任务描述
知识点:安装配置ZooKeeper
重 点: 安装配置ZooKeeper
难 点:无
内 容:
ZooKeeper是一个开源分布式协调服务,其独特的Leader-Follower集群结构,很好的解决了分布式单点问题。目前主要用于诸如:统一命名服务、配置管理、锁服务、集群管理等场景。大数据应用中主要使用ZooKeeper的集群管理功能。
因为在项目中会使用到HBase,所以需要安装ZooKeeper。HBase是一个开源的、分布式的NoSQL数据库,它建立在Hadoop分布式文件系统(HDFS)之上。HBase具有高可靠性、高可扩展性、高性能等特点,它适合于存储和处理大规模数据。而ZooKeeper是一个分布式的协调服务,它能够提供分布式系统中的一致性和可靠性支持。在HBase中,ZooKeeper负责协调HBase集群中所有RegionServer的状态、负载均衡以及Master的选举等任务。因此,ZooKeeper在HBase中扮演了一个非常重要的角色,它确保了HBase集群的稳定性和可靠性。
任务主要内容为:ZooKeeper下载安装,环境变量的修改,配置ZooKeeper。
任务指导
1、安装ZooKeeper集群的主要步骤
- 同时在node1、node2、node3三个节点上安装ZooKeeper;
- 分别在node1、node2、node3三个节点上配置用户环境变量;
- 分别在node1、node2、node3三个节点上修改ZooKeeper的配置文件;
- 分别在node1、node2、node3三个节点上创建ZooKeeper的数据存储目录和日志存储目录;
- 分别在node1、node2、node3三个节点上创建的ZooKeeper的数据存储目录中创建myid文件;
- 分别在node1、node2、node3三个节点上启动ZooKeeper;
2、常见问题
- 如果启动报类似异常:QuorumCnxManager@384] - Cannot open channel to 2 at election address slave-02/192.168.0.178:3888
该异常是可以忽略的,因为该服务启动时会尝试连接所有节点,而其他节点尚未启动。通过后面部分可以看到,集群在选出一个Leader后,最后稳定 了。其他结点可能也出现类似问题,属于正常。
- 如果不关闭防火墙,客户端使用API操作HDFS以及ZooKeeper,可能就会出现下面常见的两种异常:
**API操作HDFS时会出现异常:**java.net.NoRouteToHostException: No route to host
**API操作ZK时会出现异常:**org.apache.zookeeper.KeeperException$ConnectionLossException: KeeperErrorCode = ConnectionLoss for xxxx
- 关闭防火墙。在Hadoop集群环境(linux系统)中最好关闭防火墙,不然会出现很多问题,例如namenode找不到datanode等。
使用root权限登陆后,输入关闭防火墙命令(在所有节点执行以下操作):
# systemctl stop firewalld
# systemctl disable firewalld任务实现
1. 安装配置ZooKeeper
在node1节点上,进入/opt/software/目录(此目录是为实验提供的安装软件所在目录,如果没有请自行到官方网站下载):
[root@node1 ~]# cd /opt/software/
-
首先在node1节点安装ZooKeeper,解压ZooKeeper安装包:
[root@node1 software]# tar -zxvf /opt/software/zookeeper-3.4.13.tar.gz -C /opt/module
2. 配置用户环境变量
-
使用【vi /etc/profile】打开配置文件,增加如下内容:
export ZK_HOME=/opt/module/zookeeper-3.4.13
export PATH=PATH:ZK_HOME/bin

-
使修改的环境变量生效
[root@node1 software]# source /etc/profile

-
将/etc/profile拷贝到其它所有机器上
[root@node1 software]# scp -rq /etc/profile node2:/etc/
[root@node1 software]# scp -rq /etc/profile node3:/etc/ -
并在node2、node3执行【source /etc/profile】使环境变量生效


3. 配置ZooKeeper
-
在node1节点上,修改ZooKeeper的配置文件
[root@node1 software]# cd $ZK_HOME/conf/
[root@node1 conf]# cp zoo_sample.cfg zoo.cfg
[root@node1 conf]# vi zoo.cfg -
将zoo.cfg文件修改成如下内容:
客户端心跳时间(毫秒)
tickTime=2000
允许心跳间隔的最大时间
initLimit=10
同步时限
syncLimit=5
数据存储目录
dataDir=/opt/module/zookeeper-3.4.13/data
数据日志存储目录
dataLogDir=/opt/module/zookeeper-3.4.13/data/log
端口号
clientPort=2181
集群节点和服务端口配置
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888以下为优化配置
服务器最大连接数,默认为10,改为0表示无限制
maxClientCnxns=0
快照数
autopurge.snapRetainCount=3
快照清理时间,默认为0
autopurge.purgeInterval=1
-
创建ZooKeeper的数据存储目录和日志存储目录
[root@node1 conf]# cd ../
[root@node1 zookeeper-3.4.13]# mkdir -p /opt/module/zookeeper-3.4.13/data
[root@node1 zookeeper-3.4.13]# mkdir -p /opt/module/zookeeper-3.4.13/data/log -
在data目录中创建一个文件myid,输入内容为1
[root@node1 zookeeper-3.4.13]# echo "1" > data/myid
-
修改ZooKeeper的日志输出路径
[root@node1 zookeeper-3.4.13]# vi bin/zkEnv.sh
-
修改内容如下:
if [ "x{ZOO_LOG_DIR}" = "x" ] then ZOO_LOG_DIR="ZK_HOME/logs"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi

-
修改ZooKeeper的日志配置文件
[root@node1 zookeeper-3.4.13]# vi conf/log4j.properties
-
修改内容如下:
zookeeper.root.logger=INFO,ROLLINGFILE

-
创建日志目录
[root@node1 zookeeper-3.4.13]# mkdir /opt/module/zookeeper-3.4.13/logs
-
在node1中将zookeeper目录复制到其它节点
[root@node1 zookeeper-3.4.13]# scp -rq /opt/module/zookeeper-3.4.13 node2:/opt/module
[root@node1 zookeeper-3.4.13]# scp -rq /opt/module/zookeeper-3.4.13 node3:/opt/module -
在node2中修改data目录中的myid文件
[root@node2 ~]# rm -rf /opt/module/zookeeper-3.4.13/data/myid
[root@node2 ~]# echo "2" > /opt/module/zookeeper-3.4.13/data/myid -
在node3中修改data目录中的myid文件
[root@node3 ~]# rm -rf /opt/module/zookeeper-3.4.13/data/myid
[root@node3 ~]# echo "3" > /opt/module/zookeeper-3.4.13/data/myid
4. Zookeeper启动,测试
-
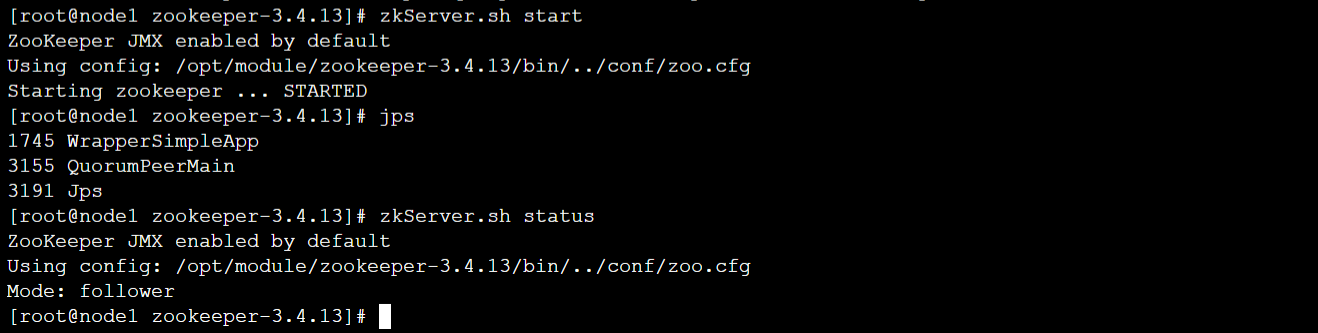
分别在node1、node2、node3节点上启动ZooKeeper服务
[root@node1 ~]# zkServer.sh start
[root@node2 ~]# zkServer.sh start
[root@node3 ~]# zkServer.sh start
-
分别在node1、node2、node3节点上查看状态
[root@node1 ~]# zkServer.sh status
[root@node2 ~]# zkServer.sh status
[root@node3 ~]# zkServer.sh status
-
如果要关闭ZooKeeper服务,可以分别在三个节点上使用关闭命令。这里不要执行关闭命令,后面安装Kafka和HBase会用到ZooKeeper集群。
zkServer.sh stop