朋友们、伙计们,我们又见面了,本期来给大家解读一下有关Linux程序地址空间的相关知识点,如果看完之后对你有一定的启发,那么请留下你的三连,祝大家心想事成!
C 语 言 专 栏:C语言:从入门到精通
数据结构专栏:数据结构
个 人 主 页 :stackY、
C + + 专 栏 :C++
Linux 专 栏 :Linux

目录
[1. 程序地址空间分布](#1. 程序地址空间分布)
[2. 基于地址空间,重新理解地址](#2. 基于地址空间,重新理解地址)
[3. 进程地址空间](#3. 进程地址空间)
[3.1 地址空间和区域划分](#3.1 地址空间和区域划分)
[3.2 为什么要有地址空间?](#3.2 为什么要有地址空间?)
[4. 基于地址空间进行扩展](#4. 基于地址空间进行扩展)
[4.1 每一个进程都有页表](#4.1 每一个进程都有页表)
[4.2 缺页中断](#4.2 缺页中断)
[4.3 进程的独立性](#4.3 进程的独立性)
[5. 写时拷贝](#5. 写时拷贝)
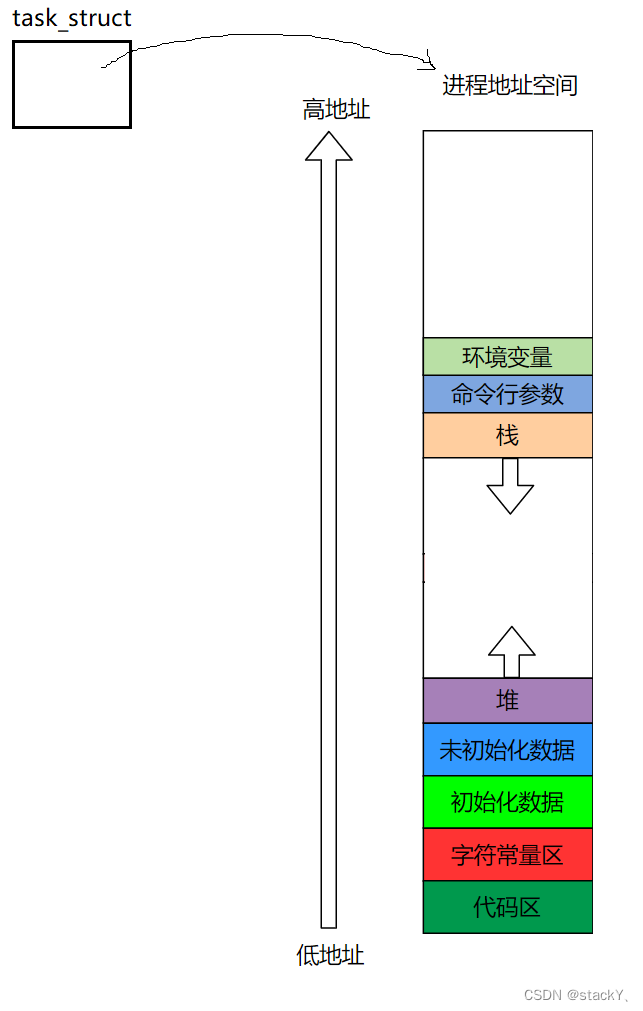
1. 程序地址空间分布
在C语言阶段就了解过这个图,那么本章来配合代码深入了解一下:
cpp#include <stdio.h> #include <stdlib.h> int un_gval; int init_gval = 100; int main(int argc, char *argv[], char *env[]) { printf("code addr: %p\n", main); // 代码区 const char *str = "HelloLinux!"; printf("read only char addr: %p\n", str); // 字符常量区 printf("init global value addr: %p\n", &init_gval); // 已初始化全局数据区 printf("uninit global value addr: %p\n", &un_gval); // 未初始化全局数据区 char* heap = (char*)malloc(100); printf("heap addr: %p\n", heap); // 堆区 printf("stack addr: %p\n", &str); // 栈区 int i = 0; for(i = 0; argv[i]; i++) { printf("argv[%d]: %p\n",i, argv[i]); // 命令行参数 } for(i = 0; env[i]; i++) { printf("env[%d]: %p\n",i, env[i]); // 环境变量 } return 0; }
使用代码将对应区域的地址打印出来可以发现于图片完全一致。
① 在程序地址空间中的堆区是向上增长的,栈区是向下增长的,通常也叫做堆栈相对而生。② 我们定义的任何类型(栈区中)都是整体向下开辟,使用时局部向上使用。
③ 在栈中定义的int类型变量是4个字节,我们要访问时,需要通过它的起始地址 再配合它的类型大小进行访问,变量类型大小就相当于起始地址的偏移量 ,访问的形式就是起始地址 + 偏移量。
④ static修饰局部变量本质上就是将局部变量的地址放到了全局区(全局变量)。


2. 基于地址空间,重新理解地址
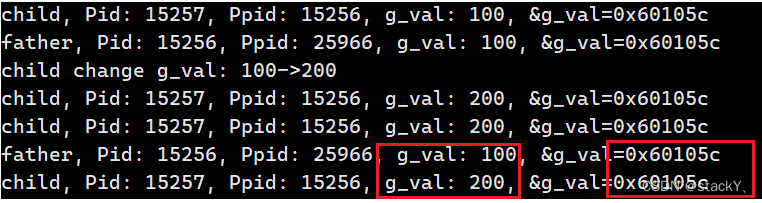
在之前的进程创建与进程fork本质章节中遗留了一个问题:如何理解同一个变量会有两个不同的指?
cpp#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/types.h> int g_val = 100; int main() { pid_t id = fork(); if(id == 0) { //child int cnt = 5; while(1) { printf("child, Pid: %d, Ppid: %d, g_val: %d, &g_val=%p\n", getpid(), getppid(), g_val, &g_val); sleep(1); if(cnt == 0) { g_val=200; printf("child change g_val: 100->200\n"); } cnt--; } } else { //father while(1) { printf("father, Pid: %d, Ppid: %d, g_val: %d, &g_val=%p\n", getpid(), getppid(), g_val, &g_val); sleep(1); } } return 0; }可以看到具有相同的地址同一个变量居然会有两个值,那么这也就证明了我们C/C++中观察到的地址并不是物理地址 ,我们平时用到的地址都是虚拟地址/线性地址。
3. 进程地址空间
前面提到的虚拟地址也叫做进程的地址空间,它属于进程PCB中的一个字段,每一个进程在运行之后,都会有一个进程地址空间。
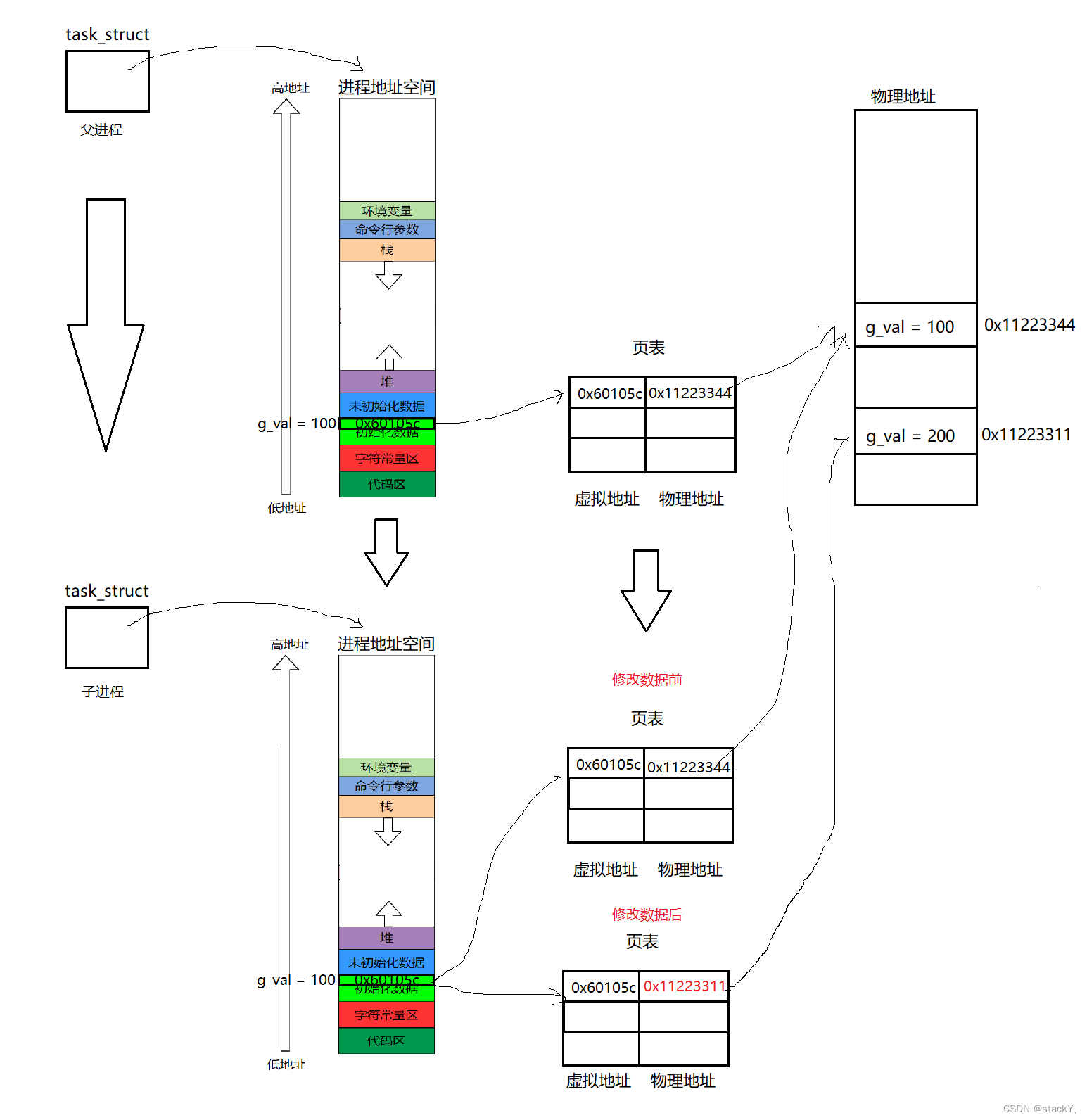
现在就来一步一步解释为什么同一个地址的变量会有两种值:① 我们定义的全局变量g_val在已初始化全局数据区 ,里面保存的是该变量的起始地址 ,进程地址空间不存储数据 ,它是虚拟地址,那么就要有需要有真正存储数据的地址--物理地址。
② 数据存储在物理地址中,需要通过一种类似于hash的映射关系由虚拟到物理的转化,这种方式在这里叫做--页表,通过页表可以完成由虚拟地址映射到物理地址。
③ 父进程创建子进程的时候需要以自己的PCB为模版来构建子进程的PCB,所以父进程中的全局变量g_val的虚拟地址在子进程的进程地址空间中也会有,同样的,子进程的页表也需要按照父进程为模版构建,所以虚拟到物理的转化关系也有了。
④ 此时,子进程的虚拟地址到物理地址的转化之后也指向了同一块物理地址,当检测到子进程要修改这个变量时,OS会先以写时拷贝的方式在物理地址中重新找一块空间,拷贝原来的数据到新的空间,并将子进程页表中的映射关系随之改变,然后就可以随意的修改变量。
⑤ 当子进程修改完变量的值之后,我们再查看时就会发现同一个地址(虚拟地址)的变量会有两个值。
3.1 地址空间和区域划分
先来了解一下空间的概念(以32位机器为例),在之前C语言的指针阶段就提到,计算机只认识二进制,那么二进制的0或1表示的就是有无的意思,那么在计算机里面的0或1表示的就是是否有电频,32位机器中存在会有32根地址总线,每一根地址线表示的情况都会两种,所以32根地址线一共会有2^32种情况,我们访问数据是以byte为单位,所以它的总大小换算一下就是2^32byte = 4GB大小的空间。
地址空间
假设一个OS的内存一共有4GB的空间大小,在我们运行程序的时候,OS会管理许多的进程,那么进程被调度是需要内存空间的,所以呢,OS就会虚拟的给每一个进程分配OS仅有的4GB的内存空间,那么在OS管理下的所有的进程都会认为自己将来会有4GB的内存空间, 简单的说就是OS给每一个进程画了一张饼 ,那么这张饼就叫做虚拟地址空间(地址空间)。
区域划分
通过一个小故事来理解区域划分:
在某小学,小胖和小花是同桌,共同使用一个长度位100cm的桌子,由于小胖的不注意卫生,遭到了小花的嫌弃,所以呢,小花就提出不再共同使用这张桌子,而是在桌子的中间画一条线,他两每一个用一半,这条线也被我们亲切的称为38线,所以画38线的本质就是对空间进行区域划分
区域调整
还是小胖和小花的这个例子,再画完38线之后呢,小胖和小花愉快的度过了一段时间,但是还是因为小胖的不自觉,经常把自己的垃圾放在小花的那一块,这就让小花很不能忍受,再加上小花实力在小胖之上,所以直接将小胖的区域再次压缩,从之前的五五分直接变成了四六分,对小胖的区域压缩的行为就叫做区域调整。
代码简述
对小胖和小花的这个行为使用计算机语言简单的描述就是:

地址空间也要被管理!
在OS中会有许多的进程,每一个进程都有对应的地址空间,在系统中,一定要对地址空间做管理,防止地址空间的混淆。根据管理的本质:先描述,再组织。
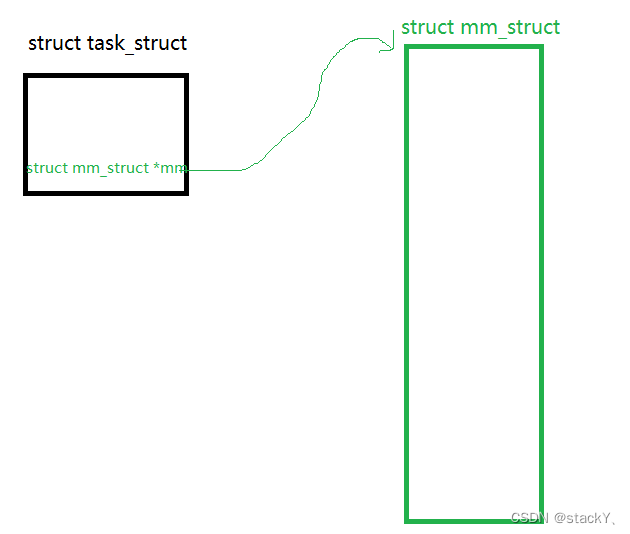
在Linux中,这个进程/虚拟地址空间的东西叫做:struct mm_struct:它是进程PCB中的一个字段,在PCB中是通过struct mm_struct *mm指向的一个结构化字段。
得出的结论:地址空间最终是一个内核的数据结构对象!就是一个内核结构体,所以我们看到的地址叫做虚拟地址。

3.2 为什么要有地址空间?
1. 地址空间固定的存储结构,可以让进程以统一的视角看待内存,所以任意一个进程,可以通过地址空间 + 页表将乱序的内存数据变成有序并分门别类的规划好。
在我们的计算机中存在许多的程序,那么当程序要运行就要被加载到内存中,OS就要在内存中给进程分配空间,此时的进程的代码和数据会在内存中杂乱的分布,没有顺序,这使得PCB在寻找自己的代码和数据时非常麻烦,地址空间恰好解决了这一点。
2. 地址空间配合页表可以很好的进行进程访问的内存安全检查。
在页表中还存在一个字段,它表示的是访问权限的字段,有的是只读,有的是只写,有的是读写,就比如常量字符串只允许读,不允许修改。地址空间就起到了一个控制检查的作用。
3. 将进程管理和内存管理解耦
由PCB到虚拟地址的提取以及保存的这一过程是属于进程管理的,从内存到物理地址的提取与保存这一过程是属于内存管理的,两者互不影响!
4. 基于地址空间进行扩展
4.1 每一个进程都有页表
在CPU内部有一个寄存器叫做:CR3寄存器,它主要是保存当前进程的页表地址。
在之前的进程切换章节我们了解到,进程要被CPU调度,进程在CPU内运行形成的临时数据叫做进程的硬件上下文,那么页表由虚拟到物理的转化也是属于数据,那么CP3寄存器的数据也叫做该进程的硬件上下文, 当进程切换的时候,会将进程的硬件上下文数据从寄存器剥离下来,保存在自己的PCB中,那么每一个进程都要这么做,所以每一个进程都有自己独立的页表。
4.2 缺页中断
页表中的虚拟地址可能有很多,但是物理地址可能还没有分配好,所以再继续访问的时候发现物理地址没有分配好,此时OS就会暂停访问,然后在物理地址中开辟空间,并且修改页表,然后继续执行访问,这个操作叫做缺页中断。
页表中还存在一个字段,它表示的是该地址是否分配或者是否有内容。
4.3 进程的独立性
虚拟地址有很多个,有可能相同,也有可能不同,多个进程通过页表由虚拟地址映射到同一块内存,这些个虚拟地址很可能相同,也有可能不同,通过各自的页表的映射关系之后,所映射的物理地址是完全不一样的,所以即使两个相同虚拟地址的进程,其中一个挂掉了,也不会影响另外一个。
通过页表,让进程映射到不同的物理内存,从而体现了进程具有独立性!
5. 写时拷贝
在前面说到过当子进程写入的时候,OS会发生写时拷贝,重新开辟一块空间给子进程,那么这个写时拷贝中间还存在许多细节:
1. 当父进程形成子进程的时候,子进程开始写入,那么OS会在何时发生写时拷贝?或者说是在某一时机发生写时拷贝?当父进程创建子进程的时候,首先将自己的页表读写权限改为只读,然后再创建子进程,但是这个过程用户并不知道,当用户进行写入时,会因为页表转化的权限问题而出错,此时,操作系统就会介入,从而触发重新申请内存的拷贝内容的策略机制,这个就叫做写时拷贝。
2. 反正都是要写入,只重新开辟空间就好了,为什么要拷贝原来的内容呢?我们写入的操作不一定要把原始数据全部修改,如果不拷贝原始数据,然后写入操作,会导致原始数据的丢失以及不完整。

朋友们、伙计们,美好的时光总是短暂的,我们本期的的分享就到此结束,欲知后事如何,请听下回分解~,最后看完别忘了留下你们弥足珍贵的三连喔,感谢大家的支持!