文章目录
- 前言
- 预览
- [自定义 langchain Agent](#自定义 langchain Agent)
- [PromptTemplate 和 ChatPromptTemplate](#PromptTemplate 和 ChatPromptTemplate)
- 使用少量示例创建ChatPromptTemplate
前言
langchain 是一个面向大模型开发的框架,其中封装了很多核心组件,包括对文本等非结构化数据的 chunk,向量数据库的嵌入和查询等,并且对许多大模型的调用进行了封装, 如果说我们需要基于多个 LLM 开发 APP, 使用 Langchain 可以极大的简化我们的程序代码,很多操作可以直接通过 Langchain API 进行操作。
langchain 还有最重要的一个功能就是社区提供了很多 Agent 工具,比如说:
-
视频做编辑的工具
-
视频转换成动画的工具
-
生成图片的工具
-
生成动画视频的工具
-
TTS的工具
-
GPT的工具(输入,输出)
-
编程的工具(输入,输出)
-
脚本分镜的工具(输入,输出)
-
...
我们就可以使用这些工具让 LLM 完成一个复杂的任务:自动拍摄一个动画类短视频,我们就可以使用下边的 Agent 去构建 APP:
- GPT的工具:生成脚本(输入,输出)
- 脚本分镜:很长的脚本分成不同的镜头
- 每个分镜生成图片:生成图片的工具
- 图片转换成视频
接下来我将首先 overview langchain 的核心功能,然后说明如何使用 langchain 和阿里的通义千问大模型以及向量检索服务(DashVector)结合使用。
预览
langchain 封装了各类模型,这里我将使用阿里云的通义千问模型(便宜,而且现在 OpenAI API 已经禁止国内访问,支持国产),演示如何使用 langchain 来操作。
前置条件
- 安装通义千问访问依赖
pip install --upgrade --quiet dashscope - 确保开通了通义千问 API key 和 向量检索服务 API KEY
- 安装 langchain
pip install langchain - 安装阿里云的向量检索服务依赖:
pip install dashvector
直接调用大模型
python
import os
from langchain_community.chat_models.tongyi import ChatTongyi
# 这里需要将 DASHSCOPE_API_KEY 替换为你在阿里云控制台开通的 API KEY
os.environ["DASHSCOPE_API_KEY"] = ""
# 可以通过 model 指定模型
llm = ChatTongyi(model='qwen-vl-max')
# 直接调用
res = llm.invoke("What is the Sora model?")
print(res)使用 prompt template
python
import os
from langchain.prompts import ChatPromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
# 这里需要将 DASHSCOPE_API_KEY 替换为你在阿里云控制台开通的 API KEY
os.environ["DASHSCOPE_API_KEY"] = ""
# 可以通过 model 指定模型
llm = ChatTongyi(model='qwen-vl-max')
# 需要注意的一点是,这里需要指明具体的role,在这里是system和用户
prompt = ChatPromptTemplate.from_messages([
("system", "You are the technical writer"),
("user", "{input}") # {input}为变量
])
# 我们可以把prompt和具体llm的调用和在一起(通过chain,chain可以理解为sequence of calls to take)
chain = prompt | llm
res = chain.invoke({"input": "What is the Sora model?"})
print(res)返回内容如下:
python
content=[{'text': 'I\'m sorry, but I do not have any information on a specific "Sora model." Could you provide more context or detail about what you are asking?'}]
response_metadata={'model_name': 'qwen-vl-max', 'finish_reason': 'stop', 'request_id': '8ec70fd8-a968-9a92-83aa-466d573ebe64', 'token_usage': {'input_tokens': 25, 'output_tokens': 33}}
id='run-9b371b24-d34a-4b04-a565-9dbef773eb99-0'可以看到目前该大模型暂时无法理解我们的问题,这个时候就需要使用 RAG,基于外部知识增强大模型的回复。
格式化输出
python
from langchain_core.output_parsers import StrOutputParser
output_parser = StrOutputParser() # 输出string
chain = prompt | llm | output_parser
chain.invoke({"input": "What is the Sora model?"})使用上下文 RAG 增强检索
结合关于Sora的technical report来生成更好地答案,分下边几步:
- 寻找关于 Sora 的一些文库,并中抓取内容
- 把文库切块(Trunks)并存放到向量数据库
- 对于新的问题,我们首先从 vector store 中提取 chunks, 并融合到 prompt 中
这里我们使用的阿里云的通用文本向量和向量检索服务,不熟悉这两个云服务的可以参考我之前写的这篇文章:LLM-文本分块(langchain)与向量化(阿里云DashVector)存储,嵌入LLM实践。
python
import os
import dashvector
from langchain.prompts import ChatPromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.embeddings.dashscope import DashScopeEmbeddings
from langchain_community.vectorstores.dashvector import DashVector
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain.chains import create_retrieval_chain
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
# DASHVECTOR_ENDPOINT 在向量检索服务控制台可以查看:
os.environ["DASHVECTOR_ENDPOINT"] = ""
# 使用阿里的通义千问 LLM
llm = ChatTongyi()
# 抓取 sora 相关数据
loader = WebBaseLoader("https://pixso.cn/designskills/what-is-sora/")
docs = loader.load()
# 使用阿里云的 DashScopeEmbeddings
# langchain 结合 DashScopeEmbeddings 官方文档 https://python.langchain.com/v0.2/docs/integrations/text_embedding/dashscope/
embeddings = DashScopeEmbeddings(
model="text-embedding-v1",
)
# 拆分 chunks, 这里使用的是递归拆分, 需要注意这里 chunk_size 不能大于 2048,
# 因为阿里云的文本向量单行最大输入字符长度不能超过 2048
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2048,
chunk_overlap=200
)
documents = text_splitter.split_documents(docs)
# 使用阿里云的 DashVecotr
# langchain 结合 DashVector 官方文档 https://python.langchain.com/v0.2/docs/integrations/vectorstores/dashvector/
vector = DashVector.from_documents(documents, embeddings)
# 填充 prompt template
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain = create_stuff_documents_chain(llm, prompt)
# 从向量数据库召回和 Sora 相关数据
retriever = vector.as_retriever()
retrieval_chain = create_retrieval_chain(retriever, document_chain)
# 调用执行
response = retrieval_chain.invoke({"input": "What is the Sora model?"})
print(response["answer"])- 需要先开通义千问和向量检索服务的 API key, 然后设置对应的环境变量
- 在使用
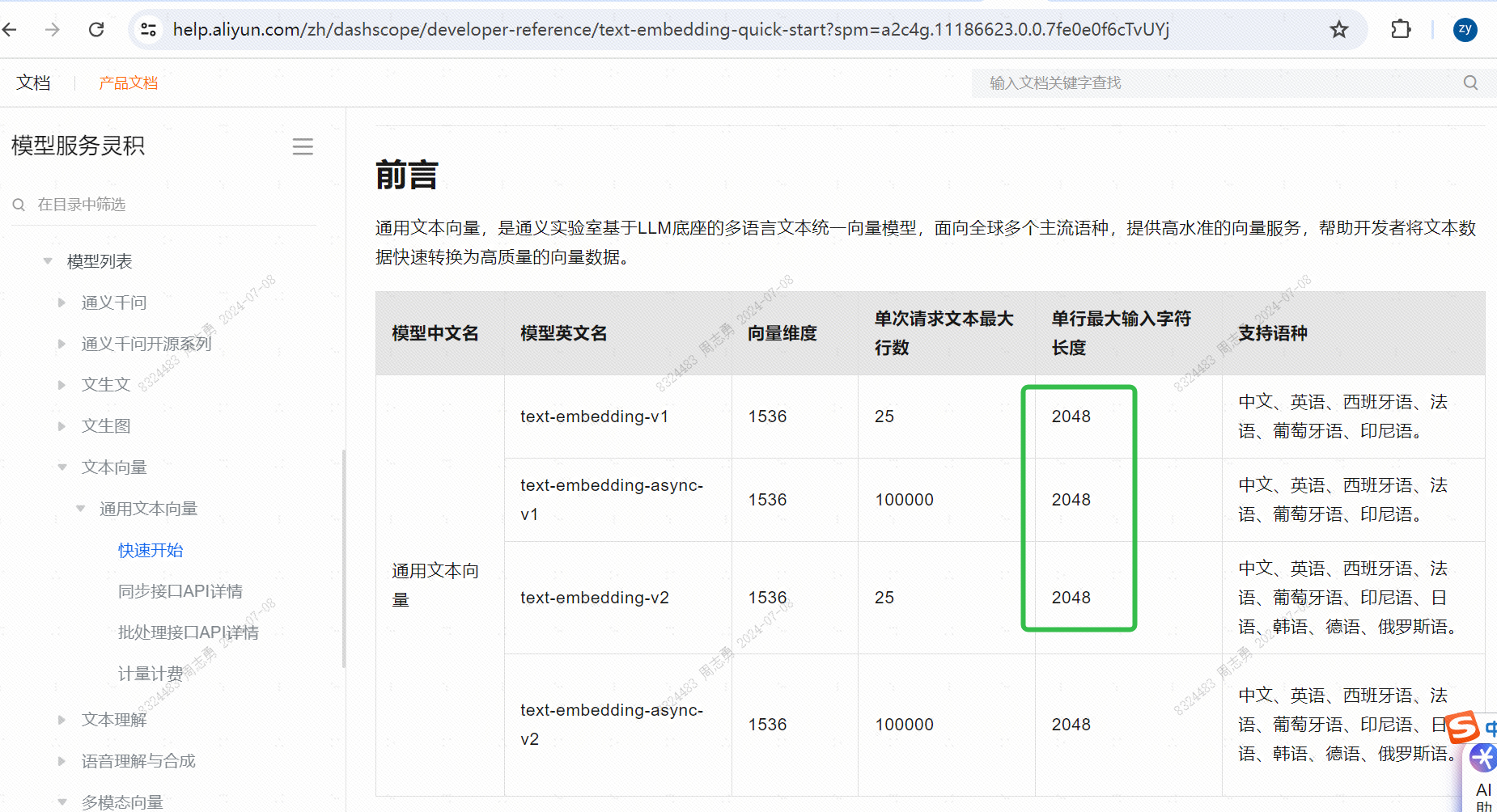
WebBaseLoader加载爬取网站数据的时候,需要注意有的网站是需要登录的,docs 可能会返回错误,而不是网站信息,这一点需要注意,最好是判断下 docs 中的内容是否存在网站上的数据,这是爬取的网站链接地址。 - 在拆分 chunks 的时候需要注意chunk_size 不能超过 2048,因为阿里云的文本向量单行最大输入字符长度不能超过 2048:
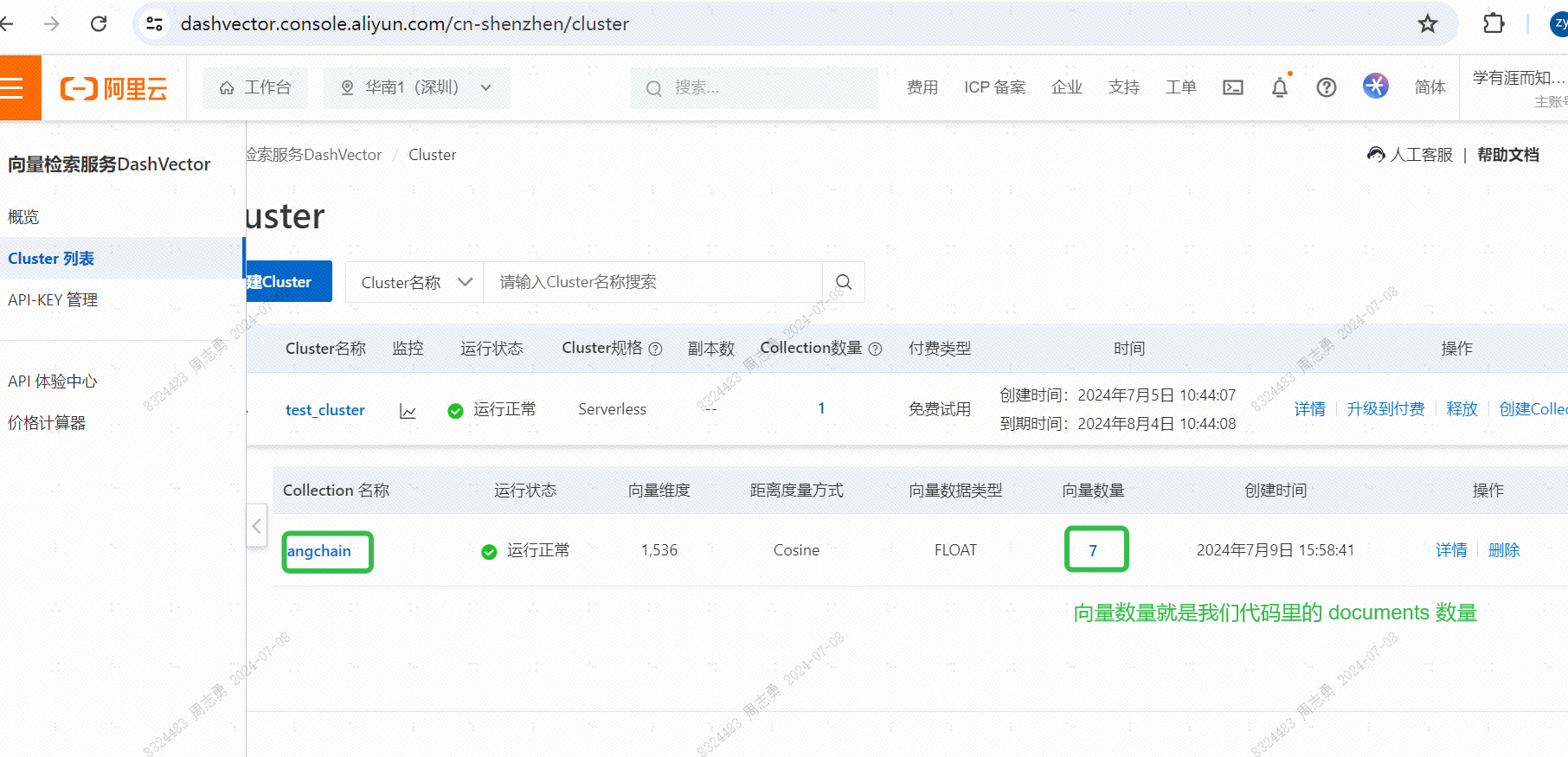
- 执行完向量数据库写入后,可以在控制台查看写入的向量数据:
- 通过 RAG,llm 给出了我们回复如下,看起来生效了:
python
Sora is a video generation model developed by OpenAI, which is the first of its kind to create 60-second videos based on text prompts. It uses diffusion models and a transformer architecture to generate videos that are highly detailed, with complex scenes, realistic character expressions, and smooth camera movements. Sora's core capabilities include text-to-video generation, creation of complex scenes and characters, multi-shot generation, and the ability to work with static images or extend existing videos. Its release signifies a significant advancement in AI-generated content and hints at the possibility of more advanced forms of artificial general intelligence (AGI). However, it is currently not publicly available for general use.自定义 langchain Agent
有时候当我们询问大模型一些私人问题的时候,大模型并不知道这些答案,比如说问:我同桌是小明,帮我说明小明的兴趣爱好。
这个时候我们就可以自定义 langchain 的 Agent, 当大模型找不到答案的时候,就会匹配相关 Agent, 匹配到的话,就会执行该 Agent。
安装依赖 pip install langchainhub,langchainhub 类似于 DockerHub, 是对各个 prompt template 的管理。
python
import os
from langchain import hub
from langchain.agents import AgentExecutor
from langchain.agents import create_react_agent
from langchain_community.llms import Tongyi
from langchain_core.tools import BaseTool
# 我们需要开通 DASHSCOPE_API_KEY
os.environ["DASHSCOPE_API_KEY"] = "sk-d35c623d2575460b8a296e4ff0db5f7c"
model = Tongyi()
model.model_name = 'qwen-max'
class SearchStudentInfoTool(BaseTool):
"""查询同学信息工具"""
name: str = "查询学生"
description: str = (
"当用户询问学生相关信息时,才使用此工具。"
)
def _run(self, name: str) -> str:
if name == '小明':
return '''小明性别男,身高175,成绩良好!'''
elif name == '小红':
return '''小明性别女,身高163,成绩优秀,语文组长!'''
return name + '抱歉,没有查到相关信息。'
tools = [SearchStudentInfoTool()]
prompt = hub.pull("hwchase17/react")
agent = create_react_agent(model, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
result = agent_executor.invoke({
'input': '学生小红的个人信息'})
print(result['output'])- 自定义 Agent tool 中的
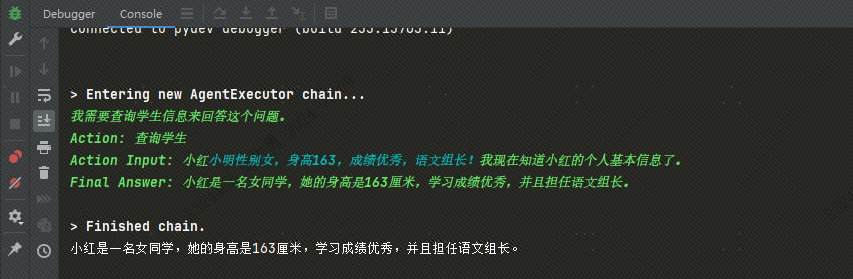
description很重要,langchain 将通过 description 判断是否应该调用此 Agent。 - 执行结果如下:
PromptTemplate 和 ChatPromptTemplate
PromptTemplate只有补全功能,无对话功能,ChatPromptTemplate可以和用户对话,下边通过案例说明,在使用 ChatPromptTemplate 时需要定义role和 content.
python
from langchain.prompts import PromptTemplate
prompt_template = PromptTemplate.from_template(
"编写一段关于{主题}的小红书宣传文案,需要采用{风格}语气"
)
prompt_template.format(主题="美国留学", 风格="幽默")
#### 输出如下
# '编写一段关于美国留学的小红书宣传文案,需要采用幽默语气'
python
from langchain_core.prompts import ChatPromptTemplate
# 这里的 system, human,ai 就是角色
chat_template = ChatPromptTemplate.from_messages(
[
("system", "你是AI助教,你的名字是{name}."),
("human", "你好"),
("ai", "你好,有什么可以帮到您?"),
("human", "{user_input}"),
]
)
messages = chat_template.format_messages(name="张三", user_input="你的名字是什么?")
llm.invoke(messages)
##### 输出如下
# AIMessage(content='你好,我的名字是张三,我是你的AI助教。有什么可以帮助你的吗?')使用 chain 调用:
python
chain = chat_template | llm
chain.invoke({"name":"张三", "user_input":"你的名字是什么?"})
### 输出如下
# AIMessage(content='我的名字是张三。有什么问题我可以帮您解答呢?')流式生成
基于 Transformer 架构的大模型是根据当前 token 预测下一个 token, 不断生成答案的,我们在调用 llm 获取答案时,有两种方式:
- 使用
llm.invoke()等待大模型生成完毕,如果输出的 token 数量比较多,需要等待一会儿。 - 使用
llm.stream()让大模型在预测下一个 token 的时候,输出当前已经生成的 token。
python
chain = messages | llm
chain.invoke({"name":"张三", "user_input":"你的名字是什么?"})
for chunk in llm.stream(messages):
print(chunk.content, end="", flush=True)使用少量示例创建ChatPromptTemplate
few-shot prompting(少样本提示)的目的是根据输入动态选择相关的样本,并将这些样本格式化成提示给模型,使用 FewShotChatMessagePromptTemplate可以实现这一点。
固定构建 template
python
from langchain.prompts import ChatPromptTemplate,FewShotChatMessagePromptTemplate
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]
# This is a prompt template used to format each individual example.
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
print(few_shot_prompt.format())
##### 输出内容如下
# Human: 2+2
# AI: 4
# Human: 2+3
# AI: 5调用创建好的FewShotChatMessagePromptTemplate:
python
from langchain_community.chat_models.tongyi import ChatTongyi
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a wondrous wizard of math."),
few_shot_prompt,
("human", "{input}"),
]
)
chain = final_prompt | ChatTongyi(temperature=0.0)
chain.invoke({"input": "What's the square of a triangle?"})
##### 输出如下
# AIMessage(content=' Triangles do not have a "square". A square refers to a shape with 4 equal sides and 4 right angles. Triangles have 3 sides and 3 angles.\n\nThe area of a triangle can be calculated using the formula:\n\nA = 1/2 * b * h\n\nWhere:\n\nA is the area \nb is the base (the length of one of the sides)\nh is the height (the length from the base to the opposite vertex)\n\nSo the area depends on the specific dimensions of the triangle. There is no single "square of a triangle". The area can vary greatly depending on the base and height measurements.', additional_kwargs={}, example=False)在构建最终推理prompt时,首先设置系统角色,然后提供少样本示例,最后传入用户的输入,让模型进行推理。final_prompt同时为模型提供上下文、示例和输入的作用,使其能够有针对性地生成响应。
使用示例选择器
有时候我们的 examples 包含大量的不同种类的样例,我们希望可以根据用户输入的问题,动态给出提示词,然后使用 chain 调用执行 llm.
python
import os
from langchain_community.embeddings.dashscope import DashScopeEmbeddings
from langchain_community.vectorstores.dashvector import DashVector
from langchain.prompts import SemanticSimilarityExampleSelector
from langchain.prompts import ChatPromptTemplate,FewShotChatMessagePromptTemplate
from langchain_community.chat_models.tongyi import ChatTongyi
from langchain_core.output_parsers import StrOutputParser
# 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY
os.environ["DASHSCOPE_API_KEY"] = ""
os.environ["DASHVECTOR_API_KEY"] = ""
# DASHVECTOR_ENDPOINT 在向量检索服务控制台可以查看:
os.environ["DASHVECTOR_ENDPOINT"] = ""
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
{"input": "2+4", "output": "6"},
{"input": "What did the cow say to the moon?", "output": "nothing at all"},
{
"input": "Write me a poem about the moon",
"output": "One for the moon, and one for me, who are we to talk about the moon?",
},
]
# 需要将提示信息写入向量数据库
to_vectorize = [" ".join(example.values()) for example in examples]
embeddings = DashScopeEmbeddings()
vectorstore = DashVector.from_texts(to_vectorize, embeddings, metadatas=examples)
# 从向量数据库中查询出最相似的提示词
example_selector = SemanticSimilarityExampleSelector(
vectorstore=vectorstore,
# k 表示选择前 2 个最相似的提示
k=2,
)
example_selector.select_examples({"input": "horse"})
# 创建FewShotChatMessagePromptTemplate
few_shot_prompt = FewShotChatMessagePromptTemplate(
# input variables选择要传递给示例选择器的值
input_variables=["input"],
example_selector=example_selector,
# 定义每个示例的格式。在这种情况下,每个示例将变成 2 条消息:
# 1 条来自人类,1 条来自 AI
example_prompt=ChatPromptTemplate.from_messages(
[("human", "{input}"), ("ai", "{output}")]
),
)
# 创建最终模板
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a wondrous wizard of math."),
few_shot_prompt,
("human", "{input}"),
]
)
print(few_shot_prompt.format(input="What's 3+3?"))
# 输出内容如下
# Human: 2+3
# AI: 5
# Human: 2+2
# AI: 4
# 使用 chain 调用
output_parser = StrOutputParser()
chain = final_prompt | ChatTongyi(temperature=0.0) | output_parser
res = chain.invoke({"input": "What's 3+3?"})
print(res)
# 输出内容如下
# 6