在最近的一项研究中,来自美国宇航局和IBM的一组研究人员合作开发了一种模型,该模型可应用于地球科学,天文学,物理学,天体物理学,太阳物理学,行星科学和生物学以及其他多学科学科。当前的模型,如 SCIBERT、BIOBERT和SCHOLARBERT仅部分覆盖了其中的一些领域。现有的模型没有充分考虑所有这些相关领域。
为了弥合这一差距,该团队推出了INDUS,这是一套基于LLMs编码器的专门针对这些特定领域的设备。由于INDUS 是根据从各种来源精心挑选的语料库进行培训的,因此可以保证涵盖这些领域的知识体系。INDUS 套件包括多种类型的模型,以满足不同的需求。
在这项研究中,Indus特别关注与地球、天体、太阳和太阳系内的行星相关的跨学科领域,如物理学、地球科学、天体物理学、太阳物理学、行星科学和生物学。虽然现有的特定领域模型(如 scibert、biobert和scholarbert)的训练语料库部分涵盖了其中一些领域,但目前还没有一个特定的模型可以共同涵盖所有感兴趣的领域。Indus,这是一个基于llm Encoder的合集,专注于这些感兴趣的领域,使用来自不同来源的精心策划的语料库进行训练。
具体而言,Indus做到了:
-
利用字节对编码算法IndusBPE,从精选的科学语料库中定制的分词器。
-
利用精心策划的科学语料库和IndusBPE标记器预训练了多个encoder-only的大模型(Indus-base)。通过微调这个编码器模型,使用对比学习目标来学习"通用"句子嵌入(粉色的部分),进而创建了sentence-embedding模型。最后还使用知识蒸馏技术训练了这些模型的更小,更高效的版本(Indus-small)。
-
本次还创建三个新的科学基准数据集,即气候变化ner(实体识别任务)、nasa-qa(抽取式问答任务)和 nasa-ir(检索任务),以进一步加速这一多学科领域的研究。
-
通过实验结果表明模型在这些基准任务以及现有的特定领域基准上具有很强的性能,与原始模型相比,在大多数基准任务中,知识提炼的小模型在延迟方面实现了显着提高,同时保持了强大的经验性能。
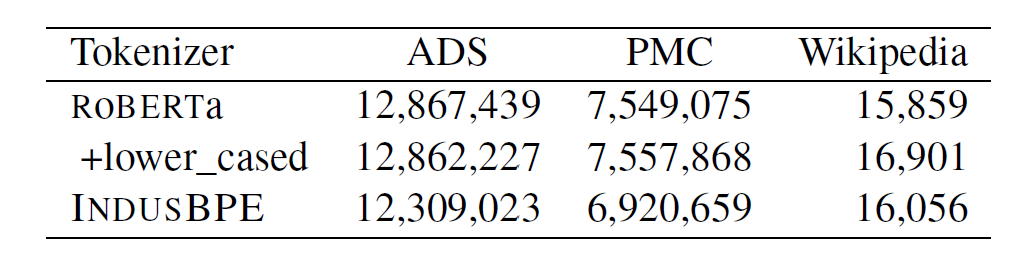
至于训练数据方面,下图左侧是本次的训练语料库的组成部分,右侧对比RoBERTa和IndusBPE Tokenizer的效率,标记越少,计算成本越低。下文为两者切词的对比。
|-----------------------------------------------------------------------------------|-----------------------------------------------------------------------------------|
|  |
|  |
|
-
SAO/NASA ADS:涵盖了天文学和天体物理学、物理学和普通科学领域的出版物,包括所有arXiv。
-
PubMed Central (pmc)是由美国国家医学图书馆和美国国立卫生研究院维护的生物医学和生命科学期刊文献的全文档案。本次使用了pmc中具有商业友好许可证的部分,以及pmc中所有文章的PubMed摘要。
-
美国气象学会 (ams): 使用了涵盖地球系统、地球相互作用、应用气象学和气候学、物理海洋学、大气科学、气候、水文气象学、天气和预报以及社会影响等主题的全文期刊文件。
-
美国地球物理联盟 (agu):数据集包括大气、生物地球科学、地球表面、机器学习和计算、海洋、行星、固体地球和空间物理学等主题的期刊文档。
-
NASA通用元数据存储库 (CMR):是一个高性能、高质量的元数据系统,对NASA地球科学数据和信息系统 (ESDIS)的所有数据和服务元数据记录进行编目。
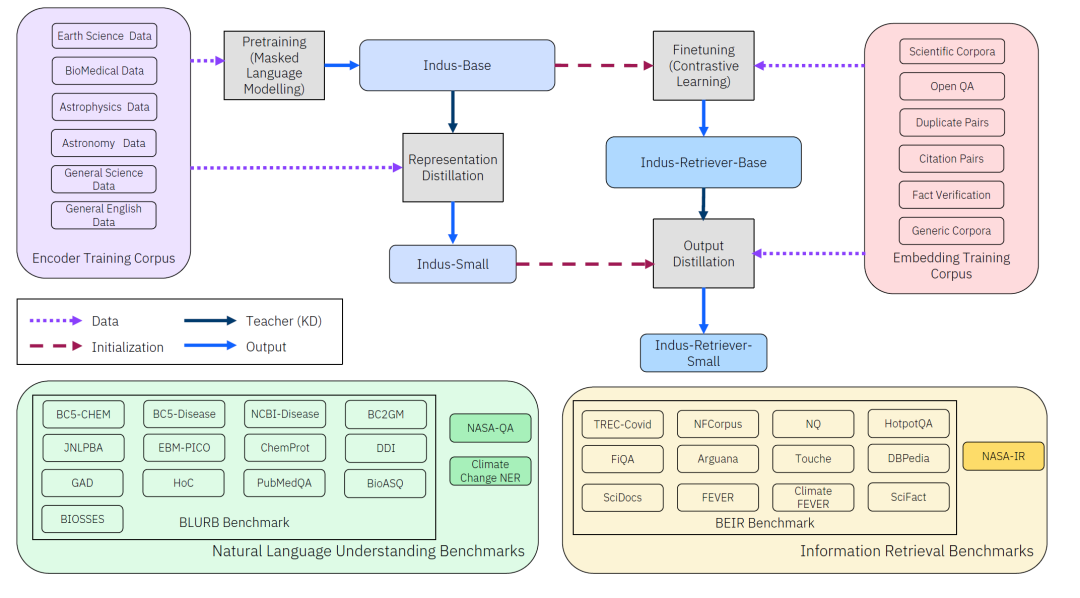
模型的整体架构如上,没有太复杂的地方。唯一值得关注的是利用了知识蒸馏和对比学习,训练出更小的模型,和检索器。
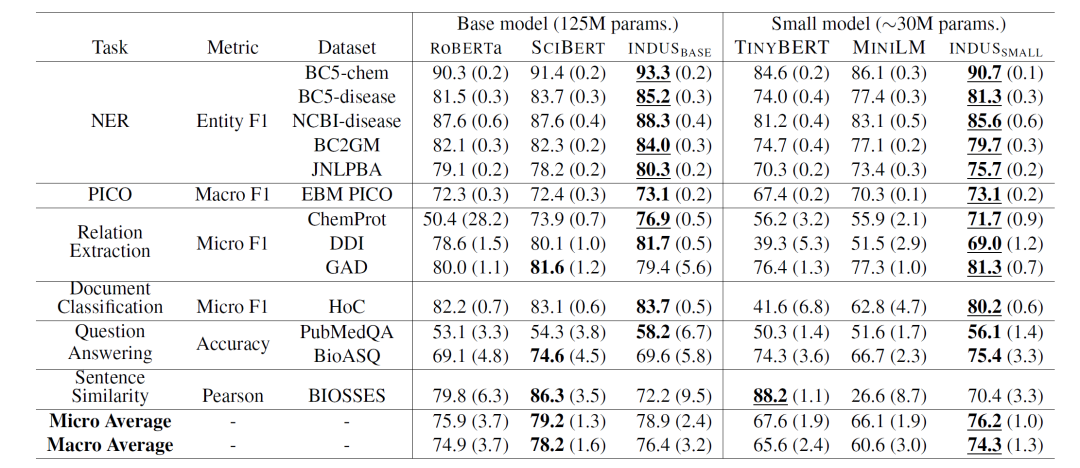
实验结果表明,这些模型在最近创建的基准任务和当前使用的领域特定基准上都表现良好。它们的性能优于特定领域的编码器(如 SCIBERT)和通用模型(如 RoBERTa),关键是整体的体积很小!欢迎大家下载品尝(PC压力不大!!):