免责声明
本文的爬虫知识仅用于合法和合理的数据收集,使用者需遵守相关法律法规及目标网站的爬取规则,尊重数据隐私,合理设置访问频率,不得用于非法目的或侵犯他人权益。因使用网络爬虫产生的任何法律纠纷或损失,由使用者自行承担风险和责任。
1、认识爬虫
1.1、初识爬虫
概述:网络爬虫 也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去 的蜘蛛,爬虫程序通过请求url地址,根据响应的内容进行解析采集数据。简而言之就是:用代码模拟人的行为,去各各网站溜达、点点按钮、查查数据。或者把看到的数据拿下来。
爬虫的作用:通过有效的爬虫手段批量采集数据,可以降低人工成本,提高有效数据量,给予运营/销售的数据支撑,加快产品发展。
1.2、爬虫的合法性
概述:爬虫有时合法,有时不合法,因情况而定,利用程序进行批量爬取网上的公开信息(前端显示的数据信息),因为信息是完全公开的,所以是合法的;但是通过爬虫获取隐私信息或对目标网站造成DDOS攻击就是不合法的爬虫。
合法的爬虫:①、公开且没有标识不可爬取的数据;②、不影响目标网站的服务器;③、不影响目标网站的业务。
非法爬虫:①、获取用户数据;②、明文规定不能爬取的数据(1、在域名后加上/robots.txt查看网站标明的爬取规则,但不是所有网站都有。2、页面上标明不允许爬取);③、影响目标网站业务(占用网站大量资源导致正常用户无法访问);④、影响目标网站服务器(由于频率过高对服务器造成DDOS攻击)
实操1:查看bilibili的爬虫规则。
在浏览器的地址栏中输入如下地址:
www.bilibili.com/robots.txt运行结果如下:

结果分析:
# /index.html:User-agent: *表示这是对所有爬虫的规则,禁止所有爬虫访问 /medialist/detail/ 路径,禁止所有爬虫访问 /index.html 页面。
User-agent: * Disallow: /medialist/detail/ Disallow
# 下面是针对特定爬虫的规则,表示允许这些特定的爬虫(例如 Yisouspider、Applebot、bingbot 等)访问网站的所有部分。
User-agent: Yisouspider
Allow: /
User-agent: Applebot
Allow: /
User-agent: bingbot
Allow: /
User-agent: Sogou inst spider
Allow: /
User-agent: Sogou web spider
Allow: /
User-agent: 360Spider
Allow: /
User-agent: Googlebot
Allow: /
User-agent: Baiduspider
Allow: /
User-agent: Bytespider
Allow: /
User-agent: PetalBot
Allow: /
# 最后又给了一个针对所有爬虫的规则,该条规则禁止所有爬虫访问网站的所有部分。
User-agent: *
Disallow: /注意:该文件存在矛盾之处,因为它对所有爬虫(User-agent: *)先是指定了允许和禁止的部分,但在文件最后又禁止了所有访问,但是根据标准,最后一条匹配的规则会覆盖之前的规则。因此所有的爬虫最终都会被禁止访问整个网站,尽管之前有针对特定爬虫的允许规则。
1.3、反爬与反反爬
反爬:企业不想让自己的数据被别人拿到,这时就会设置反爬的手段不让爬虫获取数据。
常用反爬手段:①、合法检测:请求校验(useragent,referer,接口加签等);②、验证码:识别文字、做题、滑动等;③、小黑屋:IP/用户限制请求频率,或者直接拦截;④、投毒:反爬虫高境界可以不用拦截,拦截是一时的,投毒返回虚假数据,可以误导竞品决策。
反反爬:破解掉反爬手段,再获取其数据。
1.4、爬虫的基本流程
基本流程:
①、确定想要获取哪些数据;
②、获取目标url(获取目标数据来源于哪个网站,并通过地址栏将这个网站的url获取)
③、分析结构(分析目标数据具体放在哪个位置,该数据是如何展现出来的)
④、构思爬取策略
⑤、编码
基本手段:
①、破解请求限制:1、请求头设置,如useragant为有效客户端;2、控制请求频率(根据实际情景);3、IP代理;4、签名/加密参数从html/cookie/js分析。
②、破解登录授权:请求中带上用户cookie信息。
③、破解验证码:简单的验证码可以使用识图读验证码第三方库。
解析获取到的数据:
①、HTML Dom解析:1、正则匹配,通过的正则表达式来匹配想要爬取的数据,如:有些数据不是在html 标签里,而是在html的script 标签的js变量中;2、使用第三方库解析html dom,比较喜欢类jquery的库。
②、数据字符串(json):1、正则匹配(根据情景使用);2、转 JSON/XML 对象进行解析
问:很多编程语言都能实现网络爬虫,为什么要选择Python?
答:Python简单,高效,第三方模块库多。
1.5、浏览器开发工具
概述:对于爬虫来说,最核心的就是发送请求,让网络服务器返回相应的数据。而最为核心之一就是找到URL,这时就需要一个可以帮助我们分析URL的工具----浏览器开发者工具(通过F12打开)。
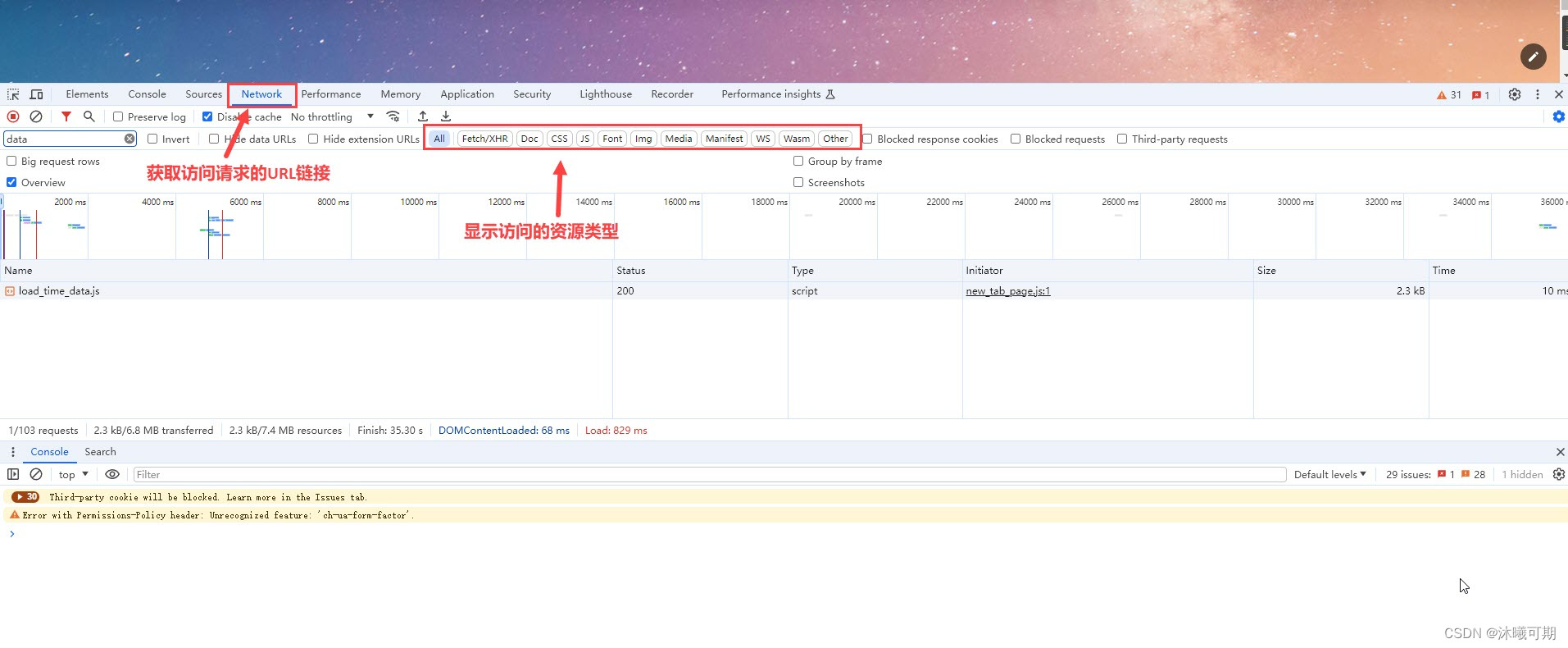
实操2:关闭浏览器工具中网络标签下无用的窗口信息。
首先打开谷歌浏览器,按F12打开浏览器开发工具,然后按如下图所示步骤操作:
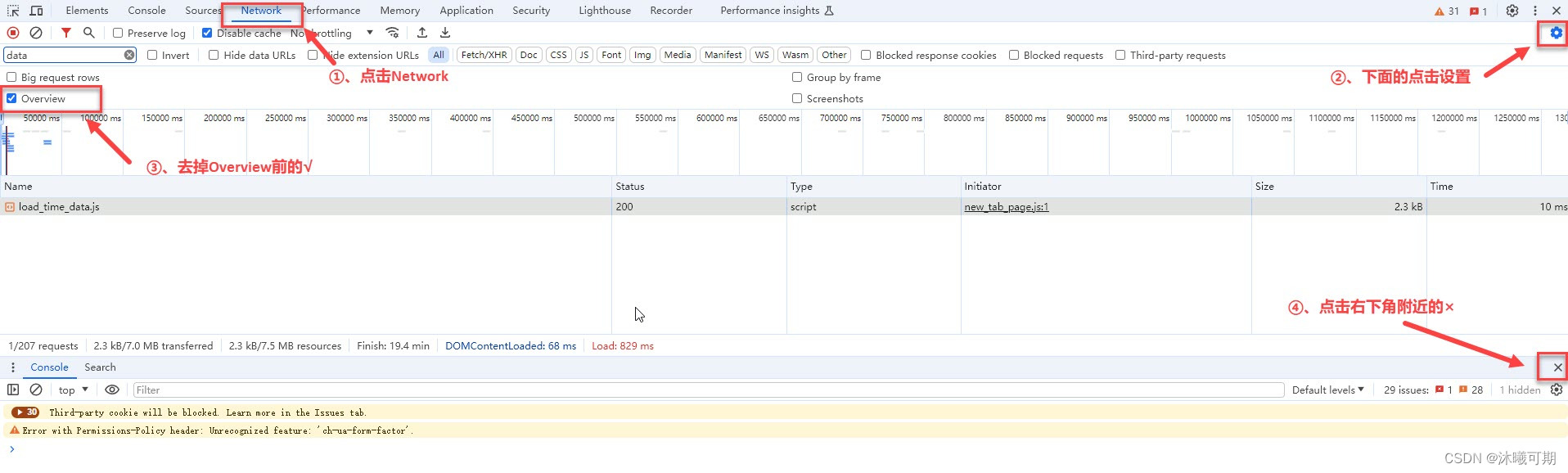
修改后的浏览器工具网络标签的界面如下:

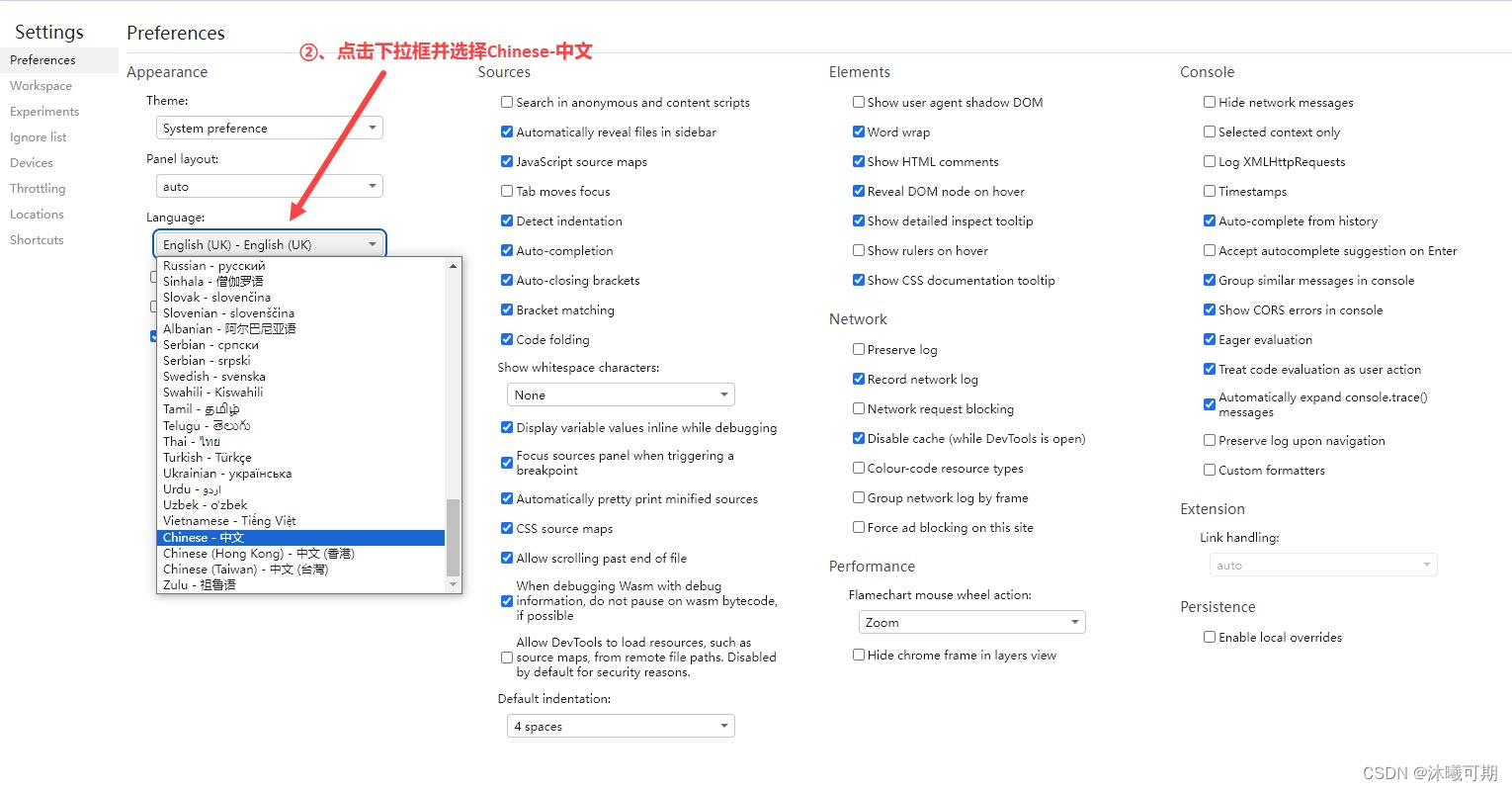
实操3:将浏览器工具的语言切换成中文。
首先打开谷歌浏览器,按F12打开浏览器开发工具,然后按如下图所示步骤操作:

关闭浏览器开发工具,再次打开后的结果如下:

2、urllib开发爬虫
2.1、第一个爬虫
概述:urllib模块库是python3自带的,在Python2叫urllib2。
实操4:获取百度响应信息中前300个字符并打印。
python
from urllib.request import urlopen
# 请求地址
url = "http://www.baidu.com"
# 发送请求
result = urlopen(url)
# 打印响应结果
# read() 方法主要用于从文件对象中读取数据,decode()方法是将字节数据转换为字符串的主要工具
print(result.read().decode()[:300])运行结果如下:

2.2、urllib的基本用法
语法1:
python
requset.urlopen(url,data,timeout)语法解析:
①、urlopen方法用于发送请求;
②、第一个参数url即为URL,是必须要传送的。第二个参数data是访问URL时要传送的数据,第三个timeout是设置超时时间;
③、data和timeout是可选参数,data默认为空None,timeout默认为socket._GLOBAL_DEFAULT_TIMEOUT。
语法2:
python
response.read()语法解析:read()方法就是读取文件里的全部内容,返回bytes类型。
语法3:
python
response.getcode()语法解析:getcode方法用于返回 HTTP的响应码,200表示请求成功,404表示请求的资源不存在,500表示服务器发送错误。
语法4:
python
response.geturl()语法解析:geturl方法用于返回实际数据的实际URL,防止重定向问题。
语法5:
python
response.info()语法解析:info方法用于返回服务器响应的HTTP报头。
实操5:通过百度测试urllib中所有的用法。
python
from urllib.request import urlopen
# 请求地址
url = "http://www.baidu.com"
# 发送请求
response = urlopen(url)
# 打印响应结果
# read() 方法主要用于从文件对象中读取数据,decode()方法是将字节数据转换为字符串的主要工具
print(f"请求到的内容为:{response.read().decode()[:50]}")
print(f"请求的状态码:{response.getcode()}")
print(f"请求的url为:{response.geturl()}")
print(f"http报头信息:{response.info()}")运行结果如下:

2.3、request对象的使用
概述:使用urllib.request.urlopen发送请求时,可以将参数封装到一个Request对象中。
封装的参数:①、发送的请求链接url;②、请求头信息headers;③、请求数据data。
知识点补充:**http://httpbin.org/get**是一个用于测试 HTTP 请求的端点,由 httpbin.org 提供。它是一个简单而实用的服务,用于测试各种 HTTP 请求和响应。访问这个 URL 会返回一个包含有关请求的详细信息的 JSON 响应。这对于开发和调试网络应用程序非常有帮助,因为你可以查看发送的请求的各个方面以及服务器返回的响应。
实操6:通过request获取http://httpbin.org/get的所有返回信息。
python
from urllib.request import Request,urlopen
# 准备链接
url = "http://httpbin.org/get"
# 创建request对象
req = Request(url)
# 发送请求
resp = urlopen(req)
# 打印响应结果
print(resp.read().decode())运行结果如下:
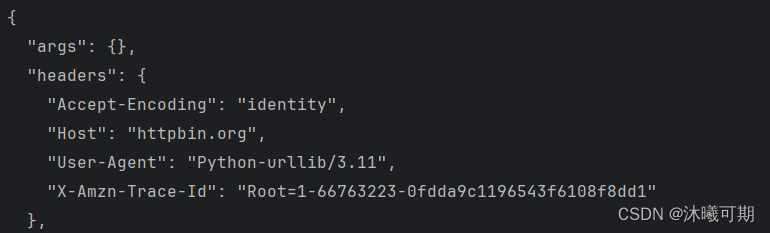
问题引入:通过上面的信息可知,通过程序直接请求别人的网站时,我们的User-Agent显示的是Python-urllib/3.11,这明显是一个程序名而不是一个浏览器。
获取User-Agent的方式:
①、通过浏览器访问http://httpbin.org/get获取User-Agent,请求后的结果如下:

②、通过浏览器开发工具获取User-Agent:
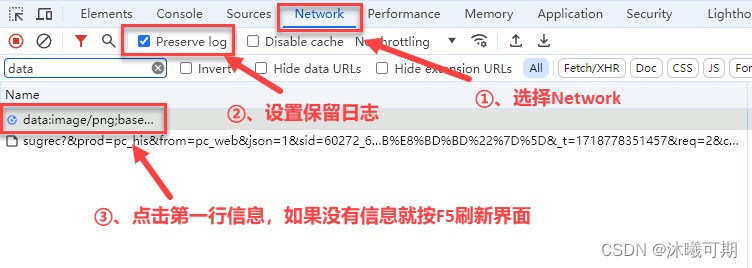
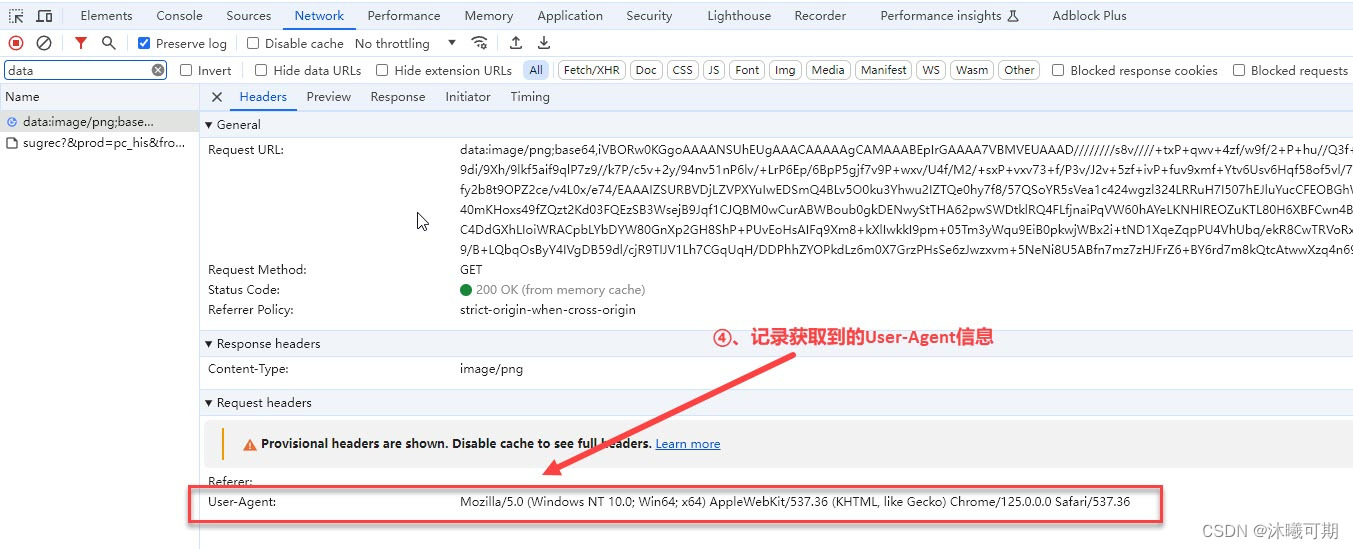
实操7:为我们的网络爬虫伪装一个User-Agent并用程序访问http://httpbin.org/get验证是否成功。
python
from urllib.request import Request,urlopen
# 准备链接
url = "http://httpbin.org/get"
# 定义伪装的header信息
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"}
# 创建request对象
req = Request(url,headers=header)
# 发送请求
resp = urlopen(req)
# 打印响应结果
print(resp.read().decode())运行结果如下:

发送请求/响应header头的含义:
| 名称 | 含义 |
|---|---|
| Accept | 告诉服务器客户端支持的数据类型 |
| Accept-Charset | 告诉服务器客户端采用的编码 |
| Accept-Encoding | 告诉服务器客户机支持的数据压缩格式 |
| Accept-Language | 告诉服务器客户机的语言环境 |
| Host | 客户机通过这个头告诉服务器想访问的主机名 |
| If-Modified-Since | 客户机通过这个头告诉服务器资源的缓存时间 |
| Referer | 客户机通过这个头告诉服务器,它是从哪个资源来访问服务器的。(一般用于防盗链) |
| User-Agent | 客户机通过这个头告诉服务器,客户机的软件环境 |
| Cookie | 客户机通过这个头告诉服务器,可以向服务器带数据 |
| Refresh | 服务器通过这个头,告诉浏览器隔多长时间刷新一次 |
| Content-Type | 服务器通过这个头,回送数据的类型 |
| Content-Language | 服务器通过这个头,告诉服务器的语言环境 |
| Server | 服务器通过这个头,告诉浏览器服务器的类型 |
| Content-Encoding | 服务器通过这个头,告诉浏览器数据采用的压缩格式 |
| Content-Length | 服务器通过这个头,告诉浏览器回送数据的长度 |
2.4、urllib发送get请求
问题引入:用浏览器进行搜索时,如果内容包含中文,浏览器会将我们的中文内容进行转码,因此,当我们的参数中包含中文时就需要使用特定的方法对中文进行转码,下图是网页中转码的实际截图:
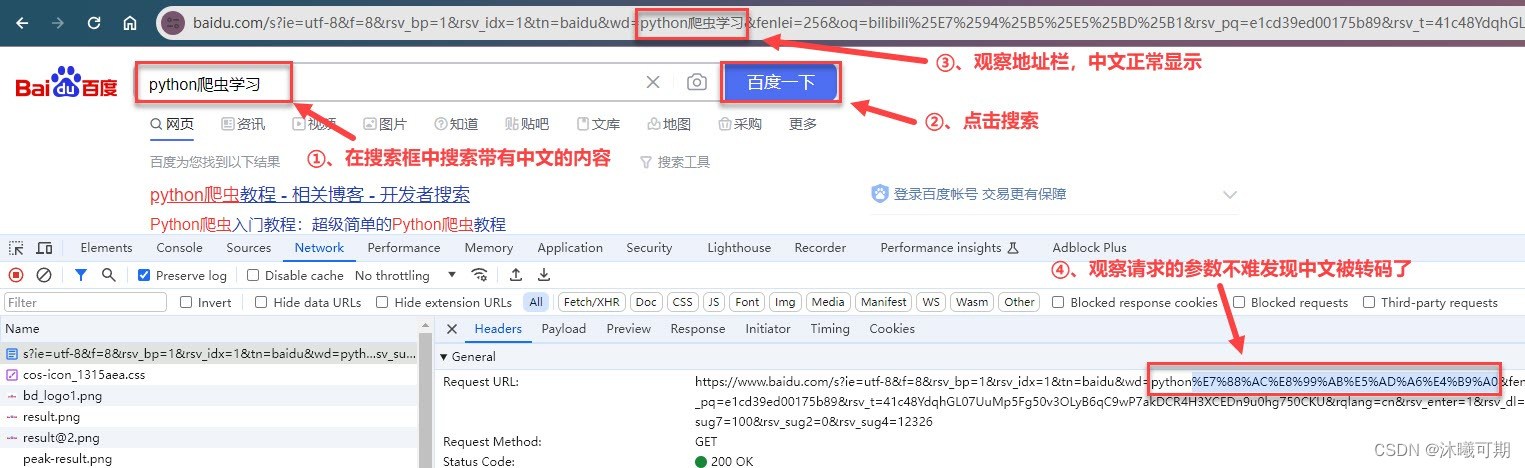
概述:Get请求的参数都是在Url中体现的,如果有中文就需要转码,这时我们可使用:①、urllib.parse.urlencode() 转换键值对;②、urllib.parse. quote() 转换一个值。
实操8:利用爬虫获取百度中任意带有中文信息的搜索结果页面信息。
python
from urllib.request import Request,urlopen
from urllib.parse import quote,urlencode
# 准备url
def quote_url():
args= "python学习"
url = f"https://www.baidu.com/s?wd={quote(args)}"
return url
def urlencode_url():
args = {"wd":"python学习"}
url = f"https://www.baidu.com/s?{urlencode(args)}"
return url
# 准备header信息
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"}
# 创建Request对象(分别传入不同函数内的url验证是否两种方式都有效)
req = Request(quote_url(),headers=header)
# req = Request(urlencode_url(),headers=header)
# 发送请求
resp = urlopen(req)
# 打印获取的信息
print(resp.read().decode()[:1080])运行结果如下:
2.5、实战之某瓣电影TOP250
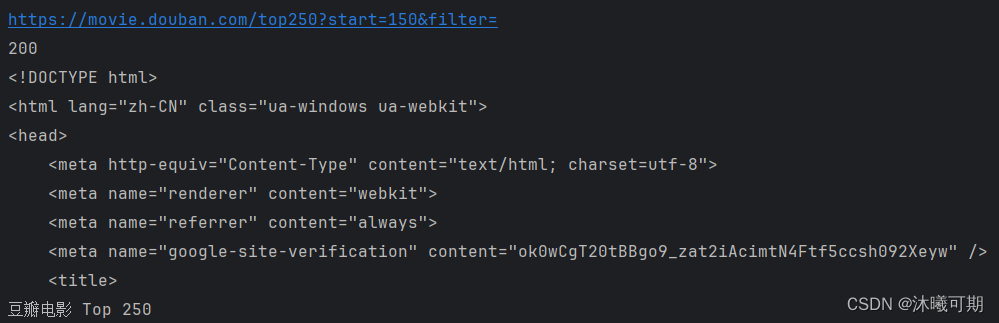
实操9:获取某瓣电影 Top 250中任意连续页面的网页信息,要求每页只打印前2000个字符串信息。
python
# 以下是该网站的前三页地址
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=50&filter=
https://movie.douban.com/top250?start=100&filter=通过观察地址不难发现,不同的网页信息通过start参数来区分。
python
import time
from urllib.request import Request,urlopen
from time import sleep
def myCrawler_top250(start,end):
# 构造url地址
for i in range(start*50-50,end*50+1,50):
url = f"https://movie.douban.com/top250?start={i}&filter="
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"}
# 创建请求对象
req = Request(url,headers=header)
# 发送网络请求
resp = urlopen(req)
# 读取并打印返回信息
print(resp.geturl()) # 打印爬取的url
print(resp.getcode()) # 打印状态码
print(resp.read().decode()[:2000]) # 打印返回的内容
# 休眠1秒,缓解目标网站的压力
time.sleep(1)
if __name__ == '__main__':
# 获取第4页到第6页的内容
myCrawler_top250(4,6)运行结果如下:
2.6、urllib发送post请求
概述:POST请求的参数data需要放到Request请求对象中,data是一个字典,里面要匹配键值对。
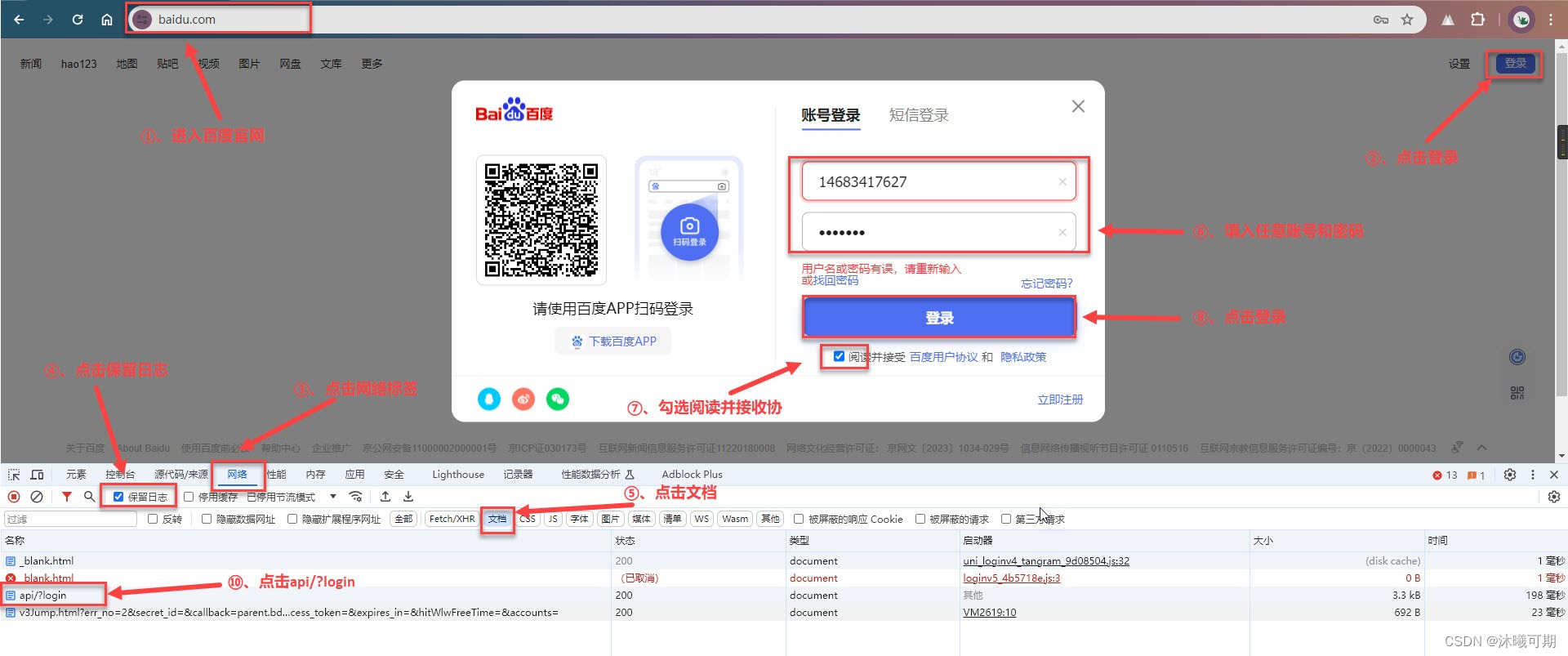
实操10:获取百度登录的地址,并尝试利用urllib向百度发送一个用于登录的post请求。
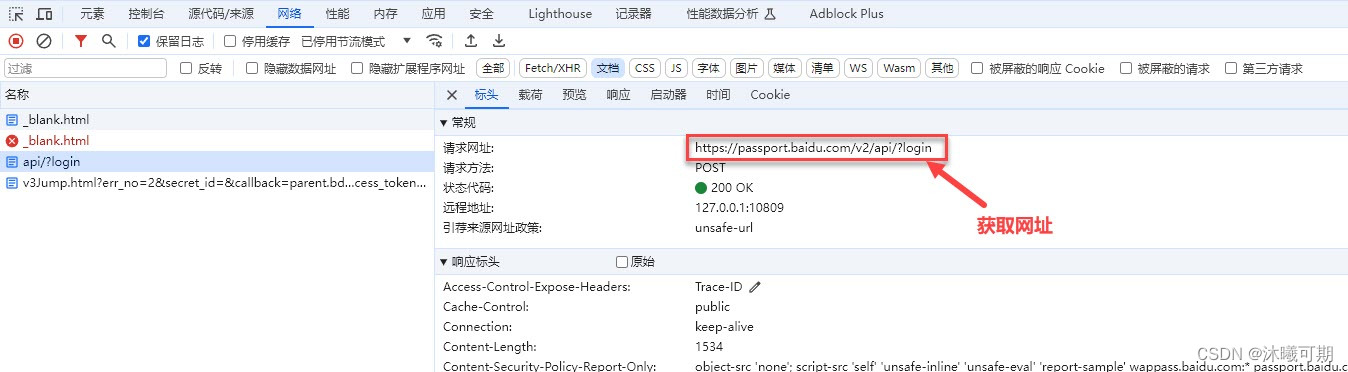
①、首先进入百度官网,点击登录并获取登录网址:
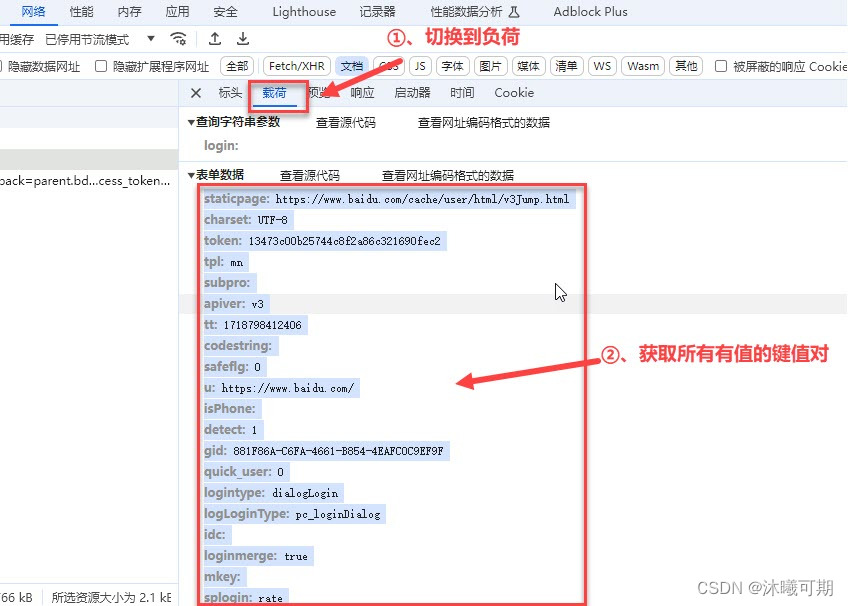
②、获取data参数需要的键值对信息:
②、通过urllib发送post请求:
python
from urllib.request import Request,urlopen
from urllib.parse import urlencode
url = "https://passport.baidu.com/v2/api/?login"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"}
# 封装数据
data = {
"staticpage": "https://www.baidu.com/cache/user/html/v3Jump.html",
"charset": "UTF-8",
"token": "13473c00b25744c8f2a86c321690fec2",
"tpl": "mn",
"apiver": "v3",
"tt": "1718798412406",
"safeflg": "0",
"u": "https://www.baidu.com/",
"detect": "1",
"gid": "881F86A-C6FA-4661-B854-4EAFC0C9EF9F",
"quick_user": "0",
"logintype": "dialogLogin",
"logLoginType": "pc_loginDialog",
"loginmerge": "true",
"splogin": "rate",
"username": "123",
"password": "123"
}
# urlencode将字典转换为URL编码的字符串
encode_data = urlencode(data).encode()
# 创建一个请求对象
req = Request(url,headers=header,data=encode_data)
# 发送请求
resp = urlopen(req)
# 打印返回的信息
print(resp.read().decode())运行结果如下:
由上图可知,我们并没有成功发送post请求实现登录,大家可以参考程序中的思路去实现urllib发送post请求。
2.7、动态页面的数据获取
静态页面特征:访问有UI页面URL,可以直接获取数据;
动态页面特征:访问有UI页面URL,不能获取数据,需要抓取新的请求获取数据。
概述:有些网页内容使用AJAX加载,而AJAX一般返回的是JSON,直接对AJAX地址进行post或get,就返回JSON数据了
实操11:判断虎扑网是动态网页还是静态网页。
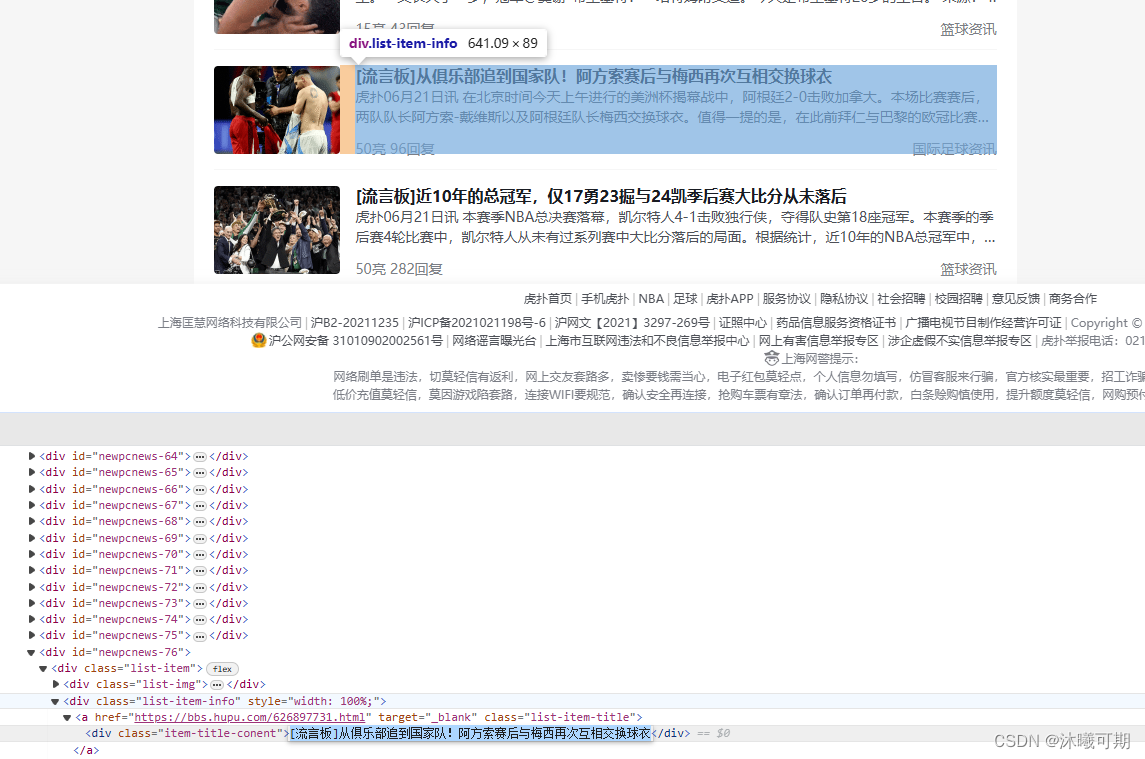
方式一:通过搜索内容判断,如果网页源码内有主页中的任意标题名就说明是静态网页(避免搜索前面的几个标题,因为部分网页可能会将前几条数据在前端写死)
①、下滑首页,获取任意一个标题名(可以只复制一部分,防止内容中间有其他样式标签):
②、检查整页源码:
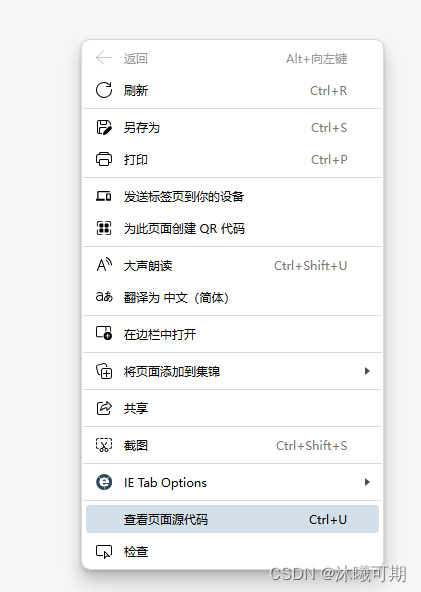
③、通过Ctrl+F查询复制的标题,搜索不到就说明这是一个动态网站,能搜索到就说明是一个静态网页。
方式二:通过浏览器开发工具判断,如果有xhr文件,该网站大概率就是动态网站。
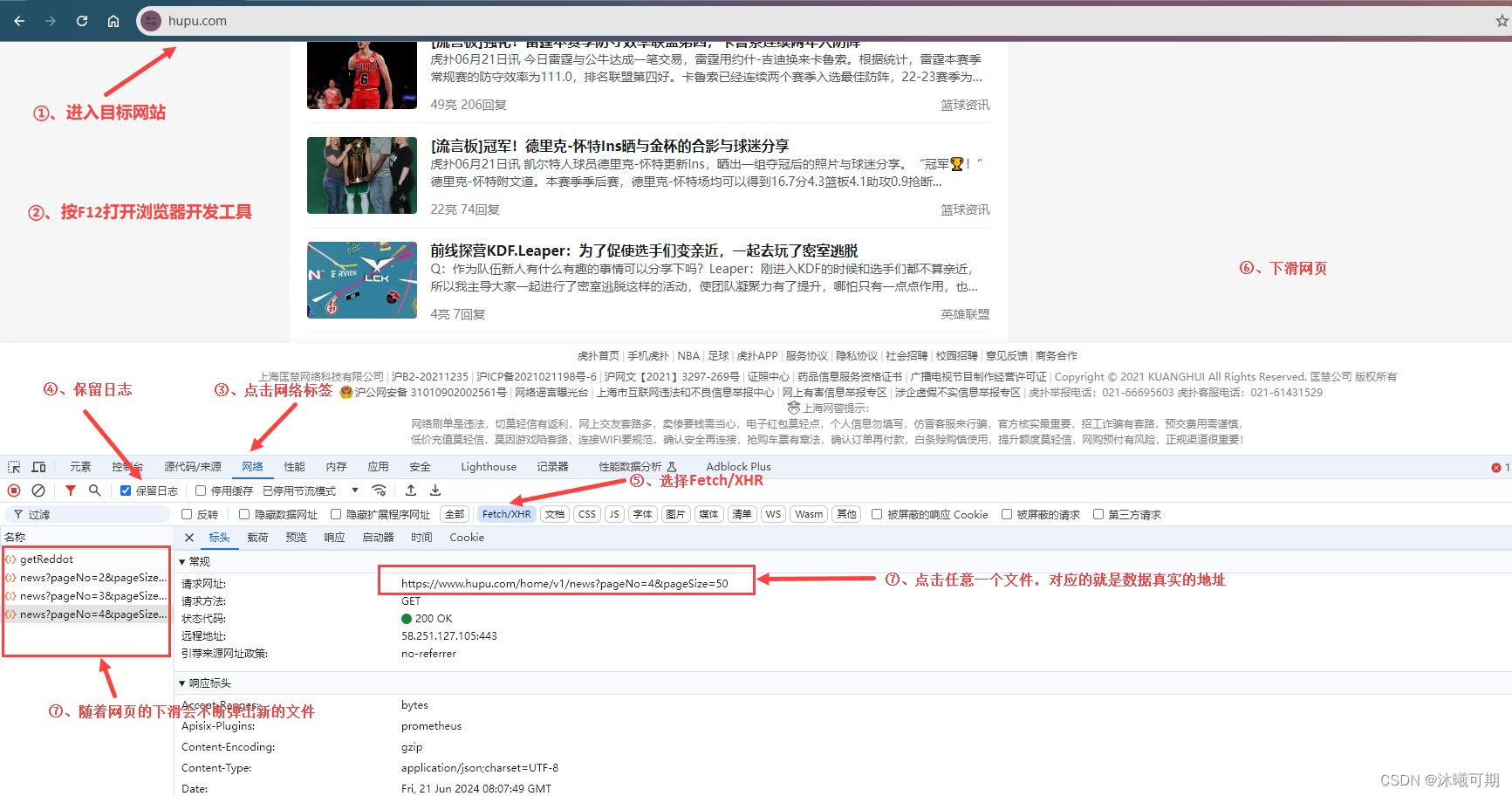
实操12:获取动态页面中任意一页的数据。
python
from urllib.request import Request,urlopen
# 定义目标地址,headers
url = "https://www.hupu.com/home/v1/news?pageNo=3&pageSize=50"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36"}
# 定义Request对象
req = Request(url,headers=header)
# 发送请求
resp = urlopen(req)
# 打印获取的信息
# 读取响应内容并解码
context = resp.read().decode()
# 将解码后的内容中所有的,替换成换行,将展示结果平铺
content_with_line_breaks = context.replace(',', '\n')
# 打印解码并自动换行的结果
print(f"{content_with_line_breaks}")运行结果如下:

3、爬虫相关技术
3.1、请求SSL证书验证
概述:
①、现在随处可见 https 开头的网站,urllib可以为 HTTPS 请求验证SSL证书,就像web浏览器一样,如果网站的SSL证书是经过CA认证的,则能够正常访问,如:https ://www.baidu.com/百度一下,你就知道。
②、如果SSL证书验证不通过,或者操作系统不信任服务器的安全证书,比如浏览器在访问远古时期的12306网站的时候,会警告用户证书不受信任。
SSL问题的参考代码:
python
import ssl
# 忽略SSL安全认证
context = ssl._create_unverified_context()
# 添加到context参数里
response = urlopen(request, context = context)3.2、伪装请求头
概述:在前面的学习中,我们通过网页中User-Agent的值设置了请求头,但这样会产生两个问题:①、获取较繁琐;②、目标网站认为该用户的请求较频繁(因为一直是一个固定的User-Agent在请求)。基于以上的问题,就考虑使用fake-useragent。
安装:
python
# 在终端输入(ALT+F12)
pip install fake-useragent运行结果如下:
实操13:验证fake-useragent能否产生多个不同的User-Agent信息。
python
from fake_useragent import UserAgent
# 创建UserAgent对象
ua = UserAgent()
# 利用UserAgent对象获取不同浏览器的User-Agent信息(每次运行都有不同的结果)
print(ua.chrome)
print(ua.chrome)
print(ua.firefox)
print(ua.firefox)
print(ua.edge)
print(ua.edge)运行结果如下:

实操14:通过fake-useragent生成Chrome的User-Agent并访问http://httpbin.org/get验证结果。
python
from urllib.request import Request,urlopen
from fake_useragent import UserAgent
# 创建UserAgent对象
ua = UserAgent()
url = "http://httpbin.org/get"
# 创建request对象
req = Request(url,headers={"User-Agent":ua.chrome})
# 发送请求
resp = urlopen(req)
# 打印响应信息
print(resp.read().decode())运行结果如下:

3.3、设置代理
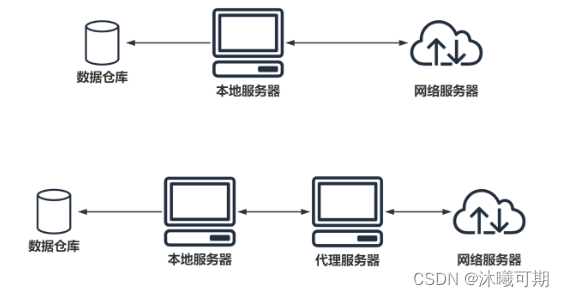
概述:爬虫设置代理就是让别的服务器或电脑代替自己的服务器去获取数据。
爬虫代理源码:
代理分类:
①、透明代理:目标网站知道你使用了代理并且知道你的源IP地址,这种代理显然不符合我们这里使用代理的初衷;
②、匿名代理:匿名程度比较低,也就是网站知道你使用了代理,但是并不知道你的源IP地址;
③、高匿代理:这是最保险的方式,目标网站既不知道你使用的代理更不知道你的源IP。
注意:代理IP无论是免费,还是付费,都不能保证一定可用。
实操15:模拟不使用代理和使用代理。
python
########## 不使用代理 ##########
from urllib.request import Request,build_opener,ProxyHandler
from fake_useragent import UserAgent
url = "http://httpbin.org/get"
ua = UserAgent()
header = {"User-Agent":ua.chrome}
# 创建请求对象
req = Request(url,headers=header)
# 构建一个可以使用代理的控制器
# ProxyHandler({'type':'ip:port'})
# type指http或https
handler = ProxyHandler()
# 创建一个能够处理特定类型请求的 opener,比如处理 HTTP 重定向、认证、代理等
opener = build_opener(handler)
# 使用自定义的 opener 打开 URL
resp = opener.open(req)
# 打印响应信息
print(resp.read().decode())运行结果如下:
然后去网上找一个免费的代理,并将类型,ip地址和端口号填入ProxyHandler方法中,以下是我找到的免费代理:

修改后的代码如下:
python
from urllib.request import Request,build_opener,ProxyHandler
from fake_useragent import UserAgent
url = "http://httpbin.org/get"
ua = UserAgent()
header = {"User-Agent":ua.chrome}
# 创建请求对象
req = Request(url,headers=header)
# 构建一个可以使用代理的控制器(创建代理处理器)
# ProxyHandler({'type':'ip:port'})
# type指http或https
handler = ProxyHandler({"https":"119.39.76.253:80"})
# 创建一个能够处理特定类型请求的 opener,比如处理 HTTP 重定向、认证、代理等
opener = build_opener(handler)
# 使用自定义的 opener 打开 URL
resp = opener.open(req)
# 打印响应信息
print(resp.read().decode())运行结果如下:
3.4、cookie的使用
概述:Cookie 是存储在用户浏览器中的小数据文件,用于保存用户的会话信息、偏好设置和跟踪用户行为,以便网站在后续访问时能够提供个性化服务和维持状态。
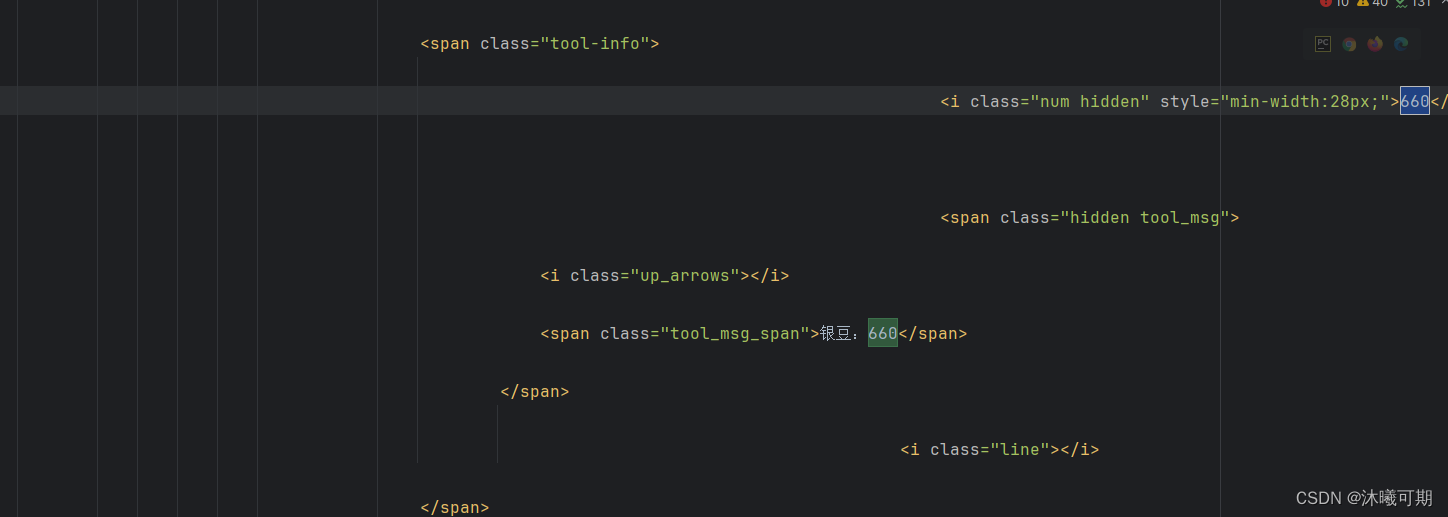
实操16:获取某牙直播平台个人信息中的银豆数量(要登录才能获取到):
python
# 当请求头不包含cookie时
from urllib.request import urlopen,Request
from fake_useragent import UserAgent
url = "https://i.huya.com/"
header = {"User-Agent":UserAgent().chrome}
# 创建请求对象
req = Request(url,headers=header)
# 发送请求
resp = urlopen(req)
# 获取响应信息
with open("myblog.html","w",encoding="utf-8") as f:
f.write(resp.read().decode("utf-8"))获取的文件内容如下:
通过搜索并不能找到我们的银豆信息。
然后通过浏览器开发工具-->网络-->表头-->复制cookie信息-->将cookie信息补充到请求头:
python
from urllib.request import urlopen,Request
from fake_useragent import UserAgent
url = "https://i.huya.com/"
header = {"User-Agent":UserAgent().chrome,"Cookie":"udb_guiddata=79a3df881af44e69a33b38efcf5534ec; udb_deviceid=w_766286372399177728; __yamid_tt1=0.2543070640208269; __yamid_new=CA79F7AF9500000186581840F3A07DB0; game_did=wEnyJNHSc3IPY42Ye1gYhtXpuxBwho7u81J; alphaValue=0.80; sdidshorttest=test; first_username_flag=_first_1; guid=0a7d311d6cc52c6548014efb4ffb8854; huya_ua=webh5&1.0.0&huya; SoundValue=1.00; videoBitRate=4000; Hm_lvt_51700b6c722f5bb4cf39906a596ea41f=1714224261,1714567558,1715442596,1715782218; isInLiveRoom=; guid=0a7d311d6cc52c6548014efb4ffb8854; udb_passdata=3; __yasmid=0.2543070640208269; udb_biztoken=AQAgl54WAlOTGGJfulS_jJzqYrugI97HI6dEqqCl32EkkyW31z1Mg-eC5EwqXLKnNSgWGEMH4azeTCR6eg2f-5hvNFTP_CAdgteny7G7ewQUqQc5dV2cBHQMAr45IVuXlRXTl6eKANOlwOgYdIXwaFyCBZbzengk0Do2r6O9E8gPI5yDLKiHVRRo1RuxPlJ-ARDq-3mxSLGFZ71YzT3CY3yUink5iovbxUgB1T04YM3jUvI6SmRCsdcVBf4lnh-WXIczW7lw0-6fjztHcFCeDdhbpDsd8dWpdt-nliiJocb3I8CvcbczhAF61otmgvcN_SnNNyBn4XKkzPU6HFp2-_BQ; udb_cred=ChDUt7N2ZX7y6sPmWk6hW_Qvoen22xzSYvISKgsb4af2E5x1eery2EMZ_mWY-UJjVXECG2iKF2gonDty-X-Its1FtEF2rLykh-3NDbcTk-uIKZOMBeIBgOlVUTMcnkHmiCJLdAkqkUaxVhOrsj30fNwq; udb_origin=100; udb_other=%7B%22lt%22%3A%221719045090434%22%2C%22isRem%22%3A%221%22%7D; udb_status=10; udb_uid=2301608087; udb_version=1.0; yyuid=2301608087; h_unt=1719045090; __yaoldyyuid=2301608087; _yasids=__rootsid%3DCACA7AABA6100001B5411115C10098E0; sdid=0UnHUgv0_qmfD4KAKlwzhqZb5S6OXLz9qXc5mn5jmM9WUEih_2-hvJz15SCjqFv-OTJvl9___NzLlUFc_RQafCT1_rTSFeqmVteLLHT-mh3DWVkn9LtfFJw_Qo4kgKr8OZHDqNnuwg612sGyflFn1du3SKTgOviL1pi6btrsOFhVUMNIsMkAGYM_6gLIfS_QA; sdidtest=0UnHUgv0_qmfD4KAKlwzhqZb5S6OXLz9qXc5mn5jmM9WUEih_2-hvJz15SCjqFv-OTJvl9___NzLlUFc_RQafCT1_rTSFeqmVteLLHT-mh3DWVkn9LtfFJw_Qo4kgKr8OZHDqNnuwg612sGyflFn1du3SKTgOviL1pi6btrsOFhVUMNIsMkAGYM_6gLIfS_QA; PHPSESSID=rk1l8j34e25mvqsd97les1e2k0; undefined=undefined; huya_flash_rep_cnt=4; huya_web_rep_cnt=35"}
# 创建请求对象
req = Request(url,headers=header)
# 发送请求
resp = urlopen(req)
# 获取响应信息
with open("myblog.html","w",encoding="utf-8") as f:
f.write(resp.read().decode("utf-8"))运行结果如下:
3.5、登录后保持cookie
概述:为实现Cookie不丢失可以通过urllib.request.HTTPCookieProcessor来扩展opener的功能。
由于目前学到的登录方式无法登录绝大多数网站,下面贴出参考代码以供参考:
python
from urllib.request import Request,build_opener
from fake_useragent import UserAgent
# 用于转码
from urllib.parse import urlencode
from urllib.request import HTTPCookieProcessor
# 登录界面地址
login_url ='https://www.kuaidaili.com/login/'
# 用于登录的参数
args = {
'username':'398707160@qq.com',
'passwd':'123456abc'
}
# 请求头
headers = {
'User-Agent':UserAgent().chrome
}
# 创建请求对象,封装请求参数
req = Request(login_url,headers= headers,data = urlencode(args).encode())
# 创建一个可以保存cookie的控制器对象
handler = HTTPCookieProcessor()
# 构造发送请求的对象
opener = build_opener(handler)
# 登录
resp = opener.open(req)
'''
-------------------------上面已经登录好----------------------------------
'''
# 登录成功后的页面地址
index_url ='https://www.kuaidaili.com/usercenter/overview'
index_req = Request(index_url,headers =headers)
index_resp = opener. Open(index_req)
with open("test.html","wb",encoding="utf-8") as f:
f.write(index_resp.read())3.6、请求异常处理
概述:当程序访问的资源路径存在错误时,错误情况又分为根目录正确 与 根目录错误两种情况,它们的状态码路径存在差异,可通过调试程序了解。
python
from urllib.request import Request,urlopen
from fake_useragent import UserAgent
from urllib.error import URLError
# 请求地址和请求头信息
url = "https://baidu.com/abcdefg"
header = {"user-agent":UserAgent().chrome}
# 封装请求参数
req = Request(url,headers=header)
try:
# 发送请求后返回的结果
resp = urlopen(req)
# 打印响应信息
print(resp.read().decode()[:1000])
except URLError as e:
print("状态码如下:")
if e.args:
# e.args[0].errno是通过调试知道的
# 当请求的根目录不存在时就抛出这个状态码
print(e.args[0].errno)
else:
# 如果请求的根目录是对的就会抛出这个状态码
print(e.code)
print("程序结束")4、Requests模块
概述:Requests属于第三方模块,主要用于发送请求,并且发送请求时的参数无需转码。
4.1、Requests模块的基本使用
安装:(在Pycharm的 终端ALT+F12 中输入以下命令)
python
pip install requests运行结果如下:

requests的基本请求方式:
python
req = requests.get("http://www.baidu.com")
req = requests.post("http://www.baidu.com")
req = requests.put("http://www.baidu.com")
req = requests.delete("http://www.baidu.com")
req = requests.head("http://www.baidu.com")
req = requests.options("http://www.baidu.com")知识点补充:urllib发送请求与requests发送请求最大的区别在于urllib的参数需要通过urlencode()进行转码,但requests的参数无需转码即可直接发送。
实操17:尝试通过程序获取百度中有关爬虫的搜索结果(要求通过requests发送get请求获取)
python
import requests
from fake_useragent import UserAgent
# 测试get请求
def Get():
# 目标地址
url = "https://www.baidu.com/s"
# 请求头
header = {"User-Agent":UserAgent().chrome}
# 传递的参数
param = {"wd":"爬虫"}
# 发送get请求
resp = requests.get(url,headers=header,params=param)
# 打印结果
print(resp.text[:1500])
if __name__ == '__main__':
Get()运行结果如下:

实操18:通过requests向某校教务系统发送post请求并登录
python
import requests
from fake_useragent import UserAgent
def post():
url = 'http://某校教务系统'
header = {'User-Agent': UserAgent().chrome}
# 构建传递的参数(以下涉及个人隐私信息,所以删除部分内容用.代替)
data = {
"csrftoken": "............. .................., .....................",
"language": "zh_CN",
'yhm': '2........',
"mm": "..................................................................................................."
}
# 发送请求
resp = requests.post(url, headers=header, data=data)
# 打印结果
print(resp.text)
if __name__ == '__main__':
post()运行结果如下:

4.2、Requests伪装爬虫
概述:在前面的章节中我们已经使用fake_useragent伪装了爬虫的请求头,本章节我们将尝试利用Requests为爬虫设置代理IP。
python
import requests
from fake_useragent import UserAgent
url = "http://httpbin.org/get"
header = {"User-Agent":UserAgent().edge}
def proxy():
# 设置IP代理
proxy = {
# 参数格式:"type" : "type://ip:port"
'http':'http://47.243.166.133:18080',
}
# 发送请求
resp = requests.get(url,headers=header,proxies=proxy)
# 打印响应内容
print(resp.text)
if __name__ == '__main__':
proxy()运行结果如下:

4.3、Requests功能补充
4.3.1、设置超时时间
概述:可以通过timeout属性设置超时时间,一旦超过这个时间还没获得响应内容,就会提示错误。
python
requests.get('http://github.com', timeout=0.5)4.3.2、session自动保存cookies
概述:seesion的意思是保持一个会话,比如 登陆后继续操作(记录身份信息) 而requests是单次请求的请求,身份信息不会被记录。
python
# 创建一个session对象
s = requests.Session()
# 用session对象发出get请求,设置cookies
s.get('http://httpbin.org/cookies/set/sessioncookie/123456789') 4.3.3、SSL验证
概述:当网站报错SSL错误时可通过以下代码解决。
python
# 禁用安全请求警告
requests.packages.urllib3.disable_warnings()
resp = requests.get(url, verify=False, headers=headers)4.3.4、获取响应信息
| 代码 | 含义 |
|---|---|
| resp.json() | 获取响应内容(以json字符串) |
| resp.text | 获取响应内容 (以字符串) |
| resp.content | 获取响应内容(以字节的方式) |
| resp.headers | 获取响应头内容 |
| resp.url | 获取访问地址 |
| resp.encoding | 获取网页编码 |
| resp.request.headers | 请求头内容 |
| resp.cookie | 获取cookie |
实操20:尝试登录快代理网站,利用session保存cookie。(由于技术受限,目前该网站已经加入了滑块验证,因此无法实现post请求,所以拿到的界面是没有登录的界面,但是大家可以借鉴实操中利用requests保存cookie的思路)
python
import requests
from fake_useragent import UserAgent
url1 = "https://youtube.com/"
header = {"User-Agent":UserAgent().edge}
def timeout():
resp = requests.get(url1,timeout=0.8,headers=header)
print(f"网站编码为{resp.encoding}")
print(f"获取的网页内容为:\n{resp.text}")
def session():
url_login = "https://www.kuaidaili.com/login/"
data = {
"login_type": "1",
"username": "17........",
"passwd": "........",
"next": "/"
}
url_index = "http://www.kuaidaili.com/usercenter/overview/"
# 使用session对象保存cookie并发送post请求实现登录
s = requests.Session()
s.post(url_login,headers=header,data=data)
# 发送get请求验证session是否保存了cookie
resp = s.get(url_index,headers=header)
with open("myText.html", "w",encoding="utf-8") as f:
f.write(resp.text)
if __name__ == '__main__':
session()5、数据解析
5.1、正则表达式
概述:正则表达式是对字符串操作的一种逻辑公式,就是用事先定义 好的一些特定字符、及这些特定字符的组合,组成一个"规则字 符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑。

5.1.1、匹配规则
定位符:
| 字符 | 描述 |
|---|---|
| ^ | 匹配输入字符串开始的位置。如果设置了 RegExp 对象的 Multiline 属性,^ 还会与 \n 或 \r 之后的位置匹配。 |
| $ | 匹配输入字符串结尾的位置。如果设置了 RegExp 对象的 Multiline 属性,$ 还会与 \n 或 \r 之前的位置匹配。 |
| \b | 匹配一个单词边界,即字与空格间的位置。 |
| \B | 非单词边界匹配。 |
注意:定位符与限定符不能同时使用。
普通字符:
| 字符 | 描述 |
|---|---|
| ABC | 匹配 ... 中的所有字符,例如 aeiou 匹配字符串 "google roobit muxi" 中所有的a e o u a 字母 |
| \^ABC | 匹配除了 ... 中字符的所有字符,例如 \^aeiou 匹配字符串 "google runoob taobao" 中除了a e o u a 字母的所有字母 |
| A-Z | A-Z 表示一个区间,匹配所有大写字母,a-z 表示所有小写字母 |
| . | 匹配除换行符(\n、\r)之外的任何单个字符,相等于 \^\\n\\r |
| \\s\\S | 匹配所有字符。\s 是匹配所有空白符,包括换行,\S 非空白符,不包括换行 |
| \w | 匹配字母、数字、下划线。等价于 A-Za-z0-9_ |
特殊字符:
| 特别字符 | 描述 |
|---|---|
| ( ) | 标记一个子表达式的开始和结束位置,一般用于分组。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。 |
| [ | 标记一个中括号表达式的开始。要匹配 [,请使用 \[。 |
| ? | 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配 ? 字符,请使用 \?。 |
| \ | 将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, 'n' 匹配字符 'n'。'\n' 匹配换行符。序列 '\' 匹配 "",而 '(' 则匹配 "("。 |
| { | 标记限定符表达式的开始。要匹配 {,请使用 \{。 |
| | | 指明两项之间的一个选择。要匹配 |,请使用 |。 |
非打印字符:
| 字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。例如, \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 'c' 字符。 |
| \f | 匹配一个换页符。等价于 \x0c 和 \cL |
| \n | 匹配一个换行符。等价于 \x0a 和 \cJ。 |
| \r | 匹配一个回车符。等价于 \x0d 和 \cM |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 \\f\\n\\r\\t\\v。注意 Unicode 正则表达式会匹配全角空格符。 |
| \S | 匹配任何非空白字符。等价于 \^ \\f\\n\\r\\t\\v |
| \t | 匹配一个制表符。等价于 \x09 和 \cI |
| \v | 匹配一个垂直制表符。等价于 \x0b 和 \cK |
限定符:
| 字符 | 描述 |
|---|---|
| * | 匹配前面的子表达式零次或多次。例如,zo* 能匹配 "z" 以及 "zoo"。* 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,'zo+' 能匹配 "zo" 以及 "zoo",但不能匹配 "z"。+ 等价于 {1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 、 "does" 中的 "does" 、 "doxy" 中的 "do" 。? 等价于 {0,1}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,'o{2}' 不能匹配 "Bob" 中的 'o',但是能匹配 "food" 中的两个 o。 |
| {n,} | n 是一个非负整数。至少匹配n 次。例如,'o{2,}' 不能匹配 "Bob" 中的 'o',但能匹配 "foooood" 中的所有 o。'o{1,}' 等价于 'o+'。'o{0,}' 则等价于 'o*'。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,"o{1,3}" 将匹配 "fooooood" 中的前三个 o。'o{0,1}' 等价于 'o?'。请注意在逗号和两个数之间不能有空格。 |
5.1.2、贪婪模式与非贪婪模式
概述:正则表达式通常用于在文本中查找匹配的字符串,Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符; 非贪婪的则相反,总是尝试匹配尽可能少的字符。
举例:正则表达式"ab"如果用于查找"abbbc",将找到"abbb"。如果使用非贪婪的数量词"ab?",将找到"a"
5.1.3、正则表达式的修饰符(可选标志)
概述:正则表达式可以包含一些可选标志修饰符来控制匹配的模式,并且多个标志可以通过按位 OR(|) 来连接。
| 修饰符 | 描述 |
|---|---|
| re.I | 使匹配对大小写不敏感 |
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,记住是多行,而不是整个字符串的开头和结尾 |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
正则表达式参考网站:正则表达式在线测试 | 菜鸟工具 (jyshare.com)
5.2、Python操作正则表达式
5.2.1、常用方法
参数说明:
pattern:表示要匹配的内容,是一个正则表达式;
string:表示用于匹配的字符串;
replace:表示要替换的内容。
python
# re.match是尝试从字符串的起始位置开始匹配的一个模式,如果不是起始位置匹配成功的话,match()就返回none
re.match(pattern, string)
python
# re.search 扫描整个字符串并返回第一个成功匹配的结果
re.search(pattern, string)
python
# re.findall 查找全部匹配的内容
re.findall(pattern,string)
python
# re.sub用于替换字符串
re.sub(pattern,replace,string)实操21:练习所有Python操作正则表达式的方法。
python
import re
# 用于匹配的字符串
my_str = "python is the best programming language in the world"
print("-----------------------match(规则,内容)测试---------------------------------")
# 精准匹配字符串是否是以p开头
m1 = re.match("p",my_str)
print(m1)
print(f"m1匹配的内容为:{m1.group()}")
# 匹配my_str字符串中从头开始最多2个字符(字符包括字母,数字和下划线)
m2 = re.match("\w{,2}",my_str)
print(m2)
print(f"m2匹配的内容为:{m2.group()}")
# 匹配my_str字符串中从头开始最多十个非空字符的内容
m3 = re.match("\S{,10}",my_str)
print(m3)
print(f"m3匹配的内容为:{m3.group()}")
print("-----------------------search(规则,内容)测试---------------------------------")
# 匹配my_str字符串中第一个以i开头,除字母i外后面的字母最大长度为5的单词
s1 = re.search("i\w{,5}",my_str)
print(f"s1匹配的内容为:{s1.group()}")
# 匹配字符串中第一个单词
s2 = re.search("\w+",my_str)
print(f"s2匹配的内容为:{s2.group()}")
# 匹配字符串中第二个单词
s3 = re.search("\s\w+",my_str)
print(f"s3匹配的内容为:{s3.group()}")
# 匹配字符串中第三个单词(运用分组)
s4 = re.search("\s\w+(\s\w+)",my_str)
print(f"s4匹配的内容为:{s4.group(1)}")
print("-----------------------findall(规则,内容)测试---------------------------------")
# 匹配my_str字符串中所有以i开头的单词(findall如果没有匹配项就会返回一个空列表)
f1 = re.findall("\si\w+",my_str)
f2 = []
# 取出多余空格
for i in f1:
j = str(i).replace(" ","")
f2.append(j)
print(f"f1匹配的内容为:{f1}")
print(f"f1去掉多余空格后的内容为:{f2}")
# 匹配new_str字符串中的网址和网址对应的文本内容
# 如果findall方法中有分组,那么该方法就会将所有分组匹配的内容返回
new_str = "<html><div><a href='https://www.baidu.com/'>百度一下</a></div></html>"
# .表示除换行外的任意字符,+表示1次或多次
f3 = re.findall("<a href='(.+)'>(\w+)</a>",new_str)
print(f"f3匹配的内容为:{f3}")
print("-----------------------sub(规则(要替换的内容),替换后的内容,内容(要替换的内容来自哪个字符串))测试---------------------------------")
# 将所有的python替换成Python
sub1 = re.sub("python","Python",my_str)
print(f"my_str替换后的内容为:{sub1}")运行结果如下:

5.2.2、正则表达式实战
实操22:对某静态新闻网站进行爬取,要求过滤出所有有关关键词"湖南"的网址及其对应的标题。
python
import re
import requests
from fake_useragent import UserAgent
url = "http://www.cdyee.com/"
# 创建请求头
header = {'User-Agent':UserAgent().edge}
# 禁用安全请求警告并发送请求
requests.packages.urllib3.disable_warnings()
resp = requests.get(url, verify=False, headers=header)
# 设置字符集(防止内容乱码)
resp.encoding="utf-8"
f = re.findall('<a .+ href=(.+)><div.+>(.*湖南.*)</div></a>',resp.text)
print(f"所有有关湖南的新闻链接及其标题有:{f}")运行结果如下:

5.3、bs4
5.3.1、bs4入门
概述:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。
Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,仅仅需要说明一下原始编码方式就可以了。
Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
bs4官网Beautiful Soup 4.4.0 文档 --- beautifulsoup 4.4.0q 文档
bs4模块安装:pycharm终端(ALT+F12)中运行
python
# 下面两种方式任选其一即可
pip install beautifulsoup4
pip install bs4运行结果如下:

知识点补充:Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,与默认解析器相比之下,lxml 解析器更加强大,速度更快,推荐安装。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, "html.parser") | 1. Python的内置标准库 2. 执行速度适中 3.文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 1. 速度快 2.文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, "lxml", "xml") BeautifulSoup(markup, "xml") | 1. 速度快 2.唯一支持XML的解析器 3.需要安装C语言库 | |
| html5lib | BeautifulSoup(markup, "html5lib") | 1. 最好的容错性 2.以浏览器的方式解析文档 3.生成HTML5格式的文档 4.速度慢 | 不依赖外部扩展 |
lxml解析器安装:pycharm终端(ALT+F12)中运行
python
pip install lxml运行结果如下:

创建bs4对象:
python
from bs4 import BeautifulSoup
# html代表要解析的内容,lxml表示使用lxml解析器进行解析
BeautifulSoup(html,"lxml")实操23:尝试利用bs4获取html代码中的标签信息。
python
from bs4 import BeautifulSoup
html = """
<title>百度</title>
<div float='left'>Welcome to Baidu</div>
<div class="info" float='right'>
<span>开始搜索</span>
<a href='www.baidu.com' target="_blank">百度一下</a>
<strong><!--注释信息--></strong>
</div>
"""
bs = BeautifulSoup(html,"lxml")
print("-----------------获取标签-----------------")
# 获取title标签的内容
print(bs.title)
# 获取div标签的内容(html中有两个div标签,但只能获取到第一个div标签,这也是bs4的缺点)
print(bs.div)
# 获取div标签内部的strong标签(即使是内部标签bs4也会逐层查找)
print(bs.strong)
print("-----------------获取属性-----------------")
# 获取第一个div容器的所有属性
print(bs.div.attrs)
# 获取a标签的href属性对应的值(下面两种写法都可)
print(f"a标签的href属性对应的值为:{bs.a.get('href')}")
print(f"a标签的href属性对应的值为:{bs.a['href']}")
print("-----------------获取内容-----------------")
# 获取title包含的文本内容(下面两种写法都可)
print(bs.title.string)
print(bs.title.text)
# 下面区分string和text(string会提取所有内容,text会解析内容后再提取)
print(f"通过string获取strong标签中的注释信息:{bs.strong.string}")
print(f"通过text获取strong标签中的注释信息:{bs.strong.text}") # 由于strong标签的内容是html中的注释标签,所以不会打印内容运行结果如下:

5.3.2、bs4进阶
5.3.2.1、find_all() 搜索文档树
①、当传入的值是字符串
概述:传入一个字符串参数,Beautiful Soup会查找与字符串完整匹配的内容。
python
#返回所有的div标签
print(soup.find_all('div'))②、当传入的值是正则表达式
概述:传入正则表达式作为参数,Beautiful Soup会通过正则表达式的 match() 来匹配内容。
python
#返回所有的div标签
print (soup.find_all(re.compile("^div")))③、当传入的值是列表
概述:传入列表参数,Beautiful Soup会将与列表中任一元素匹配的内容返回。
python
#返回所有匹配到的span a标签
print(soup.find_all(['span','a']))④、当传入的值是一个id的参数
概述:传入一个 id 的参数,Beautiful Soup会搜索每个标签的 id 对应的属性。
python
#返回id为welcom的标签
print(soup.find_all(id='welcome'))⑤、当传入的值为True
概述:True 可以匹配任何值,表示获取所有的标签。
python
print(soup.find_all(True))⑥、按CSS进行搜索
概述:通过 class_ 参数搜索所有指定CSS类名的标签。
python
# 返回class等于info的div
print(soup.find_all('div',class_='info'))⑦、按属性进行搜索
概述:通过指定容器,容器中的属性及其对应的值精确找到指定标签。
python
# 返回class属性为info的div(这里的容器,属性及其对应的值都可以进行更换))
soup.find_all("div", attrs={"class": "info"})5.3.2.1、CSS选择器
语法:
python
soup.select(参数)参数:
| 表达式 | 说明 |
|---|---|
| tag | 选择指定标签 |
* |
选择所有节点 |
| #id | 选择id为container的节点 |
| .class | 选取所有class包含container的节点 |
| li a | 选取所有li下的所有a节点 |
| ul + p | (兄弟)选择ul后面的第一个p元素 |
| div#id > ul | (父子)选取id为id的div的第一个ul子元素 |
| table ~ div | 选取与table相邻的所有div元素 |
| atitle | 选取所有有title属性的a元素 |
| aclass="title" | 选取所有class属性为title值的a |
| ahref\*="http" | 选取所有href属性包含muxi的a元素 |
| ahref\^="http" | 选取所有href属性值以http开头的a元素 |
| ahref$=".png" | 选取所有href属性值以.png结尾的a元素 |
| inputtype="redio":checked | 选取选中的hobby的元素 |
实操24:练习bs4中find_all和select方法检索指定信息。
python
from bs4 import BeautifulSoup
html = """
<title id="name">百度</title>
<div float='left' class="info">Welcome to Baidu</div>
<div class="info" float='right' id="right">
<span>开始搜索</span>
<a href='www.baidu.com' target="_blank">百度一下</a>
<strong class="muxi"><!--注释信息--></strong>
</div>
"""
bs = BeautifulSoup(html,"lxml")
print("---------------------获取整个标签---------------------")
print("---------------------find_all()---------------------")
# 通过结果可知find_all()不仅会找到所有的div标签,还会将其子标签一起获取
print(f"获取html中所有的div标签:{bs.find_all('div')}")
print()
# 获取所有id的属性值为name的标签(通过id值进行搜索)
print(f"id为name的标签:{bs.find_all(id='name')}")
print()
# 获取class的属性值为class的标签(通过css进行搜索)
print(f"class属性为info的标签为:{bs.find_all(class_='info')}")
print()
# 获取所有target属性为_blank的标签(通过属性进行搜索,这里没有指定标签类型,表示所有的标签)
print(f"target属性为_blank的标签为:{bs.find_all(attrs={'target':'_blank'})}")
print()
print("---------------------CSS选择器---------------------")
# 通过CSS选择器获取strong标签
print(bs.select("strong"))
print()
# 获取id为right的div标签下的第一个span标签
print(f"id为right的div标签下的第一个span标签:{bs.select('div#right span')}")
print()
# 获取class为muxi的标签
print(f"class为muxi的标签为:{bs.select('.muxi')}")
print()
print("---------------------获取具体的内容(和bs4基础章节的用法类似)---------------------")
# 获取id为right的div标签下的第一个span标签的文本信息(由于获取整个标签时返回的类型是列表,所以获取内容时要指定下标)
print(f"id为right的div标签下的第一个span标签的文本信息为:{bs.select('div#right span')[0].text}")
# 获取a标签的链接(下面两种方法都可)
print(f"a标签的链接为:{bs.select('a')[0]['href']}")
print(f"a标签的链接为:{bs.select('a')[0].get('href')}")运行结果如下:

5.3.3、bs4实操
实操25:获取某新闻网站的新闻标题及其对应的链接。
python
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
# 准备目标地址和请求头
url = "http://www.people.com.cn/"
header = {"User-Agent":UserAgent().edge}
# 发送请求
resp = requests.get(url,headers=header)
# 设置字符集
resp.encoding="gbk"
# 创建bs4对象
bs = BeautifulSoup(resp.text,"lxml")
# 提取数据
dic = {}
for i in range(len(bs.select("ul.list1 li a"))):
dic[bs.select("ul.list1 li a")[i].text] = bs.select("ul.list1 li a")[i].get("href")
print(dic)运行结果如下:

5.4、pyquery
官网pyquery: a jquery-like library for python --- pyquery 1.2.4 documentation
安装:pycharm终端(ALT+F12)中运行
python
pip install pyquery运行结果如下:

5.4.1、初始化方式
①、当要解析的内容是字符串时
python
from pyquery import PyQuery as pq
# 创建一个pyquery对象
doc = pq(str)
# 查找名为tagname的标签
print(doc(tagname))②、当要解析的内容是url时
python
from pyquery import PyQuery as pq
# 创建pyquery对象,该语句会发送一个 HTTP 请求获取该网页的 HTML 内容,并将其解析成一个可操作的文档对象
doc = pq(url='http://www.baidu.com')
# 在解析后的文档中查找 <title> 标签的内容并将其打印出来
print(doc('title'))③、当要解析的内容是文件时
python
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
print(doc(tagname))5.4.2、选择节点
①、选择当前节点
python
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
doc('#main #top')②、选择子节点
思路:
1、在doc中一层层写出来
2、获取到父标签后使用children方法
python
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
doc('#main #top').children()③、选择父节点
思路:到当前节点后使用parent方法
④、获取兄弟节点
思路:获取到当前节点后使用siblings方法
5.4.3、获取属性
python
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
div = doc('#main #top')
# 注意:下面的a并不是变量,而是demo.html文件中的标签a
print(a.html())
# 需要提前使用type()方法获取其类型,然后调用对应的方法获取属性
print(a.text()) # pyquery
print(a.text) #element5.4.4、获取内容
python
from pyquery import PyQuery as pq
doc = pq(filename='demo.html')
div = doc('#main #top')
# 注意:下面的a并不是变量,而是demo.html文件中的标签a
print(a.html())
print(a.text()) # pyquery
print(a.text) #element5.5、xpath
5.5.1、xpath入门
概述:之前 BeautifulSoup 的用法,已经是非常强大的库了,不过还有一些比较流行的解析库,例如 lxml,使用的就是 Xpath 语法,同样是效率比较高的解析方法。XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。XPath 是 W3C XSLT 标准的主要元素,并且 XQuery 和 XPointer 都构建于 XPath 表达之上
参考网站:
官网 lxml - Processing XML and HTML with Python
节点关系:
①、父节点(Parent)
②、子节点(Children)
③、同胞节点(Sibling):同级节点。
④、先辈节点(Ancestor):父节点的父节点(至少是爷爷辈,还可以有更深的层次关系)。
⑤、后代节点(Descendant):子节点的子节点(至少是孙子辈,还可以有更深的层次关系)。
常用路径表达式:
| 表达式 | 描述 |
|---|---|
| nodename(标签名) | 选取此节点(标签)的所有子节点 |
/ |
从根节点选取 |
// |
从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(从任意位置选取) |
. |
选取当前节点 |
.. |
选取当前节点的父节点 |
@ |
选取属性 |
通配符:
概述:XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 | 举例 | 结果 |
|---|---|---|---|
| * | 匹配任何元素节点 | xpath('div/*') | 获取div下的所有子节点 |
| @ | 匹配任何属性节点 | xpath('div@\*') | 选取所有带属性的div节点 |
| node() | 匹配任何类型的节点 |
选取若干路径:
概述:通过在路径表达式中使用"|"运算符,您可以选取若干个路径
| 表达式 | 结果 |
|---|---|
| xpath('//div` | `//table') |
谓语:
概述:谓语被嵌在方括号内,用来查找某个特定的节点或包含某个制定的值的节点。
| 表达式 | 结果 |
|---|---|
| xpath('/body/div1') | 选取body下的第一个div节点 |
| xpath('/body/divlast()') | 选取body下最后一个div节点 |
| xpath('/body/divlast()-1') | 选取body下倒数第二个节点 |
| xpath('/body/divpositon()\<3') | 选取body下前两个div节点 |
| xpath('/body/div@class') | 选取body下带有class属性的div节点 |
| xpath('/body/div@class="main"') | 选取body下class属性为main的div节点 |
| xpath('/body/divprice\>35.00') | 选取body下price元素大于35的div节点 |
运算符:
| 运算符 | 描述 | 实例 | 返回值 |
|---|---|---|---|
| 计算两个节点集 | //book | //cd | |
+ |
加法 | 6 + 4 | 10 |
-- |
减法 | 6 -- 4 | 2 |
* |
乘法 | 6 * 4 | 24 |
div |
除法 | 8 div 4 | 2 |
= |
等于 | price=9.80 | 如果 price 是 9.80,则返回 true。如果 price 是 9.90,则返回 false。 |
!= |
不等于 | price!=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
< |
小于 | price<9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
<= |
小于或等于 | price<=9.80 | 如果 price 是 9.00,则返回 true。如果 price 是 9.90,则返回 false。 |
> |
大于 | price>9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.80,则返回 false。 |
>= |
大于或等于 | price>=9.80 | 如果 price 是 9.90,则返回 true。如果 price 是 9.70,则返回 false。 |
or |
或 | price=9.80 or price=9.70 | 如果 price 是 9.80,则返回 true。如果 price 是 9.50,则返回 false。 |
and |
与 | price>9.00 and price<9.90 | 如果 price 是 9.80,则返回 true。如果 price 是 8.50,则返回 false。 |
mod |
计算除法的余数 | 5 mod 2 | 1 |
xpath筛选xml文件的节点:
①、element(元素节点):/元素节点名(例如/div用于获取所有的div)
②、attribute(属性节点):@属性名
③、text() (文本节点):/text()
④、concat(元素节点,元素节点):用于连接两个内容
⑤、comment (注释节点)
⑥、root (根节点)
5.5.2、xpath工具
①、浏览器 - 元素 - Ctrl + F
概述:首先打开浏览器开发工具(F12),点击元素选项卡,再按Ctrl+F快捷键即可打开xpath工具,然后在xpath工具中输入xpath语句即可(例如:查找所有class属性值为book-mid-info的div下的h2下的a标签//div@class='book-mid-info'/h2/a)。

②、浏览器 - 控制台 - $x(xpath表达式)
概述:首先打开浏览器开发工具(F12),点击控制台选项卡,然后在控制台中输入$x(),在小括号中写入xpath语句,最后敲回车即可。

③、浏览器插件之XPath Helper
概述:需要通过浏览器设置 - 扩展 - 获取扩展 - 搜索XPath Helper - 安装XPath Helper,走完以上流程后才能使用,点击安装后的XPath Helper,在左侧数据xpath语句,右侧就会显示对应的内容。

注意:如果想要在python中使用xpath语句,需要通过如下语句提前在终端(Alt+F12)下载lxml:
pip install lxml5.5.3、xpath实战
实操26:获取某小说网站中不同排行榜的书名及其对应的网络地址。
python
import requests
from fake_useragent import UserAgent
from lxml import etree
url = "https://www.faloo.com/"
header = {"User-Agent":UserAgent().edge}
resp = requests.get(url,headers=header)
resp.encoding = "gbk"
# 创建etree对象
e = etree.HTML(resp.text)
fic_name = e.xpath("//div[@class='bangBox']/ul/li/a/@title")
fic_url = e.xpath("//div[@class='bangBox']/ul/li/a/@href")
# 创建一个空字典,方便后面做去重
fiction = {}
for name,url in zip(fic_name,fic_url):
# 对应书名和url地址并去重
fiction[name] = url
print(fiction)运行结果如下:

5.6、JSON数据
概述:JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互;JSON和XML的比较可谓不相上下。Python 中自带了JSON模块,直接import json就可以使用了。
参考网站:
官方文档:json --- JSON encoder and decoder --- Python 3.12.4 documentation
Json在线解析网站:JSON在线解析及格式化验证 - JSON.cn
理解:json简单说就是javascript中的对象和数组,所以这两种结构就是对象和数组两种结构,通过这两种结构可以表示各种复杂的结构。
对象:对象在js中表示为{ }括起来的内容,数据结构为 { key:value, key:value, ... }的键值对的结构。在面向对象的语言中,key为对象的属性,value为对应的属性值。取值方法为 对象.key 获取属性值,这个属性值的类型可以是数字、字符串、数组、对象这几种
数组:数组在js中是中括号 括起来的内容,数据结构为 "Python", "javascript", "C++", ...,取值方式和所有语言中一样,使用索引获取,字段值的类型可以是 数字、字符串、数组、对象几种
Python中的json模块:
概述:json模块提供了四个功能:dumps,dump,loads,load。
json.loads()
概述:json.loads() 的主要作用是将 JSON 格式的数据转换为 Python 中的字典、列表等数据类型。
注意:用 json.loads() 解析 ' {"city": "北京", "name": "范爷"} ' 时,键一定要用双引号包裹,否则无法解析并报错。
python
import json
strList = '[1, 2, 3, 4]'
strDict = '{"city": "北京", "name": "范爷"}'
json.loads(strList)
# [1, 2, 3, 4]
json.loads(strDict) # json数据自动按Unicode存储
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u732b'}json.dumps()
概述:json.dumps() 主要作用是将 Python 的数据结构(如字典、列表等)转换为 JSON 格式的字符串,以便存储或传输。
python
import json
listStr = [1, 2, 3, 4]
tupleStr = (1, 2, 3, 4)
dictStr = {"city": "北京", "name": "范爷"}
json.dumps(listStr)
# '[1, 2, 3, 4]'
json.dumps(tupleStr)
# '[1, 2, 3, 4]'
# 注意:json.dumps() 序列化时默认使用的ascii编码
# 添加参数 ensure_ascii=False 禁用ascii编码,按utf-8编码
json.dumps(dictStr)
# '{"city": "\\u5317\\u4eac", "name": "\\u5927\\u5218"}'
# ensure_ascii表示不转换成unicode编码,原文显示
print(json.dumps(dictStr, ensure_ascii=False))
# {"city": "北京", "name": "范爷"}json.dump()
概述:json.dump() 的主要作用是将 Python 数据结构(如字典、列表等)转换为 JSON 格式并保存到文件中。
python
import json
listStr = [{"city": "北京"}, {"name": "范爷"}]
json.dump(listStr, open("listStr.json","w"), ensure_ascii=False)
# ensure_ascii表示不转换成unicode编码,原文显示
dictStr = {"city": "北京", "name": "范爷"}
json.dump(dictStr, open("dictStr.json","w"), ensure_ascii=False)json.load()
概述:json.load() 的主要作用是将存储在文件中的 JSON 数据转换为 Python 中的字典、列表等数据类型。
python
import json
strList = json.load(open("listStr.json"))
print(strList)
# [{u'city': u'\u5317\u4eac'}, {u'name': u'\u5927\u5218'}]
strDict = json.load(open("dictStr.json"))
print(strDict)
# {u'city': u'\u5317\u4eac', u'name': u'\u5927\u5218'}5.7、jsonpath
概述:JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Python,Javascript, PHP 和 Java。JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
安装:pycharm终端(ALT+F12)中运行
python
pip install jsonpath运行结果如下:

参考文档:JSONPath - XPath for JSON
JsonPath与XPath语法对比:
概述:Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法
| XPath | JSONPath | 描述 |
|---|---|---|
/ |
$ |
根节点 |
. |
@ |
现行节点 |
/ |
.or[] |
取子节点 |
.. |
n/a |
取父节点,Jsonpath未支持 |
// |
.. |
就是不管位置,选择所有符合条件的条件 |
* |
* |
匹配所有元素节点 |
@ |
n/a |
根据属性访问,Json不支持,因为Json是个Key-value递归结构,不需要。 |
[] |
[] |
迭代器标示(可以在里边做简单的迭代操作,如数组下标,根据内容选值等) |
| |
[,] |
支持迭代器中做多选。 |
[] |
?() |
支持过滤操作. |
n/a |
() |
支持表达式计算 |
() |
n/a |
分组,JsonPath不支持 |
实操27:获取某招聘网站的所有城市信息(该网站的数据是json格式)。
python
import requests
from fake_useragent import UserAgent
import json
from jsonpath import jsonpath
# 准备目标网址和请求头
url = "http://www.lagou.com/lbs/getAllCitySearchLabels.json"
header = {""
"User-Agent": UserAgent().edge,
}
# 创建会话对象(添加cookie)
session = requests.session()
# 发送请求
resp = session.get(url, headers=header)
# 将json类型数据转换成python对象
obj = json.loads(resp.text)
# 第一个参数是转换成python对象后的数据,第二个参数是表达式(表达式必须以$开始)
name = jsonpath(obj,"$..name")
city = []
for i in name:
city. Append(i)
print(city)运行结果如下:

5.8、数据提取巩固练习
实操28:获取某电影网站中经典影片板块中的片名和评分。
python
from bs4 import BeautifulSoup
import requests
from fake_useragent import UserAgent
# 目标网址
url = "https://www.maoyan.com/films?showType=3"
# 创建请求头
header = {"User-Agent":UserAgent().edge}
# 创建session对象
session = requests.session()
# 发送请求
resp = session.get(url,headers=header,data={})
# 设置字符集
resp.encoding = "utf-8"
def bs4_get():
# 创建BeautifulSoup对象
soup = BeautifulSoup(resp.text,"lxml")
# 创建空字典用于后面存电影名及其对应的评分
movie = {}
# 获取电影名和评分
names = [name.text for name in soup.select('div.channel-detail.movie-item-title a')]
scores = [score.text for score in soup.select("div.channel-detail.channel-detail-orange")]
# 将电影名和评分都保存到字典中
for name,score in zip(names,scores):
movie[name] = score
print(movie)
if __name__ == '__main__':
bs4_get()运行结果如下:

实操29:利用xpath获取某电影网站中经典影片板块中的电影名称及其对应的评分。
python
import requests
from fake_useragent import UserAgent
from lxml import etree
def xpath_getdata():
# 目标地址
url = "https://www.maoyan.com/films?showType=3&offset=30"
# 准备请求头
header = {"User-Agent":UserAgent().edge}
# 创建会话对象
session = requests.session()
# 发送请求
resp = session.get(url,headers=header)
# 创建etree对象
e = etree.HTML(resp.text)
# 获取电影名
names = e.xpath("//div[@class='channel-detail movie-item-title']/@title")
# 获取评分(由于网页结构的特殊性,xpath不能完美的提取div标签下两个i标签中的文本,因此这里将所有获取的div标签中的内容转换为字符串)(div.xpath("string(.)")表示返回div标签下所有子节点的串联文本)
scores = [div.xpath('string(.)') for div in e.xpath("//div[@class='channel-detail channel-detail-orange']")]
movie = {}
for name,score in zip(names,scores):
movie[name] = score
print(movie)
if __name__ == '__main__':
xpath_getdata()运行结果如下:

实操30:利用正则表达式获取某电影网站中经典影片板块中的电影名称及其对应的评分。
python
import requests
from fake_useragent import UserAgent
import re
def re_getdata():
# 目标地址
url = "https://www.maoyan.com/films?showType=3&offset=60"
# 创建请求头
header = {"User-Agent":UserAgent().edge}
# 创建会话对象
session = requests.session()
# 发送请求
resp = session.get(url,headers=header)
# 解析数据
names = re.findall('<div class="channel-detail movie-item-title" title="(.+?)">',resp.text)
# 将每个存放评分的div获取并将内部的数据传入到get_scores方法中做进一步数据提取(注意:正则表达式里的引号要和源程序对应)
scores =[get_scores(data) for data in re.findall('<div class="channel-detail channel-detail-orange">(.+?)</div>',resp.text)]
movie = {}
for name,score in zip(names,scores):
movie[name] = score
print(movie)
def get_scores(data):
"""
该函数用于进一步确定是否有评分,如果有评分就将评分拼接,如果没有评分就直接返回原结果
"""
if data!="暂无评分":
data = ".".join(re.findall("\d+",data))
return data
if __name__ == '__main__':
re_getdata()运行结果如下:

6、爬虫效率提升
6.1、多线程
6.1.1、多线程原理
概述:爬虫使用多线程来处理网络请求,使用线程来处理URL队列中的url,然后将url返回的结果保存在另一个队列中,其它线程再读取这个队列中的数据,然后写到文件中

组成部分:
①、URL队列和响应队列
概述:将要爬取的url放在一个队列中,这里使用标准库Queue。
python
from queue import Queue
urls_queue = Queue()
out_queue = Queue()②、多线程的实现方式
概述:如果队列为空,线程就会被阻塞,直到队列不为空。处理队列中的一条数据后,就需要通知队列已经处理完该条数据
python
# 方法一:用类包装实现
import threading
class ThreadCrawl(threading.Thread):
def __init__(self, queue, out_queue):
threading.Thread.__init__(self)
self.queue = queue
self.out_queue = out_queue
def run(self):
while True:
item = self.queue.get()
python
# 方法二:利用函数包装实现
from threading import Thread
def func(args)
pass
if __name__ == '__main__':
info_html = Queue()
t1 = Thread(target=func,args=(info_html,))
python
# 方法三:利用线程池管理多线程
# 简单往队列中传输线程数
import threading
import time
import queue
class Threadingpool():
def __init__(self,max_num = 10):
self.queue = queue.Queue(max_num)
for i in range(max_num):
self.queue.put(threading.Thread)
def getthreading(self):
return self.queue.get()
def addthreading(self):
self.queue.put(threading. Thread)
def func(p,i):
time. Sleep(1)
print(i)
p.addthreading()
if __name__ == "__main__":
p = Threadingpool()
for i in range(20):
thread = p.getthreading()
t = thread(target = func, args = (p,i))
t.start()6.1.2、函数实现爬虫多线程
实操31:利用函数实现多线程+queue队列实现对某动态网站多页数据的获取,解析和保存。
python
import time
import requests
from fake_useragent import UserAgent
from threading import Thread
from queue import Queue
import json
def spider():
"""
从队列中获取url,然后拿着这个url去获取数据
"""
while not url_queue.empty():
requests_url = url_queue.get()
# 获取数据
header = {"User-Agent":UserAgent().firefox}
resp = requests.request("GET",requests_url,headers=header)
# 将获取的数据保存到队列中
data_queue.put(resp.text)
# 解析数据(从队列中拿json数据并解析成python对象)
data_py = json.loads(data_queue.get())
# 保存数据
with open("./myText.html", "a", encoding="utf-8") as f:
f.write(str(data_py).replace("},","},\n"))
# 降低请求频率
time.sleep(4)
if __name__ == '__main__':
# 创建url地址的队列
url_queue = Queue()
# 创建数据队列
data_queue = Queue()
# 初始化url,获取前5页的地址
for i in range(1,6):
url = f"https://www.hupu.com/home/v1/news?pageNo={i}&pageSize=50"
# 将产生的url放进url_queue队列中
url_queue.put(url)
# 创建三个线程
for i in range(3):
# 创建线程
th = Thread(target=spider)
# 启动线程
th.start()文件内容如下:

6.1.3、类实现爬虫多线程
实操32:利用类实现多线程+queue队列实现对某动态网站多页数据的获取,解析和保存。
python
import time
import requests
from fake_useragent import UserAgent
from threading import Thread
from queue import Queue
import json
class MyThread(Thread):
def run(self):
"""
从队列中获取url,然后拿着这个url去获取数据
"""
while not url_queue.empty():
requests_url = url_queue.get()
# 获取数据
header = {"User-Agent":UserAgent().firefox}
resp = requests.request("GET",requests_url,headers=header)
# 将获取的数据保存到队列中
data_queue.put(resp.text)
# 解析数据(从队列中拿json数据并解析成python对象)
data_py = json.loads(data_queue.get())
# 保存数据
with open("./myText.html", "a", encoding="utf-8") as f:
f.write(str(data_py).replace("},","},\n"))
# 降低请求频率
time.sleep(4)
if __name__ == '__main__':
# 创建url地址的队列
url_queue = Queue()
# 创建数据队列
data_queue = Queue()
# 初始化url,获取前5页的地址
for i in range(1,6):
url = f"https://www.hupu.com/home/v1/news?pageNo={i}&pageSize=50"
# 将产生的url放进url_queue队列中
url_queue.put(url)
# 创建三个线程
for i in range(3):
# 创建线程
th = MyThread()
# 启动线程
th.start()运行结果如下:

6.2、多进程
6.2.1、多进程思想
概述:multiprocessing是python的多进程管理包,和threading.Thread类似。multiprocessing模块可以让程序员在给定的机器上充分的利用CPU,在multiprocessing中,通过创建Process对象生成进程,然后调用它的start()方法。
python
from multiprocessing import Process
def func(name):
print('hello', name)
if __name__ == "__main__":
p = Process(target=func,args=('sxt',))
p.start()
p.join() # 等待进程执行完毕注意:在使用并发设计的时候尽可能的避免共享数据,尤其是在使用多进程的时候。 如果你真有需要共享数据,可以使用由Manager()返回的manager提供list, dict, Namespace, Lock, RLock, Semaphore, BoundedSemaphore, Condition, Event, Barrier, Queue, Value and Array类型的支持。
python
from multiprocessing import Process,Manager,Lock
def print_num(info_queue,l,lo):
with lo:
for n in l:
info_queue.put(n)
def updata_num(info_queue,lo):
with lo:
while not info_queue.empty():
print(info_queue.get())
if __name__ == '__main__':
manager = Manager()
into_html = manager.Queue()
lock = Lock()
a = [1, 2, 3, 4, 5]
b = [11, 12, 13, 14, 15]
p1 = Process(target=print_num,args=(into_html,a,lock))
p1.start()
p2 = Process(target=print_num,args=(into_html,b,lock))
p2.start()
p3 = Process(target=updata_num,args=(into_html,lock))
p3.start()
p1.join()
p2.join()
p3.join()进程池:
概述:进程池内部维护一个进程序列,当使用时,则去进程池中获取一个进程,如果进程池序列中没有可供使用的进进程,那么程序就会等待,直到进程池中有可用进程为止。
进程池的方法:apply同步执行-串行,apply_async异步执行-并行。
python
from multiprocessing import Pool,Manager
def print_num(info_queue,l):
for n in l:
info_queue.put(n)
def updata_num(info_queue):
while not info_queue.empty():
print(info_queue.get())
if __name__ == '__main__':
html_queue =Manager().Queue()
a=[11,12,13,14,15]
b=[1,2,3,4,5]
pool = Pool(3)
pool.apply_async(func=print_num,args=(html_queue,a))
pool.apply_async(func=print_num,args=(html_queue,b))
pool.apply_async(func=updata_num,args=(html_queue,))
pool.close() #这里join一定是在close之后,且必须要加join,否则主进程不等待创建的子进程执行完毕
pool.join() # 进程池中进程执行完毕后再关闭,如果注释,那么程序直接关闭6.2.2、利用函数实现多进程
实操33:利用函数实现多进程+Manager队列实现对某动态网站多页数据的获取,解析和保存。
python
import requests
from fake_useragent import UserAgent
from time import sleep
from multiprocessing import Process,Manager
import json
def spider(url_queue,data_queue):
"""
从队列中获取url,然后拿着这个url去获取数据
"""
while not url_queue.empty():
requests_url = url_queue.get()
# 获取数据
header = {"User-Agent":UserAgent().firefox}
resp = requests.request("GET",requests_url,headers=header)
# 将获取的数据保存到队列中
data_queue.put(resp.text)
# 解析数据(从队列中拿json数据并解析成python对象)
data_py = json.loads(data_queue.get())
# 保存数据
with open("./myText.html", "a", encoding="utf-8") as f:
f.write(str(data_py).replace("},","},\n"))
# 降低请求频率
sleep(4)
if __name__ == '__main__':
# 创建url地址的队列
url_queue = Manager().Queue()
# 创建数据队列
data_queue = Manager().Queue()
# 初始化url,获取前3页的地址
for i in range(1,4):
url = f"https://www.hupu.com/home/v1/news?pageNo={i}&pageSize=50"
# 将产生的url放进url_queue队列中
url_queue.put(url)
# 创建进程列表
all_process = []
# 创建三个进程
for i in range(3):
# 创建线程
pro = Process(target=spider,args=(url_queue,data_queue))
# 启动线程
pro.start()
# 将所有进程添加到进程列表中
all_process.append(pro)
# 等待所有进程结束再关闭进程
[p.join() for p in all_process]运行后的文件内容如下:

6.2.3、利用进程池实现多进程
实操34:利用进程池+Manager队列实现对某动态网站多页数据的获取,解析和保存。
python
import requests
from fake_useragent import UserAgent
from time import sleep
from multiprocessing import Pool,Manager
import json
def spider(url_queue,data_queue):
"""
从队列中获取url,然后拿着这个url去获取数据
"""
while not url_queue.empty():
requests_url = url_queue.get()
# 获取数据
header = {"User-Agent":UserAgent().firefox}
resp = requests.request("GET",requests_url,headers=header)
# 将获取的数据保存到队列中
data_queue.put(resp.text)
# 解析数据(从队列中拿json数据并解析成python对象)
data_py = json.loads(data_queue.get())
# 保存数据
with open("./myText.html", "a", encoding="utf-8") as f:
f.write(str(data_py).replace("},","},\n"))
# 降低请求频率
sleep(4)
if __name__ == '__main__':
# 创建url地址的队列
url_queue = Manager().Queue()
# 创建数据队列
data_queue = Manager().Queue()
# 初始化url,获取前3页的地址
for i in range(1,4):
url = f"https://www.hupu.com/home/v1/news?pageNo={i}&pageSize=50"
# 将产生的url放进url_queue队列中
url_queue.put(url)
# 创建进程池,括号内写进程数量
pool = Pool(3)
# 开启异步进程
pool.apply_async(func=spider,args=(url_queue,data_queue))
pool.apply_async(func=spider, args=(url_queue, data_queue))
pool.apply_async(func=spider, args=(url_queue, data_queue))
# 关闭所有进程
pool.close()
# 等待所有进程结束
pool. Join()运行后的文件内容如下:

6.3、协程
背景:网络爬虫速度效率慢,多部分在于阻塞IO这块(网络/磁盘)。在阻塞时,CPU的中内核是可以处理别的非IO操作。因此可以考虑使用协程来提升爬虫效率,这种操作的技术就是协程。
概述:协程一种轻量级线程,拥有自己的寄存器上下文和栈,本质是一个进程,相对于多进程,无需线程上下文切换的开销,无需原子操作锁定及同步的开销,简而言之就是让阻塞的子程序让出CPU给可以执行的子程序。
注意:一个进程包含多个线程,一个线程可以包含多个协程,多个线程相对独立,线程的切换受系统控制。 多个协程也相对独立,但是其切换由程序自己控制
安装:在Pycharm终端(Alt+F12)中运行如下代码
python
pip install aiohttp运行结果如下:

参考网站:Welcome to AIOHTTP --- aiohttp 3.9.5 documentation
常用方法:
| 属性或方法 | 功能 |
|---|---|
| aiohttp.ClientSession() | 获取客户端函数 |
| session.get(url) | 发送get请求 |
| seesion.post(url) | 发送post请求 |
| resp.status | 获取响应状态码 |
| resp.url | 获取响应url地址 |
| resp.cookies | 获取响应cookie内容 |
| resp.headers | 获取响应头信息 |
| resp.read() | 获取响应bytes类型 |
| resp.text() | 获取响应文本内容 |
实操35:利用aiohttp实现协程,并展示如何发送请求头和参数。
python
import aiohttp
import asyncio
from fake_useragent import UserAgent
# 定义了一个异步函数
async def header1_aiohttp():
"""
该函数用于展示利用aiohttp实现协程时放置请求头的方法1
"""
# 创建了aiohttp.ClientSession实例,并利用async with保证会话结束后能自动关闭
async with aiohttp.ClientSession(headers={"User-Agent":UserAgent().edge}) as session:
# 利用会话发送get请求,并利用async with保证使用完毕后能自动关闭
async with session.get("http://httpbin.org/get",) as resp:
rs = await resp.text()
print(rs)
async def header2_aiohttp():
"""
该函数用于展示利用aiohttp实现协程时放置请求头的方法2
"""
async with aiohttp.ClientSession() as session:
async with session.get("http://httpbin.org/get",headers={"User-Agent":UserAgent().edge}) as resp:
rs = await resp.text()
print(rs)
async def params_aiohttp():
"""
该函数用于展示利用aiohttp实现协程时如何传递参数
"""
async with aiohttp.ClientSession() as session:
async with session.get("http://httpbin.org/get",params={"key":"muxi"}) as resp:
rs = await resp.text()
print(rs)
if __name__ == '__main__':
# 获取当前线程的事件循环
loop = asyncio.get_event_loop()
# 运行一个异步任务,直到括号内的函数执行完成
loop.run_until_complete(header1_aiohttp())
loop.run_until_complete(header2_aiohttp())
loop.run_until_complete(params_aiohttp())运行结果如下:
