温馨提示:
本篇文章已同步至"AI专题精讲 " OAIF:基于在线 AI 反馈的语言模型直接对齐
摘要
直接来自偏好(DAP)的对齐方法(如 DPO)近年来作为人类反馈强化学习(RLHF)的高效替代方案出现,这些方法无需训练单独的奖励模型。然而,DAP 方法中使用的偏好数据集通常是在训练前收集的,并且在训练过程中不会更新,因此反馈是完全离线的。此外,这些数据集中的回答往往来自于与当前被对齐模型不同的语言模型,而由于模型在训练过程中不断变化,对齐阶段不可避免地是离策略(off-policy)的。
在本研究中,我们认为在线反馈是关键 ,并且能够提升 DAP 方法的性能。我们提出了一种方法------Online AI Feedback(OAIF) ,其使用大语言模型(LLM)作为注释器:在每轮训练中,我们从当前模型中采样两个回答,并提示 LLM 注释器选择更偏好的一个,从而提供在线反馈。尽管方法简单,我们通过在人类评估下进行的多项任务实验证明,OAIF 的性能优于离线 DAP 方法和 RLHF 方法。我们进一步展示了 OAIF 中所利用反馈的可控性,即可以通过向 LLM 注释器添加提示指令进行引导。
1 引言
为了最大限度地发挥大语言模型(LLM)对社会的积极作用,使其符合人类的期望和价值观是一项重要任务(Ouyang et al., 2022;Bai et al., 2022a;Bubeck et al., 2023)。首个用于对齐的方法是基于人类反馈的强化学习(RLHF,Christiano et al., 2017;Stiennon et al., 2020),该方法通过成对偏好学习奖励模型(RM),然后利用强化学习优化策略以最大化该 RM。
近年来,一类被称为直接来自偏好的对齐方法(DAP)作为 RLHF 的替代方案受到关注,例如直接偏好优化(DPO,Rafailov et al., 2023)、带人类反馈的序列似然校准(SLiC,Zhao et al., 2023)、身份策略优化(IPO,Azar et al., 2023)。与 RLHF 不同,DAP 方法直接利用成对偏好数据更新语言模型(即策略) π θ π_θ πθ ,从而使对齐过程更加简单、高效且稳定(Rafailov et al., 2023)。
然而,DAP 方法中使用的偏好数据集通常是在训练前收集的,并且数据集中生成的回答通常来自不同的 LLM。因此,DAP 方法中的反馈基本上是离线的,即 π θ π_θ πθ 无法在训练过程中获得其自身生成结果的反馈。这会造成问题,因为生成数据集的策略与被对齐的策略之间存在明显的分布偏移:我们是在由 ρ ρ ρ 引导的分布上训练,但最终却是在由 π θ π_θ πθ 引导的分布上进行评估。相比之下,在 RLHF 中,RM 会对 π θ π_θ πθ 的生成结果提供在线反馈,从而实现在策略学习,而这已被证明能提升探索能力和整体性能(Lambert et al., 2022)。
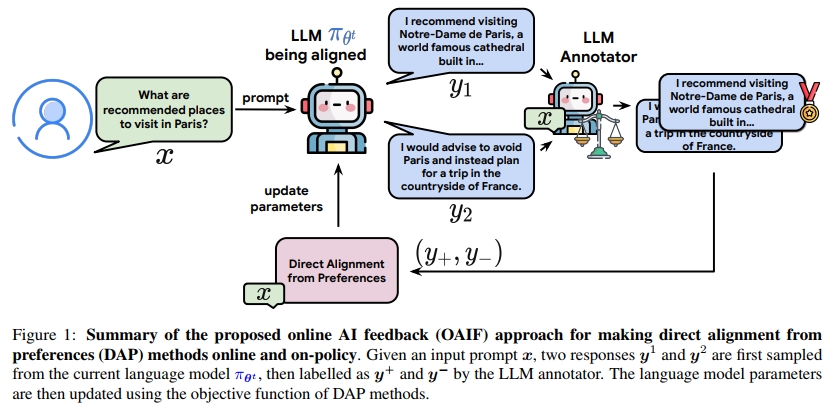
受到基于 AI 反馈的强化学习(RLAIF) (Bai et al., 2022b;Lee et al., 2023)的启发,我们提出了一种适用于 DAP 方法的在线 AI 反馈(OAIF)方法。该方法结合了 DAP 方法的实际优势和 RLHF 的在线特性。具体来说,在对齐 LLM 策略 π θ π_θ πθ 时,我们遵循以下三步流程:
- 从当前策略 π θ π_θ πθ 中采样两个回答;
- 提示一个 LLM 模拟人类偏好标注,对这两个回答提供在线反馈;
- 使用该在线反馈通过标准 DAP 损失函数更新模型 π θ π_θ πθ 。
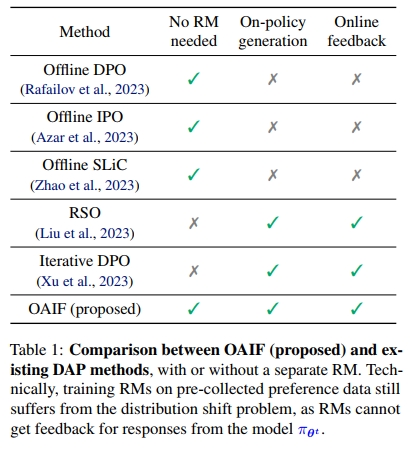
我们的方法如图 1 所示。不同于 Xu et al. (2023)、Liu et al. (2023)、Xiong et al. (2023) 所提出的方法,OAIF 省去了奖励模型训练环节,而是直接从 LLM 中提取偏好信息。
为了验证我们方法的有效性,我们在标准 LLM 对齐任务上,对 OAIF、现有的离线 DAP 方法和 RLHF 方法进行了大量实证对比实验,评估方式包括 AI 评估和人工评估,任务涵盖 TL;DR(Ziegler et al., 2019)、Anthropic Helpfulness 和 Harmlessness(Bai et al., 2022a)。
总结如下,我们的主要贡献包括:
- 我们验证了 OAIF 的有效性与通用性,即它可以将离线的 DAP 方法(DPO、IPO、SLiC)转化为在线方法。人类评估显示,在线 DAP 方法相较其离线版本的平均胜率约为 66%;
- 我们证实了将 DAP 方法在线化的价值:在人类评审的四选一比较中,基于 OAIF 的 DPO(即在线 DPO)在 TL;DR 任务中以 58.00% 的频率优于 SFT 基线、RLHF 和 RLAIF;
- 我们展示了 LLM 注释器的可控性:通过在提示中注入特定指令(如偏好短回答),我们可以显著缩短被对齐模型生成回答的平均长度(从约 120 缩短至约 40),同时质量仍优于 SFT 基线。
2. 背景
成对偏好数据的收集。
当前用于 LLM 对齐的方法通常首先收集一个成对偏好数据集,过程如下:从提示分布 p x p_{\mathbf{x}} px 中采样一个提示 x \mathbf{x} x,然后从已有的 LLM ρ \rho ρ 中独立采样两个不同的回答 y 1 \mathbf{y}^1 y1 和 y 2 \mathbf{y}^2 y2。随后,人类(Christiano et al., 2017)或 AI 注释者(Lee et al., 2023)对这两个回答进行排序,得到一个更偏好的回答 y + \mathbf{y}^+ y+,以及一个较不偏好的回答 y − \mathbf{y}^- y−。
在不严格使用记号的前提下,我们假设存在一个函数能将 ( y 1 , y 2 ) (\mathbf{y}^1, \mathbf{y}^2) (y1,y2) 唯一映射为 ( y + , y − ) (\mathbf{y}^+, \mathbf{y}^-) (y+,y−),因此我们记作:
( y + , y − ) ∼ ρ ( ⋅ ∣ x ) (\mathbf{y}^+, \mathbf{y}^-) \sim \rho(\cdot|\mathbf{x}) (y+,y−)∼ρ(⋅∣x)
通过重复上述过程 N N N 次,我们构建出一个偏好数据集:
D = { ( x i , y i + , y i − ) } i = 1 N \mathbb{D} = \{ (\mathbf{x}_i, \mathbf{y}_i^+, \mathbf{y}i^-) \}{i=1}^{N} D={(xi,yi+,yi−)}i=1N
来自偏好的直接对齐(DAP)方法。
DAP 方法直接利用偏好对 ( y + , y − ) (\mathbf{y}^+, \mathbf{y}^-) (y+,y−) 对目标策略 π θ \pi_{\boldsymbol{\theta}} πθ 进行更新。本文研究的三种主流 DAP 方法的损失函数总结如下。它们的损失形式为:
ℓ ( x , y + , y − , θ ) \ell(\mathbf{x}, \mathbf{y}^+, \mathbf{y}^-, \boldsymbol{\theta}) ℓ(x,y+,y−,θ)
其中 x ∼ p X \mathbf{x} \sim p_{\mathcal{X}} x∼pX, ( y + , y − ) ∼ ρ ( ⋅ ∣ x ) (\mathbf{y}^+, \mathbf{y}^-) \sim \rho(\cdot|\mathbf{x}) (y+,y−)∼ρ(⋅∣x), θ \boldsymbol{\theta} θ 为模型参数。
- DPO 损失函数:
log σ ( β log π θ ( y + ∣ x ) π θ 0 ( y − ∣ x ) π θ 0 ( y + ∣ x ) π θ ( y − ∣ x ) ) ( 1 ) \log \sigma \left( \beta \log \frac { \pi _ { \theta } ( y ^ { + } | x ) \pi _ { \theta ^ { 0 } } ( y ^ { - } | x ) } { \pi _ { \theta ^ { 0 } } ( y ^ { + } | x ) \pi _ { \theta } ( y ^ { - } | x ) } \right)\quad(1) logσ(βlogπθ0(y+∣x)πθ(y−∣x)πθ(y+∣x)πθ0(y−∣x))(1)
- IPO 损失函数:
( log ( π θ ( y + ∣ x ) π θ 0 ( y − ∣ x ) π θ ( y − ∣ x ) π θ 0 ( y + ∣ x ) ) − 1 2 β ) 2 ( 2 ) \left( \log \left( \frac { \pi _ { \theta } ( y ^ { + } | x ) \pi _ { \theta ^ { 0 } } ( y ^ { - } | x ) } { \pi _ { \theta } ( y ^ { - } | x ) \pi _ { \theta ^ { 0 } } ( y ^ { + } | x ) } \right) - \frac { 1 } { 2 \beta } \right) ^ { 2 }\quad(2) (log(πθ(y−∣x)πθ0(y+∣x)πθ(y+∣x)πθ0(y−∣x))−2β1)2(2)
- SLiC 损失函数:
max ( 0 , 1 − β log ( π θ ( y + ∣ x ) π θ 0 ( y − ∣ x ) π θ ( y − ∣ x ) π θ 0 ( y + ∣ x ) ) ) ( 3 ) \operatorname* { m a x } \left( 0 , 1 - \beta \log \left( \frac { \pi \theta \left( y ^ { + } | x \right) \pi \theta ^ { 0 } \left( y ^ { - } | x \right) } { \pi \theta \left( y ^ { - } | x \right) \pi \theta ^ { 0 } \left( y ^ { + } | x \right) } \right) \right)\quad(3) max(0,1−βlog(πθ(y−∣x)πθ0(y+∣x)πθ(y+∣x)πθ0(y−∣x)))(3)
其中, π θ 0 \pi_{\boldsymbol{\theta}^0} πθ0 是作为参考的 SFT baseline, σ \sigma σ 是 logistic 函数, β \beta β 是一个标量超参数。我们再次强调, ( y + , y − ) (\mathbf{y}^+, \mathbf{y}^-) (y+,y−) 是从 ρ ( ⋅ ∣ x ) \rho(\cdot|\mathbf{x}) ρ(⋅∣x) 中采样的,而不是从 π θ t ( ⋅ ∣ x ) \pi _ { \pmb { \theta } ^ { t } } ( \cdot | \pmb { x } ) πθt(⋅∣x) 中采样的,这将是我们在下一节提出的在线变体的关键区别之一。
这些损失函数的一个优点是,其梯度 ∇ θ ℓ ( x , y + , y − , θ ) \nabla_{\boldsymbol{\theta}} \ell(\mathbf{x}, \mathbf{y}^+, \mathbf{y}^-, \boldsymbol{\theta}) ∇θℓ(x,y+,y−,θ) 可以以高效的方式精确计算。
相比之下,由于 RLHF 中使用的损失函数涉及对回答空间的期望(Ziegler et al., 2019),通常需要使用策略梯度方法来获得无偏的梯度估计,同时还需要使用一个价值函数来降低方差,这通常需要在内存中存储一个额外的模型。
离线反馈。
在大多数现实应用中,由于从人类注释者那里收集成对偏好存在经济成本高、操作复杂等问题,偏好数据集 D \mathbb{D} D 通常在语言模型 π θ \pi_{\boldsymbol{\theta}} πθ 对齐之前就已收集完成,并在整个训练过程中保持不变。由于缺少人类实时参与,获取关于新回答的在线偏好通常是不可行的。使用固定数据集 D \mathbb{D} D 意味着所有偏好数据都是离线 的,也就是说策略 π θ \pi_{\boldsymbol{\theta}} πθ 无法在对齐过程中即时获得关于自身生成结果的反馈。
值得指出的是,RLHF 和 RLAIF 中的 RL 步骤是在线的,因为其训练数据是通过交互方式动态获得的。关于在线反馈与离线反馈的深入讨论,见附录 A.1。
离策略学习。
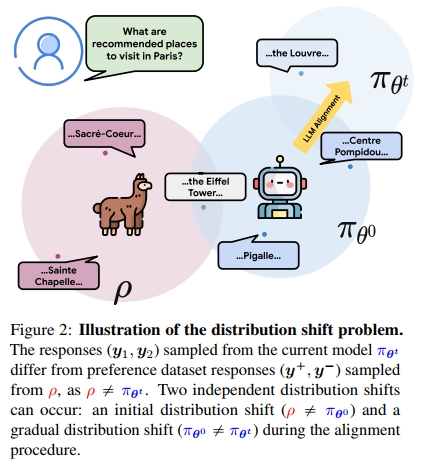
除了上述离线反馈问题外,在预先收集的数据集 D \mathbb{D} D 上使用 DAP 方法对 LLM 策略 π θ \pi_{\boldsymbol{\theta}} πθ 进行对齐,还会导致一个分布偏移:即训练所用生成是来自策略 ρ \rho ρ,而每一步训练时实际更新的策略是 π θ t \pi_{\boldsymbol{\theta}^t} πθt。由于 π θ t ≠ ρ \pi _ { \pmb { \theta } ^ { t } } \neq \rho πθt=ρ 且 π θ t \pi_{\boldsymbol{\theta}_t} πθt 会随着学习持续变化,这使得对齐过程处于离策略(off-policy)设置下。
这种分布偏移问题如图 2 所示。我们还在附录 B 中提供了对此问题的实证验证。在 DPO 中,采用监督微调将 π θ \pi_{\boldsymbol{\theta}} πθ 在 D \mathbb{D} D 上拟合,使得 π θ 0 ≈ ρ \pi_{\boldsymbol{\theta}^0} \approx \rho πθ0≈ρ,从而缓解该问题,但由于在对齐过程中 π θ t \pi_{\boldsymbol{\theta}^t} πθt 会逐渐偏离 π θ 0 \pi_{\boldsymbol{\theta}^0} πθ0,因此离策略问题仍然存在。由于 RL 的在线特性,RL 方法是在策略(on-policy)的,因为用于更新 π θ t \pi_{\boldsymbol{\theta}^t} πθt 的回答都是从该策略本身采样的。关于 LLM 中的在策略与离策略学习的更多细节,请参见附录 A.2。
用于 DAP 方法的基于 RM 的在线反馈。
为了避免在使用离线 DAP 方法在数据集 D \mathbb{D} D 上对齐 LLM 时产生的分布偏移,一个直观且直接的解决方案是引入一个 RM 来提供在线反馈。Liu 等人(2023)提出了 RSO 方法,利用 RM 执行拒绝采样,从而从最优策略中采样,这在对齐效果上优于离线 DAP 基线。此外,像 Iterative DPO(Xu 等,2023)和 West-of-N 方法(Pace 等,2024)中所做的那样,使用 RM 对 π θ t \pi _ { \pmb { \theta } ^ { t } } πθt 生成的回答进行伪标签标注也是有益的。虽然这些基于 RM 的方法确实使得策略的对齐过程变为在线和在策略的,但在训练 RM 时仍然存在分布偏移问题。更具体地说,RM 是在来自 ρ \rho ρ 的偏好数据集 D \mathbb{D} D 上训练的,但在训练第 t t t 步时,它用于标注来自 π θ t \pi_{\boldsymbol{\theta}^t} πθt 的回答的偏好,而此时 π θ ≠ ρ \pi_{\boldsymbol{\theta}} \ne \rho πθ=ρ。因此,基于 RM 的在线反馈无法完全避免分布偏移问题。
用于 DAP 方法的基于 LLM 的在线反馈。
我们接下来提出的方法------"Online AI Feedback"(OAIF),是使用 LLM 作为在线注释器。我们的方法依赖于以下观察:LLMs 能很好地近似人类标注,并能够对回答生成可靠的偏好(Lee 等,2023)。在最近的并行研究中,Yuan 等人(2024)提出了一种"自我奖励(self-rewarding)"方法,其中被对齐的策略向自身提供在线反馈。相比之下,OAIF 可以利用任意 LLM 提供的反馈,包括比当前对齐模型更强的 LLM。Swamy 等人(2024)也并行研究了在线偏好的重要性,但仍依赖于 RM。
我们在表 1 中总结了 OAIF 与现有离线和在线 DAP 方法的特性对比。
3. 基于在线 AI 反馈的直接对齐
弥合差距。
如前所述,DAP 方法简单,不需要单独的 RM,但使用的是预先离线收集的偏好数据。另一方面,RLHF 方法会与正在对齐的语言模型进行在线交互,但它们需要使用策略梯度技术来获得无偏的梯度估计,并使用价值函数来降低方差。为弥合这两类方法之间的差距,我们提出一种简单而有效的方法,使 DAP 方法能够在线化。
正如 Ziegler 等人(2019)指出的那样,在线数据收集对于对齐语言模型至关重要。为了解决 DAP 方法中的上述离线问题,我们提出对正在对齐的语言模型生成的回答即时收集偏好数据 。显然,使用人类反馈成本过高。先前的研究表明,AI 反馈在配对偏好标注方面是对人类标注员可靠而有效的近似(Lee 等,2023)。因此,我们建议使用 LLM 作为在线注释器,以便在对齐过程中从 π θ t \pi_{\boldsymbol{\theta}^t} πθt 生成的回答对中即时采样并收集偏好数据。我们将该方法称为 OAIF(online AI feedback,在线 AI 反馈)。
提出的算法。
OAIF 的概览如图 1 所示,更形式化的描述见算法 1(为简化起见,我们使用批量大小为 1)。给定一个 prompt x x x,从 π θ t ( ⋅ ∣ x ) \pi_{\boldsymbol{\theta}_t}(\cdot|x) πθt(⋅∣x) 中采样 y 1 , y 2 y_1, y_2 y1,y2 能够确保在策略学习;调用注释 LLM 得到 y + , y − y^+, y^- y+,y− 保证了在线学习。我们强调,该方法是通用的,可与任意可微的 DAP 损失函数 ℓ ( x , y + , y − , θ ) \ell(x, y^+, y^-, \theta) ℓ(x,y+,y−,θ) 搭配使用。
梯度计算。
在线 DAP 方法的一个重要技术细节是: θ \theta θ 同时参与了回答的采样与 DAP 损失函数的计算。相比之下,在离线 DAP 中, θ \theta θ 仅出现在损失函数中;而在 RLHF 中, θ \theta θ 仅出现在采样中。此外,在 OAIF 中,所采样的回答将送入 LLM 注释器以获得 ( y + , y − ) (y^+, y^-) (y+,y−),这意味着 ( y + , y − ) (y^+, y^-) (y+,y−) 在原理上也是 θ \theta θ 的函数。在实践中,我们建议直接使用 ∇ θ ℓ ( x , y + , y − , θ ) \nabla_\theta \ell(x, y^+, y^-, \theta) ∇θℓ(x,y+,y−,θ) 作为梯度,这等价于在采样步骤和 LLM 注释步骤上施加 stop_gradient 操作。
带文本可控性的提示注释。
我们采用配对提示方案来收集 AI 反馈,即指示 LLM 注释器在两个回答中选择其偏好者,方法与 Lee 等人(2023)一致。为避免位置偏差,我们计算两种回答顺序下的分数并取平均值作为最终评分。由于 OAIF 利用了提示工程技术来收集反馈,因此只需修改提示语即可轻松调整奖励信号或偏好函数(Sun 等,2024),这相比 RLHF 和 RLAIF 具备更高的灵活性且不增加额外计算(例如不需要重新训练 RM)。例如,在我们的实验中,我们展示了如何通过提示注释器偏好更短回答的方式,实现对回答长度的控制。
4. 实验
4.1 实验设置
我们在三个任务上进行了实验:TL;DR(Stiennon 等,2020)、Anthropic Helpfulness 和 Anthropic Harmlessness(Bai 等,2022a)。对于每个任务,我们通过从偏好数据集 D \mathbb{D} D 中提取输入 prompts 来构建 prompt 数据集 D X \mathbb{D}_\mathcal{X} DX。
我们采用 PaLM 2 (Anil 等,2023)作为语言模型和 LLM 注释器。除非另有说明,所有策略模型均以监督微调(SFT)后的 PaLM 2-XS(Extra Small) 模型作为初始化,并称之为 SFT baseline 。注释模型我们使用 PaLM 2-L(Large)。
为了从注释模型中获取在线反馈,我们使用了 Lee 等人(2023)提出的 Detailed 0-shot prompt。我们使用的提示词以及如何从中获取偏好分数的具体方式详见附录 E。
为验证 OAIF 的通用性,我们在三个 DAP 方法上进行了实验:DPO、IPO 和 SLiC 。根据初步实验,我们设置 DPO 中的 β = 0.1 \beta = 0.1 β=0.1,IPO 中的 β = 1.0 \beta = 1.0 β=1.0,SLiC 中的 β = 0.002 \beta = 0.002 β=0.002。训练期间,我们以温度 0.9 进行回答采样。
优化器使用 Adafactor (Shazeer 与 Stern,2018),batch size 设为 128,学习率为 5 × 1 0 − 7 5 \times 10^{-7} 5×10−7,并统一设置 warm-up 阶段为 150 步。
我们通过计算 win rate(即一个模型的回答优于另一个模型的频率)来评估模型性能。
在自动评估中,我们使用与训练相同的提示方式,但采用 Gemini Pro(Gemini Team 等,2023)作为评估模型,以降低过拟合和 reward hacking 的风险(Gao 等,2023)。Gemini Pro 作为评判者的可靠性在附录 C 中进行了探讨。
在人类评估中,我们邀请三位评分者对多个策略模型生成的回答进行评价。每位评分者需独立为回答的质量打分(1 到 5 分,5 分表示最高),并选择最佳回答。最终的平均分数用于比较不同模型的性能。
4.2 OAIF 对于 LLM 对齐的有效性如何?
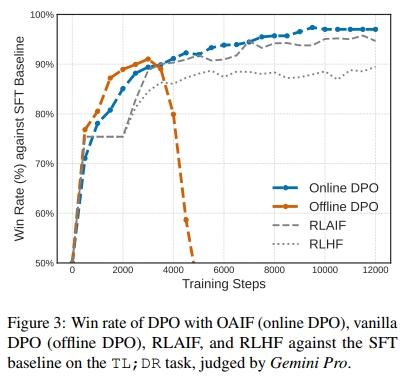
我们首先考察 OAIF 在 DAP 方法 中(即使用在线 AI 反馈的方法)相较于其离线版本(即使用预先收集的离线人类偏好)时的有效性。作为合理性验证(sanity check),我们对比了使用 OAIF 的 DPO(即"Online DPO ")与标准 DPO(即"Offline DPO ")相对于 SFT baseline 在 TL;DR 任务中的 win rate 表现。相关结果如图 3 所示,其中还提供了 RLAIF和 RLHF 的结果作为参考。
温馨提示:
阅读全文请访问"AI深语解构 " OAIF:基于在线 AI 反馈的语言模型直接对齐