1、群里有小伙伴询问kettle连接hive的demo,今天抽点时间整理下。其实kettle连接hive和连接mysql数据库也是一样的。
1)kettle中的lib目录下放hive驱动jar,这里我使用的是kyuubi-hive-jdbc-shaded-1.9.0.jar。
2)设置hive连接参数。
3)通过表输入进行读取数据。
2、下载kyuubi-hive-jdbc-shaded-1.9.0.jar,放到lib目录下面,记得重启kettle spoon。否则不生效
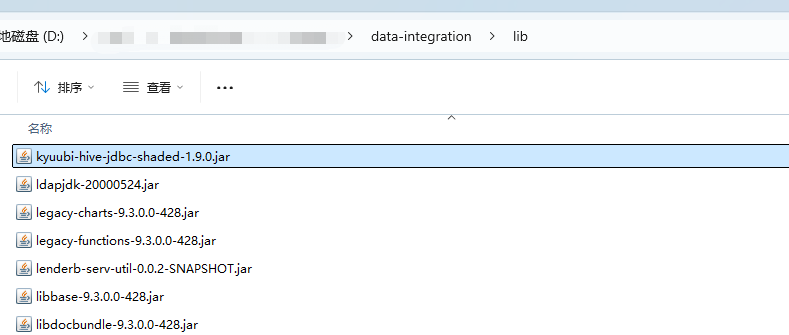
3、设置hive连接参数,我这里只设置了ip地址、数据库名称、端口信息。如下图所示:
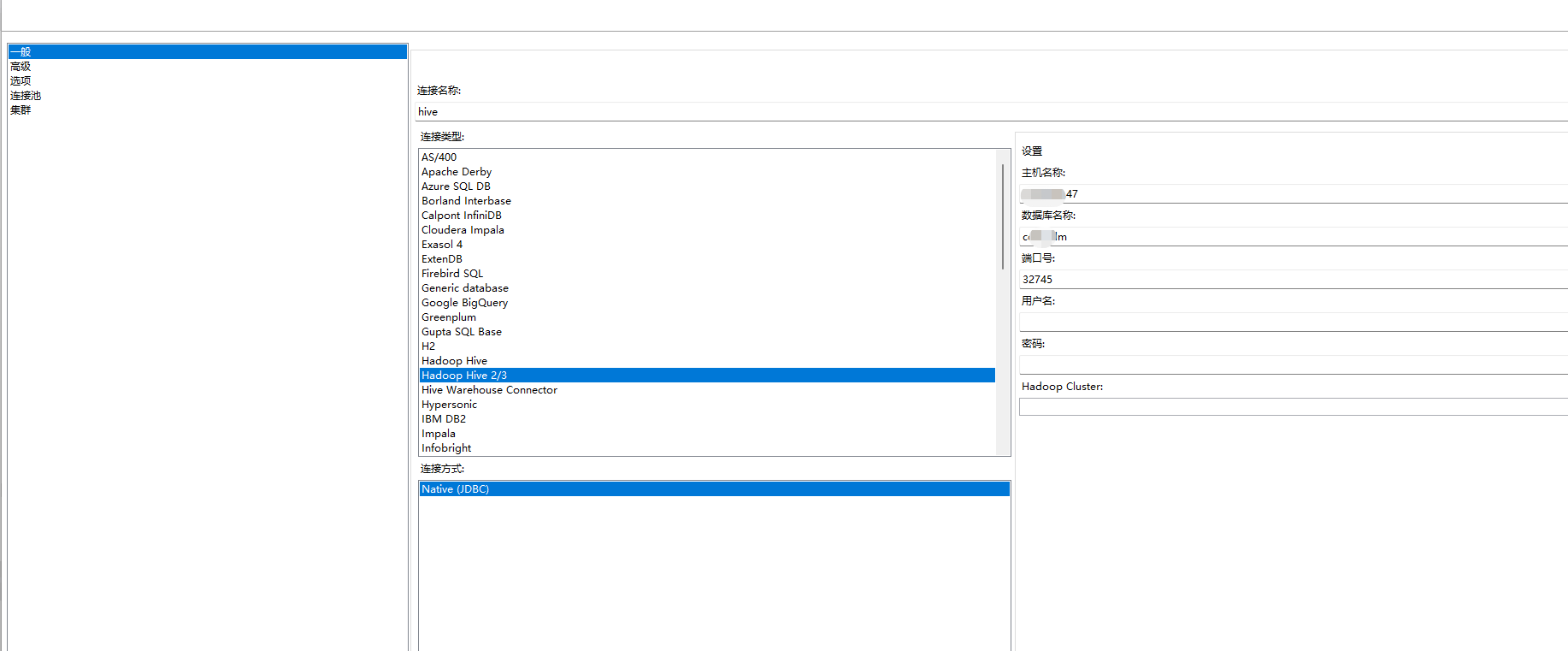
4、拖动表输入到画布,写日志步骤进行打印读取数据。表输入步骤选择之前设置的hive连接,填写select语句。如下图所示:
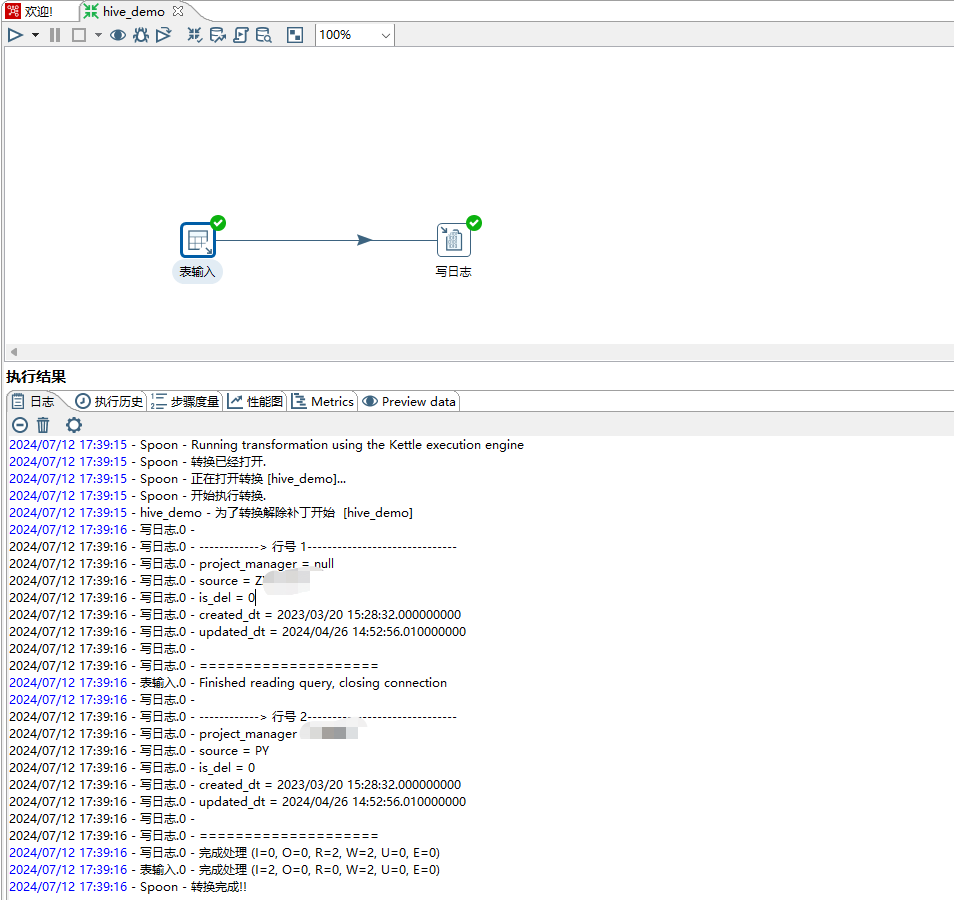
5、点击运行按钮测试,数据可以正常获取。如下图所示:
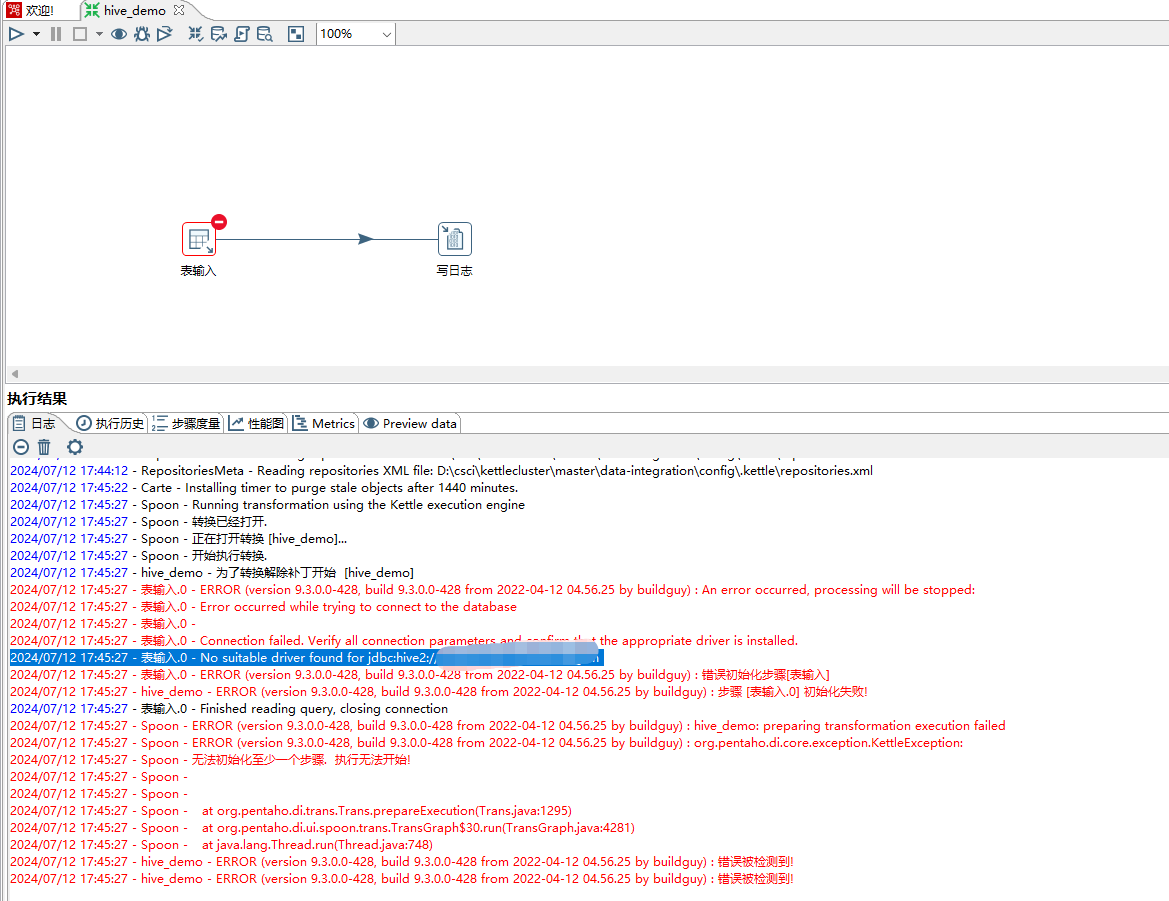
6、删除kyuubi-hive-jdbc-shaded-1.9.0.jar,重新运行,出现找不到驱动jar错误,如下图所示。
kettle支持的其他数据源也是这个流程,欢迎小伙伴们留言探讨。
