注意:该项目只展示部分功能,如需了解,文末咨询即可。
本文目录
- [1 开发环境](#1 开发环境)
- [2 系统设计](#2 系统设计)
- [3 系统展示](#3 系统展示)
- [3.1 功能展示视频](#3.1 功能展示视频)
- [3.2 大屏页面](#3.2 大屏页面)
- [3.3 分析页面](#3.3 分析页面)
- [3.4 基础页面](#3.4 基础页面)
- [4 更多推荐](#4 更多推荐)
- [5 部分功能代码](#5 部分功能代码)
1 开发环境
发语言:python
采用技术:Spark、Hadoop、Django、Vue、Echarts等技术框架
数据库:MySQL
开发环境:PyCharm
2 系统设计
在当前餐饮行业竞争日益激烈的背景下,特别是火锅这一细分市场,传统的经营决策模式愈发依赖于经营者的个人经验,缺乏客观数据支持,难以精准把握市场动态与消费者需求。与此同时,大数据技术的迅猛发展为深度洞察市场提供了前所未有的机遇。本项目旨在构建一个基于Python、Spark、Hadoop等大数据技术的火锅店数据可视化分析系统,通过对海量线上餐厅数据的采集、处理、分析与可视化呈现,将零散的数据转化为直观的商业洞察。其核心意义在于,赋能餐饮从业者实现从"经验驱动"向"数据驱动"的决策模式转型,帮助他们科学地进行市场定位、优化定价策略、提升服务质量;同时,也为广大消费者提供一个全面、客观的消费参考,从而推动整个火锅行业的精细化运营和高质量发展。
功能模块的设计紧密围绕需求分析展开,旨在从多个维度对火锅店数据进行深度挖掘与解读。
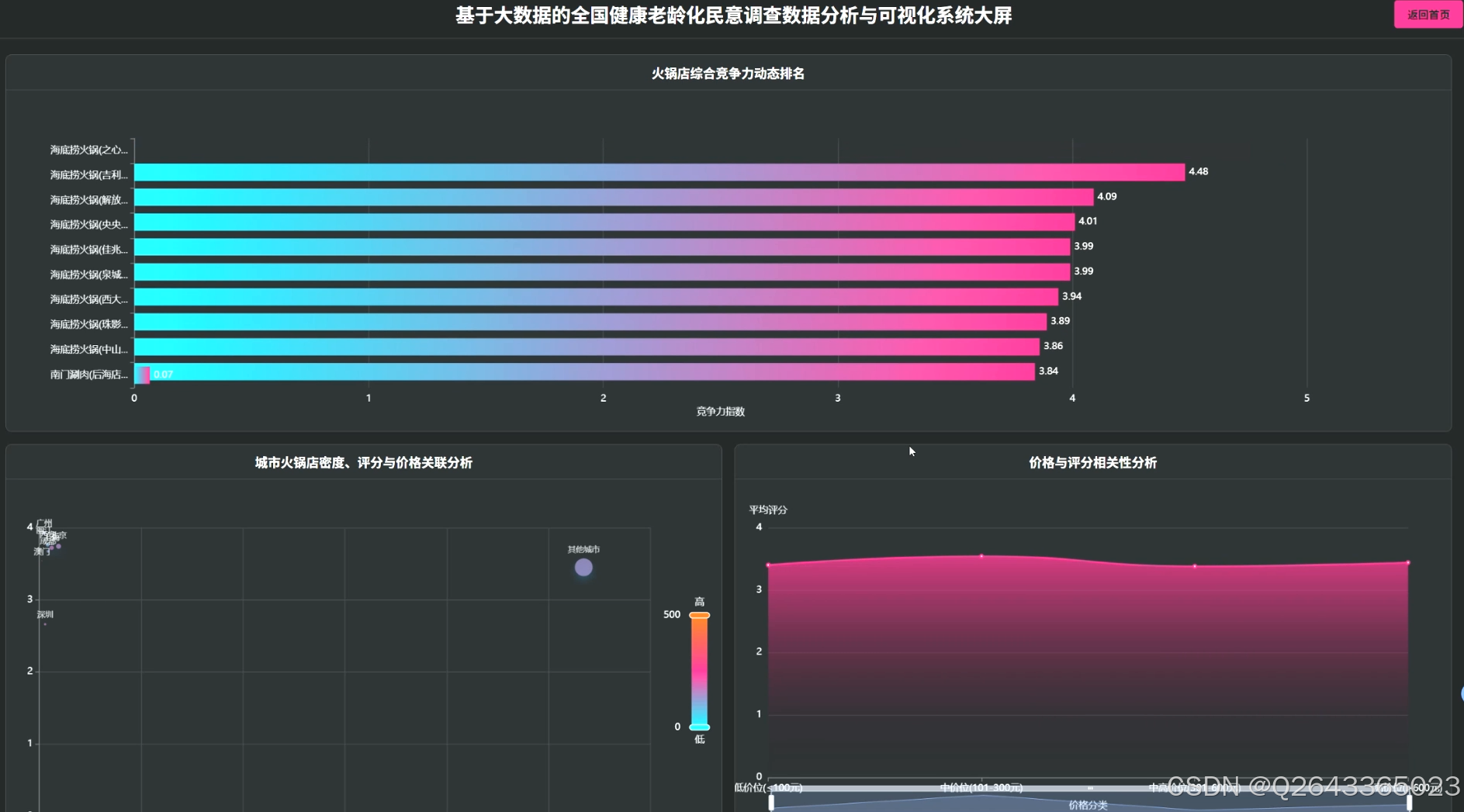
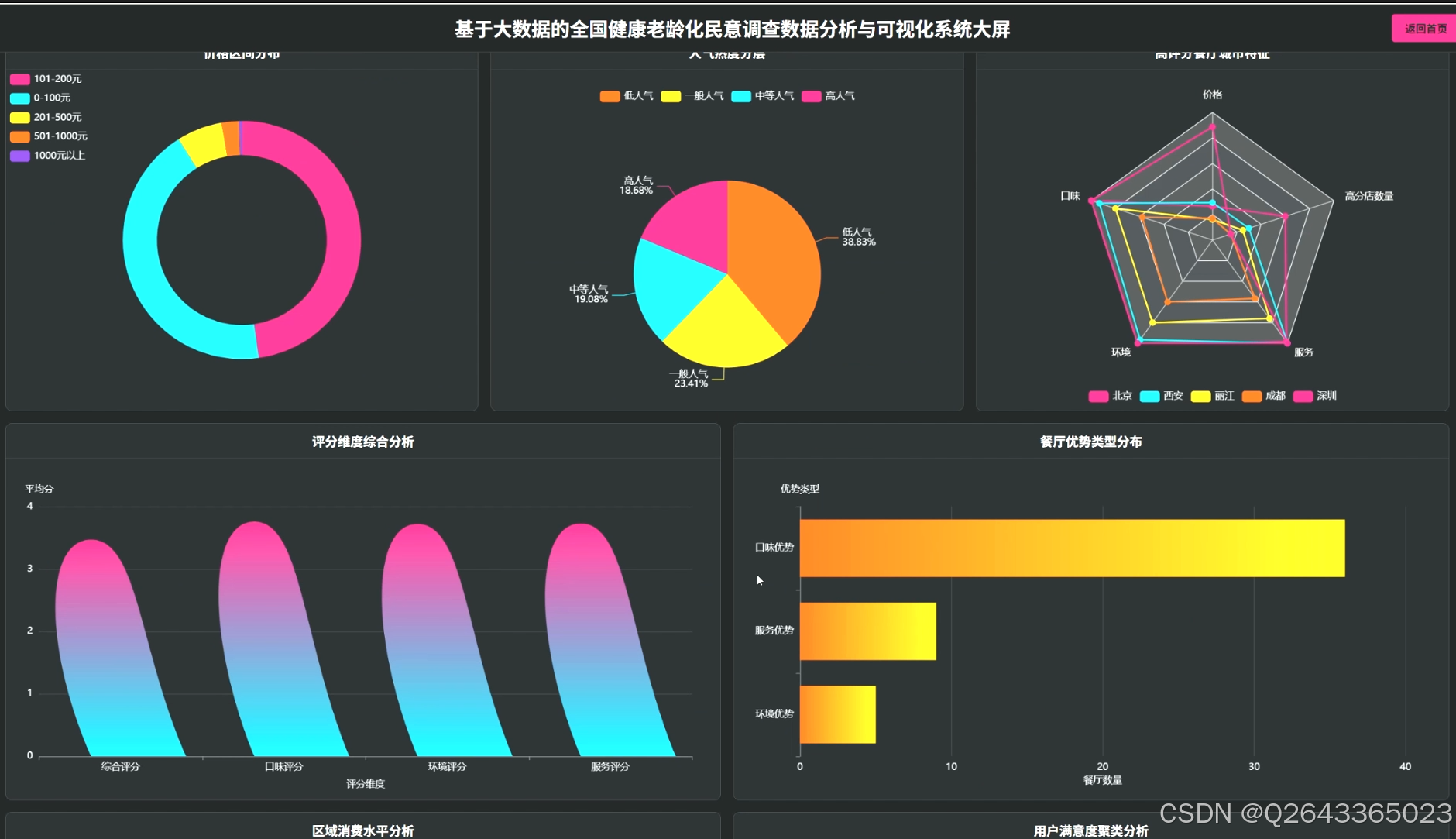
1.市场宏观分析模块:该模块聚焦于市场的整体态势。包括价格区间分布统计,揭示市场主流消费层级;城市火锅店密度与评分关联分析,识别热门城市与潜力市场;以及区域消费水平分析,通过对比各城市平均消费,为跨区域扩张提供决策依据。
2...店铺竞争力与质量评估模块:此模块专注于单个店铺的微观分析。通过评分维度综合分析,全面评估行业的整体服务水平;高评分火锅店特征分析,提炼成功经营的关键要素;并构建火锅店综合竞争力评估模型,结合价格、人气、多维评分等指标,为店铺提供客观的行业排名。
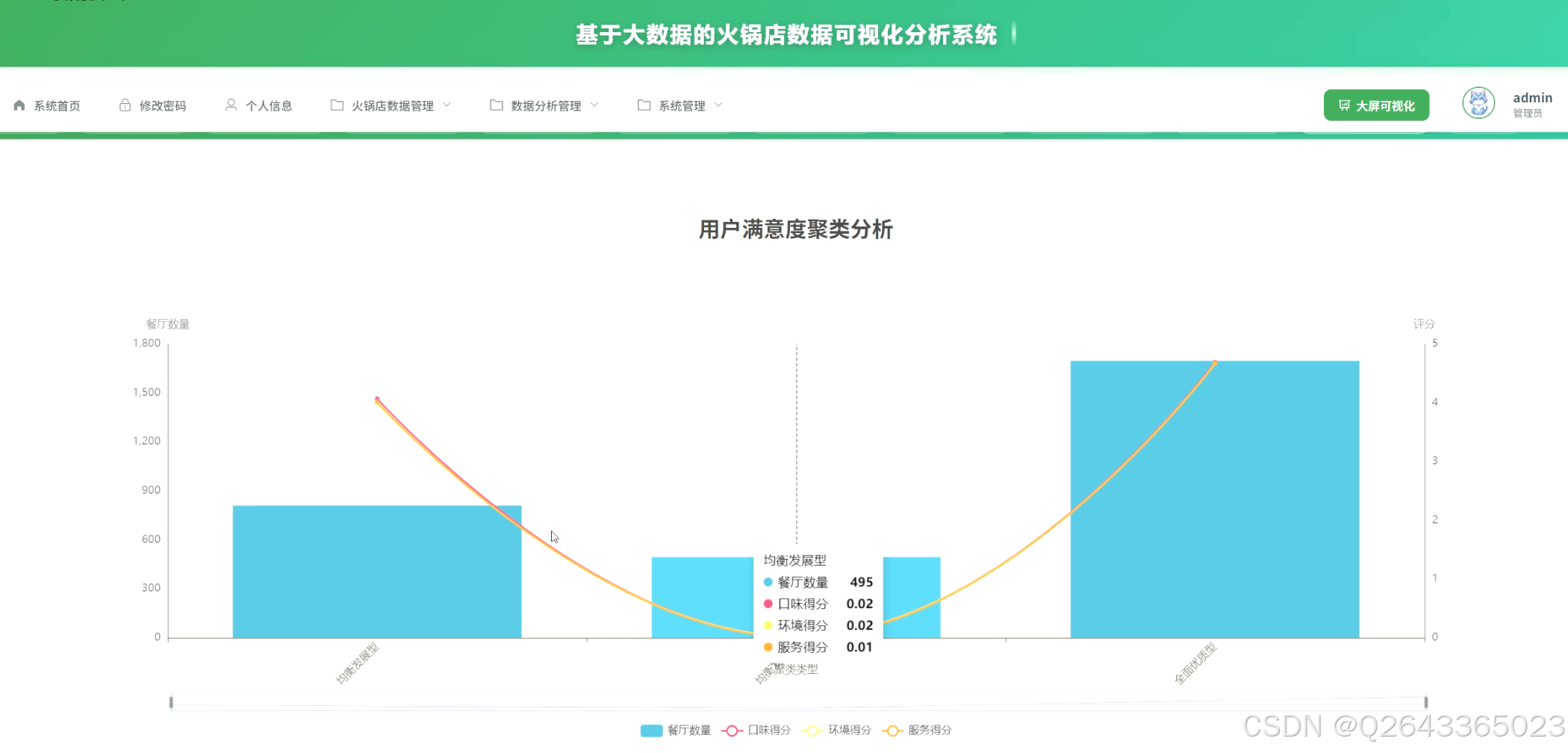
3...经营策略优化洞察模块:该模块旨在为商家提供可执行的优化建议。包括人气热度分层分析,探究高人气店铺的运营秘诀;价格与评分相关性分析,验证"质价相符"的市场规律;评分差异化分析,帮助店铺识别自身的服务短板;以及利用K-means算法进行用户满意度聚类分析,发现不同服务模式的店铺客群,指导差异化经营。
3 系统展示
3.1 功能展示视频
基于K-Means算法+大数据的火锅店数据可视化分析系统源码 !!!请点击这里查看功能演示!!!
3.2 大屏页面
3.3 分析页面
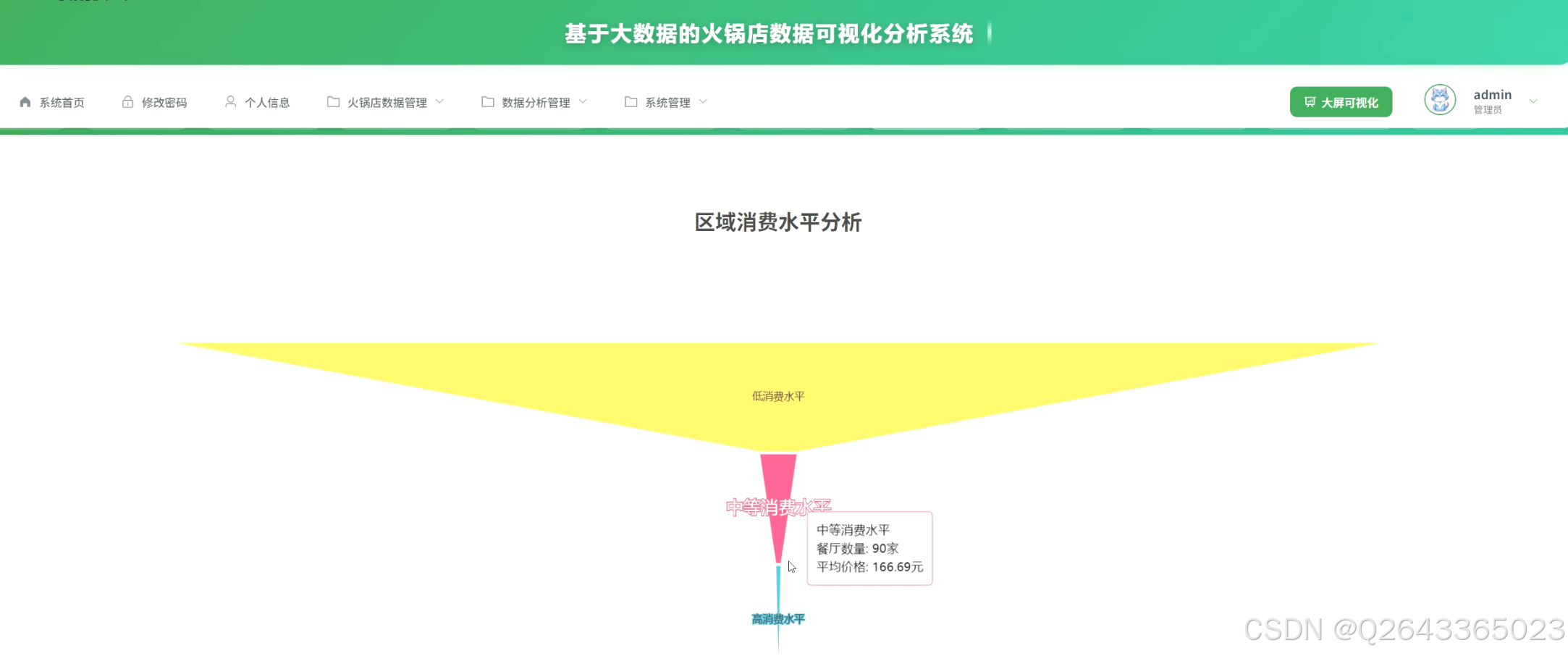
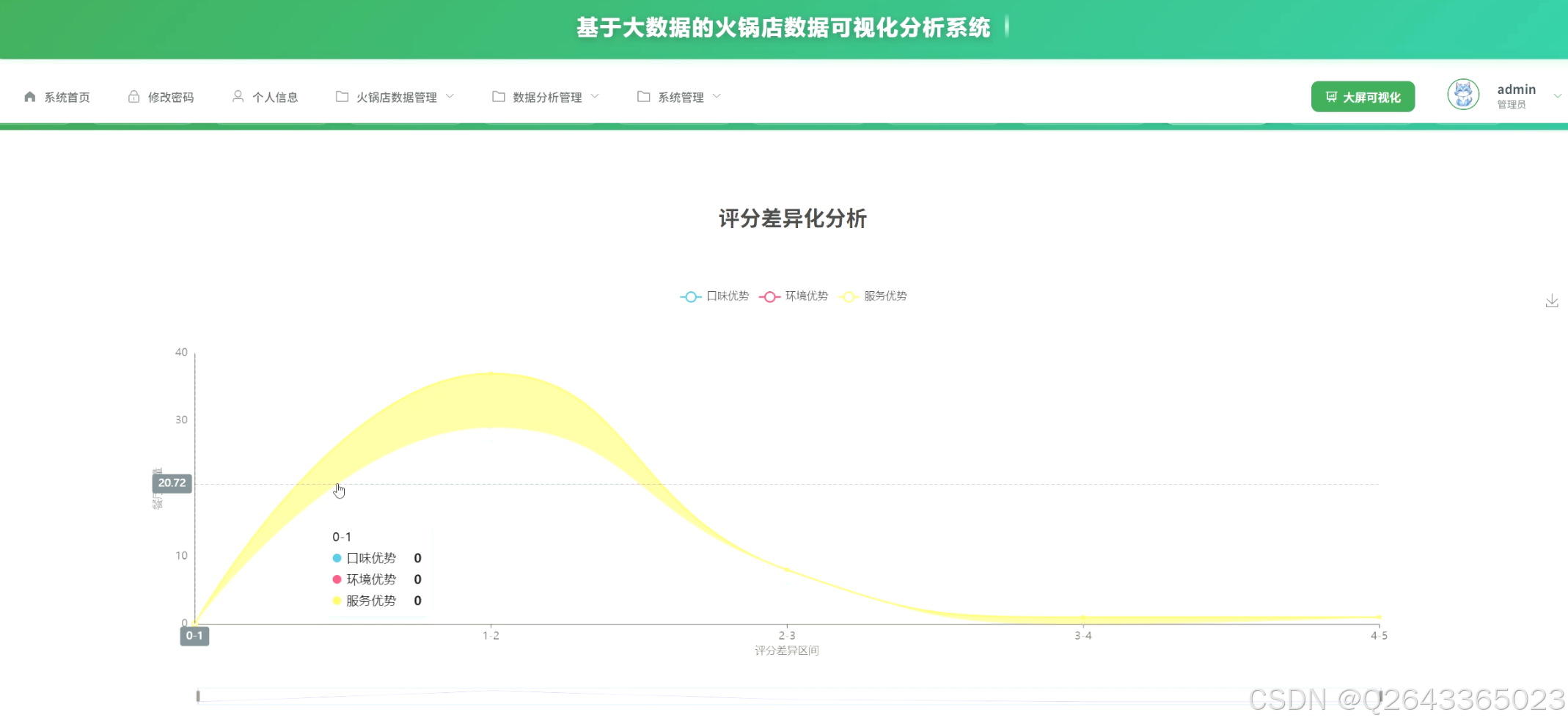
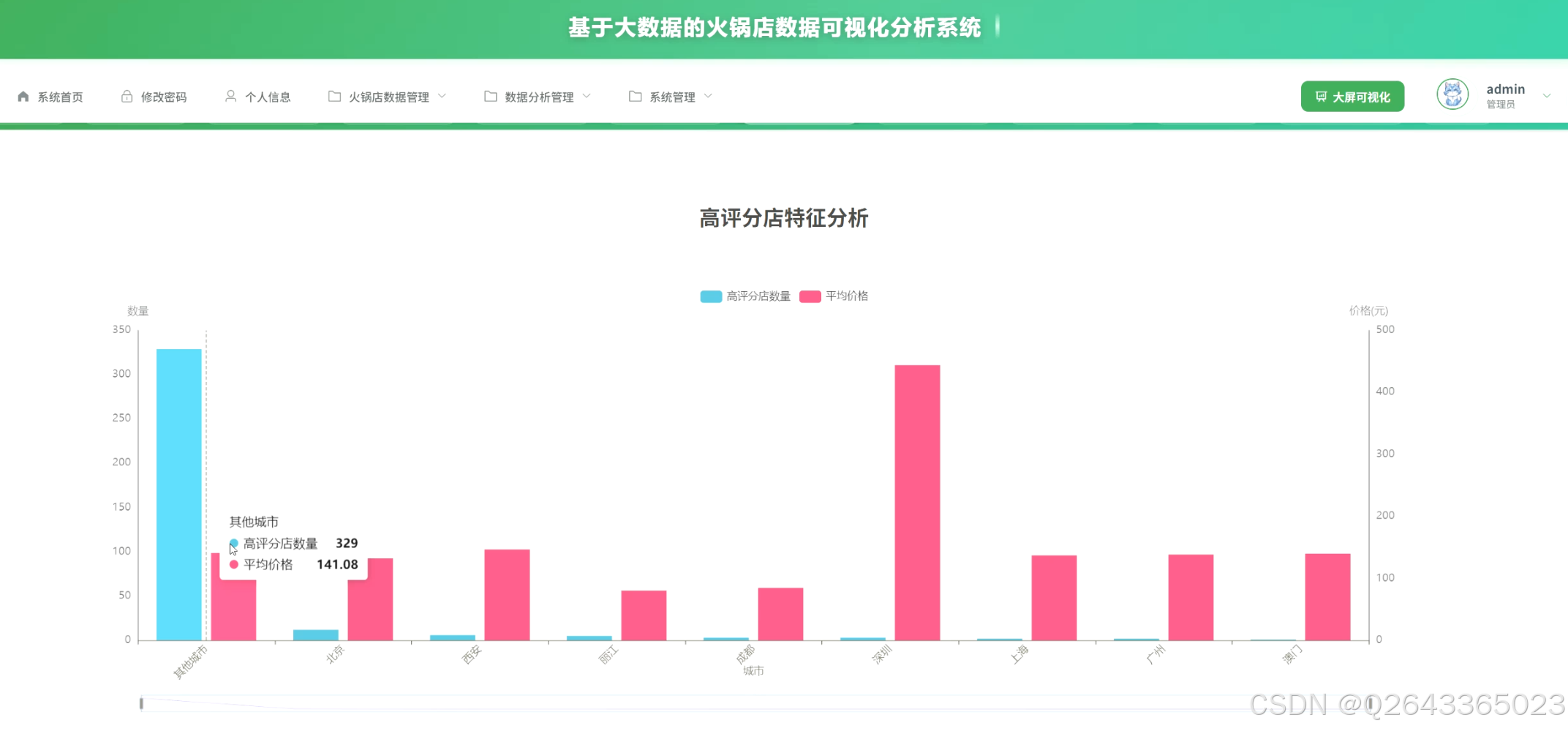
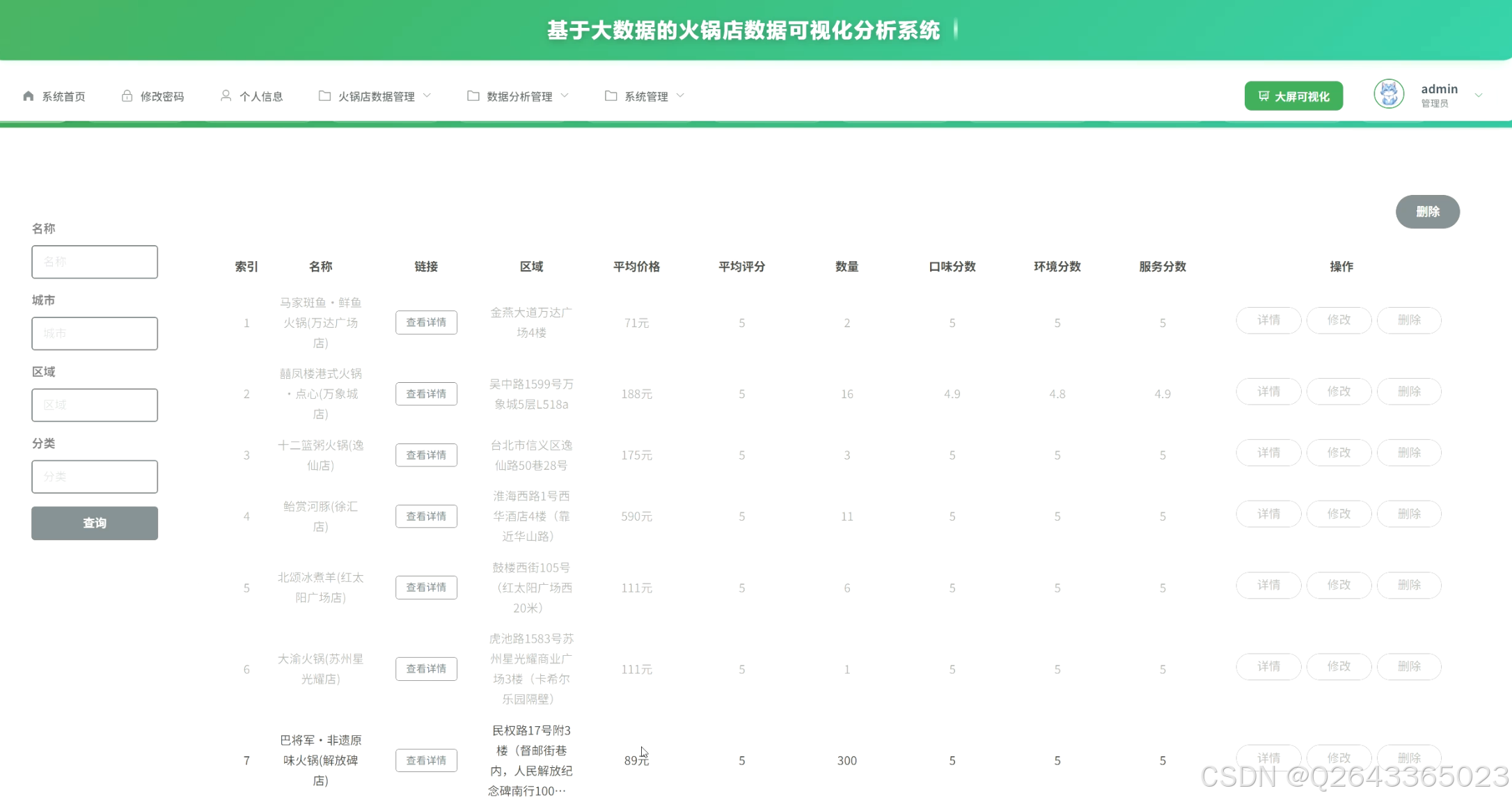
3.4 基础页面
4 更多推荐
计算机专业毕业设计新风向,2026年大数据 + AI前沿60个毕设选题全解析,涵盖Hadoop、Spark、机器学习、AI等类型
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
【避坑必看】26届计算机毕业设计选题雷区大全,这些毕设题目千万别选!选题雷区深度解析
紧跟风口!2026计算机毕设新赛道:精选三大热门领域下的创新选题, 拒绝平庸!毕设技术亮点+功能创新,双管齐下
纯分享!2026届计算机毕业设计选题全攻略(选题+技术栈+创新点+避坑),这80个题目覆盖所有方向,计算机毕设选题大全收藏
计算机专业毕业设计选题深度剖析,掌握这些技巧,让你的选题轻松通过,文章附35个优质选题助你顺利通过开题!
5 部分功能代码
python
# ==============================================================================
# 模块一:城市火鍋店密度與評分關聯分析核心代碼
# 功能:統計各城市火鍋店的數量、平均綜合評分和總評論數,用於分析地域分佈特徵。
# ==============================================================================
def analyze_city_density_and_rating(df):
"""
對火鍋店數據按城市進行聚合分析。
:param df: 包含原始火鍋店數據的Spark DataFrame。
:return: 包含各城市分析結果的Spark DataFrame,字段包括:city, shop_count, avg_rating, total_reviews。
"""
print("--- 开始执行【城市火锅店密度与评分关联分析】模块 ---")
# 步驟1: 數據清洗 - 從'areaName'字段中提取城市名稱
# 由於原始city字段不準確,我們定義一個UDF(用戶自定義函數)來提取更精確的城市信息。
# 這裡做一個簡化處理,提取地址中第一個'市'或'区'之前的地名作為城市名。
def extract_city(area_name):
if area_name is None:
return "未知"
try:
if "市" in area_name:
return area_name.split("市")[0] + "市"
elif "区" in area_name:
return area_name.split("区")[0] + "区" # 處理直轄市的情況
return area_name[:2] # 備用策略,取前兩個字
except:
return "未知"
# 將UDF註冊到Spark中
extract_city_udf = udf(extract_city, StringType())
# 應用UDF創建新的'city_clean'列
df_with_city = df.withColumn("city_clean", extract_city_udf(col("areaName")))
# 步驟2: 按城市分組並進行聚合計算
# - shop_count: 每個城市的店鋪總數
# - avg_rating: 每個城市的平均綜合評分
# - total_reviews: 每個城市的總評論數
city_analysis_df = df_with_city.groupBy("city_clean") \
.agg(
count("*").alias("shop_count"),
round(avg("avgScore"), 2).alias("avg_rating"),
sum("count").alias("total_reviews")
) \
.withColumnRenamed("city_clean", "city") # 將列名改為'city'以便前端使用
print("--- 【城市火锅店密度与评分关联分析】模块执行完毕 ---")
return city_analysis_df
# ==============================================================================
# 模块二:用户满意度聚类分析(K-Means)核心代码
# 功能:基于口味、环境、服务三个评分维度,对火锅店进行聚类,识别不同类型的服务模式。
# ==============================================================================
def analyze_satisfaction_clustering(df):
"""
使用K-Means算法对火锅店进行聚类分析。
:param df: 包含原始火锅店數據的Spark DataFrame。
:return: 增加了聚類標籤和標籤說明的Spark DataFrame。
"""
print("--- 开始执行【用户满意度聚类分析】模块 ---")
# 步驟1: 特徵工程 - 將需要聚類的字段合併為一個特徵向量
# K-Means算法要求輸入為向量格式,我們使用VectorAssembler來組合特徵列。
feature_cols = ["kouweifenshu", "huanjingfenshu", "fuwufenshu"]
# 處理空值,聚類算法不接受空值,這裡用0填充
df_cleaned = df.na.fill(0, subset=feature_cols)
assembler = VectorAssembler(
inputCols=feature_cols,
outputCol="features"
)
df_vector = assembler.transform(df_cleaned)
# 步驟2: 初始化並訓練K-Means模型
# 設置聚類數量k=4,可以根據業務需求調整
kmeans = KMeans(featuresCol="features", k=4, seed=1)
model = kmeans.fit(df_vector)
# 步驟3: 進行預測 - 為每家店鋪打上聚類標籤
# 'prediction'列即為每個數據點所屬的簇ID (0, 1, 2, 3)
predictions_df = model.transform(df_vector)
# 步驟4: 結果解釋 - 為聚類標籤添加可讀的中文說明
# 根據需求分析,需要為聚類結果添加說明字段,方便業務人員理解。
# 這裡的標籤命名是基於對聚類中心點的假設分析,實際應用中需分析各簇特徵後再命名。
predictions_with_label_df = predictions_df.withColumn("cluster_label",
when(col("prediction") == 0, "口味优先型")
.when(col("prediction") == 1, "环境服务均衡型")
.when(col("prediction") == 2, "综合发展型")
.when(col("prediction") == 3, "服务体验型")
.otherwise("未知类型")
)
print("--- 【用户满意度聚类分析】模块执行完毕 ---")
# 選擇需要的列返回,避免過多無用信息
result_df = predictions_with_label_df.select("id", "name", "kouweifenshu", "huanjingfenshu", "fuwufenshu", "prediction", "cluster_label")
return result_df
# ==============================================================================
# 主程序入口:用於演示和調試
# ==============================================================================
if __name__ == "__main__":
# 1. 初始化SparkSession
# local[*] 表示使用本機所有可用的CPU核心
spark = SparkSession.builder \
.appName("HotPotAnalysisCoreModules") \
.master("local[*]") \
.getOrCreate()
# 2. 讀取數據集
# 確保HotPotRestaurant.csv文件在項目根目錄或指定路徑下
# header=True表示第一行是列名,inferSchema=True會自動推斷列類型
try:
raw_df = spark.read.csv("HotPotRestaurant.csv", header=True, inferSchema=True)
except Exception as e:
print(f"读取CSV文件失败,请确保文件路径正确: {e}")
spark.stop()
exit()
# 3. 調用核心模塊一並展示結果
city_analysis_result = analyze_city_density_and_rating(raw_df)
print("城市火锅店密度与评分关联分析结果:")
city_analysis_result.show(10, truncate=False) # 展示前10條結果,不截斷列內容
# 4. 調用核心模塊二並展示結果
clustering_result = analyze_satisfaction_clustering(raw_df)
print("用户满意度聚类分析结果:")
clustering_result.show(10, truncate=False) # 展示前10條結果,不截斷列內容源码项目、定制开发、文档报告、PPT、代码答疑
希望和大家多多交流 ↓↓↓↓↓