📢博客主页:肩匣与橘
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由肩匣与橘 编写,首发于CSDN🙉
📢生活依旧是美好而又温柔的,你也是✨
数据库系统工程师是近年来比较热门的职业,随着企业信息化建设的深入发展,对于数据库系统工程师的需求也越来越大。软考中级数据库系统工程师考试是对于候选人在数据库系统工程领域中的专业技能和知识的考核,具有一定的难度和专业性。因此,在备考软考中级数据库系统工程师考试之前,需要对相关知识进行全面系统的学习和掌握。 本文是在备考软考中级数据库系统工程师考试过程中的笔记总结,旨在为大家提供一些笔记总结,帮助大家更好地备考和应对考试。本文主要涵盖了软考中级数据库系统工程师考试的相关知识点和技能要求,包括数据库系统基础、数据库设计与应用、数据库管理与维护、数据库安全与备份等方面的内容。
软考中级 | 数据库系统工程师 | 笔记总结
[4.6 编写程序时的错误](#4.6 编写程序时的错误)
[9.11UNION 操作符](#9.11UNION 操作符)
一、计算机系统
1.1运算器
功能:
- 执行所有的算术运算。加减乘除等
- 执行所有的逻辑运算。逻辑与、逻辑非、逻辑或。
组成:
- 算术逻辑单元(ALU):负责处理数据,实现对数据的算术运算和逻辑运算。
- 累加寄存器(AC):也称为累加器,当算数逻辑单元ALU执行运算时,提供一个工作区
- 数据缓冲寄存器(DR):对内存进行读写操作时,用DR暂时存放指令或数据。作为CPU和内存、外设之间在操作速度上的缓冲,以及数据传送的中转站。
- 状态条件寄存器(PSW):主要存放状态条件的,分为状态标志和控制标志。
1.2控制器
- 指令寄存器(IR):用来暂时存放一条指令,由指令译码器根据指令寄存器中的内容产生各种微操作指令,控制其他部分协调工作。
- 程序计数器(PC):存放的是将要执行的下一条指令的地址。PC+1------>地址加一
- 地址寄存器(AR):保存当前CPU所访问的内存单元地址。由于内存和CPU的速度差异,需要用AR保存地址信息,直到内存读写操作完成为止
- 指令译码器(ID):对指令中的操作码字段进行分析解释,识别该指令规定的操作,然后向操作控制器发出具体的控制信号。
1.3指令
指令是对机器进行程序控制的最小单位。 包括操作码和操作数。操作码指出是什么操作,由指令译码器ID来识别。操作数直接指出操作数本身或者指出操作数所在的地址。
1.4存储器与总线
- 数据总线(DB):用来传送数据信息,是双向的。DB的宽度决定了CPU和计算机其他设备之间每次交换数据的位数。
- 地址总线(AB):用于传送CPU发出的地址信息,是单向的。宽度决定了CPU的最大寻址能力。
- 控制总线(CB):用来传送控制信号、时序信号和状态信息等。CB中的每一条线的信息传送方向是单方向且确定的,但CB作为一个整体则是双向的。
优点
- 简化了系统结构,便于系统设计制造
- 大大减少了连线数目,便于布线,减小体积,提高系统可靠性
- 便于接口设计,所有与总线链接的设备均采用类似的接口
- 便于系统的扩充、更新与灵活配置,易于实现系统的模块化
- 便于设备的软件设计,所有接口软件就是对不同的接口地址进行操作
- 便于故障诊断和维修,同时降低了成本
1.5输入输出技术****
程序控制方式:(中断方式、DMA方式)
- 无条件传送:外设总是准备好的,无条件,随时接收和提供数据。
- 程序查询方式:CPU利用程序来查询外设的状态,准备好了再传数据。
- 中断方式:CPU不等待,也不执行程序去查询外设的状态,而是由外设在准备好以后,向CPU发出中断请求。
以上三种方式都需要CPU的参与。
- DMA方式:数据的传输是在主存和外设之间直接进行,不需要CPU的干预,实际操作是由DMA硬件直接执行完成的。
- 通道方式和外围处理机方式:更进一步减轻了CPU对1/0操作的控制更进一步提高了CPU的工作效率,但是是以增加更多硬件为代价的。
1.6计算机软件=程序+数据+相关文档。
1.7操作数
包含在指令中是立即寻址,操作数的地址包含在指令中是直接寻址。
1.8计算机硬件的典型结构
单总线结构、双总线结构、采用通道的大型系统结构。
1.9CPU由运算器和控制器组成
控制器由程序计数器(PC)、指令寄存器(IR)、指令译码器(ID)、状态条件寄存器、时序产生器和微操作信号发生器组成。
- PC: pc自动增加一个值,指向下一条要执行的指令,当程序转移时将转移地址送入PC。
- IR:用于存放当前要执行的指令。
- ID:对现行的指令进行分析,确定指令类型、指令要完成的操作和寻址方式。
1.10指令执行的过程
- 取指令:控制器首先按程序计数器所指出的指令地址从内存中取出一条指令。
- 指令译码:将指令的操作码部分送入指令译码器中进行分析,然后根据指令的功能发出控制命令。
- 按指令操作码执行。
- 形成下一条指令地址。
1.11CPU的基本功能
- 程序控制
- 操作控制
- 时间控制
- 数据处理------CPU的根本任务
1.12计算机体系结构和计算机组成的区别
体系结构要解决的问题是计算机系统在总体上、功能上需要解决的问题,而计算机组成要解决的是逻辑上如何具体实现的问题。
1.13 计算机体系结构分类(指令流、数据流、多倍性)
Flynn分类:传统的顺序执行的计算机在同一时刻只能执行一条指令(即只有一个控制流)、处理一个数据(即只有一个数据流),因此被称为单指令流单数据流计算机Single Instruction Single Data即SISD计算机)。而对于大多数并行计算机而言,多个处理单元都是根据不同的控制流程执行不同的操作,处理不同的数据,因此,它们被称作是多指令流多数据流计算机,即MIMD(Multiple Instruction Multiple Data)计算机。曾经在很长一段时间内成为超级并行计算机主流的向量计算机除了标量处理单元之外,最重要的是具有能进行向量计算的硬件单元。在执行向量操作时,一条指令可以同时对多个数据(组成一个向量)进行运算,这就是单指令流多数据流(Single Instruction Multiple Data,SIMD)的概念。因此,我们将向量计算机称为SIMD计算机。第四种类型即所谓的多指令流单数据(MultipleInstructionSingleData)计算机。在这种计算机中,各个处理单元组成一个线性阵列,分别执行不同的指令流,而同一个数据流则顺次通过这个阵列中的各个处理单元。这种系统结构只适用于某些特定的算法。相对而言,SIMD和MISD模型更适合于专用计算。在商用并行计算机中,MIMD模型最为通用,SIMD次之,而MISD最少用。
|--------------|------------------------|---------------------|-----------------------|
| 体系结构类型 | 结构 | 关键特性 | 代表 |
| 单指令流单数据流SISD | 控制部分:一个 处理器:一个 主存模块:一个 | | 单处理器系统 |
| 单指令流多数据流SIMD | 控制部分:一个 处理器:多个 主存模块:多个 | 各处理器以异步的形式执行同一条指令 | 并行处理机 阵列处理机 指令超级向量处理机 |
| 多指令流单数据流MISD | 控制部分:多个 处理器:多个 主存模块:多个 | 被证明不可能,至少是不实际 | 目前没有,有文献称流水线计算机为此类 |
| 多指令流多数据流MIMD | 控制部分:多个 处理器:多个 主存模块:多个 | 能够实现作业、任务、指令等各级全面并行 | 多处理机系统 多计算机 |
1.14存储器的分类
- 按存储器的位置:内存(主存)和外存(辅存)。
- 按存储器的材料:磁存储器、半导体存储器(静态和动态)和光存储器。
- 按工作方式:读写存储器和只读存储器。只读存储器(ROM/PROM/EPROM/EEPROM/闪存)
- 按访问方式:按地址访问的存储器和按内容访问的存储器(相连存储器)。
- 按寻址方式:随机存储器(RAM)、顺序存储器(ASM)---磁带、直接存储器(DAM)---磁盘就是直接存储器。
1.15输入/输出
直接程序控制、中断方式、直接存储器存取(DMA)。
1.16 流水线技术
流水线周期:各子任务中执行时间最长的(最慢的)的子任务执行时间Tn=执行一条指令的所需时间+(n-1)*流水线周期
吞吐率和建立时间是流水线技术的两个重要技术指标。吞吐率是指单位时间内流水线处理机流出的结果数;流水线开始工作经过一段时间(建立时间)才能到达最大的吞吐率。若m个子过程所用的时间都是t0则建立时间是 m*t0,否则t0取子过程中的最长时间。那么n条指令执行完成需要的时间为第一条完全执行的时间加上后n-1条所用的时间(n-1)*m*t0。
1.17虚拟存储器
- 页式:页表硬件少,查表速度快,主存零头少;分页无逻辑性,不利于存储保护。
- 段式:优点是:段的界限分明;支持序的模块化设计;易于对的译改和保护便于多道程序的共享。主要缺点,因段的长度不一,主存利用率不高,产生大内存碎片,造成浪费:段表庞大,查表速度慢。
- 段页式:地址变换速度比较慢。
1.18指令特点
只有20%的指令经常应用频率达80%→RISC(精简指令集计算机)简化了CPU的控制器,提高了处理速度,特点有:
- 指令种类少。一般只有十几到几十条简单的指令。
- 指令长度固定,指今格式少。这可使指译码更加简单。
- 寻址方式少。适合于组合逻辑控制器,便于提高速度。
- 设置最少的访内指令。访问内存比较花时间,尽少用。
- 在 CPU内部设大的存器使大多数作在速很的CPU内部进行。
- 非常适合水线操作。由于指简单,并行行就更易实现。
1.19信息安全的基本要素
- 机密性:确保信息不给未授权的实体或进程。
- 完整性:只有得到允许的人才能修改数据能够别数否已被改。
- 可用性:得到授权的实体在需要时可访问数据。
- 可控性可以控制授权范围内的信息流向及行为方式。
- 可审性:对出现的安全问题提供调查的依据和手段。
1.20 计算机安全等级
(技术安全性、管理安全性、政策法律安全性):分为四组七个等级。
|---|--------|
| 组 | 安全级别 |
| 1 | A1 |
| 2 | B3 |
| 2 | B2 |
| 2 | B1 |
| 3 | C2 |
| 3 | C1 |
| 4 | D(最低级) |
1.21计算机病毒的特点
- 寄生性
- 隐蔽性
- 非法性
- 传染性
- 破坏性
1.22计算机病毒的类型
- 系统引导型病毒------------BOOT型病毒
- 文件外壳型病毒------------攻击command.com文件
- 混合型病毒------------Flip病毒、One Half病毒(幽灵)
- 目录型病毒------------改变目录项不敢变相关文件
- 宏病毒------------用宏的word或是excel文件
1.23计算机可靠性

1.24计算机可靠模型
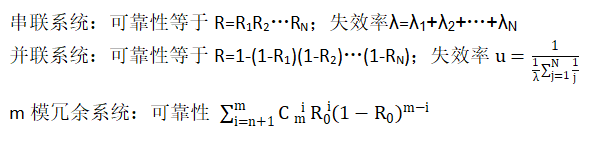
1.25对称加密技术
加密密钥和解密密钥相同
- DES(数据加密标准算法):采用替换和移位方法加密,用56位进行对64位数据加密(也就是说只有56是有效的),每次加密对64位数据进行16次的编码,密钥长度为64位。它加密速度快,密钥容易产生。由于DES的密钥较短,不能抵抗对密钥的穷举搜索攻击。
- RC-5算法。
- IDEA算法:明文和密文的长度都为64位,密钥为128位。
1.26非对称加密技术
运用公钥加密和私钥解密
- RSA算法:RAS技术是指可靠性(R)、可用性(A)、可维性(S)
- 信息摘要是一个单向散列函数,经过散列函数得到一个固定的散列值,常用的信息摘要算法有MD5、SHA算法,散列值分别为128和160位。
- 数字签名:用私钥进行加密用公钥解密。
- 数字时间戳技术:电子商务安全服务项目之一,能提供电子文件的日期和时间信息的安全保护。它是在数据加密上加上了时间,有摘要、文件的日期和时间及数据签名组成。
1.27信息传输加密
- 链路加密:对传输途径进行加密
- 节点加密
- 端到端加密
1.28SSL安全协议
主要应用于提高应用程序之间数据的安全系数。提供的服务有:
- 用户和服务器的合法性认证。
- 加密数据以隐藏被传送的数据。
- 保护数据的完整性。
1.29DES与RAS的比较
DES 是对称密钥密码算法,它的加密密钥和解密密钥是相同的。RSA 是非对称密钥密码算法,它使用不同的密销分别用于加密和解密数据,还可以用于数字签名。对称密钥密码算法的效率要比非对称密钥密码算法高很多,适用于对文件等大量的数据进行加密。
1.30计算机故障诊断技术
计算机的故障:
- 永久性故障
- 间隙性故障
- 瞬时性故障
1.31内存容量
内存容量=末地址-首地址+1
1.32存储相关计算问题
- 计算磁道数:磁道数 = (外半径-内半径)×道密度×记录面数。注:硬盘的第一面和最后一面是保护用的要减掉,即有n个双面的盘片记录面数为n×2-2。
- 非格式化磁盘容量:容量=位密度×π×最内圈直径×总磁道数。注:每道位密度是不通的,但是容量是相同的,其中0道是最外面的磁道位密度最小。
- 格式化磁盘容量:容量=每道扇区数×扇区容量×总磁道数。
- (格式化)平均数据传输率:传输率=每道扇区数×扇区容量×盘片转速。
- 存取时间=寻道时间﹢等待时间。其中:寻道时间是指磁头移动所需的时间;等待时间为等待读写的扇区转到磁头下方所需的时间。
- (非格式化)平均数据传输率:传输率=最内直径×π(3.14)×位密度×盘片转速。注:一般采用非格式化。
1.33数制运算

1.34码制
- 反码:正数的反码与原码相同,负数反码为原码按位取反(符号位不变)。
- 补码:正数的补码与原码相同,负数的补码为反码末位加1(即除去符号位按位取反末位加1)。
- 移码(增码):将补码的符号位求反。
- [X + Y ]补= [X]补+ [Y ]补
- [X - Y ]补= [X]补- [Y ]补
- [ - Y ]补= - [Y ]补
1.35校验码
- 循环校验码(CRC):模二除法:指在除法运算的过程中不计其进位的除法。
- 海明校验码:根据信息位数,确定校验位数,2r≥k+r+1。k为信息位数,r为校验位数,求出满足不等式的最小r即为校验位数。
二、数据结构与算法
2.1数据结构
数据结构指数据元素的组织形式。
2.2线性表的顺序存储结构
特点是物理位置上的邻接关系来表示结点的逻辑关系,具有可以随机存取表中的任一结点的,但插入删除不方便
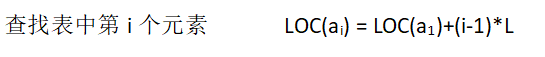
2.3线性表的链式存储结构
用一组任意的存储单元来存放线性表的数据元素,链表中的结点的逻辑次序和物理次序不一定相同。

2.4线性表的插入和删除

2.5栈的顺序存储
采用两个顺序栈共享一个数据空间:(先进后出)
|-----|---|-----|-----|-----|---|-----|
| 栈底1 | → | 栈顶1 | ... | 栈顶2 | ← | 栈底2 |
2.6队列
只允许在表的一端插入元素(队尾),另一端删除元素(队头)。(先进先出)
2.7子串
子串包含在它的主串中的位置是子串的第一个字符首次出现的位置。
2.8广义表
广义表是线性表的推广,是由零个或多个单元素或子表所组成的有限序列。广义表与线性表的区别在于:线性表的元素都是结构上不可分的单元素,而广义表的元素既可以是单元崇,也可以是有结构的表。
2.9二叉树的性质
- 二叉树第i层上的结点数目最多为2i-1(i≥1)。
- 深度为K的二叉树至多有2k-1个结点(k≥1)。
- 在任意一颗二叉树中,若终端结点的个数为n0,度为2的节点数为n2,则n0=n2+1。
- 具有n个结点的完全二叉树的深度为
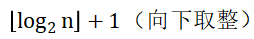
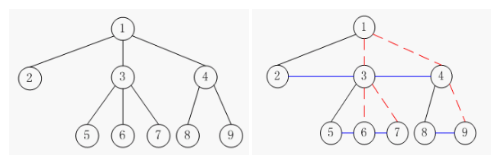
2.10树与二叉树的转换
左孩子不变,其兄弟结点变为左孩子的右孩子;或是将树置保留左孩子结点,其它全删去,然后将各层的兄弟结点连起来。如:
2.11相同遍历
树的前序遍历与二叉树的先序遍历一样;树的后序与二叉树的中序遍历一样。
2.12散列
散列就是把任意长度的输入通过散列算法,变换成固定长度的输出,该输出就是散列值,如此建立的表为散列表,散列表是可以动态创建的。
2.13二分查找
二分查找(折半查找):要求关键字必须采用顺序存储结构,并且必须按关键字的大小有序排序。
2.14查找二叉树
查找二叉树(二叉排序树)------动态查找表:或者为空树或者满足:
- 查找树的左右子树各是一颗查找树。
- 若查找树的左子树非空,则其左子树上各节点的值均小于根结点的值。
- 若查找树的右子树非空,则其右子树上各节点的值均大于根结点的值。
- 平衡二叉树:或者是空树,或者是满足:树中任一节点左右子树的深度相差不超过1。结点的平衡度:其右子树的深度减去左子树的深度(因此平衡度只能为1,0,-1)。
2.15有向图中所有顶点的出度数之和
有向图中所有顶点的出度数之和等于入度数之和。
2.16图中边数
在图中,边数等于所有顶点的度数之和的一半。
2.17顶点和边数
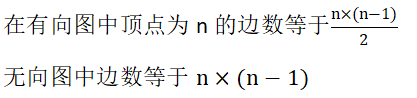
2.18长度
C语言中,struct中各成员都占有自己的内存空间,总长度为所有成员的长度之和,而union中的长度等于最长的成员的长度。
三、操作系统
3.1操作系统的类型
- 批处理操作系统(单道和多道)
- 分时系统(多路性(同时性)、独立性、交互性、及时性)注:UNIX是多用户多任务的分时系统。
- 实时系统------高可靠性
- 网络操作系统
- 分布式操作系统
- 微机操作系统
- 嵌入式操作系统
3.2互斥和同步
利用PV操作实现进程的互斥和同步。
3.3网络操作系统
- 集中模式
- 客户机/服务器模式
- 对等模式
3.4中断响应时间
从发出中断请求到进入中断处理所用的时间。
3.5中断响应时间
中断响应时间=关中断的最长时间 +保护CPU内部寄存器的时间 +进入中断服务函数的执行时间 +开始执行中断服务例程(ISR)的第一条指令时间。
3.6数据记录
在磁盘驱动器向盘片的磁性涂层写入数据时,均是以串行方式一位接着一位的顺序记录在盘片的磁道上。
3.7高速缓存的组成
高速缓存的组成:Cache由两个部分组成:控制部分和Cache存储器部分。
3.8Cache与主存之间的地址映像
Cache与主存之间的地址映像,就是把CPU送来的主存地址转换成Cache地址。有三种方式:
直接映像:它把主存空间按Cache大小等分成区,每区内的各块只能按位置一一对应到Cache的相应块位置上。
- 主存地址:主存区号+块号B+块内地址W
- Cache地址:块号b + 块内地址w
- 对应关系:块号B=块号b , 块内地址W = 块内地址 w
全相联映像:主存中的每一页可以映像到Cache中的任意一页。
- 主存地址:块号B+块内地址W
- Cache地址:块号b +块内地址w
- 对应关系:块号B通过地址变换表对应于块号b , 块内地址W = 块内地址 w
组相联映像:是直接映像和全相联映像的折中方案。即组间直接映像,组内全相联映像。
- 主存地址:区号E+组号G+组内块号B+块内地址W
- Cache地址:组号g + 组内块号b + 块内地址w
- 组间是直接映射关系,组内是全相连映射关系
- 对应关系:组号G=组号g,组内块号B通过地址变换表对应于组内块号b , 块内地址W = 块内地址 w
3.9Cache存储器
- 命中率:t3=μ×t1﹢﹙1-μ﹚×t2。其中:μ为Cache的访问命中率(1﹣μ)为未命中率,t1表示Cache的周期时间,t2表示主存储器的周期时间,t3为"Cache+主存储器"的平均周期。
- 使用Cache后提高的倍数: r = t2/t3。
3.10 替换算法
目标就是使Cache获得最高的命中率。常用算法如下:
- 随机替换算法。就是用随机数发生器产生一个要替换的块号,将该块替换出去。
- 先进先出算法。就是将最先进入Cache的信息块替换出去。此法简单但并不能说最先进入的就不经常使用。
- 近期最少使用算法。这种方法是将近期最少使用的Cache中的信息块替换出去。该算法较先进先出算法要好一些。但此法也不能保证过去不常用将来也不常用。
- 优化替换算法。使用这种方法时必须先执行一次程序,统计Cache的替换情况。
3.11局部性理论和Denning的工作集理论
- 虚拟存储管理系统的基础是程序的局部性理论:程序的局部性表现在时间局部性和空间局部性上。时间局部性是指最近被访问的存储单元可能马上又要被访问。空间局部性是指马上被访问的存储单元,其相邻或附近单元也可能马上被访问。
- 根据程序的局部性理论,Denning提出了工作集理论:在进程运行时,如果能保证它的工作集页面都在主存储器内,就会大大减少进程的缺页次数,使进程高效地运行;否则将会因某些工作页面不在内存而出现频繁的页面调入/调出现象,造成系统性能急剧下降,严重时会出现"抖动"现象。
3.12进程状态
- 就绪→运行:条件是被调度程序选中。
- 运行→就绪:条件是时间片到(超时) 或被更高优先级的进程剥夺。
- 运行→等待:条件是不具备运行条件,等待某一事件的发生。
- 等待→就绪:条件是等待的事件已发生,具备了运行条件。
在状态转换中不能由等待态直接进入运行态,也不能由就绪态进入等待态。
3.13进程不发生死锁的条件
系统资源数 = 进程数*(每个进程所需资源数-1)+1。
3.14前趋图
前趋图是一个有向无循环图。
3.15PV操作
生产者和消费者问题。
- 临界资源:诸进程间需要互斥方式对其进行共享的资源,如打印机。
- 临界区:每个进程中访问临界资源的那段程序代码。
- s:信号量;P操作:使S = S-1,若S<0,进程暂停执行,放入信号量的等待队列;V操作:使s = s+1,若s≤0,唤醒等待队列中的一个进程。
- 进入临界区时进行P操作,退出临界区是进行V操作。
3.16进程通信(间接通信)
- 发送信件:如果指定信箱未满,则将信件送入信箱中由指针所指示的位置,并释放等待该信箱中信件的等待者;否则发送信件者被置成等待信箱状态。
- 接收信件:如果指定信箱中有信,则取出一封信件,并释放等待信箱的等待者,否则接收信件者被置成等待信箱中信件的状态进程通信。
3.17存储管理
- 页式存储管理:逻辑地址分为页号+页内地址,页表分为 页号+块号,块号对应内存块号。物理地址 = 块号+页内地址。页内地址由每页的大小决定,如逻辑地址有16K=214,页面大小为2K=211则页内地址为11位,也号为3位。即:P=INTA/L;d=AMOD L.其中逻辑地址为A。页面大小为L页号P,页内地址d。
- 段式存储管理方式:逻辑地址分为 段号+段内地址,段表分为 段号+段长+基址。基址对应内存地址。物理地址 = 基址+段内地址。
- 段页式存储管理方式:逻辑地址分为 段号(s)+段内页号(P)+页内地址(w)。由一个段表和多个(一组页表)组成。物理地址 = 块号+页内地址。在多道环境下,每道程序还需要一个基号作为用户标识。那么物理地址 = (基号+段号+页号)*2n+页内地址。其中2n是将n位的页内地址拼接到后面。
3.18文件系统的主要功能
实现对文件的按名存取,使用打开文件(open)将文件的控制信息从辅存读到内存。
3.19FAT16文件系统中磁盘分区容量
FAT16文件系统中磁盘分区容量=簇的大小×216。
3.20Spooling技术
Spooling技术是用一类物理设备模拟另一类物理设备的技术,实现这种技术的功能模块称做斯普林系统。Spooling系统的特点:
- 提高了I/O速度。
- 将独占设备改造成共享设备。
- 实现了虚拟设备的功能。
四、程序设计基础
4.1程序设计语言的种类
- 逻辑程序设计语言:不需要描述具体的接替过程,只需给出一些必要的事实和规则,作为专家系统的开发工具。
- 函数式程序设计语言:主要用于符号数据处理,如积分演算、数理逻辑、游戏推演和人工智能等领域。
- 面向对象程序设计语言:java、C++。
- 命令式程序设计语言:基于动作的语言,如fortran、pascal和c。
4.2程序语言的基本成分
- 数据成分:常量和变量、全局量和局部量、数据类型。
- 运算成分:
- 控制成分:顺序结构、选择结构和循环结构。
- 函数:函数定义、函数声明、函数调用。
4.3面向对象程序设计语言的基本特征
- 类库是衡量成熟与否的标识。
- 支持继承------与其它语言的主要区别。
- 支持动态性。
- 支持模版操作,具体有函数模版和类模版,即泛型编程。
- 抽象数据对象。
4.4C语言的特点
C语言的特点是过程式程序设计属于静态语言所有成分可在编译时确定。
4.5脚本语言
脚本语言是动态语言,可在运行时可改变不能产生独立的目标程序。
4.6 编写程序时的错误
- 静态错误:分为语法错误和语义错误。
- 动态错误:指源程序中的逻辑错误,发生在程序运行时错误,如除数为0数组下标出界。
五、网络基础
5.1TCP
TCP是第四层(传输层)的传输控制协议;IPSec是第三层(网络层)的VPN协议;PPOE工作于第二层(数据链路层);SSL是工作于TCP协议之上的安全协议。
5.2FTP传输需建立
- 控制连接:文件传输命令,由客户端向服务器端请求。
- 数据连接:文件的传输,主动模式由服务器端主动连接,被动模式服务器等待客户端来连接。
5.3端口号
|-----|--------|---------------|
| 端口号 | 服务进程 | 说明 |
| 20 | FTP | 文件传输协议(数据连接) |
| 21 | FTP | 文件传输协议(控制连接) |
| 23 | TELNET | 虚拟终端网络 |
| 25 | SMTP | 简单邮件传输协议 |
| 53 | DNS | 域名服务器 |
| 80 | HTTP | 超文本传输协议 |
| 110 | POP3 | 邮局协议(简单邮件读取) |
| 111 | RPC | 远程过程调用 |
| 143 | IMAP | 交互式存取协议(报文存取) |
5.4电子商务交易
通过身份认证可以确定一个实体的身份,防止一个实体假装成另一个实体;认证与授权相结合,可以防止他人对数据进行非授权的修改、破坏;保护信息的机密性可以防止信息从被监视的通信过程中泄漏出去。抗抵赖性防止参与此交易的一方否认曾经发生过此次交易
5.5网络安全技术
信息存取的保障有用户的标识和验证、用户存取权限控制、系统安全监控、计算机病毒的防治、数据加密。
- VPN技术:通过隧道将两个内部网络通过公共网络进行连接使其成为一个总体网络。
- 防火墙技术:包过滤防火墙(屏蔽路由器):将路由器放置于内部网络中,网络层安全。应用代理防火墙:也就是双宿主机防火墙,应用层安全。状态检测技术防火墙:以上两种技术的综合,屏蔽路由器置于外部网络,双宿主机置于内部网络。屏蔽子网防火墙:设置DMZ(非军事区)由屏蔽路由器和双宿主机构成。
5.6多模光纤的特点
成本低、宽芯线、聚光好、耗散大、低效,用于低速短距离的通信。单模光纤的特点是:成本高、窄芯线、需要激光源、耗散小、高效,用于高速长距离的通信。
5.7ping命令
判断用户与外部站点的连通性,一、ping127.0.0.1(本地循环地址),无法ping则说明本机TCP/IP协议不能正常工作,二、ping+本机IP不通则说明网络适配器(网卡/MODEM)出现故障,三、ping+同一网段计算机的IP不通则说明网络线路出现故障;netstat命令:用于显示TCP、UDP、IP、ICMP协议相关统计数据,一般用于检验本机网络端口的连接情况;ARP命令:可以查看和修改本地计算机的ARP表项,和查看ARP缓存和解决地址解析问题非常使用。Tracert命令:可以跟踪网络连接,Tracert(路由跟踪)是路由跟踪程序,用于确定IP数据报访问目标所采取的路径,可以查看哪段路由出现连接问题。
5.8DHCP(动态主机配置协议)
用于网络中的主机动态分配IP地址,默认情况下客户机采用最先达到的DHCP服务器分配的IP地址。
5.9Internet协议
- TCP/IP协议:是Internet协议的核心协议,基本特性(逻辑编址、路由选择、域名解析协议、错误检测和流量控制)。
- ARP(地址解析协议)和RARP(反地址解析协议)。ARP将IP地址转换为物理地址(MAC地址)。
5.10网络设计原则
- 先进性:采用先进的技术。
- 实用性:采用成熟可靠的技术和设备达到使用有效的目的。
- 开放性:网路系统采用开放的标准和技术。
- 经济性:在满足需求的基础上尽量节省费用。
- 高可用/靠性:系统具有很高的平均无故障时间,如:金融、铁路证券等。
六、多媒体基础
6.1衡量声音特性的属性(三要素)
- 音量:也叫音强,衡量声音的强弱程度。
- 音调:声音频率。
- 音色: 由混入基音的泛音决定。
6.2声音的带宽
声音信号的频率范围。
- 人耳能听到(其它声音)的音频范围:20HZ~20KHZ
- 人的说话声音音频范围:300~3400HZ
- 乐器的音频范围:20HZ~20KHZ
6.3声音信号的数字化
取样量化法
- 采样:信号测量记录。注:语音信号的采样频率一般为8KHz,音乐信号的采样频率则应该在40KHz以上。
- 数字信号是离散的,模拟信号是连续的。
- 量化(数模转换):A/D转换
6.4图形图像的区别
图形放大不会失真,图像放大会失真。
6.5色彩的三要素
- 亮度:明亮程度的感觉。
- 色调:反映的是颜色的种类。
- 饱和度:颜色的纯度,即掺入白光的程度,颜色的鲜明程度。
6.6彩色空间
- RGB彩色空间:计算机。红黄绿
- CMY彩色空间:打印。青、品红、黄
- YUV彩色空间:电视。
6.7图像文件的大小计算

6.8音频文件的大小计算
- 未经过压缩的:数据传输率(b/s)=采样频率(Hz)*量化位数(采样位数)(b)*声道数(如果求的是字节则应再除以8)
- 经过数字化后所需的存储空间(容量):声音信号数据量=数据传输率(b/s)*持续时间/8(B)
6.9视频文件的大小计算
- 存储容量的(字节数)=每帧图像的容量(B)*每秒帧数*时间注:每帧图像的容量(B)与图像文件容量计算方式一样。
- 播放时的传输速率=每张图像的容量*每秒传输的图像数
6.10常见视频标准
- MPEG-1:MPEG-1层1是对复合编码如: 数字盒式录音带;MPEG-1层2是对视频编码如: DAB,VCD;MPEG-1层3 是对音频进行编码,如Internet,MP3音乐;层4是用来检查。数字电视标准。
- MPEG-2:对交互式多媒体的应用。DVD,数字电视标准。
- MPEG-4: 多种不同的视频格式,虚拟现实、远程教育和交互式视频等的应用。多媒体应用的标准。
- MPEG-7: MPEG-7并不是一种压缩编码方法,其正规的名字叫做多媒体内容描述接口,其目的是生成一种用来描述多媒体内容的标准,这个标准将对信息含义的解释提供一定的自由度,可以被传送给设备和电脑程序,或者被设备或电脑程序查取。
- MPEG-21: "多媒体框架"或"数字视听框架",它以将标准集成起来支持协调的技术以管理多媒体商务为目标,目的就是理解如何将不同的技术和标准结合在一起需要什么新的标准以及完成不同标准的结合工作。
- CIF视频格式的图像分辨率为:352*288(常用标准化的图像格式);QCIF:176*141;DCIF:528*384
- MPEG-1编码器输出视频的数据率为15Mbps;PAL制式下其图像的分辨率为352×288,帧速率为25帧/秒。
6.11图像文件格式
- 静态格式:GIF/BMP/TIF/PCX/JPG/PSD
- 动态格式:AVI/MPG/AVS
- 目前图像使用的编码和压缩标准:JPEG/MPEG/H.261
6.12音频格式
- WAVE/MOD/MP3(MPEG-1的第三层)/REAL AUDIO/MIDI/CD AUDIO
- 音频文件通常分为声音文件和MIDI文件。声音文件是通过声音录入设备录制的原始声音;MIDI是一种音乐演奏指令序列,相当于乐谱,由电子乐器进行演奏,不包含声音数据,文件较小。
6.13压缩技术
- 多媒体数据中存在的冗余:时间冗余、空间冗余、视觉冗余、信息熵冗余、结构冗余、知识冗余。
- 视频图像压缩技术基本思想和方法:在空间上,图像数据压缩采用JPEG压缩方法来去除冗余信息,主要方法包括帧内预测编码和变换编码;在时间上,图像数据压缩采用帧间预测编码和运动补偿算法来去除冗余信息。
- 无损压缩也叫冗余压缩法或是熵编码法;有损压缩也叫熵压缩法。区别是无损压缩可以还原。霍夫曼编码和行程编码方法属于无损压缩,而预测编码、变换编码和运动补偿属于有损压缩。
- 熵编码:熵编码即编码过程中按熵原理不丢失任何信息的编码,常见的熵编码有:LZW编码、香农(Shannon)编码、哈夫曼(Huffman)编码和算术编码(arithmetic coding)。
七、数据库技术基础
7.1数据库(DB)
数据库(DB)是指长期存储在计算机内的,有组织的,可共享的数据的集合。
7.2数据库系统(DBS)
数据库系统(DBS)由数据库、硬件、软件和人员组成。
7.3数据库技术的发展
- 人工管理阶段
- 文件管理阶段
- 数据库系统阶段(有较高的数据独立性)
7.4数据模型的三要素
- 数据结构
- 数据操作
- 数据的约束条件
7.5数据操作
的DDL语言(CREATE/ALTER/DROP/完整性约束)、DML语言(SELECT/INSERT/DELETE/UPDATE);对权限的操作有DCL语言。
7.6数据模型分
概念数据模型(E-R模型)和基本数据模型(层次、网状、关系模型)和目前提出的对象模型。
7.7实体属性
- 简单属性(不可再分)和复合属性(可分如地址(省份、市...))
- 单值属性(只有一个值)和多值属性(如电话号码可有多个)
- NULL属性(没有或是未知)
- 派生属性(从其他属性可推出来)
7.8E-R法的构件

7.9扩充的E-R模型
- 弱实体(要依赖另一个实体而存在)
- 特殊化
7.10数据库系统的体系结构
- 三级模式结构(三层两映像):数据物理独立性、数据逻辑独立性
- 集中式数据库系统:两段提交协议:封锁阶段(扩展阶段)和解锁阶段(收缩阶段)
- 客户/服务器数据库体系结构
- 并行数据库系统(多个CPU):共享内存式多处理器、无共享式并行体系结构
- 分布式数据库系统:两段提交协议:表决阶段和执行阶段
- Web数据库
7.11 全码
指关系模型中所有的属性组是这个关系模式的候选键。
7.12数据库的控制功能
*事物管理(不可分割的逻辑工作单位)
- 原子性:要么都做要么都不做
- 一致性:只包含成功提交的是事物
- 隔离性:多个事物并发执行时是相互隔离的
- 持久性:一旦事物成功提交则永久的反应到数据库中
*故障恢复
- 事物内部故障
- 系统故障
- 介质故障
- 计算机病毒
- 恢复方法:静态转存和动态转存、海量转存和增量转存、日志文件
- 事物恢复步骤:反向扫描文件日志、对事物的更新操作执行逆操作、继续反向扫描日志文件,直到事物的开始标志
- 数据库镜像
*并发控制
- 并发操作带来的问题:带来数据的不一致性(丢失更新、不可重复读和读脏数据);破坏了事物的隔离性。
- 并发控制的技术:封锁,排他锁(X锁)和共享锁(S锁)
- 三级封锁协议:一级:解决丢失更新;二级:解决读脏数据;三级:解决不可重复读
- 并发调度的可串行性:可串行化是并发事物正确性准则,当且仅当可串行化时才是正确的并发调度
- 封锁的粒度:封锁的范围
- 事物是不能嵌套的,因为违背了事物的原子性;当且仅当当前没有事物执行时才能开始执行事物。
*安全性和授权
- 安全性违例(未经授权读取、修改、破坏数据)
- 授权:
read:允许读取,不许修改
insert:允许插入,不许修改
update:允许修改,不许删除
delete:允许删除
index:允许创建或删除索引
resource:允许创建新关系
alteration:允许添加或删除关系中的属性
drop:允许删除关系
7.13事物的执行状态
- 活动状态:事物的初始状态。
- 部分提交状态:全部执行完。
- 失败状态:由于硬件或是逻辑上的错误,使事物不能在继续进行,处于失败状态的事物必须回滚。然后事物就进入了中止态。
- 中止状态:事物回滚并数据库恢复到开始执行前的状态。
- 提交状态:当事物成功完成后,事物处于提交状态,只有事物处于提交状态,才能说明事物已经提交。
7.14事物的隔离级别(高到低)
- 可串行化(读幻影):SERIALIZABLE
- 可重复读:REPEATABLE READ
- 读提交数据:READ COMMITTED
- 可以读未提交数据:READ UNCOMMITTED
- SQL语句定义:SET RANSACTION SOLATON LEVEL a)/b)/c)/d)
- 幻影现象:同一事物对数据对象的两次访问得到的数据记录不同,不可重复读问题
7.15数据仓库
- DW的基本特性:面向主题的、数据是集成的、数据是先对稳定的、数据是反映历史变化的(时限一般5~10年)。
- 数据模式------事实表,多维数据模式包括(星型模式、雪花模式、事实星状模式)。
- 数据仓库体系结构:通常采用:数据仓库服务器、OLAP(联机分析处理)、前端服务器;从结构的角度:企业仓库、数据集市、虚拟仓库。
7.16数据仓库的设计
- 数据仓库的数据模型与操作行数据库的区别:不包含纯操作型的数据;扩充了码结构,增加了时间属性作为码的一部分;增加了一些导出数据。
- 数据仓库的物理设计:主要提高I/O性能,通过粒度划分和数据分割来提高系统的性能。
7.17数据挖掘技术
海量数据搜集、强大的多处理计算机和数据挖掘算法。
7.18数据挖掘中常用的技术
人工神经网络、决策树、遗传算法、近邻算法和规则推倒。
7.19数据挖掘的应用过程
- 确定挖掘对象
- 准备数据(数据挖掘工作量的60%),包括1数据选择;2数据预处理(清洗);3数据转换。
- 建立模型
- 数据挖掘
- 结果分析
- 知识应用
7.20数据转储
DBA定期地将整个数据库复制到磁带或另一个磁盘上保存起来的过程。
- 动态转储: 指转储期间允许对数据库进行存取或修改。即转储和用户事务可以并发执行。
- 静态转储:在系统中无运行事务时进行的转储操作。
- 增量转储:指每次只转储上一次转储后更新过的数据。
- 海量转储:指每次转储全部数据库。
- 从恢复角度看,使用海量转储得到的后备副本进行恢复一般说来会更方便些。但如果数据库很大,事务处理又十分频繁,则增量转储方式更实用更有效。
7.21OLAP(联机分析处理)
通常用于对数据仓库进行数据挖掘;OLTP(联机事物处理)是面向事物程序的执行,通常对应密集型更新事物的程序,应用于对数据库的操作。OLAP没有严格的时间要求,OLTP是面向业务的,对时效要求比较高。OLAP用于数据挖掘以提供决策支持,OLTP用于具体的业务。
八、关系数据库
8.1关系模型
关系模型是关系数据库的基础,由关系数据结构、关系操作集合和关系完整性规则组成。
8.2关系的度
关系的度是指关系中属性的个数,关系的势指关系中元组的个数。
8.3原子数据
在关系模型中所有的域都应该是原子数据(1NF)。
8.4关系的三种类型
基本表、查询表、视图表
8.5完整性约束
实体完整性、参照完整性、用户定义完整性。
8.6运算要求
在关系代数中对传统的的集合运算要求参与运算的关系具有相同的度且对应属性取自同一个域。
8.7关系运算
- 关系代数语言
- 关系演算语言
- 具有以上两种双重特点的语言(SQL)
8.8关系代数中的查询优化准则
- 尽可能早的执行选择运算
- 尽可能早的执行投影运算
- 避免直接做笛卡尔乘积,把笛卡尔乘积之前的操作和之后的一连串选择和投影合并起来一起做。
8.9关系模式的设计问题
- 数据冗余:同一数据重复出现多次。
- 操作异常(更新异常):修改异常、插入异常和删除异常。
- 规范化的一个原则:"关系模式有冗余问题,就分解它"。
8.10关系模式的非形式化设计准则
- 关系模式的设计尽可能只包含直接联系的属性,不要包含有间接联系的属性。
- 尽可能的不出现插入、删除和操作异常。
- 尽可能的避免放置经常为空值的属性。
- 尽可能的使等值连接在主键和外键上进行,并保证不会产生额外的元组。
8.11函数依赖
- 平凡的函数依赖:如果X→Y,Y包含于X则称X→Y是平凡的函数依赖
- 如果函数依赖集的闭包相等则函数依赖相等。
- 若存在FD W→A,如果W的任一个子集X没有X→A,则称W→A是完全函数依赖。否则叫局部函数依赖。
- 传递函数依赖:如果X→Y,Y→A,且Y不→X, A不∈Y,则X→A是传递函数依赖。
- FD和关键码:设模式R的属性集U,X是U的一个子集,如果X→U在R上成立,那么X是R的一个超键。如果X→U在R上成立,但是对于任一真子集X1都有X1→U不成立,那么X是R的一个候选键。
- 如果A是关系模式R中的候选键中的属性,那么称A是R的主属性,否则是非主属性。
- 最小函数依赖:(不包含多余的函数依赖)满足一下三个条件(最小函数依赖集G):G中的每个FD的右边都是单属性。G中没有冗余的FD。G中的左边没有冗余的属性。
8.12关系模式的范式---规范化
- 1NF:如果关系R的每个关系r的属性值都是不可分的原子值。(规范化关系);1NF存在的问题:冗余度大和更新异常。
- 2NF:如果每个非主属性完全函数依赖于候选键。
- 3NF扶沟每个非主属性都不传递依赖R的候选键。
- BCNF:如果每个属性都不传递函数依赖与R的候选键。
- 4NF:设R是一个关系模式,D是R上的多值依赖函数,如果D中成立非平凡多值依赖X→→Y时(即X、Y在D中),X必是超键,那么R是4NF。
8.13关系模式R分解成2NF模式集
如果关系模式R中,存在FD W→Z,X→Z,X⊆W,其中w是主键,Z是非主属性,则有W→Z是局部函数依赖。分解成R1(XZ),主键是X;R2(Y),Y=U-Z,主键是W,外键是X。
8.14将模式R分解成3NF
如果关系模式R中,存在FD W→Z,X→Z,X不是候选键,其中w是主键,Z是非主属性,Z不⊆X,则有W→Z是传递依赖。分解正R1(XZ),主键是X,R2(Y),Y=U-Z,主键是W,外键是X。
8.15模式的分解有三种等价情况
- 分解具有无损连接性
- 分解要保持函数依赖
- 分解既要无损连接又要保持函数依赖
8.16无损分解的充要条件是
如果p(R1,R2)是R的一个分解则要满足:(R1∩R2)→(R1-R2)或是(R1∩R2)→(R2-R1),或是R1∩R2是R1或是R2的超键,则是无损分解。
8.17保持函数依赖
设p(R1,R2... Rk)是R的一个分解,F是R上FD,如果有 则保持函数依赖。
则保持函数依赖。
8.18无损连接的测试
设关系模式R=A1,...,An,R上成立的FD集F,R的一个分解p={R1,...,Rk}。无损连接分解的判断步骤如下:
- 构造一张k行n列的表格,每列对应一个属性Aj(1≤j≤n),每行对应一个模式Ri(1≤i≤k)。如果Aj在Ri中,那么在表格的第i行第j列处填上符号aj,否则填上符号bij。
- 把表格看成模式R的一个关系,反复检查F中每个FD在表格中是否成立,若不成立,则修改表格中的元素。修改方法如下:对于F中一个FD:X→Y,如果表格中有两行在X分量上相等,在Y分量上不相等,那么把这两行在Y分量上改成相等。如果Y的分量中有一个是aj,那么另一个也改成aj;如果没有aj,那么用其中的一个bij替换另一个(尽量把ij改成较小的数,亦即取i值较小的那个)。
- 若在修改的过程中,发现表格中有一行全是a,即a1,a2,...,an,那么可立即断定p相对于F是无损连接分解,此时不必再继续修改。若经过多次修改直到表格不能修改之后,发现表格中不存在有一行全是a的情况,那么分解就是有损的。特别要注意,这里有个循环反复修改的过程,因为一次修改可能导致表格能继续修改。
8.19候选关键字的判断
- L类属性:只在函数依赖的左半部出现的属性;R类属性:只在函数依赖的左半部出现的属性;LR类属性,出现在函数依赖左右两边的属性;N类属性,两边都没出现的属性。
- 将关系模式R中的所有属性分为以上四类,用X表示L、N两类,用Y表示LR类。求X+,若X+包含关系模式的全部属性,则X为R唯一的候选键,否则下一步。在Y中取一属性A,求(XA)+,若包含R的全部属性,则转下一步,否则换另一个属性。若找到所有的候选键则结束,否则在Y中取两个、三个...,求他们属性的闭包,直到求出所有的候选键。
九、SQL语言
9.1建立基本表
- CREATE TABLE C (C# CHAR(4) NOT NULL UNIQUE / NOT NULL PRIMARY / PRIMARY KEY, CNAME CHAR(10) NOT NULL)
- CREATE TABLE C (C# CHAR(4), CNAME CHAR(10) NOT NULL, PRIMARY KEY(C#))
- 定义外键时,可以合起来写:T# CHAR(4) FOREIGN KEY(T#) REFERENCES T(T#),也可以分两行写T# CHAR(4) , FOREIGN KEY (T#) REFERENCES T(T#),
9.2删除
定义级联删除在定义B表外键(A表的主键)属性时加上ON DELETE CASCADE。此时删除A表的主键时,其主键在相应表中是外键(B表的外键)会被同时删除。也可以定义触发器。
9.3基本表的修改
- 增加新的列:ALTER TABLE<基本表名>ADD<列名><类型>{可设置缺省值0,------DEFAULT=0}
- 删除列:ALTER TABLE<基本表名>DROP COLUMN<列名>完整性约束条件CASCADE\|RESTRICT
- 修改数据类型:1ALTER TABLE<基本表名>ALTER COLUMN<列名><类型>2ALTER TABLE<基本表名>MODIFY<列名><类型>
9.4基本表的撤销
DROP TABLE<基本表名>CASCADE\|RESTRICT。
9.5数据删除
DELETE FROM <基本表名> WHERE <条件表达式>。
注:CASCADE表示所有约束和视图也自动删除,RESTRICT表示没有视图和约束时才能删除。
9.6数据修改
UPDATE<基本表名> SET<列名> = <值表达式> WHERE<条件表达式>。
9.7创建索引
- 索引的作用:通过创建唯一的索引,可以保证数据的唯一性;提高数据的检索速度;可以加速表与表之间的连接,对于实现数据的参照完整性有很重要的意义;使用ORDER BY和GROUP BY 检索时可减少查询中组和排序的时间。
- 聚簇索引对表的物理数据页中的数据按列进行排序,然后再重新存储到磁盘上,即聚簇索引与数据是混为一体的,它的也节点中存放的是实际的数据。
- 非聚簇索引是具有完全独立于数据行的结构,不用将物理数据页中的数据按列排序,节点中存放的是索引的关键字值和行定位置。
- 创建索引:CREATE UNIQUECLUSTERE INDEX<索引名>ON<基本表名>(<列名DESCASC>, <列名DESCASC>,....)
- 删除索引:DROP INDEX<索引名>,<索引名>,...
9.8视图的操作
- 视图是建立在查询的基础上的,是一张虚拟表,视图的数据必不是按视图存储结构保存在数据库中,而是存储在视图所引用的表中。
- 视图的优缺点:视图更新数据实时、安全、存储空间只占用代码的空间,但是执行过程有些慢。
- 视图的创建:CREATE VIEW<视图名>(<列名序列>)AS <SELECT 查询语句>WITH CHECK OPTION 。注:子查询(SELECT语句)中通常不允许出现ORDER BY子句和DISTINCT。WITH CHECK OPTION允许用户更新视图。其中列名要么全部省略要么全部指定。
- 视图删除:DROP VIEW<视图名>
- 视图更新(只有行列子集视图(视图是从单个基本表只使用选择、投影操作导出的))
视图更新必须遵循以下规则:
(1)从多个基本表通过连接操作导出的视图不允许更新
(2)对使用了分组函数操作的视图不允许进行更新操作。
(3)如果视图是从单个本表通过影选取作导出的则允许进行更新操作,且语法同基本表。
9.9数据定义语言(DDL)
CREATE、ALTRE、DROP;数据操作语言(DML):SELECT、INSERT、DELETE、UPDATE;数据控制语言(DCL):约束权限。
9.10查询语句

9.11UNION 操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。如:SELECT column_name(s) FROM table_name1 UNION SELECT column_name(s) FROM table_name2
9.12字符使用
sname like'王%'匹配'王'后面任意个字符;sname like'王_'匹配'王'后面一个字符;如果模式中包含特殊字符就要用到转意符,用关键字escape来定义,如:
- Like'ab\%cd%'escape'\', 匹配所有以ab%cd开头的字符串。
- Like'ab\\cd%'escape'\',匹配所有以ab\cd 开头的字符串。
9.13SQL中完整性约束
越约束:定义一个新域COLOR
- CERATE DOMAIN COLOR CHAR(6) DEFAULT'???'---将颜色默认设置为???
- CONSTRANINT COLORS---表示为这个域约束起名为colors
- CHECK(VALUE IN('Red','Yellow'.'Blue'.'Green',???'))
基本表的约束:主键、外键、检查(CHECK)
断言(ASSERTIONS):
- CERATE ASSERTION<断言名>CHEC0(<条件>)
- DROP ASSERTION<断言名>
9.14SQL中的安全性机制
视图、权限、角色、审计。
9.15SQL中的完整性约束
域约束、基本表约束、断言、触发器。
9.16权限
- 用户权限(6种):select、insert、delete、update、references、usage其中references表示允许用户定义新的关系,引用其它关系的主键做为外键;usage允许用户使用已定义的域。
- 授权语句:GRANT<权限表>ON<数据库元素>TO<用户名表>WITH GEANT OPTION WITH GEANT OPTION表示获得的权限还能获得传递权限,装权限授给别的用户。如:GRANT ALL PRIVILEGES ON TABLE S,P,J TO User1,User2; GRANT INSERT ON TABLE S TO User1 WITH GRANT OPTION;其中ALL PRIVILEGES表示用全部权限(以上6种)。
- 回收语句:REVOKE<权限表>ON<数据库元素>FROM<用户名表>RESTRICT\|CASCADE CASCADE表示连锁回收,RESTRICT不存在连锁回收时才能进行回收。如:REVOKE ALL PRIVILEGES ON TABLE S,P,JFROM User1,User2; REVOKE SELECT ON TABLE S FROM PUBLIC;PUBLIC表示多有当前的或是将来的可能出现的所有用户。
9.17触发器的使用
触发器是一个由系统自动执行的对数据库进行修改的语句。触发器由事件、条件和动作三个部分组成。
- 创建触发器:CERATE TRIGGER <名>
- 删除触发器:DROP TRIGGER <名>
9.18嵌入式SQL
区分SQL语句和主语言语句(格式):EXEC SQL<SQL语句>END_SQL(C语言中用;而不用END_SQL)
主语言工作单元与数据库工作单元的通信:
- SQL通信区(SQLCA):向主语言传递SQL语句执行的状态信息,是主语言能够根据次信息控制程序流程。
- 共享变量(主变量):主语言通过主变量向sql语句提供参数,由主语言定义,sql中DECLARE语句说明。
游标(CURSOR):主语言是面向记录的而sql语言是面向集合的,通过游标可获取多条记录或获取指定的记录。
- 定义游标
- 打开游标
- 推进游标
- 关闭游标
动态SQL语句
- 动态SQL预备语何格式EXEC SQL PREPARE <动态 SQL语名FROM<共享变量或字符串>;
- 动态SQL执行语何格式EXEC SQLEXECUTE 动态 SQL语名>;
9.19存储过程
由SQL语句和流程控制语句编写的模块,经过编译和优化后存储在数据库服务器端的数据库中。具有一下优点:
- 提高运行速度。
- 增强了SQL的功能和灵活性。
- 可降低网络的通信量。
- 减轻了程序编写的工作量。
- 间接实现安全控制功能。
- 屏蔽表的细节,简化用户操作。
十、系统开发与运行
10.1软件生存周期的六个阶段
项目计划、需求分析、设计、编码、测试、运行和维护。
10.2软件开发模型
- 瀑布模型:最早,采用结构化分析与设计方法。
- 演化模型:全局开发模型,也叫快速原型模型。
- 螺旋模型:结合瀑布模型和快速原型模型,增加了风险分析,使用与大型系统。
- 喷泉模型:以用户需求为动力,以对象驱动的模型,采用面像对象开发。
10.3需求分析阶段
需求分析阶段是软件工程的重要阶段,它为一个新系统定义业务需求。需求分析阶段的关键是描述一个系统是什么,或者一个系统必须做什么,而不是系统应该如何实现。具体来说,需求分析阶段需完成以下要求:
- 确定软件系统的功能需求和非功能需求。
- 分析软件系统的数据要求。
- 导出系统的逻辑模型。
- 修正项目开发计划。
- 如有必要,可以开发一个原型系统。
10.4软件设计
软件设计通常可分为概要设计和详细设计。概要设计的任务是确定软件系统的结构、进行模块划分、确定每个模块的功能、接口以及模块间的调用关系。设计软件系统的结构,主要任务是确定模块间的组成关系。
10.5系统测试
系统测试是将软件系统与硬件、外设和网络等其他因素结合在一起,进行信息系统的各种组装测试和确认测试,其目的是通过与系统地需求相比较,发现所开发的系统与用户需求不符或矛盾的地方。常见的系统测试主要有恢复测试、安全性测试、强度测试、性能测试、可靠性测试和安装测试。
10.6软件项目估算
- 代码行、功能点和工作量估算是最基本项目估算内容。
- IBM估算模型:基于代码行的静态单变量模型。
- CoCoMo(构造性成本)模型:分为基本、中级和详细3个级别,将软件项目类型分为组织型、半独立型和嵌入型。
- Putnam模型:动态多变量模型。
10.7风险分析
- 风险识别:性能风险、成本风险、支持风险、进度风险。建立风险条目检查表。
- 风险预测:建立风险表,估计风险对项目的影响。
- 风险评估:进一步审查在风险预测阶段所做的估算的精确度, 试图为所发现的风险排出优 先次序,并开始考虑如何控制和/或避免可能发生的风险。
- 风险控制:风险避免、风险监控、风险管理及监控计划。
10.8进度管理
进度管理(安排)通常使用Grant(甘特图)和PERT(计划评审技术)图。PERT图和Gantt图是两种常用的项目管理工具。PERT(项目评估与评审技术)图是一种图形化的网络模型,描述一个项目中的任务和任务之间的关系。Gantt图是一种简单的水平条形图,它以一个日历为基准描述项目任务。Gantt图中横坐标表示时间(如时、天、周、月、年等),纵坐标表示任务,图中的水平线段表示对一个任务的进度安排,线段的起点和终点对应在横坐标上的时间分别表示该任务的开始时间和结束时间,线段的长度表示完成该任务所需的时间。
10.9Grant
Grant不能反应出个任务之间的依赖关系。
10.10PERT
PERT不能反映任务之间的并行性。
10.11CMM
CMM是对软件组织进化阶段的描述,随着软件组织定义、实施、测量、控制和改进其软件过程,软件组织的能力经过这些阶段逐步前进。CMM将软件过程的成熟度分为5个等级,分别为:
- 初始级。软件过程的特点是杂乱无章,有时甚至很混乱,几乎没有明确定义的步骤,成功完全依赖个人努力和英雄式的核心任务。
- 可重复级。建立了基本的项目管理过程来跟踪成本、进度和机能,有必要的过程准则来重复以往在同类项目中的成功。
- 定义级。管理和工程的软件过程已经文档化、标准化,并综合成整个软件开发组织的标准软件过程。所有的项目都采用根据实际情况修改后得到的标准软件过程来发展和维护软件。
- 管理级。制定了软件工程和产品质量的详细度量标准。软件过程和产品的质量都被开发组织的成员所理解和控制。
- 优化级。加强了定量分析,通过来自过程质量反馈和来自新观念、新技术的反馈使过程能持续不断地改进。
10.12软件开发方法
结构化方法、面向数据结构方法、原型法、对象建模。
10.13软件质量特特性
- 第一层:质量特性
- 第二层:质量子特性
- 第三层:量度指标
10.14系统分析阶段的主要工作
- 对当前系统进行详细调查,收集数据。
- 建立当前系统的逻辑模型
- 对现状进行分析,提出改进意见和新系统应达到的目标
- 建立新系统的逻辑模型
- 编写系统方案的说明书
10.15系统分析的方法
- 结构化分析方法
- 面向对象分析方法
10.16面向数据结构的分析和设计(Jackson)
设计原则是使程序结构与数据结构(问题结构)相对应;以数据结构作为设计基础,根据输入/输出数据结构导出程序结构,使用与规模不大的数据处理系统。
10.17UML
用例图;静态图(类图、对象图、包图);行为图(状态图、活动图);交互图(顺序图、协作图);实现图(构建图、部署图)。
- 类图:展现了一组对象接口、协作和它们之间的关系。在面向对象系统的建模中所建立的圾常见的图就是类图。类图给出系统的静态设计视图。包含主动类的类图给出了系统的静态进程视图。
- 对象图:展现了一组对象以及它们之间的关系。对象图描述了在类图中所建立的事物实例的静态快照。和类图相同,这些图给出系统的静态设计视图或静态进程视图,但它们是从真实的或原型案例的角度建立的。
- 用例图:展现了一组用例参与者(actor)以及它们之间的关系。用例图给出系统的静态用例视图。这些图对系统的行为进行组织和建模是非常重要的。
- 序列图:是场景的图形化表示,描述了以时间顺序组织的对象之间的交互活动。
- 协作图:强调收发消息的对象的结构组织。
序列图和协作图都是交互图(interaction diagram。交互图展现了一种交互,它由组对象和它们之间的关系组成,包括它们之间可能发送的消息。交互图关注系统的动态视图。序列图和协作图是同构的,它们之间可以相互转换。
- 状态图:展现了一个状态机,它由状态、转换、事件和活动组成。状态图关注系统的动态视图,它对于接口、类和协作的行为建模尤为重要它强调对象行为的事件顺序。
- 活动图:是一种特殊的状态图,它展现了在系统内从一个活动到另一个活动的流程。活动图专注于系统的动态视图。它对于系统的功能建模特别重要,并强调对象间的控制流程。
- 构件图:展现了一组构件之间的组织和依赖。构件图专注于系统的静态实现视图。它与类图相关,通常把构件映射为一个或多个类、接口或协作。
- 部署图:展现了运行处理节点以及其中构件的配置。部署图给出了体系结构的静态实施视图。它与构件图相关,通常一个节点包含一个或多个构件。
10.18关系
聚合关系------整体-部分关系;泛化关系------一般-特殊关系。
10.19软件测试
- 白盒测试(结构测试):根据程序内部结构和逻辑结构及相关信息设计测试用例,检查程序中所有逻辑路径是否满足要求。
- 黑盒测试(行为测试):不必考虑程序内部的逻辑结构和内部特性,只需根据程序的需求规格说明书,检查是否满足要求。
10.20CVS
CVS是一种版本控制工具。
十一、数据库设计
11.1数据库系统生命周期
数据库规划、需求分析与收集、数据库设计、数据库系统实现、测试阶段、运行维护
11.2数据字典
是对用户信息要求的整理和描述(需求分析阶段)。包括数据项、数据结构、数据流、数据存储和处理过程。
11.3 需求分析阶段的任务
- 分析用户活动,产生业务流图。
- 确定系统范围,产生系统关联图。
- 分析用户活动涉及的数据,产生数据流图。
- 分析系统数据产生数据字典。
11.4需求分析阶段的成果
需求分析阶段的成果是系统说明书,包括数据流图、数据字典和各种说明性文档等。
11.5数据流图(DFD)
顶层DFD确定系统边界,将待开发的系统看做是一个加工,因此只有唯一一个加工和一些外部实体以及两者之间的输入输出数据流。0层DFD确定数据存储。
11.6面向数据结构的方法(Jackson方法)
- 设计思想:以数据结构作为设计基础,它根据输入/输出数据结构导出程序结构,适用于规模不大的数据处理系统。
- 基本思想:从问题的数据结构导出它的程序结构.作为独立的系统设计方法主要用于小规模数据处理的开发。
- 考虑问题的出发点是:数据结构。
- 最终目标:得出程序的过程性描述。
- 最佳适用范围:详细设计中,确定部分或全部模块的逻辑过程。
- 遵守结构程序设计"由顶向下"逐步细化的原则,并以其为共同的基础; "程序结构必须适应问题结构" 的基本原则,各自拥有从问题结构(包括数据结构)。
- 服从导出程序结构的一组映射规则。
11.7画DFD的注意事项
- 应适当的为数据流、加工、数据存储以及外部实体命名,名字应该反映该成分的实际含义,避免使用空洞的名字。
- 画数据流图,不是画控制流。
- 一个加工的输出数据流,不应与输入数据流同名,及时他们的组成完全相同。
- 允许一个加工有多条数据流流向另一个加工,也允许一个加工有两条相同的输出数据流流向不同的加工。
- 保持父图与子图的平衡。也就是说,父图中的某加工的输入输出流必须与他的子图的输入输出数据流在数量上和名字上相同。值得注意的是,如果父图中的一个输入(输出)数据流对应于子图中的几个输入(输出)数据流,而子图中组成这些数据流的数据项的全体正好是父图中的这一个数据流,那么他们仍然算是平衡的。
- 在自顶向下的分解过程中,若一个数据存储首次出现时,只与一个加工有关系,那么这个数据存储应作为这个加工的内部文件而不必画出。
- 保持数据守恒,也就是,一个加工的所有输出数据流中的数据必须能从该加工的输出流中直接获得,或者通过该加工能产生的数据。
- 每个加工必须既有输入数据流,又有输出数据流。
- 在整套数据流图中,每个数据存储必须既有读的数据流,又有写的数据流。但是在某张子图中,可能只有读没有写,或者只有写没有读。
- 数据流必须通过加工(也就是外部实体与外部实体,外部实体与数据存储之间不能存在数据流)。
11.8概念设计阶段------E-R图
对现实事物的抽象的三种方法:分类(固有的共同特征和行为,如:学生和教师是不通的分类)、聚集(定义某一类型的所具有的属性,如:学生的学号、姓名等)和概括(由已知类型定义一个新的类型,即得到一个子类,如:研究生是学生的子类,从学生类型中延伸出来)。
用E-R图建立概念模型:
- 进行数据抽象:根据数据流图使用以上三种抽象方法进行抽象,从高层(对数据的引用笼统)到低层(比较细致)。
- 设计局部概念模型:确定局部应用中的实体、实体的属性、实体标识符和实体间的联系。注意:1)属性不可再分;2)属性不能与其它实体之间有直接联系。
- 将局部模型综合成全局模型:其中要消除冲突,属性冲突(类型等)、结构冲突(抽象不同、属性组成不同等)和命名冲突(实体名、属性名和联系名等)。
- 全局ER模型的优化:合并实体类型、消除冗余属性、消除冗余联系。
11.9逻辑设计阶段------E-R图向关系模式的转换
逻辑设计阶段的主要任务:确定数据模型、将ER模型转换为制定的数据模型、确定完整性约束、确定用户视图。
E-R图向关系模式的转换(转换成计算机能识别的):
- 实体类型的转换:将每个实体类型转换成关系模式,实体名对应模式名,属性对应模式的属性,实体标识符对应模式的键。
- 联系类型的转换(二元联系):1若实体间的联系是1 :1的,在转换好的两个关系模式中任意一个模式的属性中加入另一个的主键(作为当前模式的外键)和联系的属性。2若实体类型之间的联系是1 :N,则在N端转换来的模式中加入1端实体类型的主键(作为当前模式的外键)和联系的属性。3若实体间的联系是M:N,则将联系类型也转换成关系模式,其属性为实体两端的实体类型的键加上联系类型的实行,主键为两端实体的之间的组合(同时两个主键也是外键)。
- 三元联系的转换:1若实体间的联系是1:1:1,则转换得的3个模式中任意一个中加入另外两个的主键(作为当前模式的外键)和联系类型的属性。2若实体间的联系是1:1:N,则在N端加入两个1端的主键(作为当前模式的外键)和联系类型的属性。3若实体间的联系是1:N: M,则联系类型也要转换成关系模式,其属性为M端和N端的实体类型的主键(作为外键)加上联系类型的属性,主键为M和N端的主键的组合。4若实体间的联系是M:N:P,则联系类型也转换成关系模式,其属性为三端实体类型的主键(作为外键)加上联系类型的属性,而主键为三端实体主键的组合。
关系模式的规范化
- 根据语义确定关系模式都的数据依赖。
- 根据数据依赖确定关系模式的范式。
- 如果不符合要求则根据模式的分解算法进行分解到达3NF、BCNF或是4NF。
- 关系模式的评价与修正。消除冗余更新异常等。
确定完整性约束。
确定用户视图(设计子模式)。提高数据的安全性和独立性。
11.10物理设计阶段
物理设计阶段------数据库的存储结构和存取方法(确定数据分布、确定存储结构、确定存取方式)
- 存储记录的结构设计
- 确定数据的存放位置
- 存取方法的设计
- 完整性和安全性的考虑
- 程序设计
11.11数据库的实现
- 用DDL定义数据库的结构
- 组织数据入库
- 编制与调试应用程序
- 数据库试运行
11.12数据库的安全性措施
- 权限机制
- 视图机制
- 数据加密
11.13在绘制数据流图的加工时可能会出现输入和输出错误
- 只有输入没有输出或者是黑洞;
- 只有输出没有输入或者是奇迹
- 输入的数据流无法通过加工产生输出流活着是灰洞
- 输入的数据流与输出的数据流名称相同
11.14数据库的并发控制
- 并发操作带来的问题:数据的不一致性(丢失修改、读脏数据和不可重复读问题)。
- 解决问题的方法:从保证事物的隔离性入手。
- 解决问题的焦点:事物在读取数据时不加控制而相互干扰。
- 封锁协议:两段封锁协议,缩短了持锁时间,提高了并发度,同时解决了数据的不一致性。为了事物并发调度的正确使用两段封锁协议。
- 可串行化(性)是并发事物的正确性准则。
11.15类图是显示
类图是显示一组类、接口、协作以及它们之间关系的图。类图用于对系统的静态设计视图建模。当对系统的静态视图建模时,通常以下述3种方式之一使用类图。
- 对系统的词汇建模。
- 对逻辑数据库模式建模。将模式看作为数据库的概念设计的蓝图。在很多领域中,要在关系数据库或者面向对象数据库中存储永久信息,可以用类图对这些数据库的模式建模。
- 对简单协作建模。
11.16状态图
状态图显示一个由状态、转换、事件和活动组成的状态机。用状态图说明系统的动态视图。状态图对接口、类或协作的行为建模是非常重要的。状态图强调一个对象按事件次序发生的行为。
11.17活动图
活动图显示从活动到活动的流。活动图显示了一组活动,从活动到活动的顺序的或分支的流,以及发生动作的对象或动作所施加的对象。用活动图说明系统的动态视图。活动图对系统的功能建模是非常重要的。活动图强调对象之间的控制流。
十二、网络与数据库
12.1分布式数据库
分布式数据库应该有场地透明性和分散存储两个特点。
12.2完全分布式式数据库应满足
- 分布性
- 逻辑相关性
- 场地透明性
- 场地自治性
12.3分布式数据库的特点
- 数据的集中控制性
- 数据独立性
- 数据冗余可靠性
- 场地自治性
- 存取的有效性
12.4分布式数据库的体系结构
四层模式结构------全局外层、全局概念层、局部概念层、局部内层。
12.5分布式事务
分布式事务有两段提交协议(2PC)和三段提交协议(3PC)。
- 2PC:协调者和参与者,只有协调者才有提交和撤销事务的表决权,其步骤是先表决后执行。
- 3PC:在2PC的基础上增加了全局预提交和准备两个报文,确认所有参与者的状态。
- 分布式事务故障比集中式事务故障多了通信故障(介质故障、系统故障、事务故障)。
12.6分布式数据库的透明性
- 分布透明性:用户不必关心数据的逻辑分区和数据的物理位置分布的细节及不必关心数据一致性的问题和局部数据库支持的数据模型。
- 分片透明性:用户不必关心数据的逻辑分片。
- 位置透明性:用户不必关心数据物理位置分配的细节。
- 复制透明性:用户不必关心数据库在网路中各个结点的复制情况,被复制的数据更新由系统自动完成。
- 局部数据模型透明性:不必关心局部数据使用的何种数据模型。
12.7XML和数据库之间传输数据
模版驱动和模型驱动。
十三、数据库发展趋势及新技术
13.1数据转移技术
数据仓库中数据转移的的目的有:改进数据仓库中数据的质量和提高数据仓库中数据的可用性。
数据转移类型:
- 简单转移:简单转移是所有数据转移的基本单元。
- 清洗:为了保证前后一致地格式化和使用某字段或是字段群。
- 集成:将业务数据从一个或几个来源取出,并逐字段的将数据映射到数据仓库的新数据结构上。
- 聚集和概括:从业务环境中找到零星的数据压缩成数据仓库中的较少数据块。
13.2面向对象数据库
面向对象数据库引入了数组(集合)类型和结构类型两种构造数据类型。将组合属性(如日期)转换为结构类型,多值属性转换为集合类型。
13.3并行数据库的目标
实现高性能、高可用性、可扩充性。
13.4并行数据库的体系结构
- 共享内存结构
- 共享磁盘结构
- 无共享资源结构(具有独领的处理器、内存和磁盘)
13.5对象-关系数据库系统
- 引用类型:ref
- 继承类型:under
- 复合类型:setof
- 嵌套关系
13.6企业资源计划发展
企业资源计划发展经历了基本MPR、闭环的MPR、MPR-Ⅱ和ERP,其中基本的MPR着重管理企业的物料需求计划,闭环的MPR强调了生产能力对需求计划的影响,MPR-Ⅱ阶段的时候围绕着企业的基本经营目标,以生产计划为主线,ERP理论以一个中心(以盈利为中心),两类业务(计划和执行)和三条干线(供应链管理、生产管理和财务管理),并将三条干线紧密结合在一起。
13.7决策支持系统(DSS)
决策支持系统(DSS)由数据库子系统、模型库子系统、人机交互系统(模型库与数据库的有机结合)、用户构成。DSS增加了模型库和模型库管理系统。在DSS的基础上增加知识库子系统(包含知识库和推理机+)形成智能DSS。
十四、知识产权基础
14.1保护期限
|--------------|----------------------------------------------|------------------------------------------------|
| 客体类型 | 权力类型 | 保护期限 |
| 公民作品 | 署名权、修改权、保护作品完整权 | 没有限制 |
| 公民作品 | 发表权、使用权和获得报酬权 | 作者终生及其死亡后的50年(第50年的12月31日) |
| 单位作品 | 发表权、使用权和获得报酬权 | 50 年(首次发表后的第50年的12月31 日),若其间未发表,不保护 |
| 公民软件 产品 | 署名权、修改权 | 没有限制 |
| 公民软件 产品 | 发表权、复制权、发行权、出租权、信 息网络传播权、翻译权、使用许可权、获得报酬权、转让权 | 作者终生及其死亡后的50年(第50年的 12月31日)对于合作开发的,则以最后死亡的作者为准 |
| 单位软件产品 | 发表权、复制权、发行权、出租权、信 息网络传播权、翻译权、使用许可权、获得报酬权、转让权 | 著作权的保护期为50年(首次发表后的第50年的12月31日),若50年内未发表的,不予保护 |
| 注册商标 | | 有效期是10年(若注册人死亡或倒闭1年后,未转移则可注销,期满后6个月内必须续注) |
| 发明专利权 | | 保护期为20年(从申请日开始) |
| 实用新型和外观设计专利权 | | 保护期为10年(从申请日开始) |
| 商业秘密 | | 不确定,公开后公众可用 |
14.2知识产权的时间性概念
知识产权具有法定的保护期限,一旦保护期限届满,权利将自行终止,成为社会公众可以自由使用的知识。至于期限的长短,依各国的法律确定。我国发明专利的保护期为20年,实用新型专利权和外观设计专利权的期限为10年,均自专利申请日起计算;我国公民的作品发表权的保护期为作者终生及其死亡后50年。我国商标权的保护期限自核准注册之日起10年,但可以根据其所有人的需要无限地续展权利期限,在期限届满前6个月内申请续展注册,每次续展注册的有效期10年,续展注册的次数不限。如果商标权人逾期不办理续展注册,其商标权也将终止。商业秘密受法律保护的期限是不确定的,该秘密一旦为公众所知悉,即成为公众可以自由使用的知识。
14.3知识产权人的确定
|------|------|----------------------------------------------|---------------------------|
| 情况说明 || 判断说明 | 归属 |
| 作品 | 职务作品 | 利用单位的物质技术条件进行创作,并除署名权外其他著作权归单位 由单位承担责任的 | 除署名权外其他著作权归单位 |
| 作品 | 职务作品 | 有合同约定,其著作权属于单位 | 除署名权外其他著作权归单位 |
| 作品 | 职务作品 | 其他 | 作者拥有著作权,单位有权在业 务范围内优先使用 |
| 软件 | 职务作品 | 属于本职工作中明确规定的开发目标 | 单位享有著作权 |
| 软件 | 职务作品 | 属于从事本职工作话动的结果 | 单位享有著作权 |
| 软件 | 职务作品 | 使用了单位资金、专用设备、未公开的 信息等物质、技术条件,并由单位或组 织承担责任的软件 | 单位享有著作权 |
| 作品软件 | 委托创作 | 有合同约定,著作权归委托方 | 委托方 |
| 作品软件 | 委托创作 | 合同中未约定著作权归属 | 创作方 |
| 作品软件 | 合作开发 | 只进行组织、提供咨询意见、物质条件或者进行其他辅助工作 | 不享有著作权 |
| 作品软件 | 合作开发 | 共同创作的 | 共同享有,技入头比例。 成果可分割的,可分开申请。 |
| 商标 || 谁先申请谁拥有(除知名商标的非法抢注) 同时申请,则根据谁先使用(需提供证据) ||
| 专利 || 无法提供证据,协商归属,无效时使用抽签(但不可不确定) 谁先申请谁拥有, 同时申请则协商归属,但不能够同时驳回双方的专利申请 ||
14.4侵权判断
- 未发表的作品、口述作品(包括即兴的演说、授课、法庭辩论等以口头语言形式表现的作品) 、摄影作品、示意图等作品也受著作权法保护。
- 对于作品而言,以下行为是不侵权的:个人学习,介绍或评论时引用,在各种形式的新闻报道中引用,学校教学与研究及图书馆陈列用的少量复制,执行公务使用,免费表演已发表作品,将汉字作品翻译成为少数民族文字,改为盲文出版。
- 对于作品而言,公开表演、播放是需要另外授权的。例如:在商场公开播放正版的音乐、VCD也是侵权行为。而且版权人对作品还享有保护作品完整权,这点也是不容忽视的。
- 对于软件产品而言,要注意保护只是针对计算机软件和文档,并不包括开发软件所用的思想、处理过程、操作方法或数学概念等。另外,以学习、研究所做的少量复制与修改,为保护合法获得的产品所做的少量复制也不侵权。
14.5授予专利权的条件
新颖性、创造性、实用性。
14.6专利制度的基本特点是
法律保护、科学审查、公开通报和国际交流。
十五、标准化基础
15.1标准化的基本概念
- 标准:对重复性的事务和概念所做的统一规定。以科学、技术和实践经验的综合成果为基础,经有关方面协商一致,由一个公认机构批准,以特定形式发布,作为共同遵守的准则和依据。
- 标准化:是指在经济、技术、科学及管理等社会实践中,对重复性事物的概念通过制订、发布和实施标准达到统一,以获得最佳秩序和社会效益的活动。它是一门综合性学科,具有综合性、政策性和统一性的特点。
- 标准化的过程:一般包括标准产生(调查、研究、形成草案、批准发布)、标准实施(宣传、普及、监督、咨询) 和标准更新(复审、废止或修订) 三个子过程。
15.2标准化的实质
通过制定、发布和实施标准,达到统一。
15.3标准化的目的
获得最佳秩序和社会效益。
15.4制定标准的原则
- 要从全局利益出发,认真贯彻国家技术经济政策。
- 充分满足使用要求。
- 有利于促进经济技术的发展。
15.5制定标准的阶段
申请、预备、委员会、审查、发布阶段。
15.6标准更新
标准复审(复审周期一般不超过五年)、标准确认、标准修订。
15.7标准的分类
- 按适用范围:国际(ISO/IEC国际标准化组织)、国家、区域、行业、地方、企业、项目规范。
- 按性质:技术标准、管理标准和工作标准。
- 按作用:基础标准、产品标准、方法标准、安全标准、卫生标准...
- 按法律约束性:强制标准、推荐标准。
15.8标准的编号
- 国际国外:标准代号+专业类号+顺序年号+年代号
- 我国:强制性用GB;推荐性用GB/T
15.9常见的标准化组织
|----------|---------------------------------|
| 标准级别 | 例子 |
| 国际标准组织 | ISO一国际标准化组织 |
| 国际标准组织 | IEC一国际电工委员会 |
| 区域标准组织 | CEN一欧洲标准委员会 |
| 区域标准组织 | CENELEC一欧洲电工标准化委员会 |
| 区域标准组织 | EBU 欧洲广播联盟 |
| 区域标准组织 | AOW-亚洲大洋洲开放系统互联研讨会 |
| 区域标准组织 | ASEB亚洲电子数据交换理事会 |
| 国家标准 | 参见上个知识点"标准化基本概念 |
| 行业标准 | IEEE-美国电气和电子工程师学会标准 DOD-美国国防部标准 |
| 行业标准 | GJB-我国国防科学技术工业委员会 |
| 行业标准 | NEMA-美国电气制造商协会标准 |
15.10 我国的标准分类
- 国家标准:(纸板)QB 1457-1992;QB/T 1315-1991;GSB(国家事物标准)。
- 行业标准:教育行业标准(JY)、金融行业标准(JR)、有点通信行业标准(YD)、医药行业标准(YY)、航天(QJ)、电子行业(SJ)、机械行业(JB)。
- 地方标准:DB加上省市代码前两位;上海DB31、重庆DB55、北京DB11.
- 企业标准:Q+/+企业代号
15.11软件工程的标准化
|-------|----------------------------------------|-----------------|-----------------|
| 类 | 标准名称 | 国家标准 | 对应国际标准 |
| 基础标准 | 软件工程术语 | GB/T 11457-89 | |
| 基础标准 | 信息处理一数据流程图、程序流程图、程序网络图和系统资源图的文件编辑符号及约定 | GB 1526-89 | IS05807-85 |
| 基础标准 | 软件工程标准分类法 | GB/T 15538-95 | ANSIIEEE 1002 |
| 基础标准 | 信息处理一程序构造及其表示法的约定 | GB 13502-92 | IS 8631 |
| 基础标准 | 信息处理一单命中判定表规范 | GB/T 15535-95 | IS0 5806 |
| 基础标准 | 信息处理系统一计算机系统配置图符号及约定 | GB/T 14085-93 | IS0 8790 |
| 开发标准 | 软件开发规范 | GB 8566-88 | |
| 开发标准 | 计算机软件单元测试 | GB/T 15532-95 | |
| 开发标准 | 信息处理一按记录组处理顺序文卷的程序流程 | | IS0 6593-85 |
| 开发标准 | 软件维护指南 | GB/T 14079-93 | |
| 文档标准 | 计算机软件产品开发文件编制指南 | GB 8567-88 | |
| 文档标准 | 计算机软件需求说明编制指南 | GB 9385-88 | ANSIIEEE 829 |
| 文档标准 | 计算机软件测试文件编制规范 | GB 9386-88 | ANSIIEEE 830 |
| 管理标准 | 计算机软件配置管理计划规范 | GB/T 12505-90 | IEEE 828 |
| 管理标准 | 信息技术 软件产品评价 质量特性及其使用指南 | GB/T 12260-96 | ISO/IEC 9126-91 |
| 管理标准 | 计算机软件质量保证计划规范 | GB 12504-90 | ANSUIEEE 730 |
| 管理标准 | 计算机软件可靠性和可维护性管理 | GB/T 14394-93 | |
| 管理标准 | 质量管理和质量保标准 | GB/T 19000.2-94 | IS0 9000-3-93 |
15.12国家标准
《计算机软件文档编制规范》,一般产生14种文件,其中管理人员主要使用的有:项目开发计划、可行性研究报告、模版开发卷宗、开发进度月报、项目开发总结报告。开发人员使用:软件需求说明书、项目开发计划、模版开发卷宗、数据需求说明书、概要设计说明书、详细设计说明书、数据库设计说明书、测试计划和测试分析报告。维护人员使用:设计说明书、模版开发卷宗和测试分析报告。
15.13标准的复审
ISO标准每5年复审一次,平均标龄4.92年,我过标准有效期一般为5年。
写在最后
本文主要对软考中级数据库系统工程师考试的相关知识点和技能要求进行了全面的总结和归纳。在备考过程中,我们应该注重理解和掌握数据库系统的基本概念和原理,同时要熟悉各种数据库系统的特点和应用场景。此外,数据库设计和应用、数据库管理和维护、数据库安全和备份等方面也是备考中需要重点关注的方向。在备考过程中,我们可以结合实际工作和项目经验,进行案例分析和实践操作,提高自己的实际操作能力和解决问题的能力。