文章目录
- 📑引言
- 一、神经元和感知器
-
- [1.1 神经元的基本概念](#1.1 神经元的基本概念)
- [1.2 感知器模型](#1.2 感知器模型)
- 二、多层感知器(MLP)
-
- [2.1 MLP的基本结构](#2.1 MLP的基本结构)
- [2.2 激活函数的重要性](#2.2 激活函数的重要性)
- [2.3 激活函数](#2.3 激活函数)
- [2.4 激活函数的选择](#2.4 激活函数的选择)
- 三、小结

📑引言
深度学习是现代人工智能的核心技术之一,而神经网络是深度学习的基础结构。神经网络通过模拟人脑的神经元工作原理,从数据中自动提取特征并进行复杂的模式识别和分类任务。在这篇博客中,我们将详细探讨神经网络的基本概念、构成单元、重要特性以及它们在深度学习中的关键作用。
一、神经元和感知器
1.1 神经元的基本概念
神经元是神经网络的基本计算单元,其灵感来源于生物神经元。生物神经元通过接收输入信号(来自其他神经元或感受器),经过处理后传递输出信号。人工神经元模拟了这一过程,主要由以下部分组成:
- 输入(Input): 接收来自其他神经元或输入数据的信号。
- 权重(Weight): 每个输入信号都与一个权重相乘,权重决定了该输入信号的重要性。
- 加权求和(Weighted Sum): 所有输入信号与对应权重的乘积之和。
- 激活函数(Activation Function): 将加权求和的结果转换为输出信号。
数学上,一个神经元的输出可以表示为:
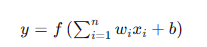
其中,( x_i ) 是输入信号,( w_i ) 是权重,( b ) 是偏置,( f ) 是激活函数。
1.2 感知器模型
感知器(Perceptron)是最简单的人工神经元模型,由Frank Rosenblatt在1958年提出。感知器是一种线性分类器,能够将输入数据分为两个类别。其基本结构如下:
- 输入层: 接收输入数据,每个输入与一个权重相乘。
- 加权求和: 将所有加权后的输入信号相加,加上偏置。
- 激活函数: 使用阶跃函数(Step Function)作为激活函数,将加权求和结果转换为输出。
阶跃函数定义为:
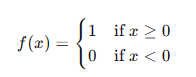
感知器模型可以表示为:
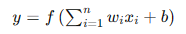
感知器的训练过程通过调整权重和偏置,使模型能够正确分类输入数据。感知器的局限性在于它只能处理线性可分的数据集,对于复杂的非线性数据无能为力。
二、多层感知器(MLP)
2.1 MLP的基本结构
多层感知器(Multi-Layer Perceptron,MLP)是由多个感知器层叠组成的神经网络模型。MLP通过引入隐藏层(Hidden Layer),能够处理复杂的非线性数据。MLP的基本结构包括:
- 输入层: 接收输入数据。
- 隐藏层: 由多个神经元组成,通过激活函数进行非线性变换。
- 输出层: 生成最终的输出结果。
每一层的输出作为下一层的输入,层与层之间全连接(Fully Connected),即每个神经元与上一层的所有神经元相连。
2.2 激活函数的重要性
激活函数是MLP中引入非线性的关键,使得神经网络能够拟合复杂的非线性关系。
常见的激活函数包括:
- Sigmoid函数:
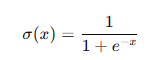
Sigmoid函数将输入压缩到(0, 1)之间,适用于输出为概率的任务,但容易导致梯度消失问题。
- Tanh函数:
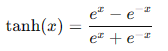
Tanh函数将输入压缩到(-1, 1)之间,相比Sigmoid具有零中心,但仍有梯度消失问题。
- ReLU函数(Rectified Linear Unit):
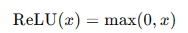
ReLU函数解决了梯度消失问题,计算简单,广泛应用于现代神经网络中。但其可能导致部分神经元"死亡",即在训练过程中输出恒为零。
- Leaky ReLU函数:
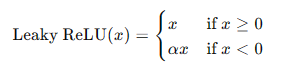
Leaky ReLU在负轴上保留一部分信息,避免了神经元死亡的问题。
MLP的训练
MLP的训练过程包括前向传播(Forward Propagation)和反向传播(Backpropagation)。前向传播计算每层的输出,反向传播计算误差梯度并更新权重。
- 前向传播: 从输入层开始,逐层计算输出,直到输出层生成最终结果。
- 反向传播: 从输出层开始,逐层计算误差梯度,并使用梯度下降法更新权重和偏置。
反向传播的关键是链式法则(Chain Rule),通过链式法则计算每层的梯度:
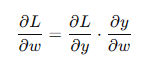
其中,( L ) 是损失函数,( y ) 是输出,( w ) 是权重。
2.3 激活函数
激活函数的作用
激活函数在神经网络中起到引入非线性的作用,使得神经网络能够学习和拟合复杂的非线性关系。不同的激活函数具有不同的特性和应用场景。
常见激活函数
- Sigmoid函数:
Sigmoid函数将输入值映射到(0, 1)之间,常用于二分类问题的输出层。其数学表达式为:
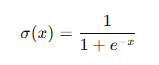
**优点:**平滑且连续,输出范围在(0, 1)之间。
**缺点:**容易导致梯度消失问题,训练深层网络时效果不佳。
- Tanh函数:
Tanh函数将输入值映射到(-1, 1)之间,常用于隐藏层的激活函数。其数学表达式为:
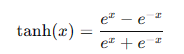
**优点:**零中心化,输出范围在(-1, 1)之间。
**缺点:**与Sigmoid函数类似,也容易导致梯度消失问题。
- ReLU函数:
ReLU函数是现代神经网络中最常用的激活函数,输出输入值与0的较大者。其数学表达式为:
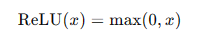
**优点:**计算简单,能够有效解决梯度消失问题,提高训练速度。
**缺点:**可能导致部分神经元"死亡",即在训练过程中输出恒为零。
- Leaky ReLU函数:
Leaky ReLU函数是ReLU的变种,在负轴上保留一部分信息,避免神经元死亡的问题。其数学表达式为:
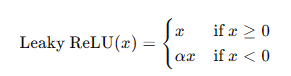
**优点:**避免神经元死亡,保留负值信息。
**缺点:**需要手动调节参数 ( \alpha )。
2.4 激活函数的选择
激活函数的选择对神经网络的性能有重要影响。
一般来说,隐藏层使用ReLU或其变种(如Leaky ReLU),输出层根据具体任务选择Sigmoid或Tanh函数。对于回归问题,输出层可以直接使用线性激活函数。
三、小结
神经网络是深度学习的基础结构,通过模拟人脑的神经元工作原理,能够从数据中自动提取特征并进行复杂的模式识别和分类任务。本文详细探讨了神经元和感知器、多层感知器(MLP)、激活函数的基本概念和关键技术。希望通过这篇详细的博客,读者能够全面理解神经网络的基础知识,为深入学习和研究深度学习技术打下坚实的基础。