演讲人:魏博文(阿里云计算平台大数据AI解决方案总监)
演讲主题:阿里云后训练解决方案
活动:甲子光年围炉夜话-后训练技术闭门会
目前大模型能力已经足够优秀,模型后训练作为大模型落地的重要一环,能显著优化模型性能,适配特定领域需求。相比于模型预训练,后训练阶段对计算资源和数据资源需求更小,更易迭代,为大语言模型提供了针对特定业务场景调优的能力,打通了通用大模型到垂直领域应用的"最后一公里"。
阿里云大数据 AI 平台重磅发布大模型后训练解决方案,通过全栈 AI 能力 ,为企业提供从算力到平台的"后训练"一体化支撑 。凭借稳定、高效、全能的产品特性,让企业从容面对大模型后训练阶段复杂的系统性工程挑战。使用阿里云大数据 AI 平台大模型后训练解决方案,实现训练效率100%的提升,有效助力大模型后训练技术在各行各业的落地。
一、后训练技术持续演进过程中的行业现状
在 AI 加速重塑千行百业的浪潮中,作为提升模型业务适配力的关键步骤,"后训练"的技术持续处于演进中。大模型技术架构逐渐从 Dense 转向 MoE,混合精度训练从 BF16 向 FP8 迁移,强化学习(RL)技术也在各行各业中尝试落地。
以训练方式转向 RL 为例,RL 的训练过程表现出高度敏感性,"非常的脆弱",数据分布或策略参数的微小变化即可能破坏收敛性。在这个过程中需通过持续监控,并且对数据和策略的动态调整,保障RL模型的顺利训练。这时候,平台的能力变得非常关键。
后训练不仅关乎算法层的优化,更依赖底层算力、平台能力与应用层协同,确保全链路的可行性与稳定性。用户对平台的需求,不再是预训练阶段仅需把数据规整好提供给平台后等待结果那么简单了,在后训练阶段,用户需要的是一个安全稳定、性能卓越且功能全面的平台 。越来越多企业认识到:唯有"云+AI"的融合,才能从底层资源到应用层全面释放 AI 价值。
二、革新架构的破局:后训练解决方案突破效能边界
针对企业大模型后训练的需求,阿里云大数据 AI 平台发布大模型后训练解决方案。以稳定、高效、全能的方案优势,将企业从繁重的底层工程中解放出来,专注于业务创新。
在基础设施层,阿里云部署遍布全球的基础设施,可根据SFT、RL、推理等不同负载弹性提供算力资源,确保不同阶段的训练任务都能获得最优的算力配比和成本效益,从而为复杂的后训练、及推理服务流程提供稳定且经济的算力基座。在模型层,通义千问Qwen系列基础模型能力领先,支持多模态、多尺寸、多架构,客户无需预训练即可启动后训练,快速适配业务场景,显著降低开发门槛与周期。同时,PAI-Model Gallery 已集成 Qwen、Deepseek 在内的等300+顶尖模型,可零代码实现微调、部署与评测,覆盖金融、汽车、教育等多行业需求。
值得一提的是,围绕"数据-训练-推理-AI应用"的全生命周期,阿里云大数据 AI 平台为后训练提供端到端支撑,保障从基模选择、数据准备、模型训练到部署上线的每一个环节都能高效运行且无缝对接。
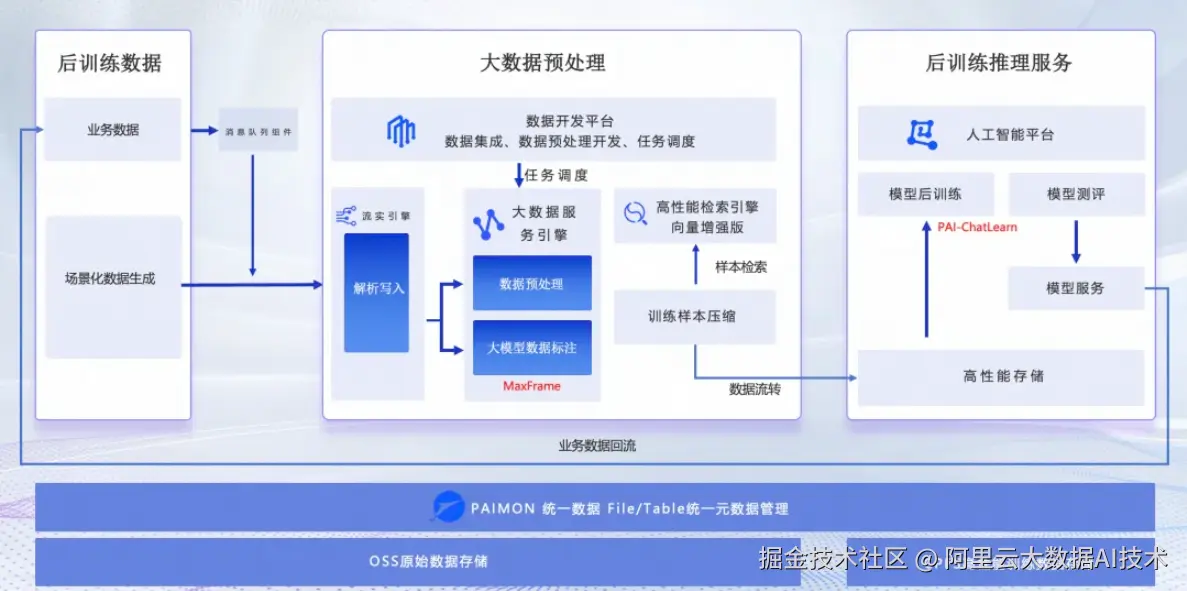
阿里云后训练解决方案架构图
在数据处理阶段,阿里云提供面向AI场景的多模态数据处理方案,接入业务数据和场景化合成的数据,通过 MaxCompute MaxFrame+PAI-EAS+Flink 等产品实现统一的数据处理体验,支持百万任务调度与管理,整体数据处理效率提升10倍以上,数据处理推理任务优化提速1倍以上,相同资源产能提升1倍。大数据开发治理平台 DataWorks 负责数据集成、数据预处理任务开发和任务调度,确保数据能够被高效地处理和利用。实时计算 Flink 版作为流式引擎,提供端到端亚秒级实时数据分析能力,实时解析并写入接收到的数据,将其转化为可处理的格式。MaxCompute 将 AI 的能力应用于数据预处理环节,发布科学计算框架 MaxFrame。MaxFrame 是构建在大规模计算平台 MaxCompute 之上的完全兼容 Python 生态的分布式计算引擎,支持 Python 编程接口,兼容 Pandas 等数据处理及 ML 算子接口且自动实现分布式处理,同时提供 AI Function 调用能力,实时调用大模型,进行多模态数据预处理,以满足用户不断增长的在 Python 生态中高效进行大数据处理和AI开发的需求。方案可集成 Hologres 和高性能向量增强引擎 Elasticsearch 实现海量数据的实时查询和向量数据的毫秒级检索;可使用 Data-Juicer 在亿级别甚至千亿级别的样本量级下,实现高效的大规模数据预处理。
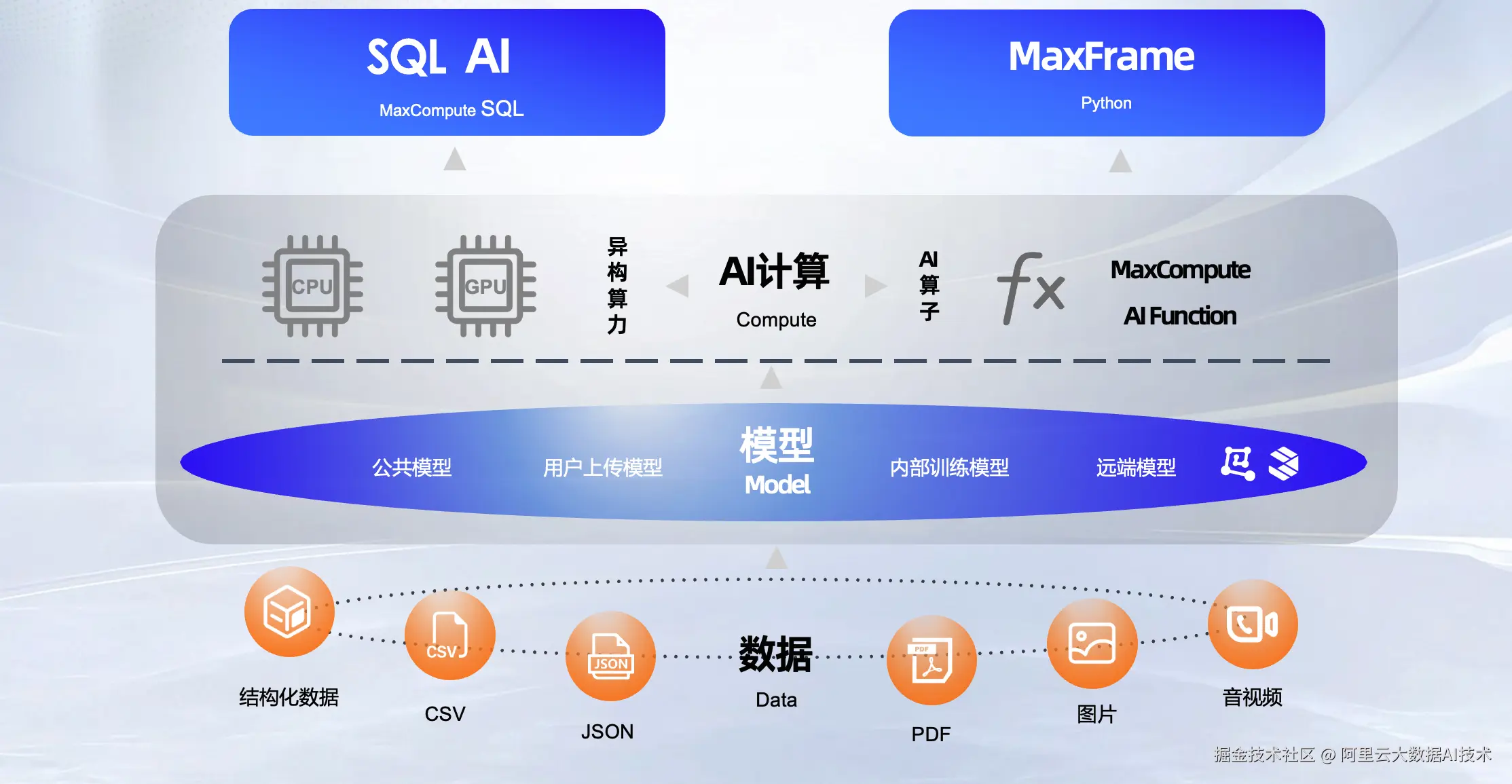
MaxCompute Data+AI 加速后训练数据预处理
在模型训练方面和模型部署阶段 ,针对 MoE 架构模型在通信和算子层面持续优化,搭载自研大规模 MoE 混合精度训练引擎 PAI-FlashMoE 和灵活、易用、高效的大规模强化学习训练框架 PAI-Chatlearn,支持 RLHF、DPO、GRPO 等多种先进的 Alignment 训练算法,支持任意模型的后训练任务快速配置,万卡规模 MoE 架构训练 MFU 达 35%-40%。实验数据表明,Qwen3-30B-A3B 模型在 4*GU8T 资源环境下,PAI-ChatLearn 相较于开源的框架来说,训练的吞吐基本上提升2倍以上 。模型在线服务平台 PAI-EAS 具备分布式推理能力,通过创新的多机Prefill-Decode-EP分离架构,结合 LLM 智能路由和 MoE 分布式推理调度引擎 Llumnix,能显著提升推理速度和资源利用率以降低模型使用成本,做到首Token生成响应时间降低92%,端到端服务吞吐提升5倍+。PAI-ModelGallery 支持包含 Qwen、DeepSeek 在内的 300 +模型的零代码一键后训练、评测、部署。

PAI-ChatLearn 整体技术架构和特点
新发布的大模型后训练解决方案在性能、成本、功能、安全等多维度均有着突出优势:
-
模型训练效率提升:MoE SFT 训练MFU 超 35%+ ,强化学习训练效率提升 200%,训练资源规模效率提升 100%;
-
模型推理效率提升:首 Token 生成响应时间降低 92%,端到端服务吞吐提升 5 倍+;
-
一体化开发效率提速:数据包处理效率相比自建提升 10 倍以上,数据处理推理任务优化提速 1 倍以上,相同资源产能提升 1 倍;
-
支持百万级任务管理及并发调度,每拉起 10000 CU资源运行仅需不到 10 秒;
-
全链路样本数据血缘存储和检索分析,数据合规安全保护;
-
企业级 Serverless 化平台,稳定可靠,兼容开源生态。
三、技术底座揭秘:解决方案核心产品全解析
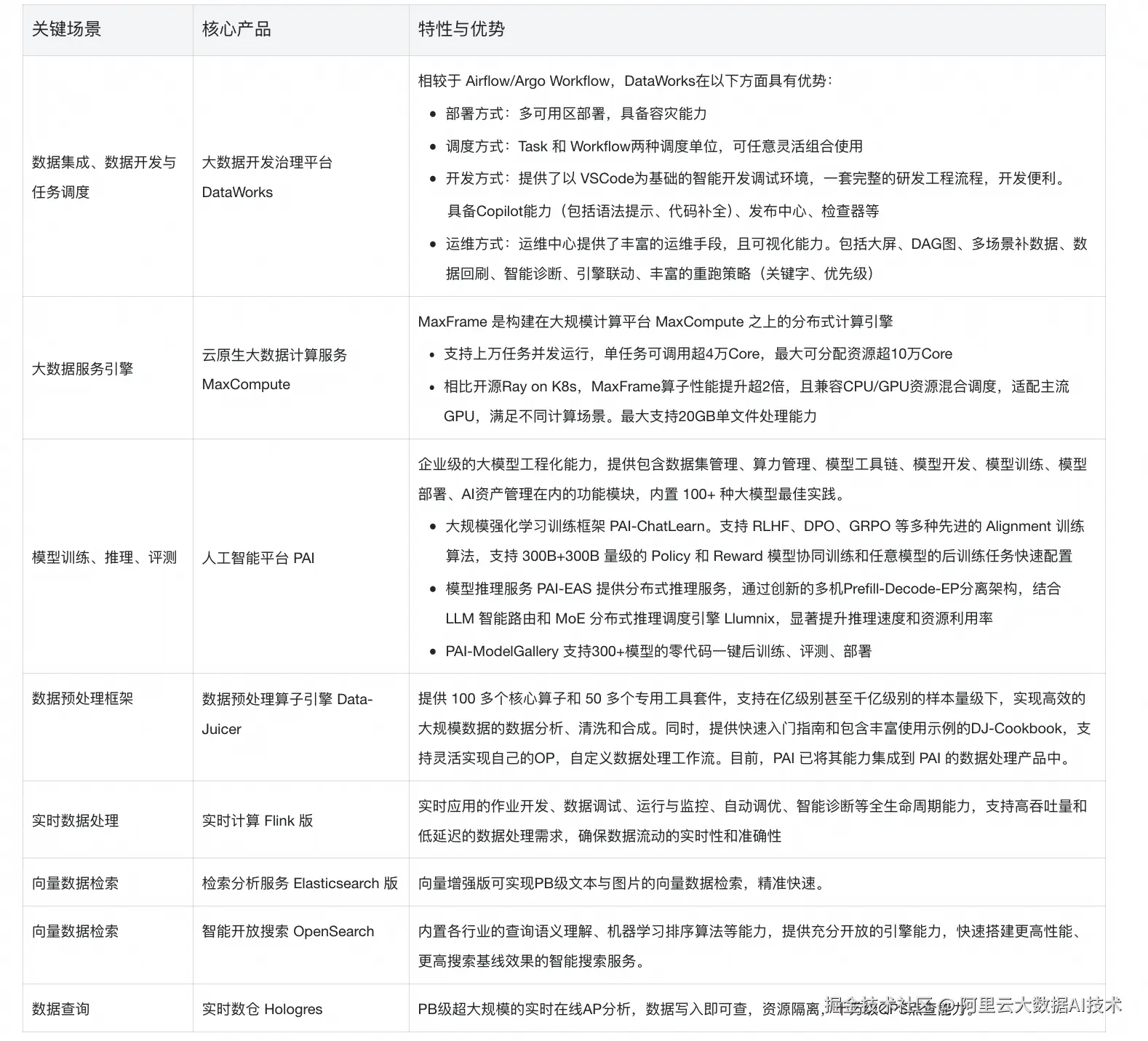
大模型后训练解决方案是基于人工智能平台和大数据产品构建的,关键场景的产品作用见下表:
大模型后训练方案的发布,标志着我们在构建高质量、可落地的大模型应用道路上迈出了坚实一步。未来,阿里云大数据AI平台将持续深耕大模型全生命周期的技术能力建设,不断优化数据处理、模型训练与推理效率,推动大模型在更多行业与场景中的深入应用,助力企业实现智能化升级与业务突破。