四、(1)网络爬虫入门及准备工作(爬虫及数据可视化)
- 1,网络爬虫入门
-
- [1.1 百度指数](#1.1 百度指数)
- [1.2 天眼查](#1.2 天眼查)
- [1.3 爬虫原理](#1.3 爬虫原理)
- [1.4 搜索引擎原理](#1.4 搜索引擎原理)
- 2,准备工作
-
- [2.1 分析爬取页面](#2.1 分析爬取页面)
- [2.2 爬虫拿到的不仅是网页还是网页的源代码](#2.2 爬虫拿到的不仅是网页还是网页的源代码)
- [2.3 爬虫就是将网页中的内容提取出来。](#2.3 爬虫就是将网页中的内容提取出来。)
- [2.4 爬虫需要找到规律](#2.4 爬虫需要找到规律)
- [2.5 使用开发者工具进行调试,找到要寻找的数据位置](#2.5 使用开发者工具进行调试,找到要寻找的数据位置)
- [2.6 主程序入口(If name=="main":)](#2.6 主程序入口(If name==”main”:))
- [2.7 引入包或库(from test import t1)](#2.7 引入包或库(from test import t1))
- [2.8 引入其他模块报错(两种解决方式)](#2.8 引入其他模块报错(两种解决方式))
- [2.9 爬虫需要引入的包](#2.9 爬虫需要引入的包)
1,网络爬虫入门
主要看课件
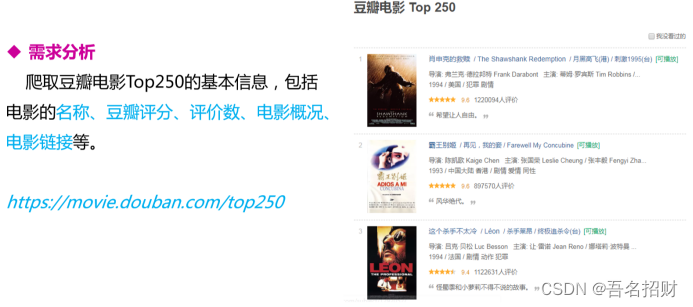
https://movie.douban.com/top250
此次任务只需对表面的也的分析,不用点进去的详细信息
接下来的1-2天进行
大概两天
后面项目做的需要扩展内容(时间充分)
使用程序复制网络上的数据
网络数据非常多,但数据价值,股市、金融数据保险等信息
电影天堂流量很大,可以在百度指数查看每天的访问人次
1.1 百度指数
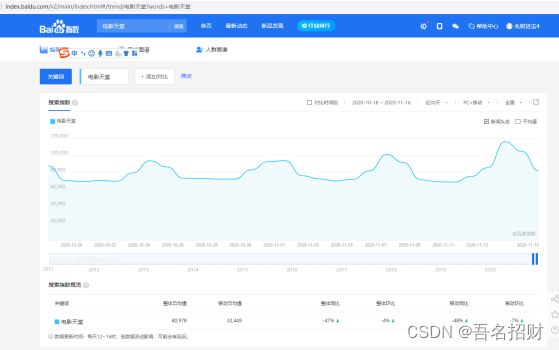
电影天堂和吃鸡对比
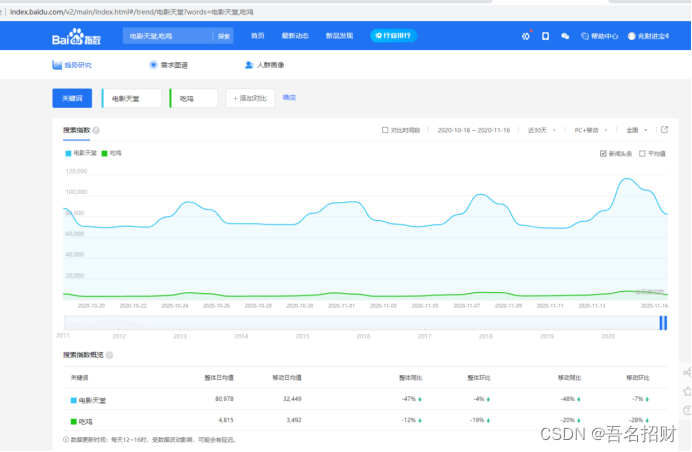
可能你觉得很简单的网站流量也是非常大的
如电影天堂网站,很多信息并不是其自己写的,很多信息是来自豆瓣的
很多流量大的网站,
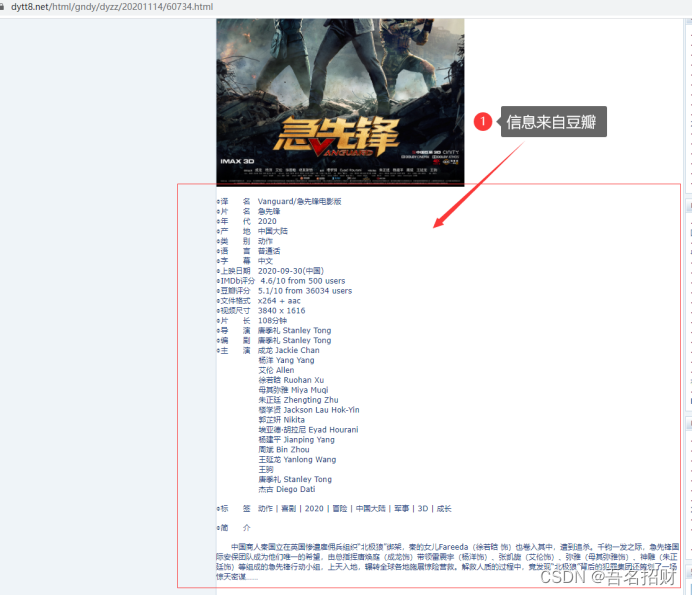
只需要将内容爬取出来
这么多的流量怎么赚钱,通过视频引流,使用广告变现,如右下角广告变现
搜索引擎就是网络爬虫
1.2 天眼查
天眼查的网站怎么赢利,有些信息不能看,需要充值才能看,卖的不是信息本身,卖的是信息之间的关系。基于数据分析,提供方案的。就是数据采集聚合。
原来的基本应用产生大量数据,现在要将数据整合,产生新的价值
爬虫可以完成特定行业的。
一些付费视频,前提是付过钱了,然后爬取,可能有加密,反爬取等
浏览器本身展示的看的,写的程序只是将我们看到的东西存起来(我们想要的数据)
爬虫根据每个网页,分析
1.3 爬虫原理
1.4 搜索引擎原理
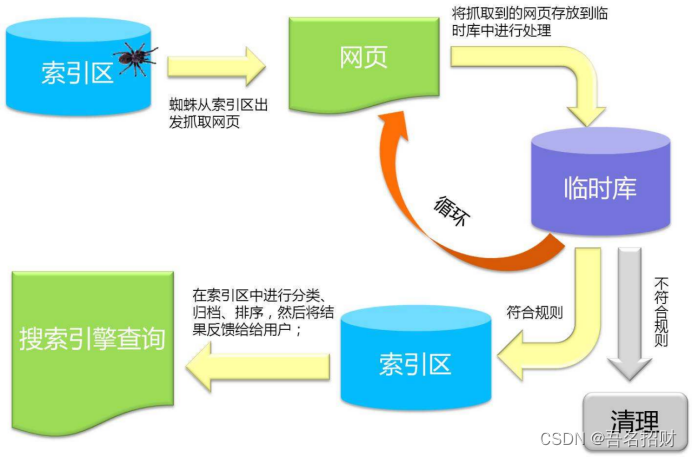
这两天的内容是前半段,将爬取的数据放到数据库中,而搜索引擎在后半段,需要将爬取的东西做一个索引,用户搜索时,可以将索引快速定位到数据库中的数据。
每次搜索不是爬虫再爬取一次,而是数据展现
这里后面没讲索引,只是讲了数据的可视化展现,实际思路是一样的
准备工作:看目标网页,怎么分析,看那些是我们想要的内容,并且找到,还包括写程序的输出框架,问题预防解决的
获取数据:很多的库,发起请求,模拟浏览器发起,获取网页信息
页面解析:页面解析库,正则表达式等库
保存数据:保存到Excel或数据库,需要很多库
2,准备工作
2.1 分析爬取页面
准备工作是用来分析要爬取的页面的
https://movie.douban.com/top250?start=25\&filter=
上方连接是第2页
问号后是参数名和参数值是&链接
start=25意思是从26个后提供共25个电影显示到页面
&filter= 可以不要
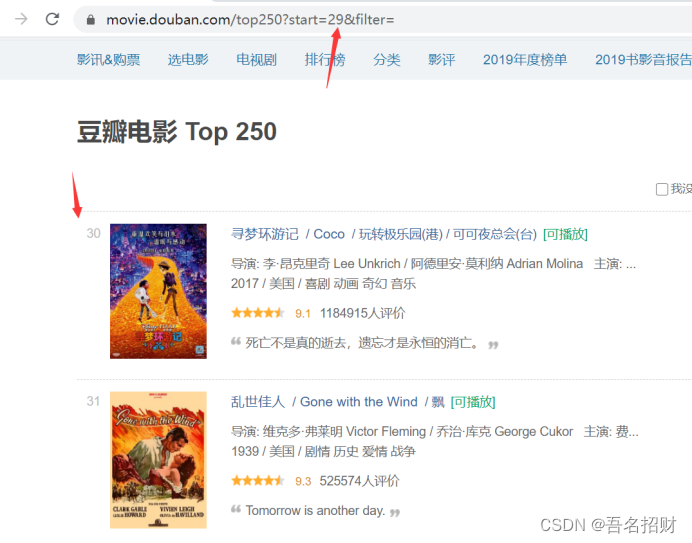
上来就看连接的特点,网络爬虫都是根据连接模拟浏览器访问网页,现在看到的所有东西
2.2 爬虫拿到的不仅是网页还是网页的源代码
返回的就是html网页,里面嵌入了js及css代码而已
2.3 爬虫就是将网页中的内容提取出来。
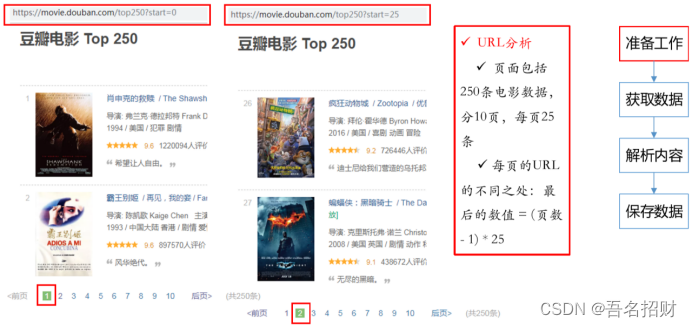
2.4 爬虫需要找到规律
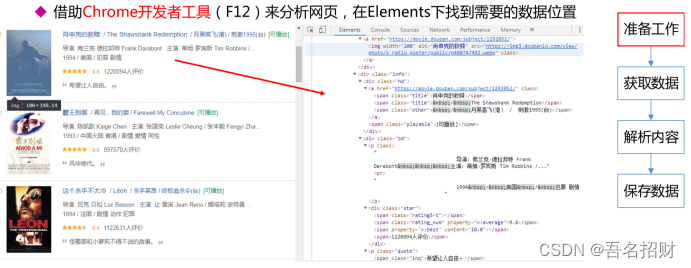
2.5 使用开发者工具进行调试,找到要寻找的数据位置
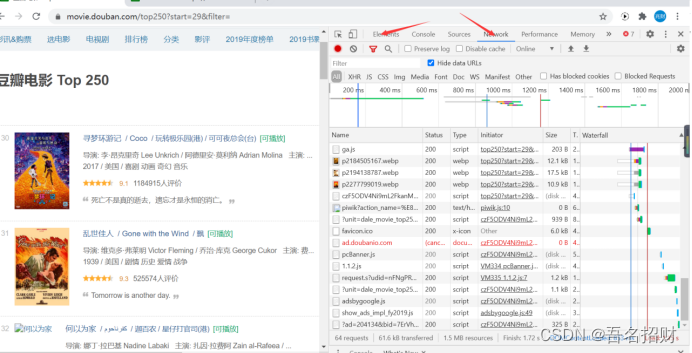
在network中,点击刷,可以看到,发起请求到显示结束,中间浏览器向服务器发出了这么多请求,因为这些请求的作用一直延长时间,中间有交互,只要有交互就会延长,可以点击红色圆圈停止记录。
点击刷新,只要内容是想要的就点击停止记录。
比如将鼠标放到开始
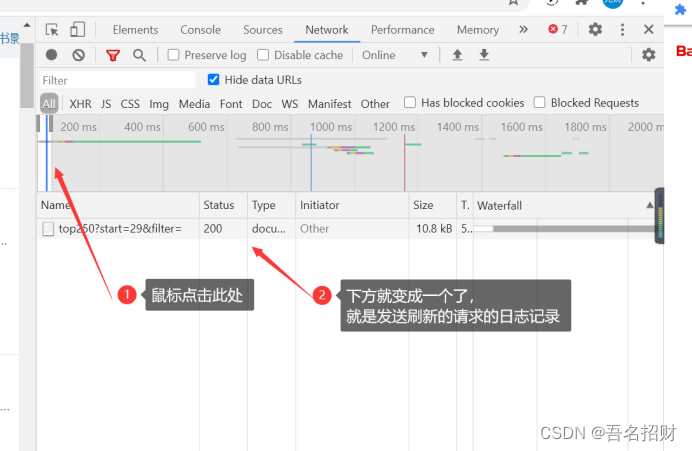
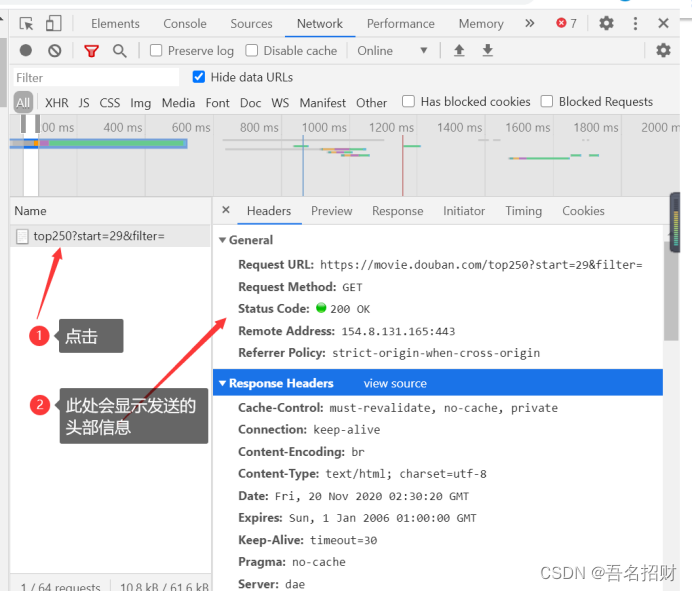
Response headers是我们发给服务器的,要求服务器的适配,服务器返回的信息就是整个网页
Headers下的所有内容全是浏览器发送给服务器的请求。
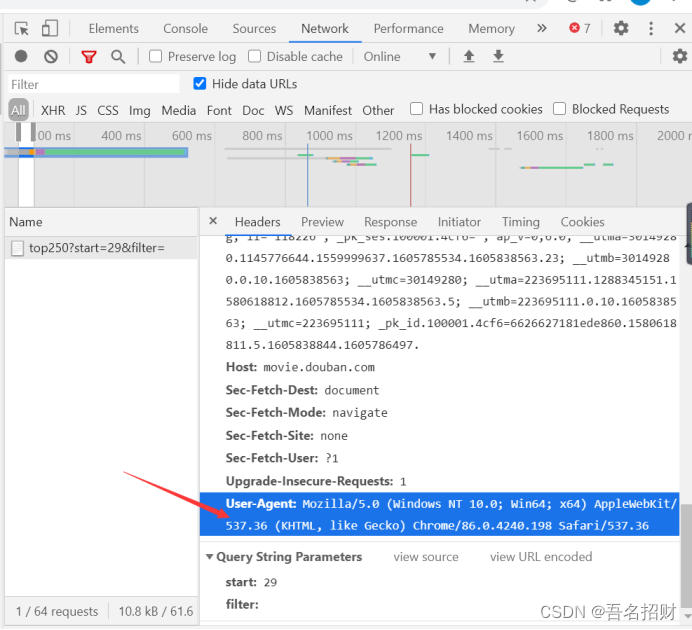
User-agent使用哪个浏览器,需要标明,如果没有,服务器可能不返回信息
Cookie如果是需要一些登录后才能进行的内容的爬取,就必须学会存储cookie和读取cookie
Headers是发送网络请求给服务器的消息,服务器通过此消息来鉴定我们的身份
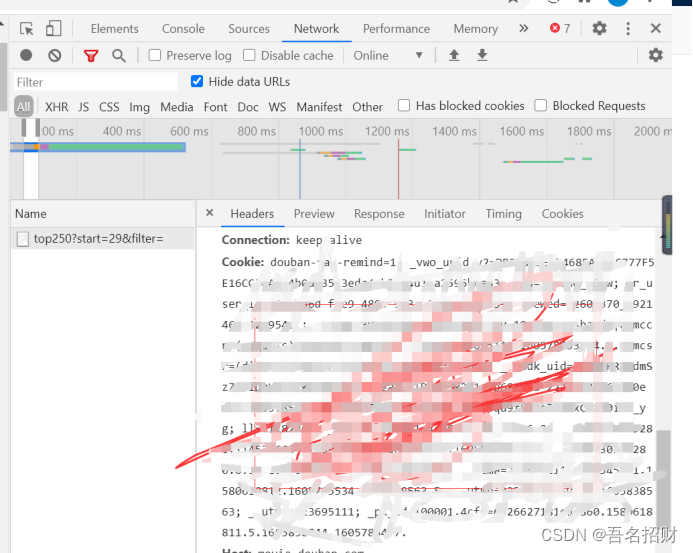
Cookie:是服务器能标识客户端信息保存在本地的信息,里面是加密的,登录信息还是客户端行为信息保存在本地的内容。当访问豆瓣时,cookie可能反映了很多我的内容,如地理位置、ip地址、浏览的以前的关键字
记录行为,不仅在本地,每次访问都会给对方法消息,服务器可以通过此进行分析
宏观可以知道有多少人使用谷歌浏览器,多少windows系统,有多少人的分辨率多少
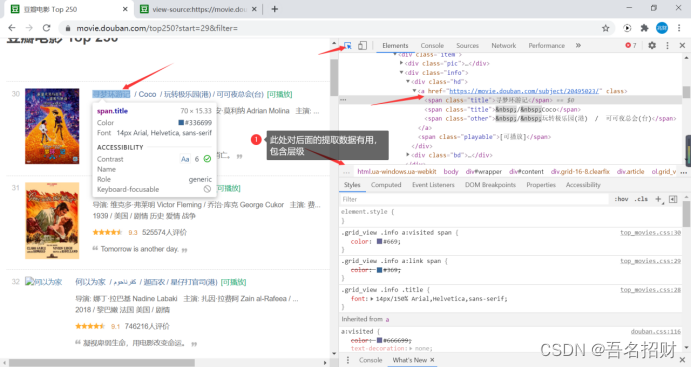
根据此层级结构可以快速锁定位置
有很多的库,可以通过此路径直接找到内容,甚至批量将剩下内容拿到

2.6 主程序入口(If name =="main":)
If _name_=="_main_":如果执行主方法,当运行的函数名是main的时候,起始2main就是程序被解释的时候默认的方法名。
定义程序执行的入口
这样写使程序安照自己的组织来,在上面写,程序入口,执行过程看
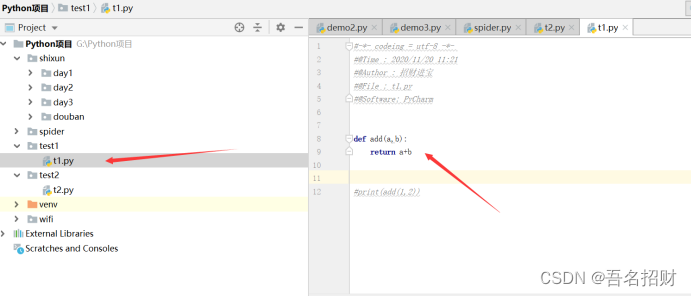
2.7 引入包或库(from test import t1)
库就是将别人写好的代码,在当前文件中直接调用,调用如下
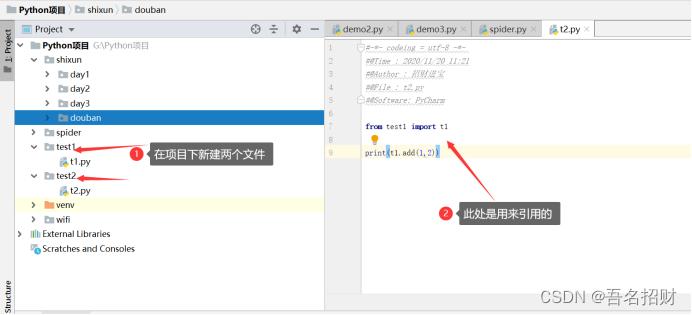
库的内容如上图所示
引入包或者库,就是别人写好的函数,可以在我们的文件中调用
from test import t1from的文件夹是包,文件夹中有个具体文件,此文件就是具体的模块,import t1模块
模块中是有函数的,上方就是引入自定义模块
2.8 引入其他模块报错(两种解决方式)
若引入其他模块
最常用引入第三方模块
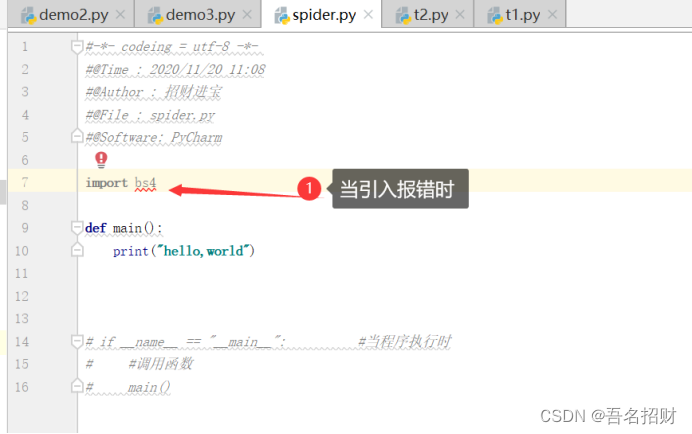
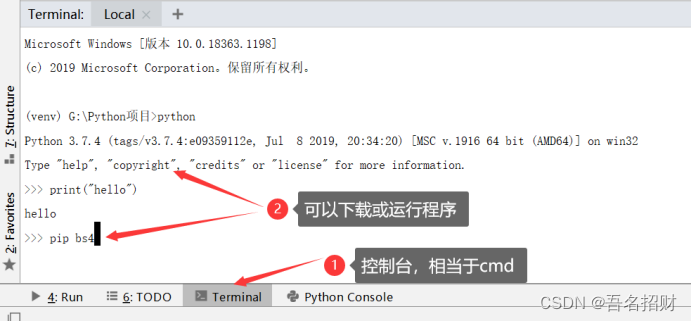
(1)使用控制台方式(这里下载可能会因为网络的不稳定而下载失败)
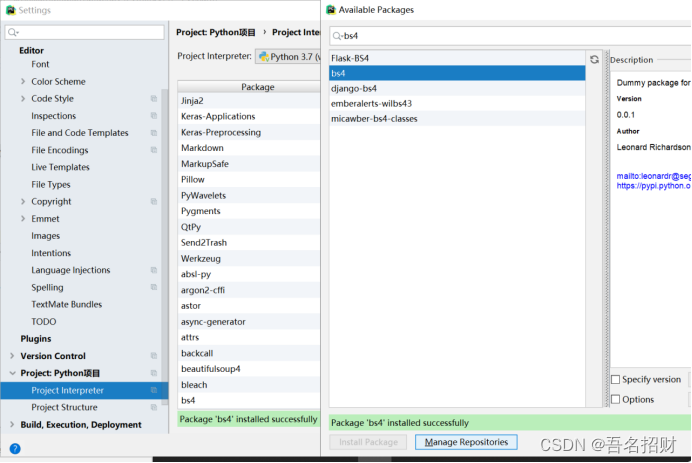
(2)可进入setting中的interpreter解释器中添加包
下面界面在安装时是可以退出的,不用在控制台安装,可能会安装很长时间,这样就能直接进行其他的操作
2.9 爬虫需要引入的包
以下的包是我们必须用到的
import urllib.request,urllib.error #指定url,获取网页数据
from bs4 import BeautifulSoup #网页解析,获取数据
import re #正则表达式,进行文字匹配
import xlwt #进行Excel操作
import sqlite3 #进行SQLite操作
Python3中将urllib2中的功能整合到urllib中了,使用urllib就可以了