这是继上一篇文章 "Elasticsearch:Runtime fields - 运行时字段(一)" 的续篇。

目录
[使用 grok 模式定义运行时字段](#使用 grok 模式定义运行时字段)
[定义 composite 运行时字段](#定义 composite 运行时字段)
[搜索特定 IP 地址](#搜索特定 IP 地址)
[使用 dissect 模式定义运行时字段](#使用 dissect 模式定义运行时字段)
在查询时覆盖字段值
如果你创建的运行时字段与映射中已存在的字段同名,则运行时字段会隐藏映射字段。在查询时,Elasticsearch 会评估运行时字段,根据脚本计算值,并将该值作为查询的一部分返回。由于运行时字段会隐藏映射字段,因此你可以覆盖搜索中返回的值而无需修改映射字段。
例如,假设你将以下文档编入 my-index-000001 索引:
DELETE my-index-000001
POST my-index-000001/_bulk?refresh=true
{"index":{}}
{"@timestamp":1516729294000,"model_number":"QVKC92Q","measures":{"voltage":5.2}}
{"index":{}}
{"@timestamp":1516642894000,"model_number":"QVKC92Q","measures":{"voltage":5.8}}
{"index":{}}
{"@timestamp":1516556494000,"model_number":"QVKC92Q","measures":{"voltage":5.1}}
{"index":{}}
{"@timestamp":1516470094000,"model_number":"QVKC92Q","measures":{"voltage":5.6}}
{"index":{}}
{"@timestamp":1516383694000,"model_number":"HG537PU","measures":{"voltage":4.2}}
{"index":{}}
{"@timestamp":1516297294000,"model_number":"HG537PU","measures":{"voltage":4.0}}后来你意识到 HG537PU 传感器没有报告其真实电压。索引值应该比报告值高 1.7 倍!你可以在 _search 请求的 Runtime_mappings 部分中定义一个脚本来隐藏 voltage 字段并在查询时计算新值,而不是重新索引数据。
如果你搜索型号与 HG537PU 匹配的文档:
GET my-index-000001/_search
{
"query": {
"match": {
"model_number": "HG537PU"
}
}
}响应包括与型号 HG537PU 匹配的文档的索引值:
{
...
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.0296195,
"hits" : [
{
"_index" : "my-index-000001",
"_id" : "F1BeSXYBg_szTodcYCmk",
"_score" : 1.0296195,
"_source" : {
"@timestamp" : 1516383694000,
"model_number" : "HG537PU",
"measures" : {
"voltage" : 4.2
}
}
},
{
"_index" : "my-index-000001",
"_id" : "l02aSXYBkpNf6QRDO62Q",
"_score" : 1.0296195,
"_source" : {
"@timestamp" : 1516297294000,
"model_number" : "HG537PU",
"measures" : {
"voltage" : 4.0
}
}
}
]
}
}以下请求定义了一个运行时字段,其中脚本评估 model_number 字段,其值为 HG537PU。对于每个匹配项,脚本将 voltage 字段的值乘以 1.7。
使用 _search API 上的 fields 参数,你可以检索脚本为与搜索请求匹配的文档的 measures.voltage 字段计算的值:
POST my-index-000001/_search
{
"runtime_mappings": {
"measures.voltage": {
"type": "double",
"script": {
"source":
"""if (doc['model_number.keyword'].value.equals('HG537PU'))
{emit(1.7 * params._source['measures']['voltage']);}
else{emit(params._source['measures']['voltage']);}"""
}
}
},
"query": {
"match": {
"model_number": "HG537PU"
}
},
"fields": ["measures.voltage"]
}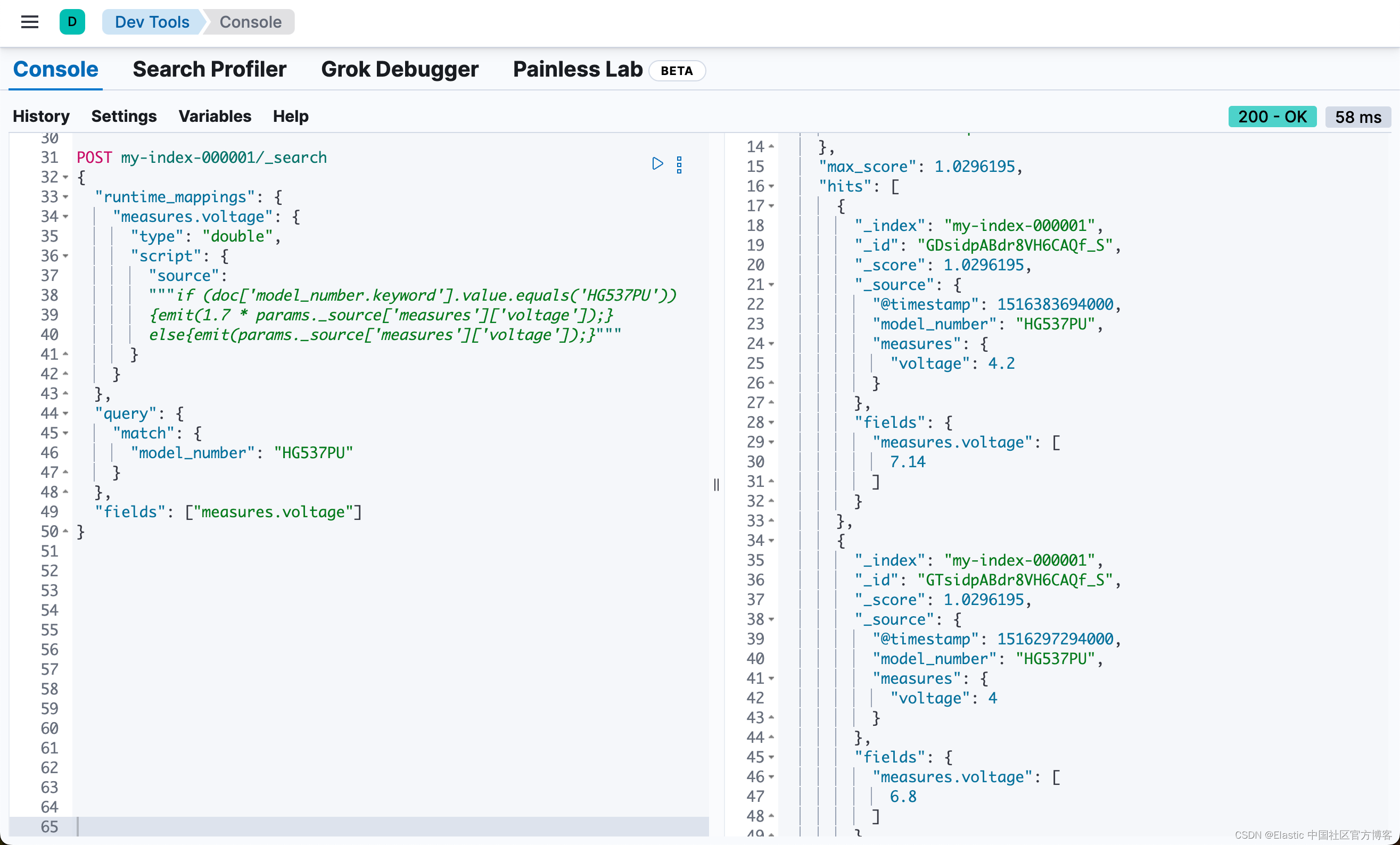
查看响应,每个结果的 measures.voltage 计算值分别为 7.14 和 6.8。这更像了!运行时字段在搜索请求中计算了此值,但没有修改映射值,该值仍会在响应中返回。
检索运行时字段
使用 _search API 上的 fields 参数检索运行时字段的值。运行时字段不会显示在 _source 中,但 fields API 适用于所有字段,即使是那些未作为原始 _source 的一部分发送的字段。
定义运行时字段以计算星期几
例如,以下请求添加了一个名为 day_of_week 的运行时字段。运行时字段包含一个脚本,该脚本根据 @timestamp 字段的值计算星期几。我们将在请求中包含 "dynamic":"runtime",以便将新字段作为运行时字段添加到映射中。
DELETE my-index-000001
PUT my-index-000001/
{
"mappings": {
"dynamic": "runtime",
"runtime": {
"day_of_week": {
"type": "keyword",
"script": {
"source": "emit(doc['@timestamp'].value.dayOfWeekEnum.getDisplayName(TextStyle.FULL, Locale.ROOT))"
}
}
},
"properties": {
"@timestamp": {"type": "date"}
}
}
}提取一些数据
让我们提取一些示例数据,这将产生两个索引字段:@timestamp 和 message。
POST /my-index-000001/_bulk?refresh
{ "index": {}}
{ "@timestamp": "2020-06-21T15:00:01-05:00", "message" : "211.11.9.0 - - [2020-06-21T15:00:01-05:00] \"GET /english/index.html HTTP/1.0\" 304 0"}
{ "index": {}}
{ "@timestamp": "2020-06-21T15:00:01-05:00", "message" : "211.11.9.0 - - [2020-06-21T15:00:01-05:00] \"GET /english/index.html HTTP/1.0\" 304 0"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:30:17-05:00", "message" : "40.135.0.0 - - [2020-04-30T14:30:17-05:00] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:30:53-05:00", "message" : "232.0.0.0 - - [2020-04-30T14:30:53-05:00] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:31:12-05:00", "message" : "26.1.0.0 - - [2020-04-30T14:31:12-05:00] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:31:19-05:00", "message" : "247.37.0.0 - - [2020-04-30T14:31:19-05:00] \"GET /french/splash_inet.html HTTP/1.0\" 200 3781"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:31:27-05:00", "message" : "252.0.0.0 - - [2020-04-30T14:31:27-05:00] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:31:29-05:00", "message" : "247.37.0.0 - - [2020-04-30T14:31:29-05:00] \"GET /images/hm_brdl.gif HTTP/1.0\" 304 0"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:31:29-05:00", "message" : "247.37.0.0 - - [2020-04-30T14:31:29-05:00] \"GET /images/hm_arw.gif HTTP/1.0\" 304 0"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:31:32-05:00", "message" : "247.37.0.0 - - [2020-04-30T14:31:32-05:00] \"GET /images/nav_bg_top.gif HTTP/1.0\" 200 929"}
{ "index": {}}
{ "@timestamp": "2020-04-30T14:31:43-05:00", "message" : "247.37.0.0 - - [2020-04-30T14:31:43-05:00] \"GET /french/images/nav_venue_off.gif HTTP/1.0\" 304 0"}搜索计算出的星期几
以下请求使用搜索 API 检索原始请求在映射中定义为运行时字段的 day_of_week 字段。此字段的值是在查询时动态计算的,无需重新索引文档或索引 day_of_week 字段。这种灵活性允许你修改映射而不更改任何字段值。
GET my-index-000001/_search
{
"fields": [
"@timestamp",
"day_of_week"
],
"_source": false
}
上一个请求返回所有匹配文档的 day_of_week 字段。我们可以定义另一个名为 client_ip 的运行时字段,该字段也对 message 字段进行操作,并将进一步细化查询。在查询之前,我们先查看一下索引的映射:
GET my-index-000001/_mapping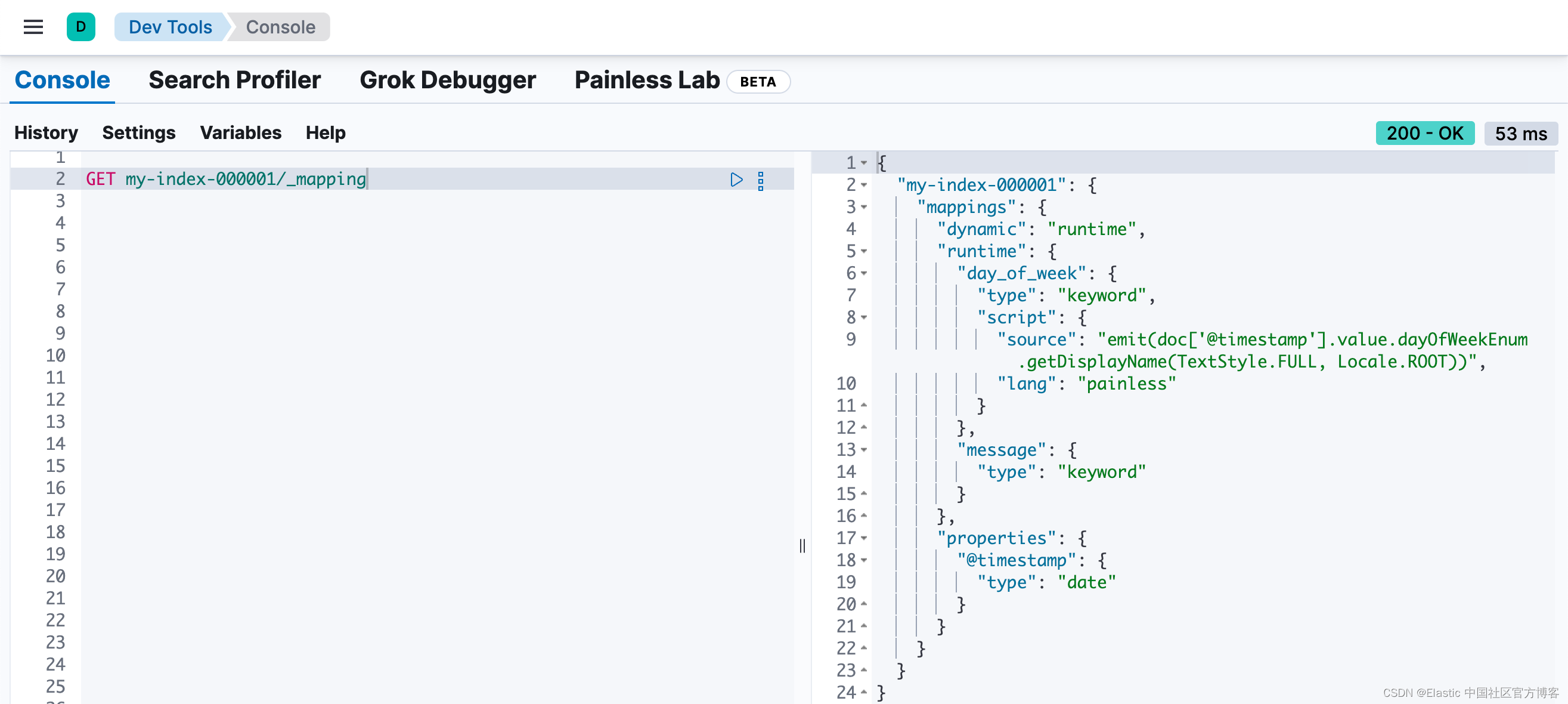
从上面我们可以看出来,由于我们在 mappings 中设置了 "dynamic": "runtime",那么 message 这个字段自动地被设置为 keyword 类型,而不是我们通常认为的 text 字段。也就是说 message 这个字段还具有 doc value。
我们可以通过如下的查询来返回 client_ip 这个字段:
PUT /my-index-000001/_mapping
{
"runtime": {
"client_ip": {
"type": "ip",
"script" : {
"source" : "String m = doc[\"message\"].value; int end = m.indexOf(\" \"); emit(m.substring(0, end));"
}
}
}
}运行另一个查询,但使用 client_ip 运行时字段搜索特定的 IP 地址:
GET my-index-000001/_search
{
"size": 1,
"query": {
"match": {
"client_ip": "211.11.9.0"
}
},
"fields" : ["*"]
}
这次响应仅包含两个命中。day_of_week(星期日)的值是在查询时使用映射中定义的运行时脚本计算的,结果仅包含与 211.11.9.0 IP 地址匹配的文档。
从相关索引中检索字段
警告:此功能处于技术预览阶段,可能会在未来版本中更改或删除。Elastic 将努力修复任何问题,但技术预览中的功能不受官方 GA 功能的支持 SLA 约束。
_search API 上的 fields 参数还可用于通过具有 lookup 类型的运行时字段从相关索引中检索字段。
注意:由 lookup 类型的运行时字段检索的字段可用于丰富搜索响应中的命中。无法查询或聚合这些字段。
POST ip_location/_doc?refresh
{
"ip": "192.168.1.1",
"country": "Canada",
"city": "Montreal"
}
PUT logs/_doc/1?refresh
{
"host": "192.168.1.1",
"message": "the first message"
}
PUT logs/_doc/2?refresh
{
"host": "192.168.1.2",
"message": "the second message"
}
POST logs/_search
{
"runtime_mappings": {
"location": {
"type": "lookup", // 1
"target_index": "ip_location", // 2
"input_field": "host", // 3
"target_field": "ip",
"fetch_fields": ["country", "city"] // 5
}
},
"fields": [
"host",
"message",
"location"
],
"_source": false
}- 在主搜索请求中定义一个运行时字段,其查找类型为使用 term 询从目标索引中检索字段。
- 查找查询针对的目标索引
- 主索引上的字段,其值用作查找术语查询的输入值
- 查找查询搜索的查找索引上的字段
- 要从查找索引中检索的字段列表。请参阅搜索请求的 fields 参数。
上面代码运行的结果为:
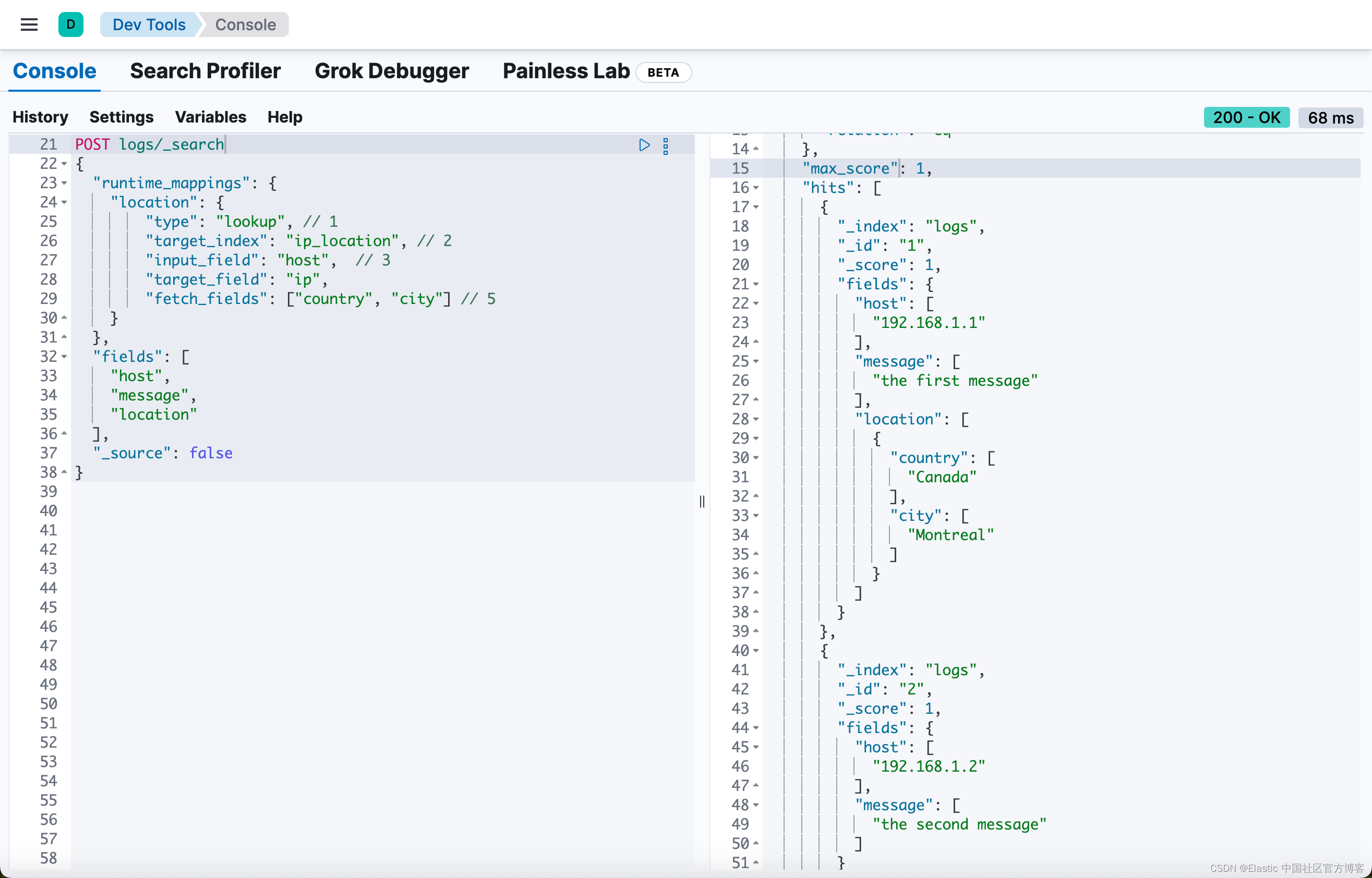
上述搜索从返回的搜索结果的每个 IP 地址的 ip_location 索引中返回 country 和 city。
查找字段的响应被分组以保持每个文档与查找索引的独立性。每个输入值的查找查询预计最多与查找索引上的一个文档匹配。如果查找查询与多个文档匹配,则将选择一个随机文档。
索引运行时字段
运行时字段由其运行的上下文定义。例如,你可以在搜索查询的上下文中或索引映射的 runtime 部分中定义运行时字段。如果你决定索引运行时字段以获得更好的性能,只需将完整的运行时字段定义(包括脚本)移动到索引映射的上下文中。Elasticsearch 会自动使用这些索引字段来驱动查询,从而缩短响应时间。此功能意味着你只需编写一次脚本,即可将其应用于支持运行时字段的任何上下文。
注意:目前不支持索引 composite 运行时字段。
然后,你可以使用运行时字段来限制 Elasticsearch 需要计算值的字段数量。将索引字段与运行时字段结合使用,可以灵活地处理索引数据以及定义其他字段的查询。
重要:索引运行时字段后,你无法更新包含的脚本。如果你需要更改脚本,请使用更新后的脚本创建一个新字段。
例如,假设你的公司想要更换一些旧的压力阀。连接的传感器只能报告真实读数的一小部分。你决定不为压力阀配备新的传感器,而是根据报告的读数计算值。根据报告的数据,你在 my-index-000001 的映射中定义以下字段:
DELETE my-index-000001
PUT my-index-000001/
{
"mappings": {
"properties": {
"timestamp": {
"type": "date"
},
"temperature": {
"type": "long"
},
"voltage": {
"type": "double"
},
"node": {
"type": "keyword"
}
}
}
}然后,你可以批量索引来自传感器的一些样本数据。这些数据包括每个传感器的 voltage 读数:
POST my-index-000001/_bulk?refresh=true
{"index":{}}
{"timestamp": 1516729294000, "temperature": 200, "voltage": 5.2, "node": "a"}
{"index":{}}
{"timestamp": 1516642894000, "temperature": 201, "voltage": 5.8, "node": "b"}
{"index":{}}
{"timestamp": 1516556494000, "temperature": 202, "voltage": 5.1, "node": "a"}
{"index":{}}
{"timestamp": 1516470094000, "temperature": 198, "voltage": 5.6, "node": "b"}
{"index":{}}
{"timestamp": 1516383694000, "temperature": 200, "voltage": 4.2, "node": "c"}
{"index":{}}
{"timestamp": 1516297294000, "temperature": 202, "voltage": 4.0, "node": "c"}在与几位现场工程师交谈后,你意识到传感器报告的值至少应该是当前值的两倍,但可能更高。你创建一个名为 voltage_corrected 的运行时字段,该字段检索当前电压并将其乘以 2:
PUT my-index-000001/_mapping
{
"runtime": {
"voltage_corrected": {
"type": "double",
"script": {
"source": """
emit(doc['voltage'].value * params['multiplier'])
""",
"params": {
"multiplier": 2
}
}
}
}
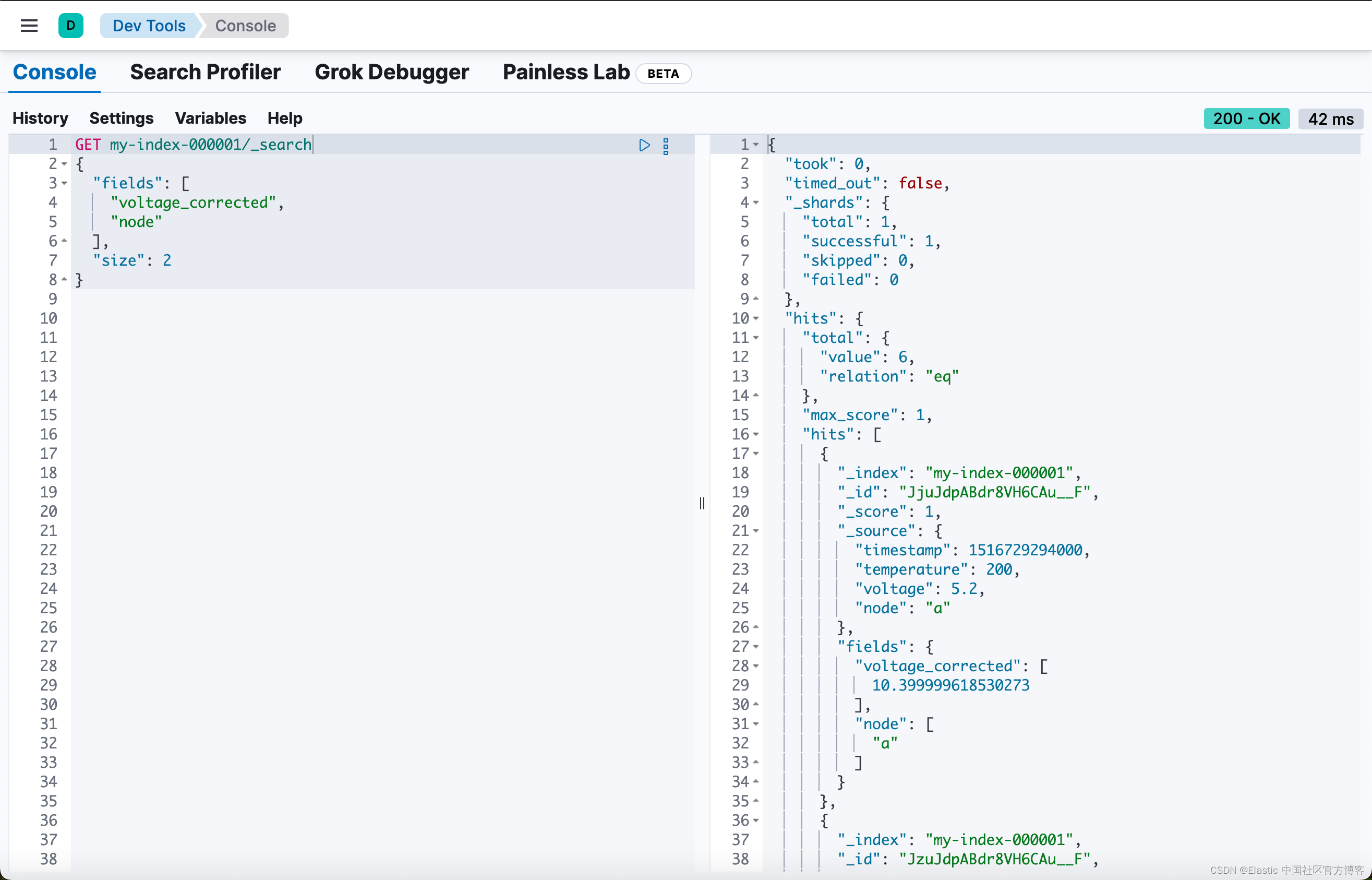
}你可以使用 _search API 上的 fields 参数检索计算值:
GET my-index-000001/_search
{
"fields": [
"voltage_corrected",
"node"
],
"size": 2
}
在查看传感器数据并运行一些测试后,你确定报告的传感器数据的乘数应为 4。为了获得更高的性能,你决定使用新的乘数参数对 voltage_corrected 运行时字段进行索引。
在名为 my-index-000001 的新索引中,将 voltage_corrected 运行时字段定义复制到新索引的映射中。就这么简单!你可以添加一个名为 on_script_error 的可选参数,该参数确定如果脚本在索引时抛出错误,是否拒绝整个文档(默认)。
DELETE my-index-000001
PUT my-index-000001/
{
"mappings": {
"properties": {
"timestamp": {
"type": "date"
},
"temperature": {
"type": "long"
},
"voltage": {
"type": "double"
},
"node": {
"type": "keyword"
},
"voltage_corrected": {
"type": "double",
"on_script_error": "fail", // 1
"script": {
"source": """
emit(doc['voltage'].value * params['multiplier'])
""",
"params": {
"multiplier": 4
}
}
}
}
}
}- 如果脚本在索引时抛出错误,则会导致整个文档被拒绝。将值设置为 ignore 将在文档的 _ignored 元数据字段中注册该字段并继续索引。
将来自传感器的一些样本数据批量索引到 my-index-000001 索引中:
POST my-index-000001/_bulk?refresh=true
{ "index": {}}
{ "timestamp": 1516729294000, "temperature": 200, "voltage": 5.2, "node": "a"}
{ "index": {}}
{ "timestamp": 1516642894000, "temperature": 201, "voltage": 5.8, "node": "b"}
{ "index": {}}
{ "timestamp": 1516556494000, "temperature": 202, "voltage": 5.1, "node": "a"}
{ "index": {}}
{ "timestamp": 1516470094000, "temperature": 198, "voltage": 5.6, "node": "b"}
{ "index": {}}
{ "timestamp": 1516383694000, "temperature": 200, "voltage": 4.2, "node": "c"}
{ "index": {}}
{ "timestamp": 1516297294000, "temperature": 202, "voltage": 4.0, "node": "c"}你现在可以在搜索查询中检索计算值,并根据精确值查找文档。以下范围查询返回计算出的 voltage_corrected 大于或等于 16 但小于或等于 20 的所有文档。同样,使用 _search API 上的 fields 参数来检索所需的字段:
POST my-index-000001/_search
{
"query": {
"range": {
"voltage_corrected": {
"gte": 16,
"lte": 20,
"boost": 1.0
}
}
},
"fields": ["voltage_corrected", "node"]
}
根据所包含脚本的计算值,响应包含与范围查询匹配的文档的 voltage_corrected 字段。
使用运行时字段探索数据
考虑要从中提取字段的大量日志数据。索引数据非常耗时,并且会占用大量磁盘空间,而你只想探索数据结构,而无需预先提交 schema。
你知道日志数据包含要提取的特定字段。在本例中,我们希望重点关注 @timestamp 和 message 字段。通过使用运行时字段,你可以定义脚本来计算搜索时这些字段的值。
将索引字段定义为起点
你可以从一个简单的示例开始,将 @timestamp 和 message 字段作为索引字段添加到 my-index-000001 映射中。为了保持灵活性,请使用 wildcard 作为 message 的字段类型:
DELETE my-index-000001
PUT /my-index-000001/
{
"mappings": {
"properties": {
"@timestamp": {
"format": "strict_date_optional_time||epoch_second",
"type": "date"
},
"message": {
"type": "wildcard"
}
}
}
}提取一些数据
映射要检索的字段后,将日志数据中的一些记录索引到 Elasticsearch 中。以下请求使用 bulk API 将原始日志数据索引到 my-index-000001 中。你可以使用小样本来试验运行时字段,而不是索引所有日志数据。
最终文档不是有效的 Apache 日志格式,但我们可以在脚本中考虑这种情况。
POST /my-index-000001/_bulk?refresh
{"index":{}}
{"timestamp":"2020-04-30T14:30:17-05:00","message":"40.135.0.0 - - [30/Apr/2020:14:30:17 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:30:53-05:00","message":"232.0.0.0 - - [30/Apr/2020:14:30:53 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:12-05:00","message":"26.1.0.0 - - [30/Apr/2020:14:31:12 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:19-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:19 -0500] \"GET /french/splash_inet.html HTTP/1.0\" 200 3781"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:22-05:00","message":"247.37.0.0 - - [30/Apr/2020:14:31:22 -0500] \"GET /images/hm_nbg.jpg HTTP/1.0\" 304 0"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:27-05:00","message":"252.0.0.0 - - [30/Apr/2020:14:31:27 -0500] \"GET /images/hm_bg.jpg HTTP/1.0\" 200 24736"}
{"index":{}}
{"timestamp":"2020-04-30T14:31:28-05:00","message":"not a valid apache log"}此时,你可以查看 Elasticsearch 如何存储你的原始数据。
GET /my-index-000001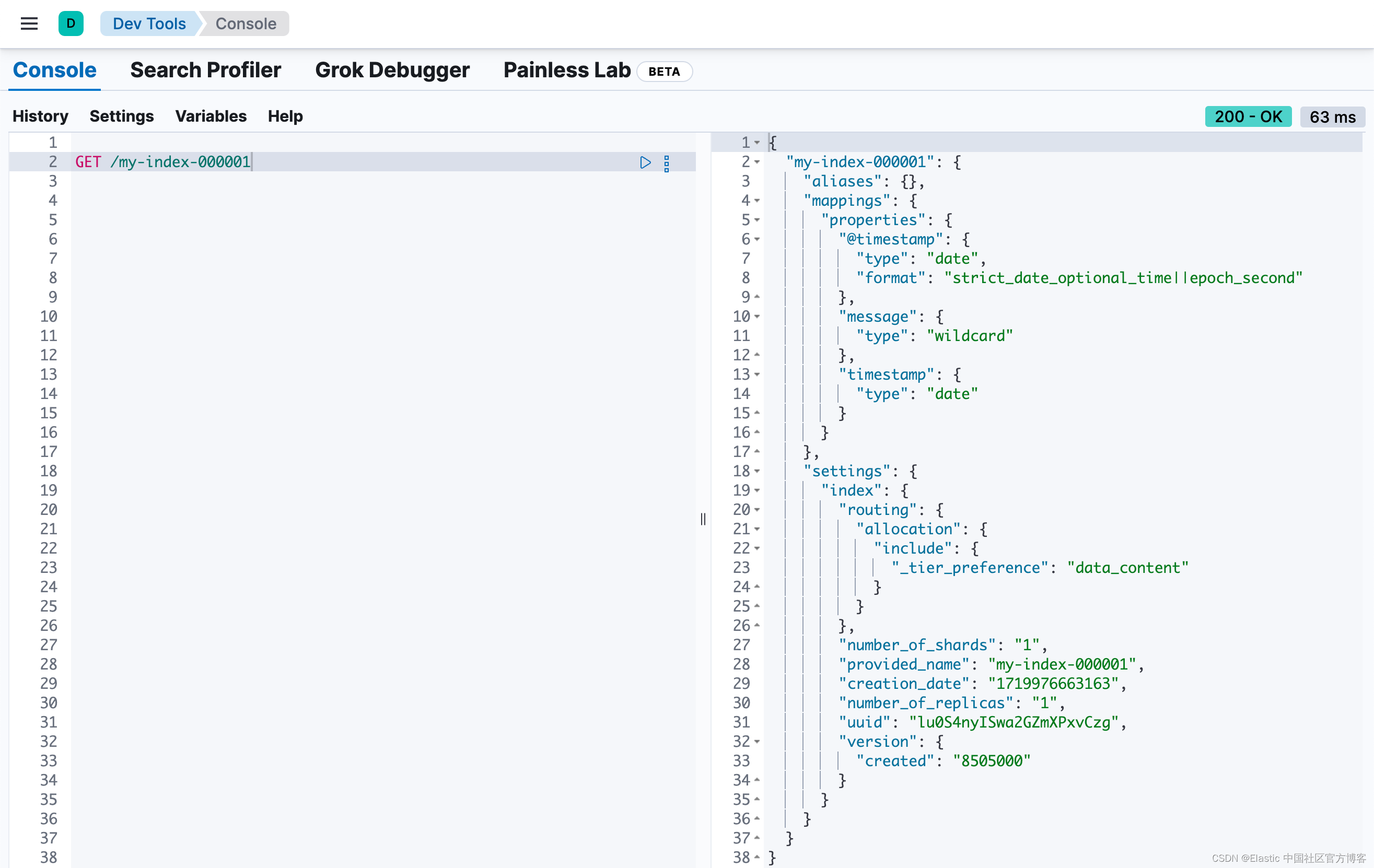
该映射包含两个字段:@timestamp 和 message。
使用 grok 模式定义运行时字段
如果你想要检索包含 clientip 的结果,则可以将该字段作为运行时字段添加到映射中。以下运行时脚本定义了一个 grok 模式,该模式从文档中的单个文本字段中提取结构化字段。grok 模式就像一个正则表达式,支持可以重复使用的别名表达式。
该脚本匹配 %{COMMONAPACHELOG} 日志模式,该模式了解 Apache 日志的结构。如果模式匹配 (clientip != null),则脚本会发出匹配 IP 地址的值。如果模式不匹配,则脚本只会返回字段值而不会崩溃。
PUT my-index-000001/_mappings
{
"runtime": {
"http.client_ip": {
"type": "ip",
"script": """
String clientip=grok('%{COMMONAPACHELOG}').extract(doc["message"].value)?.clientip;
if (clientip != null) emit(clientip);
"""
}
}
}- 此条件确保即使 message 的模式不匹配,脚本也不会崩溃。
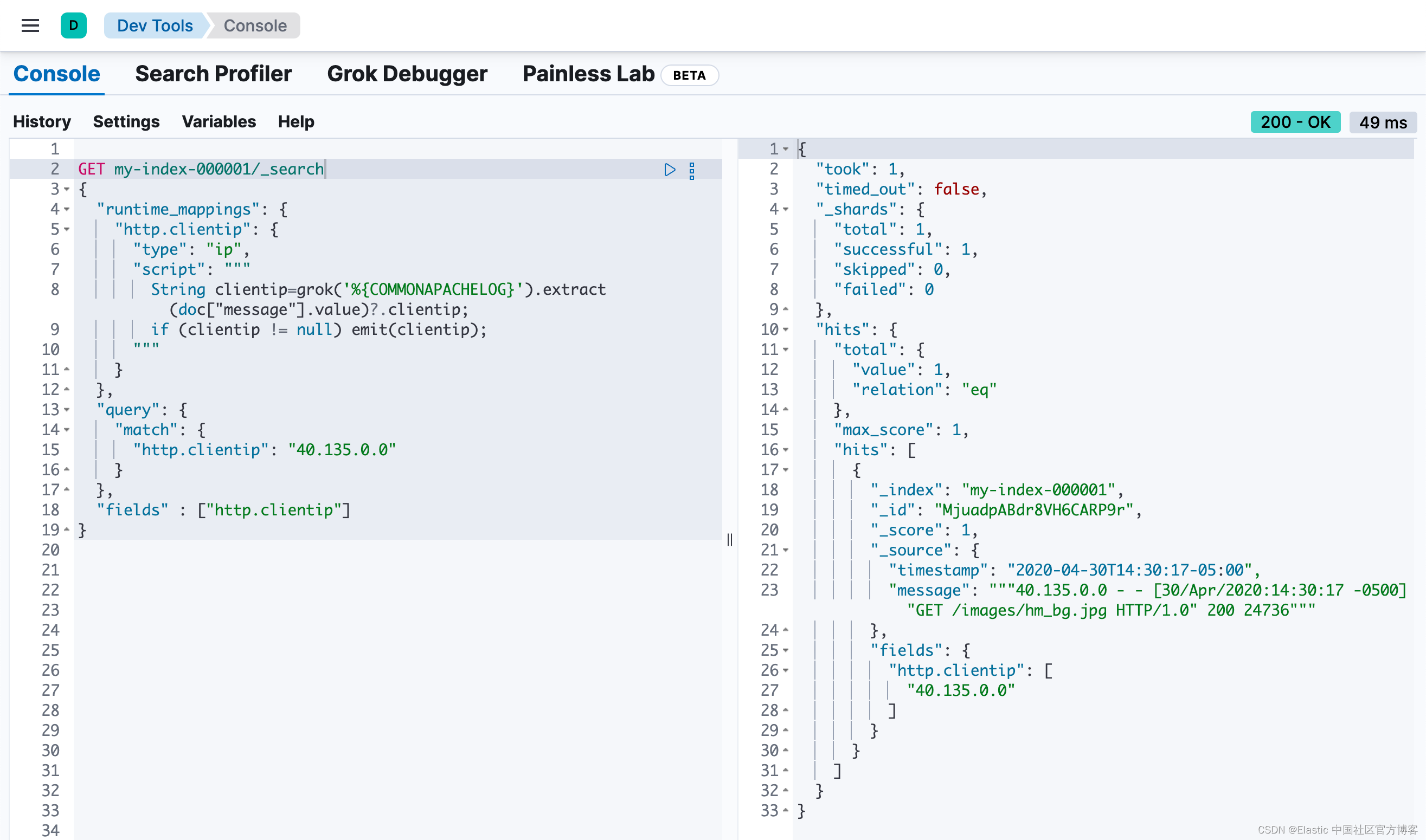
或者,你可以在搜索请求的上下文中定义相同的运行时字段。运行时定义和脚本与之前在索引映射中定义的完全相同。只需将该定义复制到搜索请求的 "runtime_mappings" 部分下,并包含与运行时字段匹配的查询即可。此查询返回的结果与你在索引映射中为 http.clientip 运行时字段定义搜索查询的结果相同,但仅限于此特定搜索的上下文:
GET my-index-000001/_search
{
"runtime_mappings": {
"http.clientip": {
"type": "ip",
"script": """
String clientip=grok('%{COMMONAPACHELOG}').extract(doc["message"].value)?.clientip;
if (clientip != null) emit(clientip);
"""
}
},
"query": {
"match": {
"http.clientip": "40.135.0.0"
}
},
"fields" : ["http.clientip"]
}
定义 composite 运行时字段
你还可以定义复合运行时字段,以便从单个脚本发出多个字段。你可以定义一组类型化的子字段并发出值映射。在搜索时,每个子字段都会检索映射中与其名称关联的值。这意味着你只需指定一次 grok 模式即可返回多个值:
PUT my-index-000001/_mappings
{
"runtime": {
"http": {
"type": "composite",
"script": "emit(grok(\"%{COMMONAPACHELOG}\").extract(doc[\"message\"].value))",
"fields": {
"clientip": {
"type": "ip"
},
"verb": {
"type": "keyword"
},
"response": {
"type": "long"
}
}
}
}
}搜索特定 IP 地址
使用 http.clientip 运行时字段,你可以定义一个简单的查询来搜索特定 IP 地址并返回所有相关字段。
GET my-index-000001/_search
{
"query": {
"match": {
"http.clientip": "40.135.0.0"
}
},
"fields" : ["*"]
}API 返回以下结果。由于 http 是一个 composite 运行时字段,因此响应包括字段下的每个子字段,包括与查询匹配的任何关联值。无需提前构建数据结构,你就可以以有意义的方式搜索和探索数据,以试验并确定要索引的字段。

另外,还记得脚本中的 if 语句吗?
if (clientip != null) emit(clientip);如果脚本不包含此条件,则查询将在任何与模式不匹配的分片上失败。通过包含此条件,查询将跳过与 grok 模式不匹配的数据。
搜索特定范围内的文档
你还可以运行对时间戳字段进行操作的范围查询。以下查询将返回时间戳大于或等于 2020-04-30T14:31:27-05:00 的任何文档:
GET my-index-000001/_search
{
"query": {
"range": {
"timestamp": {
"gte": "2020-04-30T14:31:27-05:00"
}
}
}
}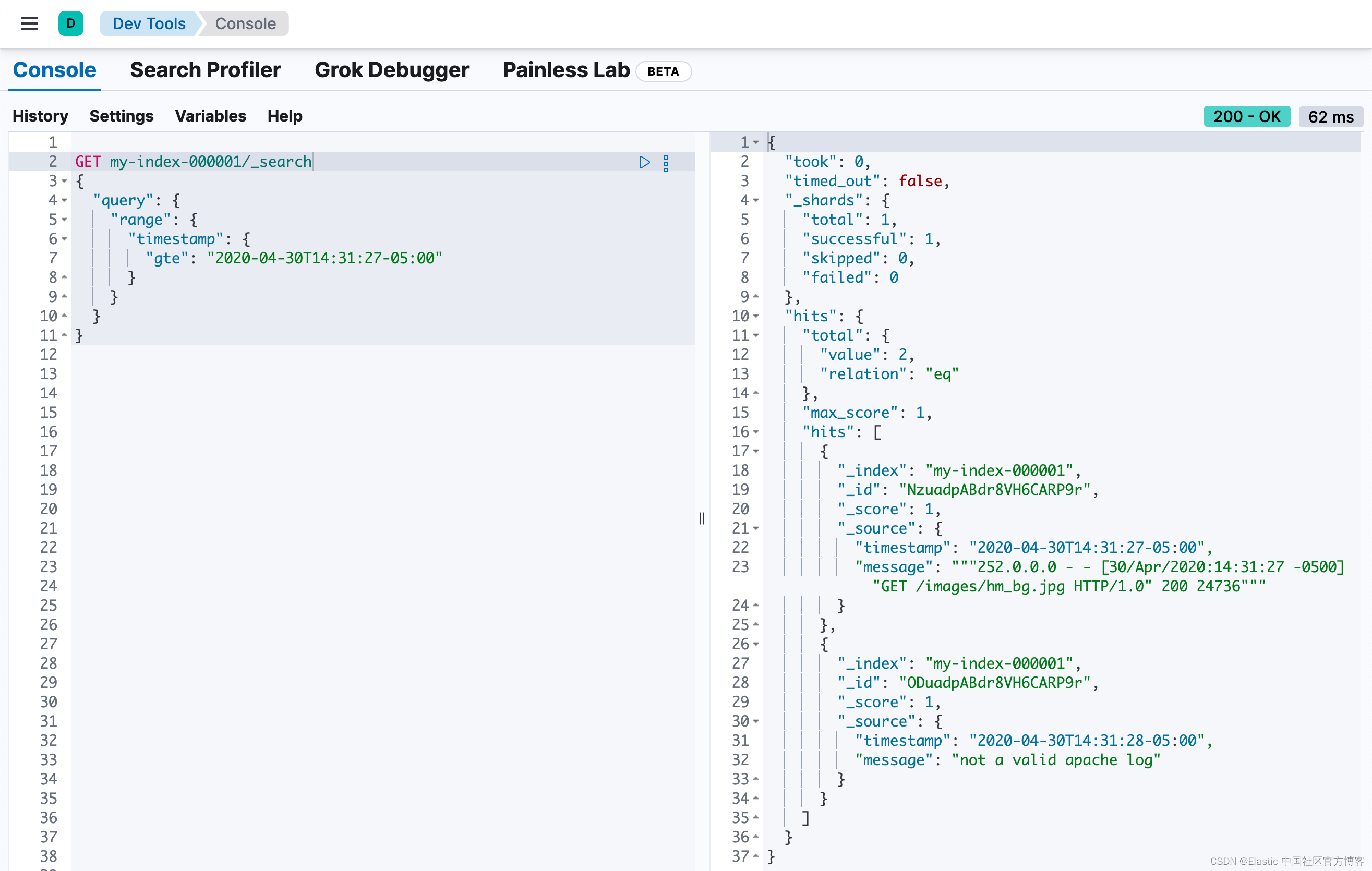
响应包含日志格式不匹配但时间戳在定义范围内的文档。
使用 dissect 模式定义运行时字段
如果你不需要正则表达式的强大功能,则可以使用解析模式代替 grok 模式。dissect 模式匹配固定分隔符,但通常比 grok 更快。
你可以使用 dissect 来实现与使用 grok 模式解析 Apache 日志相同的结果。你无需匹配日志模式,而是包含要丢弃的字符串部分。特别注意要丢弃的字符串部分将有助于构建成功的解析模式。
PUT my-index-000001/_mappings
{
"runtime": {
"http.client.ip": {
"type": "ip",
"script": """
String clientip=dissect('%{clientip} %{ident} %{auth} [%{@timestamp}] "%{verb} %{request} HTTP/%{httpversion}" %{status} %{size}').extract(doc["message"].value)?.clientip;
if (clientip != null) emit(clientip);
"""
}
}
}类似地,你可以定义一个解剖模式来提取 HTTP 响应代码:
然后,你可以使用 http.responses 运行时字段运行查询以检索特定的 HTTP 响应。使用 _search 请求的 fields 参数来指示要检索哪些字段:
GET my-index-000001/_search
{
"query": {
"match": {
"http.responses": "304"
}
},
"fields" : ["http.client_ip","timestamp","http.verb"]
}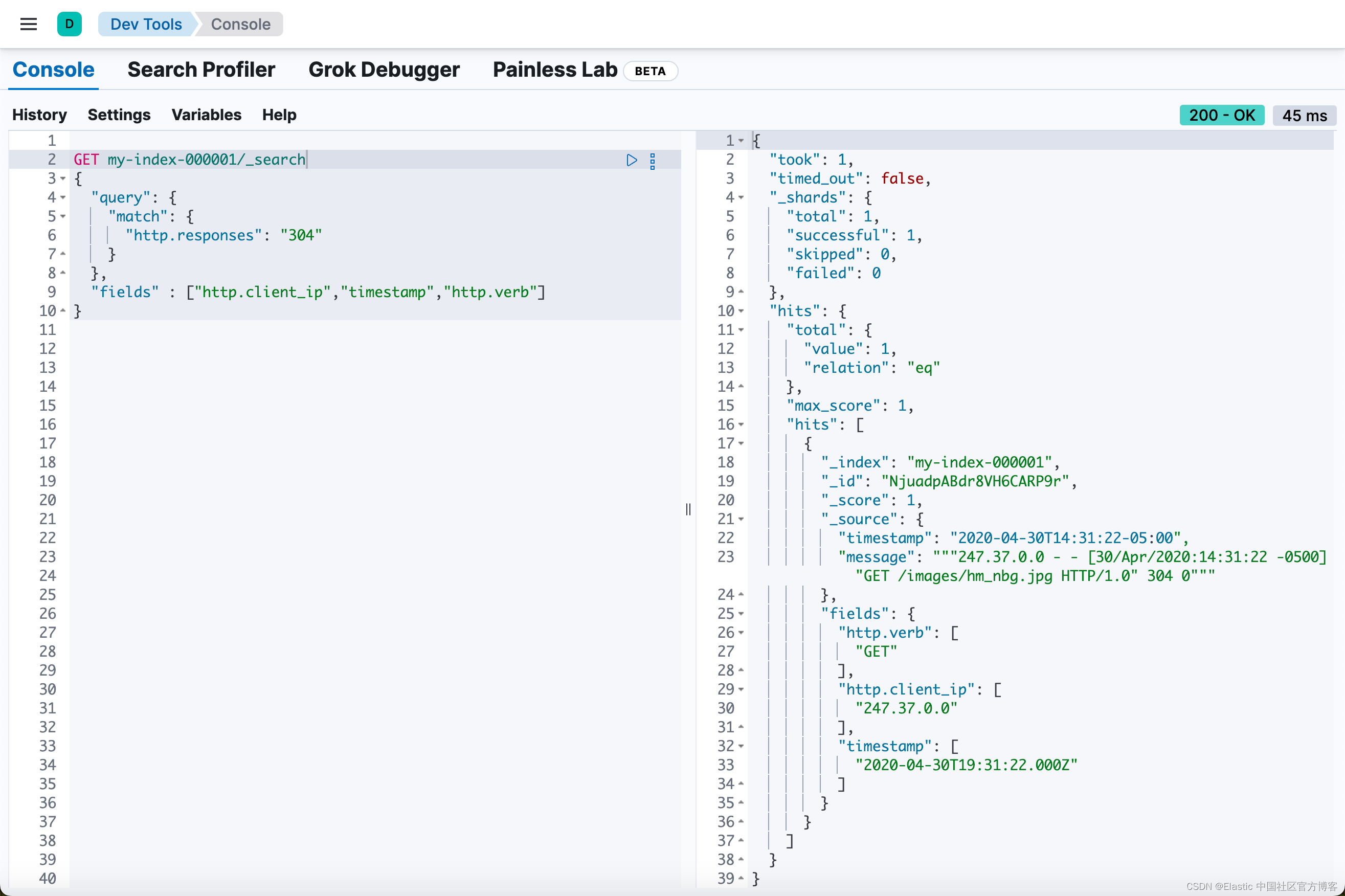
响应包含一个文档,其中 HTTP 响应为 304。