note
- Kimi K2 的预训练阶段使用 MuonClip 优化器实现万亿参数模型的稳定高效训练,在人类高质量数据成为瓶颈的背景下,有效提高 Token 利用效率。MuonClip Optimizer优化器,解决随着scaling up时的不稳定性。
- Kimi-K2 与 DeepSeek-R1 架构对比,相比较下 Kimi-k2 增加了专家数量,减少了注意力头的数量。这么设计的好处是,专家数量多无疑知识多,能记住更多东西,在知识广度上表现很好。而减少注意力头则能显著减少显存开销,另外过多的注意力头有时会学习到冗余或过于相似的注意力模式。通过减少头的数量,模型可能被迫让每个头学习到更独特、更关键的特征,这可能有助于防止过拟合,提升模型的泛化能力。
- Kimi K2 是一款具备更强代码能力、更擅长通用 Agent 任务的 MoE 架构基础模型,总参数 1T,激活参数 32B。
- Kimi K2 增强的智能体能力主要来源于两个重要方面------大规模智能体数据合成 和 通用强化学习。
文章目录
- note
- 一、Kimi-K2模型
-
- 1、Kimi-K2模型效果
- 2、Kimi-K2模型架构
- [3、MuonClip 优化器:](#3、MuonClip 优化器:)
- [4、智能体能力(Agentic Capabilities)](#4、智能体能力(Agentic Capabilities))
- [5、 通用强化学习](#5、 通用强化学习)
- 二、其他模型架构比较
- Reference
一、Kimi-K2模型
大模型开源进展,kimi-k2量化版本发布,Unsloth 量化的 Kimi-K2 放出了,包括从 1.8bit 的 UD_IQ1 到 UD-Q5_K_XL等版本:https://github.com/unslothai/llama.cpp,
量化模型地址:https://huggingface.co/unsloth/Kimi-K2-Instruct-GGUF/tree/main
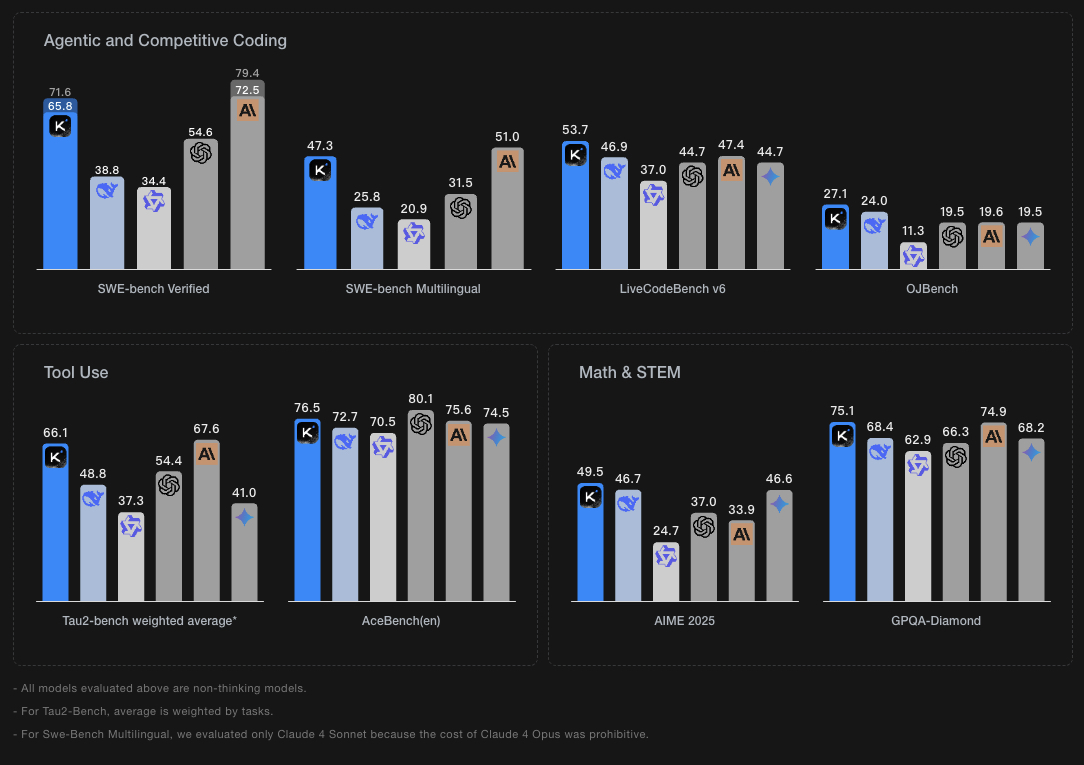
1、Kimi-K2模型效果
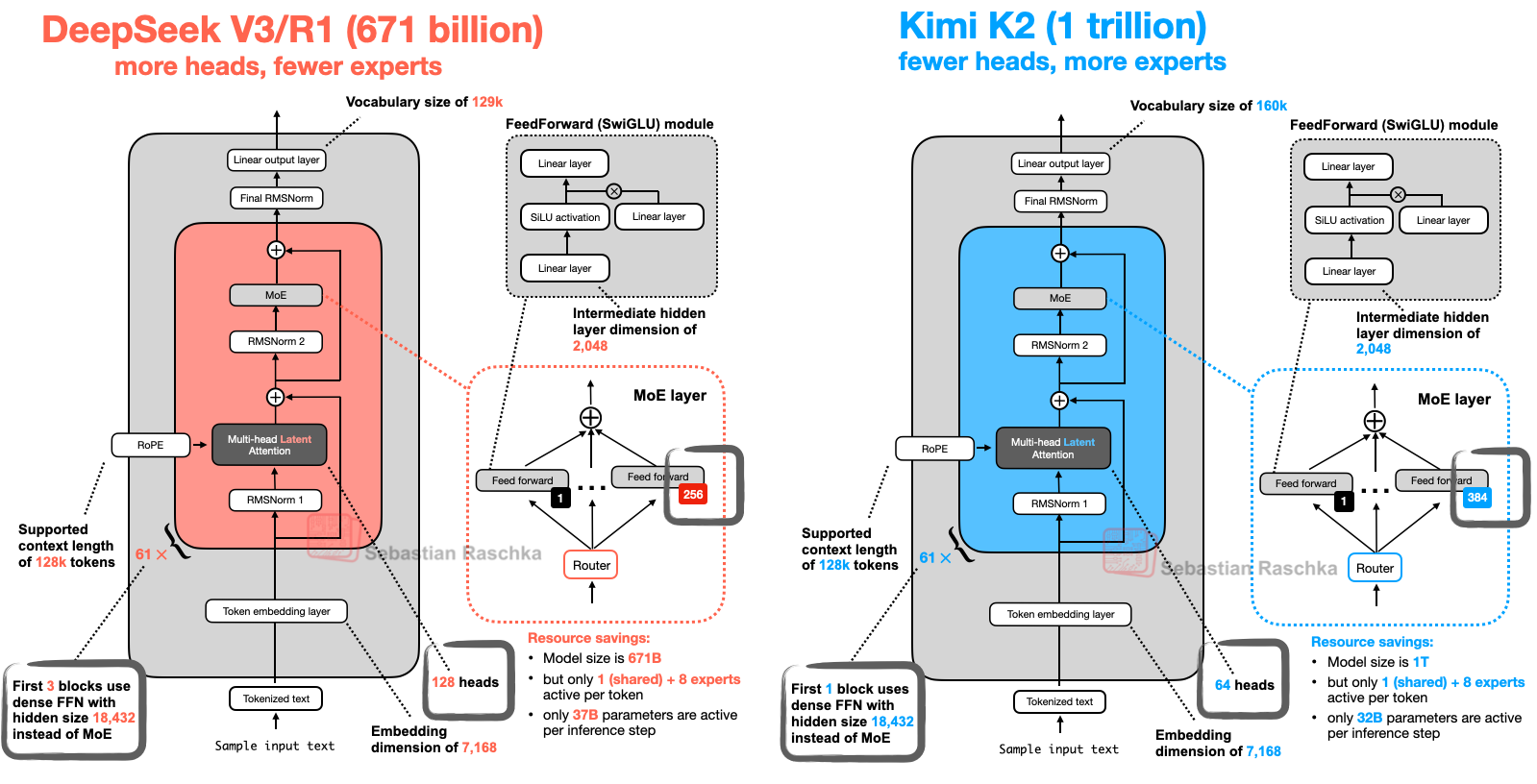
2、Kimi-K2模型架构
- Kimi-K2 与 DeepSeek-R1 架构对比,相比较下 Kimi-k2 增加了专家数量,减少了注意力头的数量。这么设计的好处是,专家数量多无疑知识多,能记住更多东西,在知识广度上表现很好。而减少注意力头则能显著减少显存开销,另外过多的注意力头有时会学习到冗余或过于相似的注意力模式。通过减少头的数量,模型可能被迫让每个头学习到更独特、更关键的特征,这可能有助于防止过拟合,提升模型的泛化能力。
- Kimi K2 是一款具备更强代码能力、更擅长通用 Agent 任务的 MoE 架构基础模型,总参数 1T,激活参数 32B。Kimi K2 的预训练阶段使用 MuonClip 优化器实现万亿参数模型的稳定高效训练,在人类高质量数据成为瓶颈的背景下,有效提高 Token 利用效率
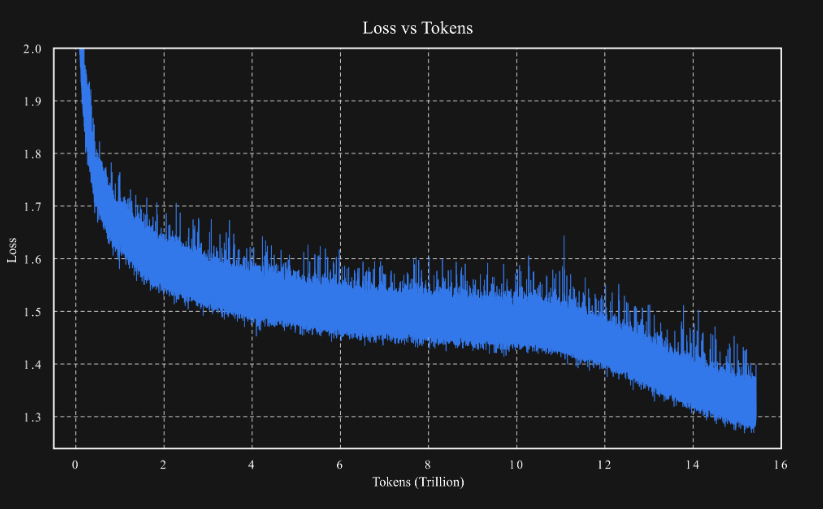
3、MuonClip 优化器:
(1)之前的工作 Moonlight 已经证明,Muon 优化器在 LLM 训练中显著优于广泛使用的 AdamW 优化器。Kimi K2 的设计目标是在 Moonlight 的基础上进一步扩展模型规模,其架构类似于 DeepSeek-V3。基于扩展定律(scaling law)的分析,我们减少了注意力头(head)数量以提升长上下文效率,并提高了混合专家(MoE)的稀疏性以增强 token 效率。在模型扩展过程中,我们遇到了一个持续性的挑战:由于注意力 logits 爆炸导致的训练不稳定问题。在我们的实验中,这一问题在使用 Muon 优化器时比使用 AdamW 更为频繁。现有的解决方案,如 logits 软限制(logit soft-capping)和查询-键归一化(query-key normalization),被证明效果有限。为了解决这一问题,我们提出了 MuonClip 优化器,在 Muon 的基础上引入了我们设计的 qk-clip 技术。具体来说,qk-clip 通过在 Muon 更新之后直接对查询(query)和键(key)投影的权重矩阵进行重新缩放,从而从源头上控制注意力 logits 的规模,达到稳定训练的目的。
(2)MuonClip 能有效防止 logit 爆炸,同时保持下游任务的性能。在实际应用中,Kimi K2 使用 MuonClip 在 15.5T token 的数据上完成了预训练,整个训练过程未出现任何训练尖峰(training spike),证明了 MuonClip 是一种适用于稳定、大规模 LLM 训练的鲁棒性解决方案。
具体细节可以看苏神博客:QK-Clip:让Muon在Scaleup之路上更进一步
4、智能体能力(Agentic Capabilities)
面向工具使用学习的大规模智能体数据合成: 为了教会模型复杂的工具使用能力,我们开发了一套受 ACEBench 启发的综合性数据生成流程,能够大规模模拟现实世界中的工具使用场景。我们的方法系统性地演化出包含数百个领域、数千种工具(包括真实 MCP(Model Context Protocol)工具和合成工具)的环境,并生成拥有不同工具集的数百个智能体。
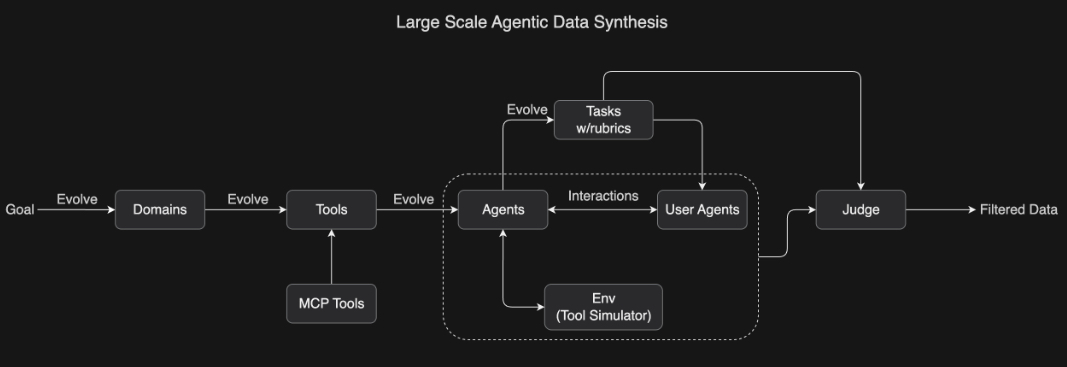
所有任务都基于评分标准(rubric-based)设计,从而实现一致的评估。智能体与模拟环境及用户代理进行交互,构建出真实的多轮工具使用场景。随后,一个大语言模型作为"评审员"根据任务评分标准评估模拟结果,并筛选出高质量的训练数据。这一可扩展的数据生成流程能够生成多样化且高质量的数据,为大规模拒绝采样(rejection sampling)和强化学习奠定了基础。
5、 通用强化学习
关键挑战在于如何将强化学习(RL)应用于具有可验证奖励(verifiable rewards)和不可验证奖励(non-verifiable rewards)的任务。典型的可验证任务包括数学问题求解和竞赛编程,而撰写研究报告通常被视为不可验证任务。
我们的通用强化学习系统不仅限于可验证奖励,还引入了一种自我评判机制(self-judging mechanism),其中模型自身充当评判者(critic),为不可验证任务提供可扩展的、基于评分标准(rubric-based)的反馈。
同时,我们使用在策略(on-policy) rollout 技术处理具有可验证奖励的任务,并利用这些结果持续更新评判者,使其不断提升对最新策略的评估准确性。这种方法可以被看作是利用可验证奖励来改进对不可验证奖励的估计。
二、其他模型架构比较
翻译:从 DeepSeek-V3 到 Kimi K2:八种现代大语言模型架构设计
原文:https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
Reference
1 https://moonshotai.github.io/Kimi-K2/
2 https://github.com/MoonshotAI/Kimi-K2
3 关于kimi-k2的一个回顾帖子,里面提到的一些细节信息可看看:1)模型 Agent 能力的开发还在早期,有不少数据在预训练阶段是缺失的(比如那些难以言语描述的经验/体验),下一代预训练模型仍然大有可为,也就是数据合成。2)关于"写前端"的初衷,关乎产品逻辑。可看看:https://bigeagle.me/2025/07/kimi-k2/,此外,对于一些技术点,可看其中关于技术部分,技术架构等的选择,差异性问题,可看看,https://www.zhihu.com/question/1927140506573435010/answer/1927892108636849910
4 Kimi K2 发布并开源,擅长代码与 Agentic 任务
5 从 DeepSeek-V3 到 Kimi K2:八种现代大语言模型架构设计
英文原版博客:https://sebastianraschka.com/blog/2025/the-big-llm-architecture-comparison.html