SQL性能分析
SQL性能下降原因:
- 查询语句写的烂
- 索引失效(数据变更)
- 关联查询太多
join(设计缺陷或不得已的需求) - 服务器调优及各个参数设置(缓冲、线程数等)
SQL调优过程:
- 观察,至少跑1天,看看生产的慢
SQL情况。 - 开启慢查询日志,设置阙值,比如超过5秒钟的就是慢
SQL,并将它抓取出来。 explain+ 慢SQL分析。show profile。- 运维经理 or DBA,进行
SQL数据库服务器的参数调优。
SQL执行频率
MySQL客户端连接成功后,通过 show session l global status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
bash
SHOW GLOBAL STATUS LIKE 'Com_______';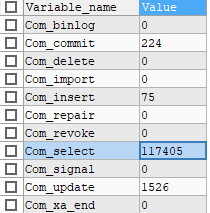
Mysql 查询优化
小表驱动大表
-
当B表是小表时,用
in优于existsqlselect * from A where id in (select id from B) -
当A表是小表时,用
exist优于insqlselect * from A where id exists (select 1 from B where A.id = B.id)
EXISTS语法:
sql
SELECT ...FROM table WHERE EXISTS (subquery)该语法可以理解为:将主查询的数据,放到子查询中做条件验证,根据验证结果(TRUE或FALSE)来决定主查询的数据结果是否得以保留
Group by 优化
group by实质是先排序后进行分组,遵照索引建的最佳左前缀。当无法使用索引列,增大sort_buffer_size参数的设置,增大max_length_for_sort_data参数的设置可以提高排序和分组的效率。
where高于having,能写在where限定的条件就不要去having限定了
Show Profile进行sql分析(重中之重)
Show Profile是mysql提供可以用来分析当前会话中语句执行的资源消耗情况。可以用于SQL的调优的测量
show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。通过have profiling参数,能够看到当前MySQL是否支持profile操作:
sql
SELECT @@have_profiling;默认profiling是关闭的,可以通过set语句在session / global级别开启profiling:
sql
SET profiling = 1;随便执行一条sql
sql
select * FROM t_blog;执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
查看每一条SQL的耗时基本情况
sql
show profiles;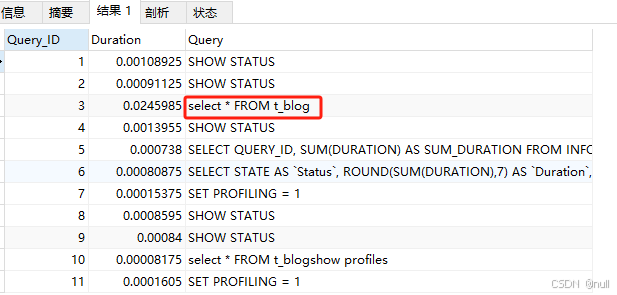
查看指定query id的SQL语句各个阶段的耗时情况
sql
show profile for query query_id;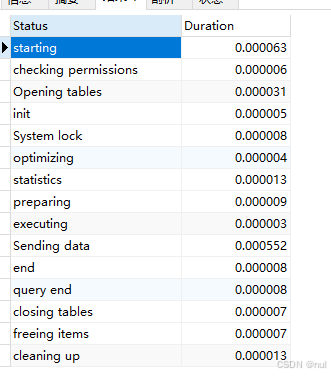
查看指定query_id的SQL语句CPU的使用情况和lO相关开销
sql
show profile cpu,block io for query query_id;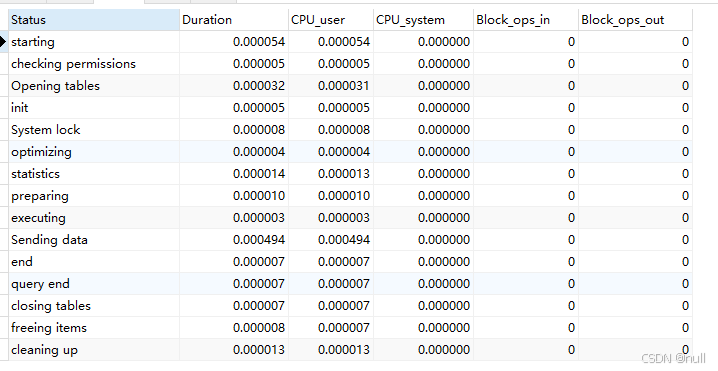
参数备注(写在代码中):show profile cpu,block io for query 3;(如此代码中的cpu,block)
ALL:显示所有的开销信息。BLOCK IO:显示块lO相关开销。CONTEXT SWITCHES:上下文切换相关开销。CPU:显示CPU相关开销信息。IPC:显示发送和接收相关开销信息。MEMORY:显示内存相关开销信息。PAGE FAULTS:显示页面错误相关开销信息。SOURCE:显示和Source_function,Source_file,Source_line相关的开销信息。SWAPS:显示交换次数相关开销的信息。
日常开发需要注意的(Status列中的出现此四个问题严重)
converting HEAP to MyISAM:查询结果太大,内存都不够用了往磁盘上搬了。Creating tmp table:创建临时表,拷贝数据到临时表,用完再删除Copying to tmp table on disk:把内存中临时表复制到磁盘,危险!locked:锁了
MySQL中,如何定位慢查询?
在MySQL中也提供了慢日志查询的功能,可以在MySQL的系统配置文件中开启这个慢日志的功能,并且也可以设置SQL执行超过多少时间来记录到一个日志文件中,我记得上一个项目配置的是2秒,只要SQL执行的时间超过了2秒就会记录到日志文件中,我们就可以在日志文件找到执行比较慢的SQL了。

explain执行计划
EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
语法:
直接在select语句之前加上关键字 explain / desc
bash
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件;
字段解释
id:表的读取顺序
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
id相同,执行顺序从表格由上至下id不同,如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
select_type: 数据读取操作的操作类型
查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
SIMPLE:简单的select查询,查询中不包含子查询或者UNIONPRIMARY:查询中若包含任何复杂的子部分,最外层查询则被标记为(最后加载的那个)SUBQUERY:在SELECT或WHERE列表中包含了子查询DERIVED:在FROM列表中包含的子查询被标记为DERIVED(衍生)MySQL会递归执行这些子查询,把结果放在临时表里UNION:若第二个SELECT出现在UNION之后,则被标记为UNION;若UNION包含在FROM子句的子查询中外层SELECT将被标记为:DERIVEDUNION RESULT:从UNION表获取结果的SELECT(两个select语句用UNION合并)
table:显示执行的表名
显示这一行的数据是关于哪张表的
type: sql的连接的类型
这条sql的连接的类型,性能由好到差为NULL、system、const、eq_ref、ref、range、 index、all
system:查询系统中的表const:根据主键索引查询eq_ref:主键索引查询或唯一索引查询,表中只有一条记录与之匹配。常见于主键或唯一索引扫描。ref:索引查询,非唯一性索引扫描,返回匹配某个单独值的所有行,本质上也是一种索引访问,它返回所有匹配某个单独值的行,然而,它可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体range:范围查询,只检索给定范围的行 ,使用一个索引来选择行。key列显示使用了哪个索引一般就是在你的where语句中出现了between、<、>、in等的查询。这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束语另一点,不用扫描全部索引index:索引树扫描,index与ALL区别为index类型只遍历索引列。这通常比ALL快,因为索引文件通常比数据文件小(也就是说虽然all和Index都是读全表,但index是从索引中读取的,而all是从硬盘中读的)all:全盘扫描
possible_key : 当前sql可能会使用到的索引
显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段火若存在索引,则该索引将被列出,但不一定被查询实际使用(系统认为理论上会使用某些索引)
key 当前sql实际命中的索引
实际使用的索引。如果为NULL,则没有使用索引(要么没建,要么建了失效)
查询中若使用了覆盖索引,则该索引仅出现在key列表中
key_len 索引占用的大小
可通过该列计算查询中使用的索引的长度。
含义是:The length of the chosen key,所选键的长度。其单位是字节。
根据这个值,就可以判断索引使用情况。比如当key_len列显示为NULL时,key列也就会显示为NULL, 说明语句没有用到索引。比如在使用组合索引的时候,判断是否所有的索引字段是否都被用到。
如何根据key_len的值判断是否所有的索引字段都被用到,就要知道key_len的计算规则。
key_len的计算规则:
-
可以为
NULL的列的key长度比非NULL列的key长度大1。sqlCREATE TABLE `a_test` ( `id` int(4) unsigned NOT NULL AUTO_INCREMENT, `server_id` int(4) NOT NULL DEFAULT <span style="color:#98c379">'0'</span>, `user_id` int(4) DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_server_id` (`server_id`), KEY `idx_user_id` (`user_id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1如上所示,当使用
idx_user_id索引时,key_len的值是5(int类型长度4+1),而使用idx_server_id索引时,key_len的值是4(仅为int类型长度4)。 -
如果索引列是字符型(
char)字段,则索引列数据类型本身占用空间跟字符集有关。不同的字符集下,同一个字符存储到表中的时候,它所占用的空间大小是不同的。一个字符存储在表中,到底占用多少个字节
byte,需要根据不同的字符集来分别计算。常用的几种字符集下,字符
character和字节byte的换算关系如下:字符集 1个字符占用字节数(Maxlen) GBK 2 UTF8 3 UTF8mb4 4 latin1 1 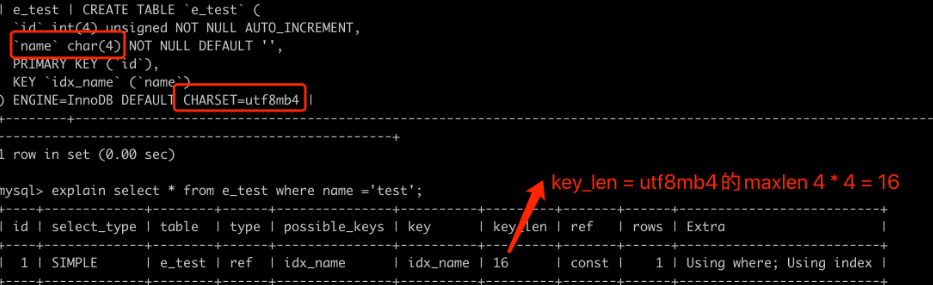
-
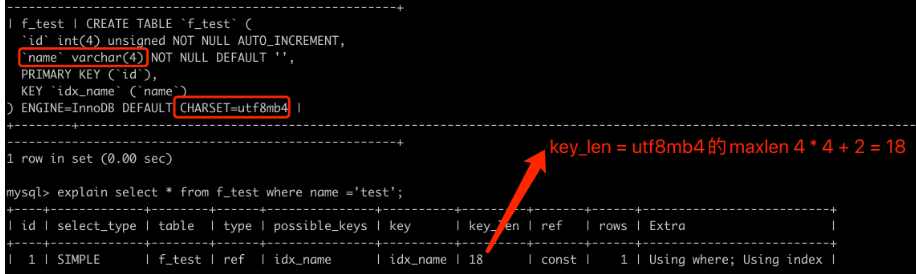
如果索引列是变长的(比如varchar),则在索引列数据类型本身占用空间的基础上再加2。
我们把上面的char类型替换成varchar。
ref:表之间的引用
显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值。
Extra 额外的优化建议

如果一条sql执行很慢的话,我们通常会使用mysql自动的执行计划explain来去查看这条sql的执行情况,比如在这里面可以通过key和key_len检查是否命中了索引,如果本身已经添加了索引,也可以判断索引是否有失效的情况
第二个,可以通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描
第三个可以通过extra建议来判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
面试官:了解过索引吗?(什么是索引)
候选人:嗯,索引在项目中还是比较常见的,
- 它是帮助MySQL高效获取数据的数据结构,
- 主要是用来提高数据检索的效率,降低数据库的IO成本,
- 同时通过索引列对数据进行排序,降低数据排序的成本,也能降低了CPU的消耗
面试官:索引的底层数据结构了解过嘛 ?候选人:MySQL的默认的存储引擎InnoDB采用的B+树的数据结构来存储索引,选择B+树的主要的原因是:
- 第一阶数更多,路径更短
- 第二个磁盘读写代价B+树更低,非叶子节点只存储指针,叶子阶段存储数据
- 第三是B+树便于扫库和区间查询,叶子节点是一个双向链表