小罗碎碎念
本期推文主题
今天的会议很多主题都集中在大模型、多模态这两个方面,很明显,这两个方向都是目前的研究热点。

所以,我这一期推文会先简单的分析一下秦文健(中科院)和史淼晶(同济大学)两位老师,然后再分别从他们最新发表的文献中挑选一篇进行分析,从而更深入的探讨一下这个方向的发展趋势。
- CVPR|Boosting Object Detection with Zero-Shot Day-Night Domain Adaptation
- Computerized Medical Imaging and Graphics|Global contextual representation via graph-transformer fusion for hepatocellular carcinoma prognosis in whole-slide images
其中第一篇与医学无关,但是我会介绍如何将文章提出的模型迁移到医学图像的处理上(尤其是研究影像组学的要重点关注)
由于小罗是研究病理的,所以第二篇文献选的是与病理相关的,这篇文章使用的全部是公开数据集(TCGA),病例数量也不大(355例),而且就是这个月初发表的,所以要发文章也不一定非得卷内部数据集和数量(顶刊除外)。
厦门之旅总结
今天MICS会议就要接近尾声了,我也即将返程,由于是晚上的高铁,所以在世茂海峡大厦找了一家汉堡王,坐着写完了这篇推文。
昨晚组织了一个小型的群友见面会,虽然到场的人数不多,但是交流的内容还是很丰富的,六点多开始吃,一直聊到店铺打烊才走。
这次厦门之行收获很大,印证了自己的一些想法,也对未来的规划做了一些调整。
说实话,我之前其实和自己老板的某些观念是冲突的,但是经历的越多,就越觉得老板说的有道理。昨晚饭后,和两位老师在商场外面又聊了一会儿,其中一位老师和我说,硕士期间的第一篇论文是很慢的,后面的就快了。只要一放松,三年的时间一下就过去了。
所以呀,接下来要踏踏实实搞课题了。年轻人有活力有想法是好事,但是也一定要扎实,要实实在在的做出一些成果。与看推文的同行共勉,加油!!
一、讲者介绍
1-1:秦文健 中科院
- 职位: 博士生导师,研究员
- 工作单位: 中国科学院深圳先进技术研究院
- 研究领域 :
- 多模态肿瘤图像计算成像与智能分析
- 图像重建、分割、建模和可视化

招生信息
- 招生专业: 生物医学工程、模式识别与智能系统、电子信息
- 招生方向: 多模态医学影像智能分析、智能计算成像、医学物理
教育背景
- 斯坦福大学: 联合培养博士生(2016-2017)
- 中国科学院大学: 博士研究生(2015-2019),硕士研究生(2009-2012)
工作经历
- 研究员: 2024年至今
- 高级工程师: 2018-2023
- 工程师: 2013-2018
- 助理工程师: 2012-2013
社会兼职
- 中国科学院青年创新促进会: 副会长(2023年至今)
- 广东省精准医学应用学会: 青委会副主任委员(2020-2023)
- 广东省生物医学工程学会智能介入医学分会: 常务委员(2020-2023)
专利与奖励
- 奖励信息: 包括省级一等奖、国家级二等奖等
- 专利成果: 包括语义分割方法、三维重建装置、多模态影像引导放射治疗配准方法等,共列出47项发明专利和实用新型专利
实验室网站

1-2:史淼晶 同济大学
基本信息
- 姓名: 史淼晶
- 职位: 教授,博士生导师
- 身份: 国家级高层次人才

教育与工作经历
- 本科: 2010年,同济大学
- 博士: 2015年,北京大学,期间有英国牛津大学和法国INRIA的联合培养经历
- 博士后: 2015-2017年,英国爱丁堡大学
- 研究员: 2017-2019年,法国国家信息与自动化研究院
- 教职: 自2020年起,历任英国伦敦国王学院(KCL)信息系助理教授、副教授,并创立视觉计算实验室(VISCOM)
- 现任: 同济大学电子与信息工程学院控制科学与工程系教授,伦敦国王学院信息系客座教授
代表性奖励与荣誉
- 2022年: 伦敦国王学院年度表彰奖,英国高等教育学会会士(FEA)
- 2019年: 国家海外高层次人才引进计划获选,法中委员会个人创新奖
- 2018年: 法国科创协会"40位40岁以下AI人才"
- 2015年: 北京大学"学术十杰"
科研与项目
-
研究方向:
- 计算机视觉与机器学习
- 自然图像
- 医学与遥感图像
-
研究兴趣:
- 多任务学习
- 小样本学习
- 自监督/半监督学习
-
学术成果: 发表50余篇论文,主要在CVPR、ICCV、ECCV等顶级会议和期刊
-
专利与著作权: 发明专利授权2项,软件著作权1项
-
学术服务: 担任多个顶级会议的资深程序委员及期刊编辑
-
科研项目: 主持包括中国自然科学基金、英国EPSRC、欧洲ERC等多个科研项目,与NVIDIA、伦敦西敏区、法国国立图书馆等有合作
实验室网站
二、讲者文献概述
2-1:秦文健课题组
在正式分析之前,要夸一句秦老师课题组做的这个网站,比大部分的课题组都要弄的专业,非常适合展现组内的研究成果。
由于小罗是研究病理的,所以我就分析一篇秦老师课题组在月初发表的与病理相关的文献。
| 期刊 | IF | |
|---|---|---|
| Global contextual representation via graph-transformer fusion for hepatocellular carcinoma prognosis in whole-slide images | Comput. Med. Imaging Graphics | 5.4 |

2-2:史淼晶课题组
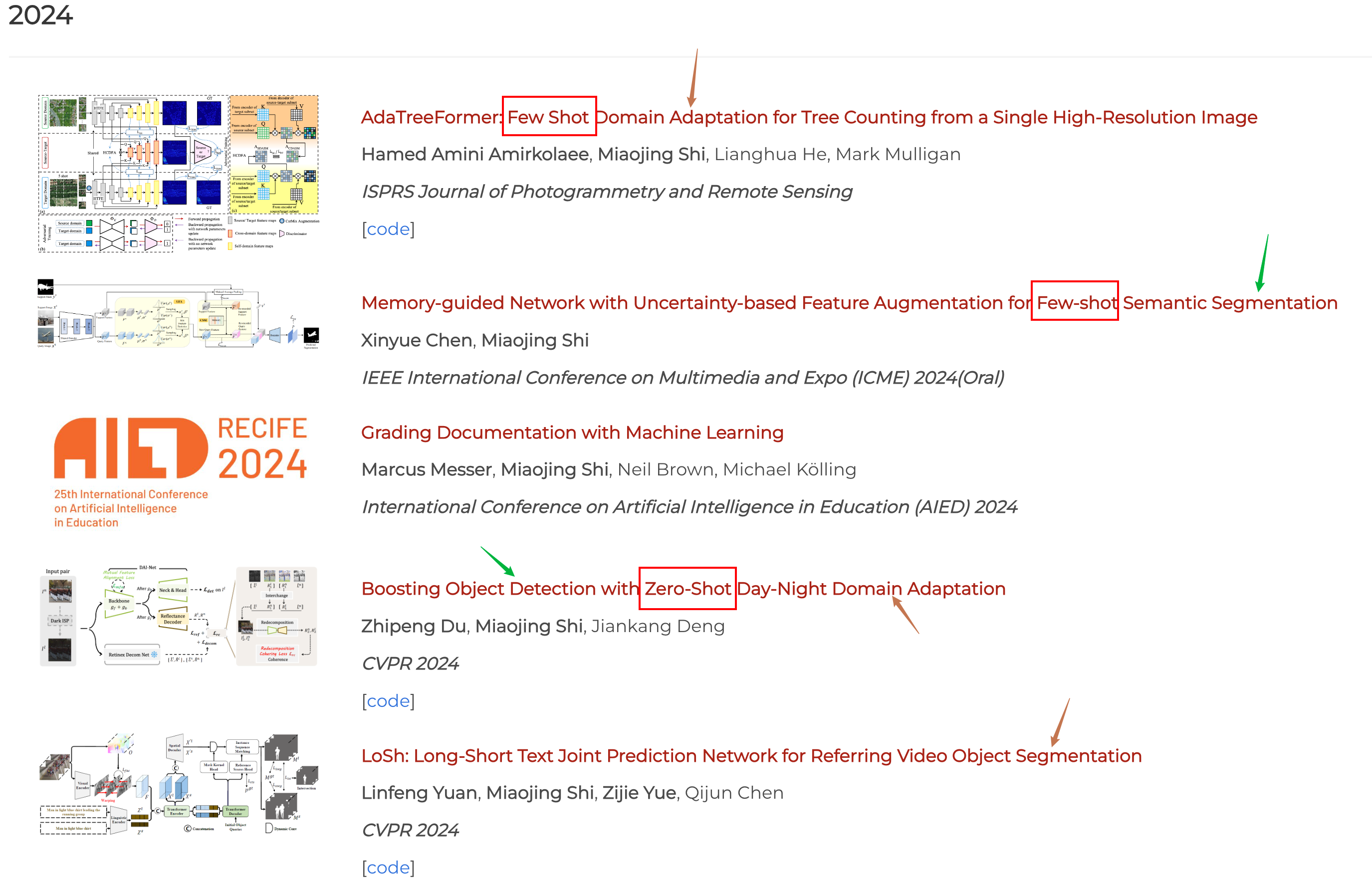
史老师课题组的产出十分可观,有很多预印本挂在arXiv上,我这里直节选部分已经正式发表的文献进行分析。
我下面这张图做了三种标记:
- 红框:Few Shot&Zero-Shot
- 绿色箭头:Segmentation
- 棕色箭头:Domain Adaptation
Few Shot&Zero-Shot在医学图像分析领域的应用
在医学图像分析领域,Few Shot Learning(小样本学习)和Zero-Shot Learning(零样本学习)是两种重要的机器学习方法,它们旨在解决数据稀缺情况下的模型泛化和学习问题。
Few Shot Learning(小样本学习)
定义 :
小样本学习是一种机器学习范式,它关注于在只有少量标注数据的情况下训练模型。在医学图像分析中,获取大量标注数据可能成本高昂且耗时,特别是在某些罕见病种的图像识别上。
应用:
- 罕见病诊断:对于罕见疾病的诊断,可能只有少量的医学图像可供训练。小样本学习可以帮助模型学习到有效的特征表示,以提高诊断的准确性。
- 快速适应新任务:在新的医学任务或新的病种出现时,小样本学习允许模型利用已有的知识快速适应,而无需从头开始收集大量数据。
- 数据增强:通过合成或增强少量的医学图像数据,小样本学习可以提高模型对新情况的泛化能力。
Zero-Shot Learning(零样本学习)
定义 :
零样本学习是一种更为极端的情况,它指的是在没有任何标注数据的情况下训练模型。模型需要能够识别在训练阶段从未见过的类别。
应用:
- 新疾病识别:在医学研究中,可能会发现新的疾病类型。零样本学习可以帮助模型在没有相关训练数据的情况下识别这些新疾病。
- 跨领域迁移:在某些情况下,可以将模型在一个领域(如动物图像识别)学到的知识迁移到另一个领域(如医学图像分析),即使这两个领域在视觉特征上可能存在差异。
- 辅助诊断:零样本学习可以辅助医生在面对未知疾病时,通过模型的预测来获得可能的诊断建议。
技术实现
- 迁移学习:利用预训练模型在大规模数据集上学到的特征,迁移到小样本或零样本的医学图像分析任务。
- 元学习:通过训练模型快速适应新任务,即使这些任务只有少量或没有标注数据。
- 多任务学习:同时学习多个相关任务,以提高模型对新任务的泛化能力。
挑战
- 数据不平衡:医学图像数据往往存在类别不平衡问题,小样本学习需要有效处理这一问题。
- 泛化能力:零样本学习需要模型具有强大的泛化能力,以识别在训练阶段未见过的类别。
- 解释性:医学领域对模型的解释性有很高的要求,小样本和零样本学习模型需要能够提供可解释的诊断结果。
小样本学习和零样本学习在医学图像分析领域的应用,为解决数据稀缺问题提供了有效的解决方案,但同时也面临着技术和伦理上的挑战。
Domain Adaptation
Domain Adaptation(领域自适应)是机器学习中的一个重要概念,特别是在处理不同数据分布的任务时。
它涉及到将一个在特定源领域(source domain)上训练好的模型调整或迁移到一个新的目标领域(target domain),其中目标领域的数据分布与源领域不同。
领域自适应的目标是提高模型在目标领域的性能,即使目标领域上没有或只有很少的标注数据。
主要概念
-
源领域(Source Domain):
- 有大量标注数据,模型在此领域上进行训练。
-
目标领域(Target Domain):
- 数据分布可能与源领域不同,可能只有少量标注数据或没有标注数据。
-
领域偏移(Domain Shift):
- 指源领域和目标领域之间的数据分布差异。
-
迁移学习(Transfer Learning):
- 领域自适应是迁移学习的一个特例,专注于处理源领域和目标领域之间的分布差异。
应用场景
- 医学图像分析:不同医院或不同设备采集的医学图像可能具有不同的特征分布。
- 自然语言处理:不同领域(如法律、医学)的文本具有不同的术语和语言风格。
- 计算机视觉:在不同环境下拍摄的图像可能具有不同的光照、背景等特征。
技术方法
-
特征对齐:
- 通过特征提取技术,找到源领域和目标领域之间的共同特征表示。
-
对抗性训练:
- 使用生成对抗网络(GAN)等方法,使模型无法区分源领域和目标领域的特征。
-
重加权:
- 对目标领域的样本进行权重调整,以减少领域之间的差异。
-
多任务学习:
- 同时学习源领域和目标领域的任务,以提高模型的泛化能力。
-
自适应技术:
- 动态调整模型参数,以适应目标领域的数据分布。
挑战
- 分布差异:源领域和目标领域的数据分布差异可能导致模型性能下降。
- 标注数据稀缺:在目标领域上可能缺乏足够的标注数据进行有效训练。
- 模型泛化:需要确保模型在适应目标领域的同时,不失去在源领域的泛化能力。
领域自适应是解决机器学习模型在新环境下泛化能力不足的有效方法,尤其在数据标注成本高昂或难以获取的情况下。
通过领域自适应技术,可以提高模型对新数据分布的适应性,从而在多种应用场景中实现更好的性能。
三、零样本日间-夜间领域自适应模型:提升低光照物体检测性能

一作&通讯
| 角色 | 姓名 | 单位 | 单位(中文) |
|---|---|---|---|
| 第一作者 | Zhipeng Du | Department of Informatics | 信息学系 |
| 通讯作者 | Miaojing Shi | College of Electronic and Information Engineering | 电子信息工程学院 |
文献概述
这篇文章提出了一种名为DAI-Net的新型零样本日间-夜间领域自适应网络,通过学习光照不变的特征表示来提升低光照环境下的物体检测性能。
作者指出,在低光照条件下进行物体检测是一个持续存在的挑战,因为通常在良好光照条件下训练的检测器在低光照数据上的性能会有显著下降。
以往的方法通过探索图像增强或使用真实低光照图像数据集的物体检测技术来缓解这个问题,但这些方法受到收集和注释低光照图像的固有困难的限制。
为了解决这一挑战,作者提出了一种零样本日间-夜间领域自适应方法,目的是在不需要真实低光照数据的情况下,将检测器从良好光照场景泛化到低光照场景。
文章首先回顾了Retinex理论,并设计了一个反射率表示学习模块,通过精心设计的照明不变性强化策略来学习基于Retinex的图像中的照明不变性。
接下来,作者引入了一个交换-重构图-一致性过程,通过执行两次顺序图像分解并引入重构图一致性损失来改进传统的Retinex图像分解过程。
通过在ExDark、DARK FACE和CODaN数据集上的广泛实验,展示了该方法在低光照泛化性方面的强性能。作者还提供了代码的GitHub链接。
重点关注
"Figure 3. Feature visualization" 展示了原始图像、DSFD检测器的backbone特征以及作者提出方法的特征可视化。
这些特征图通常用于展示不同方法在处理图像时所提取的中间特征的表现。

-
原始图像:输入的原始低光照图像,用于展示特征提取的起始点。
-
DSFD 29 backbone特征:DSFD(Dual Shot Face Detector)是一种面部检测算法。这里展示的是DSFD检测器backbone网络提取的低级特征。这些特征通常包含了图像的边缘、纹理等基础视觉信息,但在低光照条件下可能不够丰富或清晰。
-
作者的方法:这展示了作者提出的DAI-Net方法提取的特征。这些特征应该在低光照条件下更加丰富和清晰,因为DAI-Net专门设计了反射率表示学习模块和重构图一致性损失来增强特征的光照不变性。
可视化的目的是比较这三种特征图,以展示作者方法在低光照条件下如何改善特征的提取和表示,从而提高物体检测的性能。
- 原始图像可能因为光照条件差而缺乏细节。
- DSFD特征可能在某些区域不够突出,难以捕捉到所有重要的视觉线索。
- 作者方法的特征图应该更加清晰,更好地突出了物体的关键部分,即使在低光照环境下也能提供更准确的物体检测信息。
这种可视化有助于读者直观地理解不同方法在特征提取上的差异,以及作者提出方法的优势。
该模型能否迁移到医学图像处理中?
文章中提出的技术是一种零样本日间-夜间领域自适应方法,主要针对的是低光照环境下的物体检测问题。
这项技术的核心在于通过学习图像中的反射率表示来实现光照不变的特征提取,并通过特定的网络结构和损失函数来优化这一过程。
将这种技术迁移到医学图像处理中是有可能的,尤其是在以下几个方面:
光照和对比度变化
医学图像,如X光、CT、MRI等,可能会因为设备设置或患者条件的不同而存在光照和对比度的变化。使用领域自适应技术可以帮助算法更好地泛化到不同的图像条件。
图像增强
医学图像分析中经常需要增强图像特征以便于检测和分割。反射率表示学习可以用于改善图像质量,增强特定结构的可见性。
多模态融合
在医学图像处理中,经常需要将来自不同成像模式的数据结合起来。领域自适应技术可以帮助算法学习不同模态之间的共同特征表示。
数据稀缺问题
医学图像数据往往难以获取,特别是某些罕见病症的图像。零样本学习方法可以在只有少量或没有特定领域数据的情况下训练模型。
自动检测和分割
在医学图像分析中,自动检测和分割病灶或其他感兴趣的区域是一个重要任务。通过学习光照不变的特征,可以提高模型在不同成像条件下的鲁棒性。
然而,将这种技术迁移到医学图像处理也面临一些挑战:
- 数据特性差异:医学图像与自然图像在数据分布和特性上可能存在显著差异,需要针对性地调整网络结构和参数。
- 临床验证:医学图像处理算法需要经过严格的临床验证,确保其准确性和可靠性。
- 法规和伦理:医学领域的法规和伦理标准更为严格,算法的开发和应用需要遵循相应的指导原则。
总之,虽然文章中提出的技术在理论上可以迁移到医学图像处理中,但需要进一步的研究和验证来确保其在医学领域的有效性和安全性。
四、TransGNN: 一种融合图神经网络与Transformer的肝细胞癌病理预后预测模型

一作&通讯
| 角色 | 姓名 | 单位名称(中文) | 单位名称(英文) |
|---|---|---|---|
| 第一作者 | Luyu Tang | 中国科学院深圳先进技术研究院 | Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences |
| 中国科学院深圳先进技术学院 | Shenzhen College of Advanced Technology, University of Chinese Academy of Sciences | ||
| 通讯作者 | Wenjian Qin | 中国科学院深圳先进技术研究院 | Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences |
文献概述
这篇文章提出了一种结合图神经网络和Transformer的混合模型TransGNN,通过分析全切片图像来预测肝细胞癌的预后,表现出了优异的性能和临床价值。
文章首先介绍了HCC的背景,指出它是最常见的原发性肝癌,具有高度的侵袭性,并且患者通常在晚期被诊断。因此,开发更好的治疗策略和辅助系统疗法的潜在益处是至关重要的。
研究者设计了TransGNN模型,该模型结合了图神经网络(GNN)模块和Transformer模块,以表示WSIs中的全局上下文特征。
GNN模块构建了WSI图来明确捕获结构特征,而Transformer模块通过自注意力机制隐式学习全局上下文信息。该模型使用来自癌症基因组图谱(The Cancer Genome Atlas, TCGA)的355名HCC患者的362个WSIs进行验证,展示了令人印象深刻的性能,其一致性指数(Concordance Index, C-Index)达到了0.7308,并且在所有模型中表现最佳。
文章详细介绍了
- 数据集的来源
- 模型的工作流程
- WSI图的构建方法
- TransGNN的架构
- 损失函数的定义
- 实验设置
- 统计分析和模型评估
- 模型性能评估
- HCC生存分析
- 模型与临床参数的比较
- 放大倍率实验
- 注意力可视化
- 模型复杂性分析
最后,文章讨论了TransGNN模型的优势,包括其在风险分层和临床价值方面的性能,以及未来可能的改进方向,如结合来自不同数据库的数据、简化模型和提高模型的可解释性。
重点关注
Fig. 2 展示了基于 TransGNN 方法的肝细胞癌(HCC)生存分析的总体工作流程。
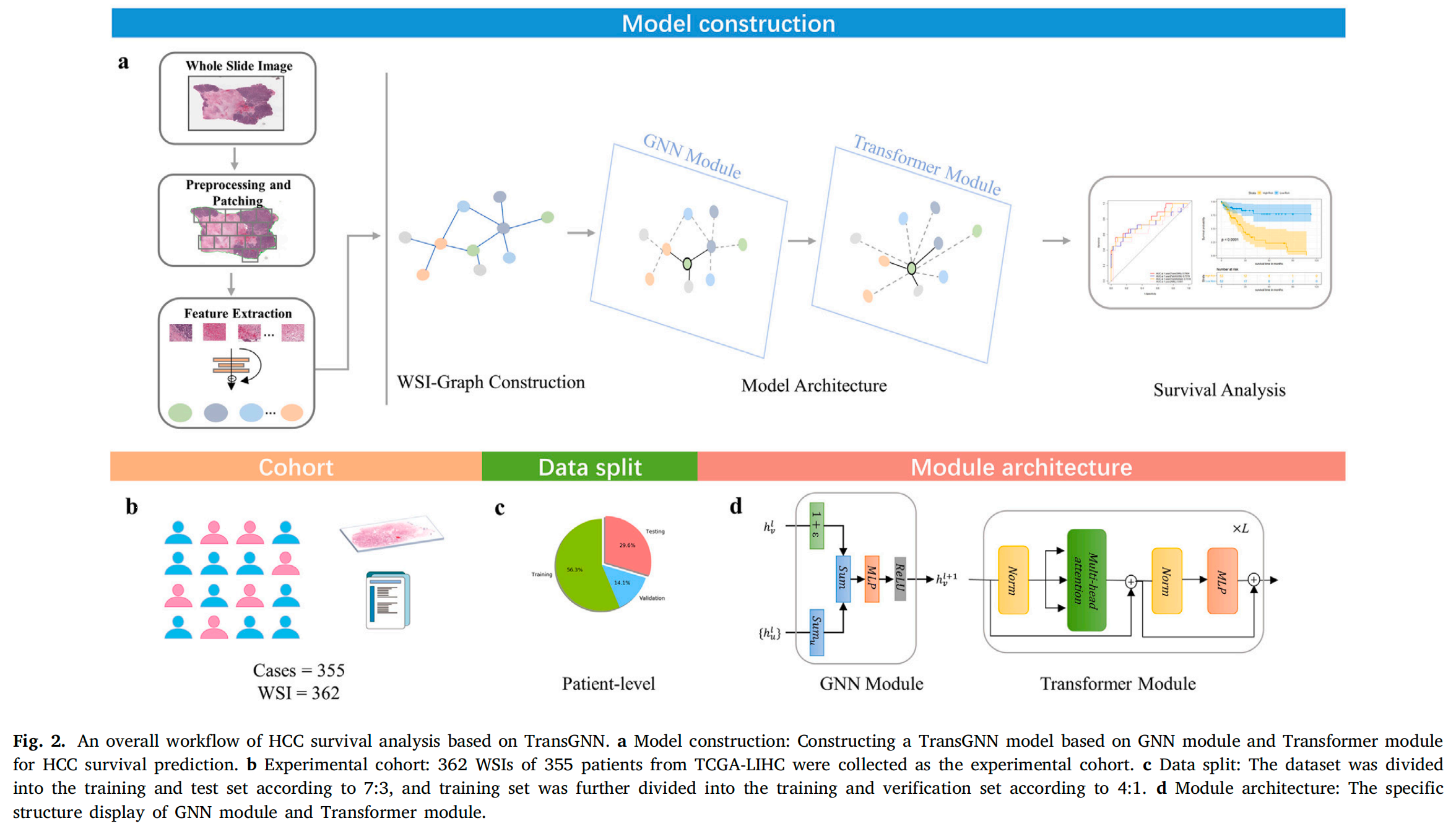
a. 模型构建 :此部分描述了 TransGNN 模型的构建过程,该模型基于图神经网络(GNN)模块和 Transformer 模块来预测 HCC 患者的生存情况。GNN 模块负责学习 WSIs 的空间邻接关系并有效捕获结构信息,而 Transformer 模块则通过自注意力机制隐式学习全局上下文信息。
b. 实验队列:本研究收集了来自癌症基因组图谱(The Cancer Genome Atlas, TCGA)的 355 名 HCC 患者的 362 个全切片图像(WSIs),作为实验队列。这些图像是进行生存分析的数据基础。
c. 数据分割 :数据集被按照 7:3 的比例分割为训练集和测试集。这样做是为了确保模型在未见过的数据上也能表现良好,从而评估模型的泛化能力。此外,训练集还被进一步按照 4:1 的比例分割为训练子集和验证子集,以便于在模型训练过程中进行交叉验证,选择最优模型。
d. 模块架构:此部分展示了 GNN 模块和 Transformer 模块的具体结构。GNN 模块利用图同构网络(Graph Isomorphism Network, GIN)结构来显式地捕获图节点间的邻接关系,而 Transformer 模块则包含多个由多头自注意力(Multi-Head Self-Attention, MHA)层、多层感知机(MLP)层以及层归一化(LayerNorm)层组成的重复块,用以隐式地学习全局上下文信息。
整体而言,Fig. 2 描述了 TransGNN 模型从数据准备到模型训练和评估的整个流程,强调了模型设计中对全局上下文信息的重视,以及如何通过结合 GNN 和 Transformer 模块来实现这一目标。