
1.爬虫简介
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。
你可以简单地想象:每个爬虫都是你的"分身"。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样。你每天使用的百度,其实就是利用了这种爬虫技术:每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。
抢票软件,就相当于撒出去无数个分身,每一个分身都帮助你不断刷新 12306 网站的火车余票。一旦发现有票,就马上拍下来,然后对你喊:土豪快来付款。
互联网就像一张网,中间以各种链接连接在一起,而小小的爬虫却能在这张网上欢快的驰骋,代替人来进行很多繁重的任务,如抢票软件、某度搜索引擎。
2.为什么用python做网页爬虫
python作为一门易上手的语言,提供了丰富的API来抓取网页文档、模拟浏览器行为、对抓取到的数据进行处理。后面我们的演示中也会展示python爬虫的简介,爬取网页内容的核心代码可能只有短短几行,却能实现强大的功能。
3.python环境配置
对于新手来说,最熟悉的还是windows环境。我使用的是anaconda+pycharm进行python代码的编写,这里anaconda方便进行外部库的管理,而pycharm也是功能强大很流行的一款IDE。
4.我需要了解哪些python爬虫的前置知识
至少会一点python的基础知识,如果不清楚的话,可以参加浙大翁恺的python慕课,或者自己找些介绍文档,如 python入门教程。同时需要了解关于html的一些基础知识,比如各种标签代表的含义:
<!--...-->:定义注释
<!DOCTYPE> :定义文档类型
<html>:html文档的总标签
<head>:定义头部
<body>:定义网页内容
<script>:定义脚本
<div>:division,定义分区,容器标签
<p>:paragraph,定义段落
<a>:定义超链接
<span>:定义文本容器
<br>:换行
<form>:定义表单
<table>:定义表格
<th>:定义表头
<tr>:表的行
<td>:表的列
<b>:定义粗体字
<img>:定义图片
熟悉上面这些html标签将会方便我们进行正则表达式的处理,以及xPath和BeautifulSoup的学习。
- 关于正则表达式
python正则表达式相关知识较多,我们只需要了解一些基础的即可,如:
6.提取网页内容并用正则表达式处理
import re
import urllib.request
import chardet
response=urllib.request.urlopen("http://news.hit.edu.cn/")#输入参数为你想爬取的网页URL
html=response.read() #读取到html变量中
chardet1=chardet.detect(html) #获取编码方式
html=html.decode(chardet1['encoding']) #按照获取到的编码方式进行处理这里我们以某高校的官方新闻网站为例演示来进行python爬虫操作,上面短短的几行代码就实现了将网页内容爬取到本地的操作。
接着就是对爬取到的内容进行正则表达式处理,得到我们想要获取的内容,观察网页源代码:

我们希望对其中的外部链接进行匹配,由之前了解到的正则表达式知识,实现如下:
mypatten="<li class=\"link-item\"><a href=\"(.*)\"><span>(.*)</span></a></li>"
mylist=re.findall(mypatten,html)
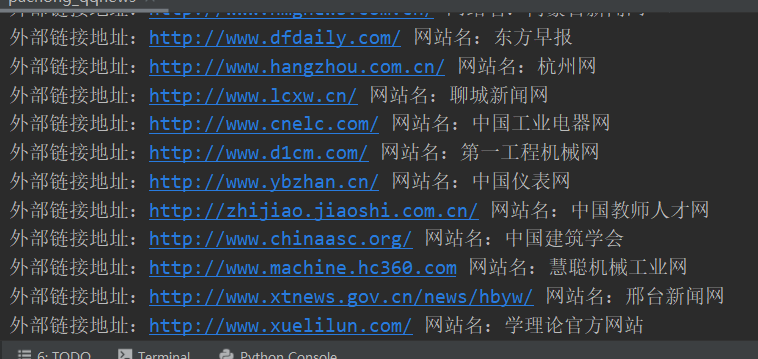
for i in mylist:
print("外部链接地址:%s 网站名:%s" %(i[0],i[1]))最后得到的效果是:
7.xPath和BeautifulSoup工具简介
除了用正则表达式处理得到的网页文档之外,我们还可以考虑网页自身的架构。
XPath,全称 XML Path Language,即 XML 路径语言,它是一门在XML文档中查找信息的语言。XPath 最初设计是用来搜寻XML文档的,但是它同样适用于 HTML 文档的搜索。
nodename选取此节点的所有子节点
/从当前节点选取直接子节点
//从当前节点选取子孙节点
.选取当前节点
..选取当前节点的父节点
@选取属性
在这里列出了XPath的常用匹配规则,例如 / 代表选取直接子节点,// 代表选择所有子孙节点,. 代表选取当前节点,.. 代表选取当前节点的父节点,@ 则是加了属性的限定,选取匹配属性的特定节点。
from lxml import etree
import urllib.request
import chardet
response=urllib.request.urlopen("https://www.dahe.cn")
html=response.read()
chardet1=chardet.detect(html)
html=html.decode(chardet1['encoding'])
etreehtml=etree.HTML(html)
mylist=etreehtml.xpath("/html/body/div/div/div/div/div/ul/div/li")BeautifulSoup4是爬虫必学的技能。BeautifulSoup最主要的功能是从网页抓取数据,Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐使用lxml 解析器。
from bs4 import BeautifulSoup
file = open('./aa.html', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser") # 缩进格式
print(bs.prettify()) # 格式化html结构
print(bs.title) # 获取title标签的名称
print(bs.title.name) # 获取title标签的文本内容
print(bs.title.string) # 获取head标签的所有内容
print(bs.head) # 获取第一个div标签中的所有内容
print(bs.div) # 获取第一个div标签的id的值
print(bs.div["id"]) # 获取第一个a标签中的所有内容
print(bs.a) # 获取所有的a标签中的所有内容
print(bs.find_all("a")) # 获取id="u1"
print(bs.find(id="u1")) # 获取所有的a标签,并遍历打印a标签中的href的值
for item in bs.find_all("a"):
print(item.get("href")) # 获取所有的a标签,并遍历打印a标签的文本值
for item in bs.find_all("a"):
print(item.get_text())最后: 如果你对Python感兴趣,想要学习Python,希望可以帮到你,一起加油!以上是给大家分享的Python全套学习资料,都是我自己学习时整理的:
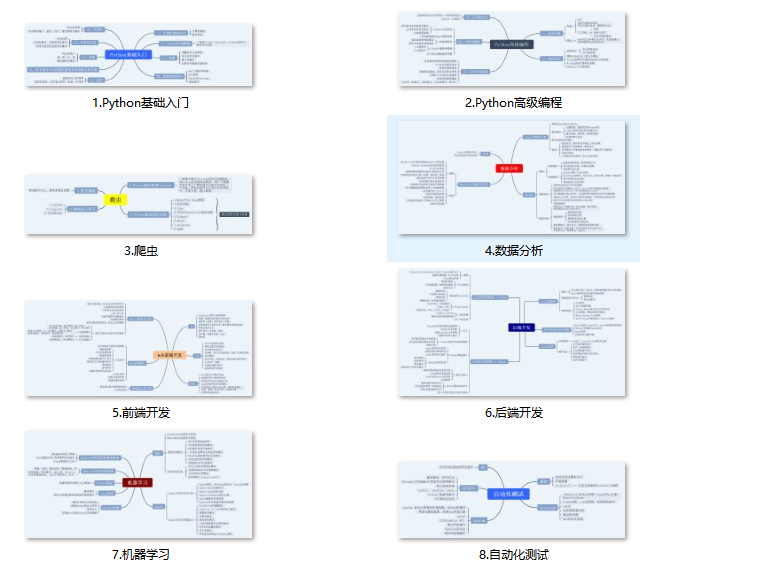
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,还有环境配置的教程,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频全套
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
**学习资源已打包,需要的小伙伴可以戳这里:【学习资料】