✨作者主页 :IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、PHP、.NET、Node.js、GO、微信小程序、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍:
本系统"基于大数据的1688商品类目关系分析与可视化系统"旨在通过对1688平台商品类目进行全面的分析,利用大数据技术对商品类目之间的层级关系、关键词分布和业务关联进行深度挖掘,并通过可视化手段展示各类目之间的内在联系与市场结构。系统基于Hadoop与Spark的分布式处理框架,通过Python、Java(两个版本),后端采用Django、Spring Boot框架(两个版本),前端利用Vue、ElementUI、Echarts等现代Web技术提供灵活的数据展示与交互界面。通过对商品类目的多维度分析与可视化展示,帮助用户深入理解平台商品的分类结构,发现潜在的市场机会。
选题背景:
随着互联网电商平台的迅猛发展,商品分类体系成为平台运营和商品管理的重要组成部分。1688作为阿里巴巴集团的B2B平台,汇聚了大量的商品和供应商,其商品类目体系涵盖了多个行业和领域。平台上商品类目的组织结构影响着商品的曝光度、购买流量以及供应链的效率。尤其是在大数据时代,商品类目之间的关系数据日益庞大且复杂,传统的手动分析方式已经无法满足实时数据分析的需求。因此,利用大数据技术对1688商品类目的关系进行全面剖析,已经成为一种迫切需求。通过对这些大数据的分析,能够有效识别出商品类目之间的关联模式,优化平台的商品分类体系,提高平台的商品管理效率。
选题意义:
本课题的研究意义体现在多个方面。首先,从学术角度来看,商品类目的层级关系与结构化分析属于电商平台大数据领域的前沿课题,通过对类目体系的深入挖掘,可以为电商平台的运营研究提供新的思路与方法。其次,从实践应用的角度,本系统能帮助1688平台和类似电商平台在商品分类和管理上获得精准的决策支持。通过对平台商品类目的全面分析,商家和平台管理者可以更好地理解市场趋势,进行精准的市场定位,优化产品推荐和推广策略。此外,系统对类目层级关系的可视化展示,有助于用户更加直观地了解平台商品结构,提升用户体验。最后,结合大数据技术,系统能够在海量数据中快速识别出潜在的商品关系和市场趋势,具有显著的商业价值和社会价值。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的1688商品类目关系分析与可视化系统界面展示:
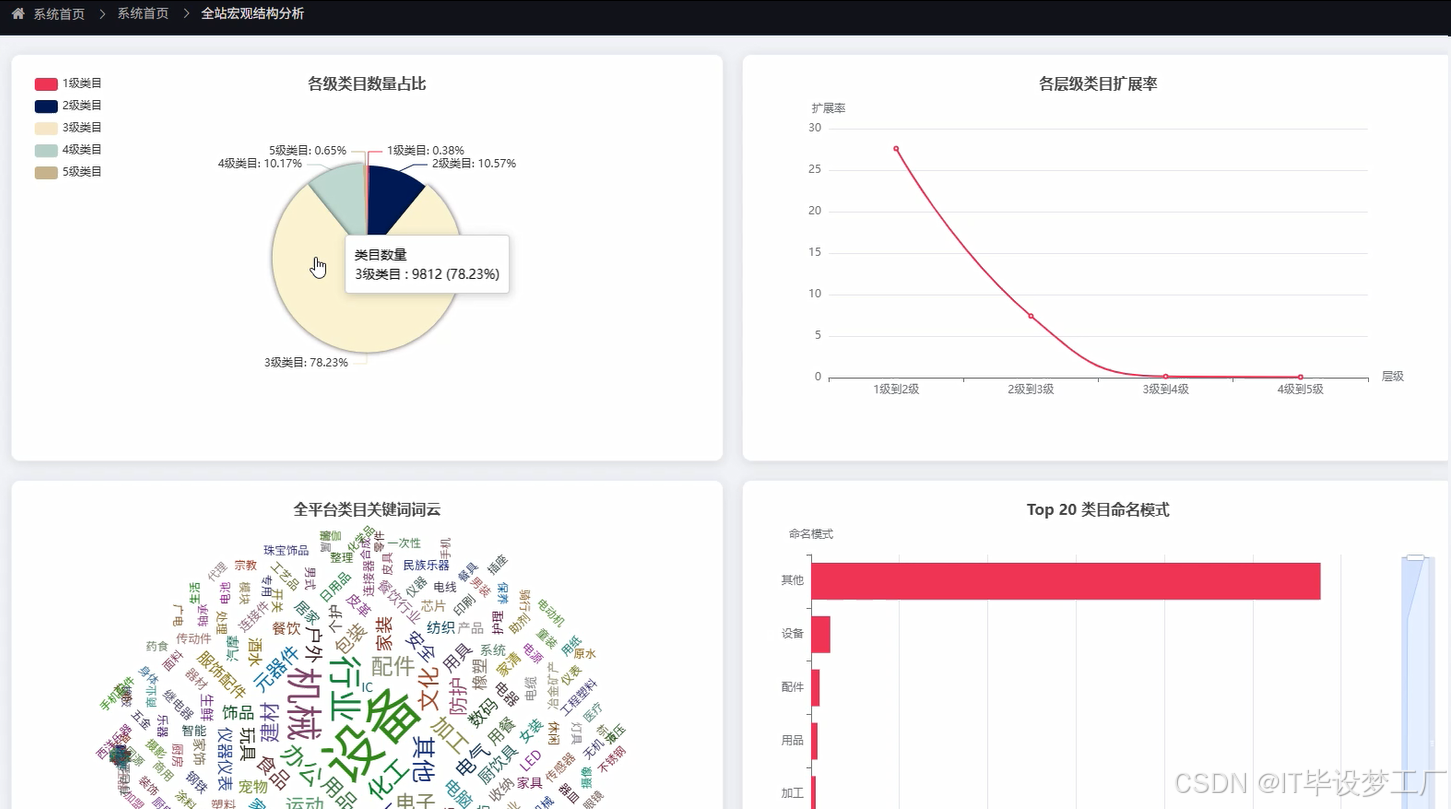
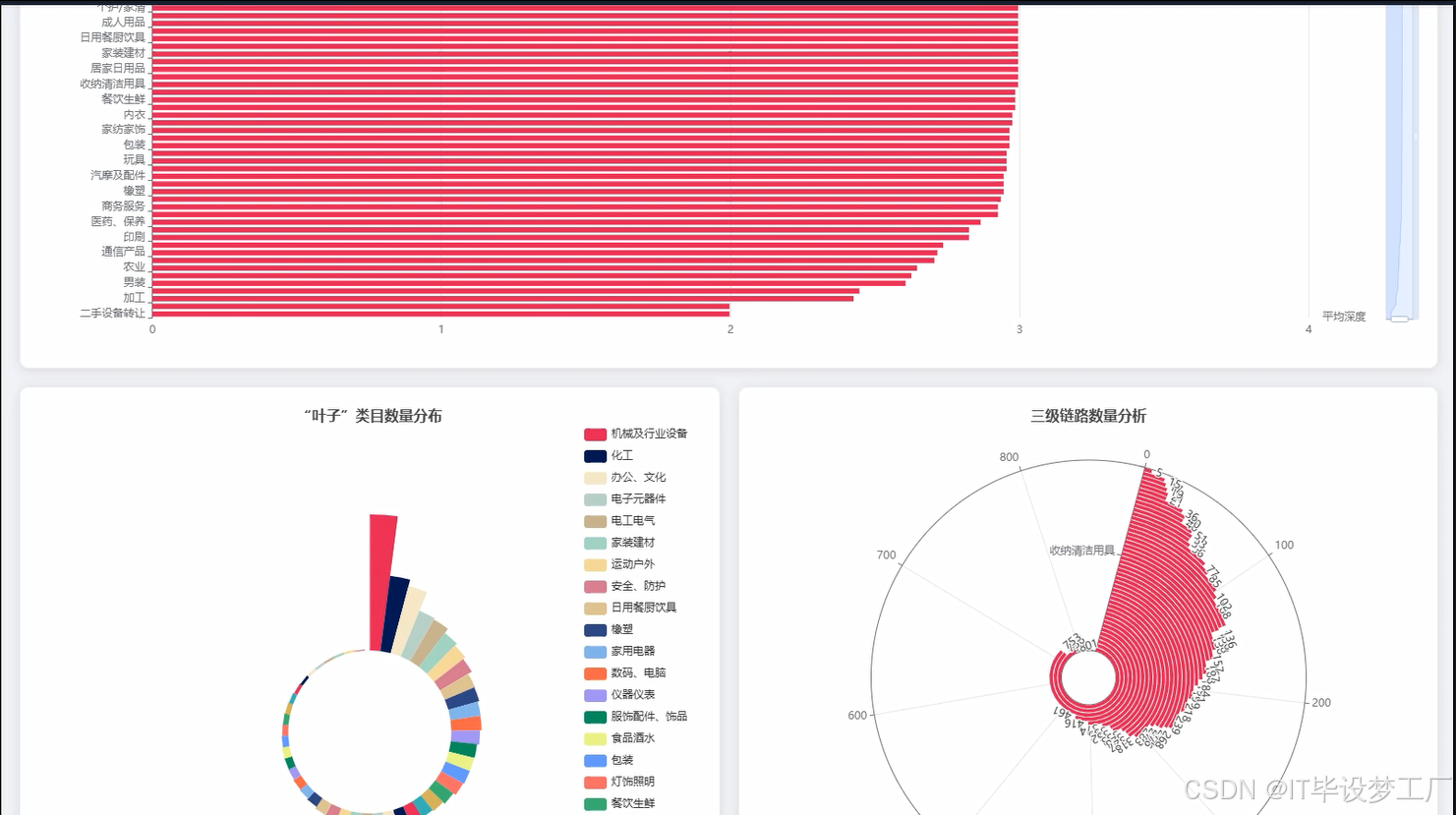
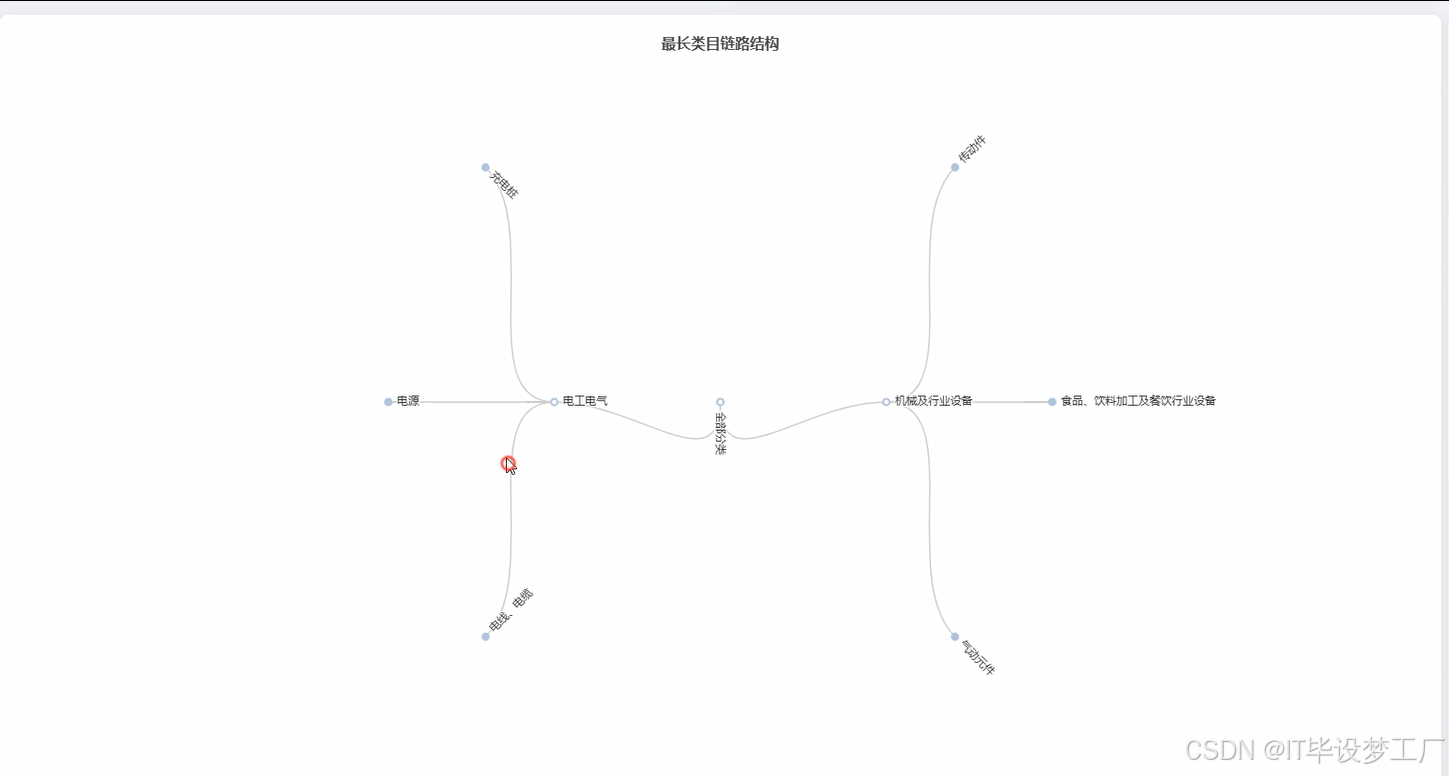

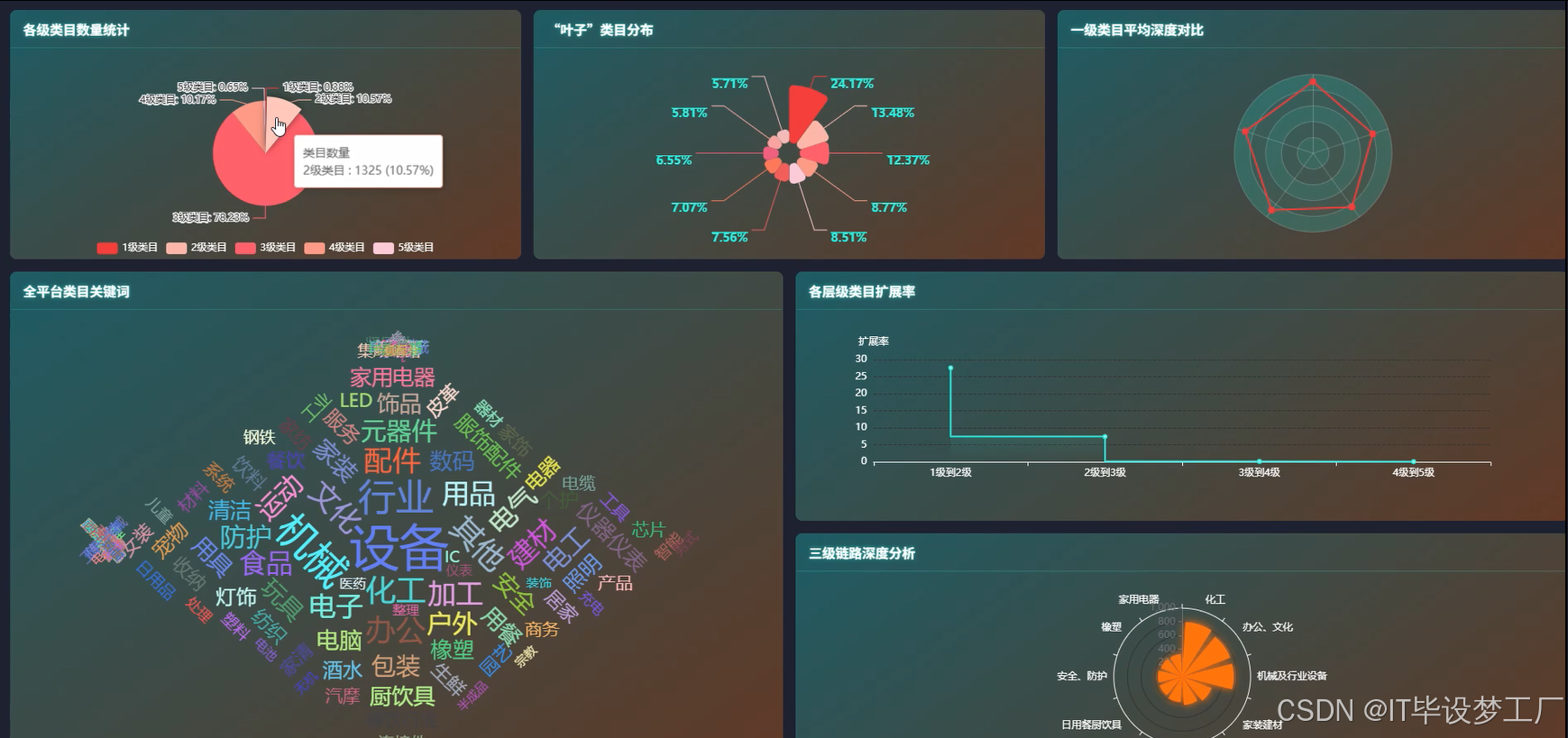
四、部分代码设计
- 项目实战-代码参考:
java(贴上部分代码)
# 引入大数据处理框架
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, countDistinct
import pandas as pd
import numpy as np
# 初始化SparkSession
spark = SparkSession.builder \
.appName("1688商品类目分析") \
.getOrCreate()
# 核心功能1: 全站各级类目数量统计
def category_level_count(dataframe):
# 从数据框中提取各个级别类目
level_1_count = dataframe.select("一级类目名").distinct().count()
level_2_count = dataframe.select("二级类目名").distinct().count()
level_3_count = dataframe.select("三级类目名").distinct().count()
level_4_count = dataframe.select("四级类目名").distinct().count()
level_5_count = dataframe.select("五级类目名").distinct().count()
# 返回各级类目的数量
return {"一级类目": level_1_count, "二级类目": level_2_count, "三级类目": level_3_count, "四级类目": level_4_count, "五级类目": level_5_count}
# 核心功能2: 各一级类目下二级类目数量对比
def category_depth_comparison(dataframe):
# 按一级类目分组,计算每个一级类目下二级类目数量
result = dataframe.groupBy("一级类目名").agg(countDistinct("二级类目名").alias("二级类目数"))
result.show() # 显示结果
# 转换为Pandas DataFrame以进行后续处理
result_pdf = result.toPandas()
return result_pdf
# 核心功能3: 类目层级深度分布分析
def category_depth_distribution(dataframe):
# 计算每个类目的深度(即非空的类目字段数)
dataframe = dataframe.withColumn("深度",
(col("一级类目名").isNotNull().cast("int") +
col("二级类目名").isNotNull().cast("int") +
col("三级类目名").isNotNull().cast("int") +
col("四级类目名").isNotNull().cast("int") +
col("五级类目名").isNotNull().cast("int"))
)
# 统计不同深度的类目数量
depth_dist = dataframe.groupBy("深度").count().orderBy("深度")
depth_dist.show() # 显示深度分布
return depth_dist
# 核心功能4: 类目网络"度中心性"Top N分析
def category_network_degree_analysis(dataframe):
# 转换为图结构,计算每个类目的连接数(即度)
edges = dataframe.select("父类目", "子类目").distinct()
vertices = edges.select("父类目").distinct().union(edges.select("子类目").distinct()).distinct()
# 创建图对象
from pyspark.graphx import Graph
graph = Graph(vertices.rdd, edges.rdd)
degree = graph.degrees
top_degree = degree.orderBy(degree["degree"], ascending=False).limit(10)
top_degree.show() # 显示度中心性Top N
return top_degree
# 核心功能5: 类目"社群"结构发现
def category_community_detection(dataframe):
# 将类目转换为图数据格式,进行社群发现
edges = dataframe.select("父类目", "子类目").distinct()
from pyspark.graphx import Graph
vertices = edges.select("父类目").distinct().union(edges.select("子类目").distinct()).distinct()
graph = Graph(vertices.rdd, edges.rdd)
communities = graph.connectedComponents()
# 提取社群信息
communities.show() # 显示社群分布
return communities五、系统视频
- 基于大数据的1688商品类目关系分析与可视化系统-项目视频:
大数据毕业设计选题推荐-基于大数据的1688商品类目关系分析与可视化系统-Hadoop-Spark-数据可视化-BigData
结语
大数据毕业设计选题推荐-基于大数据的1688商品类目关系分析与可视化系统-Hadoop-Spark-数据可视化-BigData
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇