该论文提出了一个新的框架,用于在强模型和弱模型之间进行查询路由选择。通过学习用户偏好数据,预测强模型获胜的概率,并根据成本阈值来决定使用哪种模型处理查询 。该研究主要应用于大规模语言模型(LLMs)的实际部署中,通过智能路由在保证响应质量的前提下显著降低成本。
通过创新的路由框架和算法,有效地在强模型和弱模型之间进行查询路由选择,大幅度降低了成本,同时保持了响应质量。

图是dalle生成的,看着还不错
论文创新

- 矩阵分解方法:采用了推荐系统中的矩阵分解技术,通过训练偏好数据来揭示隐藏的评分函数,从而确定不同模型对查询的质量 。
- BERT分类器:使用了标准的文本分类方法,通过全参数微调BERT模型来进行查询路由决策 。
- 因果LLM分类器:通过参数化Llama 3模型,并采用指令跟随范式来预测查询的胜率 。
性能提升的量化数据
使用来自Chatbot Arena的80k对战数据作为训练数据,进一步通过增强数据集(如MMLU验证集和GPT-4评审数据)来提高路由器性能。在多个基准上评估路由器的性能,包括开放式问答、文科和数学问题,展示了路由器在不同数据集上的广泛适应性和优越性能 。
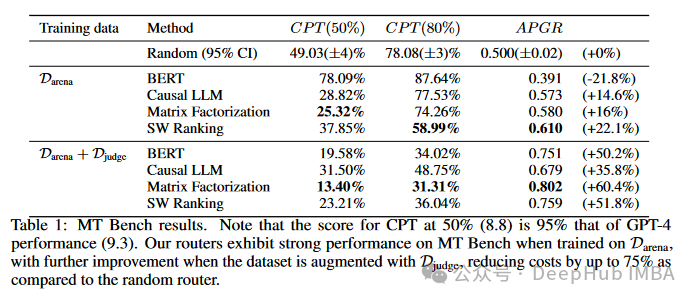
在MT Bench基准测试中,使用Darena数据集训练的因果LLM路由器相比随机路由器,能够将所需调用强模型的比例从49.03%降低到28.82%,并且在增强数据集(Djudge)后,进一步降低到31.50%。APGR(平均性能提升)也从0.573提高到0.679,表现出14.6%到35.8%的改进。类似地,矩阵分解路由器在增强数据集后,APGR达到了0.802,展示了60.4%的显著提升。
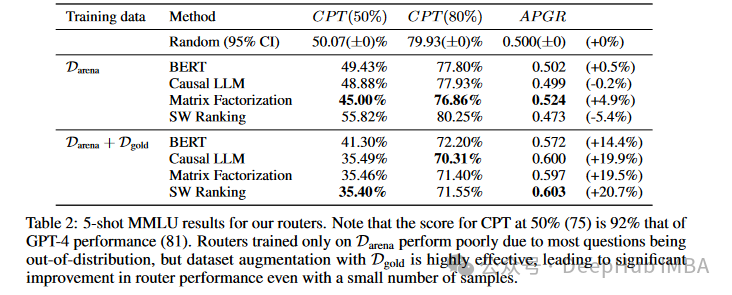
在MMLU测试中,所有路由器在仅使用Darena数据集训练时表现较差,但通过增强数据集(Dgold),性能显著提升。例如,因果LLM路由器的CPT(50%)从56.09%降低到35.49%,APGR从0.461提高到0.600,显示了19.9%的改进。同样,矩阵分解路由器的CPT(50%)从53.59%降至35.46%,APGR提高到0.597,表现出19.5%的提升。
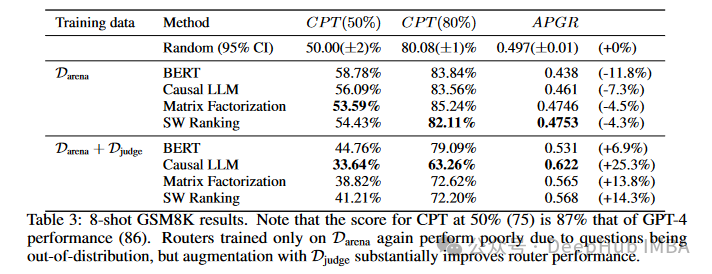
在GSM8K测试中,使用增强数据集后的因果LLM路由器,CPT(50%)从56.09%下降到33.64%,APGR从0.461提高到0.622,展现了25.3%的显著改进。矩阵分解路由器的CPT(50%)也从53.59%降至38.82%,APGR提高到0.565,表现出13.8%的提升。
这些结果表明,方法在优化成本与响应质量平衡方面具有显著优势,并展示了在不同数据集和模型组合上的广泛适应性和高效性。
论文要点
1、路由模型的训练
在路由模型的训练过程中,研究人员使用了几种具体的数据增强技术。首先,他们利用了带有黄金标签的数据集,如MMLU验证集。这些数据集包含自动计算的正确答案,例如多项选择题的答案,这些答案被用来生成偏好数据,从而增强训练数据的质量和数量。此外,他们还使用了LLM评审数据集,这些数据集通过一个强大的语言模型(如GPT-4)作为评审者,对一系列用户查询进行响应,并生成强模型和弱模型的对比标签。通过这种方式,他们能大规模生成有代表性的偏好标签,尽管这种方法成本较高,但通过选择具有代表性的查询可以显著降低成本。
为了确保人类偏好数据的代表性,研究人员采取了多项措施。首先,他们使用了来自Chatbot Arena平台的广泛用户查询数据,这些数据涵盖了超过100种语言,确保了数据的多样性和广泛性。此外,他们通过动态编程将模型划分为不同的层级,基于每个模型在Chatbot Arena排行榜上的Elo评分,最大限度地减少每层内的变异性。这种分层和聚类方法帮助他们在强模型和弱模型之间取得代表性和均衡性。
研究人员还对原始数据进行了去重和筛选,减少标签稀疏性,确保每个偏好标签在训练数据中的代表性。通过结合带有黄金标签的数据集和通过GPT-4生成的偏好数据,他们进一步增强了训练数据的代表性和可靠性。这种多重保障措施确保了训练数据的多样性、代表性和准确性,使得训练出来的路由模型能够在保证高质量响应的前提下,显著降低成本,并具有良好的泛化能力。
2、如何在实际应用中确定强弱模型之间的成本效益最佳点
在实际应用中,确定强弱模型之间的成本效益最佳点需要综合考虑多个因素。研究人员通过设置不同的成本阈值来评估强模型和弱模型在各种查询上的性能差异。在训练过程中,路由模型通过学习用户偏好数据,预测强模型获胜的概率,并根据这些预测在给定的成本限制下动态调整路由决策。通过这种方法,可以找到在不显著降低响应质量的前提下,实现成本最低的模型组合。
为了具体确定成本效益最佳点,研究人员使用了多种评估指标,例如CPT(调用强模型的最小比例)和APGR(平均性能提升)。这些指标帮助量化不同模型在各类查询下的表现,并通过实验验证找到最佳的成本效益点。例如,在评估中发现,矩阵分解路由器和相似度加权排序路由器在不同数据集上的表现,展示了在保持高质量响应的同时,显著减少调用强模型的比例。
路由模型在不同应用场景中的适应性表现出色。首先,研究人员在多个公认的基准上对模型进行了评估,包括开放式问答、文科和数学问题。这些基准测试展示了路由模型在处理不同类型任务时的灵活性和高效性。此外,通过引入数据增强技术,如黄金标签数据集和LLM评审数据集,路由模型在训练数据和实际应用数据之间的分布差异得到了有效的弥补,从而提高了模型的泛化能力。
在具体应用场景中,路由模型的适应性还体现在其能够动态调整路由策略,以应对不同复杂度的查询。例如,对于简单查询,模型能够选择较为廉价的弱模型处理,从而节约成本;而对于复杂查询,模型则选择强模型处理,以确保响应质量。通过这种灵活的调整机制,路由模型在实际应用中不仅能够显著降低成本,还能保持高质量的用户体验。综上所述,路由模型在不同应用场景中的适应性和成本效益平衡得到了充分验证,展示了其在实际部署中的巨大潜力。
3、路由模型的迁移学习能力
路由模型的迁移学习能力体现在其在测试时强弱模型发生变化的情况下,仍能保持稳定性能的机制。该机制主要依赖于模型在训练过程中所学习到的通用特性,而不是对特定模型的依赖。具体来说,路由模型通过学习大量用户查询和相应的模型偏好数据,能够识别查询的复杂度和不同模型的相对优势。这种学习过程使模型能够在面对新的强弱模型组合时,依然能够根据查询的特性进行适当的路由决策。
在训练过程中,研究人员通过使用多种数据增强技术,如黄金标签数据集和LLM评审数据集,进一步丰富和多样化了训练数据。这些技术帮助模型捕捉到更多样化的查询和模型响应模式,从而提高了模型的泛化能力和适应性。此外,研究人员在训练过程中对模型进行了多层次的聚类和分层处理,确保了训练数据的广泛代表性。这些方法共同作用,使得路由模型能够在面对新的模型组合时,依然能保持高效的性能和稳定的表现。
关于是否有计划测试更多不同组合的模型以验证迁移学习能力,研究人员确实有这样的计划。当前的实验已经展示了路由模型在一些常见模型组合上的强大适应能力,但为了进一步验证和提高模型的迁移学习能力,研究人员计划在未来的研究中引入更多不同的模型组合进行测试。这些测试将包括不同规模、不同架构和不同训练数据的模型,通过在更广泛的模型组合上验证路由模型的性能,进一步证明其在实际应用中的广泛适用性和鲁棒性。
路由模型的迁移学习能力依赖于其在训练过程中对通用特性的学习和多样化数据的使用,这使得模型在面对新的强弱模型组合时,仍能保持稳定的性能表现。研究人员也计划通过更多不同模型组合的测试,进一步验证和提升模型的迁移学习能力。
总结
这篇论文提出了一种新的路由框架,通过动态选择强弱大型语言模型(LLMs)来优化成本与响应质量的平衡。研究表明,大型语言模型在各种自然语言任务中表现出色,但更强大的模型成本高昂,而较弱的模型则更具成本效益。本文提出的路由模型利用人类偏好数据和数据增强技术,能够智能地在推理时选择适当的模型处理查询,从而显著降低成本,同时保持高质量的响应。
路由模型的迁移学习能力也得到了验证,即使在测试时强弱模型发生变化,模型仍能保持稳定的性能表现。这主要归功于模型在训练过程中学习到的通用特性和丰富多样的训练数据。研究人员计划在未来引入更多不同的模型组合进行测试,以进一步验证和提高模型的迁移学习能力。
总的来说,这篇论文展示了一种高效、灵活且具有广泛适应性的LLM路由框架,通过智能选择模型,达到了成本和性能的最佳平衡,为实际部署LLMs提供了一种高性价比的解决方案。
https://avoid.overfit.cn/post/58a7809e80ad42bbb1425b8eff261837