文章目录
- 数据库开发
-
- Day15:MySQL基础(一)
-
- 一、MySQL介绍与安装
- 二、SQL简介
- 三、数据库操作
- 四、数据表操作
- 五、表记录操作
-
- 5.1、添加记录
-
- 【1】INSERT...VALUES语句
- [【2】 INSERT...SET语句](#【2】 INSERT…SET语句)
- 5.2、查询记录
-
- 【1】查询字段(select)
- 【2】where语句
- 【3】order:排序
- [【4】group by:分组查询](#【4】group by:分组查询)
- 【5】limit:记录条数限制
- 【6】distinct:查询去重
- 5.3、更新记录
- 5.4、删除记录
数据库开发
从古至今人们都有存储数据的需求,比方说记录账目开支、货物清单、人口统计等等等等,存储的方式也一直在变化。
很久很久以前,人们把数据存在动物骨头上,后来存到竹片上,再后来存到纸上,直到近代发明了磁带留声机啥的,不过这些都是依赖人工进行整理、保存和查询的,特点就是效率低下、错误率高、查找不方便等等等等。
后来人们发明了计算机,为了管理各种数据,人们发明了一种叫文件系统的东东,可以方便的通过文件的存储路径和文件名来访问各个文件的内容,计算机程序也可以直接通过文件系统来操作各种文件,比人工管理爽多了。
随着文件中存储的内容越来越多,在文件中修改和查找某些数据已经变得非常困难了,所以人们发明了一种专门的软件来管理存储的数据,这些数据依照一定格式保存,通过这个软件可以方便的对数据进行增删改查操作,从而极大的提升了数据管理效率,人们就把这个管理数据的软件叫做数据库管理系统(英文:Database Management System,简称:DBMS)。
Day15:MySQL基础(一)

一、MySQL介绍与安装
【1】MySQL介绍
MySQL是一种开源的关系型数据库管理系统(RDBMS),它是最流行和广泛使用的数据库系统之一。
-
1996年,MySQL 1.0,由瑞典公司MySQL AB开发
-
2008年1月16号 Sun公司收购MySQL。
-
2009年4月20,Oracle收购Sun公司。
MySQL以其高性能、稳定性和可靠性而闻名,由于其体积小、速度快,尤其是开放源码这一特点,并被广泛应用于各种规模的应用程序和网站。
(5)启动MySQL服务
方式1:启动服务进程
把mysql注册到操作系统作为系统服务,保证将来电脑重启了就可以开机自启了。在上面打开的黑窗口中如下以下命令:
bash
# 启动mysql服务
mysqld确认是否安装到了系统服务,可以通过【此电脑】- 【右键】-【管理】- 【服务与应用程序】 - 【服务】- 【右边窗口】
快捷方式:
- 按下Ctrl + Alt + Del组合键。
- 在弹出的菜单中,选择"任务管理器"。这将打开任务管理器。

注意这是进程,不是系统服务
通过以下命令按回车键,接着输入上面初始化的登陆密码,就可以登陆MySQL交互终端了。
bash
mysql -uroot -p
# 退出终端
# exit方式2:注册系统服务并启动
安装名为"mysql80"的MySQL服务,但一定注意需要管理员权限,否则报权限错误
管理员权限启动终端:
- 在开始菜单中找到 "命令提示符"。
- 右键单击 "命令提示符" 并选择 "以管理员身份运行"。
- 如果系统提示确认,点击 "是" 或 "继续" 以授予管理员权限。
bash
mysqld --install mysql80
# 注销服务,用于卸载的,别乱用
# mysqld --remove mysql80mysql80就是自己取的服务名(服务器是唯一的),只要符合python的变量规则,不要使用中文,可以自己发挥。
windows下安装的mysql默认是没有启动服务的。
bash
net start mysql80
# 关闭mysql的命令:
# net stop mysql80
# 重启mysql的命令:
# net start mysql80通过以下命令按回车键,接着输入上面初始化的登陆密码,就可以登陆MySQL交互终端了。
bash
mysql -uroot -p
# 退出终端
# exit注意:mysql与linux一样,在安装成功以后默认就存在了一个权限最高的用户,叫root用户。
(6)修改root登陆密码
接下来的操作是在登陆了mysql终端以后的操作。
bash
alter user 'root'@'localhost' identified by '123';
# 'root' 就是要修改密码的用户名
# 'localhost' 表示允许用户在什么地址下可以使用密码登陆到数据库服务器,localhost表示本地登陆
# '123' 就是新的密码了,注意,不要设置空密码!以后公司里面的密码一定要非常难记的才最好。完成了上面的操作以后,mysql就安装完成了。
二、SQL简介
对数据库进行查询和修改操作的语言叫做 SQL(Structured Query Language,结构化查询语言)。SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
SQL 是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。与其他程序设计语言(如 C语言、Java 等)不同的是,SQL 由很少的关键字组成,每个 SQL 语句通过一个或多个关键字构成。
在使用它时,只需要发出"做什么"的命令,"怎么做"是不用使用者考虑的。SQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库(Oracle、DB2、Sybase、SQL Server )均支持sql。
SQL的规范:
在数据库系统中,SQL语句不区分大小写(建议用大写) 。但字符串常量区分大小写。建议命令大写,表名库名小写;
SQL语句可单行或多行书写,以";"结尾。关键词不能跨多行或简写。
用空格和缩进以及折行来提高语句的可读性。子句通常位于独立行,便于编辑,提高可读性。
sqlSELECT column1, column2, column3 FROM table1 WHERE column1 = 'value1' AND column2 = 'value2' AND column3 = 'value3'
- 注释:
sql-- 单行注释 /* 多行注释 */
三、数据库操作
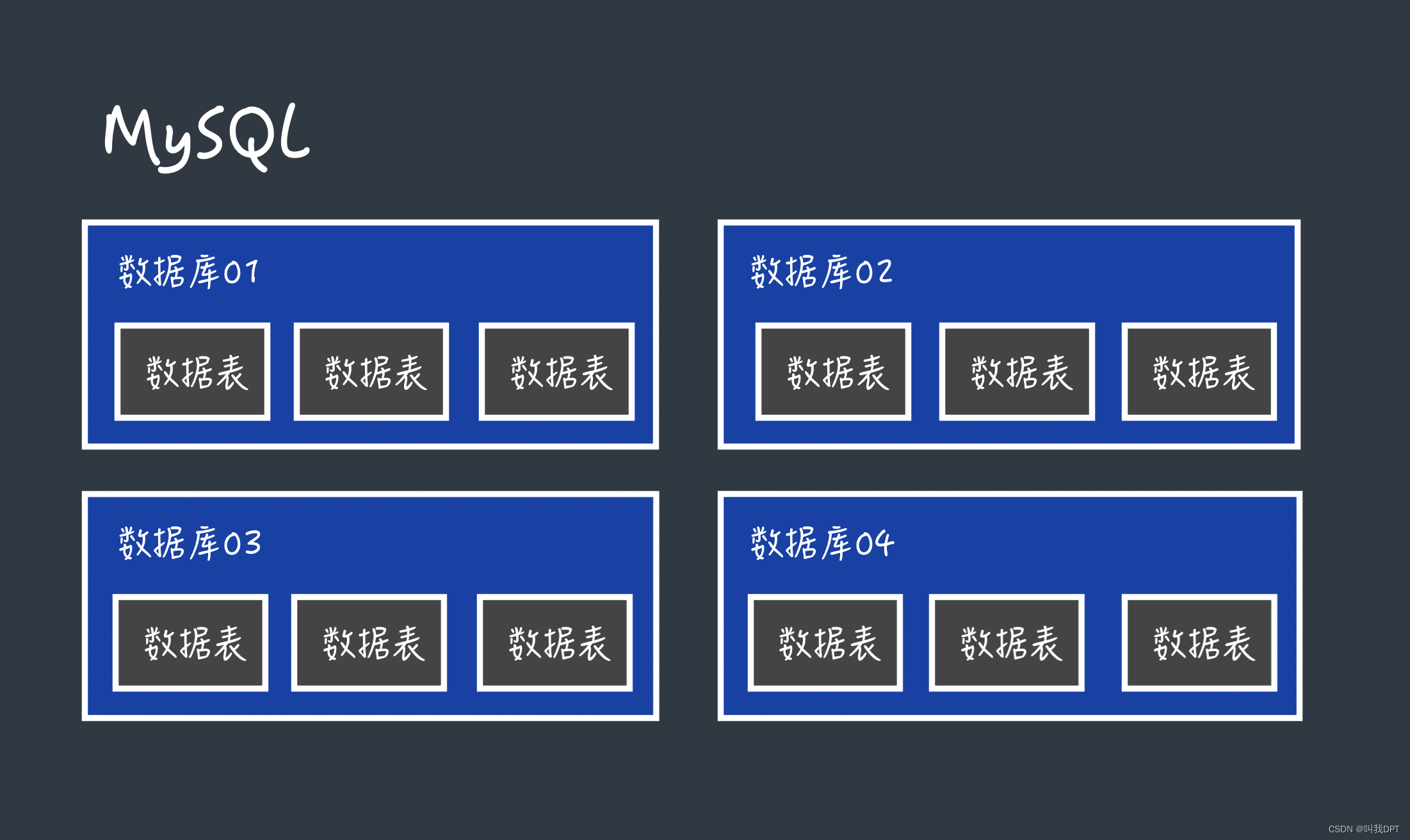
数据库的操作:
select database();查看当前数据库。只有刚进入数据库是是null初始状态,一旦选择数据库就回不去了,只能从一个数据库直接换到另一个数据库,而不是先回到初始状态再转到某数据库。
mysqldump -uroot -p123456 库名 > backup.sql; 数据库备份操作。要退出数据库的环境执行。只需要执行sql文件就可以生成一样的数据库。
sql
-- 1.创建数据库(在磁盘上创建一个对应的文件夹)
create database [if not exists] db_name [character set xxx]
-- 2.查看数据库
show databases; -- 查看所有数据库
SHOW DATABASES LIKE '%test%';-- 查看名字中包含 test 的数据库
show create database db_name; -- 查看数据库的创建方式
-- 3.修改数据库
alter database db_name [character set xxx]
-- 4.删除数据库
drop database [if exists] db_name;
-- 5.使用数据库
use db_name; -- 切换数据库 注意:进入到某个数据库后没办法再退回之前状态,但可以通过use进行切换
select database(); -- 查看当前使用的数据库
-- 数据库备份
mysqldump -u username -p password database_name > backup.sql使用 DROP DATABASE 命令时要非常谨慎,在执行该命令后,MySQL 不会给出任何提示确认信息。
DROP DATABASE 删除数据库后,数据库中存储的所有数据表和数据也将一同被删除,而且不能恢复。因此最好在删除数据库之前先将数据库进行备份。
四、数据表操作
数据表是数据库的重要组成部分,每一个数据库都是由若干个数据表组成的。比如,在电脑中一个文件夹有若干excel文件。这里的文件夹就相当于数据库,excel文件就相当于数据表。
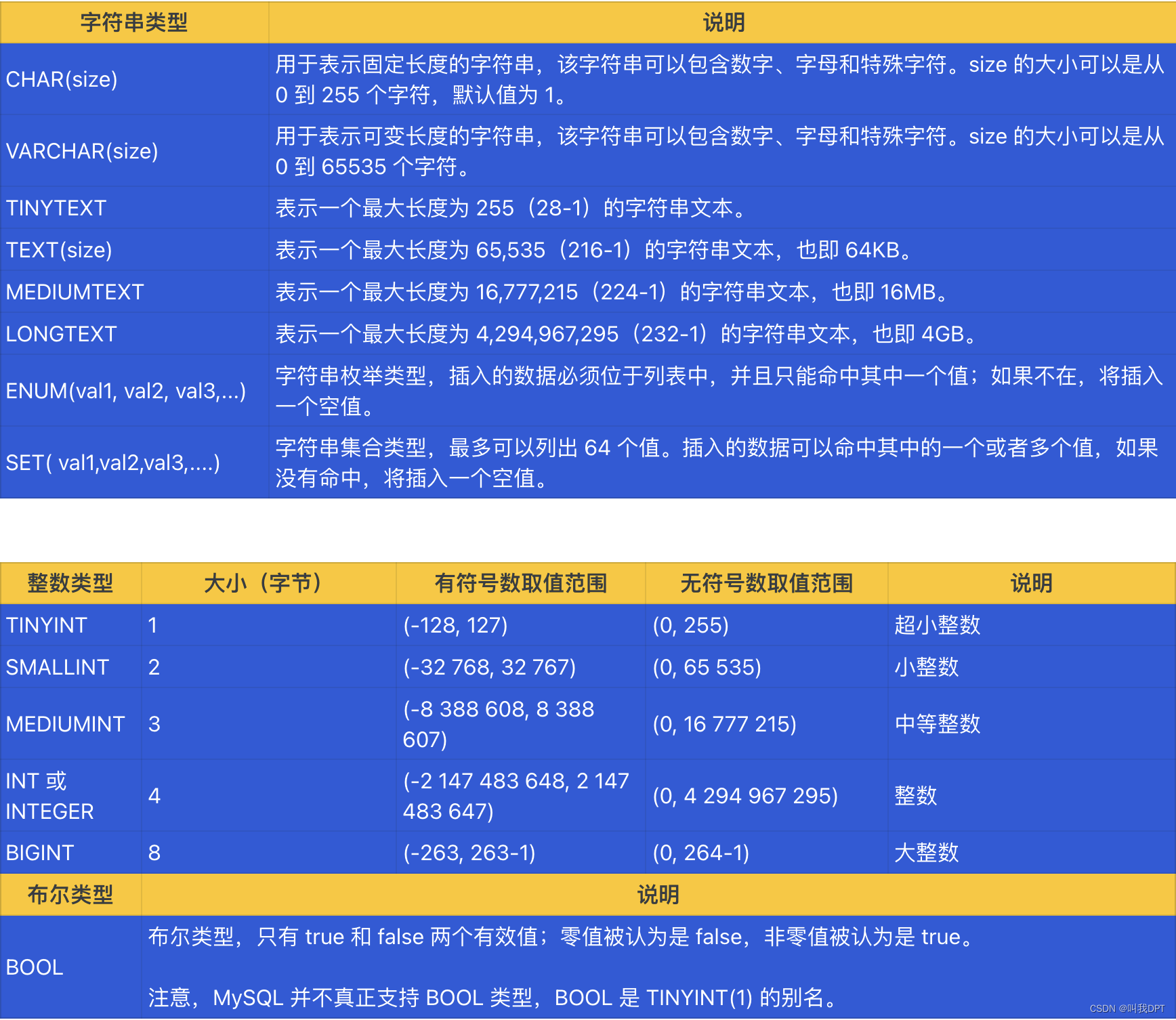
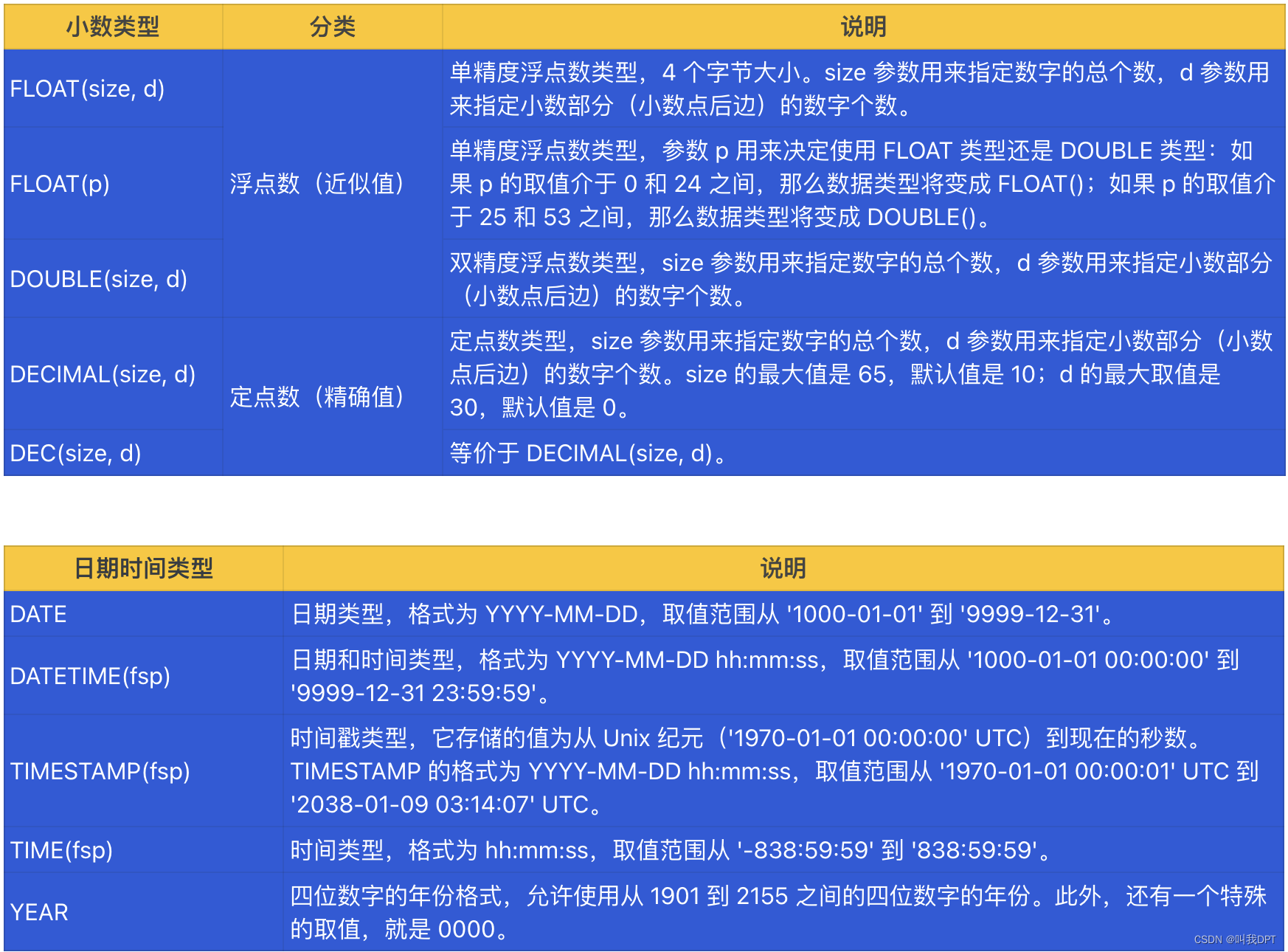
MySQL 的数据类型有大概可以分为 5 种,分别是整数类型、浮点数类型、日期和时间类型、字符串类型、二进制类型等。
4.1、数据库数据类型
数据库的数据类型:
最常用的VARCHAR和CHAR,TEXT,ENUM,SET。
INT系列。DECMAL系列。
DATETIME,事件类型系列。
BINARY,VARBINARY,BIT二进制系列。
数据库是有bool类型的,但是不能识别TRUE和FALSE关键字。所以可以通过VARCHAR(1),TINYINT(1)类型,通过1和0的方式来表示布尔类型。更好的是BIT(1)类型来表示,因为BIT(比特)类型只能存放1和0,会更节约空间。
在 MySQL 中,布尔类型被称为 BOOLEAN 或 BOOL 类型。BOOLEAN 类型用于存储布尔值,即 TRUE(真)或 FALSE(假)。
MySQL 中的布尔类型可以有以下几种表示方式:
- 整数类型:布尔类型可以表示为整数类型,其中
0表示FALSE,非零整数表示TRUE。常见的表示TRUE的整数值为1。 - 字符串类型:布尔类型也可以表示为字符串类型,其中
'0'表示FALSE,而'1'表示TRUE。这种表示方式更贴近人类可读的布尔值。
需要注意的是,尽管 MySQL 支持布尔类型的不同表示方式,但它并没有专门的存储布尔值的数据类型。在实际使用中,你可以选择使用 TINYINT(1) 或 VARCHAR(1) 等其他数据类型来存储布尔值,但约定使用 0 和 1 或 '0' 和 '1' 来表示布尔值。

BIT数据类型可以用来存储布尔值。
sql
CREATE TABLE my_table (
is_active BIT(1)
);
INSERT INTO my_table (is_active) VALUES (1); -- 存储真值
INSERT INTO my_table (is_active) VALUES (0); -- 存储假值4.2、创建数据表
sql
-- 语法
CREATE TABLE tab_name(
field1 type [约束条件],
field2 type,
...
fieldn type -- 一定不要加逗号,否则报错!
)[character set utf8];案例:
sql
CREATE TABLE student(
name varchar(20),
gender bit,
age int,
birth date,
gpa double(8,2) unsigned, -- 平均绩点
)character set=utf8;
sql
-- show tables;4.3、约束
约束:
非空约束NOT NULL
唯一约束UNIQUE
默认约束DEFAULT
主键约束PRIMARY KEY
如果没有定义主键约束,系统会从上到下找我们的字段,如果我们的字段有同时设为唯一和非空的,就将找到的第一个设为主键。如果没有系统就自己设置一个_id主键。
约束是一种限制,它通过限制表中的数据,来确保数据的完整性和唯一性。使用约束来限定表中的数据很多情况下是很有必要的。在 MySQL 中,约束是指对表中数据的一种约束,能够帮助数据库管理员更好地管理数据库,并且能够确保数据库中数据的正确性和有效性。例如,在数据表中存放年龄的值时,如果存入 200、300 这些无效的值就毫无意义了。因此,使用约束来限定表中的数据范围是很有必要的。
添加记录:
sql
INSERT <表名> 字段1,...字段n VALUES (值1,...值n) ;【1】非空约束
非空约束用来约束表中的字段不能为空。比如,在用户信息表中,如果不添加用户名,那么这条用户信息就是无效的,这时就可以为用户名字段设置非空约束。
创建表时可以使用NOT NULL关键字设置非空约束
sql
CREATE TABLE user(
name VARCHAR(22),
age int
);
insert user (name) values ("yuan");
CREATE TABLE user(
name VARCHAR(22),
age int NOT NULL
);
insert user (name) values ("yuan");【2】唯一约束
唯一约束(Unique Key)是指所有记录中字段的值不能重复出现。例如,为name字段加上唯一性约束后,每条记录的name值都是唯一的,不能出现重复的情况。
创建表时可以使用UNIQUE关键字设置非空约束
例如,在用户信息表中,要避免表中的用户名重名,就可以把用户名列设置为唯一约束。
sql
CREATE TABLE user(
name VARCHAR(22),
age int
);
insert user (name) values ("yuan");
insert user (name) values ("yuan");
CREATE TABLE user(
name VARCHAR(22) UNIQUE,
age int
);
insert user (name) values ("yuan");【3】默认值约束
默认值约束用来约束当数据表中某个字段不输入值时,自动为其添加一个已经设置好的值。
创建表时可以使用DEFAULT关键字设置默认值约束
sql
CREATE TABLE user(
name VARCHAR(22),
gender bit
);
insert user (name) values ("yuan");
CREATE TABLE user(
name VARCHAR(22),
gender bit default 1
);
insert user (name) values ("yuan");
CREATE TABLE user(
name VARCHAR(22),
gender varchar(2) default "保密"
);【4】主键约束
主键约束是使用最频繁的约束。在设计数据表时,一般情况下,都会要求表中设置一个主键。主键是表的一个特殊字段,该字段能唯一标识该表中的每条信息。
sql
CREATE TABLE user(
name VARCHAR(22),
age int,
gender varchar(1) default "男"
);
insert user (name,age) values ("yuan",18);
insert user (name,age) values ("rain",28);
insert user (name,age) values ("eric",23);
insert user (name,age) values ("yuan",18);
-- 没有唯一能标识该表中的每条记录的字段值
CREATE TABLE user(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20)
);
insert user (name) values ("yuan");
select * from user;
- 一张表中最多只能有一个主键
- 主键类型不一定必须是整型
- 表中如果没有设置主键,默认设置NOT NULL和UNIQUE的字段为主键;此外,表中如果有多个NOT NULL和UNIQUE的字段,则按顺序将第一个设置NOT NULL和UNIQUE的字段设为主键。所以主键一定是非空且唯一,但非空且唯一的字段不一定是主键。
讲完约束,最后学生表就可以调整为
sql
CREATE TABLE student(
id int primary key auto_increment ,
name varchar(20) not null,
gender bit default 1,
age int,
birth date,
gpa double(8,2) unsigned -- 平均绩点
)character set=utf8;4.4、查看表
sql
desc employee; -- 查看表结构,等同于show columns from tab_name
show tables -- 查看当前数据库中的所有的表
show create table tab_name -- 查看当前数据库表建表语句 4.5、删除表
sql
DROP TABLE [IF EXISTS] 表名1 [ ,表名2, 表名3 ...]4.6、修改表结构
可以找到一个规律:
当操作表和数据库共有的指令时,要提前说明是表还是数据库。例如:create,show,alter。
而add,rename,change,modify等就不需要加table,以为这几个指令只是操作table的
当修改表字段的类型和名字时:都要重新写约束。因为修改表字段本质上时,删除再添加。
修改表名和编码
-
修改表名
sqlALTER TABLE <旧表名> RENAME [TO] <新表名>; -
修该表所用的字符集
sqlALTER TABLE 表名 [DEFAULT] CHARACTER SET <字符集名>
修改表字段
-
增加列(字段)
sqlALTER TABLE <表名> ADD <新字段名><数据类型>[约束条件][first|after 字段名]; -
增加多个字段
sqlalter table users2 add addr varchar(20), add age int first, add birth varchar(20) after name; -
删除某字段
sqlALTER TABLE <表名> DROP <字段名>; -
修改某字段类型
sqlALTER TABLE <表名> MODIFY <字段名> <数据类型> [完整性约束条件][first|after 字段名]; -
修改某字段名
sqlALTER TABLE <表名> CHANGE <旧字段名> <新字段名> <新数据类型> [完整性约束条件][first|after 字段名];
五、表记录操作
可以有很多种方式的客户端与服务端连接,从而对磁盘的数据进行操作
5.1、添加记录
插入单挑记录:字段映射值,insert student () values ()
每一次insert都是再撞击表,heat the database。每次撞击都会浪费时间。
所以插入大量数据时:不要一条一条来,要有一条直接insert。
INSERT 语句有两种语法形式,分别是 INSERT...VALUES 语句和 INSERT...SET 语句。
【1】INSERT...VALUES语句
sql
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...);
- INSERT 语句后面的列名称顺序可以不是 表定义时的顺序,即插入数据时,不需要按照表定义的顺序插入,只要保证值的顺序与列字段的顺序相同就可以。
- 若向表中的所有列插入数据,则全部的列名均可以省略,直接采用 INSERT<表名>VALUES(...) 即可。
- 使用 INSERT...VALUES 语句可以向表中插入一行数据,也可以插入多行数据;
sqlINSERT [INTO] <表名> [ <列名1> [ , ... <列名n>] ] VALUES (值1...,值n), (值1...,值n), ... (值1...,值n); -- 用单条 INSERT 语句处理多个插入要比使用多条 INSERT 语句更快。
案例:
sql
CREATE TABLE student
(
id int primary key auto_increment,
name varchar(20) not null,
gender bit default 1,
age int,
birth date
)character set=utf8;
-- 单行插入
INSERT
student (name,gender,age,birth) VALUES
("yuan",1,18,"2002-11-12"),
-- 多行批量插入
INSERT student (name,gender,age,birth) VALUES
("张三",1,22,"2000-12-12"),
("李四",1,32,"1990-12-12"),
("王五",0,42,"1980-06-06");【2】 INSERT...SET语句
sql
INSERT INTO table_name
SET column1 = value1, column2 = value2, ...;此语句用于直接给表中的某些列指定对应的列值,即要插入的数据的列名在 SET 子句中指定。对于未指定的列,列值会指定为该列的默认值。
5.2、查询记录
select * from student。这种查询方式尽量不要用,效率很慢。
哪怕是要查询所有的,要逐个写上去select name,age,gender from student。
因为星号的方式会找有哪些字段,增加运行时间。
where是对记录做筛选having是对分组之后对组的内容做筛选
sql语句的执行顺序:
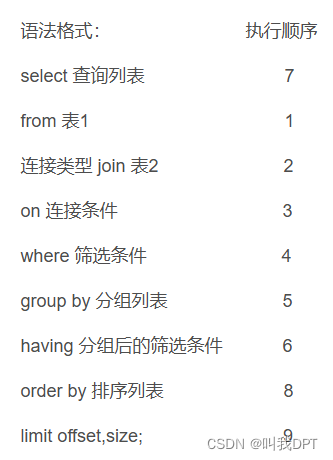

标准语法:
sql
-- 查询语法:
SELECT *|field1,filed2 ... FROM tab_name
WHERE 条件
GROUP BY field
HAVING 筛选
ORDER BY field
LIMIT 限制条数
-- Mysql在执行sql语句时的执行顺序:
-- from join on where group by having select order by limit准备数据:
sql
CREATE TABLE emp2(
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(20),
gender ENUM("male","female","other"),
age TINYINT,
dep VARCHAR(20),
province VARCHAR(20),
salary DOUBLE(7,2),
birthday DATE
) CHARACTER SET=utf8;
INSERT INTO emp (name, gender, age, dep, province, salary, birthday)
VALUES ("George", "male", 24, "教学部", "河北省", 6000, '1999-02-18'),
("danae", "male", 32, "运营部", "北京", 12000, '1992-07-12'),
("Sera", "male", 38, "运营部", "河北省", 7000, '1986-11-05'),
("Echo", "male", 19, "运营部", "河北省", 9000, '2002-03-28'),
("Abel", "female", 24, "销售部", "北京", 9000, '1999-09-10'),
("John", "male", 28, "教学部", "山东省", 8000, '1993-06-15'),
("Alice", "female", 32, "运营部", "北京", 10000, '1990-12-25'),
("Bob", "male", 24, "教学部", "河北省", 9000, '1999-08-03'),
("Cather", "female", 28, "销售部", "山东省", 6000, '1993-04-20'),
("David", "male", 34, "销售部", "山东省", 12000, '1987-09-01'),
("Emily", "female", 22, "教学部", "北京", 7000, '1999-01-08'),
("Frank", "male", 24, "教学部", "河北省", 9000, '1999-07-17'),
("Grace", "female", 32, "运营部", "北京", 8000, '1990-05-30'),
("Henry", "male", 38, "运营部", "河北省", 9000, '1984-03-12'),
("Ivy", "female", 19, "运营部", "河北省", 9000, '2002-08-22'),
("Jack", "male", 24, "销售部", "北京", 8000, '1999-10-05'),
("Kelly", "female", 28, "教学部", "山东省", 10000, '1993-02-28'),
("Leo", "male", 32, "运营部", "北京", 6000, '1990-11-11'),
("Megan", "female", 24, "教学部", "河北省", 12000, '1999-06-03'),
("Nick", "male", 34, "销售部", "山东省", 7000, '1987-07-08'),
("Olivia", "female", 22, "销售部", "山东省", 9000, '1999-03-18'),
("Peter", "male", 24, "教学部", "北京", 8000, '1999-12-01'),
("Queen", "female", 32, "运营部", "河北省", 9000, '1990-09-15'),
("Ryan", "male", 38, "运营部", "北京", 8000, '1984-11-20'),
("Sandy", "female", 19, "运营部", "河北省", 10000, '2002-05-07'),
("Tom", "male", 24, "销售部", "北京", 7000, '1999-04-27'),
("Uma", "female", 28, "教学部", "山东省", 9000, '1993-08-14'),
("Victor", "male", 32, "运营部", "北京", 6000, '1990-02-05'),
("Wendy", "female", 24, "教学部", "河北省", 12000, '1999-07-23'),
("Xander", "male", 34, "销售部", "山东省", 7000, '1987-12-16'),
("Yvonne", "female", 22, "销售部", "山东省", 9000, '1999-01-30'),
("Zack", "male", 24, "教学部", "北京", 8000, '1999-10-13');【1】查询字段(select)
sql
mysql> SELECT * FROM emp;
mysql> SELECT name,dep,salary FROM emp;【2】where语句
sql
-- where字句中可以使用:
--比较运算符:
> < >= <= <> != =
between 10 and 100 值在10到100之间
in(10,20,30) 值是10或20或30
like 'yuan%'
/*
pattern可以是%或者_,
如果是%则表示任意多字符,此例如唐僧,唐国强
如果是_则表示一个字符唐_,只有唐僧符合。两个_则表示两个字符:__
*/
-- 正则
SELECT * FROM emp WHERE emp_name REGEXP '^yu';
SELECT * FROM emp WHERE name REGEXP 'n$';
-- 逻辑运算符
在多个条件直接可以使用逻辑运算符 and or not
练习:
sql
-- 查询年纪大于24的员工
SELECT * FROM emp WHERE age > 24;
-- 查询年龄在20到30之间的员工
SELECT * FROM emp WHERE age between 20 and 30;
-- 查询工资等于7000,8000和9000的所有员工
SELECT * FROM emp WHERE salary in (7000,8000,9000);
-- 查询名字以A开头的员工
SELECT * FROM emp WHERE name like "A%";
-- 查询名字包含A的员工
SELECT * FROM emp WHERE name like "%A%";
SELECT * FROM emp WHERE REGEXP_LIKE(name, '.*A.*',"c");
-- 查询教学部的男老师信息
SELECT * FROM emp WHERE dep="教学部" AND gender="male";
-- 查询名字以A开头的员工并且工资大于等于10000的员工的姓名
SELECT * FROM emp WHERE name like "A%" and salary>=10000;
-- 查询年龄小于25或工资低于10000的员工
SELECT * FROM emp WHERE age<25 or salary < 8000;
-- 日期相关的
SELECT *
FROM emp
WHERE birthday > '1990-01-01';
SELECT *
FROM emp
WHERE MONTH(birthday) = 12;【3】order:排序
按指定的列进行,排序的列即可是表中的列名,也可以是select语句后指定的别名。
sql
-- 语法:
select *|field1,field2... from tab_name order by field [Asc|Desc]
-- Asc 升序、Desc 降序,其中asc为默认值 ORDER BY 子句应位于SELECT语句的结尾。练习:
sql
-- 按年龄从高到低进行排序
SELECT * FROM emp ORDER BY age DESC ;
-- 按工资从低到高进行排序
SELECT * FROM emp ORDER BY salary;
-- 先按工资排序,工资相同的按年龄排序
SELECT * FROM emp ORDER BY salary,age;【4】group by:分组查询
GROUP BY 语句根据某个列对结果集进行分组。分组一般配合着聚合函数完成查询。
常用聚合(统计)函数
max():最大值。min():最小值。avg():平均值。sum():总和。count():个数。
在MySQL的SQL执行逻辑中,where条件必须放在group by前面!也就是先通过where条件将结果查询出来,再交给group by去分组,完事之后进行统计,统计之后的查询用having。
练习:
sql
-- 练习案例
-- 查询男女员工各有多少人
-- 查询教学部的员工最高工资:
-- 查询平均薪水超过8000的部门
-- 查询每个组的员工姓名
-- 查询公司一共有多少员工(可以将所有记录看成一个组)
-- 每年出生的员工人数
-- 查询公司所有员工的平均工资【5】limit:记录条数限制
sql
SELECT * from emp limit 10;
SELECT * from emp limit 2,5; -- 跳过前两条显示接下来的五条纪录
SELECT * from emp limit 2,2;【6】distinct:查询去重
sql
-- 获取员工表中不重复的年龄值和薪水值,并按照相应的字段进行升序排序。
SELECT distinct age from emp order by age;
SELECT distinct salary from emp order by salary;5.3、更新记录
sql
UPDATE <表名> SET 字段 1=值 1 [,字段 2=值 2... ] [WHERE 子句 ]案例:
sql
-- 更新员工职位和工资
-- 更改部门名称
-- 年龄大于35岁的员工薪资增加百分之十五
-- 薪资最高的五个人降薪百分之三十5.4、删除记录
sql
DELETE FROM <表名> [WHERE 子句] [ORDER BY 子句] [LIMIT 子句]
<表名>:指定要删除数据的表名。ORDER BY子句:可选项。表示删除时,表中各行将按照子句中指定的顺序进行删除。WHERE子句:可选项。表示为删除操作限定删除条件,若省略该子句,则代表删除该表中的所有行。LIMIT子句:可选项。用于告知服务器在控制命令被返回到客户端前被删除行的最大值。
sql
-- 删除薪资最高的五个人,相同薪资按年龄优先
-- 删除教学部年龄最大的男老师若有错误与不足请指出,关注DPT一起进步吧!!!