概述
在先前探讨的文章中,我们构建了一个全面的数据测试体系,该体系遵循"数据获取---数据治理---数据分析"的流程。如何高效地构建数据可视化看板,以直观展现分析结果,正逐渐成为利用新兴技术提升效能的关键领域。伴随业务拓展、数据量增长与信息系统不断升级,对数据分析成果呈现的灵活性需求日益增强。这预示着能够迅速且灵活创建数据看板的能力,将成为未来技术赋能的核心趋势之一。
本实践研究旨在深入探讨利用大型语言模型(LLM)来构建Data Multi-Agents框架下数据展示与看板的潜力及其可能面临的挑战。通过LLM的智能分析能力,我们期望能自动识别关键数据指标,智能设计图表类型,并动态调整数据看板布局,以适应不同用户的需求和场景。然而,这一过程中也存在若干难题,如数据隐私保护、模型训练所需大量高质量数据集的获取,以及如何确保看板信息的准确性和实时性等,这些都是需要我们重点关注和解决的问题。
通过本次实践,我们将评估LLM在自动化数据看板构建中的适用性,探索其在提升数据可读性与洞察力方面的潜在优势,同时也会审视技术实施中可能遇到的实际障碍,以期为未来的数据可视化工具开发提供有价值的参考。
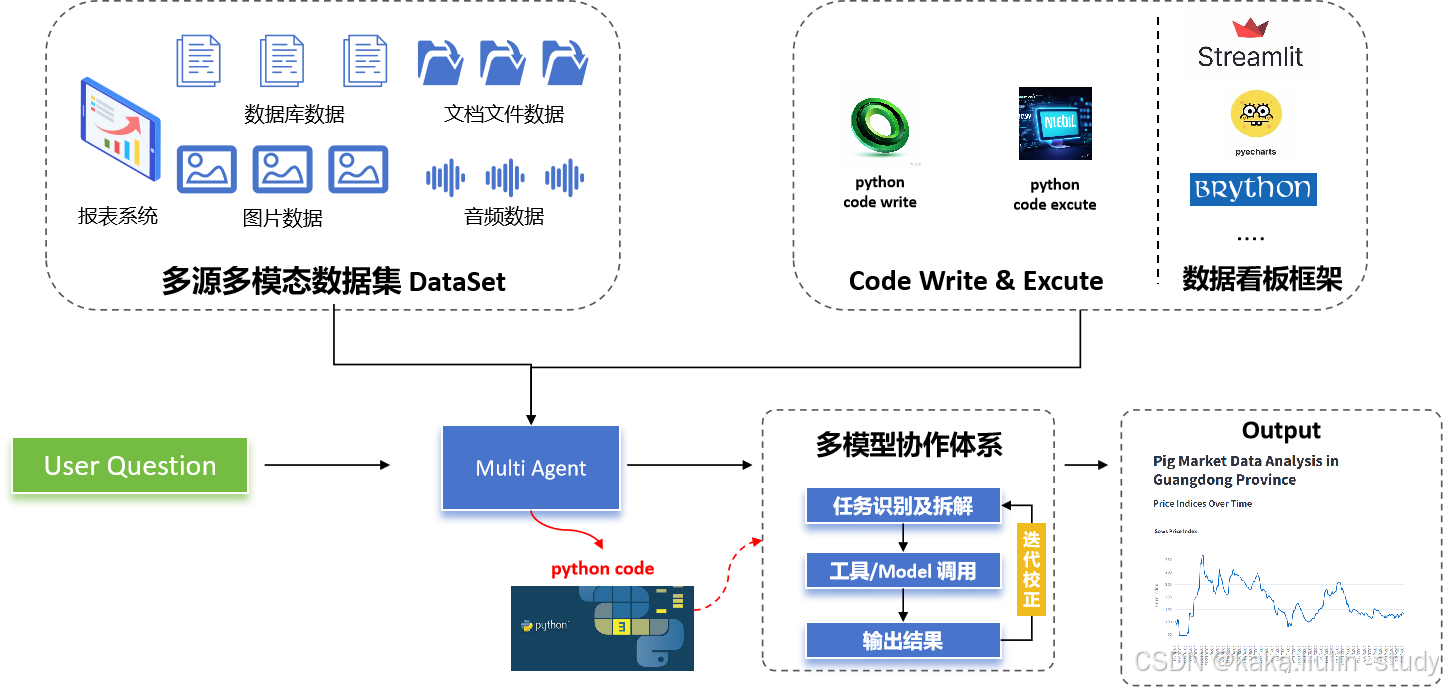
Data Agent构建
本次实践工程采用LLM+AutoGen框架,借助AutoGen框架代码生成和执行的能力构建数据展示的原生代码,并且使用Streamlit、PyEcharts、Bypython等框架来展示数据情况:
1. 代码执行器的构建
目标:
创建一个可以安全地执行Python代码的环境,用于动态生成数据可视化。
实现步骤:
- 容器化: 使用Docker容器隔离执行环境,确保主机系统安全。
- 权限控制: 限制代码执行器对系统的访问权限,防止恶意代码损害系统。
- 错误处理: 捕获并优雅地处理执行时可能发生的任何异常。
- 资源管理: 监控和限制CPU、内存使用,避免资源耗尽。
技术栈:
- Docker
- Python虚拟环境
- Error handling in Python
2. 代码编写器的构建
目标:
设计一个用户友好的界面,允许非技术用户通过自然语言描述需求,自动生成代码。
实现步骤:
- 自然语言解析: 利用LLM解析用户的自然语言指令,转换成可执行的代码片段。
- 代码模板库: 建立常用数据处理和可视化的代码模板,减少从头生成代码的需求。
- 用户反馈循环: 提供机制让用户验证和修改自动生成的代码,增强准确性。
技术栈:
- AutoGen API
- Streamlit for UI
- LLM for NLP processing
3. 代码迭代策略及提示词的构建
目标:
优化代码生成过程,提高代码质量和效率。
实现步骤:
- 迭代学习: 记录并分析用户修改的代码,让LLM从这些修改中学习,改进未来生成的代码。
- 提示词优化: 创建和维护一套高质量的提示词库,帮助引导LLM生成更准确的代码。
- 性能监控: 定期评估代码生成和执行的性能,调整算法和参数以提升效率。
技术栈:
- Machine Learning for iterative improvement
- Prompt engineering
- Performance monitoring tools
展示数据情况
在所有组件就绪后,利用Streamlit、PyEcharts、ByPython等框架创建交互式数据看板:
- Streamlit: 构建前端界面,集成所有功能。
- PyEcharts: 生成复杂的动态图表。
- ByPython: 实时代码执行和结果显示。
python
from autogen import GroupChat
from autogen import GroupChatManager
from autogen import ConversableAgent # 从autogen模块导入ConversableAgent类
from autogen.coding import LocalCommandLineCodeExecutor
from autogen import UserProxyAgent
import tempfile
from autogen.agentchat.contrib.retrieve_user_proxy_agent import RetrieveUserProxyAgent
from autogen.agentchat.contrib.retrieve_assistant_agent import RetrieveAssistantAgent
import chromadb
import autogen
config_deepseek= {"config_list": [{"model": "xxx","base_url":"xxx","api_key":"xxx"}],"cache_seed": None}
executor = LocalCommandLineCodeExecutor(
timeout=10, # 每次代码执行的超时时间,单位为秒
work_dir='/content/pig_data', # 使用临时目录来存储代码文件
)
assistant = autogen.AssistantAgent(
name="assistant",
system_message="You are a helpful assistant.",
llm_config=config_deepseek,
)
# 创建一个配置了代码执行器的代理
code_executor_agent = ConversableAgent(
"code_executor_agent",
llm_config=False, # 关闭此代理的LLM功能
code_execution_config={
"last_n_messages": 5,
"work_dir": "/content/pig_data",
"use_docker": False,}, # 使用本地命令行代码执行器
human_input_mode="NEVER", # 此代理始终需要人类输入,以确保安全
is_termination_msg=lambda msg: "TERMINATE" in msg["content"].lower()
)
# 代码编写代理的系统消息是指导LLM如何使用代码执行代理中的代码执行器
code_writer_system_message = """You are a helpful AI assistant.
Solve tasks using your coding and language skills.
In the following cases, suggest python code (in a python coding block) or shell script (in a sh coding block) for the user to execute.
1. When you need to collect info, use the code to output the info you need, for example, browse or search the web, download/read a file, print the content of a webpage or a file, get the current date/time, check the operating system. After sufficient info is printed and the task is ready to be solved based on your language skill, you can solve the task by yourself.
2. When you need to perform some task with code, use the code to perform the task and output the result. Finish the task smartly.
Solve the task step by step if you need to. If a plan is not provided, explain your plan first. Be clear which step uses code, and which step uses your language skill.
When using code, you must indicate the script type in the code block. The user cannot provide any other feedback or perform any other action beyond executing the code you suggest. The user can't modify your code. So do not suggest incomplete code which requires users to modify. Don't use a code block if it's not intended to be executed by the user.
If you want the user to save the code in a file before executing it, put # filename: <filename> inside the code block as the first line. Don't include multiple code blocks in one response. Do not ask users to copy and paste the result. Instead, use 'print' function for the output when relevant. Check the execution result returned by the user.
If the result indicates there is an error, fix the error and output the code again. Suggest the full code instead of partial code or code changes. If the error can't be fixed or if the task is not solved even after the code is executed successfully, analyze the problem, revisit your assumption, collect additional info you need, and think of a different approach to try.
When you find an answer, verify the answer carefully. Include verifiable evidence in your response if possible.
Reply 'TERMINATE' in the end when everything is done.
"""
# 创建一个名为code_writer_agent的代码编写代理,配置系统消息并关闭代码执行功能
code_writer_agent = ConversableAgent(
"code_writer_agent",
system_message=code_writer_system_message,
llm_config=config_deepseek, # 使用GPT-4模型
code_execution_config={
"last_n_messages": 5,
"work_dir": "/content/pig_data",
"use_docker": False,}, # 关闭此代理的代码执行功能
)数据多智能体协作:数据展示测试
python
prompt = """我们想要创建一个数据看板,用于展示和分析广东省生猪市场的价格动态。具体而言,我们需要关注以下几类数据:
全国母猪市场价格数据:Minimum price per week for weeded sows.csv ;淘汰母猪最低价格(周度).xlsx
全国仔猪市场价格数据:Piglet weekly out price.csv;仔猪出栏价格周度.xlsx
全国育肥猪价格数据:Weekly price of commercial pigs.csv;商品猪周度出栏价格.xlsx
一、数据获取与清洗:
1、获取广东省生猪市场的实时数据,包括育肥猪、仔猪和母猪的价格信息。
2、清洗数据,确保其准确无误且格式一致。
-计算价格指数:
1、基于获取的实时价格,计算育肥猪、仔猪和母猪的价格指数。价格指数可以通过标准化当前价格与基期价格的比例来计算
2、计算过程中,请确保考虑到数据的时间序列性质,选择最早日期作为基期。
二、数据保存:
1、将计算出的价格指数以及对应的实时价格数据保存到一个CSV文件中。CSV文件应包含日期、育肥猪价格指数、育肥猪实时价格、仔猪价格指数、仔猪实时价格、母猪价格指数、母猪实时价格等字段。
三、数据可视化:
1、使用Streamlit 库、Plotly 库:创建一个综合看板,利用Streamlit 库、Plotly 库的图表功能,展示各类猪只的价格指数与实时价格变化。保存数据看板为py文件。确保每个包含Streamlit代码的Python文件都有一个名为run的函数来运行Streamlit应用。
2、看板布局:
顶部:广东省生猪市场总览,显示最新日期的平均价格指数。
中部:
第二个模块:两个独立的折线图,母猪价格指数折线图,母猪实时价格趋势图
第三个模块:两个独立的柱状图,仔猪价格指数折线图,仔猪实时价格趋势图
第四个模块:两个独立的折线图,育肥猪价格指数折线图,育肥猪实时价格趋势图
第五个模块:两个独立的双折线图,母猪与仔猪价格指数对比折线图,母猪与育肥猪价格指数对比折线图
底部:数据表格,列出具体日期的价格指数与实时价格,便于查阅。
3、图表样式:
折线图:清晰标注日期轴,区分价格指数与实时价格的两条折线,使用不同的颜色和标记点。
颜色方案:采用温和而对比明显的颜色组合,如深蓝与亮橙,便于区分不同类别。
图例与标题:确保每个图表都有清晰的标题和图例,标注价格指数与实时价格的含义。
4、交互性与美观性
交互设计:允许用户通过下拉菜单或滑块选择不同的日期范围,动态更新图表与表格中的数据。
响应式设计:确保看板在不同设备上(桌面、平板、手机)都能良好显示,适应屏幕尺寸自动调整布局。
视觉美观:整体设计简洁明快,避免过多装饰,确保数据呈现为主。"""执行任务:
python
groupchat_result = code_writer_agent.initiate_chat(
code_excute_agent,
message=prompt,
)结果展示:
运行过程
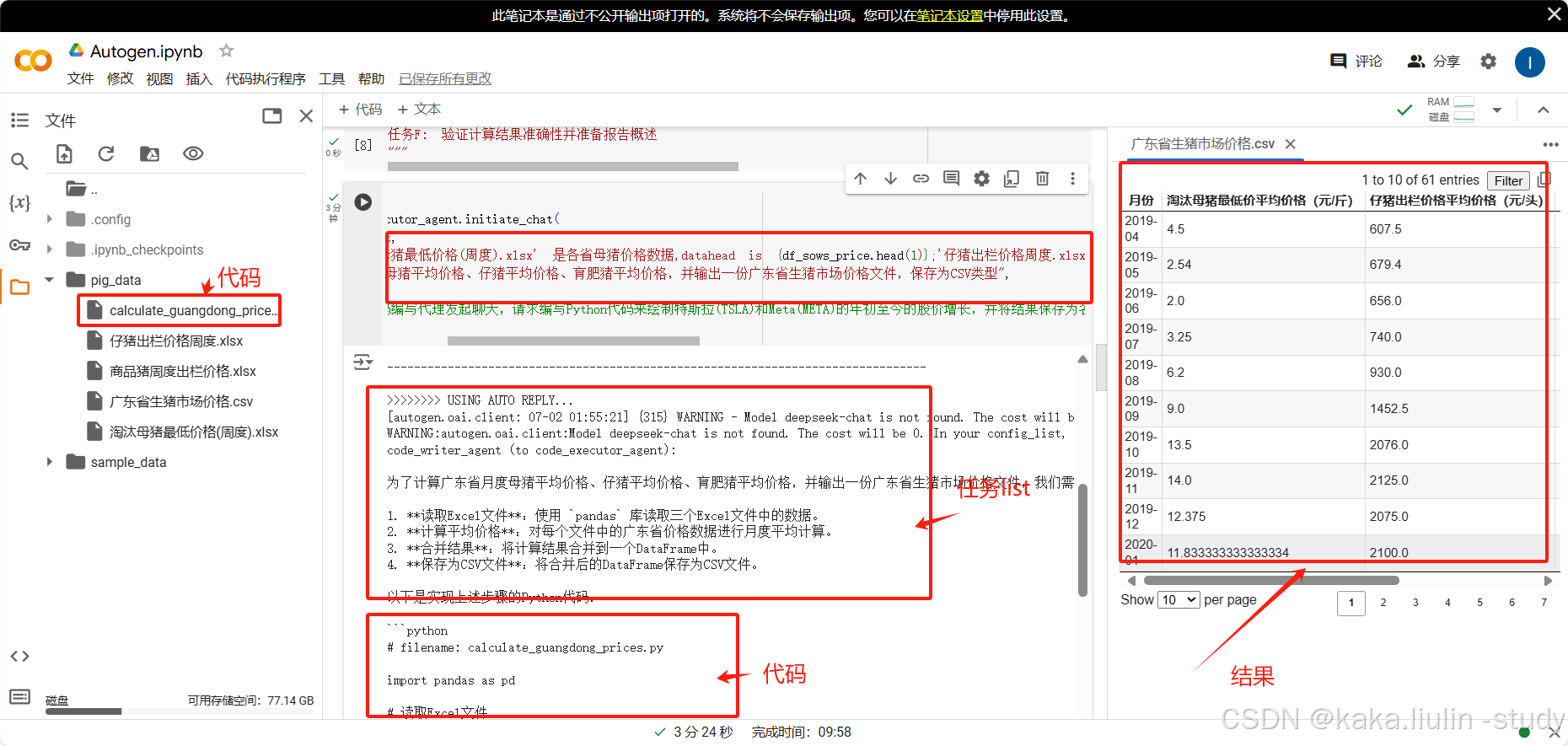
数据看板界面
WeChat_20240715175508
总结
1、AutoGen作为一个大模型应用开源开发框架,支持非openAI大模型力度不够,在测试过程中,面对复杂任务容易失灵;
2、当前的国产大模型面对多文件、多流程、复杂的任务很难快速生成准确无误的代码,导致迭代次数增加;从而极大的推高使用成本;
3、AutoGen经过更新虽然原生支持RAG应用,但是RAG应用效果远不如Langchain、Llamaindex等框架。