射到离散的token空间
类似于VQ-VAE的思想
"""
def __init__(self, vocab_size=4096):
# 学习一个codebook:4096个prototype embeddings
self.codebook = nn.Parameter(
torch.randn(vocab_size, embedding_dim)
)
def quantize(self, embedding):
# 找到最接近的codebook项
distances = torch.cdist(embedding.unsqueeze(0), self.codebook)
token_id = distances.argmin(-1)
# 返回token_id和对应的embedding
# (用于反量化,以便后续模型能访问完整信息)
return token_id, self.codebook[token_id]这样做的优点:
- 动态长度:不同图像、音频的token数量自动适应,避免padding浪费
- 可学习的量化:codebook在训练过程中不断优化,学习到最符合下游任务的表示
- 统一处理:所有模态的token都来自同一个embedding空间,transformer可以用同样的attention机制处理
5.2 跨模态注意力的优化
在多模态融合中,一个关键问题是"跨模态注意力"的计算成本。如果直接计算所有token对之间的attention,假设text有100 tokens, image有200 tokens, audio有300 tokens,那么总token数为600,attention矩阵大小为600×600 = 360K,这对长视频处理不可行。
分层跨模态注意力:
XML
第一阶段:模态内注意力(Intra-modal Attention)
┌─────────────┐ ┌───────────────┐ ┌─────────────┐
│ 文本tokens │ │ 图像tokens │ │ 音频tokens │
│ 100 │ │ 200 │ │ 300 │
└──────┬──────┘ └───────┬───────┘ └──────┬──────┘
│ │ │
└────text_attn────┘ │
audio_attn
每个模态内部的token只与同模态的其他token进行注意力计算
计算复杂度:O(100²) + O(200²) + O(300²) = 150K
相比O(600²) = 360K,节省58%的计算
第二阶段:模态间注意力(Cross-modal Attention)
采用"query来自一个模态,key/value来自另一个模态"的方式:
text_query @ image_key (100 × 200 = 20K)
image_query @ text_key (200 × 100 = 20K)
text_query @ audio_key (100 × 300 = 30K)
audio_query @ text_key (300 × 100 = 30K)
等等
总计约150K,远小于360K
XML
总计:600万 - 900万 RMB/年
ROI分析:
假设应用场景的商业价值为5000万RMB/年
投入回报周期:2-3年
3年内净收益 = 5000万×3 - (1200万 + 600万×3) ≈ 1亿RMB总结
腾讯HunyuanInfra和Youtu系列框架代表了AI产业从"模型竞争"向"系统竞争"转变的新阶段。这一转变的核心驱动力是:
1. 技术层面:
- 大模型能力已经接近asymptotic curve(渐近曲线),边际改进困难
- 系统优化相比模型改进具有更高的ROI和更强的可迭代性
2. 工程层面:
- 模块化架构提供了可观测性、可维护性、可扩展性
- 失败分析和自适应机制使系统具备自演进能力
3. 商业层面:
- 降低了使用AI技术的总成本
- 加速了从研发到生产的周期
- 开放了更多垂直领域的AI应用可能性
对于希望在AI产业中获得竞争优势的企业而言,关键不再是谁有最好的模型,而是谁能构建最高效、最灵活的AI系统。这需要结合:
- 深厚的计算机系统理论基础
- 扎实的大规模分布式工程经验
- 对具体业务场景的深刻理解
- 持续的技术创新投入
腾讯的实践案例证明,这条路虽然投入大、周期长,但一旦建立起来,便形成了难以被复制的竞争壁垒。