任务描述
到目前为止,我们已经将数据采集到了HBase集群中,接下来需要对采集到的数据进行分析,统计出想要的结果。分析过程使用MapReduce的方式,注意,一个业务指标不一定对应一个mapreduce-job,根据业务需要,会采取一个MapReduce分析多个业务指标的方式来完成任务。
任务指导
分析模块的流程图如下:
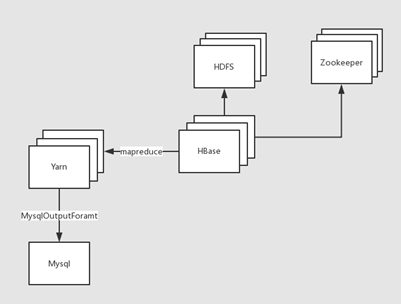
业务目标:
a) 用户每天主叫通话数量统计,通话时间统计。
b) 用户每月通话记录统计,通话时间统计。
c) 用户之间亲密关系统计。(通话次数与通话时间体现用户亲密关系,学生独自完成)
任务实现
数据库安装在【master1】,可通过命令【mysql -uroot -pQst@123456】进入MySQL命令行
1、 MySQL表结构设计
在这里需要将分析的结果数据保存到MySQL中,方便Web端查询展示。根据业务需要,MySQL的表设计如下(对应数据库 db_telecom):
建库语句如下:
CREATE DATABASE `db_telecom` /*!40100 DEFAULT CHARACTER SET utf8 */;1) 表tb_contacts:用户存放用户手机号码与联系人姓名。
|-----------|-----------------------|--------|
| 列名 | 类型 | 备注 |
| id | int(11) NOT NULL | 自增长、主键 |
| telephone | varchar(255) NOT NULL | 手机号 |
| name | varchar(255) NOT NULL | 联系人姓名 |
建表语句如下:
USE `db_telecom`;
CREATE TABLE `tb_contacts` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`telephone` varchar(255) NOT NULL,
`name` varchar(255) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;2) 表tb_call:用于存放某个时间维度下通话次数、通话时长的总和。
|-------------------|----------------------------|----------------------|
| 列名 | 类型 | 备注 |
| id_date_contact | varchar(255) NOT NULL | 复合主键(联系人维度id,时间维度id) |
| id_date_dimension | int(11) NOT NULL | 时间维度id |
| id_contact | int(11) NOT NULL | 查询人的电话号码 |
| call_sum | int(11) NOT NULL DEFAULT 0 | 通话次数总和 |
| call_duration_sum | int(11) NOT NULL DEFAULT 0 | 通话时长总和 |
建表语句如下:
USE `db_telecom`;
CREATE TABLE `tb_call` (
`id_date_contact` varchar(255) CHARACTER SET latin1 NOT NULL,
`id_date_dimension` int(11) NOT NULL,
`id_contact` int(11) NOT NULL,
`call_sum` int(11) NOT NULL DEFAULT '0',
`call_duration_sum` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id_date_contact`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;3) 表tb_dimension_date:用于存放时间维度的相关数据。
|-------|------------------|--------------------------------|
| 列名 | 类型 | 备注 |
| id | int(11) NOT NULL | 自增长、主键 |
| year | int(11) NOT NULL | 当前通话信息所在年 |
| month | int(11) NOT NULL | 当前通话信息所在月,如果按照年来统计信息,则month为-1 |
| day | int(11) NOT NULL | 当前通话信息所在日,如果按照月来统计信息,则day为-1 |
建表语句如下:
USE `db_telecom`;
CREATE TABLE `tb_dimension_date` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`year` int(11) NOT NULL,
`month` int(11) NOT NULL,
`day` int(11) NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;4) 表tb_intimacy:用于存放所有用户的用户关系的结果数据。
|---------------------|----------------------------|--------------|
| 列名 | 类型 | 备注 |
| id | int(11) NOT NULL | 自增长、主键 |
| intimacy_rank | int(11) NOT NULL | 好友亲密度排名 |
| id_contact1 | int(11) NOT NULL | 联系人1,当前所查询人 |
| id_contact2 | int(11) NOT NULL | 联系人2,与联系人为好友 |
| call_count | int(11) NOT NULL DEFAULT 0 | 两联系人通话次数 |
| call_duration_count | int(11) NOT NULL DEFAULT 0 | 两联系人通话持续时间 |
建表语句如下:
USE `db_telecom`;
CREATE TABLE `tb_intimacy` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`intimacy_rank` int(11) NOT NULL,
`id_contact1` int(11) NOT NULL,
`id_contact2` int(11) NOT NULL,
`call_count` int(11) NOT NULL DEFAULT '0',
`call_duration_count` int(11) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;2、需求:按照不同的维度统计通话
根据需求,我们设计出上面的MySQL的表结构。接下来需要按照时间范围(年月日),结合MapReduce统计出所属时间范围内所有手机号码的通话次数总和以及通话时长总和。
思路:
- 维度,即某个角度。例如:按照时间维度来统计通话,统计2023年所有月份的通话记录,那么维度可以表述为2023年*月*日。
- 通过Mapper将数据按照不同维度聚合给Reducer。
- 通过Reducer得到在Mapper中按照各个维度聚合过来的数据,进行汇总,输出。
- 由于数据输入是HBase,数据输出是MySQL,HBase已经提供了Inputformat,而MySQL没有提供Outputformat,所以需要根据业务需求自定义Outputformat。
- HBase中的数据结构:
| 标签 | 说明 |
|---|---|
| rowkey 行键 | 例:01_15245678901_20180704164833_13844456789_1_0180 |
| family 列族 | 例:f1列族:存放主叫信息 f2列族:存放被叫信息 |
| columns 字段 | 例:call1:第一个手机号 call2:第二个手机号 date_time:通话建立的时间,例:20230704164833 date_time_ts:date_time对应的时间戳形式 duration:通话时长(单位:秒) flag:标记call1是主叫还是被叫(call1与call2身份互斥) |
2、 编写代码:数据分析
1)参考"数据生产"步骤新建项目 ct_analysis,pom.xml的依赖项如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.qst</groupId>
<artifactId>ct_analysis</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase</artifactId>
<version>2.3.5</version>
<type>pom</type>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-common</artifactId>
<version>2.10.1</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12.4</version>
<configuration>
<skipTests>true</skipTests>
</configuration>
</plugin>
</plugins>
</build>
</project>2)项目结构:
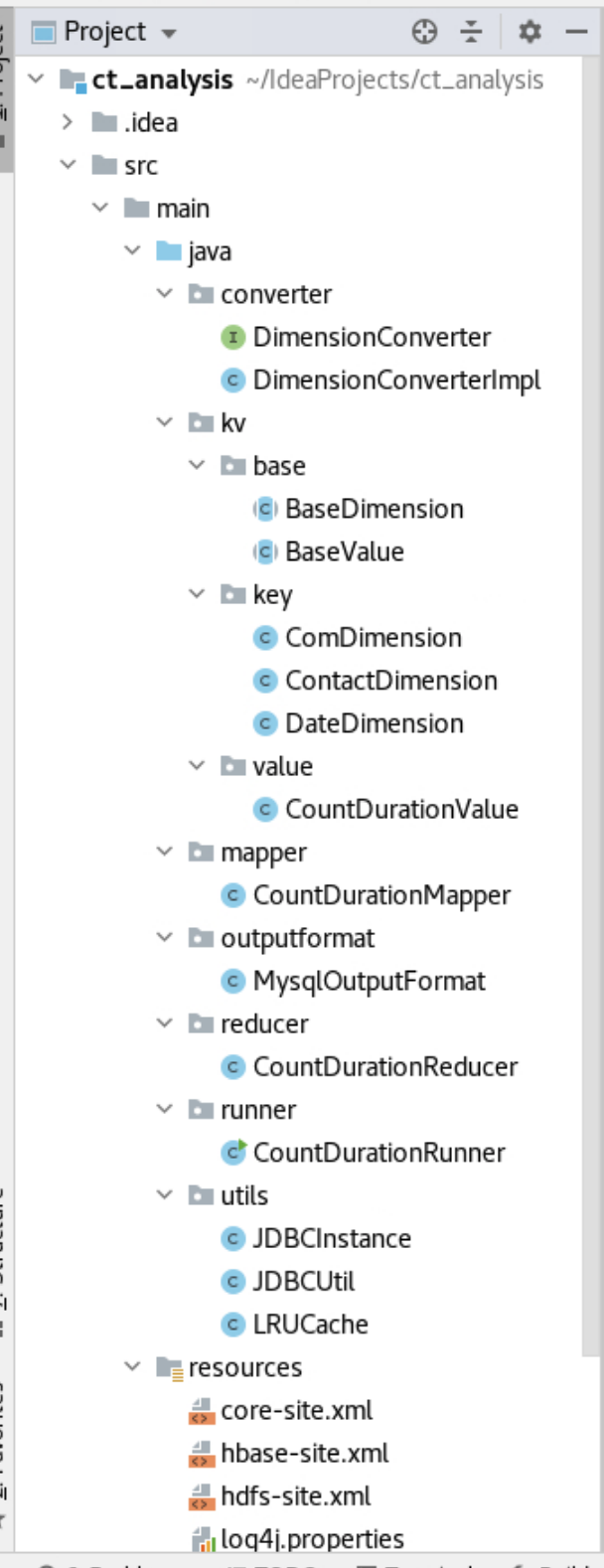
3)类列表:
|------------------------|-----------------------------------|
| 类名 | 备注 |
| CountDurationMapper | 数据分析的Mapper类,继承自TableMapper |
| CountDurationReducer | 数据分析的Reducer类,继承自Reducer |
| CountDurationRunner | 数据分析的驱动类,组装并运行Job |
| MysqlOutputFormat | 自定义对接MySQL输出的Outputformat |
| BaseDimension | 维度(key)基类 |
| BaseValue | 值(value)基类 |
| ComDimension | 时间维度+联系人维度的组合维度 |
| ContactDimension | 联系人维度 |
| DateDimension | 时间维度 |
| CountDurationValue | 通话次数与通话时长的封装 |
| JDBCUtil | 连接 MySQL 的工具类 |
| JDBCInstance | 单例 JDBCConnection |
| DimensionConverter | 转化接口,根据传入的维度对象,得到该对象对应的数据库主键id |
| DimensionConverterImpl | IConverter 实现类,负责实际的维度转 id 功能 |
| LRUCache | 用于缓存已知的维度 id,减少对 MySQL 的操作次数,提高效率 |
4) 因为需要将数据保存到MySQL中,所以在这里先定义两个访问MySQL的工具类。
JDBCUtil类:用于创建MySQL的JDBC连接、关闭连接。
package utils;
import java.sql.*;
public class JDBCUtil {
//定义JDBC连接器实例化所需要的固定参数
private static final String MYSQL_DRIVER_CLASS = "com.mysql.jdbc.Driver";
private static final String MYSQL_URL = "jdbc:mysql://master1:3306/db_telecom?useUnicode=true&characterEncoding=UTF-8";
private static final String MYSQL_USERNAME = "root";
private static final String MYSQL_PASSWORD = "Qst@123456";
/**
* 实例化JDBC连接器对象
*/
public static Connection getConnection(){
try {
Class.forName(MYSQL_DRIVER_CLASS);
return DriverManager.getConnection(MYSQL_URL, MYSQL_USERNAME, MYSQL_PASSWORD);
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException e) {
e.printStackTrace();
}
return null;
}
/**
* 释放连接器资源
*/
public static void close(Connection connection, Statement statement, ResultSet resultSet){
try {
if(resultSet != null && !resultSet.isClosed()){
resultSet.close();
}
if(statement != null && !statement.isClosed()){
statement.close();
}
if(connection != null && !connection.isClosed()){
connection.close();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
}JDBCInstance类:用于以单例模式获取MySQL的JDBC连接对象。
package utils;
import java.sql.Connection;
import java.sql.SQLException;
public class JDBCInstance {
private static Connection connection = null;
private JDBCInstance(){}
public static Connection getInstance(){
try {
if(connection == null || connection.isClosed() || !connection.isValid(3)){
connection = JDBCUtil.getConnection();
}
} catch (SQLException e) {
e.printStackTrace();
}
return connection;
}
}5) 自定义MapReduce输出的键和值。
根据前面MySQL表的设计思路得出:
mapper的输出格式:
- 联系人_通话日期,通话时长 17596034534_2018-01 , 360
reducer的输出格式:
- 联系人_通话日期,通话次数_通话时长 17596034534_2018-01 , 10_360
所以,在这里我们需要自定义MapReduce输出的键和值,以满足业务需求。键为联系人维度和日期维度的聚合维度,值为通话次数和通话时长的组合值。
BaseDimension类:定义键(维度)的基类。
package kv.base;
import org.apache.hadoop.io.WritableComparable;
public abstract class BaseDimension implements WritableComparable<BaseDimension>{}BaseValue类:定义值的基类。
package kv.base;
import org.apache.hadoop.io.Writable;
public abstract class BaseValue implements Writable{}ContactDimension类:联系人维度。
package kv.key;
import kv.base.BaseDimension;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class ContactDimension extends BaseDimension{
private String telephone;
private String name;
public ContactDimension(){
super();
}
public ContactDimension(String telephone, String name){
super();
this.telephone = telephone;
this.name = name;
}
public String getTelephone() {
return telephone;
}
public void setTelephone(String telephone) {
this.telephone = telephone;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
ContactDimension that = (ContactDimension) o;
if (telephone != null ? !telephone.equals(that.telephone) : that.telephone != null) return false;
return name != null ? name.equals(that.name) : that.name == null;
}
@Override
public int hashCode() {
int result = telephone != null ? telephone.hashCode() : 0;
result = 31 * result + (name != null ? name.hashCode() : 0);
return result;
}
@Override
public int compareTo(BaseDimension o) {
ContactDimension anotherContactDimension = (ContactDimension) o;
int result = this.name.compareTo(anotherContactDimension.name);
if(result != 0) return result;
result = this.telephone.compareTo(anotherContactDimension.telephone);
return result;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.telephone);
out.writeUTF(this.name);
}
@Override
public void readFields(DataInput in) throws IOException {
this.telephone = in.readUTF();
this.name = in.readUTF();
}
}DateDimension类:日期维度。
package kv.key;
import kv.base.BaseDimension;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class DateDimension extends BaseDimension {
private String year;
private String month;
private String day;
public DateDimension(){
super();
}
public DateDimension(String year, String month, String day){
super();
this.year = year;
this.month = month;
this.day = day;
}
public String getYear() {
return year;
}
public void setYear(String year) {
this.year = year;
}
public String getMonth() {
return month;
}
public void setMonth(String month) {
this.month = month;
}
public String getDay() {
return day;
}
public void setDay(String day) {
this.day = day;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
DateDimension that = (DateDimension) o;
if (year != null ? !year.equals(that.year) : that.year != null) return false;
if (month != null ? !month.equals(that.month) : that.month != null) return false;
return day != null ? day.equals(that.day) : that.day == null;
}
@Override
public int hashCode() {
int result = year != null ? year.hashCode() : 0;
result = 31 * result + (month != null ? month.hashCode() : 0);
result = 31 * result + (day != null ? day.hashCode() : 0);
return result;
}
@Override
public int compareTo(BaseDimension o) {
DateDimension anotherDateDimension = (DateDimension)o;
int result = this.year.compareTo(anotherDateDimension.year);
if(result != 0) return result;
result = this.month.compareTo(anotherDateDimension.month);
if(result != 0) return result;
result = this.day.compareTo(anotherDateDimension.day);
return result;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(this.year);
out.writeUTF(this.month);
out.writeUTF(this.day);
}
@Override
public void readFields(DataInput in) throws IOException {
this.year = in.readUTF();
this.month = in.readUTF();
this.day = in.readUTF();
}
}ComDimension类:聚合维度。
package kv.key;
import kv.base.BaseDimension;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class ComDimension extends BaseDimension {
private ContactDimension contactDimension = new ContactDimension();
private DateDimension dateDimension = new DateDimension();
public ComDimension(){
super();
}
public ContactDimension getContactDimension() {
return contactDimension;
}
public void setContactDimension(ContactDimension contactDimension) {
this.contactDimension = contactDimension;
}
public DateDimension getDateDimension() {
return dateDimension;
}
public void setDateDimension(DateDimension dateDimension) {
this.dateDimension = dateDimension;
}
@Override
public int compareTo(BaseDimension o) {
ComDimension anotherComDimension = (ComDimension) o;
int result = this.dateDimension.compareTo(anotherComDimension.dateDimension);
if(result != 0) return result;
result = this.contactDimension.compareTo(anotherComDimension.contactDimension);
return result;
}
@Override
public void write(DataOutput out) throws IOException {
contactDimension.write(out);
dateDimension.write(out);
}
@Override
public void readFields(DataInput in) throws IOException {
contactDimension.readFields(in);
dateDimension.readFields(in);
}
}CountDurationValue类:Reducer输出的值,封装了通话次数与通话时长。
package kv.value;
import kv.base.BaseValue;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class CountDurationValue extends BaseValue{
private String callSum;
private String callDurationSum;
public CountDurationValue(){
super();
}
public String getCallSum() {
return callSum;
}
public void setCallSum(String callSum) {
this.callSum = callSum;
}
public String getCallDurationSum() {
return callDurationSum;
}
public void setCallDurationSum(String callDurationSum) {
this.callDurationSum = callDurationSum;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(callSum);
out.writeUTF(callDurationSum);
}
@Override
public void readFields(DataInput in) throws IOException {
this.callSum = in.readUTF();
this.callDurationSum = in.readUTF();
}
}6) CountDurationMapper类: 继承自TableMapper<ComDimension, Text>,TableMapper是HBase封装的Mapper类,使用HBase提供的InputFormat,输入格式为<ComDimension, Text>,其中ComDimension是前面我们定义的复合维度,如:15066860034_2018,Text为通话时长,如:360。
package mapper;
import kv.key.ComDimension;
import kv.key.ContactDimension;
import kv.key.DateDimension;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.Text;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class CountDurationMapper extends TableMapper<ComDimension, Text>{
private ComDimension comDimension = new ComDimension();
private Text durationText = new Text();
private Map<String, String> phoneNameMap;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
super.setup(context);
phoneNameMap = new HashMap<String, String>();
phoneNameMap.put("17078388295", "李雁");
phoneNameMap.put("13980337439", "卫艺");
phoneNameMap.put("14575535933", "仰莉");
phoneNameMap.put("19902496992", "陶欣悦");
phoneNameMap.put("18549641558", "施梅梅");
phoneNameMap.put("17005930322", "金虹霖");
phoneNameMap.put("18468618874", "魏明艳");
phoneNameMap.put("18576581848", "华贞");
phoneNameMap.put("15978226424", "华啟倩");
phoneNameMap.put("15542823911", "仲采绿");
phoneNameMap.put("17526304161", "卫丹");
phoneNameMap.put("15422018558", "戚丽红");
phoneNameMap.put("17269452013", "何翠柔");
phoneNameMap.put("17764278604", "钱溶艳");
phoneNameMap.put("15711910344", "钱琳");
phoneNameMap.put("15714728273", "缪静欣");
phoneNameMap.put("16061028454", "焦秋菊");
phoneNameMap.put("16264433631", "吕访琴");
phoneNameMap.put("17601615878", "沈丹");
phoneNameMap.put("15897468949", "褚美丽");
}
@Override
protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {
//05_19902496992_20170312154840_15542823911_1_1288
String rowKey = Bytes.toString(key.get());
String[] splits = rowKey.split("_");
if(splits[4].equals("0")) return;
//以下数据全部是主叫数据,但是也包含了被叫电话的数据
String caller = splits[1];
String callee = splits[3];
String buildTime = splits[2];
String duration = splits[5];
durationText.set(duration);
String year = buildTime.substring(0, 4);
String month = buildTime.substring(4, 6);
String day = buildTime.substring(6, 8);
//组装 ComDimension
//组装 DateDimension
05_19902496992_20170312154840_15542823911_1_1288
DateDimension yearDimension = new DateDimension(year, "-1", "-1");
DateDimension monthDimension = new DateDimension(year, month, "-1");
DateDimension dayDimension = new DateDimension(year, month, day);
//组装ContactDimension
ContactDimension callerContactDimension = new ContactDimension(caller, phoneNameMap.get(caller));
ContactDimension calleeContactDimension = new ContactDimension(callee, phoneNameMap.get(callee));
//开始聚合主叫数据
comDimension.setContactDimension(callerContactDimension);
//年
comDimension.setDateDimension(yearDimension);
context.write(comDimension, durationText);
//月
comDimension.setDateDimension(monthDimension);
context.write(comDimension, durationText);
//日
comDimension.setDateDimension(dayDimension);
context.write(comDimension, durationText);
//开始聚合被叫数据
comDimension.setContactDimension(calleeContactDimension);
//年
comDimension.setDateDimension(yearDimension);
context.write(comDimension, durationText);
//月
comDimension.setDateDimension(monthDimension);
context.write(comDimension, durationText);
//日
comDimension.setDateDimension(dayDimension);
context.write(comDimension, durationText);
}
}7) CountDurationReducer类:
继承自Reducer<ComDimension,Text,ComDimension,CountDurationValue>,输入格式为:<ComDimension,Text>其中ComDimension为复合维度,如:18047140826_2018,Text为通话时长,如:360;输出格式为:<ComDimension,CountDurationValue>其中ComDimension为复合维度,如:18047140826_2018,CountDurationValue为组合输出值,如:10_360。
package reducer;
import kv.key.ComDimension;
import kv.value.CountDurationValue;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class CountDurationReducer extends Reducer<ComDimension, Text, ComDimension, CountDurationValue>{
CountDurationValue countDurationValue = new CountDurationValue();
@Override
protected void reduce(ComDimension key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int callSum = 0;
int callDurationSum = 0;
for(Text t : values){
callSum++;
callDurationSum += Integer.valueOf(t.toString());
}
countDurationValue.setCallSum(String.valueOf(callSum));
countDurationValue.setCallDurationSum(String.valueOf(callDurationSum));
context.write(key, countDurationValue);
}
}8) 由于需要将MapReduce结果数据直接保存到MySQL中,Hadoop并没有提供相应的OutputFormat,所以在这里我们自定义MysqlOutputFormat类。因为传入的是维度对象,而保存到MySQL中的是该对象对应的数据库主键id,所以需要编写类DimensionConverterImpl实现根据传入的维度对象,得到该对象对应的数据库主键id,并使用缓存机制,缓存已知的维度id,减少对 MySQL 的操作次数,提高效率。
LRUCache类:实现一个缓存类。
package utils;
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache extends LinkedHashMap<String, Integer> {
private static final long serialVersionUID = 1L;
protected int maxElements;
public LRUCache(int maxSize) {
super(maxSize, 0.75F, true);
this.maxElements = maxSize;
}
/*
* (non-Javadoc)
*
* @see java.util.LinkedHashMap#removeEldestEntry(java.util.Map.Entry)
*/
@Override
protected boolean removeEldestEntry(Map.Entry<String, Integer> eldest) {
return (size() > this.maxElements);
}
}DimensionConverter接口:转化接口,根据传入的维度对象,得到该对象对应的数据库主键id。
package converter;
import kv.base.BaseDimension;
public interface DimensionConverter {
int getDimensionID(BaseDimension dimension);
}**DimensionConverterImpl类:**DimensionConverter接口的实现类,根据传入的维度数据,得到该数据对应的在表中的主键id。为了减少对MySQL的操作次数,这里使用了缓存机制,缓存已知的维度id。所以该类的实现逻辑为:
根据传入的维度数据,得到该数据对应的在表中的主键id
** 做内存缓存,LRUCache
if(缓存中有数据){
直接返回id
}else if(缓存中无数据){
则查询MySql
if(MySql中有该条数据){
直接返回id
将本次读取到的id缓存到内存中
}else if(MySql中没有该条数据){
插入该条数据
再次反查该数据,得到id并返回
将本次读取到的id缓存到内存中
}
}实现代码如下:
package converter;
import kv.base.BaseDimension;
import kv.key.ContactDimension;
import kv.key.DateDimension;
import utils.JDBCInstance;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import utils.JDBCUtil;
import utils.LRUCache;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
/**
* 1、根据传入的维度数据,得到该数据对应的在表中的主键id
* ** 做内存缓存,LRUCache
* if(缓存中有数据){
* 直接返回id
* }else if(缓存中无数据){
* 则查询MySql
* if(MySql中有该条数据){
* 直接返回id
* 将本次读取到的id缓存到内存中
* }else if(MySql中没有该条数据){
* 插入该条数据
* 再次反查该数据,得到id并返回
* 将本次读取到的id缓存到内存中
* }
* }
*/
public class DimensionConverterImpl implements DimensionConverter {
//Logger
private static final Logger logger = LoggerFactory.getLogger(DimensionConverterImpl.class);
//对象线程化 用于每个线程管理自己的JDBC连接器
private ThreadLocal<Connection> threadLocalConnection = new ThreadLocal<>();
//构建内存缓存对象
private LRUCache lruCache = new LRUCache(3000);
public DimensionConverterImpl() {
//jvm关闭时,释放资源
Runtime.getRuntime().addShutdownHook(new Thread(() -> JDBCUtil.close(threadLocalConnection.get(), null, null)));
}
@Override
public int getDimensionID(BaseDimension dimension) {
//1、根据传入的维度对象获取对应的主键id,先从LRUCache中获取
//时间维度:date_dimension_year_month_day, 10
//联系人维度:contact_dimension_telephone, 12
String cacheKey = genCacheKey(dimension);
//尝试获取缓存的id
if (lruCache.containsKey(cacheKey)) {
return lruCache.get(cacheKey);
}
//没有得到缓存id,需要执行select操作
//sqls包含了1组sql语句:查询和插入
String[] sqls = null;
if (dimension instanceof DateDimension) {
sqls = getDateDimensionSQL();
} else if (dimension instanceof ContactDimension) {
sqls = getContactDimensionSQL();
} else {
throw new RuntimeException("没有匹配到对应维度信息.");
}
//准备对Mysql表进行操作,先查询,有可能再插入
Connection conn = this.getConnection();
int id = -1;
synchronized (this) {
id = execSQL(conn, sqls, dimension);
}
//将刚查询到的id加入到缓存中
lruCache.put(cacheKey, id);
return id;
}
/**
* 得到当前线程维护的Connection对象
*
* @return
*/
private Connection getConnection() {
Connection conn = null;
try {
conn = threadLocalConnection.get();
if (conn == null || conn.isClosed()) {
conn = JDBCInstance.getInstance();
threadLocalConnection.set(conn);
}
} catch (SQLException e) {
e.printStackTrace();
}
return conn;
}
/**
* @param conn JDBC连接器
* @param sqls 长度为2,第一个位置为查询语句,第二个位置为插入语句
* @param dimension 对应维度所保存的数据
* @return
*/
private int execSQL(Connection conn, String[] sqls, BaseDimension dimension) {
PreparedStatement preparedStatement = null;
ResultSet resultSet = null;
try {
//1
//查询的preparedStatement
preparedStatement = conn.prepareStatement(sqls[0]);
//根据不同的维度,封装不同的SQL语句
setArguments(preparedStatement, dimension);
//执行查询
resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
int result = resultSet.getInt(1);
//释放资源
JDBCUtil.close(null, preparedStatement, resultSet);
return result;
}
//释放资源
JDBCUtil.close(null, preparedStatement, resultSet);
//2
//执行插入,封装插入的sql语句
preparedStatement = conn.prepareStatement(sqls[1]);
setArguments(preparedStatement, dimension);
//执行插入
preparedStatement.executeUpdate();
//释放资源
JDBCUtil.close(null, preparedStatement, null);
//3
//查询的preparedStatement
preparedStatement = conn.prepareStatement(sqls[0]);
//根据不同的维度,封装不同的SQL语句
setArguments(preparedStatement, dimension);
//执行查询
resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
return resultSet.getInt(1);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
//释放资源
JDBCUtil.close(null, preparedStatement, resultSet);
}
return -1;
}
/**
* 设置SQL语句的具体参数
*
* @param preparedStatement
* @param dimension
*/
private void setArguments(PreparedStatement preparedStatement, BaseDimension dimension) {
int i = 0;
try {
if (dimension instanceof DateDimension) {
//可以优化
DateDimension dateDimension = (DateDimension) dimension;
preparedStatement.setString(++i, dateDimension.getYear());
preparedStatement.setString(++i, dateDimension.getMonth());
preparedStatement.setString(++i, dateDimension.getDay());
} else if (dimension instanceof ContactDimension) {
ContactDimension contactDimension = (ContactDimension) dimension;
preparedStatement.setString(++i, contactDimension.getTelephone());
preparedStatement.setString(++i, contactDimension.getName());
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 返回联系人表的查询和插入语句
*
* @return
*/
private String[] getContactDimensionSQL() {
String query = "SELECT `id` FROM `tb_contacts` WHERE `telephone` = ? AND `name` = CONVERT( ? USING utf8) COLLATE utf8_unicode_ci ORDER BY `id`;";
String insert = "INSERT INTO `tb_contacts` (`telephone`, `name`) VALUES (?, CONVERT( ? USING utf8) COLLATE utf8_unicode_ci);";
return new String[]{query, insert};
}
/**
* 返回时间表的查询和插入语句
*
* @return
*/
private String[] getDateDimensionSQL() {
String query = "SELECT `id` FROM `tb_dimension_date` WHERE `year` = ? AND `month` = ? AND `day` = ? ORDER BY `id`;";
String insert = "INSERT INTO `tb_dimension_date` (`year`, `month`, `day`) VALUES (?, ?, ?);";
return new String[]{query, insert};
}
/**
* 根据维度信息得到维度对应的缓存键
*
* @param dimension
* @return
*/
private String genCacheKey(BaseDimension dimension) {
StringBuilder sb = new StringBuilder();
if (dimension instanceof DateDimension) {
DateDimension dateDimension = (DateDimension) dimension;
sb.append("date_dimension")
.append(dateDimension.getYear())
.append(dateDimension.getMonth())
.append(dateDimension.getDay());
} else if (dimension instanceof ContactDimension) {
ContactDimension contactDimension = (ContactDimension) dimension;
sb.append("contact_dimension").append(contactDimension.getTelephone());
}
return sb.toString();
}
}MysqlOutputFormat类:
package outputformat;
import converter.DimensionConverterImpl;
import kv.key.ComDimension;
import kv.value.CountDurationValue;
import utils.JDBCInstance;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import utils.JDBCUtil;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.SQLException;
public class MysqlOutputFormat extends OutputFormat<ComDimension, CountDurationValue>{
private OutputCommitter committer = null;
@Override
public RecordWriter<ComDimension, CountDurationValue> getRecordWriter(TaskAttemptContext context)
throws IOException, InterruptedException {
//初始化JDBC连接器对象
Connection conn = null;
conn = JDBCInstance.getInstance();
try {
conn.setAutoCommit(false);
} catch (SQLException e) {
throw new RuntimeException(e.getMessage());
}
return new MysqlRecordWriter(conn);
}
@Override
public void checkOutputSpecs(JobContext context) throws IOException, InterruptedException {
//输出校检
}
@Override
public OutputCommitter getOutputCommitter(TaskAttemptContext context) throws IOException, InterruptedException {
if(committer == null){
String name = context.getConfiguration().get(FileOutputFormat.OUTDIR);
Path outputPath = name == null ? null : new Path(name);
committer = new FileOutputCommitter(outputPath, context);
}
return committer;
}
static class MysqlRecordWriter extends RecordWriter<ComDimension, CountDurationValue> {
private DimensionConverterImpl dci = new DimensionConverterImpl();
private Connection conn = null;
private PreparedStatement preparedStatement = null;
private String insertSQL = null;
private int count = 0;
private final int BATCH_SIZE = 500;
public MysqlRecordWriter(Connection conn) {
this.conn = conn;
}
@Override
public void write(ComDimension key, CountDurationValue value) throws IOException, InterruptedException {
try {
//tb_call
//id_date_contact, id_date_dimension, id_contact, call_sum, call_duration_sum
//year month day
int idDateDimension = dci.getDimensionID(key.getDateDimension());
//telephone name
int idContactDimension = dci.getDimensionID(key.getContactDimension());
String idDateContact = idDateDimension + "_" + idContactDimension;
int callSum = Integer.valueOf(value.getCallSum());
int callDurationSum = Integer.valueOf(value.getCallDurationSum());
if(insertSQL == null){
insertSQL = "INSERT INTO `tb_call` (`id_date_contact`, `id_date_dimension`, `id_contact`, `call_sum`, `call_duration_sum`) VALUES (?, ?, ?, ?, ?) ON DUPLICATE KEY UPDATE `id_date_contact` = ?;";
}
if(preparedStatement == null){
preparedStatement = conn.prepareStatement(insertSQL);
}
//本次SQL
int i = 0;
preparedStatement.setString(++i, idDateContact);
preparedStatement.setInt(++i, idDateDimension);
preparedStatement.setInt(++i, idContactDimension);
preparedStatement.setInt(++i, callSum);
preparedStatement.setInt(++i, callDurationSum);
//无则插入,有则更新的判断依据
preparedStatement.setString(++i, idDateContact);
preparedStatement.addBatch();
count++;
if(count >= BATCH_SIZE){
preparedStatement.executeBatch();
conn.commit();
count = 0;
preparedStatement.clearBatch();
}
} catch (SQLException e) {
e.printStackTrace();
}
}
@Override
public void close(TaskAttemptContext context) throws IOException, InterruptedException {
try {
if(preparedStatement != null){
preparedStatement.executeBatch();
this.conn.commit();
}
} catch (SQLException e) {
e.printStackTrace();
}finally {
JDBCUtil.close(conn, preparedStatement, null);
}
}
}
}8) CountDurationRunner类,MapReduce的驱动类,组装Mapper、Reducer、MySqlOutputFormat等。
package runner;
import kv.key.ComDimension;
import kv.value.CountDurationValue;
import mapper.CountDurationMapper;
import outputformat.MysqlOutputFormat;
import reducer.CountDurationReducer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class CountDurationRunner implements Tool {
private Configuration conf = null;
@Override
public void setConf(Configuration conf) {
this.conf = HBaseConfiguration.create(conf);
}
@Override
public Configuration getConf() {
return this.conf;
}
@Override
public int run(String[] args) throws Exception {
//得到conf
Configuration conf = this.getConf();
//实例化Job
Job job = Job.getInstance(conf);
job.setJarByClass(CountDurationRunner.class);
//组装Mapper InputForamt
initHBaseInputConfig(job);
//组装Reducer Outputformat
initReducerOutputConfig(job);
return job.waitForCompletion(true) ? 0 : 1;
}
private void initHBaseInputConfig(Job job) {
Connection connection = null;
Admin admin = null;
try {
String tableName = "ns_ct:calllog";
connection = ConnectionFactory.createConnection(job.getConfiguration());
admin = connection.getAdmin();
if (!admin.tableExists(TableName.valueOf(tableName))) throw new RuntimeException("无法找到目标表.");
Scan scan = new Scan();
//可以优化
//初始化Mapper
TableMapReduceUtil.initTableMapperJob(tableName, scan, CountDurationMapper.class, ComDimension.class, Text.class, job, true);
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (admin != null) {
admin.close();
}
if (connection != null && !connection.isClosed()) {
connection.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
private void initReducerOutputConfig(Job job) {
job.setReducerClass(CountDurationReducer.class);
job.setOutputKeyClass(ComDimension.class);
job.setOutputValueClass(CountDurationValue.class);
job.setOutputFormatClass(MysqlOutputFormat.class);
}
public static void main(String[] args) {
try {
//int status = ToolRunner.run(new CountDurationRunner(), args);
int status = ToolRunner.run(new CountDurationRunner(), args);
System.exit(status);
} catch (Exception e) {
e.printStackTrace();
}
}
}9) 在resources文件新建log4j.properties文件,添加内容如下:
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Define some default values that can be overridden by system properties
hadoop.root.logger=INFO,console
hadoop.log.dir=.
hadoop.log.file=hadoop.log
# Define the root logger to the system property "hadoop.root.logger".
log4j.rootLogger=${hadoop.root.logger}, EventCounter
# Logging Threshold
log4j.threshold=ALL
# Null Appender
log4j.appender.NullAppender=org.apache.log4j.varia.NullAppender
#
# Rolling File Appender - cap space usage at 5gb.
#
hadoop.log.maxfilesize=256MB
hadoop.log.maxbackupindex=20
log4j.appender.RFA=org.apache.log4j.RollingFileAppender
log4j.appender.RFA.File=${hadoop.log.dir}/${hadoop.log.file}
log4j.appender.RFA.MaxFileSize=${hadoop.log.maxfilesize}
log4j.appender.RFA.MaxBackupIndex=${hadoop.log.maxbackupindex}
log4j.appender.RFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
#log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n
#
# Daily Rolling File Appender
#
log4j.appender.DRFA=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFA.File=${hadoop.log.dir}/${hadoop.log.file}
# Rollover at midnight
log4j.appender.DRFA.DatePattern=.yyyy-MM-dd
log4j.appender.DRFA.layout=org.apache.log4j.PatternLayout
# Pattern format: Date LogLevel LoggerName LogMessage
log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
# Debugging Pattern format
#log4j.appender.DRFA.layout.ConversionPattern=%d{ISO8601} %-5p %c{2} (%F:%M(%L)) - %m%n
#
# console
# Add "console" to rootlogger above if you want to use this
#
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
#
# TaskLog Appender
#
#Default values
hadoop.tasklog.taskid=null
hadoop.tasklog.iscleanup=false
hadoop.tasklog.noKeepSplits=4
hadoop.tasklog.totalLogFileSize=100
hadoop.tasklog.purgeLogSplits=true
hadoop.tasklog.logsRetainHours=12
log4j.appender.TLA=org.apache.hadoop.mapred.TaskLogAppender
log4j.appender.TLA.taskId=${hadoop.tasklog.taskid}
log4j.appender.TLA.isCleanup=${hadoop.tasklog.iscleanup}
log4j.appender.TLA.totalLogFileSize=${hadoop.tasklog.totalLogFileSize}
log4j.appender.TLA.layout=org.apache.log4j.PatternLayout
log4j.appender.TLA.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
#
# HDFS block state change log from block manager
#
# Uncomment the following to suppress normal block state change
# messages from BlockManager in NameNode.
#log4j.logger.BlockStateChange=WARN
#
#Security appender
#
hadoop.security.logger=INFO,NullAppender
hadoop.security.log.maxfilesize=256MB
hadoop.security.log.maxbackupindex=20
log4j.category.SecurityLogger=${hadoop.security.logger}
hadoop.security.log.file=SecurityAuth-${user.name}.audit
log4j.appender.RFAS=org.apache.log4j.RollingFileAppender
log4j.appender.RFAS.File=${hadoop.log.dir}/${hadoop.security.log.file}
log4j.appender.RFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.RFAS.MaxFileSize=${hadoop.security.log.maxfilesize}
log4j.appender.RFAS.MaxBackupIndex=${hadoop.security.log.maxbackupindex}
#
# Daily Rolling Security appender
#
log4j.appender.DRFAS=org.apache.log4j.DailyRollingFileAppender
log4j.appender.DRFAS.File=${hadoop.log.dir}/${hadoop.security.log.file}
log4j.appender.DRFAS.layout=org.apache.log4j.PatternLayout
log4j.appender.DRFAS.layout.ConversionPattern=%d{ISO8601} %p %c: %m%n
log4j.appender.DRFAS.DatePattern=.yyyy-MM-dd
#
# hadoop configuration logging
#
# Uncomment the following line to turn off configuration deprecation warnings.
# log4j.logger.org.apache.hadoop.conf.Configuration.deprecation=WARN
#
# hdfs audit logging
#
hdfs.audit.logger=INFO,NullAppender
hdfs.audit.log.maxfilesize=256MB
hdfs.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=${hdfs.audit.logger}
log4j.additivity.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=false
log4j.appender.RFAAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.RFAAUDIT.File=${hadoop.log.dir}/hdfs-audit.log
log4j.appender.RFAAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.RFAAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.RFAAUDIT.MaxFileSize=${hdfs.audit.log.maxfilesize}
log4j.appender.RFAAUDIT.MaxBackupIndex=${hdfs.audit.log.maxbackupindex}
#
# mapred audit logging
#
mapred.audit.logger=INFO,NullAppender
mapred.audit.log.maxfilesize=256MB
mapred.audit.log.maxbackupindex=20
log4j.logger.org.apache.hadoop.mapred.AuditLogger=${mapred.audit.logger}
log4j.additivity.org.apache.hadoop.mapred.AuditLogger=false
log4j.appender.MRAUDIT=org.apache.log4j.RollingFileAppender
log4j.appender.MRAUDIT.File=${hadoop.log.dir}/mapred-audit.log
log4j.appender.MRAUDIT.layout=org.apache.log4j.PatternLayout
log4j.appender.MRAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
log4j.appender.MRAUDIT.MaxFileSize=${mapred.audit.log.maxfilesize}
log4j.appender.MRAUDIT.MaxBackupIndex=${mapred.audit.log.maxbackupindex}
# Custom Logging levels
#log4j.logger.org.apache.hadoop.mapred.JobTracker=DEBUG
#log4j.logger.org.apache.hadoop.mapred.TaskTracker=DEBUG
#log4j.logger.org.apache.hadoop.hdfs.server.namenode.FSNamesystem.audit=DEBUG
# Jets3t library
log4j.logger.org.jets3t.com.service.impl.rest.httpclient.RestS3Service=ERROR
# AWS SDK & S3A FileSystem
log4j.logger.com.amazonaws=ERROR
log4j.logger.com.amazonaws.http.AmazonHttpClient=ERROR
log4j.logger.org.apache.hadoop.fs.s3a.S3AFileSystem=WARN
#
# Event Counter Appender
# Sends counts of logging messages at different severity levels to Hadoop Metrics.
#
log4j.appender.EventCounter=org.apache.hadoop.log.metrics.EventCounter
#
# Job Summary Appender
#
# Use following logger to send summary to separate file defined by
# hadoop.mapreduce.jobsummary.log.file :
# hadoop.mapreduce.jobsummary.logger=INFO,JSA
#
hadoop.mapreduce.jobsummary.logger=${hadoop.root.logger}
hadoop.mapreduce.jobsummary.log.file=hadoop-mapreduce.jobsummary.log
hadoop.mapreduce.jobsummary.log.maxfilesize=256MB
hadoop.mapreduce.jobsummary.log.maxbackupindex=20
log4j.appender.JSA=org.apache.log4j.RollingFileAppender
log4j.appender.JSA.File=${hadoop.log.dir}/${hadoop.mapreduce.jobsummary.log.file}
log4j.appender.JSA.MaxFileSize=${hadoop.mapreduce.jobsummary.log.maxfilesize}
log4j.appender.JSA.MaxBackupIndex=${hadoop.mapreduce.jobsummary.log.maxbackupindex}
log4j.appender.JSA.layout=org.apache.log4j.PatternLayout
log4j.appender.JSA.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{2}: %m%n
log4j.logger.org.apache.hadoop.mapred.JobInProgress$JobSummary=${hadoop.mapreduce.jobsummary.logger}
log4j.additivity.org.apache.hadoop.mapred.JobInProgress$JobSummary=false
#
# Yarn ResourceManager Application Summary Log
#
# Set the ResourceManager summary log filename
yarn.server.resourcemanager.appsummary.log.file=rm-appsummary.log
# Set the ResourceManager summary log level and appender
yarn.server.resourcemanager.appsummary.logger=${hadoop.root.logger}
#yarn.server.resourcemanager.appsummary.logger=INFO,RMSUMMARY
# To enable AppSummaryLogging for the RM,
# set yarn.server.resourcemanager.appsummary.logger to
# <LEVEL>,RMSUMMARY in hadoop-env.sh
# Appender for ResourceManager Application Summary Log
# Requires the following properties to be set
# - hadoop.log.dir (Hadoop Log directory)
# - yarn.server.resourcemanager.appsummary.log.file (resource manager app summary log filename)
# - yarn.server.resourcemanager.appsummary.logger (resource manager app summary log level and appender)
log4j.logger.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=${yarn.server.resourcemanager.appsummary.logger}
log4j.additivity.org.apache.hadoop.yarn.server.resourcemanager.RMAppManager$ApplicationSummary=false
log4j.appender.RMSUMMARY=org.apache.log4j.RollingFileAppender
log4j.appender.RMSUMMARY.File=${hadoop.log.dir}/${yarn.server.resourcemanager.appsummary.log.file}
log4j.appender.RMSUMMARY.MaxFileSize=256MB
log4j.appender.RMSUMMARY.MaxBackupIndex=20
log4j.appender.RMSUMMARY.layout=org.apache.log4j.PatternLayout
log4j.appender.RMSUMMARY.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
# HS audit log configs
#mapreduce.hs.audit.logger=INFO,HSAUDIT
#log4j.logger.org.apache.hadoop.mapreduce.v2.hs.HSAuditLogger=${mapreduce.hs.audit.logger}
#log4j.additivity.org.apache.hadoop.mapreduce.v2.hs.HSAuditLogger=false
#log4j.appender.HSAUDIT=org.apache.log4j.DailyRollingFileAppender
#log4j.appender.HSAUDIT.File=${hadoop.log.dir}/hs-audit.log
#log4j.appender.HSAUDIT.layout=org.apache.log4j.PatternLayout
#log4j.appender.HSAUDIT.layout.ConversionPattern=%d{ISO8601} %p %c{2}: %m%n
#log4j.appender.HSAUDIT.DatePattern=.yyyy-MM-dd
# Http Server Request Logs
#log4j.logger.http.requests.namenode=INFO,namenoderequestlog
#log4j.appender.namenoderequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.namenoderequestlog.Filename=${hadoop.log.dir}/jetty-namenode-yyyy_mm_dd.log
#log4j.appender.namenoderequestlog.RetainDays=3
#log4j.logger.http.requests.datanode=INFO,datanoderequestlog
#log4j.appender.datanoderequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.datanoderequestlog.Filename=${hadoop.log.dir}/jetty-datanode-yyyy_mm_dd.log
#log4j.appender.datanoderequestlog.RetainDays=3
#log4j.logger.http.requests.resourcemanager=INFO,resourcemanagerrequestlog
#log4j.appender.resourcemanagerrequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.resourcemanagerrequestlog.Filename=${hadoop.log.dir}/jetty-resourcemanager-yyyy_mm_dd.log
#log4j.appender.resourcemanagerrequestlog.RetainDays=3
#log4j.logger.http.requests.jobhistory=INFO,jobhistoryrequestlog
#log4j.appender.jobhistoryrequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.jobhistoryrequestlog.Filename=${hadoop.log.dir}/jetty-jobhistory-yyyy_mm_dd.log
#log4j.appender.jobhistoryrequestlog.RetainDays=3
#log4j.logger.http.requests.nodemanager=INFO,nodemanagerrequestlog
#log4j.appender.nodemanagerrequestlog=org.apache.hadoop.http.HttpRequestLogAppender
#log4j.appender.nodemanagerrequestlog.Filename=${hadoop.log.dir}/jetty-nodemanager-yyyy_mm_dd.log
#log4j.appender.nodemanagerrequestlog.RetainDays=3将Hadoop的【core-site.xml】、【hdfs-site.xml】和HBase的【hbase-site.xml】文件拷贝至resources文件夹下:

3、 运行测试
1) 打包ct_analysis项目。
2) 将MySQL驱动包放到Hadoop根目录的lib目录下。
[root@master1 ~]# cp /opt/software/mysql-connector-java-5.1.47-bin.jar $HADOOP_HOME/share/hadoop/
[root@master1 ~]# scp /opt/software/mysql-connector-java-5.1.47-bin.jar slave1:$HADOOP_HOME/share/hadoop/
[root@master1 ~]# scp /opt/software/mysql-connector-java-5.1.47-bin.jar slave2:$HADOOP_HOME/share/hadoop/3) 提交任务
在IDE中右键运行行【runner.CountDurationRunner.java】

4) 观察MySQL中的结果。
[root@master1 ~]# mysql -uroot -pQst@123456
mysql> use db_telecom;
mysql> select * from tb_call;
mysql> select * from tb_contacts;
mysql> select * from tb_dimension_date;