[atguigu@node001 ~]$ spark-shell \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
> --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
> --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18760 [main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://node001:4040
Spark context available as 'sc' (master = local[*], app id = local-1704790850201).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.2
/_/
Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
027
++4.2.1 启动 spark-shell++
2)设置表名,基本路径和数据生成器
bash复制代码
scala> import org.apache.hudi.QuickstartUtils._
import org.apache.hudi.QuickstartUtils._
scala> import scala.collection.JavaConversions._
import scala.collection.JavaConversions._
scala> import org.apache.spark.sql.SaveMode._
import org.apache.spark.sql.SaveMode._
scala> import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceReadOptions._
scala> import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.DataSourceWriteOptions._
scala> import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.hudi.config.HoodieWriteConfig._
scala>
scala> val tableName = "hudi_trips_cow"
tableName: String = hudi_trips_cow
scala> val basePath = "file:///tmp/hudi_trips_cow"
basePath: String = file:///tmp/hudi_trips_cow
scala> val dataGen = new DataGenerator
dataGen: org.apache.hudi.QuickstartUtils.DataGenerator = org.apache.hudi.QuickstartUtils$DataGenerator@66e6b022
scala>
scala>
scala> val inserts = convertToStringList(dataGen.generateInserts(10))
inserts: java.util.List[String] = [{"ts": 1704209002713, "uuid": "58f04a7a-6d32-42a6-8915-dfc00ae845fc", "rider": "rider-213", "driver": "driver-213", "begin_lat": 0.4726905879569653, "begin_lon": 0.46157858450465483, "end_lat": 0.754803407008858, "end_lon": 0.9671159942018241, "fare": 34.158284716382845, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1704623138251, "uuid": "d2c871b0-e98e-44ee-815b-09fbcc5771bb", "rider": "rider-213", "driver": "driver-213", "begin_lat": 0.6100070562136587, "begin_lon": 0.8779402295427752, "end_lat": 0.3407870505929602, "end_lon": 0.5030798142293655, "fare": 43.4923811219014, "partitionpath": "americas/brazil/sao_paulo"}, {"ts": 1704362707376, "uuid": "74e4699e-3644-477e-9d12-bf83a67c59c1", "rider": "rider-213", "driver"...
scala> val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2))
warning: one deprecation (since 2.12.0)
warning: one deprecation (since 2.2.0)
warning: two deprecations in total; for details, enable `:setting -deprecation' or `:replay -deprecation'
df: org.apache.spark.sql.DataFrame = [begin_lat: double, begin_lon: double ... 8 more fields]
scala> df.write.format("hudi").
| options(getQuickstartWriteConfigs).
| option(PRECOMBINE_FIELD_OPT_KEY, "ts").
| option(RECORDKEY_FIELD_OPT_KEY, "uuid").
| option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath").
| option(TABLE_NAME, tableName).
| mode(Overwrite).
| save(basePath)
warning: one deprecation; for details, enable `:setting -deprecation' or `:replay -deprecation'
7744528 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
7744558 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
7747037 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:///tmp/hudi_trips_cow/.hoodie/metadata
scala>
[atguigu@node001 ~]$ nohup hive --service metastore &
[1] 11371
[atguigu@node001 ~]$ nohup: 忽略输入并把输出追加到"nohup.out"
[atguigu@node001 ~]$ jpsall
================ node001 ================
3472 NameNode
4246 NodeManager
4455 JobHistoryServer
11384 -- process information unavailable
10456 SparkSubmit
3642 DataNode
4557 SparkSubmit
11437 Jps
================ node002 ================
6050 Jps
2093 DataNode
2495 NodeManager
2335 ResourceManager
================ node003 ================
5685 Jps
2279 SecondaryNameNode
2459 NodeManager
2159 DataNode
[atguigu@node001 ~]$ netstat -anp | grep 9083
(Not all processes could be identified, non-owned process info
will not be shown, you would have to be root to see it all.)
tcp6 0 0 :::9083 :::* LISTEN 11371/java
[atguigu@node001 ~]$ spark-sql \
> --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
> --conf 'spark.sql.catalog.spark_catalog=org.apache.spark.sql.hudi.catalog.HoodieCatalog' \
> --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
0 [main] WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
1410 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1410 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
8317 [main] WARN org.apache.spark.util.Utils - Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
8319 [main] WARN org.apache.spark.util.Utils - Service 'SparkUI' could not bind on port 4041. Attempting port 4042.
Spark master: local[*], Application Id: local-1706012797408
spark-sql (default)> show databases;
namespace
default
edu2077
Time taken: 11.185 seconds, Fetched 2 row(s)
spark-sql (default)>
> create database spark_hudi;
Response code
Time taken: 11.725 seconds
spark-sql (default)> use spark_hudi;
Response code
Time taken: 0.673 seconds
spark-sql (default)> create table hudi_cow_nonpcf_tbl (
> uuid int,
> name string,
> price double
> ) using hudi;
422168 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
422406 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
425565 [main] WARN org.apache.hadoop.hive.ql.session.SessionState - METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
Response code
Time taken: 10.492 seconds
spark-sql (default)> show tables;
namespace tableName isTemporary
hudi_cow_nonpcf_tbl
Time taken: 1.444 seconds, Fetched 1 row(s)
spark-sql (default)> desc hudi_cow_nonpcf_tbl;
col_name data_type comment
_hoodie_commit_time string
_hoodie_commit_seqno string
_hoodie_record_key string
_hoodie_partition_path string
_hoodie_file_name string
uuid int
name string
price double
Time taken: 2.179 seconds, Fetched 8 row(s)
spark-sql (default)> create table hudi_mor_tbl (
> id int,
> name string,
> price double,
> ts bigint
> ) using hudi
> tblproperties (
> type = 'mor',
> primaryKey = 'id',
> preCombineField = 'ts'
> );
Response code
Time taken: 1.803 seconds
spark-sql (default)> show tables;
namespace tableName isTemporary
hudi_cow_nonpcf_tbl
hudi_mor_tbl
Time taken: 0.257 seconds, Fetched 2 row(s)
spark-sql (default)> desc hudi_mor_tbl;
col_name data_type comment
_hoodie_commit_time string
_hoodie_commit_seqno string
_hoodie_record_key string
_hoodie_partition_path string
_hoodie_file_name string
id int
name string
price double
ts bigint
Time taken: 0.636 seconds, Fetched 9 row(s)
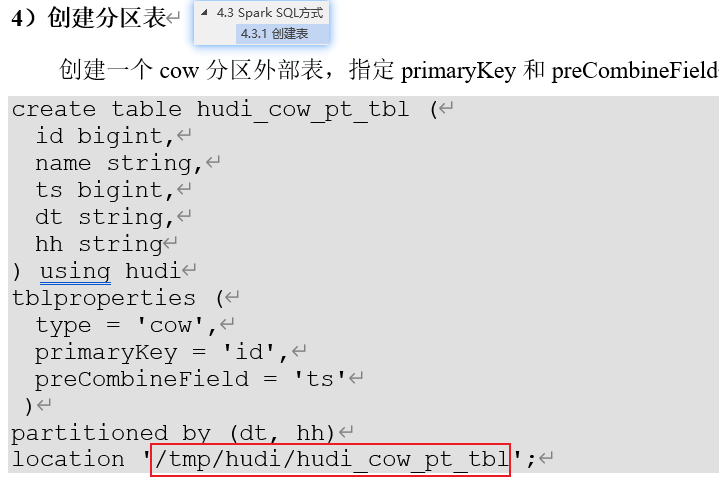
spark-sql (default)> create table hudi_cow_pt_tbl (
> id bigint,
> name string,
> ts bigint,
> dt string,
> hh string
> ) using hudi
> tblproperties (
> type = 'cow',
> primaryKey = 'id',
> preCombineField = 'ts'
> )
> partitioned by (dt, hh)
> location '/tmp/hudi/hudi_cow_pt_tbl';
Response code
Time taken: 21.88 seconds
spark-sql (default)> create table hudi_ctas_cow_nonpcf_tbl
> using hudi
> tblproperties (primaryKey = 'id')
> as
> select 1 as id, 'a1' as name, 10 as price;
1514254 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:/home/atguigu/spark-warehouse/spark_hudi.db/hudi_ctas_cow_nonpcf_tbl/.hoodie/metadata
1546852 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1546852 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 63.078 seconds
spark-sql (default)> select * from hudi_ctas_cow_nonpcf_tbl;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name price
20240123205131373 20240123205131373_0_0 id:1 bee32427-f490-40dd-89ed-3bacd3adf6fb-0_0-17-15_20240123205131373.parquet 1 a1 10
Time taken: 1.636 seconds, Fetched 1 row(s)
spark-sql (default)> create table hudi_ctas_cow_pt_tbl
> using hudi
> tblproperties (type = 'cow', primaryKey = 'id', preCombineField = 'ts')
> partitioned by (dt)
> as
> select 1 as id, 'a1' as name, 10 as price, 1000 as ts, '2021-12-01' as dt;
1646675 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:/home/atguigu/spark-warehouse/spark_hudi.db/hudi_ctas_cow_pt_tbl/.hoodie/metadata
1664435 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1664435 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 26.019 seconds
spark-sql (default)> select * from hudi_ctas_cow_pt_tbl;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name price ts dt
20240123205354771 20240123205354771_0_0 id:1 dt=2021-12-01 88ad8031-2239-4bce-8494-5bf109012400-0_0-69-1259_20240123205354771.parquet 1 a1 10 1000 2021-12-01
Time taken: 2.829 seconds, Fetched 1 row(s)
spark-sql (default)>
033
++4.3.2 插入数据++
bash复制代码
spark-sql (default)> show tables;
namespace tableName isTemporary
hudi_cow_nonpcf_tbl
hudi_cow_pt_tbl
hudi_ctas_cow_nonpcf_tbl
hudi_ctas_cow_pt_tbl
hudi_mor_tbl
Time taken: 1.298 seconds, Fetched 5 row(s)
spark-sql (default)> insert into hudi_cow_nonpcf_tbl 1, 'a1', 20;
Error in query:
mismatched input '1' expecting {'(', 'FROM', 'MAP', 'REDUCE', 'SELECT', 'TABLE', 'VALUES'}(line 1, pos 32)
== SQL ==
insert into hudi_cow_nonpcf_tbl 1, 'a1', 20
--------------------------------^^^
spark-sql (default)> insert into hudi_cow_nonpcf_tbl select 1, 'a1', 20;
458055 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Cannot find HUDI_CONF_DIR, please set it as the dir of hudi-defaults.conf
458212 [main] WARN org.apache.hudi.common.config.DFSPropertiesConfiguration - Properties file file:/etc/hudi/conf/hudi-defaults.conf not found. Ignoring to load props file
475300 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:/home/atguigu/spark-warehouse/spark_hudi.db/hudi_cow_nonpcf_tbl/.hoodie/metadata
517206 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
517206 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 80.477 seconds
spark-sql (default)> insert into hudi_mor_tbl select 1, 'a1', 20, 1000;
640716 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path file:/home/atguigu/spark-warehouse/spark_hudi.db/hudi_mor_tbl/.hoodie/metadata
694713 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
694723 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 71.597 seconds
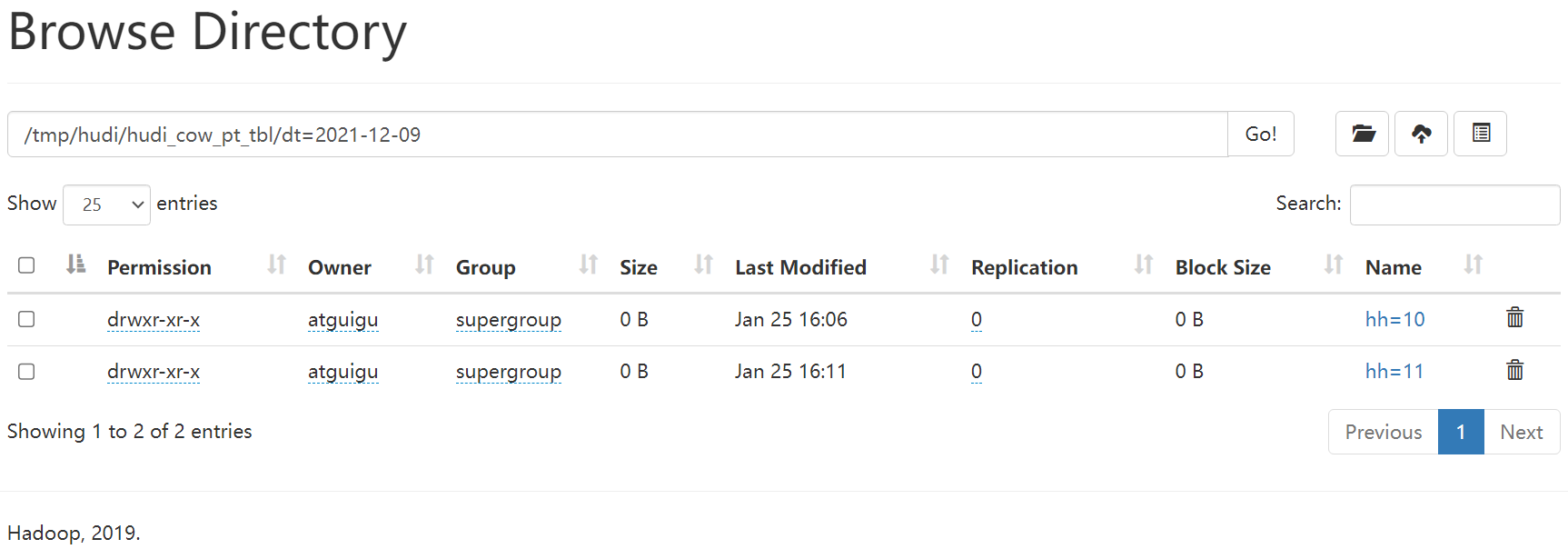
spark-sql (default)> insert into hudi_cow_pt_tbl partition (dt, hh)
> select 1 as id, 'a1' as name, 1000 as ts, '2021-12-09' as dt, '10' as hh;
743011 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl/.hoodie/metadata
04:48 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
04:49 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
04:53 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
Response code
Time taken: 46.44 seconds
spark-sql (default)> insert into hudi_cow_pt_tbl partition(dt = '2021-12-09', hh='11') select 2, 'a2', 1000;
10:06 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
10:07 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
10:11 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl. Falling back to direct markers.
Response code
Time taken: 71.592 seconds
spark-sql (default)> select * from hudi_mor_tbl;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name price ts
20240125160415749 20240125160415749_0_0 id:1 a81ca1da-f642-45c5-ac7e-eb93de803ba8-0_0-65-1253_20240125160415749.parquet 1 a1 20.0 1000
Time taken: 23.135 seconds, Fetched 1 row(s)
spark-sql (default)> -- 向指定preCombineKey的表插入数据,则写操作为upsert
spark-sql (default)> insert into hudi_mor_tbl select 1, 'a1_1', 20, 1001;
1353572 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1353573 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 46.455 seconds
spark-sql (default)> select id, name, price, ts from hudi_mor_tbl;
id name price ts
1 a1_1 20.0 1001
Time taken: 2.081 seconds, Fetched 1 row(s)
spark-sql (default)> set hoodie.sql.bulk.insert.enable=true;
key value
hoodie.sql.bulk.insert.enable true
Time taken: 0.214 seconds, Fetched 1 row(s)
spark-sql (default)> set hoodie.sql.insert.mode=non-strict;
key value
hoodie.sql.insert.mode non-strict
Time taken: 0.027 seconds, Fetched 1 row(s)
spark-sql (default)> insert into hudi_mor_tbl select 1, 'a1_2', 20, 1002;
1538483 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.metastore.event.db.notification.api.auth does not exist
1538486 [main] WARN org.apache.hadoop.hive.conf.HiveConf - HiveConf of name hive.server2.active.passive.ha.enable does not exist
Response code
Time taken: 42.906 seconds
spark-sql (default)> select id, name, price, ts from hudi_mor_tbl;
id name price ts
1 a1_2 20.0 1002
1 a1_1 20.0 1001
Time taken: 1.015 seconds, Fetched 2 row(s)
spark-sql (default)> set hoodie.sql.bulk.insert.enable=false;
key value
hoodie.sql.bulk.insert.enable false
Time taken: 2.396 seconds, Fetched 1 row(s)
spark-sql (default)> create table hudi_cow_pt_tbl1 (
> id bigint,
> name string,
> ts bigint,
> dt string,
> hh string
> ) using hudi
> tblproperties (
> type = 'cow',
> primaryKey = 'id',
> preCombineField = 'ts'
> )
> partitioned by (dt, hh)
> location '/tmp/hudi/hudi_cow_pt_tbl1';
1737608 [main] WARN org.apache.hadoop.hive.ql.session.SessionState - METASTORE_FILTER_HOOK will be ignored, since hive.security.authorization.manager is set to instance of HiveAuthorizerFactory.
Response code
Time taken: 12.013 seconds
spark-sql (default)> insert into hudi_cow_pt_tbl1 select 1, 'a0', 1000, '2021-12-09', '10';
1765548 [main] WARN org.apache.hudi.metadata.HoodieBackedTableMetadata - Metadata table was not found at path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1/.hoodie/metadata
22:14 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
22:15 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
22:23 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
Response code
Time taken: 64.552 seconds
spark-sql (default)> select * from hudi_cow_pt_tbl1;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name ts dt hh
20240125162301446 20240125162301446_0_0 id:1 dt=2021-12-09/hh=10 1e1b2016-8b33-4d4b-a824-4cd53ab7e8ec-0_0-290-5658_20240125162301446.parquet 1a0 1000 2021-12-09 10
Time taken: 1.702 seconds, Fetched 1 row(s)
spark-sql (default)> insert into hudi_cow_pt_tbl1 select 1, 'a1', 1001, '2021-12-09', '10';
23:04 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
23:05 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
23:09 WARN: Timeline-server-based markers are not supported for HDFS: base path hdfs://node001:8020/tmp/hudi/hudi_cow_pt_tbl1. Falling back to direct markers.
Response code
Time taken: 16.112 seconds
spark-sql (default)> select * from hudi_cow_pt_tbl1;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name ts dt hh
20240125162431677 20240125162431677_0_0 id:1 dt=2021-12-09/hh=10 1e1b2016-8b33-4d4b-a824-4cd53ab7e8ec-0_0-329-6292_20240125162431677.parquet 1a1 1001 2021-12-09 10
Time taken: 1.122 seconds, Fetched 1 row(s)
spark-sql (default)> select * from hudi_cow_pt_tbl1 timestamp as of '20220307091628793' where id = 1;
_hoodie_commit_time _hoodie_commit_seqno _hoodie_record_key _hoodie_partition_path _hoodie_file_name id name ts dt hh
Time taken: 20.962 seconds
spark-sql (default)>