Hive介绍
1、Hive本质
Hive本质是【数仓设计方案】,hive本身并不存储数据【数据包含:元数据 + (表)数据】。
2、hql和sql对比
- sql = 结构化查询语言【structured query language】
- hql = hive/hadoop类sql查询语言 【hive/hadoop query language like sql】
说明 :对于hql而言,表面是sql。实际上,数据存储 于HDFS ,执行引擎 是Spark,MapReduce,Pig,Tez等。
3、数据存储
- 元数据 存储于RDB关系型数据库中。其默认存储于DERBY中,但一般在生产环境 下存储于mysql中。
- (表)数据 存储于HDFS中。
补充:元数据的讲解
元数据(Metadata)是指描述数据的数据,它提供关于数据集、资源、文件、系统或者业务流程的额外信息,其中就包含库名,表名,字段,数据类型等。
在Hive中,元数据 则是由HiveMetaStore 来统一管理,进行存储、管理、保护和查询等操作。
4、计算引擎
一 :MapReduce
- Map:清洗,列变形,列裁剪
- Map+Reduce:聚合
二 :Spark ✔
- 1、Job中间输出结果可以保存在内存,不再需要读写HDFS
- 2、速度快,比MapReduce平均快10倍以上
5、Hive层次结构【元数据映射】
| 逻辑结构 | 物理结构 |
|---|---|
| 库 | 文件夹(与库同名.db) |
| 表 | 文件夹(与表同名) |
| 分区 | 文件夹 (格式:分区字段名=分区字段值) |
| 数据 | 文件 |
| 分桶 | 小文件(目的:抽样和数据修改) |
6、Hive执行过程
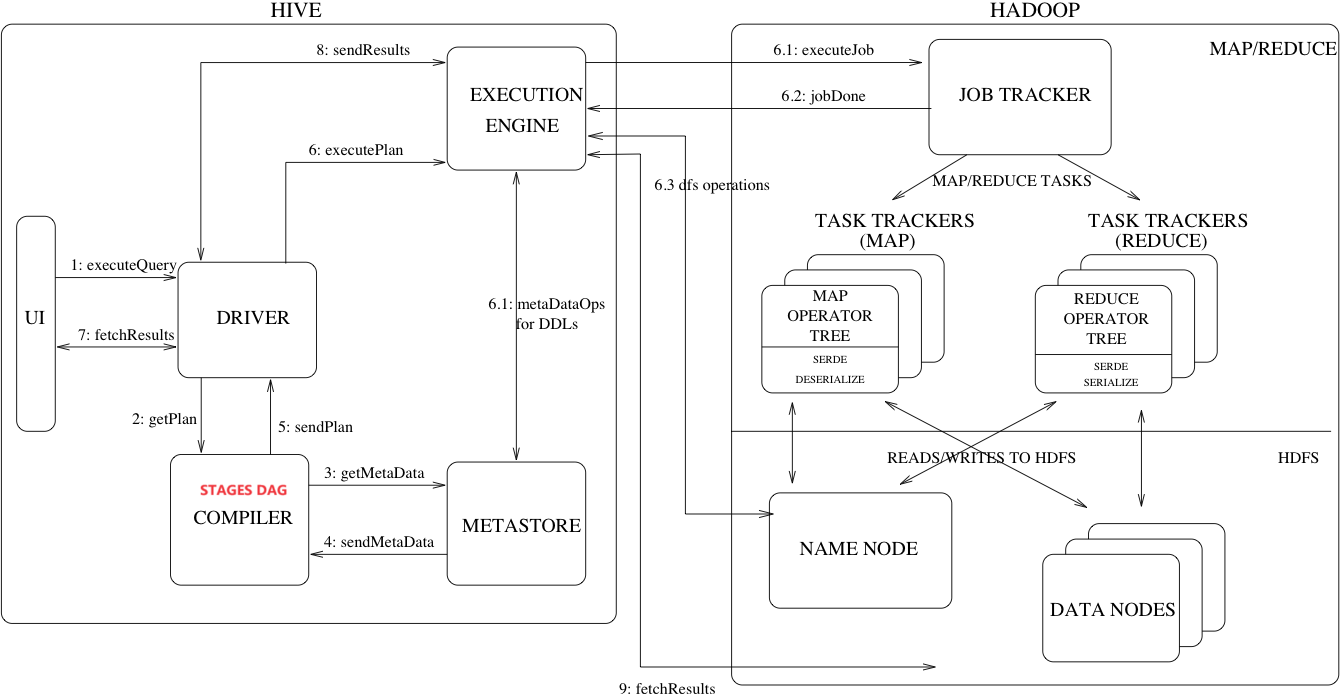
1.UI客户端发出请求 executeQuery[执行查询语句]
2.Driver[驱动] 通过 Compiler 进行编译
3.Compiler 需要向 MetaStore 请求元数据。
编译过程:
Compiler[驱动] 得到 元数据 后
先 生成 逻辑执行计划
再 通过优化形成 物理执行计划
4.将 物理执行计划 通过 Driver[驱动] 交给 ExecutionEngine[执行引擎]
5.ExecutionEngine[执行引擎] 将 物理执行计划 交给 hadoop的MapReduce进行job任务。
6.最终结果落盘到datanode上。
7.UI客户端 向 Driver[驱动] 发起请求 fetchResults
8.Driver 通过 ExecutionEngine[执行引擎] 从 datanode 上将数据拉过来,交给 UI客户端。