导读本文将分享如何利用 Apache SeaTunnel 将各个业务系统的数据同步到 OLAP 引擎。

主要内容包括以下六大部分:
-
Apache SeaTunnel 项目介绍
-
Apache SeaTunnel 核心功能
3.SeaTunnel 在 OLAP 场景下的应用
-
社区近期计划
-
WhaleTunnel 产品特性
-
问答环节
分享嘉宾|高俊 白鲸开源科技有限公司 架构师
编辑整理|安徽大学 刘金辉
内容校对|李瑶
出品社区|DataFun
01
**Apache SeaTunnel ****项目介绍**
- 项目定位------EtLT 时代的新一代数据集成平台
Apache SeaTunnel ****项目的定位是 EtLT 时代的新一代数据集成平台。
什么是 EtLT 呢?这其实要从 ETL 和 ELT 说起。ETL 是早期数据同步到数仓的一种方式,首先从数据源中抽取数据,接着对数据进行转化,比如聚合、校验等计算,再把数据加载到数仓中。后来,随着数据源的逐渐增多以及数仓架构的演进,从 ETL 时代逐渐转换到了 ELT 时代。大家所熟悉的贴源层其实就是 ELT 时代的核心体现,贴源层的所有数据和数据源是保持一致的。ELT 的核心理念是数据先加载到数仓里面,再在数仓上利用数仓庞大的计算集群去进行大批量的计算。
随着一些新型数据库的出现,包括数据湖,以及各种 OLAP 引擎和云平台的出现,使得数据源井喷式增长。并且业务系统的数据需求越来越多元化、异构化,数据体量也越来越大,时效性要求越来越高,之前 ETL 或 ELT 的方式已很难满足当前的需求,因此 EtLT 数据集成平台应运而生。
数据集成平台的核心理念是在抽取后做轻量级的清洗。轻量级清洗指的是,只针对数据里面的每一行数据做 UDF 级别的处理。一行数据抽取过来后,对其进行转换,转换之后写入到目标端。这里的转换不做聚合、不做校验,不在内存里面缓存任何数据,仅仅是对数据做简单的标准化之后就落到目标端。
这一过程对数据开发工程师的要求与以前不同,需要工程师非常了解各种数据库的读取特性、写入特性,不需要对业务有很强的理解,更核心的是在于对各个数据源之间 API 的使用。
所以工程师团队会分为两部分,一部分是做数据同步的工程师,主要负责利用快速的数据集成工具来进行数据从源端到目标端的抽取,并维护相关工具去接入一些新的源和新的目标端;另一部分则是熟悉业务系统的工程师,是业务分析数据应用人员,主要负责基于庞大的计算集群去做数据处理,即基于业务从贴源层到各数仓层级的转化。
**SeaTunnel **的定位就是在 EtLT 时代,负责其中 EtL 的过程。
2. ** SeaTunnel **的设计目标
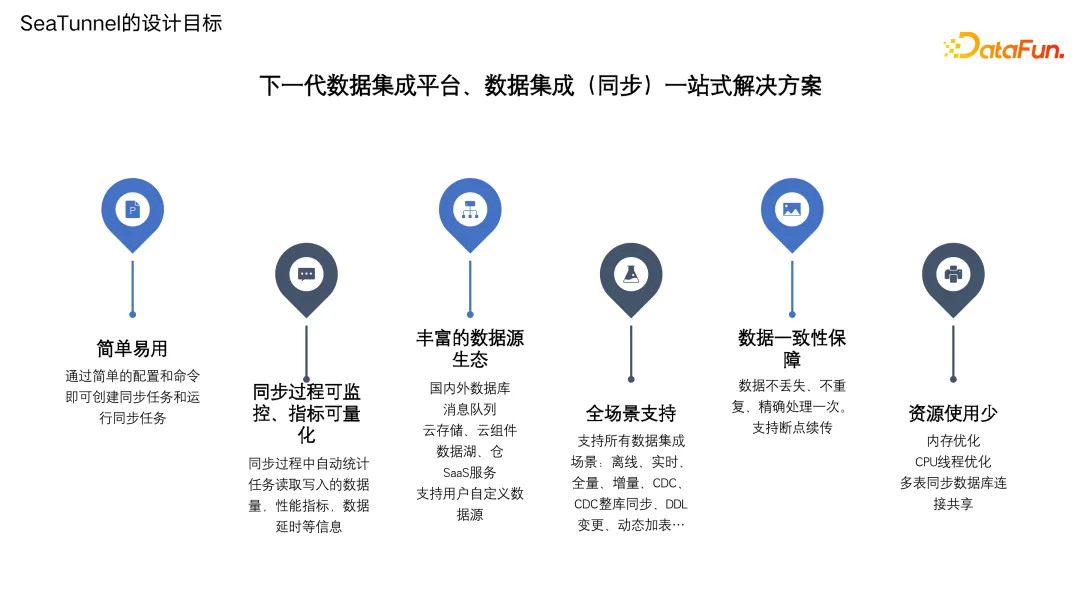
SeaTunnel 的设计目标主要包括:
-
**简单易用。**通过简单的配置和命令就可以创建和运行同步任务。
-
**支持丰富的数据源生态。**数据集成平台引擎和工具的核心功能就是要快速适应各种新出现的数据源和目标端。
-
**同步过程可监控、指标可量化。**能够在同步过程中,监控同步到了哪一阶段,自动统计任务读取写入的数据量,以及每个阶段的各种性能指标。
-
**支持全场景。**包括日常的微批、离线同步、实时同步、增量同步,还有 CDC 同步。CDC 同步又包括整库同步,还要去做 DDL 的变更、动态加表等等。
-
**数据一致性保障。**数据的一致性是数据同步过程中的核心要求,要保证数据不丢失、不重复、精确处理一次。并且在一些大任务,特别是实时 CDC 任务中,要能够支持断点续传。
-
**资源使用少。**因为同步的引擎和做 ETL 的 Transform 的引擎是不一样的,在数仓里面往往有几百台甚至上千台的计算集群做计算,而每天同步几百亿甚至数 T 的数据只有两三台机器,所以要能够实现使用更少的资源去同步更多的数据。这就涉及到内存的优化、线程的优化、多表同步、数据连接池优化,以及资源共享等等。
**3. SeaTunnel ****的整体架构**
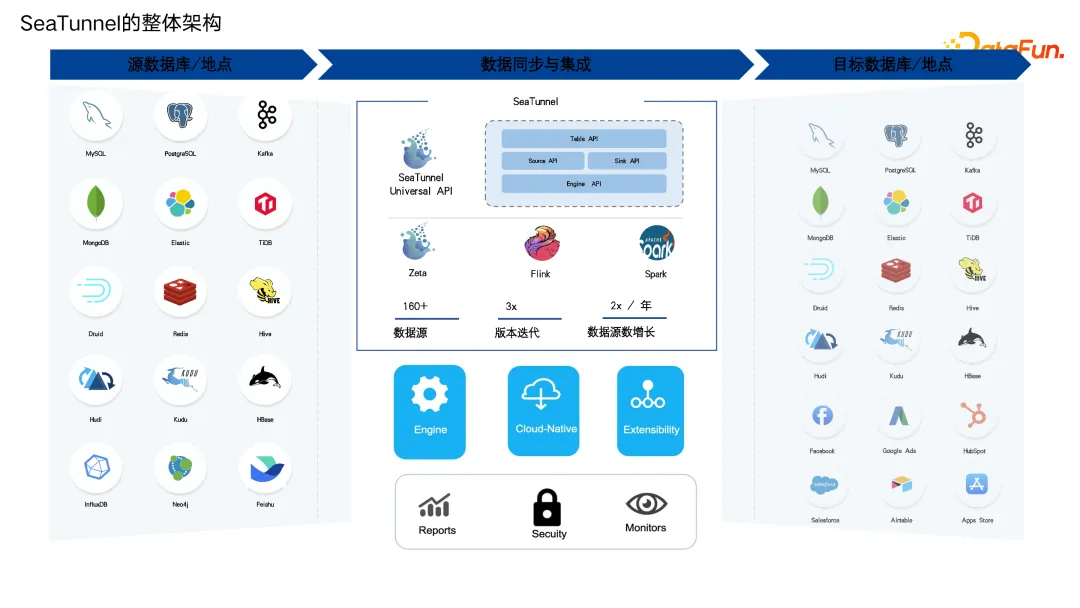
上图展示了 SeaTunnel 的整体架构。左边是支持的各种数据源,右边是各种目标端。中间包括 SeaTunnel 的各种 API,比如 Table API、Source API、SinkAPI、Transform API 以及 Engine API。
Engine API 的作用是支持各种计算引擎。比如一个同步任务,今天可能在 Zeta 引擎上运行,当 Zeta 引擎资源不足时,可以在 Flink 引擎上去运行,同一套代码,同一个配置文件,通过改单个参数即实现跨平台执行。
目前 SeaTunnel 支持的数据源和目标端共有 160 多种,版本已经迭代超过两年。
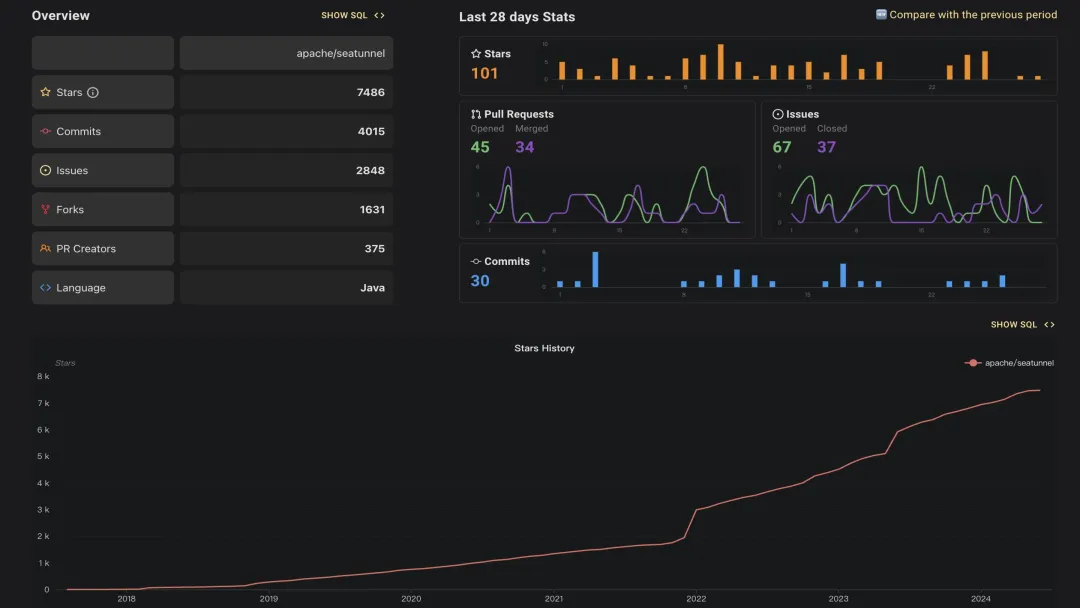
社区现状如上图所示,Stars 有 7000+,Commits 超过 4000,有 370 多位贡献者,采用 Java 技术栈。
02
**Apache SeaTunnel ****核心功能**
**1. ****与引擎解耦的连接器 API**
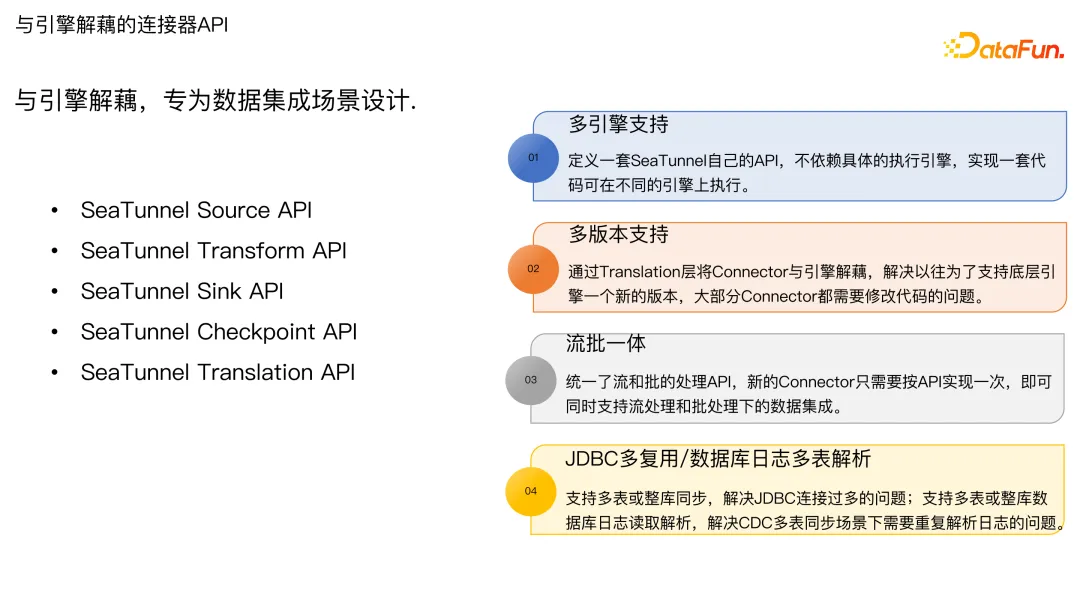
下面介绍 Apache SeaTunnel 的一些核心功能。
上图中列出了 SeaTunnel 的核心 API,其目标是与引擎解耦,是专为数据集成场景而设计的,主要包括 Source API、Transform API、Sink API、Checkpoint API 和 Translation API。整个项目的实现机制是 SPI 动态加载的机制,基于这套 API 可以快速扩展各种插件。这套 API 的主要优势在于:
-
**多引擎支持。**在前文中已做介绍,支持一套代码在不同引擎上执行。
-
**多版本支持。**通过 Translation 层将 Connector 与引擎解耦,在配置作业时,只需要一个配置文件,即可通过不同的命令提交到不同的引擎上运行,平台会自动适配集群的 Flink、Spark 或 Zeta 的版本。
-
**流批一体。**一个任务既可以跑批也可以跑流,仅仅改参数即可指定流或批。新的 connector 只需要按照 API 实现一次,就可以同时支持流处理和批处理下的数据集成。
-
**JDBC ****多复用/数据库日志多表解析。**JDBC 连接可以复用,这在同步场景下是非常有意义的。比如同步上万张表时,控制其仅使用有限的 JDBC 连接非常重要,可以防止源端和目标端的 JDBC 连接打满,导致生产库出问题。对于 CDC 同步来说,在多表的场景下能够复用对 binlog 的解析,防止每个表加载一次 binlog 读取一次 binlog 带来带宽压力。
2. 与引擎解耦的连接器实现------Source Connector
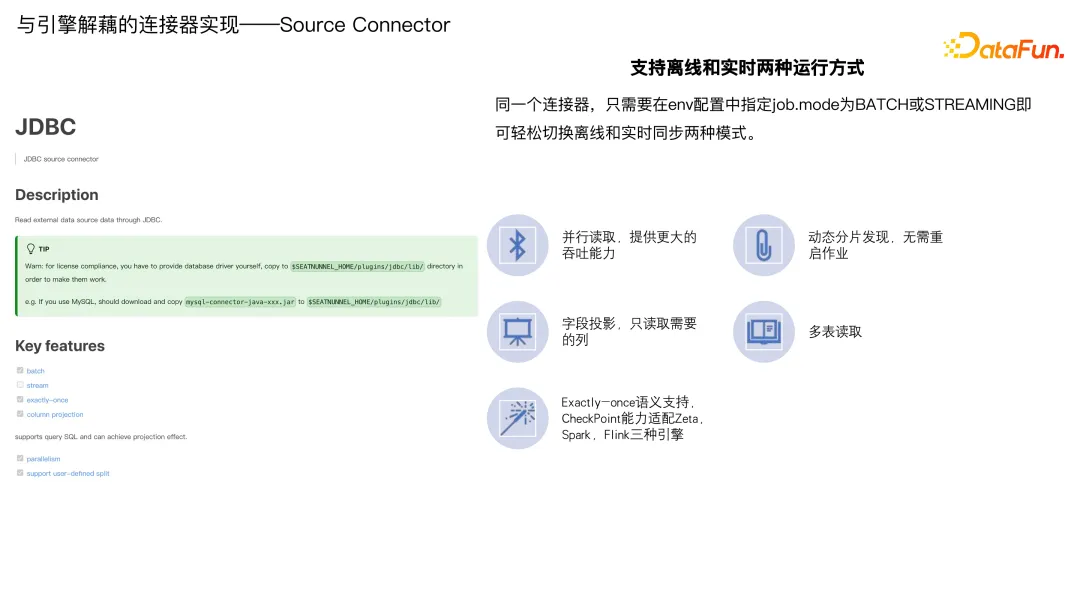
这是基于 Source API 实现的 JDBC Source。其特点就是能够通过在 env 里面配置 job 的 mode 为 batch 或 streaming,就可以轻松切换离线和实时两种同步模式。它具备并行读取的能力,能够提供最大的吞吐能力;能够做动态的分片发现,无需重启作业;字段投影,只需读取需要同步的列;支持多表读取;支持 Exactly-once 语义,通过实现 Checkpoint API,能够支持 Zeta、Spark、Flink 三种引擎的切换。
**3. ****与引擎解耦的连接器实现------Sink Connector**

Sink Connector 是基于 Sink API 实现的一个Doris的连接器,上图中列出了其版本,同样可以支持实时和离线两种模式。并且支持 save mode 功能,支持结构的 save mode 和数据的 save mode。它能够支持在作业运行之前去自动建表,或者删表重建,或者清理表里面已经有的数据,还可以执行一些自定义 SQL 去处理目标端已有的数据。
自动建表,支持模板修改,在多表同步的场景下可以解放双手。支持的表引擎包括 unique 和 duplicate 这两个模型,聚合模型尚不支持。同时支持 exactly-once 语义,利用 Doris 的事务机制做到数据的不丢失不重复。
最后是 CDC 的支持,支持源端 CDC 事件同步到 Doris 里面去做数据的增删改,以及表结构的变更。
4. ** CDC Connector **设计
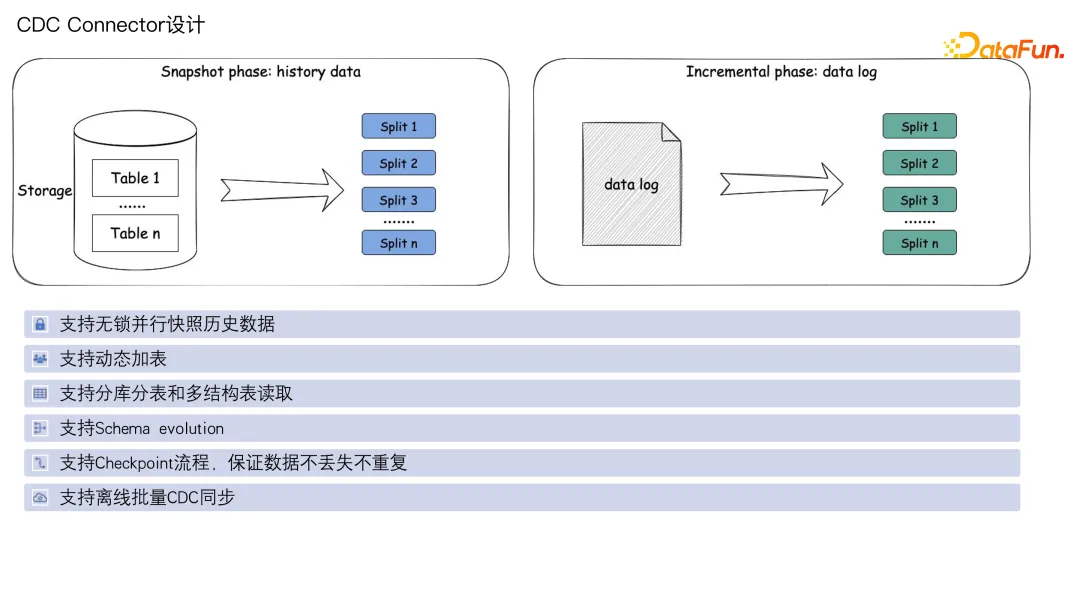
CDC 连接器主要的特性就是能够支持无锁并行快照处理历史数据,支持动态加表。比如一个任务里面跑了十张表,后面有一张新的表想同步,可以暂停,去修改配置加一张表,再恢复作业,它会接着之前的进度去运行。
支持分库分表和多结构表读取,支持 Schema evolution,支持 Checkpoint 流程,保证数据不丢失不重复。同时还能够支持离线 CDC,即解析 binlog 同步到目标端的一种批量运行的方式。
5. ** Checkpoint **功能设计 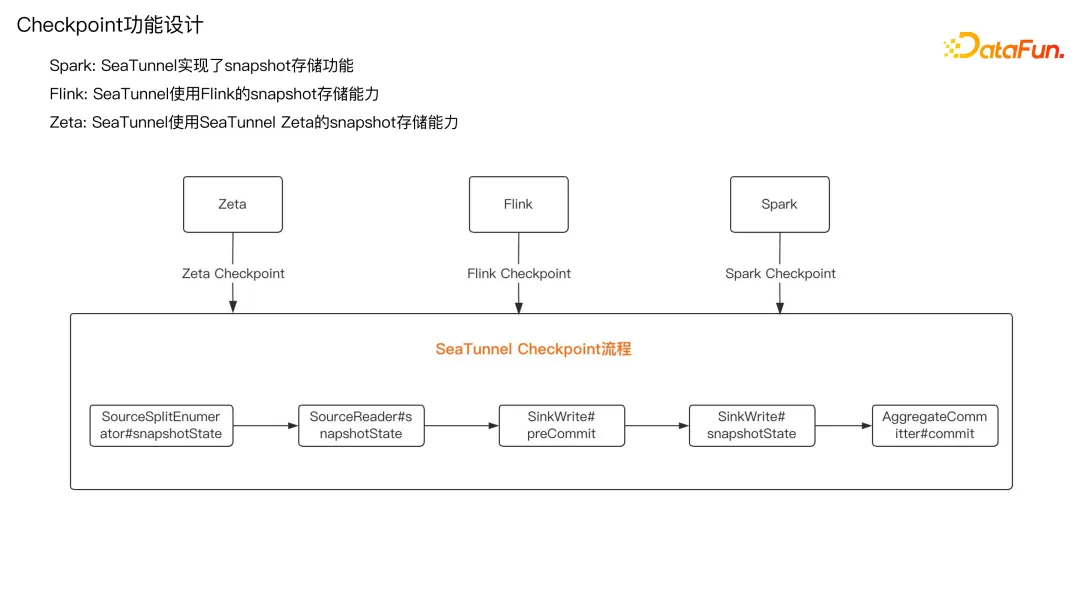
Checkpoint 目前主要的流程是从 Split 枚举器开始到 Source Reader,然后到 Sink Write,最后是 Aggregation Commit。
在处理同步数据的过程中,主要作用就是这五个核心的 API,即 Source 枚举器的 API、Source 读取的 API、Sink 写入的 API、Snapshot 快照的 API 以及最终提交数据到目标端的 API。
为了支持多引擎,在 Spark 上实现了 Snapshot 的存储功能。因为 Spark 本身不支持 Checkpoint。为了能够让 SeaTunnel 的 Checkpoint 在 Spark 环境上使用,在 Spark 上实现了 Snapshot 存储的功能。Flink 是直接使用了 Flink 的 Snapshot 存储能力。Zeta 引擎,是使用了 SeaTunnel Zeta 的 Snapshot 的存储能力。这是 Snapshot 功能的设计。
**6. ****模型推演**

下面介绍模型推演。假设从 MySQL 同步数据到 Doris 里面,在多表的场景下,比如上万张表,如果让业务人员在目标端一张一张地建表,代价是非常大的,这时就会用到自动建表的功能。那么如何获得应该建的表的结构呢?比如每个字段的类型是什么,字段的长度和精度是什么?而且不同数据库对中文字符串的存储可能是不一样的,比如有的数据库的 VARCHAR(1000)中 1000 指的是字节长度,而在有的数据库 VARCHAR(1000)的 1000 则是字符长度,字节和字符间的转化会涉及到数据库的字符编码。要保证目标端建的这张表的结构一定能够放下源端同步过来的数据,就要利用到模型推演的特性。
整个过程为,首先 Source 端在读取 MySQL 数据库之后,会拿到 MySQL 的 CatalogTable List,这里面保存了 MySQL 里面每个字段的原始类型,包括长度、精度、是否是主键、是否是索引,以及字段注释等等。
在 SeaTunnel 里面会对每个数据源实现 TypeConverter#convert 方法。这个方法主要的作用是根据比如 MySQL 数据库的特性,将这个数据库里面的表结构转换成 SeaTunnel 里面的 CatalogTable 对应的 Java 的类型。字段的长度和精度会随着数据库里面的字符类型和字节类型的特性,以及字符编码的特性,进行扩充。例如如果源端存储的是字符,比如 VARCHAR(1000)是字符个数,而目标端可能是字节,那么在有中文的场景下,就会把这个 VARCHAR(1000)扩充三倍或四倍,作为 SeaTunnel 类型里面的长度。
在目标 Sink 端接收到上游传过来的 CatalogTable List,这个上游可以是 Source,也可能是一些中间的 Transform,这个从上游传过来的 CatalogTable List 又会在 Sink 里面。
Sink 里面,要去实现 TypeConverter#reconvert 的方法。在这个方法里面,要根据 SeaTunnel 里面的 CatalogTable 里面的字段类型、精度还有特点,再结合自己数据库的字段类型的精度和特点,转换成当前数据库最合适的表结构。最终就拿这个表结构在目标端建表。这就是整个模型推演的过程。
**7. ****多表同步**
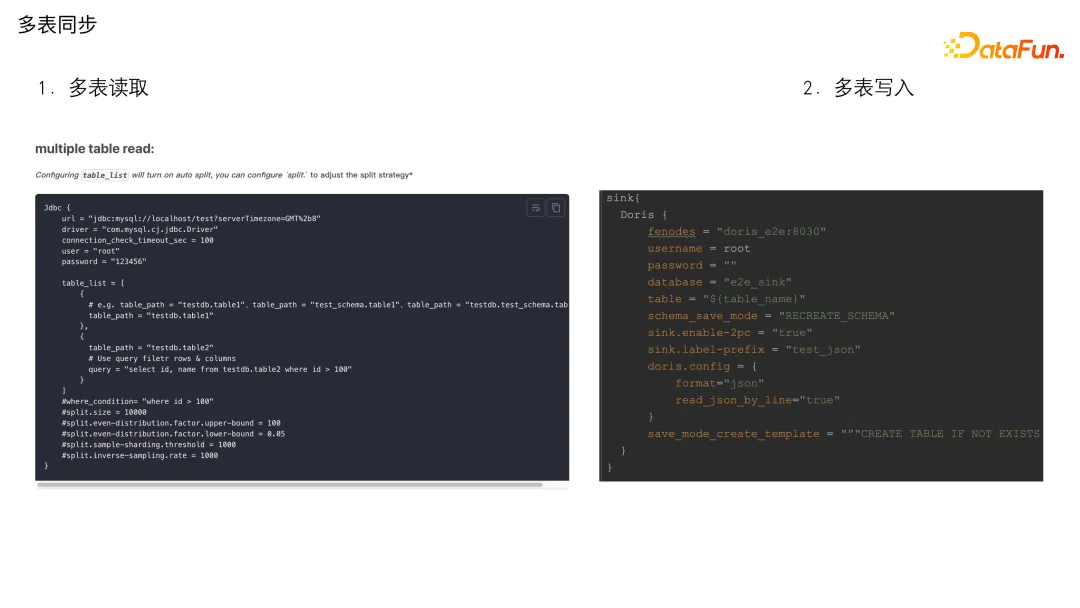
在 SeaTunnel 里面支持多表读取和多表写入。多表读取中,可以在 table_list 中写多张表,只要写上 table_path,当然针对某些表只想同步几个字段或加 where 条件过滤,可以再加上一个 query。如果很多张表都同样有 update_time 字段,想去做批量的增量同步,可以使用全局的 where 条件,这个条件会应用到 table_list 里面的所有表,为所有表添加 where 条件做增量同步。
多表写入,table 参数的值可以写成表达式的形式,${table_name}代表源端的表名和目标端的表名是一模一样的,当然可以再加前缀、后缀或一些特殊的处理。最终它会按照这个表达式匹配上游传过来的表名计算,计算出最终的表名,去查表、使用表,或者做自动建表。
**8. ****新一代数据同步引擎------SeaTunnel Zeta**

下面介绍一下 SeaTunnel Zeta,这是专门为数据集成设计的新一代数据同步引擎,它不依赖第三方组件,也不依赖大数据平台,可以自己去组集群,而且是无主、自选主的集群。同时它支持 WAL log 方式,即使整个集群重启,之前正在运行的作业也能够恢复。同时支持分布式快照算法,能够保障数据的一致性。
同时也支持更详细的数据同步维度的监控指标,比如表级的监控、各个阶段级的监控、数据延迟的监控等等,这些同步过程中的指标都是在 SeaTunnel 的 Zeta 引擎里面去实现的。同时,Zeta 支持事件通知,可以指定事件的通知策略和目标端,里面发生的一些事件,可以通知给目标系统。
同时支持 Classloader 隔离、Classloader Cache,可以在同步各种作业时节省 JVM 的 metaspace 内存空间。 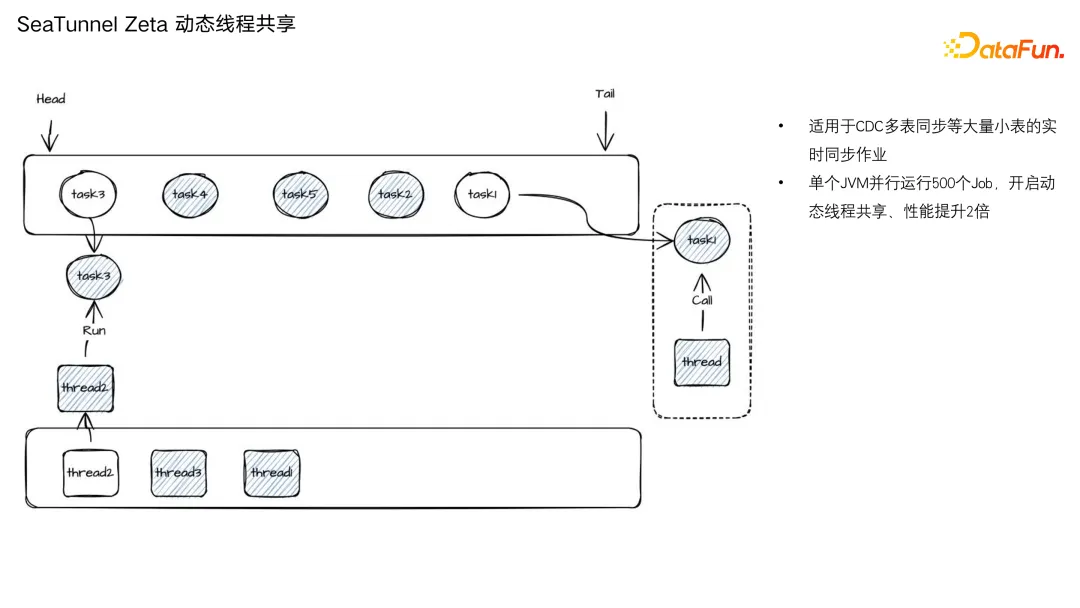 Zeta 的核心特点是支持运行非常多的任务,特别 CDC 多表同步等大量小任务的实时同步作业,同时支持集群模式,任务会分布在集群各个节点上去运行。
Zeta 的核心特点是支持运行非常多的任务,特别 CDC 多表同步等大量小任务的实时同步作业,同时支持集群模式,任务会分布在集群各个节点上去运行。
9. ** SeaTunnel Zeta **性能对比

我们对 Zeta 的性能进行了测试。对比了 MySQL 到 Hive、Postgres 到 Hive、SQL Server 到 Hive 的场景,还在云上测试了 MySQL 同步到 S3 的场景。测试数据约为 32 列,3000 万行,转换成 text 大概有 18G。使用了 1 个测试节点,是 8Core 16G。和 DataX 做了对比,目前在所有场景下比 DataX 快 30% 到 50% 左右,并且内存的降低对性能没有显著的影响。测试发现在低内存的场景下和高内存的场景下,对 SeaTunnel 的同步性能影响不大。

与国外的一些 SaaS 同步工具进行了对比,是 AWS DMS 和 Glue 的 2 到 5 倍,是 Airbyte 的三十多倍。目前在所有数据同步引擎中,SeaTunnel Zeta 引擎的速度是最快的。
03
**Apache SeaTunnel ****在 OLAP 场景下的应用**
**1. ****丰富的 OLAP引擎数据源支持**

下面介绍一下在 OLAP场景下的应用。目前支持的 OLAP 引擎包括 Doris、StarRocks、ClickHouse 以及 GreenPlum 等,仍在继续扩充中。
**2. ****批量同步各种数据源的数据到 OLAP 引擎**
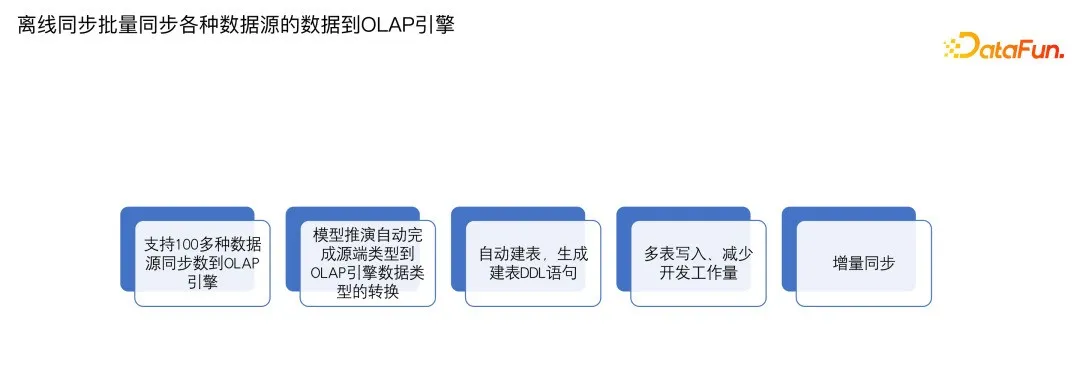
在离线批量同步到 OLAP 引擎场景,目前支持一百多种数据源能够离线批量同步到 OLAP 引擎里,包括传统的数据库、数仓、云上的文件系统,还有 socket、消息队列等等各种各样的数据源。在此过程中,能够去做模型推演,自动完成源端到目标端的类型转换,能够自动建表、生成建表 DDL 语句,并支持多表写入,减少了开发工作量,同时还支持增量同步。

以 Doris 为例,支持多表同步,多表写入,一次配置;支持模型推演,自动建表;支持多种表模型;使用 StreamLoader 这种方式高吞吐写入;支持事务和断点续传,支持 Exactly Once 数据精确一次写入;支持源端的 where 条件实现多表的增量同步。
**3. ****实时同步各种数据源的数据到 OLAP 引擎**
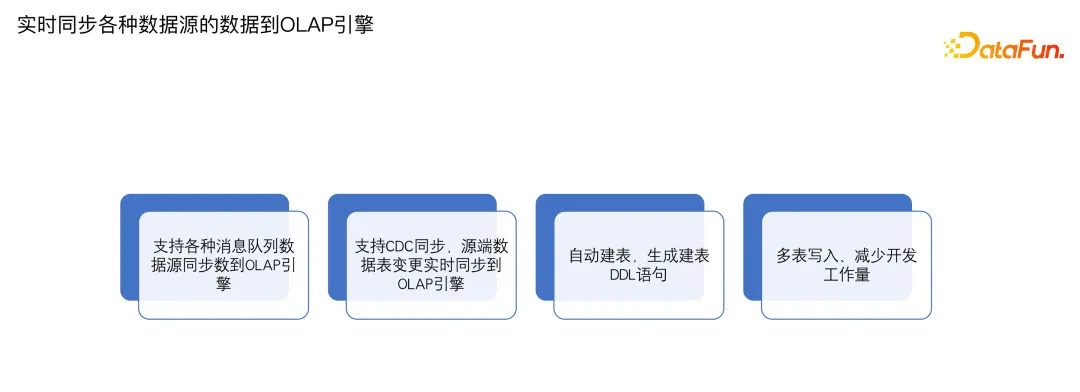
实时同步到 OLAP 引擎也同样支持各种数据源,比如消息队列,还有各种数据库,比如 MySQL、PG、Oracle、Sql Server 等,支持实时 CDC 同步到 OLAP 引擎里面。同样能够支持模型推演、自动建表,以及多表写入。
 同样以 Doris 为例,支持多表读取,多表写入,一次配置;支持模型推演,自动建表;使用 SteamLoader 写入,实现了高吞吐;支持 Checkpoint 的触发写入,实现了低延迟;支持事务,支持断点续传,实现精确一次写入。
同样以 Doris 为例,支持多表读取,多表写入,一次配置;支持模型推演,自动建表;使用 SteamLoader 写入,实现了高吞吐;支持 Checkpoint 的触发写入,实现了低延迟;支持事务,支持断点续传,实现精确一次写入。
04
社区近期计划
社区的近期规划主要包括以下几大方面: 
1. ** SeaTunnel Zeta Master/Worker **新架构
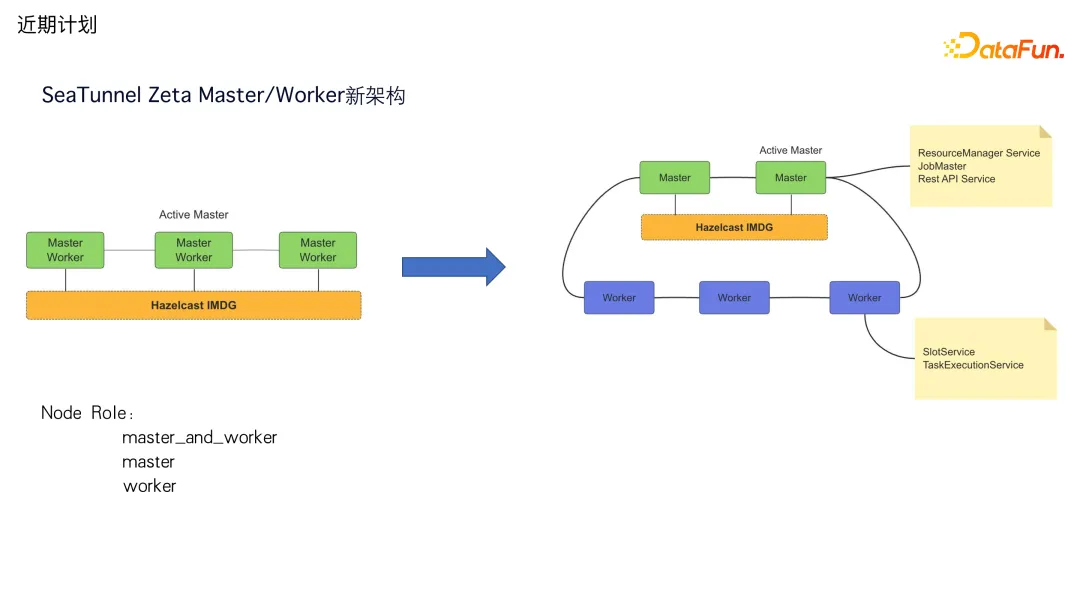
首先是实现 SeaTunnel Zeta Master/Work 新架构。
在 SeaTunnel 当前的架构里是不分 Master 和 Worker 角色的,所有节点既是 Master 又是 Worker,当然会从里面选 active 的 Master。
下面是分布式内存网格,就是在各个节点之间可以往 HashMap 里面去 put 数据,HashMap 就会分散在集群的所有节点中,有副本。Flink 等工具会把任务的状态信息存在 Zk 等三方系统中。而 SeaTunnel Zeta 不需要三方系统,其内部自带的分布式内存网格就可以存储作业的状态信息。任何节点挂了,它都会去重新分布内存网格里面的数据,保证作业在另外的节点去进行容错恢复时能够找到之前的状态。
之前存在一个问题,当 Master Worker 在一起的时候,一旦集群的负载比较高,假设一个 active Master 的节点挂了,它会容错在新的节点上,在容错的过程中,因为 Master 节点挂了,所有的任务都要重新进行容错,就可能导致新的 Master 节点上的 Worker 节点又产品高负载,这可能又会使新的 Master 挂掉。
基于这种场景,我们开发了新的架构,将 Master 和 Worker 分开部署,Master 上只存储数据和调度任务,Work 节点只进行任务的执行和资源的提供。这样整个 SeaTunnel 中节点的角色就分为 Master、Worker,master_and_worker 三种,可以根据需求去使用。
2. ** 支持使用 SQL 的方式创建 SeaTunnel 任务** 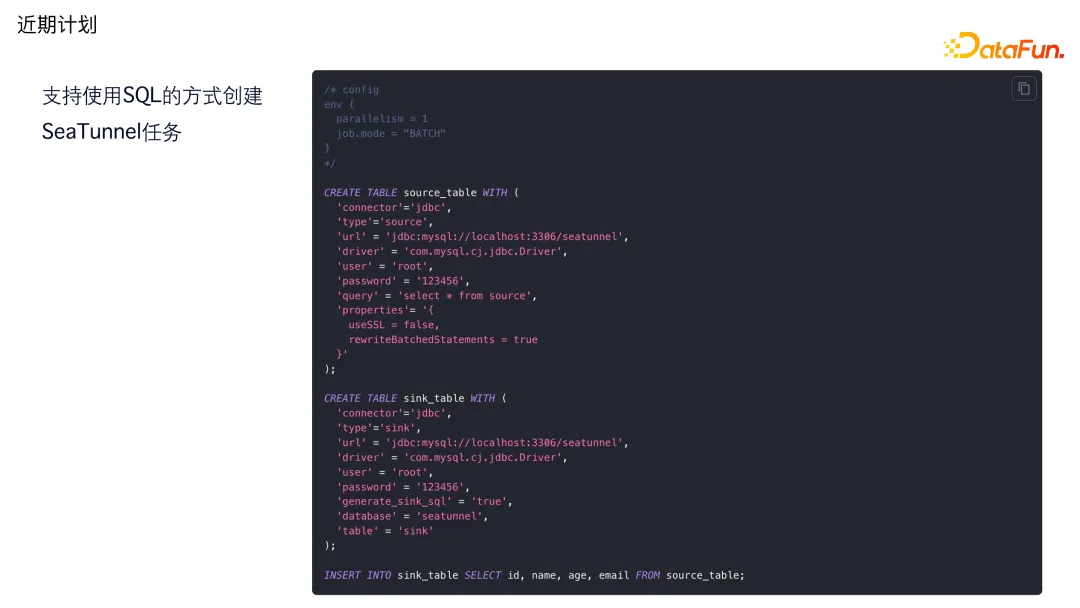
第二个是支持使用 SQL 的方式去创建 SeaTunnel 任务。之前 SeaTunnel 的任务创建是使用 HOCON 的文件格式,现在支持使用 SQL 的方式去创建任务。可以 create 一张 Source 表,一张 Sink 表,最终通过 insert into 语句,从 Source 表里面查数据,同步到目标表。这是一个即将发布的功能。
3. ** ClassLoader **及插件加载机制重构  第三个是 ClassLoader 支持插件加载机制,当前的版本 2.3.5 中,在一个集群里面,是没有办法既跑 Hive2 的同步任务又跑 Hive3 的同步任务的。因为 ClassLoader 隔离和 Flink 类似,Hadoop包使用的是 parent first 的机制,这就会导致整个集群里面只能有一个版本的 Hadoop 相关的包。考虑到同步的场景,可能会涉及到不同版本的 Hive 作业在集群里面去同步。所以我们进行了改造,把 Hadoop 相关的包改成了 child first。这样各个不同版本的 Hive 的同步任务和 Hadoop 的同步任务,就可以在集群里面互不干扰去进行运行。修改之后,包结构目录的结构有变化,这将在 2.4 版本中发布。
第三个是 ClassLoader 支持插件加载机制,当前的版本 2.3.5 中,在一个集群里面,是没有办法既跑 Hive2 的同步任务又跑 Hive3 的同步任务的。因为 ClassLoader 隔离和 Flink 类似,Hadoop包使用的是 parent first 的机制,这就会导致整个集群里面只能有一个版本的 Hadoop 相关的包。考虑到同步的场景,可能会涉及到不同版本的 Hive 作业在集群里面去同步。所以我们进行了改造,把 Hadoop 相关的包改成了 child first。这样各个不同版本的 Hive 的同步任务和 Hadoop 的同步任务,就可以在集群里面互不干扰去进行运行。修改之后,包结构目录的结构有变化,这将在 2.4 版本中发布。
4. ** Zeta CDC **同步释放空闲的 Reader
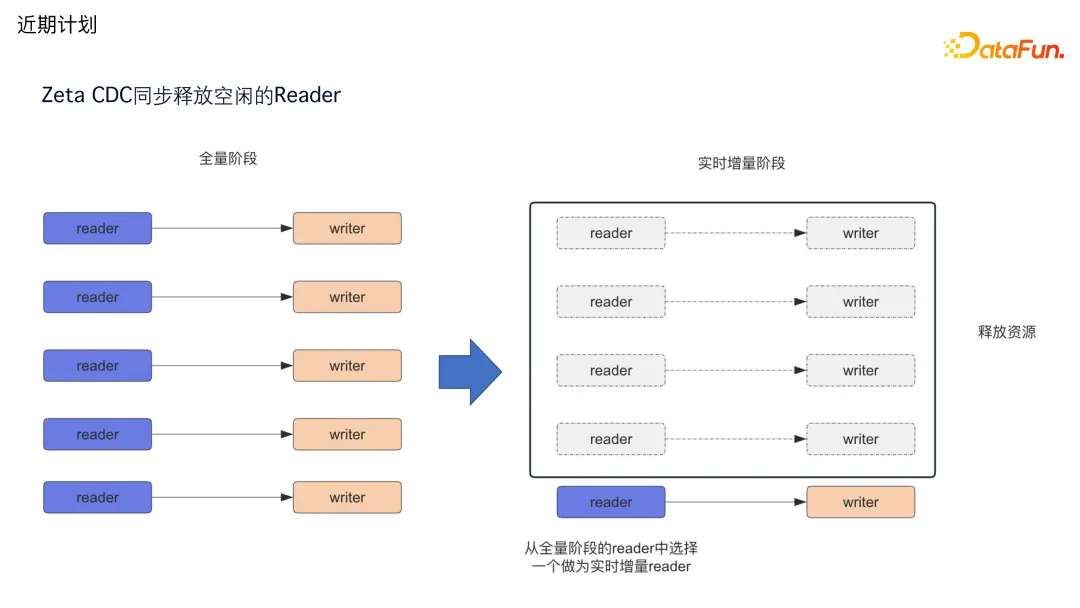
第四个是新增了 Zeta CDC 同步释放空闲 Reader 的功能。在 CDC 全量阶段,为了加快同步的速度,会并行地开很多 Reader 去进行数据的读取和写入。但是当它进入到解析 binlog 进行增量同步的时候,读取只能是单线程的,因为 binlog 是有序的,不能把顺序打乱。这个时候前面的四个 Reader 和 Writer 其实就没有任何的数据流了。当前的 2.3.5 版本会把它放在里面进行空转,即将发布的 2.3.6 版本里面,会释放之前的资源,把里面的 JDBC 资源、内存的资源等全部给释放掉,保证能够尽量占用更少的空间同步更多的数据,支持更大规模任务的运行。
针对单个 Writer 写入很慢的问题,可以在 Writer 里面设置 Writer 的线程数。这样读是单线程,而写又是多线程并行的写入。因为读是读文件,读文件解析是非常快的,单个作业能够达到每秒三十多兆。但写入有时候是瓶颈,所以在 Writer 端也支持设置并行度。
**5. ****支持事件通知机制**
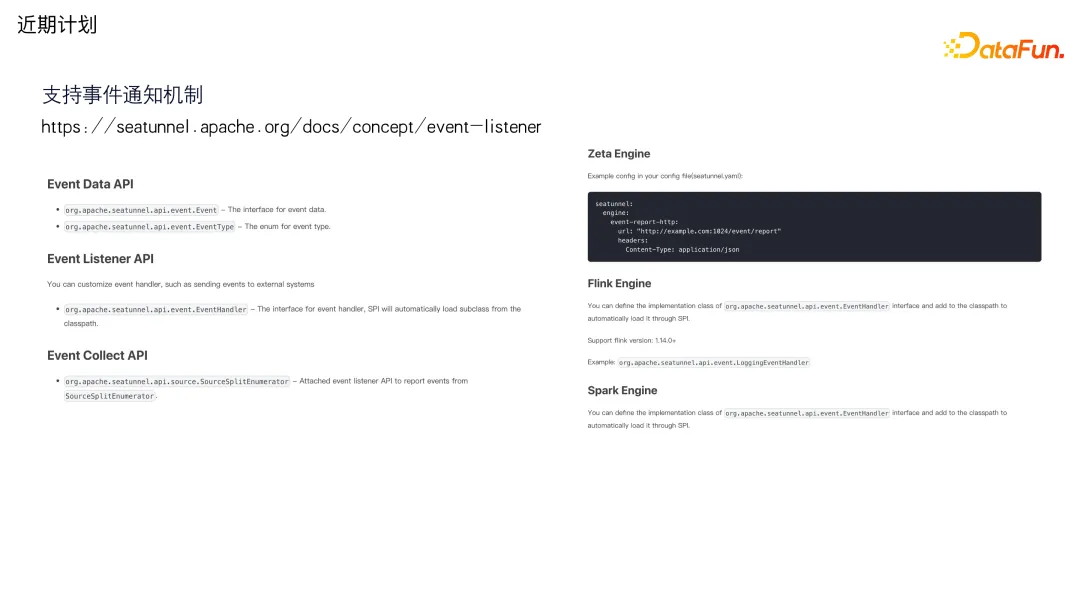
最后是支持事件通知机制,通过这些 API,可以将 Zeta 引擎里面产生的事件,比如作业成功或失败,或者 DDL 变更信息,这些都可以通过请求发送到别的系统中去。
05
**WhaleTunnel ****产品特性**
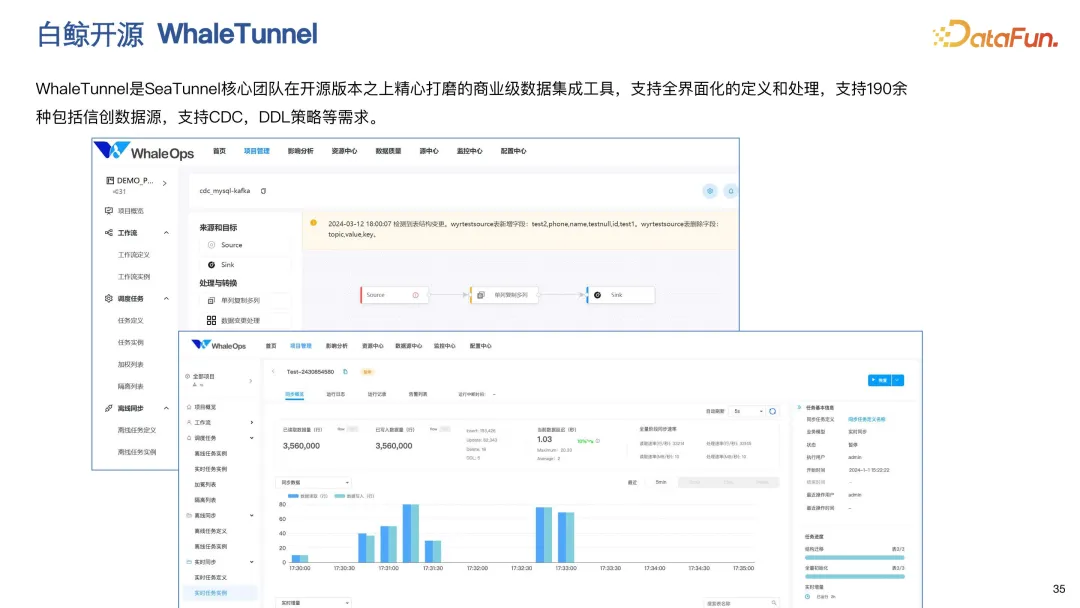
最后介绍一下 WhaleTunnel 产品的特性。WhaleTunnel 是基于 Aapache SeaTunnel 开发的商业化产品。它与 SeaTunnel 的区别是能够支持全部界面化的操作。和商业化的 DolphinScheduler 进行了深度的集成,支持同步任务的编排、依赖、并行等特性。同时提供全可视化的操作,有更详细的监控,界面非常友好,能够让用户更清晰地了解整个同步过程。

以上列表中,对 SeaTunnel 和 WhaleTunnel 进行了详细的对比。
商业版本支持更丰富的数据源,包括达梦、偶数、人大金仓、翰高等信创数据库,并支持对应的 CDC 同步。有些 CDC 的同步实现机制可能不同,比如开源版本对 Oracle 的 CDC 是使用 log miner 的方式,而商业版本则是有日志解析的 Oracle Agent 的实时同步方式。
可视化方面,商业版本支持可视化的模型推演,以及可视化的数据处理转换。在商业版本的 web 上,支持定时检查 DDL 变更,比如对于离线同步任务会定时检查源表是否有新增表、是否有表结构变更等等,如果有的话,会及时进行模型推演,检查任务配置是否正确,防止在调度起来后再出现任务报错。
监控力度方面,目前开源版本是作业级别的,商业版本会有全量阶段、增量阶段,还有各种结构迁移阶段,表级别的监控。当然开源版本中很快也会提供表级监控。
商业版本还支持其它一些功能,比如整库同步、DDL 变更的支持,还有 DDL 变更策略。针对 DDL 变更,能够去选择在下游是应用、忽略还是暂停,可以进行手工处理。
以上就是本次分享的内容。最后欢迎大家关注我们的项目和产品。 
06
问答环节
Q1**:信创数据源如何连接,比如 GaussDB?**
A1:对于信创数据源,目前 SeaTunnel 有 JDBC 可以直接去连接,在商业产品 WhaleTunnel 里面,采用 JDBC 的方式读,copy 的方式写入。因为 JDBC 写入是有性能瓶颈的,所以为了加快写入,我们使用了 copy 这种方式。
Q2**:CDC 的全量同步阶段是怎么做的?**
A2:全量同步阶段首先去加载这张表,读取这张表的 catalog table,读取到表结构信息,包括有没有主键、有没有唯一索引。拿到这些信息之后,基于主键或者唯一索引对这张表进行分片,通过 Source Split 分片枚举器那个接口。分片之后,根据用户设置的并行度,进行并行的读取。
在读取过程中,支持两种模式。第一种模式是在全量阶段,只同步历史数据,不管 binlog 数据,这种时候同步的性能是最快的,而且对内存的使用是最少的。第二种方式是一边读历史数据,同时一边去读 binlog 里面的数据,和历史数据做去重,最终把去重之后的数据写入到目标端。
第一种方式带来的问题是当全量阶段同步完成之后,再去开始增量同步,在目标端数据会有回溯,假设在同步历史阶段的过程中数据发生了变更。比如从 0 变成了 1,变成了 2,最后变成了 10,可能全量阶段同步完之后,目标端就已经是 10 了。这个时候再去同步增量阶段的 binlog 的时候,这个数据会发现从 10 会突然会变成 2,又从 2 变成 3、变成 4、变成 5,最终回到 10,虽然最终是一致的,但在这个过程中,数据会有回溯。第二种方式,一边存量一边增量的方式是不存在这一问题的。
Q3**:MySQL 增量 binlog 的性能大概能够有多少?**
A3:我们进行了测试,在不考虑目标端的情况下,源是 MySQL CDC,目标端是使用 Console Sink,Console Sink 一般是用来测试的,它类似于黑洞,就是数据来了之后它会把它吃掉,不会做任何的写入。测试结果显示每个任务能够每秒处理 30 兆的 binlog,即单个任务每秒 30 兆的性能。如果带宽大的话,还会有性能的提升。
Q4**:对达梦的 CDC 支持力度如何?数据准确性和一致性上能够保证到什么样的程度?**
A4:信创数据库是在商业产品 WhaleTunnel 里面支持的,采用了 logminer 那套实现机制。底层基于 Debezium 的 API 来实现。因为准确性是基于读回放和目标端的事务和幂等写入去实现的,所以在一致性上是没有问题的。性能方面需要去具体的生产环境测试,目前没有相关数据。
Q5**:实际上落地实施怎么样,有没有一些比较大的成功案例?**
A5:SeaTunnel 在进入 Apache 之前叫 Waterdrop,当时就已经有很多企业在用。目前京东、B 站都在用 SeaTunnel。B 站每天同步的数据在几百个 T,京东每天同步的数据量也达到了 T 级别,都是比较大的。当然还有其他很多企业在使用。
以上就是本次分享的内容,谢谢大家。
联系方式
公司网站: www.whaleops.com
联系邮箱: zenghui@whaleops.com
本文由 白鲸开源科技 提供发布支持!