原文链接:https://arxiv.org/abs/2403.11761
0. 概述
本文的BEVCar模型是基于环视图像和雷达融合的BEV目标检测和地图分割模型,如图所示。模型的图像分支利用可变形注意力,将图像特征提升到BEV空间中,其中雷达数据用于初始化查询。然后,使用交叉注意力融合图像和雷达特征。最后,降低空间分辨率,并使用多类分类头进行BEV分割(车辆、地图)。
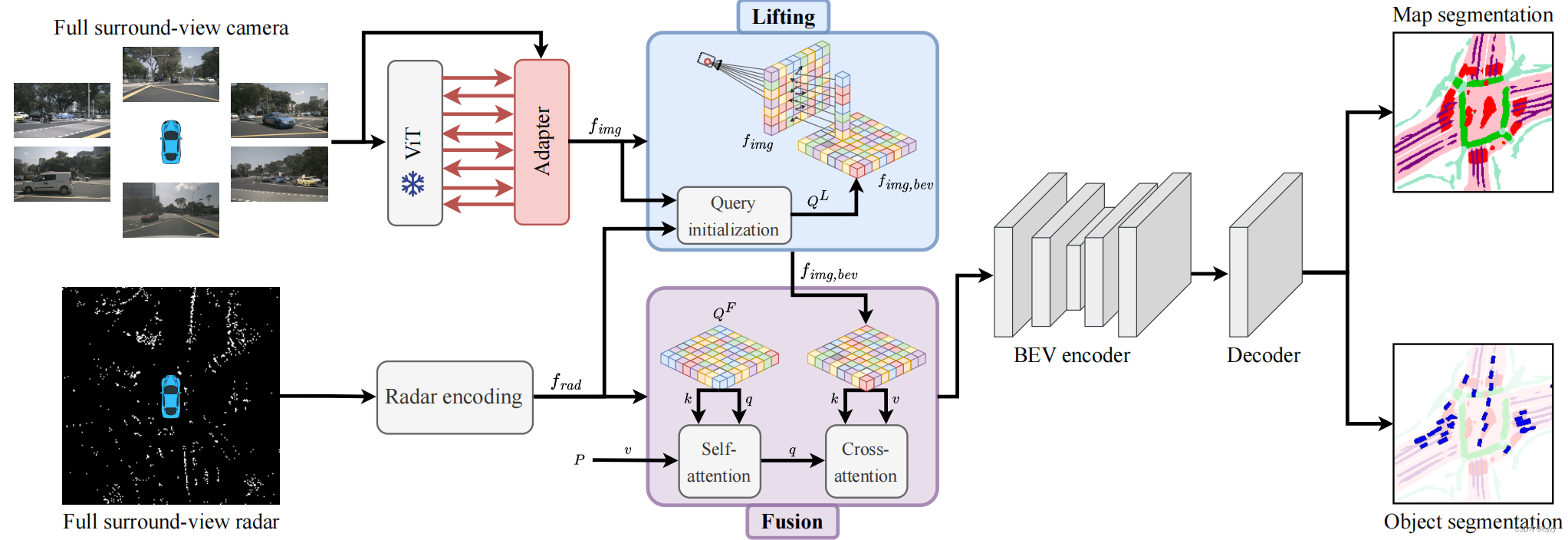
1. 传感器数据编码
摄像头:使用冻结的DINOv2 ViT-B/14(可学权重的ViT适应器),输出多尺度图像特征。
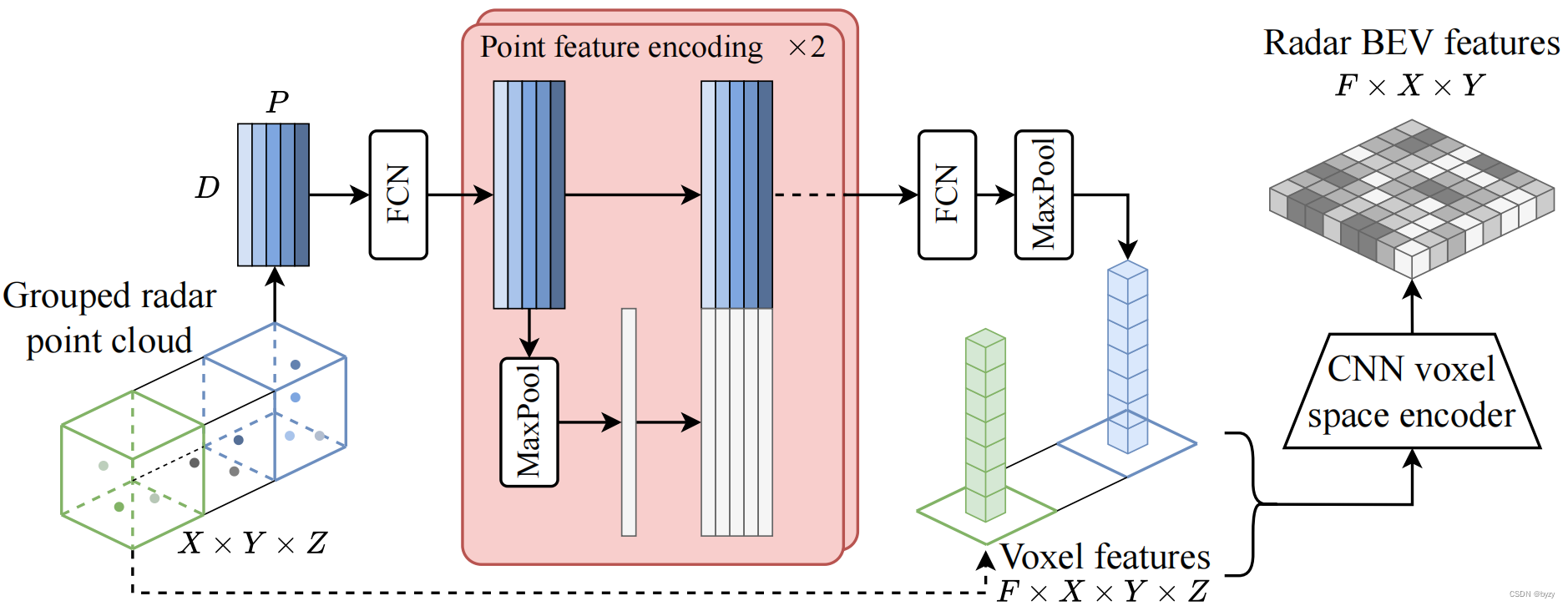
雷达 :类似SparseFusion3D,本文使用的雷达点原始特征包括3D位置 ( x , y , z ) (x,y,z) (x,y,z),未补偿的速度 ( v x , v y ) (v_x,v_y) (vx,vy)和RCS值(捕捉表面的可检测程度)。将点云体素化后,输入下图所示的特征编码模块(FCN表示全连接层,其结构与PointNet类似)。最后将体素特征表达输入体素编码器,压缩高度,得到雷达BEV特征 f r a d f_{rad} frad。
2. 图像特征提升
受BEVFormer启发,本文在可变形注意力的基础上,提出使用稀疏雷达点来初始化查询。
查询初始化:即利用雷达的3D信息初步地将图像特征提升到BEV。首先初始化以前视相机为中心的3D体素,将每个体素与一个或两个视图关联,然后根据射线投射将图像特征提升到3D(关联多个视图的体素,其特征取平均)。
注:此步骤与LSS的方法不同,因其考虑了每个像素的大小(如图,射线经过区域的部分相邻区域也被标记为同一颜色)。因此,实际上该方法更接近Simple-BEV(其中双线性采样被替换为最近邻采样)。
最后使用 1 × 1 1\times 1 1×1卷积压缩高度,得到 X × Y × F X\times Y\times F X×Y×F的特征。然后,使用雷达指导的可变形注意力得到 X × Y × F X\times Y\times F X×Y×F的初始化查询 Q i m g L Q_{img}^L QimgL。
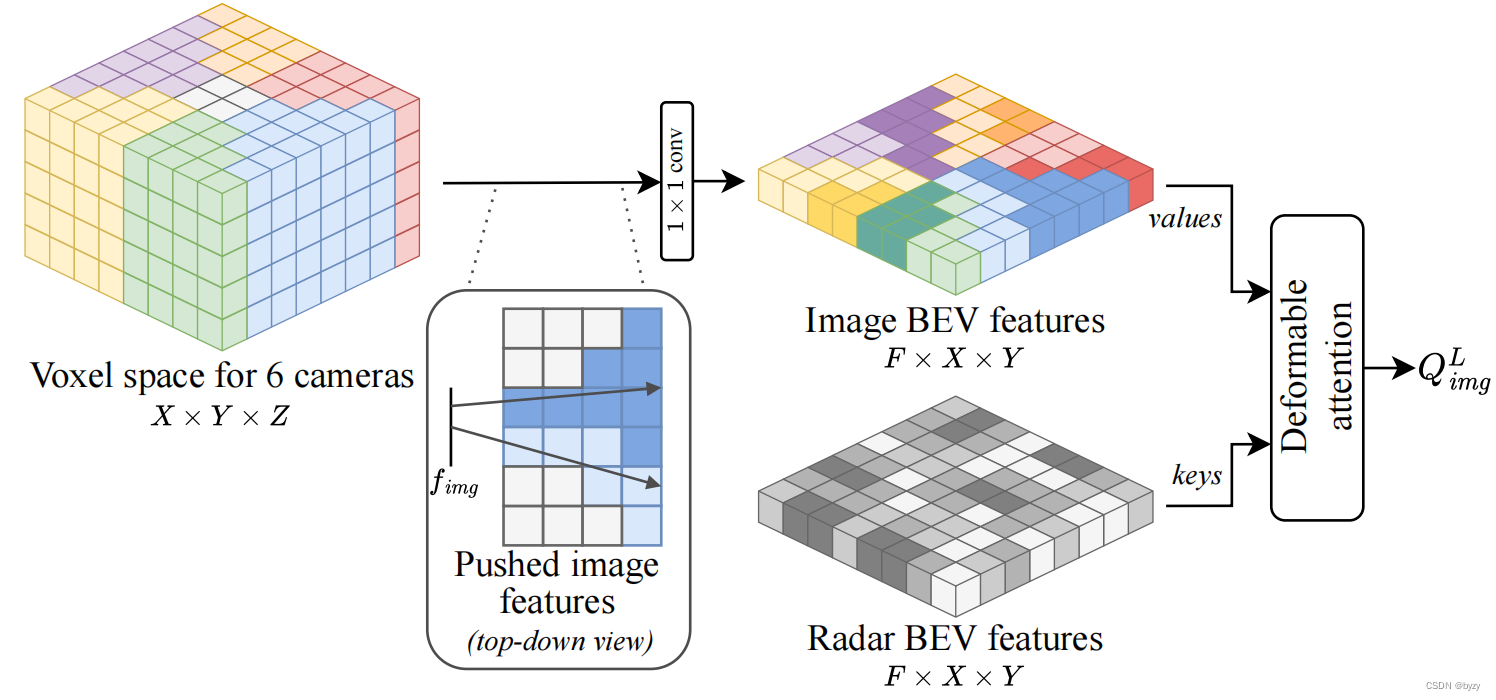
提升 :将初始化查询 Q i m g L Q_{img}^L QimgL与可学习位置编码 Q p o s L Q_{pos}^L QposL和可学习查询 Q b e v L Q_{bev}^L QbevL求和得到 Q L Q^L QL,再使用可变形注意力从图像进行特征采样,得到最终的图像BEV特征。
此处可变形注意力的查询参考点如何确定?文中提到再次建立 X × Y × Z X\times Y\times Z X×Y×Z的体素空间,是否同一BEV位置、不同高度的体素对应的查询均相同(为对应的BEV查询),而参考点为体素在图像上的投影?
3. 传感器融合
类似TransFusion,本文查询雷达点周围的图像特征,并使用可变形注意力提取特征。本文将 f r a d f_{rad} frad,可学习位置编码 Q p o s F Q_{pos}^F QposF和可学习BEV查询 Q b e v F Q_{bev}^F QbevF求和,得到 Q F Q^F QF,然后将图像特征作为交叉注意力的键与值,并将输出送入BEV编码器。
4. BEV分割头
本文为多类BEV分割使用单一任务头。具体来说,使用卷积网络输出1个物体类别和 M M M个地图元素类别,输出的大小为 ( M + 1 ) × X × Y (M+1)\times X\times Y (M+1)×X×Y(注意一个像素可以同时属于多种类别)。
目标检测:本文考虑所有车辆。使用二元交叉熵损失监督:
L B C E = − 1 N ∑ i = 1 N log ( p i , t ) L_{BCE}=-\frac1N\sum_{i=1}^N\log(p_{i,t}) LBCE=−N1i=1∑Nlog(pi,t)
其中
p i , t = { p i 若 y i = 1 1 − p i 否则 p_{i,t}=\begin{cases}p_i&若y_i=1\\1-p_i&否则\end{cases} pi,t={pi1−pi若yi=1否则
y i ∈ { 0 , 1 } y_i\in\{0,1\} yi∈{0,1}表示像素 i i i是否属于车辆类别, p i p_i pi为预测 y i = 1 y_i=1 yi=1的概率。
地图分割 :本文使用 α \alpha α平衡的多类别focal损失:
F F O C = ∑ c = 1 C − 1 N ∑ i = 1 N α i , t ( 1 − p i , t ) γ log ( p i , t ) F_{FOC}=\sum_{c=1}^C-\frac1N\sum_{i=1}^N\alpha_{i,t}(1-p_{i,t})^\gamma\log(p_{i,t}) FFOC=c=1∑C−N1i=1∑Nαi,t(1−pi,t)γlog(pi,t)
其中 c c c为语义类别编号, γ \gamma γ为区分简单/困难样本的聚焦参数。 α i , t \alpha_{i,t} αi,t类似 p i , t p_{i,t} pi,t的定义:
α i , t = { α 若 y i = 1 1 − α 否则 \alpha_{i,t}=\begin{cases}\alpha&若y_i=1\\1-\alpha&否则\end{cases} αi,t={α1−α若yi=1否则
其中 α \alpha α处理前景/背景的不平衡性。