1.引言
JVS-BI是一体化、自助式的数据分析平台,它采用的高度集成化的思路,针对企业级用户,提供集中仓库+便捷分析的企业级数据开发套件,解决企业各种需要数据分析的场景,多种数据库、多种业务系统、跨库关联、离线数据分析等等。
2.系统架构概览
1).系统架构:JVS-BI系统的整体架构图如下所示:
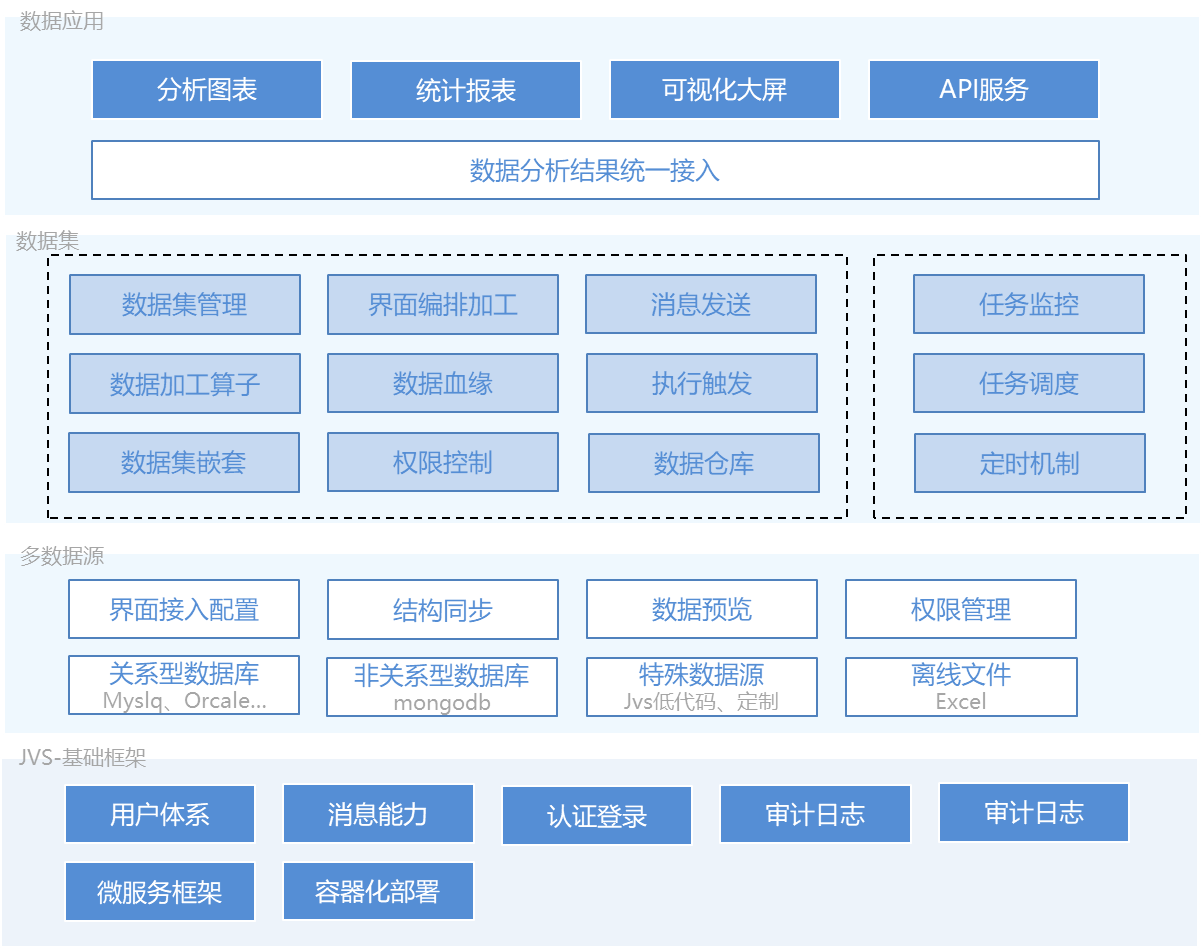
整体架构包含四层:
- 基础框架层:基础框架层采用 JVS 的统一数字化底座,包括基础的用户体系、基础的消息能力、统一认证、微服务框架等基础组件,实现BI 运行的基础环境。
- 数据接入层:数据接入层 采用 JDBC数据连接模式,实现各种数据库、数据文件的统一接入,屏蔽底层数据来源的异常差异,向上层数据存储、数据加工提供统一的基础服务能力。
- 数据加工层:采用界面化配置的ELT,实现数据的抽取、数据集中存储、数据的界面化加工、效果预览、任务调度等数据编排的能力,为数据引用提供分析结果。
- 数据应用层:系统提供图表(可嵌入业务系统中使用的数据可视化)、报表(明细数据统计)、大屏(数据可视化展示)、数据服务(API),实现配置与结果预览与调用。
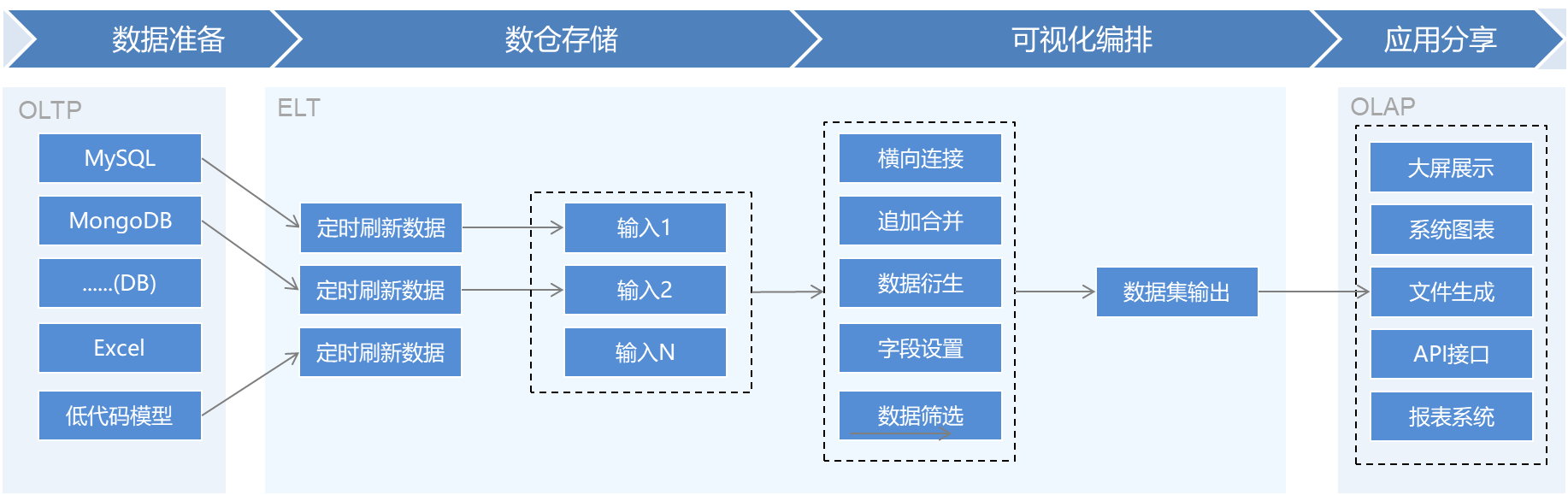
2).使用流程,如下图所示,由数据准备,数据集加工(抽取+编排)生成标准数据集,然后再配置数据的应用结果
3).架构特点:
- 私有化部署与技术开放性
- JVS-BI侧重于私有化部署,对数据安全性、敏感性高的客户
- JVS-BI可提供全源码开放的技术服务,主要向合作伙伴提供技术服务
- 可视化配置与低技术门槛
- JVS-BI采用多个配置化引擎,实现"0"代码的配置
- 数据源配置、数据集配置、大屏配置、报表配置、图表配置、API配置、门户配置
- 多数据源的集成接入
- 关系型数据库接入
- 分析型数据库的接入
- 离线数据文件(excel)的接入
- 独立的分布式数仓存储
- 采用独立数据仓库集中存储分析数据,不影响业务系统
- 采用doris 分部署数据仓库,支持海量的数据存储与加工
- 数据加工界面化配置
- 采用界面化、任务节点流程化 连接配置的方式,无需编写SQL脚本
- 采用抽取数据+模拟建模的方式,所见即所得,更加形象进行数据加工配置
- 采用完善的任务调度机制,前置、后置、定时调度等,支持多种数据加工场景
- 采用自动化的生成数据血缘关系,清晰的展示数据的来源与数据的最终用途
- 数据引用的界面化配置
- 图表的界面配置引擎
- 报表的界面配置引擎
- 大屏的界面配置引擎
- API数据服务的配置
3.技术栈说明
- 前端:Vue3+ElementPlus+Vite+Pinia
- 后端:Spring_cloud_alibaba、Spring boot、Mybatis plus、Nacos、RabbitMq、Xxl-job、Datax
- 数据:Doris、Mysql、Redis
- 运维:K8S+docker
4.核心组件详解
- 多数据源:该功能支持接入多种不同类型的数据源,包括但不限于关系型数据库(如MySQL, PostgreSQL等)、NoSQL数据库(如MongoDB)、大数据存储系统(如Hadoop)以及API接口等。用户可以根据需要灵活选择和配置所需的数据源,从而实现在一个平台上集中管理和分析来自不同来源的数据。
- ELT数据集:ELT(Extract, Load, Transform)数据集功能允许用户从各种数据源中提取(Extract)数据,将其加载(Load)到数据仓库中,并在加载后进行必要的转换(Transform)的界面配置操作。
- 图表配置器:图表配置器提供了一个直观的界面配置引擎,允许用户根据自己的需求选择和配置各种类型的图表(如柱状图、折线图、饼图等)。用户可以关联不同数据来源,自定义图表的数据源、颜色、轴标签、图例等多种属性,以满足不同的数据可视化需求。
- 报表配置器:报表配置器使用户能够轻松设计和生成数据报表,支持明细报表、分组报表、交叉报表等
- 大屏配置器:大屏配置器专为创建大型数据可视化展示而设计。用户可以通过拖拽和配置各种图表、指标和动态元素,构建出专业且吸引人的数据大屏。这些大屏可以用于实时监控、业务展示或会议演示等多种场景。
- API配置:API配置功能允许用户轻松集成和管理外部API服务。用户可以通过配置API请求参数、认证方式等,实现向其他系统提供加工后数据的API
- 任务执行监控:对任务执行提供界面化的监控界面。