小罗碎碎念
本期文献主题:大语言模型在病理AI领域中的应用
本期推文是大模型4病理AI系列的第2期,每一篇文献都使用了ChatGpt,应用场景如下:
- 直接用ChatGpt生成回答
- 比较多种主流大模型在指定任务中的性能表现
- 比较大模型与专用模型在指定任务中的性能表现
重点关注一下第二篇文献,中山附一出品的,应用场景就是我上面列举的第三种,不过用的专用模型只是一个简单的CNN,并且研究的问题并不复杂------甲状腺结节的良恶性诊断。

一、数字病理学研究中的ChatGPT:机遇与挑战

一作&通讯
| 角色 | 姓名 | 单位(英文) | 单位(中文) |
|---|---|---|---|
| 第一作者 | Mohamed Omar | Department of Pathology and Laboratory Medicine, Weill Cornell Medicine, New York, NY, USA | 威尔康奈尔医学院病理学和实验室医学系,纽约,美国 |
| 通讯作者 | Renato Umeton | Department of Informatics & Analytics, Dana Farber Cancer Institute, Boston, MA USA | 达纳-法伯癌症研究所信息学与分析部,波士顿,美国 |
文献概述
这篇文章探讨了在数字病理学研究中整合大型语言模型(LLMs)的潜力和挑战,并强调了定制AI工具在提高研究效率和准确性方面的重要性。
-
引言:
- 数据科学和人工智能(AI)在过去二十年中改变了数据分析和解释的方式。
- 大型语言模型(LLMs)在处理文本信息方面的能力引起了广泛关注,尤其是在需要专业知识的科学领域。
-
LLMs:填补知识差距:
- LLMs如GPT-3、GPT-4等在自然语言处理方面具有广泛的应用,包括文本生成和复杂问题回答。
- 在医学研究中,LLMs的潜力在于帮助研究人员跟上新科学成果的涌入,尤其是在需要快速吸收新知识的领域。
-
LLMs的领域特定挑战:
- 尽管LLMs的能力令人印象深刻,但它们在应用到专业学科时的适应性常常受到质疑。
- 数字病理学是一个涉及从玻璃幻灯片扫描生成的组织病理学图像的新兴子领域,这一领域的快速发展对知识更新提出了挑战。
-
领域特定AI工具的进步:
- 需要为数字病理学等专业领域定制AI工具。
- 例如,BioBERT通过在生物医学文献上进行额外训练,显著提高了在生物医学研究任务中的表现。
-
数字病理学中的领域特定AI:GPT4DFCI-RAG:
- 作者团队创建了一个全面的数字病理学文献数据库,并结合GPT4DFCI(基于GPT-4 Turbo的私有和安全生成AI工具)和RAG(检索增强生成)架构,创建了GPT4DFCI-RAG。
- 该工具通过动态查询语义数据库,生成基于最新文献的准确和相关响应。
-
通过PathML和ChatGPT-4集成增强数字病理学分析:
- PathML库是计算病理学的重大进步,简化了复杂组织病理学数据集的分析。
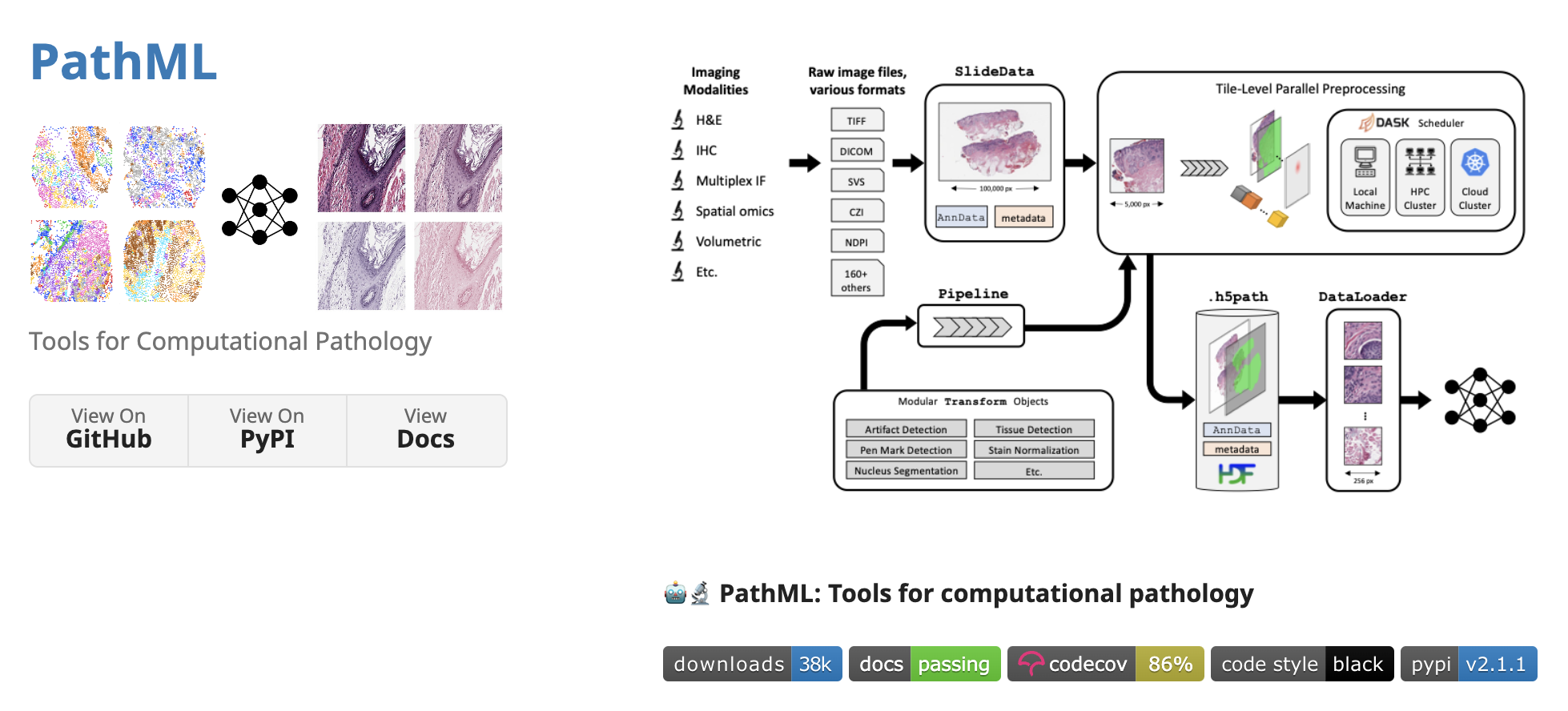
- 作者通过将PathML文档与GPT-4集成,使用户能够通过直观的聊天界面与PathML交互,获取病理图像分析的指导。
-
潜在影响:提高研究效率和教育:
- 这些AI工具可以显著提高生产力,通过简化知识获取和自动化手动或重复性任务,从而为更重要的任务腾出时间。
- 在学术出版和公共卫生领域,这些工具也显示出巨大的潜力。
-
结论:
- 领域特定文本生成AI工具有潜力显著增强医学研究和公共卫生,但其全部潜力仍在逐步展现。
- 将这些工具整合到学术和研究框架中可以提高从不断扩大的学术数据库中获取知识效率和准确性。
文章还讨论了这些工具在药物发现和制药研究中的应用,并强调了将这些工具整合到研究团队中可以减少手动工作量,提高科学研究的有效性。
重点关注
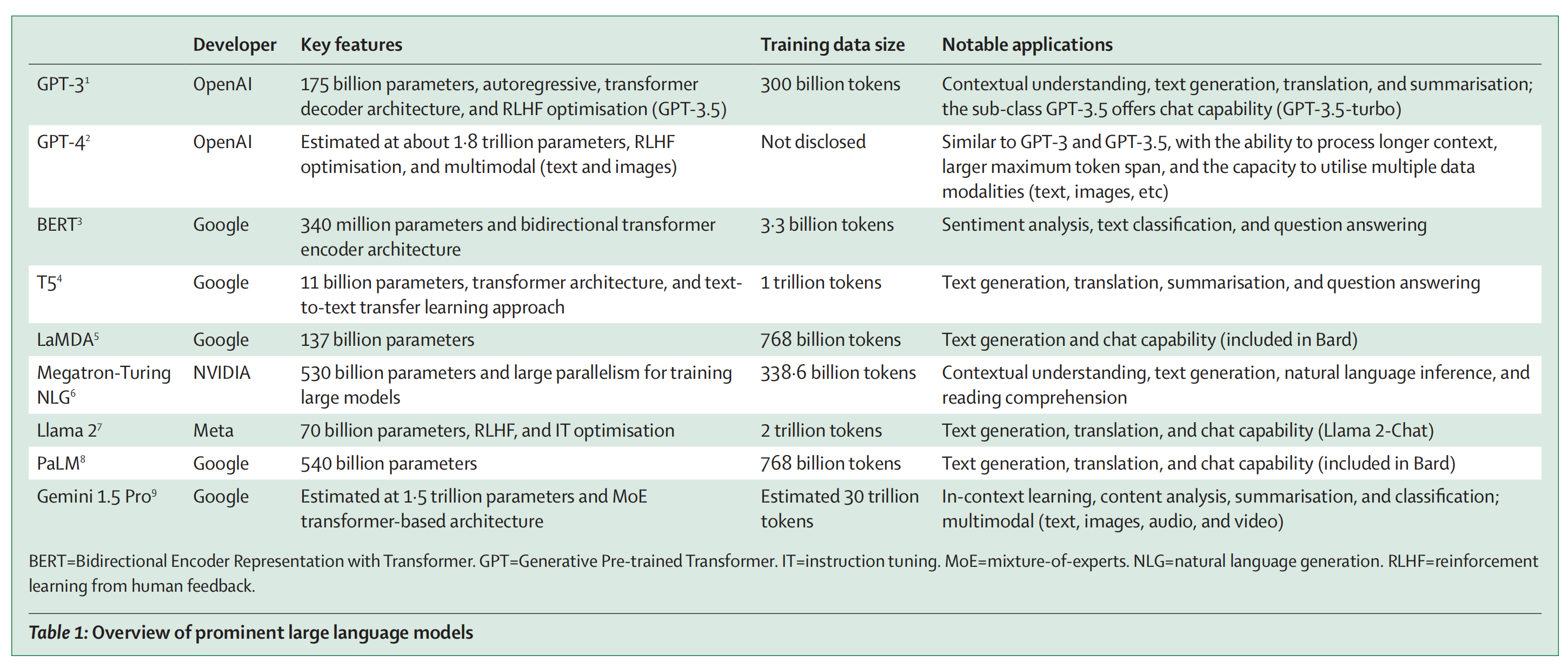
Table 1提供了当前一些主要大型语言模型(LLMs)的概述。
-
GPT-3:
- 开发者: OpenAI
- 参数量: 1750亿
- 特点: 自回归、变换器解码器架构、RLHF(人类反馈的强化学习)优化
- 训练数据量: 3000亿个token
- 应用: 语境理解、文本生成、翻译、总结;子类GPT-3.5提供聊天功能
-
GPT-4:
- 开发者: OpenAI
- 参数量: 估计约1.8万亿
- 特点: RLHF优化、多模态(文本和图像)
- 训练数据量: 未披露
- 应用: 类似GPT-3和GPT-3.5,但能处理更长的上下文、更大的最大token跨度,并能利用多种数据模态
-
BERT:
- 开发者: Google
- 参数量: 3.4亿
- 特点: 双向变换器编码器架构
- 训练数据量: 33亿个token
- 应用: 情感分析、文本分类、问题回答
-
T5:
- 开发者: Google
- 参数量: 110亿
- 特点: 变换器架构、文本到文本的迁移学习方法
- 训练数据量: 1万亿个token
- 应用: 文本生成、翻译、总结、问题回答
-
LaMDA:
- 开发者: Google
- 参数量: 1370亿
- 训练数据量: 7680亿个token
- 应用: 文本生成和聊天能力(包含在Bard中)
-
Megatron-Turing NLG:
- 开发者: NVIDIA
- 参数量: 5300亿
- 特点: 大规模并行训练大型模型
- 训练数据量: 3386亿个token
- 应用: 语境理解、文本生成、自然语言推理、阅读理解
-
Llama:
- 开发者: Meta
- 参数量: 700亿
- 特点: RLHF、IT(指令调整)优化
- 训练数据量: 2万亿个token
- 应用: 文本生成、翻译、聊天能力(Llama 2-Chat)
-
PaLM:
- 开发者: Google
- 参数量: 5400亿
- 训练数据量: 7680亿个token
- 应用: 文本生成、翻译、聊天能力(包含在Bard中)
-
Gemini 1.5 Pro:
- 开发者: Google
- 参数量: 估计1.5万亿
- 特点: MoE(专家混合)变换器基础架构
- 训练数据量: 估计3万亿个token
- 应用: 上下文学习、内容分析、总结、分类;多模态(文本、图像、音频、视频)
这些模型展示了当前大型语言模型在参数量、训练数据量和应用领域的多样性。每个模型都有其独特的特点和优化方法,使其在特定任务中表现出色。
二、大语言模型在医学影像诊断中的潜力:以甲状腺结节超声图像为例

一作&通讯
| 作者角色 | 作者姓名 | 单位名称(中文) |
|---|---|---|
| 第一作者 | Shao-Hong Wu | 中山大学附属第一医院医学超声科 |
| 第一作者 | Wen-Juan Tong | 中山大学附属第一医院医学超声科 |
| 通讯作者 | Li-Da Chen | 中山大学附属第一医院医学超声科 |
| 通讯作者 | Wei Wang | 中山大学附属第一医院医学超声科 |
文献概述
这篇文章是关于大型语言模型(LLMs)在医学影像诊断中的应用,特别是超声(US)诊断甲状腺结节的一致性和准确性。
- 背景 :
- 大型语言模型(LLMs)在医学影像解释中具有巨大潜力,但目前缺乏研究其在处理与医学诊断相关推理问题方面的可行性。
- 本研究旨在探讨利用三种公开可用的LLMs(OpenAI的ChatGPT 3.5、ChatGPT 4.0和Google的Bard)来增强基于标准化报告(病理学作为参考标准)的医学影像诊断的一致性和准确性。
- 材料与方法 :
- 收集了2022年7月至2022年12月期间来自中山大学附属第一医院的甲状腺结节超声图像及其病理结果,用于评估由三种LLMs生成的恶性诊断。
- 评估了LLMs之间的诊断一致性,并比较了它们的诊断性能,包括准确性、敏感性、特异性和接收者操作特征曲线下面积(AUC)。
- 结果 :
- 共评估了1161张 甲状腺结节超声图像(498个良性,663个恶性),来自725名患者(平均年龄42.2岁)。
- ChatGPT 4.0和Bard显示出较高的内部一致性(κ范围0.65-0.86),而ChatGPT 3.5的一致性较低(κ范围0.36-0.68)。
- ChatGPT 4.0的诊断准确性在78%-86%之间,敏感性在86%-95%之间,而Bard的准确性和敏感性分别为74%-86%和74%-91%。
- ChatGPT 4.0结合图像到文本策略的AUC为0.83,准确性为84%,与人类读者和LLMs的交互策略相当,甚至超过了仅与一名初级读者交互的策略。
- 结论 :
- LLMs,特别是与图像到文本方法结合使用时,显示出在增强诊断医学影像方面的潜力。与Bard和ChatGPT 3.5相比,ChatGPT 4.0在一致性和诊断准确性方面表现最佳。
- 研究设计 :
- 研究首先评估了三种LLMs在诊断甲状腺结节时的内部和外部一致性,然后确定了LLMs在区分良性和恶性甲状腺结节时的诊断性能,并评估了三种不同的模型部署策略:人类读者与LLMs的交互、图像到文本模型与LLMs的交互以及端到端卷积神经网络模型。
- 患者数据收集 :
- 收集了符合条件的患者的超声图像,包括良性和恶性甲状腺结节的图像,并排除了没有超声检查或病理结果的患者。
- 图像解释 :
- 提供了图像解释的详细说明,包括如何使用图像到文本模型和端到端CNN模型。
- 统计分析 :
- 使用SPSS软件进行统计分析,评估了LLMs的内部和外部一致性,并比较了不同诊断策略的性能。
- 讨论 :
- 讨论了LLMs在医学影像诊断中的潜力,强调了ChatGPT 4.0在一致性和诊断准确性方面的优势,并指出了LLMs在处理医学诊断推理问题中的可行性。
知识点补充
LLMs(大型语言模型)在诊断甲状腺结节时的内部和外部一致性评估
-
内部一致性(Intra-LLM Agreement):
- 定义:每个LLM对同一数据集的诊断结果在三次评估中的一致性。
- 方法:每个LLM对所有甲状腺结节图像进行三次独立的评估,以确定其诊断结果的重复性。
- 统计分析:使用Fleiss κ系数来评估每个LLM的内部一致性,κ值范围从0(无一致性)到1(完全一致性)。
-
外部一致性(Inter-LLM Agreement):
- 定义:不同LLMs对同一数据集的诊断结果之间的一致性。
- 方法:通过投票方法获取三个LLMs对同一甲状腺结节图像集的最终诊断结果,最常出现的结果被认定为该图像的最终诊断。
- 统计分析:使用Cohen κ系数来评估不同LLMs之间的外部一致性,κ值同样范围从0到1。
-
诊断性能评估:
- 关键指标:包括准确性(Accuracy)、敏感性(Sensitivity)、特异性(Specificity)和接收者操作特征曲线下面积(AUC)。
- 方法:计算每个LLM和部署策略的诊断性能指标,并通过比较这些指标来评估不同策略的有效性。
-
模型部署策略:
- 人类-LLM交互:人类读者首先解释图像,然后LLM基于人类读者记录的TI-RADS(甲状腺影像报告和数据系统)特征提供诊断。
- 图像到文本-LLM:使用图像到文本模型进行图像分析,然后由LLM进行诊断。
- 端到端卷积神经网络(CNN)模型:使用端到端CNN模型进行图像分析和诊断。
-
统计测试:
- McNemar测试 和Delong测试:用于比较不同诊断策略(如人类-LLM交互、图像到文本-LLM和CNN)之间的诊断性能。
通过这些方法,研究者能够评估LLMs在诊断甲状腺结节时的一致性,并比较不同LLMs和诊断策略的有效性。
端到端卷积神经网络(CNN)模型的具体作用
-
图像分析和诊断:
- 该模型直接对超声图像进行分析,以确定甲状腺结节的性质(良性或恶性)。
- 它是一个传统的端到端CNN模型,经过训练,能够从图像中提取特征并进行诊断。
-
集成多个网络:
- CNN模型集成了三个并行运行的主干网络(ResNet、DenseNet和ResNeXt),并通过投票计算来确定癌症的概率。
-
与LLMs的比较:
- CNN模型的诊断性能与LLMs(如ChatGPT 4.0和Bard)的诊断性能进行了比较,以评估不同方法在甲状腺结节诊断中的有效性。
- 该模型的诊断性能通过关键指标(如准确性、敏感性、特异性和AUC)进行评估,并与LLMs的诊断结果进行对比。
-
提供透明度:
- 与传统的深度学习模型相比,LLMs提供了更清晰的诊断步骤洞察,避免了"黑箱"操作,使得临床医生能够追踪和理解每个诊断决策背后的逻辑。
-
辅助诊断:
- CNN模型作为一种辅助工具,帮助医生在诊断过程中做出更准确的判断,尤其是在处理复杂的医学图像时。
-
数据集训练:
- CNN模型在大量图像数据集上进行了训练,以确保其在实际应用中的有效性和可靠性。
通过这些作用,文章展示了端到端CNN模型在医学影像诊断中的潜力,并与LLMs进行了比较,以确定哪种方法更适合实际的临床应用。
重点关注
Figure 1 展示了本研究的概况图,描述了三种不同的模型部署策略,并分析了它们在诊断甲状腺结节时的表现。
Top Box (顶部框)
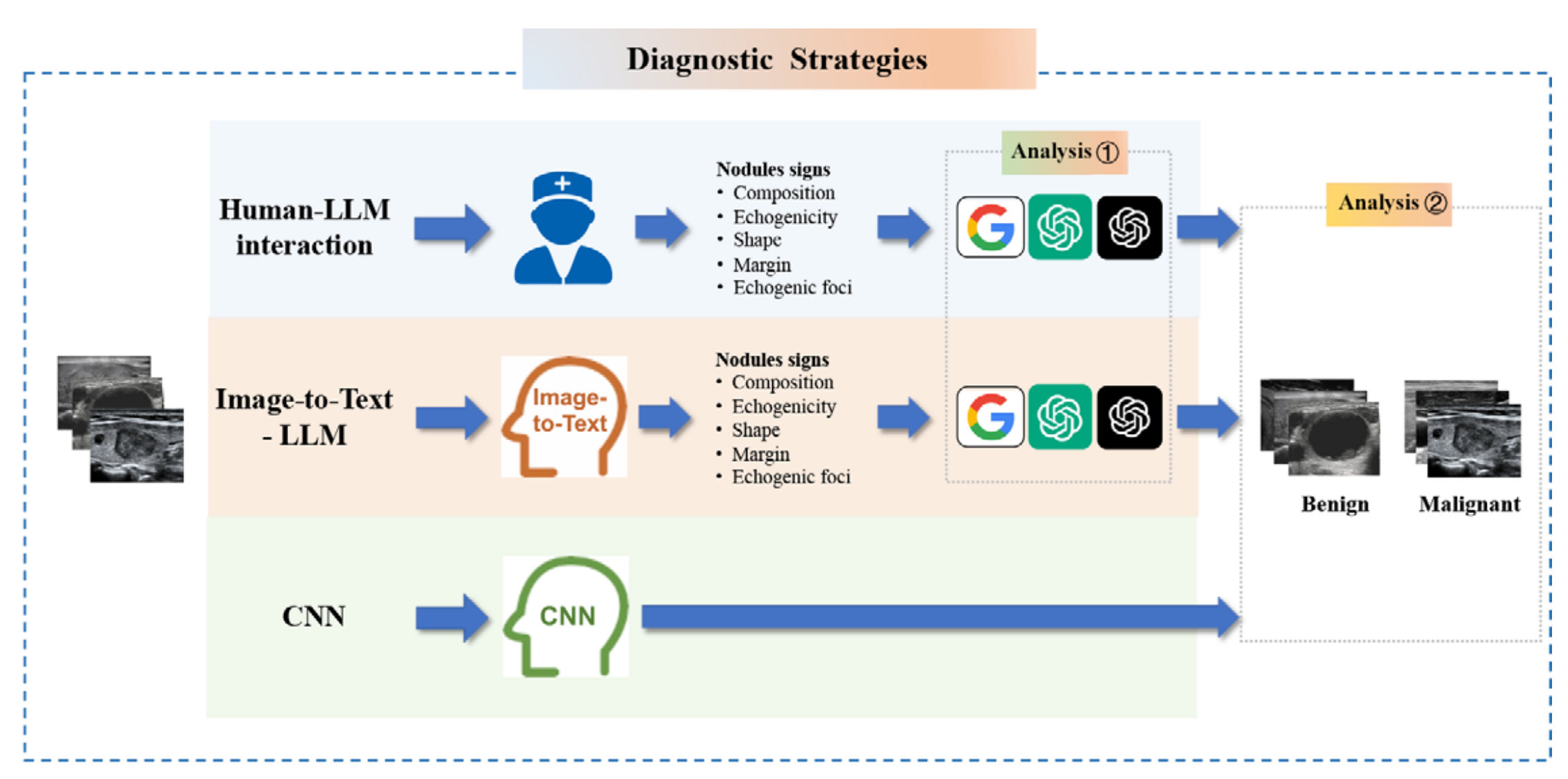
三种模型部署策略:
-
人类-LLM交互(Human-LLM Interaction):
- 人类读者首先对超声图像进行解读。
- 然后,LLM根据人类读者记录的TI-RADS(甲状腺影像报告和数据系统)特征生成诊断结果。
-
图像到文本-LLM(Image-to-Text--LLM):
- 使用图像到文本模型来分析超声图像,并提取图像特征。
- 然后,LLM根据这些文本描述进行诊断。
-
卷积神经网络(CNN):
- 使用端到端的CNN模型直接对超声图像进行分析和诊断,不依赖于人类或图像到文本模型的中间步骤。
Middle Box (中间框)
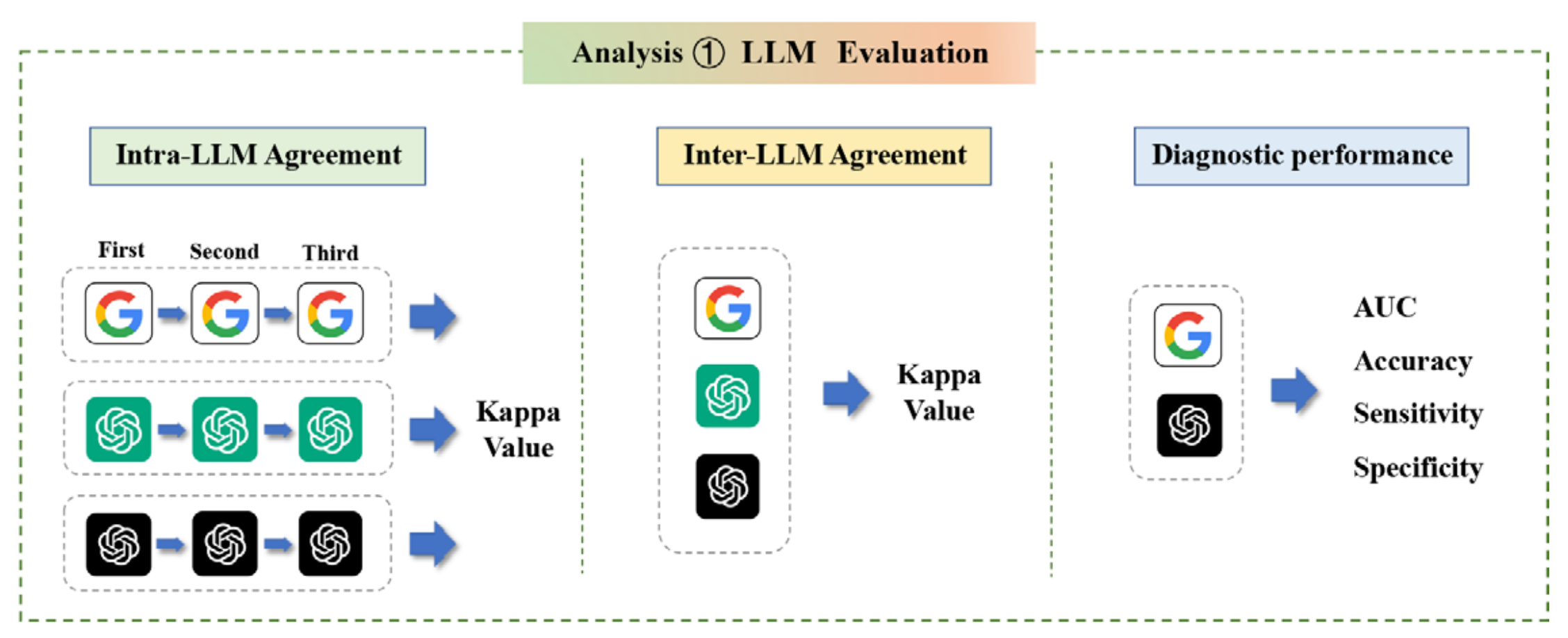
LLM一致性和诊断性能分析:
- 使用美国放射学院的甲状腺影像报告和数据系统(TI-RADS)标准来评估LLMs的诊断一致性和性能。
- 这包括评估LLMs在诊断甲状腺结节时的准确性、敏感性、特异性和接收者操作特征曲线下面积(AUC)。
Bottom Box (底部框)
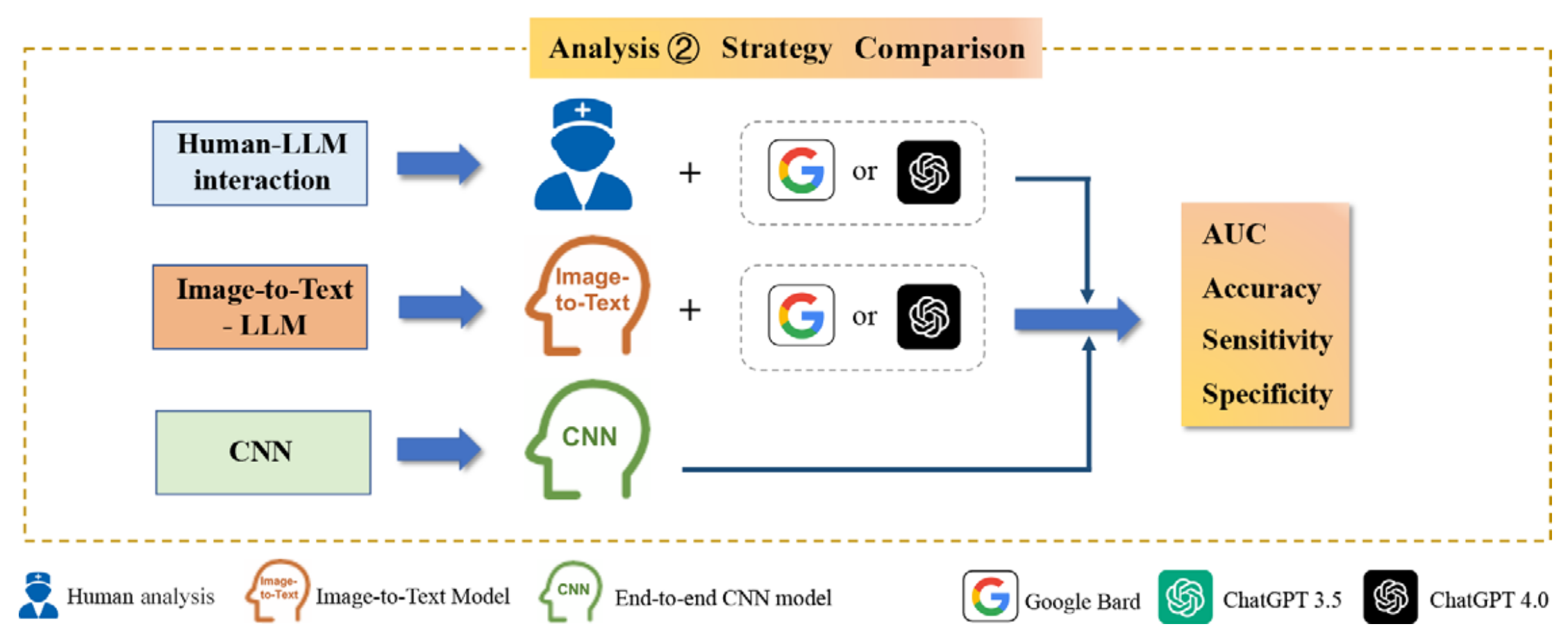
三种策略的比较:
- 对比三种策略在区分良性和恶性甲状腺结节方面的表现。
- 比较的指标可能包括但不限于诊断准确性、敏感性和特异性。
- 目的是确定哪种策略在实际应用中更为有效,尤其是在提高诊断一致性和准确性方面。
这种设计允许研究者评估每种策略的优势和局限性,并为未来的研究和临床实践提供指导。通过比较这些策略,研究旨在找到最有效的方法来提高甲状腺结节诊断的准确性和一致性。
三、AI辅助牙科诊断:一项与口腔医学住院医生的对比分析

一作&通讯
| 姓名 | 职位 | 单位(中文) |
|---|---|---|
| Hamad Albagieh | 第一作者 | 沙特国王大学口腔医学院 |
| Khalid S. Alshahrani | 通讯作者 | 沙特国王大学口腔医学院 |
文献概述
这篇文章比较了人工智能与资深住院医生在口腔病变诊断中的表现,并探讨了AI在牙科领域的应用潜力和局限性。
-
背景介绍:
- 人工智能(AI)是计算机科学领域,旨在构建能够执行通常需要人类智能的任务的智能机器。
- AI可以帮助牙医进行临床诊断和治疗计划。
-
研究目的:
- 比较AI和口腔医学住院医生在诊断不同病例、提供治疗和确定其在工作领域中辅助的可靠性。
-
研究方法:
- 对沙特国王大学牙科学院第三年和第四年的口腔医学和病理学住院医生进行了比较分析。
- 住院医生通过Google Forms进行了包含19个选择题的闭卷多项选择题测试,每个问题有四个选项(A-D)和一个有五个选项(A-E)的问题。
- 测试结果与三个主要语言模型(OpenAI、Stablediffusion和PopAI)生成的响应进行比较。
-
结果:
- 三个大型语言模型(LLM)和20名资深住院医生对20个临床病例的口腔病变诊断的响应进行了分析。
- 在20个问题中,只有两个问题(10%)的响应存在显著差异。
- LLM的中位得分为50.0(45.0到60.0),最低为40(Stablediffusion),最高为70(OpenAI)。
- 资深住院医生的中位得分为65.0(55.0-75.0),最高和最低得分分别为40和90。
- 住院医生和LLM之间的百分比得分没有显著差异(p = 0.211)。
- 使用Kappa值测量一致性,发现住院医生之间的一致性较弱(Kappa值为0.396),而LLM之间的一致性为中等(Kappa值为0.622)。
-
结论:
- 研究显示,在响应得分方面没有显著差异,但住院医生之间的一致性分析较低,而LLM之间的一致性较高。
- 牙医应考虑AI在提供诊断和治疗方面的益处,并将其用于辅助。
-
讨论:
- AI模型易于使用,提供易于理解的语言答案,并在医疗信息不足的情况下提供管理计划和治疗过程的一般指导。
- 在临床实践中使用LLM时,医疗从业者需要谨慎对待"幻觉"现象,即LLM将虚假或不准确的信息作为事实传达。
-
局限性和意义:
- 研究的样本量较小,仅限于口腔病变诊断,可能限制了发现的普遍性。
- 未来的研究应探索更广泛的医疗条件,并扩展数据集,以更全面地评估LLM在临床决策中的表现。
-
结论:
- 比较研究揭示了LLM在口腔病变诊断中的潜力和局限性。
- 尽管LLM在整体表现上与资深牙科住院医生相当,但在特定诊断准确性和治疗建议方面的具体差异需要进一步调查和完善这些模型,以确保其在临床实践中的最佳效用。
-
附录:
- 提供了20个临床病例的详细描述和问题选项。
这篇文章强调了AI在医疗领域的潜力,同时也指出了其在特定临床场景中可能存在的局限性和需要改进的地方。
重点关注
图1(FIGURE 1)展示了个别住院医生和每个大型语言模型(LLM)正确答案的比例。
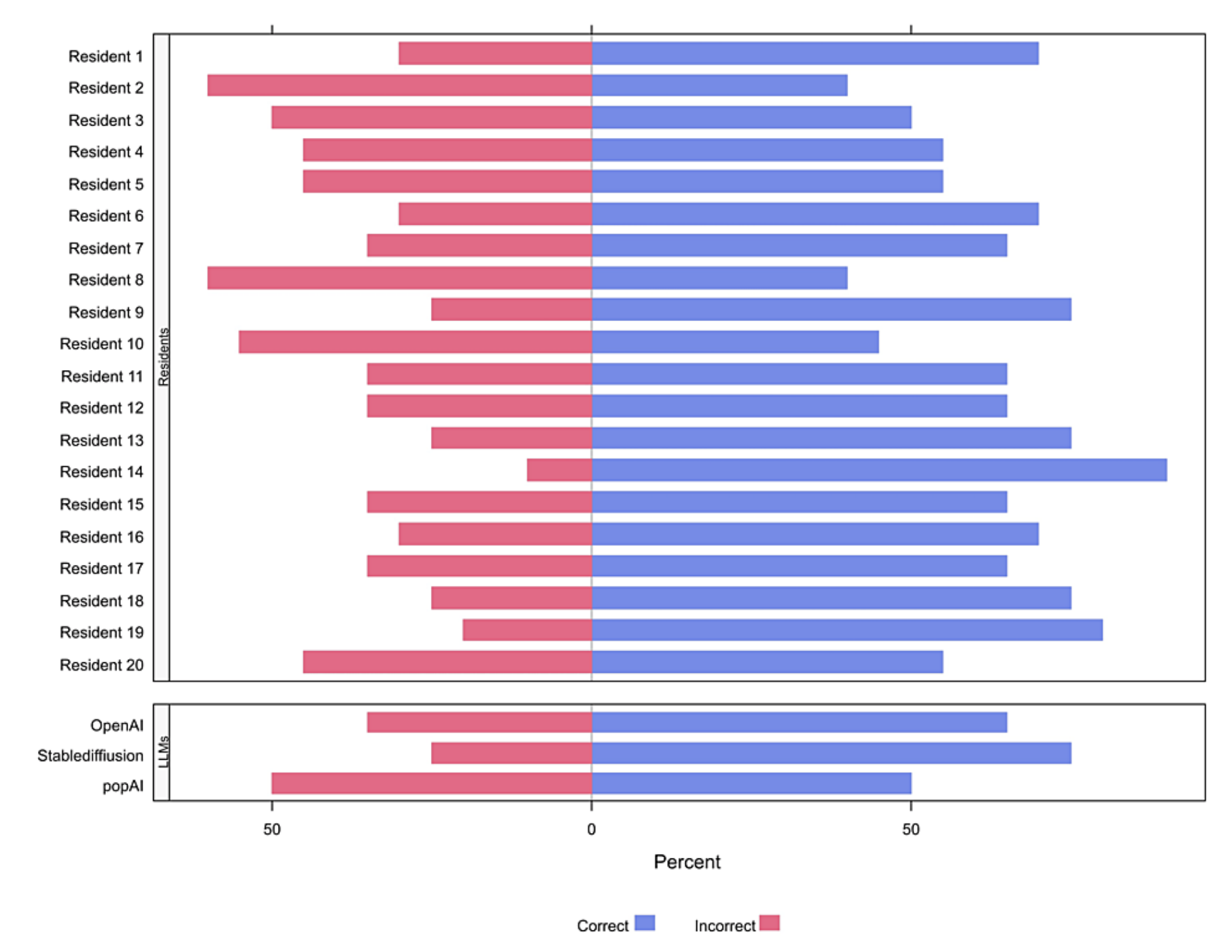
- 数据展示 :
- 图1通过条形图的形式,展示了每个住院医生和每个大型语言模型在20个临床病例诊断问题中正确答案的比例。
- 每个条形代表一个住院医生或一个语言模型。
- 比较分析 :
- 通过比较不同条形的长度,可以直观地看出不同住院医生和语言模型在诊断问题上的表现。
- 结果解读 :
- 根据图表,可以观察到住院医生和语言模型在某些问题上的表现差异。
- 例如,某些住院医生可能在特定类型的口腔病变诊断上表现更好,而某些语言模型可能在其他问题上表现更优。
总结来说,图1通过可视化的方式展示了不同参与者在口腔病变诊断问题上的表现,为读者提供了一个直观的比较和分析工具。
四、主流大语言模型在黑色素瘤管理中的比较研究:ChatGPT、BingAI和Google BARD
一作&通讯
| 作者角色 | 作者姓名 | 单位(中文) |
|---|---|---|
| 第一作者 | Xin Mu | 半岛健康整形外科部,澳大利亚维多利亚州墨尔本 |
| 第一作者 | Bryan Lim | 半岛健康整形外科部,澳大利亚维多利亚州墨尔本;莫纳什大学中央临床学院,澳大利亚维多利亚州墨尔本 |
| 通讯作者 | Ishith Seth | 半岛健康整形外科部,澳大利亚维多利亚州墨尔本;莫纳什大学中央临床学院,澳大利亚维多利亚州墨尔本 |
文献概述
这篇文章比较了Google的AI BARD、BingAI和ChatGPT在提供黑色素瘤管理建议方面的表现,发现ChatGPT在可靠性和适宜性方面略胜一筹。
-
背景:
- 大型语言模型(LLMs)是人工智能(AI)技术在自然语言处理领域的前沿应用,具有在医疗保健领域的巨大潜力。
- 黑色素瘤是一种由黑色素细胞引起的恶性肿瘤,是皮肤癌中最具有侵袭性和致命性的形式。
- AI在黑色素瘤管理中的应用包括诊断、解释测试结果和识别适合患者的临床试验机会。
-
研究目的:
- 评估和比较三个主要的LLMs(Google的AI BARD、BingAI和ChatGPT-4)在提供基于证据的黑色素瘤管理指导方面的表现。
-
方法:
- 向三个LLMs提出五个关于黑色素瘤病理学的问题,并将其回答与当前的临床指南和文献进行比较。
- 使用可靠性矩阵(包括Flesch阅读易读性评分、Flesch-Kincaid年级水平和Coleman-Liau指数)评估回答的可靠性和适宜性(使用修改后的DISCERN评分)。
- 使用t检验计算LLMs之间的平均可读性和可靠性评分差异,p值小于0.05被认为具有统计学意义。
-
结果:
- 三个LLMs的平均可读性评分相同。
- ChatGPT在可读性方面表现最佳,但其优势在统计学上不显著(p > 0.05)。
- 在适宜性方面,ChatGPT显著优于BARD(p = 0.04),但与BingAI的差异不显著。
- ChatGPT在提供与临床指南一致的医疗建议方面表现更好。
-
结论:
- 研究表明,ChatGPT在提供可靠、基于证据的临床建议方面略胜一筹,但所有LLMs在深度和特异性方面仍存在局限性。
- 未来的研究应通过整合专业数据库和专家知识来提高LLMs的性能,以支持以患者为中心的护理。
-
讨论:
- LLMs在医疗领域的应用因其快速的信息检索能力和算法决策而受到欢迎。
- ChatGPT在具体性方面表现优异,但BARD在回答问题时表现出不一致性,而BingAI则常常提供不相关的答案。
- 所有LLMs在提供可靠和当前文献方面存在不一致性,未来应考虑地区性指南和实践。
- LLMs的训练数据需要定期更新,以反映最新的临床指南和研究。
-
限制:
- 研究的评估由一组整形外科医生和住院医师(N = 7)进行,可能存在主观性和偏见。
- 使用参数配对t检验分析平均可读性和可靠性评分,可能受到异常值的影响。
-
结论:
- ChatGPT在所有测试的可靠性指标中得分较高,但其表现在深度和特异性方面不足,限制了其在个体化临床决策中的实用性。
- 医疗专业人员在解释和情境化LLM建议方面至关重要,尤其是对于需要多学科输入的复杂病例。
- 未来的研究应通过整合专业数据库和专家知识来提高LLMs的性能,并重新评估其算法中的不平等,以确保AI生成内容的可追溯性和可信度。
文章最后还提到了作者贡献、数据可用性声明和伦理声明。
重点关注
FIGURE 1 展示了对黑色素瘤最佳诊断评估方法的讨论,并要求提供五个高水平的证据参考文献。
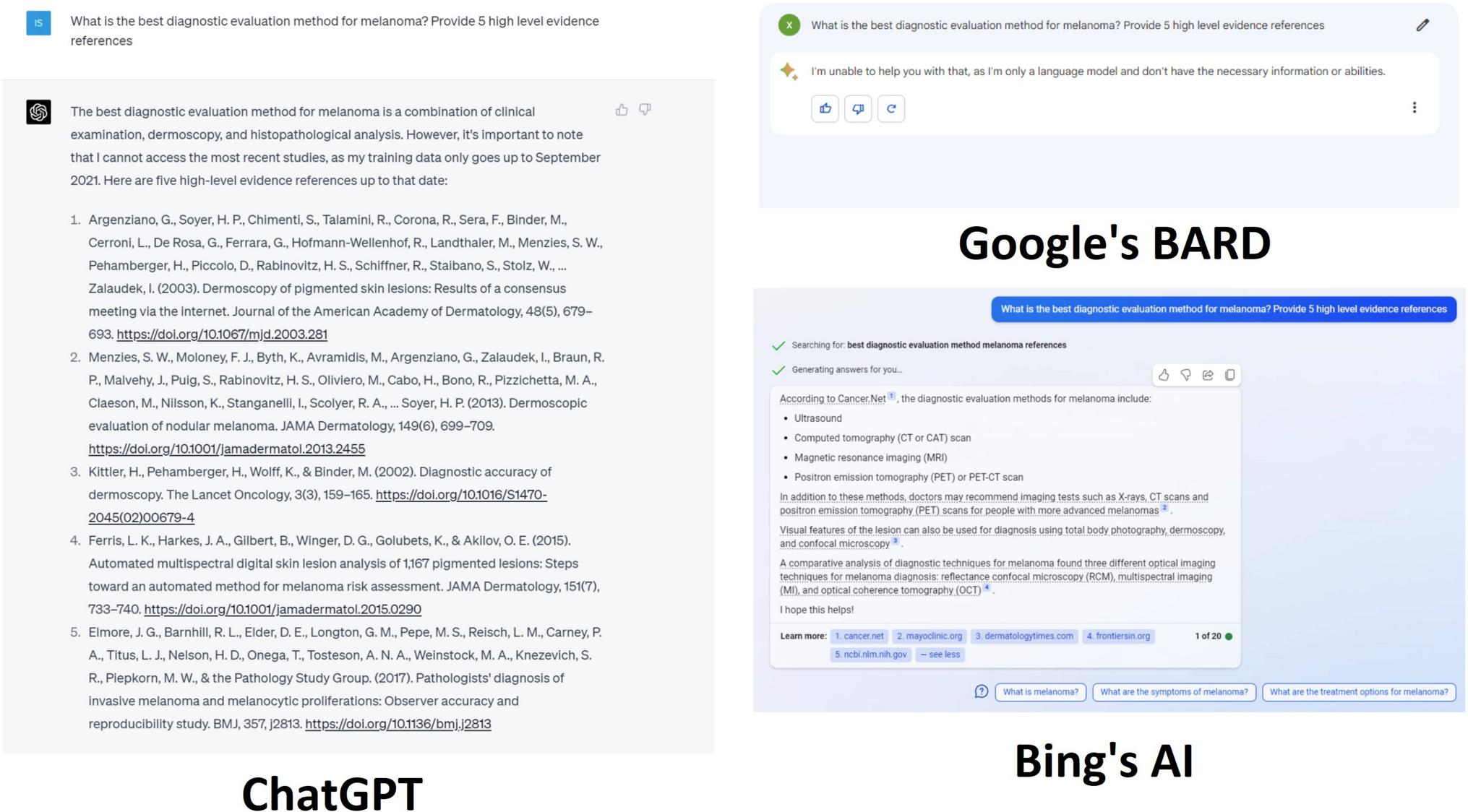
-
ChatGPT的回答:
- ChatGPT指出黑色素瘤的诊断依赖于临床和组织病理学发现,其中组织病理学是最终的诊断测试,符合国家指南。
- 提供了五个参考文献,但其中有两个参考文献存在问题:第二个参考文献的DOI不正确,第四个参考文献(Ferris, L.K. et al, 2015)不存在。
-
BingAI的回答:
- BingAI强调了放射学检查,如正电子发射断层扫描(PET)、计算机断层扫描(CT)和X射线,这些主要用于黑色素瘤诊断后分期,而不是作为初步诊断测试。
- BingAI还错误地提到反射共聚焦显微镜和光学相干断层扫描,这些更多适用于脉络膜而非皮肤黑色素瘤的监测。
-
BARD的回答:
- BARD未能提供任何关于黑色素瘤诊断的见解。
分析总结:
- ChatGPT的回答在提供诊断建议方面更接近临床指南,尽管存在参考文献的错误。
- BingAI的回答虽然提到了一些重要的诊断工具,但主要集中在分期而非初步诊断,且引用了一些不适用于皮肤黑色素瘤的技术。
- BARD未能提供有用的诊断信息。
参考文献问题:
- ChatGPT提供的参考文献中有两个问题:一个DOI错误,一个文献不存在。这表明在引用文献时可能存在准确性问题。
结论:
- ChatGPT在提供基于证据的临床建议方面表现较好,但需要确保参考文献的准确性。
- BingAI和BARD在提供黑色素瘤诊断建议方面存在明显不足,需要进一步改进其信息的准确性和相关性。
五、病理学与实验室医学中的人工智能:大语言模型的应用前景

一作&通讯
| 作者角色 | 姓名 | 单位(英文) | 单位(中文) |
|---|---|---|---|
| 第一作者 | Simone Arvisais-Anhalt | Department of Laboratory Medicine, University of California San Francisco | 加州大学旧金山分校实验室医学系 |
| 通讯作者 | Steven L. Gonias | Department of Pathology, University of California San Diego | 加州大学圣地亚哥分校病理学系 |
| 通讯作者 | Sara G. Murray | Department of Medicine, University of California San Francisco | 加州大学旧金山分校医学院 |
文献概述
这篇文章探讨了大语言模型(LLMs)在病理学和实验室医学中的应用,并提出了实施这些技术的优先事项。
- 引言 :
- 介绍了人工智能(AI)和大型语言模型(LLMs)在病理学和实验室医学中的潜在变革作用。
- 讨论了ChatGPT的发布及其对学术病理学、实验室医学和病理学教育的影响。
- LLMs的潜在应用 :
- LLMs可以用于生成病理和实验室医学的医疗报告,分析大量临床数据,提供临床决策支持,进行患者教育,进行质量控制和医学文献分析。
- LLMs在病理教育中的应用 :
- LLMs可以帮助学术病理学家开发演示文稿和讲座,例如通过ChatGPT生成关于贫血原因的医学讲座大纲。
- LLMs在患者报告注释中的应用 :
- LLMs可以为患者门户网站(如MyChart)中的实验室和病理报告提供有用的注释,帮助患者更好地理解他们的检测结果。
- LLMs在医院实验室和病理工作流程中的应用 :
- LLMs可以提高工作流程的效率,例如在尸检服务中简化工作流程,通过总结复杂数据来辅助病理学家。
- LLMs的安全和伦理使用 :
- 讨论了LLMs在病理学中使用时可能出现的问题,如"幻觉"现象(生成不准确的信息)和偏见问题。
- 强调了人类监督的重要性,并讨论了FDA和其他监管机构在确保AI工具在临床医学中可信度方面的努力。
- 结论 :
- LLMs有望在多个行业中革新文本处理方式,病理学和实验室医学可能通过LLMs的应用得到显著提升。
- 尽管存在风险,但通过额外的LLMs训练、临床医生的监督以及强有力的验证和质量监控,这些问题可以得到缓解。
重点关注
Table 1列出了大型语言模型(LLMs)在病理学和实验室医学中的潜在应用【由chatGpt生成】。

-
医疗报告生成:
- LLMs可以自动生成病理和实验室医学的医疗报告,节省时间并减轻病理学家和实验室专业人员的工作量。
-
数据分析:
- LLMs可以分析大量的临床数据,如电子健康记录,以识别有助于疾病诊断、治疗计划和结果分析的模式和趋势。
-
临床决策支持:
- LLMs可以为临床医生提供决策支持,帮助他们更准确和全面地做出关于患者护理的决策。例如,LLMs可以分析患者的症状和病史,建议可能的诊断或治疗选项。
-
患者教育:
- LLMs可以用于开发聊天机器人或虚拟助手,帮助患者获取有关其医疗状况、治疗选项和治疗后护理的信息。
-
质量控制:
- LLMs可以监控实验室测试流程,并识别潜在的错误来源或质量问题,从而提高实验室结果的准确性和可靠性。
-
医学文献分析:
- LLMs可以分析医学文献并提取相关信息,以支持临床决策。这可以帮助医疗专业人员了解最新的研究和治疗选项。
这些应用展示了LLMs在病理学和实验室医学中的多方面潜力,从提高工作效率到增强患者教育和临床决策支持。然而,这些应用的成功实施需要进一步的验证、监督和质量监控,以确保其准确性和可靠性。