什么是数据闭环
在自动驾驶研发、生产、测试、运营的整个生命周期中,数据发挥着至关重要的作用。对数据进行高效的收集和利用,加速数据循环链路,是目前自动驾驶技术迭代的关键。
过去几年的自动驾驶技术开发与迭代更多的以模型驱动为核心,以模型为核心驱动的智驾技术最大的特点在于模型不会随着输入数据的变化而更新迭代,而在以数据为驱动的模型中,数据的改变对模型产生相应的影响。
近年来,数据驱动的应用在智驾领域日趋广泛,在数据驱动的模型中,数据可以通过规模化来不断加固和完善智驾系统,数据可以通过数据采集、数据筛选、数据标注、模型训练、模型检测、形成量产模型的闭环链路进行模型优化。构成高效的数据闭环,日益成为自动驾驶产品研发的核心竞争力。形成数据闭环带来的优势主要体现在以下两个方面:提高数据利用和流转效率和以单位获取计算资源的成本的功能。
整数家数据闭环智能系统
基于数据闭环在智驾领域的强大优势和迫切需求,整数智能以成为行业数据标注领航员的企业愿景与驱动,自主研发了整数智能系统,以驱动数据闭环。整数家的智能系统能够在车辆端进行开发的过程中,反馈从驾驶数据到车辆传感器感知搜集的数据并上传到云端,并进一步提供给智能数据平台进行仿真模拟和再利用。经过训练后的模型能够通过智能系统的MLops平台进行快速的评估与发布,而这些迭代和服务,乃至用户体验的优化都可以再次推送到车辆端,构成数据闭环链路。数据驱动本质上是数据流的驱动,在整数智能建构的数据闭环体系中,算法效率越高,数据流动的效率越高,模型依据数据迭代的成本越低,从而不断提高更新迭代成本与核心竞争力。
整数智能的数据闭环系统可以分为数据接入、数据管理和数据使用三个环节。
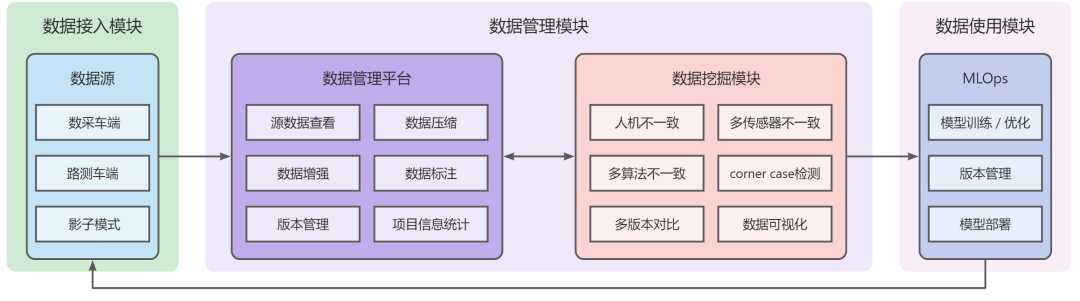
整数智能数据闭环系统链路
数据接入
在自动驾驶开发中,海量数据需要从不同的车端,以合适的格式和方式,尽快传到云端,进行高效的存储和数据回放;在回放之后,优化的算法再高效地流转到各个开发流程。数据输入主要包括激光雷达、车载相机、毫米波雷达(以下分别简称Lidar、Camera、Radar)等传感器的场景数据采集,以及从车辆底盘获取自车信号(速度、加速度、转向等)。
在数据接入领域,整数智能从采集端开始提高数据质量,通过制定严格的标准规则、引入数据算法,实现高质量的数据采集。同时引入了"影子模式",在车辆端后台运行,进行行车数据的记录和行车路线的规划。在数据接入环节对采集数据进行规范化和质量把控,为下一环节中的数据处理降低数据清洗成本、提高数据处理的质量和效率。
数据管理
数据管理分为平台管理和数据挖掘两个模块。
在数据管理环节,整数智能自主研发并投入使用智能数据工程平台(MooreData Platform),支持图片、视频、文本、表格、音频、3D点云、自定义、医疗影像、遥感地图等所有主流数据类型,支持图像分类、目标检测、语义分割、目标跟踪、文本分类、中文分词、命名实体识别等多种数据标注功能。平台内置数据增强功能(针对图片类型),可以针对已有数据集进行快速扩充,获得更好的数据多样性。除此之外,平台还拥有交互式标注、预标注、模型审核等智能提效系统,支持图片、视频、文本、表格、3D点云等数据的智能高效处理。
数据挖掘
优质数据的筛选和利用是让数据在系统中高效运转的关键。在数据闭环链路中,整数智能持续从不断更新的数据中筛选有价值的数据,组成严密的知识筛选体系,降低标注和使用数据的成本,帮助模型更好的成长。数据挖掘模块能够帮助数据闭环全力发挥作用,提高数据闭环链路的运行效率和模型训练效果。
通过参数配置,数据挖掘模块在数据闭环链路中通过数据积累有效解决以下问题:
-
人机不一致(急加速、急刹车、AEB误触发)
-
时间不一致(障碍物错漏、类别跳变、预测结果无序抖动)
-
多传感器不一致(Radar / Lidar / Camera感知不一致,重叠FOV内感知不一致)
-
极端案例检测(交通事故、极端天气、特殊路况、低能见度)
-
多种版本(开发版与稳定版的召回率、预测结果、预测时间对比,车端与云端的预测结果对比,剪枝 / 蒸馏 / 量化效果对比)
除此之外,整数智能在数据挖掘模块已经拥有成熟的软件开发包,可以敏捷地针对特定场景进行二次开发。
数据使用:MLops平台
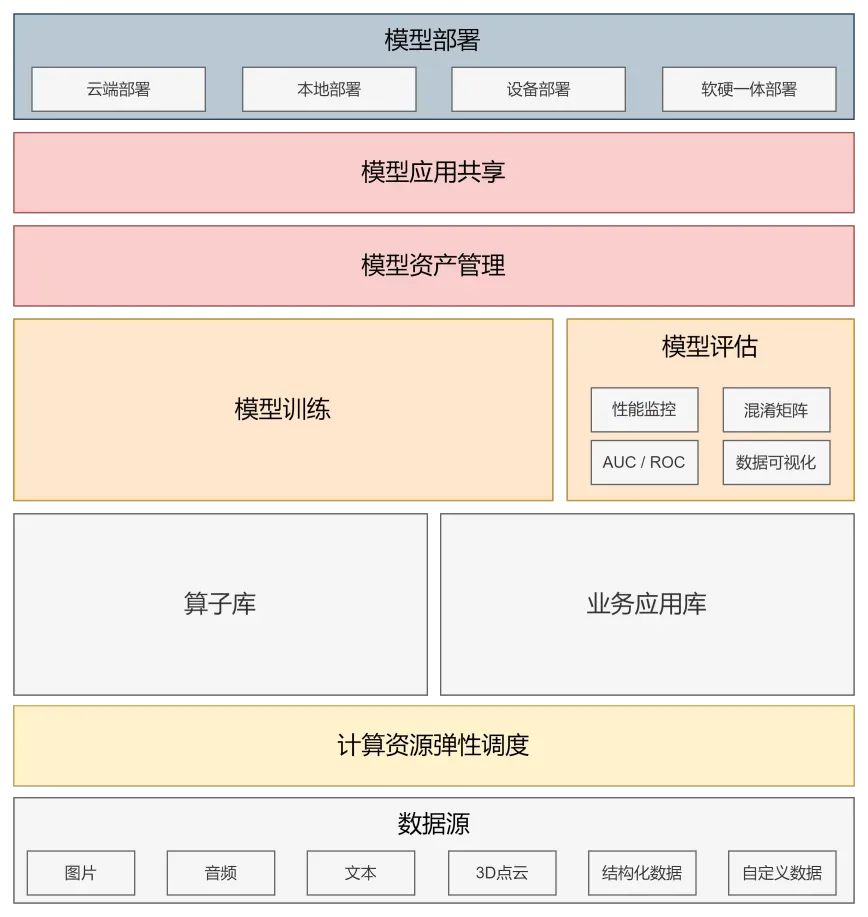
数据运维、模型运维和开发运维是人工智能工程化的三大核心,为加强对数据和大模型的管理,推进数据模型运维自动化,整数智能在数据使用模块设计了一系列MLops方法并投入使用。
MLOps是用于数据科学家和专业运维人员之间协作和交流的一系列实践。在数据训练大模型的过程中应用这些实践进行数据管理和部署,可以在简化管理流程的同时显著提高模型质量,并能欧在大规模生产环境中自动部署机器学习和深度学习模型,使模型能够快速有效地与业务需求以及监管要求保持一致。
整数智能在过往的数据实践中自主设计了一套MLops流程,用于增强工作流程和模型的复用性,提高机器学习生命周期的运转效率,降低数据运维和迭代的时长和成本。整数智能的MLops平台能够实现在同一平台上完成机器学习全流程的任务,实现快速的模型开发、部署和运维,助力解决开发、训练、测试全过程的困难。整数家的MLops平台通过以下几个维度实现数据运维过程的提质增效:
-
云边一体:用户可通过云端对于边缘端的应用、函数、规则和模型进行版本管理、灰度升级等操作,在云端提供不同粒度数据,快速解决标注运维的问题定位和解决,降低边缘端运营成本。
-
自动迭代:平台会在生产环境中根据数据可用性进行数据筛选,并将新数据自动喂入大模型进行训练,帮助模型迭代,保持模型性能不断提升。
-
精准分析:定义问题是数据科学家的核心能力,整数智能MLOps流程可以通过完善的数据分析、数据可视化等手段帮助业务侧更直观、快速、便捷地了解模型情况。
-
弹性资源:整数智能已加入「英伟达初创加速计划」,拥有丰富的GPU计算资源,通过MLOps与GPU计算资源的整合,能够实现更高效、更低成本的数据项目的启动和运营。
AI Power系统持续服务数据闭环全链路
数据处理和数据管理在人工智能中的作用至关重要,但是人工进行数据采集、数据处理标注和数据审核的过程,都需要繁琐的流程和漫长的处理时间,这些都构成了大模型建构和维护的高昂时间、金钱与人力成本;同时基于不同数据标注员不同的主观性特质,以及不同的熟练程度,数据处理难以实现高度标准化,从而影响模型的性能。
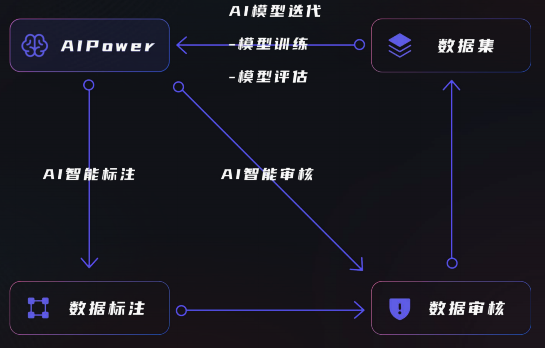
整数智能数据管理平台自研"AIPower闭环系统"
为了提高数据工程生产与管理效率,整数智能自研AI Power系统,为持续的自动化数据管理提供技术与平台支持,并持续将AI Power投入到数据生产、管理和再利用的数据闭环全链路各环节中。AI Power闭环系统是一个能够自我迭代强化的系统,这一系统提供包括AI智能标注、AI智能审核在内的AI辅助功能,能够大大提升标注与审核的效率,并在不断地学习迭代中日益培养出强大的平台性能。
整数智能信息技术(杭州)有限责任公司,起源自浙江大学计算机创新技术研究院,致力于成为AI行业的数据领航员。整数智能也是中国人工智能产业发展联盟、ASAM协会、浙江省人工智能产业技术联盟成员,其提供的智能数据工程平台(MooreData Platform)与数据集构建服务(ACE Service),满足了智能驾驶、AIGC等数十个人工智能应用场景对于先进的智能标注工具以及高质量数据的需求。
欢迎体验智能数据工程平台(个人版),免费、智能、简易,开箱即用:
平台个人版使用手册,可以参考内容进行图像(视频)标注:
https://molar.yuque.com/wkrh7x/motcvg/vd5el9ibwzrtarya

目前公司已合作海内外顶级科技公司与科研机构客户1000余家,拥有知识产权数十项,通过ISO9001、ISO27001等国际认证,也多次参与人工智能领域的标准与白皮书撰写,也受到《CCTV财经频道》《新锐杭商》《浙江卫视》《苏州卫视》等多家新闻媒体报道。