动态资源分配,主要是spark在运行中可以相对合理的分配资源。
- 初始申请的资源远超实际需要,减少executor
- 初始申请的资源比实际需要少很多,增多executor
- Spark运行多个job,这些job所需资源有的多有的少,动态调整executor数量
相关参数
spark.dynamicAllocation.enabled:默认false,设置为true则启用动态资源分配,允许 Spark 根据任务需求自动调整执行器的数量。
spark.shuffle.service.enabled:默认为false,禁用独立的 Shuffle 服务。如果使用动态资源分配,需要设置为true,将Shuffle与Executor分开。
spark.dynamicAllocation.initialExecutors:默认0,初始执行器的数量。
spark.dynamicAllocation.minExecutors:默认0,执行器的最小数量。
spark.dynamicAllocation.maxExecutors:默认Int最大值,执行器的最大数量。
spark.dynamicAllocation.executorAllocationRatio:默认1.0,用于执行器分配的比例,表示给每个应用程序分配的资源相对于集群中所有可用资源的比例。
spark.dynamicAllocation.schedulerBacklogTimeout:默认1s,作业调度队列中作业等待的超时时间。
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout:默认1s,作业调度队列中连续等待的时间阈值。
spark.dynamicAllocation.executorIdleTimeout:默认60s,没有缓存的执行器空闲时自动释放的超时时间。
spark.dynamicAllocation.cachedExecutorIdleTimeout:默认Int最大值,有缓存的空闲执行器的超时时间。
ExecutorAllocationManager
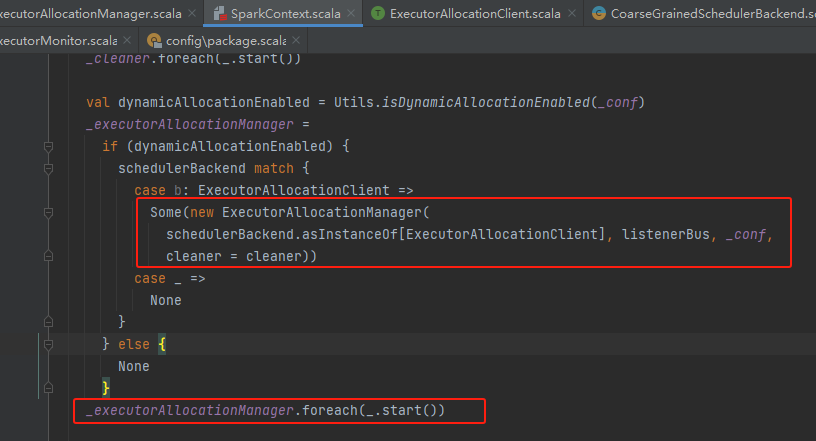
ExecutorAllocationManager是在SparkContext初始化的时候创建的,创建后调用它的start方法。
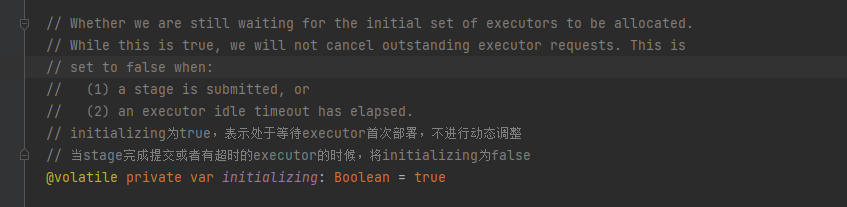
initializing变量标记ExecutorAllocationManager是否可以进行动态调整。
addTime变量是添加新的executor的时间点

start
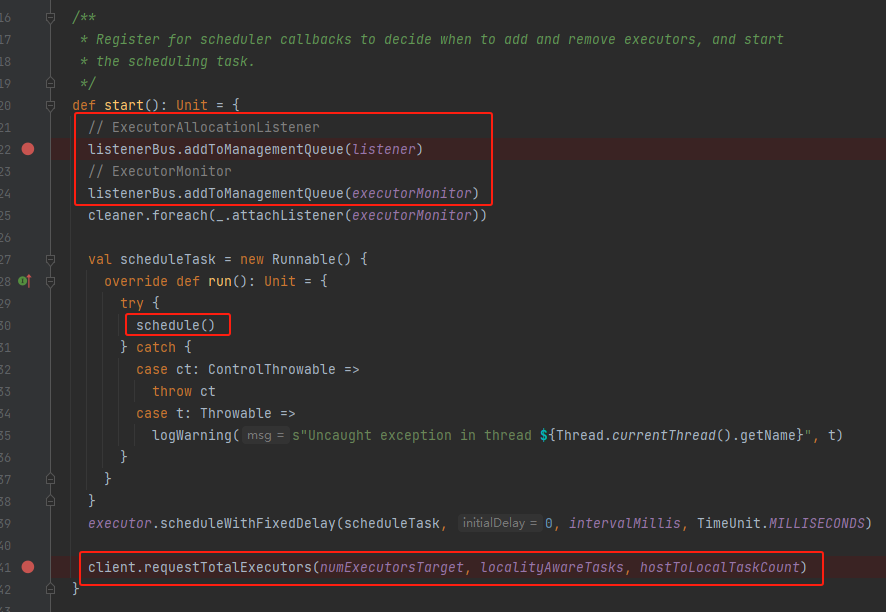
在start方法首先注册了两个listener:
- ExecutorAllocationListener:通知给定的分配管理器何时添加和删除执行器。
- ExecutorMonitor:执行器活动的监视器,用于检测空闲执行器。
定时调度每100ms执行一次schedule方法。
最后向更新集群发送所需executor的信息。
- numExecutors:向集群申请的executor数量。集群不一定为了达到这个数量就启动或者杀死executor
- localityAwareTasks:stage中具有局部首选项的任务数。这包括正在运行、挂起和已完成的任务。有些task是有指定在哪里运行或者哪里不运行的。
- hostToLocalTaskCount:host和希望在host上运行的task数量。包括正在运行、挂起和已完成的任务。
schedule
调用executorMonitor的timedOutExecutors获取超时的executor。
如有超时的executor,表明executor首次部署成功过,将initializing置为false,标志可以进行动态调整executor数量。
调用updateAndSyncNumExecutorsTarget方法向集群同步executor调度的相关信息,集群收到新的信息后会判断是否满足需求,不满足的话会添加executor。这里集群只可能增加executor来满足目标数量,不会进行kill executor。
最后调用removeExecutors移除超时的executor集合。
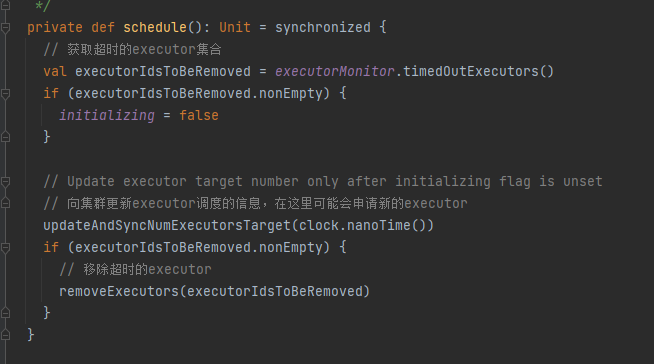
updateAndSyncNumExecutorsTarget
首先是调用maxNumExecutorsNeeded方法获取所需executor的最大数量。
- initializing为true,表明executor首次还没有部署完成,不能动态调整
- maxNeeded < numExecutorsTarget:此次所需的最大数量比上次申请的executor数量少,此时就要向集群更新executor目标数量,让集群可以停止还没有完成部署的executor的申请
- addTime != NOT_SET && now >= addTime:到达添加时间,可以申请添加executor
- 其他情况:没有达到添加时间

maxNumExecutorsNeeded
计算当前任务所需要的最大executor数量。
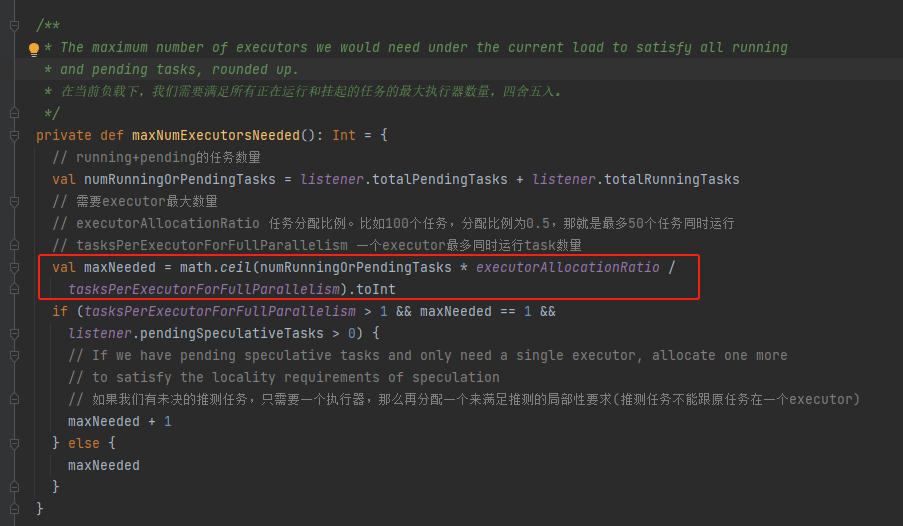
addExecutors
计算新的executor目标值,每次新增都是加上numExecutorsToAdd变量值。再经过校验调整到合理的值。
如果跟上一次的目标值一致,表示新增executor过程完成了,重置numExecutorsToAdd为1。
向集群发送executor目标值,让集群根据情况调整。
最后调整numExecutorsToAdd方便下一次扩容。
executor新增的速度是 1 2 4 8...,这样做是因为新增速度为固定值会造成目标1.executor数量小,增长速度大,申请了过多的executor;2.目标executor数量大,增长速度小,executor扩容慢。
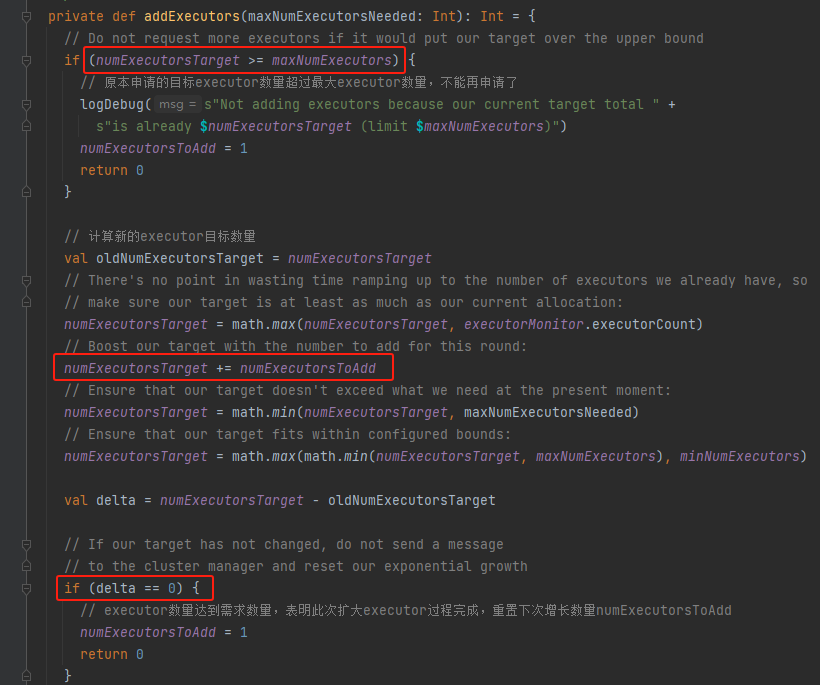
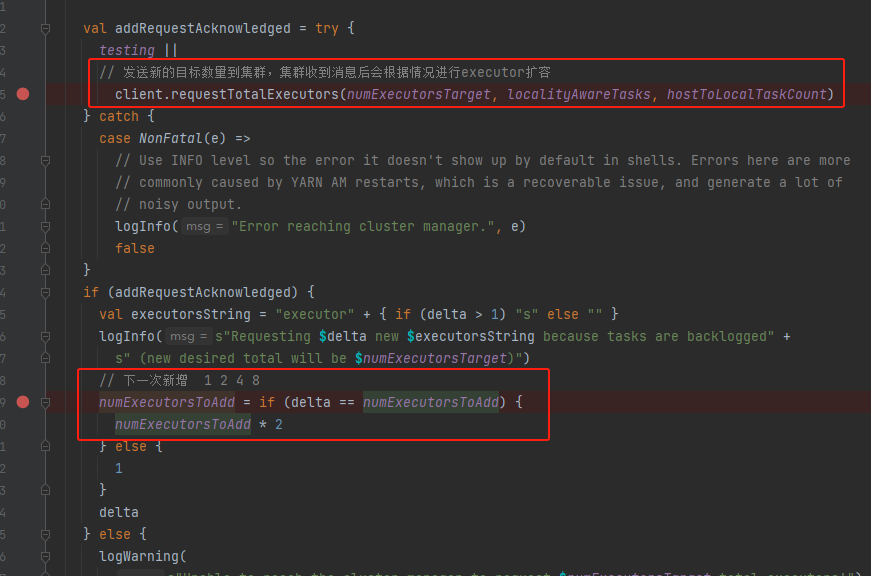
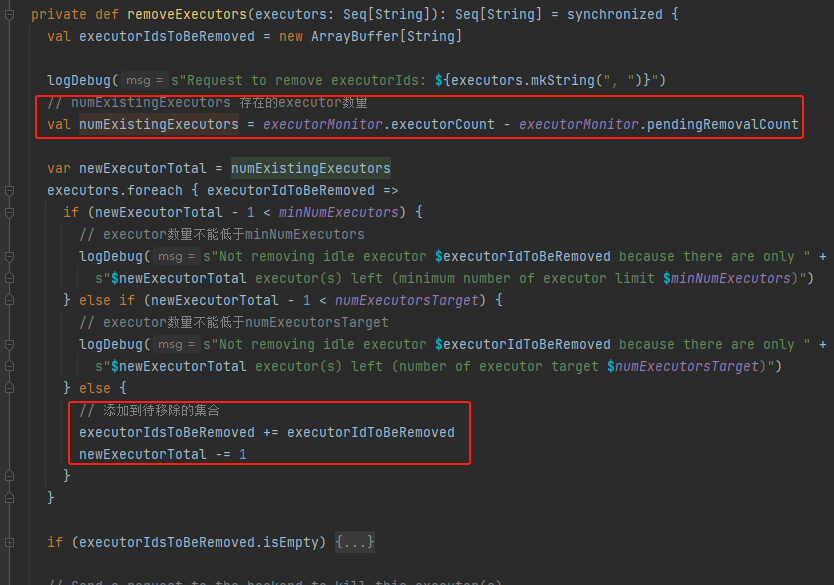
removeExecutors
移除executor不能直接将超时的executor都移除了,存活的executor数量还要大于等于executor最小数量、executor目标数量。
executorIdsToBeRemoved是实际需要移除的executor
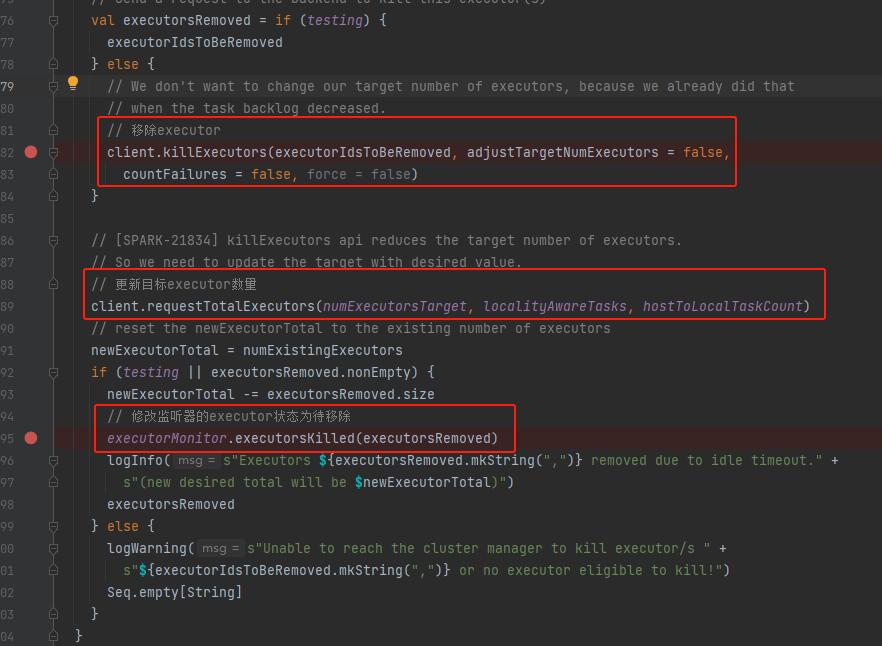
向集群发送kill executor的命令,更新executor目标数量到集群。最后修改executorMonitor中对应executor状态为待移除,不再进行监控这些executor
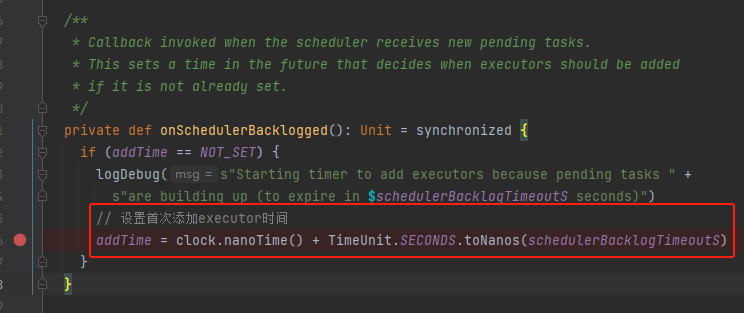
onSchedulerBacklogged
当调度程序收到新的待处理任务时调用回调。有挤压任务,添加addTime
- stage完成提交,等待task调度
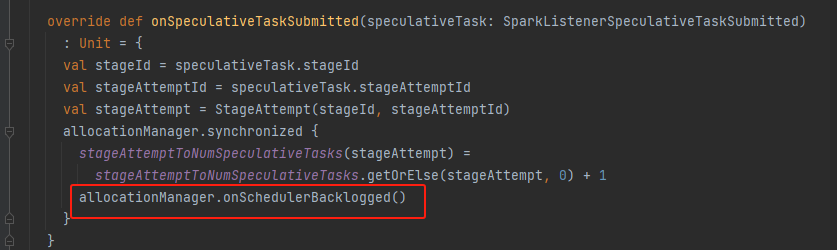
- 推测task提交
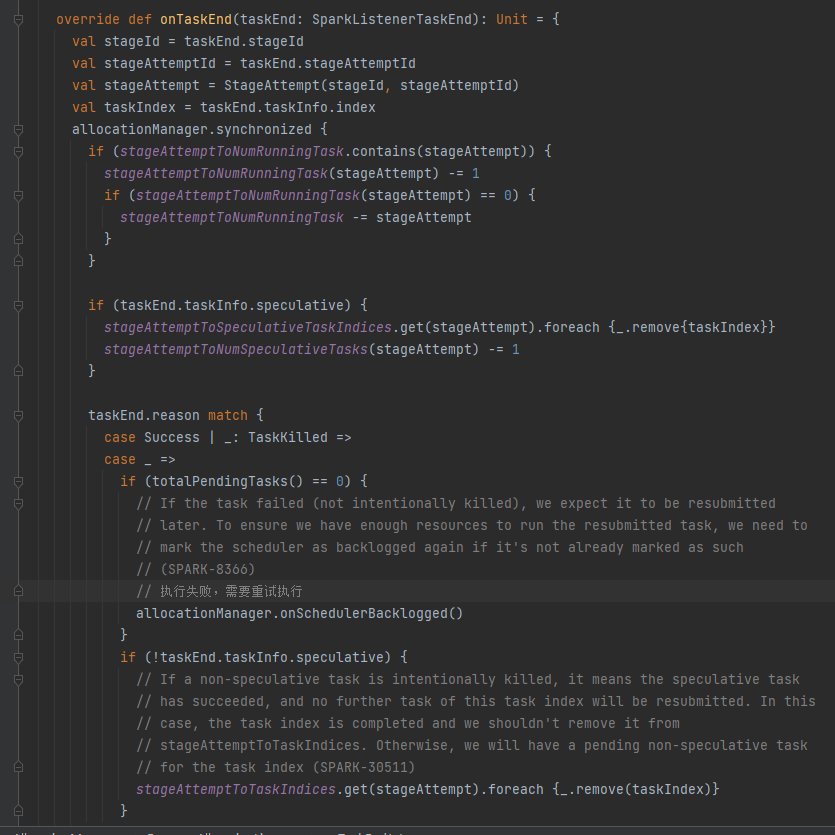
- task执行失败,需要重试执行
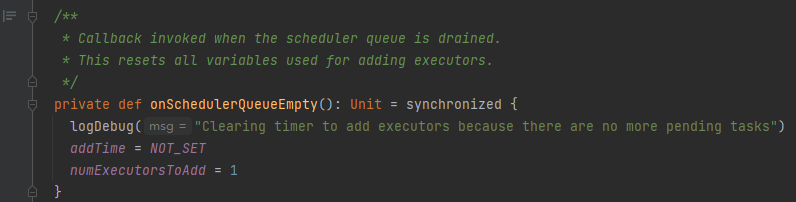
onSchedulerQueueEmpty
没有等待执行的task任务,重置addTime
- stage中task全部完成
- task开始,pending的task数量为0
ExecutorAllocationListener
可以简单看一下相关变量,只要是记录stage和task的关系(task总量,运行的task数量,pending的task数量,运行的推测task数量,pending的推测task数量。。。)
它是是一个listener,主要是监听了stage和task相关事件
- SparkListenerStageSubmitted
- SparkListenerStageCompleted
- SparkListenerTaskStart
- SparkListenerTaskEnd
- SparkListenerSpeculativeTaskSubmitted
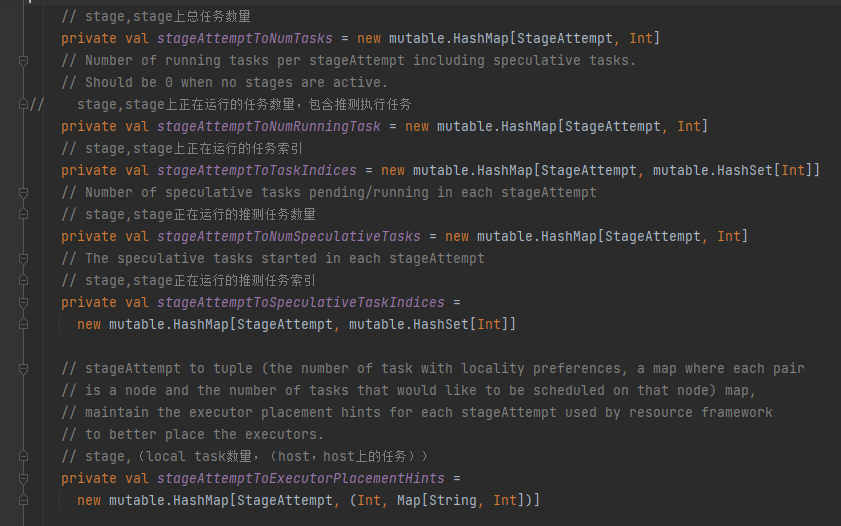
根据上面的变量,获取running和pending任务量
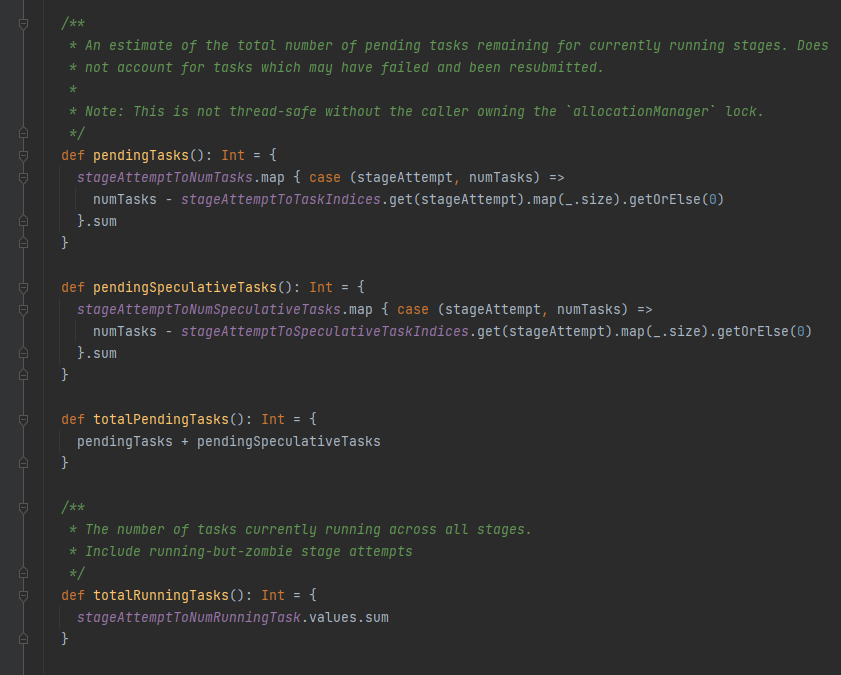
onStageSubmitted
stage提交完成,将initializing置为false。更新相关变量。
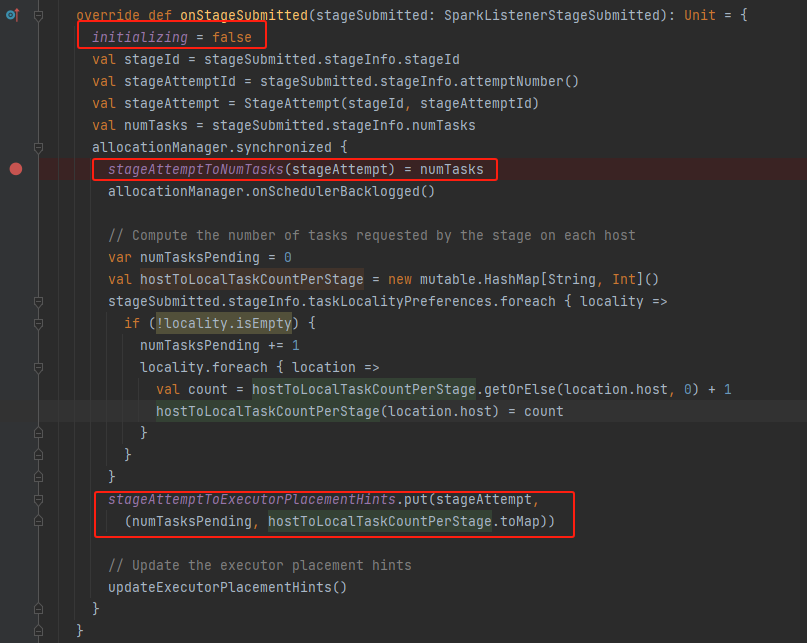
onStageCompleted
stage完成,修改相关变量。如果这个stage是最后一个stage,表明没有任务需要执行,就调用onSchedulerQueueEmpty将addTime、numExecutorsToAdd重置。
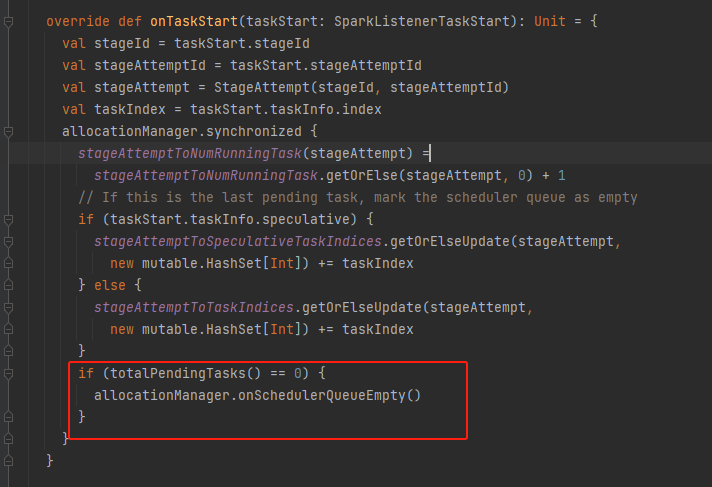
onTaskStart
task开始执行,更新相关变量。如果处于pending状态的task数量为0,调用onSchedulerQueueEmpty重置executor新增相关变量。
onTaskEnd
task执行结束,更新相关变量。
onSpeculativeTaskSubmitted
推测任务提交,更新相关变量。实际task数量增加,调用onSchedulerBacklogged进行新的调度。
ExecutorMonitor
ExecutorMonitor监听executor相关事件,使用Tracker记录executor的信息,可以返回超时的executor信息。
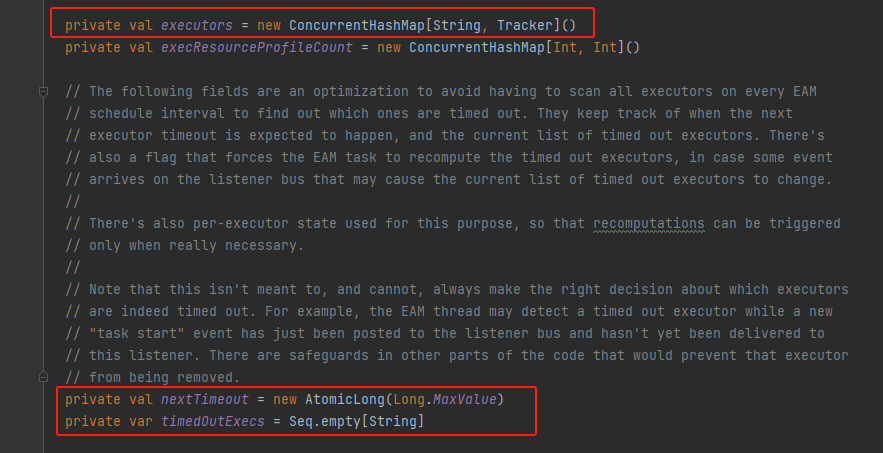
executors:executor信息的集合
nextTimeout:下一次超时的时间
timedOutExecs:超时的executor集合
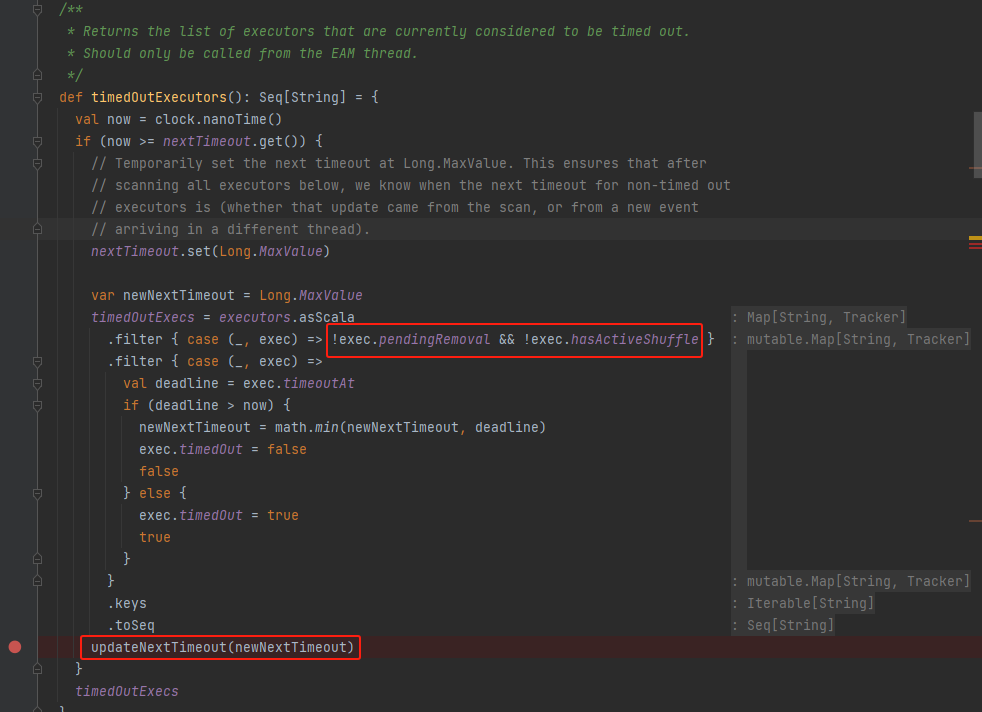
timedOutExecutors
遍历executor的tracker,获取超时的executor。最后更新下一次超时时间。
newNextTimeout下一次超时时间是所有executor中最近的超时时间
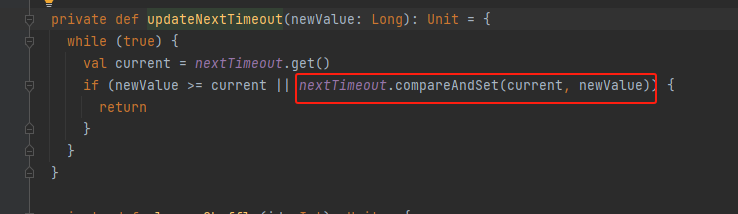
updateNextTimeout
更新nextTimeout
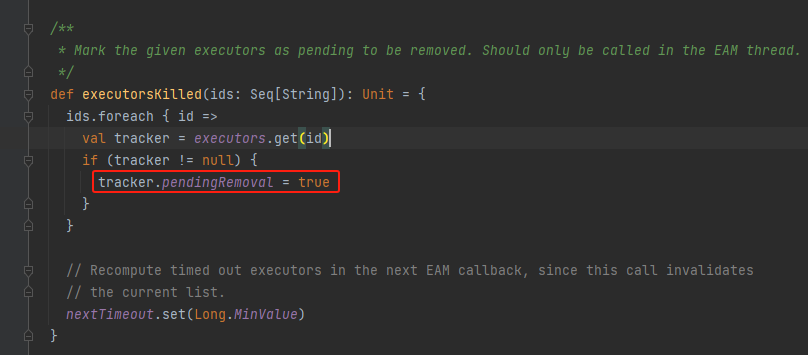
executorsKilled
是ExecutorAllocationManager在移除executor的时候调用,这里是标记executor为待移除,不是真的移除。真的移除是监听SparkListenerExecutorRemoved事件
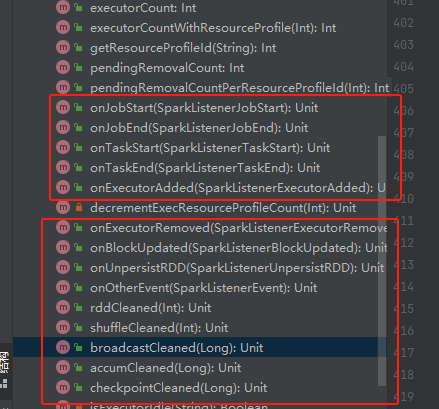
监听相关的方法
基本都是更新相关的变量
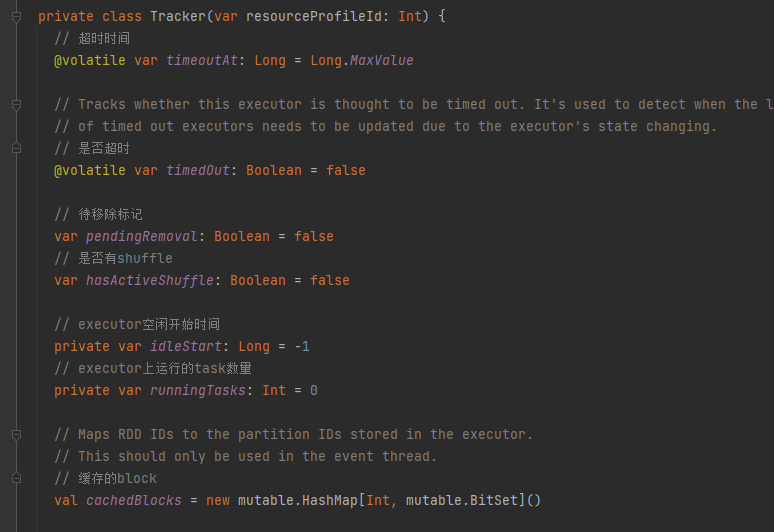
Tracker
记录executor信息
主要变量:
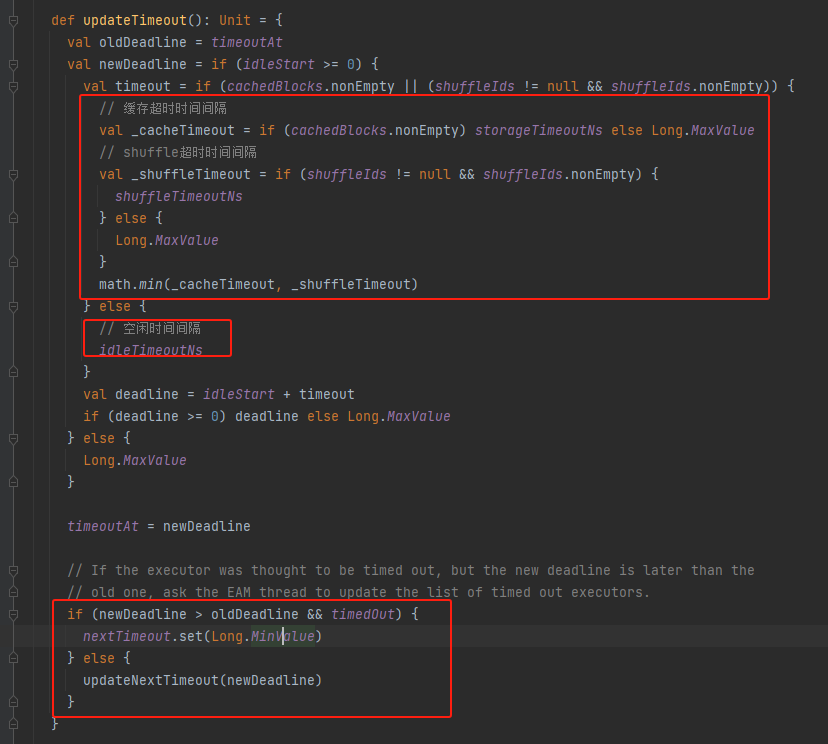
timeoutAt:超时时间
idleStart:executor空闲开始时间
cachedBlocks:缓存的block
updateTimeout
获取timeout,不含cache和shuffle的就是idleTimeoutNs,有cacje和shuffle的时候还要计算cache和shuffle的超时时间。
调用ExecutorMonitor的updateNextTimeout更新下一次超时时间nextTimeout