任务描述
测试Hadoop集群的可用性
任务指导
-
在Web UI查看HDFS和YARN状态
-
测试HDFS和YARN的可用性
任务实现
1. 在Web UI查看HDFS和YARN状态
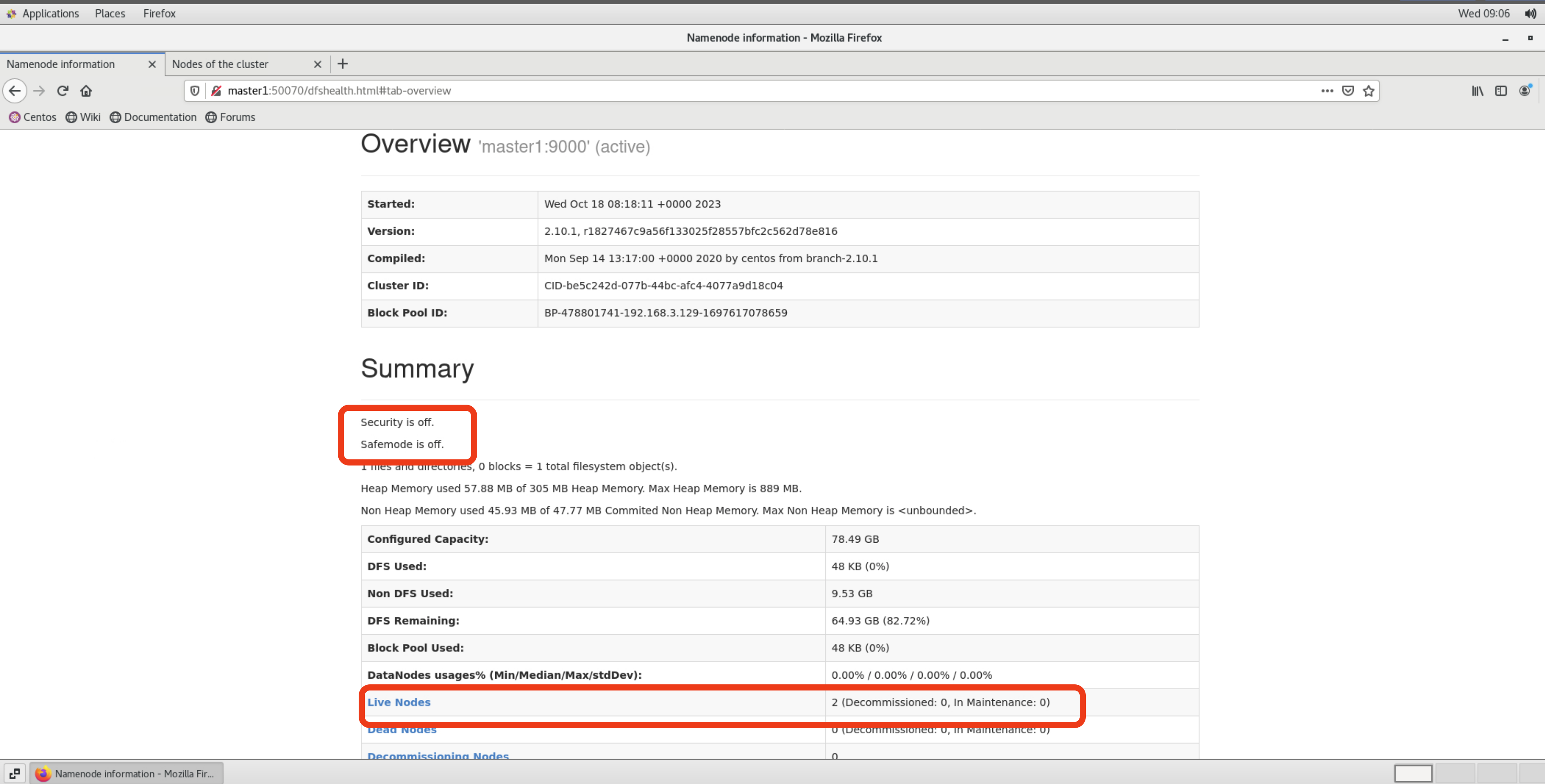
在【master1】打开Web浏览器访问Hadoop其中HDFS NameNode对应的Web UI地址如下:
++http://master1:50070++
如下图HDFS自检成功,已退出安全模式代表着可以对HDFS进行读写;集群中有2个【Live Nodes】可用来存储数据
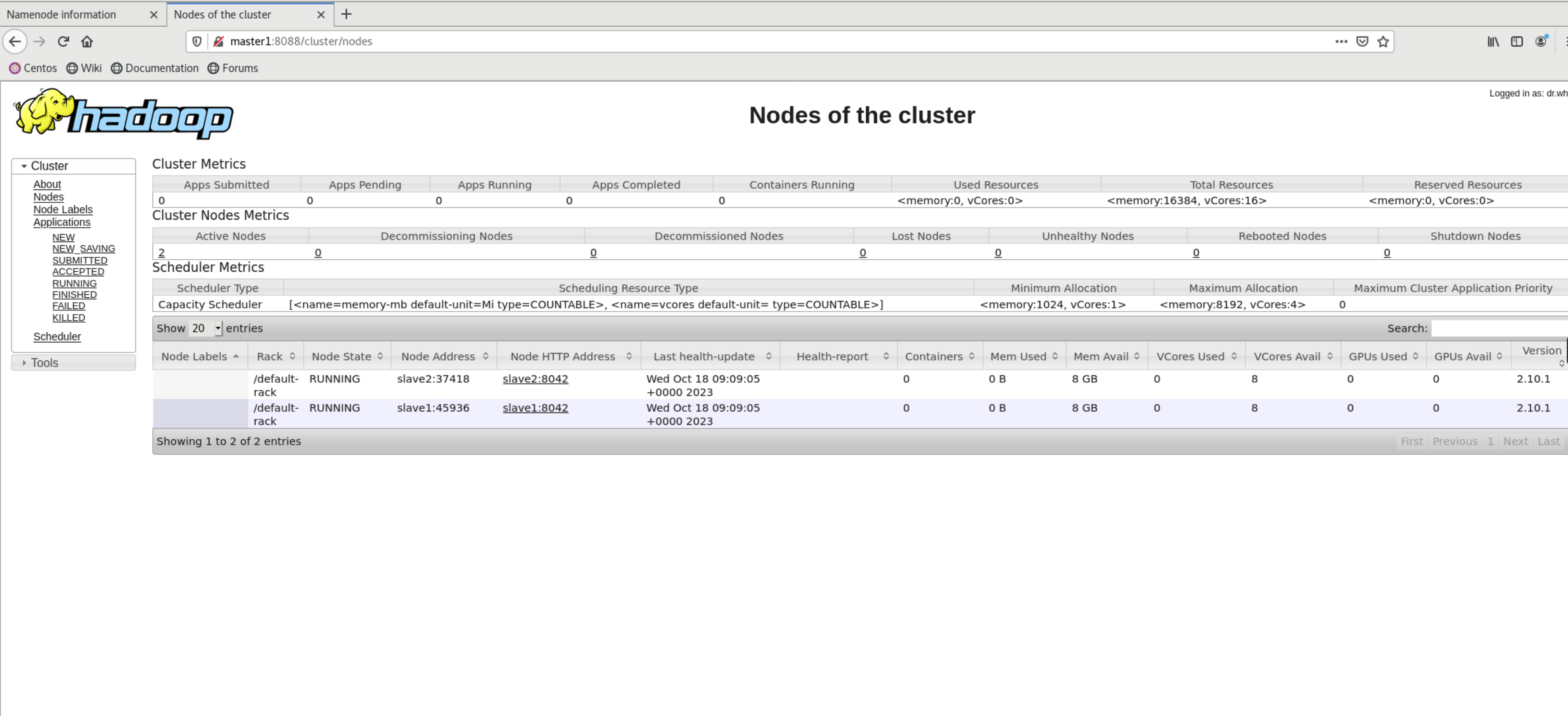
YARN ResourceManager对应的Web UI地址如下:
++http://master1:8088++
如下图YARN集群启动成功,集群中有两个节点【slave1、slave2】可供用来执行计算任务:
2. 测试HDFS和YARN的可用性
在HDFS创建目录
[root@master1 ~]# hdfs dfs -mkdir /input将本地的文本文件上传到HDFS
[root@master1 ~]# cd $HADOOP_HOME
[root@master1 hadoop-2.10.1]# hdfs dfs -put README.txt /input执行Hadoop自带的测试程序WordCount,此程序将统计输入目录下所有文件中的单词数量:
[root@master1 hadoop-2.10.1]# cd $HADOOP_HOME
[root@master1 hadoop-2.10.1]# cd share/hadoop/mapreduce
[root@master1 mapreduce]# yarn jar hadoop-mapreduce-examples-2.10.1.jar wordcount /input /output执行结果如下:
[root@master1 mapreduce]# yarn jar hadoop-mapreduce-examples-2.10.1.jar wordcount /input /output
23/10/18 09:50:56 INFO client.RMProxy: Connecting to ResourceManager at master1/192.168.3.129:8032
23/10/18 09:50:56 INFO input.FileInputFormat: Total input files to process : 1
23/10/18 09:50:56 INFO mapreduce.JobSubmitter: number of splits:1
23/10/18 09:50:57 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1697619784960_0001
23/10/18 09:50:57 INFO conf.Configuration: resource-types.xml not found
23/10/18 09:50:57 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
23/10/18 09:50:57 INFO resource.ResourceUtils: Adding resource type - name = memory-mb, units = Mi, type = COUNTABLE
23/10/18 09:50:57 INFO resource.ResourceUtils: Adding resource type - name = vcores, units = , type = COUNTABLE
23/10/18 09:50:57 INFO impl.YarnClientImpl: Submitted application application_1697619784960_0001
23/10/18 09:50:57 INFO mapreduce.Job: The url to track the job: http://master1:8088/proxy/application_1697619784960_0001/
23/10/18 09:50:57 INFO mapreduce.Job: Running job: job_1697619784960_0001
23/10/18 09:51:04 INFO mapreduce.Job: Job job_1697619784960_0001 running in uber mode : true
23/10/18 09:51:04 INFO mapreduce.Job: map 100% reduce 0%
23/10/18 09:51:06 INFO mapreduce.Job: map 100% reduce 100%
23/10/18 09:51:06 INFO mapreduce.Job: Job job_1697619784960_0001 completed successfully
23/10/18 09:51:06 INFO mapreduce.Job: Counters: 52
File System Counters
FILE: Number of bytes read=3704
FILE: Number of bytes written=5572
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=2992
HDFS: Number of bytes written=439695
HDFS: Number of read operations=41
HDFS: Number of large read operations=0
HDFS: Number of write operations=16
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Other local map tasks=1
Total time spent by all maps in occupied slots (ms)=0
Total time spent by all reduces in occupied slots (ms)=0
TOTAL_LAUNCHED_UBERTASKS=2
NUM_UBER_SUBMAPS=1
NUM_UBER_SUBREDUCES=1
Total time spent by all map tasks (ms)=428
Total time spent by all reduce tasks (ms)=1202
Total vcore-milliseconds taken by all map tasks=0
Total vcore-milliseconds taken by all reduce tasks=0
Total megabyte-milliseconds taken by all map tasks=0
Total megabyte-milliseconds taken by all reduce tasks=0
Map-Reduce Framework
Map input records=31
Map output records=179
Map output bytes=2055
Map output materialized bytes=1836
Input split bytes=101
Combine input records=179
Combine output records=131
Reduce input groups=131
Reduce shuffle bytes=1836
Reduce input records=131
Reduce output records=131
Spilled Records=262
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=10
CPU time spent (ms)=1560
Physical memory (bytes) snapshot=812826624
Virtual memory (bytes) snapshot=6216478720
Total committed heap usage (bytes)=562036736
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=1366
File Output Format Counters
Bytes Written=4540查看结果目录
[root@master1 mapreduce]# hdfs dfs -ls /output回显如下
[root@master1 mapreduce]# hdfs dfs -ls /output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2023-10-18 09:51 /output/_SUCCESS
-rw-r--r-- 2 root supergroup 1306 2023-10-18 09:51 /output/part-r-00000其中【_SUCCESS】文件为标识文件,代表任务执行成功,以【part-r-】为前缀的文件为Reduce的输出文件,【part-r-XXXXX】文件个数与MapReduce中的Reduce个数对应,执行如下命令查看结果
[root@master1 mapreduce]# hdfs dfs -cat /output/part-r-*结果如下:
[root@master1 mapreduce]# hdfs dfs -cat /output/part-r-*
(BIS), 1
(ECCN) 1
(TSU) 1
(see 1
5D002.C.1, 1
740.13) 1
<http://www.wassenaar.org/> 1
Administration 1
Apache 1
BEFORE 1
BIS 1
Bureau 1
Commerce, 1
Commodity 1
Control 1
Core 1
Department 1
ENC 1
Exception 1
Export 2
For 1
Foundation 1
Government 1
Hadoop 1
Hadoop, 1
Industry 1
Jetty 1
License 1
Number 1
Regulations, 1
SSL 1
.
.
.
略由此证明HDFS和YARN可以正常运行。